
Research on the Method of Video Abstraction
Xueheng Wang
Dulwich College, Dulwich Common, London, U.K.
Keywords: Video Summarization, Deep Learning, Multimodal Learning, Unsupervised Learning, Reinforcement
Learning.
Abstract: Video summarization aims to generate compact and informative representations of video content by extracting
key frames or segments that best capture the original video’s semantics and narrative. With the explosive
growth of video data, particularly in surveillance, sports, and entertainment, video summarization has become
increasingly significant for efficient content browsing, indexing, and retrieval. Early summarization methods
relied heavily on low-level visual features and clustering heuristics. However, with the advent of deep learning,
especially recurrent neural networks and Transformer architectures, substantial improvements in
summarization quality have been achieved. This review presents a structured analysis of recent advances in
supervised and unsupervised video summarization techniques, focusing on attention mechanisms, multimodal
fusion, etc. The paper also explores domain-specific applications, particularly in sports video summarization,
where action localization and multimodal analysis have shown remarkable potential. A comparative analysis
of evaluation metrics and benchmark datasets is included to provide insights into current challenges. Finally,
the paper discusses open issues and propose future directions, such as improving temporal coherence,
minimizing annotation costs, and integrating semantic understanding for enhanced summarization. This
review aims to serve as a comprehensive reference for researchers and practitioners seeking to understand
and advance the field of video summarization.
1 INTRODUCTION
With the rapid development of the Internet, video has
emerged as a vivid and expressive medium of
information, becoming an indispensable part of
everyday life. The widespread use of short video
platforms has led to an enormous number of users and
a massive volume of video content uploaded daily.
This explosive growth of video data presents
significant challenges in information selection and
increases the burden on viewers. Simultaneously, the
proliferation of surveillance equipment has
accelerated the advancement of intelligent
monitoring technologies, playing a crucial role in
criminal investigations, urban management, and
campus safety. Globally, a vast number of
surveillance cameras generate massive amounts of
data every day, creating significant storage pressure.
Traditional data analysis methods are inefficient and
struggle to rapidly extract key content, severely
limiting the effective utilization of surveillance video.
Video summarization techniques aim to extract
key frames or segments to generate compact and
information-rich summaries that enable users to
quickly grasp the core content of a video. In the
context of short videos, summarization improves
browsing efficiency, satisfies users’ demand for quick
access to information, and contributes to increased
platform engagement. In surveillance, summarization
facilitates rapid identification of important events,
reduces the cost and time of manual retrieval, and
effectively alleviates storage burdens while
improving playback efficiency. Moreover, traditional
video editing heavily relies on manual effort, which
is time-consuming and labor-intensive, making it
unsuitable for today’s fast-paced environments.
Video summarization algorithms can automatically
identify and extract important content to generate
concise video clips, which are widely applied in
scenarios such as social media short videos, news
highlights, and movie trailers—greatly reducing
human effort and improving the convenience of
content creation and sharing.
In the domain of sports, video summarization also
plays a critical role. With the global sports market
growing rapidly—particularly football, which holds a
dominant position—video summarization provides
438
Wang, X.
Research on the Method of Video Abstraction.
DOI: 10.5220/0014360900004718
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 2nd International Conference on Engineering Management, Information Technology and Intelligence (EMITI 2025), pages 438-446
ISBN: 978-989-758-792-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

valuable tools for tactical analysis and training
reviews. It enables athletes and coaches to quickly
revisit key moments and opponent strategies, thereby
enhancing match preparation and understanding. For
fans, summarization delivers an enhanced viewing
experience by allowing them to enjoy the
highlights—such as goals and turning points—
without watching the entire match. Compared with
traditional manual editing, automated video
summarization systems significantly reduce human
and material resource demands, offering wide
applicability and notable effectiveness.
This paper focuses on the development of vi
deo summarization algorithms. The following sec
tions will introduce representative methods, datas
ets, and evaluation metrics in the field, and pro
pose future directions for improvement.
2 BACKGROUND AND RELATED
WORK
The concept of video summarization was formally
introduced in the 1990s (Barbieri et al, 2003). Early
methods primarily relied on optical flow analysis to
identify local minima of motion within video frames,
emphasizing the importance of static images to
extract summary segments. In 1996, Wolf et al.
proposed viewing a video sequence as a trajectory
curve in a high-dimensional feature space (Wolf,
1996), where the intersection points of curve
segments were selected as keyframes for multi-level
video summarization. In 2000, Doulamis et al.
introduced a method based on constructing
multidimensional fuzzy histograms of video frames
(Doulamis et al, 2000), identifying keyframes by
eliminating shots or frames with similar content.
These approaches represent several early traditional
techniques for video summarization.
With the rapid advancement of machine learn
ing in recent years, deep neural networks have
been successfully applied to the field of video s
ummarization, achieving promising results. Deep
learning-based methods can be broadly categoriz
ed into supervised (and weakly supervised) and
unsupervised learning approaches.
2.1 Supervised Learning
Supervised methods based on deep learning treat
video summarization as a prediction problem,
estimating the frame-level importance by modeling
temporal dependencies between frames. During
training, the network receives a sequence of video
frames along with user-annotated ground-truth
summaries. The predicted importance scores are
compared with the ground-truth annotations, and the
model is optimized through backpropagation using a
designated loss function.
Based on this approach, Zhang et al. were the first
to propose, in 2016 (Zhang et al, 2016), the use of
Long Short-Term Memory (LSTM) networks to
model temporal dependencies among video frames.
They employed a Multilayer Perceptron (MLP) to
predict frame-level importance scores and
incorporated a Determinantal Point Process (DPP) to
enhance the diversity of visual content in the
generated summary. The architecture is illustrated in
Figure 1. Building on this framework, Zhao et al.
proposed a two-layer LSTM architecture in 2017
(Zhao et al, 2017). The first layer encodes structural
information from the video, while the second layer
estimates the importance of video segments based on
this representation and selects the key segments for
summarization.
Subsequently, in 2018, Zhao et al. further
integrated a trained module designed to detect shot-
level temporal structures within the video (Zhao et al,
2018). This prior knowledge was then used to
estimate the importance of each shot, resulting in a
final video summary composed of key shots. In 2019,
Lebron Casas et al. extended the LSTM-based
framework by incorporating an attention mechanism
to model user interest (Lebron et al, 2019).
The attention-enhanced information was then
used to estimate frame-level importance and select
keyframes for constructing a video storyboard. It is
advisable to keep all the given values
Figure 1: The video summarization algorithm based on
supervised model (Zhang et al, 2016).
In addition, several approaches have adopted the
Sequence-to-Sequence (Seq2Seq) architecture,
originally developed in the field of natural language
processing, to compute importance scores through an
Research on the Method of Video Abstraction
439
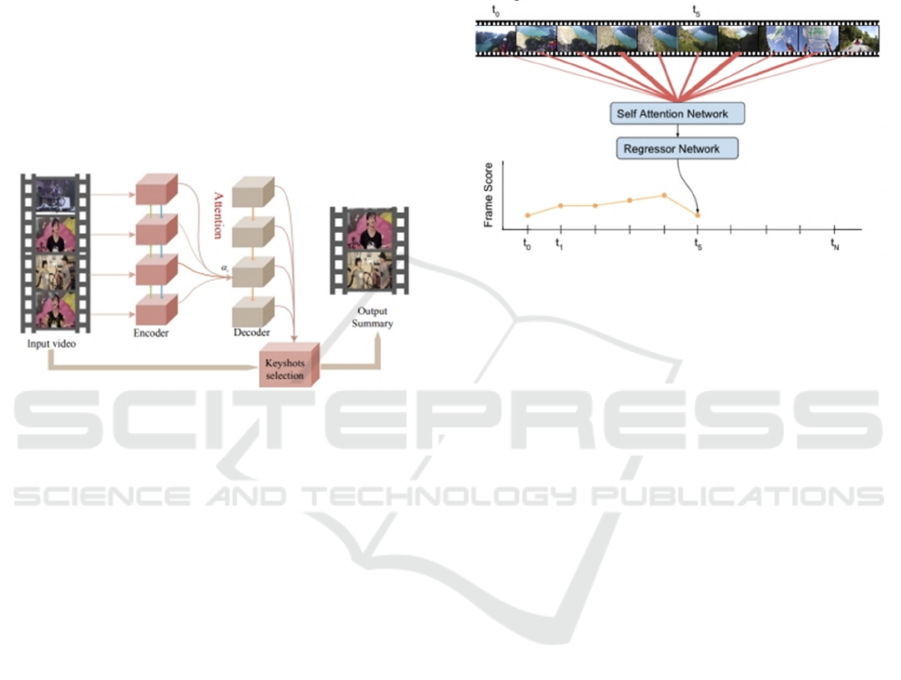
encoder– decoder framework. In this structure, the
encoder is responsible for extracting video features,
while the decoder predicts the frame-level importance
scores.
In 2019, Ji et al. formulated video summarization
as a Seq2Seq learning problem and proposed an
LSTM-based encoder – decoder network with an
intermediate attention layer, as illustrated in Figure 2
(Ji et al, 2019). In the same year, Lal et al. improved
the decoder design by employing a convolutional
LSTM to better model the spatiotemporal
relationships within the video (Lal et al, 2019),
leading to improved performance. In 2021, Gao et al.
also adopted this structure and achieved promising
results (Gao et al, 2021).
Figure 2: The video summarization algorithm based o
n supervised model (Picture credit: Original)
With the remarkable success of Transformers in
the field of computer vision, several studies have
incorporated the self-attention mechanism to replace
LSTM for video feature extraction. In 2019, Fajtl et
al. proposed a video summarization network that
employs self-attention to extract video features,
followed by a two-layer fully connected network to
compute frame-level importance scores (Fajtl et al,
2019). The model architecture is illustrated in Figure
3.
In 2023, Khan et al. directly utilized the Vision
Transformer (ViT) model as the feature extractor and
introduced a pyramid structure to refine multi-scale
features (Khan et al, 2023; Puthige et al, 2023). In
another study, the standard multi-head attention
mechanism was enhanced with channel attention and
spatial attention modules to more effectively capture
inter-feature dependencies (Hsu et al, 2023).
Furthermore, a spatiotemporal Transformer
architecture was proposed to explicitly model the
correlations between non-adjacent frames, resulting
in improved summarization performance (Rochan et
al, 2018).
In addition, building upon the Seq2Seq
framework, Rochan et al. introduced a novel
approach that combines Fully Convolutional
Networks (FCNs) with the DeepLab semantic
segmentation model to analyze video content,
offering a new perspective for video summarization
(Long et al, 2015; Chen et al, 2017; Zhao et al, 2021).
Figure 3: video summarization model based on self-
attention algorithm (Picture credit: Original)
Given the multimodal nature of video data, many
approaches incorporate features from different
modalities to enrich the extracted representations and
achieve more accurate summarization results.
Commonly used features include audio and textual
information, which, when combined with visual
features, provide more comprehensive context for
video analysis and help improve both model
performance and robustness.
In 2021, Zhao et al. utilized both audio and visual
information for video summarization by extracting
features from each modality using LSTM networks,
as illustrated in Figure 4 (Zhao et al, 2021). Zhang et
al. introduced a semantic video encoder to extract
high-level semantic information, which was then
combined with visual feature representations to
enhance the model’s sensitivity to important content
(Zhang et al, 2023).
In addition, multimodal features can also be
augmented through human-centric signals. For
example, proposed a novel video summarization
framework based on eye-tracking data. This method
calculates motion saliency scores by measuring the
distance between the viewer’s current and previous
fixation points, and uses these scores as auxiliary
features alongside visual features to guide the
summarization process (Paul et al, 2019).
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
440

Figure 4: Multimodal Feature Video Summarization Algorithm Example Diagram (Picture credit: Original).
2.2 Unsupervised Learning
Although supervised video summarization methods
can yield relatively good results, they heavily depend
on manually annotated datasets, which are costly and
time-consuming to produce. To address this limitation,
unsupervised learning methods have emerged. In the
absence of explicit supervision (i.e., ground-truth
labels used in supervised learning), most unsupervised
approaches adopt heuristic strategies that define
constraints based on quantifiable characteristics of
summaries, aiming to generate segments that best
represent the original video content.
The main idea of clustering-based methods is to
first aggregate similar shots together and select
cluster centers as components of the summary
segments. In 1998, Y. Zhuang et al. first used this
method, directly clustering video frames with similar
features and selecting cluster center frames to form
the final video summary (Zhuang et al, 1998). In 2006,
Y. Hadi et al. improved the clustering accuracy by
using K-nearest neighbor methods on this basis (Hadi
et al, 2006). Additionally, combining prior
information from specific domains with clustering
methods can yield better results. References further
integrated color information as features for clustering,
achieving remarkable performance. The algorithm
flowchart is shown in Figure 5 (Mundur et al, 2006;
Avila et al, 2011).
Figure 5: Video summarization model based on clustering methods (Picture credit: Original).
GAN-based methods primarily learn
summarization by distinguishing between the original
video and summary segments generated by the
generator. The model typically consists of a generator
and a discriminator: the generator estimates frame
importance and produces summaries, while the
discriminator judges the similarity between the
generated summary and the original video. When the
discriminator fails to distinguish between the two
videos, it indicates that the generator has learned to
construct summary segments representing the entire
video content. In this context, Mahasseni et al. first
integrated an LSTM-b-ased keyframe selector with a
variational autoen-coder and a trainable discriminator,
learning video summarization through an adversarial
training process (Mahasseni et al, 2017).
Research on the Method of Video Abstraction
441
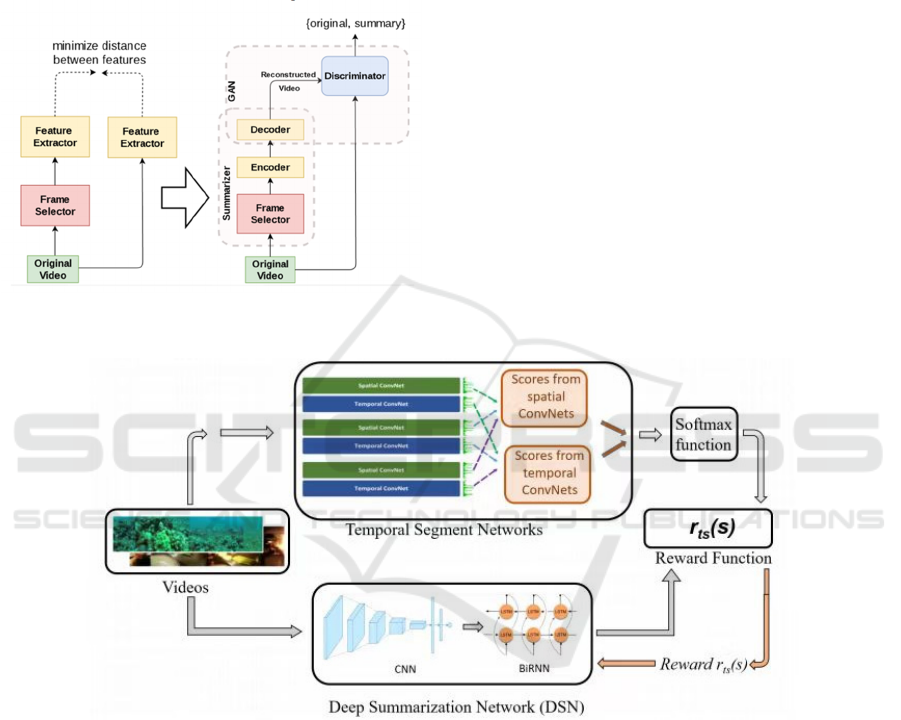
Subsequently, Apostolidis et al. proposed a label-
based method to train the adversarial component of
the network (Apostolids et al, 2020). Jung et al.
extended the attention mechanism on the basic
framework to evaluate frame dependencies across
different temporal granularities during keyframe
selection (Jung et al, 2019). The model schematic of
GAN-based methods is shown in Figure 6.
Figure 6: A schematic diagram of a video summarization
model based on GAN network (Picture credit: Original)
Reinforcement learning-based methods mainly
achieve video summarization by maximizing reward
functions. Zhou et al. proposed the first work in this
direction, defining video summarization as a
decision-making process and training the summary
generator through diversity-representativeness
rewards (Zhou et al, 2018). On this basis, Yaliniz et
al. further considered the consistency of generated
summaries (Yaliniz et al, 2021). Gonuguntla et al.
utilized segment networks within the basic
framework of the first work in this field to better
extract spatial and temporal information of video
frames (Gonuguntla et al, 2019), training the
summary generator via reward functions. Reference
enriches features by extracting shot-level information
while setting three shot-based reward functions for
generator training (Yuan et al, 2023). Reference
employs a Unet network as an encoder-decoder based
on diversity-representativeness rewards to further
enrich features (Zang et al, 2023). Figure 7 shows a
schematic diagram of a video summarization model
based on reinforcement learning.
Figure 7: Diagram of a video summarization model based on reinforcement learning (Picture credit: Original)
3 DATASETS, EVALUATION
METRICS, AND METHOD
PERFORMANCE
COMPARISONS
3.1 Datasets
This section provides a detailed introduction to four
datasets in the field of video summarization, where
Cosum and MPII Movie Description Dataset are
domain-specific datasets, while TVsum and SumMe
are general-purpose datasets.
The SumMe dataset consists of 25 first-person
view videos from YouTube (Gygli et al, 2014),
featuring diverse contents and themes such as sports,
travel, and daily activities. Each video ranges from 1
to 6 minutes in length. For each video, user-generated
summaries and their keyframes are provided. The
summaries are manually annotated by users who
mark the parts they consider most representative of
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
442

the video content. Figure 8 shows several video
examples from the SumMe dataset.
Figure 8: Example Images from the SumMe Dataset Videos
(Picture credit: Original).
The TVSum dataset comprises 50 third-person
perspective video clips sourced from YouTube (Song
et al, 2015), each ranging from 3 to 10 minutes in
length. These videos span ten diverse categories, such
as sports, news, and movies, with five videos per
category. The dataset also provides frame-level and
keyframe annotations derived from summaries
generated by multiple volunteers. Figure 9 displays
example images from several videos within the
TVSum dataset.
Figure 9: Example Images from the TVsum Dataset Videos
(Picture credit: Original).
The CoSum dataset contains videos sourced from
news reports and documentaries, providing sentence-
based summary annotations (Chu et al, 2015). This
dataset is primarily designed for video understanding
research and studies focusing on natural language
summarization.
The MPII Movie Description Dataset comprises
video clips from various film genres, accompanied by
detailed natural language descriptions. It is suitable
for research on movie video summarization
incorporating semantic information.
The YTB dataset includes diverse videos
downloaded from YouTube—spanning categories
such as cartoons, news, sports, advertisements, TV
programs, and home videos—with durations ranging
from 1 to 10 minutes (Gj et al, 2008).
3.2 Evaluation Metrics
Evaluation methods for video summarization are
generally divided into two categories: objective
evaluation and subjective evaluation. These methods
help measure the similarity between the generated
summary and the original video, as well as the quality
of the summary from the user’s perspective.
Objective Evaluation Methods: Objective
evaluation methods for video summarization aim to
assess the quality of generated summaries using
quantitative metrics and algorithms. These methods
rely on features of the video content, such as the
diversity of keyframes, information coverage,
temporal distribution, as well as factors related to the
summary itself, including length and coherence.
Through objective evaluation, researchers and
developers can rapidly assess the performance of their
summarization algorithms and conduct optimization
and comparative analysis. Below are three commonly
used objective evaluation metrics in the field of video
summarization:
Precision (P): Measures the proportion of truly
useful information within the algorithm-generated
summary, i.e., the ratio of correctly predicted
keyframes to all predicted segments.
Temporal Coverage (Recall, R): Measures the
extent to which the algorithm can retrieve all the
useful segments manually annotated, i.e., the
proportion of predicted keyframes that overlap with
the ground truth summary segments.
F-Score (F): A harmonic mean of precision and
recall, providing a more comprehensive evaluation of
the algorithm’s overall performance. The F-Score is
calculated as follows:
ଶோ
ାோ
(1)
Subjective evaluation involves human viewers or
experts who assess the quality of generated
summaries based on their personal perceptions and
judgments. Common approaches include user surveys,
user experience testing, and expert reviews. By
observing participants’ reactions, ratings, and
feedback, researchers can gain insights into the
perceived quality of summaries. This type of
evaluation provides intuitive and comprehensive
results, helping researchers understand user
preferences, likes, and satisfaction levels, thereby
guiding the improvement and optimization of
summarization algorithms.
User Surveys: Participants are presented with
generated video summaries and asked to provide
feedback and ratings to capture their subjective
impressions of summary quality.
User Viewing Behavior Analysis: Monitoring
user behaviors while watching video summaries —
such as viewing duration and click counts—serves to
Research on the Method of Video Abstraction
443
evaluate the attractiveness and effectiveness of the
summaries.
User Satisfaction Surveys: Collecting data on user
satisfaction regarding the generated summaries helps
determine whether the summaries meet user
expectations.
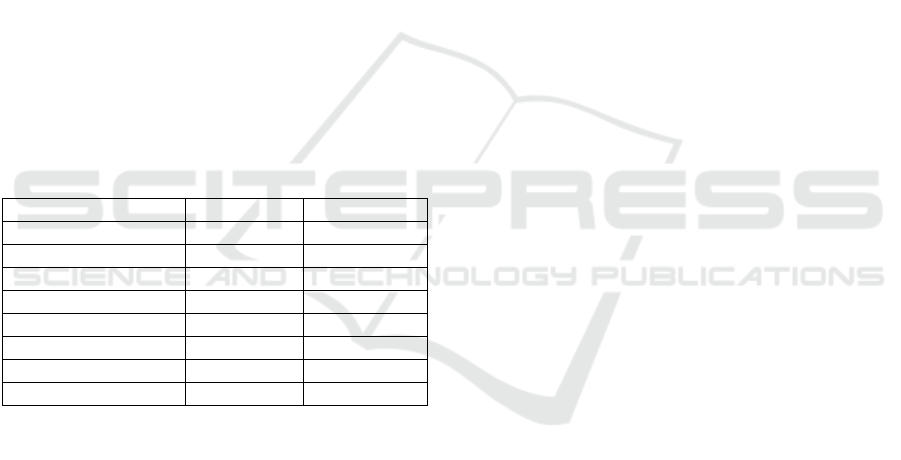
3.3 Comparison of Methods and Results
To evaluate the overall performance of various
unsupervised video summarization methods, we
report their F-score results on two widely used
benchmark datasets: SumMe and TVSum. The F-
score, as the harmonic mean of precision and recall,
provides a balanced measure of both accuracy and
coverage in identifying keyframes. The selected
methods cover a range of algorithmic strategies,
including clustering-based approaches, adversarial
learning frameworks, and reinforcement learning
techniques. By comparing their F-scores across
datasets, we can better understand each method's
generalization ability and effectiveness in diverse
video scenarios. The results are summarized in Table
1.
Table 1: Comparison of F-scores of Different Unsupervised
Algorithms on Two Datasets
Al
g
orith
m
SumMe TVSum
OnlineMotion-AE
37.7 51.5
SUM-FCN
41.5 52.7
PCDL
42.7 58.4
ACGAN
46.0 58.5
SUM-GAN-AAE
48.9 58.3
CRSUM
47.3 58.0
DR-DSN 41.4 57.6
EDVS 42.6 57.3
From the comparison in Table 1, it can be
observed that the best-performing methods on both
benchmark datasets are those based on Generative
Adversarial Networks (GANs).
4 CONCLUSIONS
Video summarization technology, as a crucial
approach to managing the explosive growth of video
data, has undergone a significant evolution from
traditional handcrafted visual feature-based methods
to automated intelligent techniques powered by deep
learning. This paper systematically reviews the
mainstream technologies in the field, including
supervised learning approaches based on LSTM and
Transformer models, unsupervised methods such as
clustering and generative adversarial networks, and
reinforcement learning frameworks, with a particular
emphasis on the role of multimodal fusion in
enhancing summary quality. Moreover, sports video
summarization, as a representative application
scenario, has driven advancements in action
recognition and event localization.
Despite considerable progress, several challenges
remain in video summarization. First, the high cost of
annotated data limits the general applicability of
supervised methods, making the design of efficient
weakly supervised or unsupervised learning
strategies a critical issue. Second, the temporal
continuity and semantic coherence of videos have yet
to be fully leveraged, leaving room for improving the
narrative and viewing experience of summaries.
While multimodal information fusion significantly
boosts model performance, effective collaboration
among different modalities and noise handling still
require breakthroughs. Finally, with the increasing
demand for real-time summarization, enhancing
computational efficiency and deployability without
compromising accuracy remains an important
direction.
Future research can be pursued in several
directions: (1) exploring transfer learning across
domains and tasks to alleviate dependence on large-
scale annotated datasets; (2) integrating cutting-edge
techniques such as graph neural networks and causal
reasoning to deepen the understanding of temporal
relationships and event causality; (3) advancing
multimodal fusion strategies by combining visual,
auditory, textual, and behavioral data to construct
semantically richer summary models; and (4)
promoting lightweight model design and hardware
acceleration to achieve real-time and scalable video
summarization.
In summary, as an interdisciplinary research
hotspot, video summarization is expected to benefit
from rapid developments in artificial intelligence,
finding widespread applications in entertainment,
surveillance, security, sports, and beyond, thereby
providing more efficient and intelligent video
information services to users.
REFERENCES
Apostolidis, E., Adamantidou, E., Metsai. A. I., et al.
(2020). Unsupervised video summarization via atte
ntion-driven adversarial learning," in International
Conference on Multimedia Modeling, pp. 492-504.
Avila, S. E. F., Lopes, A. P. B., Luz, A., et al. (201
1). VSUMM: A mechanism designed to produce s
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
444

tatic video summaries and a novel evaluation meth
od. Pattern Recognition Letters, 2011, 32(1): 56-6
8.
Barbieri, M., Agnihotri, L., Dimitrova, N. (2003). Vid
eo summarization: methods and landscape, in Inter
net Multimedia Management Systems IV, pp. 1-13.
Chen, L. C., Papandreou, G., Kokkinos, I., et al. (201
7). DeepLab: Semantic image segmentation with d
eep convolutional nets, atrous convolution, and ful
ly connected CRFs, IEEE Transactions on Pattern
Analysis and Machine Intelligence, 40(4): 834-848.
Chu, W., Song, Y., Jaimes, A. (2015). Video co-sum
marization: Video summarization by visual co-occu
rrence. in IEEE Conference on Computer Vision a
nd Pattern Recognition, pp. 3584-3592.
Doulamis, A. D., Doulamis, N. D., Kollias, S. D. (20
00). Fuzzy video content representation for video
summarization and content-based retrieval. Signal
Processing, 80(6): 1049-1067.
Fajtl, H., Sokeh, V., Argyriou, D., et al. (2019). Sum
marizing Videos with Attention. in Asian Conferen
ce on Computer Vision Workshops, pp. 39-54.
Gao, J., Yang, X., Zhang, Y., et al. (2021). Unsuperv
ised video summarization via relation-aware assign
ment learning. IEEE Transactions on Multimedia,
23: 3203-3214.
Gj, M., Loskovska, S., Dimitrovski, I., et al. (2008).
Comparison of Automatic Shot Boundary Detectio
n Algorithms Based On Color, Edges and Wavelet
s. in International Multiconference Information Soc
iety.
Gonuguntla, N., Mandal, B., Puhan, N., et al. (2019).
Enhanced Deep Video Summarization Network, in
British Machine Vision Conference.
Gygli, M., Grabner, H., Riemenschneider, H., et al. (2
014). Creating Summaries from User Videos, in E
CCV, pp. 505–520.
Hadi, Y., Essannouni, F., Thami, R. O. H. (2006). Vi
deo summarization by k-medoid clustering," in AC
M Symposium on Applied Computing, pp. 1400-1
401.
Hsu, T. C., Liao, Y. S., Huang, C. R. (2023). Video
Summarization With Spatiotemporal Vision Transfo
rmer. IEEE Transactions on Image Processing.
Ji, Z., et al. (2019). Video summarization with attenti
on-based encoder–decoder networks. IEEE Transact
ions on Circuits and Systems for Video Technolog
y, 30(6): 1709-1717.
Jung, Y., Cho, D., Kim, D., et al. (2019). Discriminat
ive feature learning for unsupervised video summa
rization. in AAAI Conference on Artificial Intellig
ence.
Khan, H., Hussain, T., Khan, S. U., et al. (2023). De
ep multi-scale pyramidal features network for supe
rvised video summarization," Expert Systems with
Applications, 221: 121288.
Lal, S., Duggal, S., Sreedevi, I. (2019). Online video
summarization: Predicting future to better summari
ze present. in IEEE Winter Conference on Applica
tions of Computer Vision, pp. 471-480.
Lebron, C. L., Koblents, E. (2019). Video summarizat
ion with LSTM and deep attention models. in Inte
rnational Conference on MultiMedia Modeling, pp.
175-187.
Long, J., Shelhamer, E., Darrell, T. (2015). Fully con
volutional networks for semantic segmentation. in
IEEE Conference on Computer Vision and Pattern
Recognition, pp. 3431-3440.
Mahasseni, B., Lam, M., Todorovic, S. (2017). Unsup
ervised Video Summarization with Adversarial LS
TM Networks. in IEEE Conference on Computer
Vision and Pattern Recognition, pp. 2982-2991.
Mundur, P., Rao, Y., Yesha, Y. (2006). Keyframe-bas
ed video summarization using Delaunay clustering.
International Journal on Digital Libraries, 6(2): 2
19-232.
Paul, M., Salehin, M. M. (2019). Spatial and motion
saliency prediction method using eye tracker data
for video summarization. IEEE Transactions on Ci
rcuits and Systems for Video Technology, 29(6):
1856-1867.
Puthige, I., Hussain, T., Gupta, S., et al. (2023). Atte
ntion Over Attention: An Enhanced Supervised Vi
deo Summarization Approach," Procedia Computer
Science, 218: 2359-2368.
Rochan, M., Ye, L., Wang, Y. (2018). Video summar
ization using fully convolutional sequence network
s. in ECCV, pp. 347-363.
Song, Y., Vallmitjana, J., Stent, A., et al. (2015). TV
Sum: Summarizing web videos using titles. in IEE
E Conference on Computer Vision and Pattern Re
cognition, pp. 5179–5187.
Wolf, W. H. (1996). Key frame selection by motion
analysis. in IEEE Computer Society, 1996, pp. 12
28–1231.
Yuan, Y., Zhang, J. (2023). Unsupervised Video Sum
marization via Deep Reinforcement Learning With
Shot-Level Semantics. IEEE Transactions on Circu
its and Systems for Video Technology, 33(1): 445
-456.
Yaliniz, G., Ikizler-Cinbis, N. (2021). Using independe
ntly recurrent networks for reinforcement learning
based unsupervised video summarization. Multimed
ia Tools and Applications, 80: 17827–17847.
Zang, S. S., Yu, H., Song, Y., et al. (2023). Unsuper
vised video summarization using deep Non-Local
video summarizationnetworks, Neurocomputing, 51
9: 26–35.
Zhang, K., Chao, W. L., Sha, F., et al. (2016). Video
summarization with long short-term memory, in
ECCV, pp. 766–782.
Zhang, Y., Liu, Y., Kang, W., et al. (2023). VSS-Net:
Visual Semantic Self-mining Network for Video
Summarization. IEEE Transactions on Circuits and
Systems for Video Technology.
Zhao, B., Gong, M., Li, X. (2021). Audiovisual video
summarization. IEEE Transactions on Neural Net
works and Learning Systems. 34(8): 5181-5188.
Research on the Method of Video Abstraction
445

Zhao, B., Li, X., Lu, X. (2017). Hierarchical recurren
t neural network for video summarization," in AC
M International Conference on Multimedia.
Zhao, B., Li, X., Lu, X. (2018). Hsa-rnn: Hierarchical
structure-adaptive rnn for video summarization. in
IEEE Conference on Computer Vision and Patter
n Recognition.
Zhou, K., Qiao, Y., Xiang, T. (2018). Deep reinforce
ment learning for unsupervised video summarizatio
n with diversity-representativeness reward. in AAA
I Conference on Artificial Intelligence, vol. 32.
Zhuang, Y., Rui, Y., Huang, T. S., et al. (1998). Ada
ptive keyframe extraction using unsupervised cluste
ring," in IEEE International Conference on Image
Processing, pp. 866-870.
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
446
