
A Comparative Analysis of Pedestrian Detection Performance for
YOLOv8 Models on the BDD100K Dataset
Yaxiaer Yashengjiang
a
School of Information Science and Engineering, East China University of Science and Technology, Shanghai, China
Keywords: YOLOv8, Object Detection, Autonomous Driving, Pedestrian Detection, BDD100K.
Abstract: Efficient and reliable pedestrian detection is paramount for autonomous driving safety. This paper presents a
systematic comparison of YOLOv8 models of varying scales (s, m, l) in complex driving scenarios, focusing
on performance trade-offs. The models were trained and evaluated on the "pedestrian" class of the BDD100K
dataset, covering core metrics like mean Average Precision (mAP), precision, recall, model parameters, and
inference speed. Results show a positive correlation between model scale and detection performance.
YOLOv8l achieved the highest accuracy (mAP50 of 0.683) and demonstrated superior robustness, especially
in challenging nighttime, rainy conditions, and for small object detection. However, this came at the cost of
the slowest inference speed. Conversely, YOLOv8s offered the fastest inference but compromised on
accuracy. This quantitative analysis reveals the inherent trade-offs between accuracy, efficiency, and
robustness among YOLOv8 models, providing empirical data to guide model selection for autonomous
systems based on specific hardware and performance needs.
1 INTRODUCTION
Autonomous vehicles are transitioning from concept
to industrialization, regarded as a key technology
poised to reshape future transportation paradigms
(Badue et al., 2021). The core capability of an
autonomous driving system lies in its precise
perception and understanding of complex, dynamic
driving environments (Yurtsever et al., 2020). Within
this context, object detection technology is tasked
with identifying critical elements on the road and has
been a focus of research for decades (Zou et al.,
2023). Therefore, high-performance and reliable
object detection serves as the cornerstone for the
proper functioning of subsequent decision-making
and planning modules, and indeed, for the safety of
the entire autonomous driving system. However, the
open and variable nature of real-world road scenes
poses significant challenges to detection algorithms.
Factors such as varying lighting conditions, adverse
weather, multi-scale targets, partial occlusions, and
the high demand for real-time processing place
stringent requirements on both the accuracy and
efficiency of detection algorithms.
a
https://orcid.org/0009-0007-8305-4117
In recent years, advancements in deep learning,
particularly in Convolutional Neural Networks
(CNNs) and Transformer architectures (Vaswani et
al., 2017), have propelled the development of object
detection technology. Researchers have made
substantial efforts to enhance model performance and
adapt them to specific application scenarios. For
instance, a study targeting Advanced Driver
Assistance Systems (ADAS) (Parekh, 2025)
evaluated the performance of the CNN-based
YOLOv8 model family against the Transformer-
based real-time detection model RT-DETR. The
findings indicated that while RT-DETR excelled on
the general-purpose COCO dataset, YOLOv8 series
models often achieved higher mAP and lower
inference latency in specific ADAS-related tasks.
Furthermore, another study (Mishra et al., 2024)
demonstrated the adaptability and optimization
potential of the YOLOv8 model in specific
challenging environments by integrating an image
enhancement algorithm to improve performance on
underwater imagery.
Existing research has validated the baseline
capabilities and application prospects of YOLOv8.
However, a systematic, detailed, and multi-
222
Yashengjiang, Y.
A Comparative Analysis of Pedestrian Detection Performance for YOLOv8 Models on the BDD100K Dataset.
DOI: 10.5220/0014325600004718
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 2nd International Conference on Engineering Management, Information Technology and Intelligence (EMITI 2025), pages 222-226
ISBN: 978-989-758-792-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

dimensional performance comparison and analysis of
the different-scale models within the YOLOv8 series
itself—specifically for detecting the critical
"pedestrian" target on a challenging, large-scale
public autonomous driving dataset—remains an area
worthy of investigation. Such an analysis is crucial
for understanding the specific trade-offs among
models of different scales in terms of accuracy, speed,
resource consumption, and sensitivity to complex
driving environment factors.
Therefore, the core work of this study is to select
three representative models from the YOLOv8
series—small, medium, and large—and conduct a
unified training, comprehensive evaluation, and in-
depth comparative study focused on the "pedestrian"
class within the BDD100K dataset. This research
aims to reveal the specific differences and inherent
trade-offs in accuracy, efficiency, robustness, and
resource consumption among these models, thereby
providing insights for future targeted optimizations.
2 DATASET AND METHODS
2.1 BDD100K Dataset and Processing
This study utilizes the large-scale driving scene object
detection dataset, Berkeley DeepDrive 100K
(BDD100K) (Yu et al., 2020). This dataset is
renowned for its vast data volume and high degree of
scene diversity, making it an ideal choice for
evaluating the comprehensive performance of
autonomous driving perception algorithms. The
annotation information in BDD100K includes 10
main categories of traffic participants, such as
"pedestrian" and "car".
The experiment strictly adheres to the official data
partitioning of BDD100K, using its training set of
approximately 70,000 images for model training and
its validation set of about 10,000 images for
performance evaluation. To align with the core
objective of this study—pedestrian detection—the
dataset was specifically processed. First, the original
annotations were converted to the YOLO standard
format. Second, all images containing the "person"
class and their corresponding pedestrian annotations
were filtered to construct a single-class data subset for
the pedestrian detection task.
2.2 The YOLOv8 Model Family
This study employs the YOLOv8 series of models as
the core research object (Jocher et al., 2023).
YOLOv8 inherits and evolves the single-stage, end-
to-end detection philosophy of the YOLO algorithm
family (Redmon et al., 2016), which fundamentally
changed real-time detection. The series has
continuously evolved with versions like YOLOv7
and YOLOv9 (Wang, Bochkovskiy, & Liao, 2023;
Wang, Yeh, & Liao, 2024). By introducing more
efficient structural components and adopting an
Anchor-Free detection head design, a trend also seen
in other modern detectors (Carion et al., 2020), it
achieves significant improvements. Its typical three-
part architecture—Backbone, Neck, and Head—
ensures powerful feature extraction, fusion, and
prediction capabilities, a common paradigm of
inefficient detectors (Tan, Pang, & Le, 2020).
To comprehensively assess the impact of model
scale on pedestrian detection performance, this study
selected three representative, pre-defined standard
models from the YOLOv8 series: YOLOv8s (small),
YOLOv8m (medium), and YOLOv8l (large). These
three models were sourced directly from the official
repository and utilized their corresponding pre-
trained weights from the COCO dataset for transfer
learning. No modifications were made to their
standard network architectures during the
experiment.
2.3 Experimental Setup
All model training and evaluation were conducted in
a unified experimental environment. The platform
was based on an Apple M3 Max processor with its
integrated GPU, accelerated using Metal
Performance Shaders (MPS), under the macOS
operating system. The key software environment
included Python 3.10, PyTorch 2.8.0.dev, and
Ultralytics YOLO 8.3.139.
During the training phase, all models were
initialized with COCO pre-trained weights and
trained for 10 epochs on the BDD100K pedestrian
subset. The optimizer used was SGD. The initial
learning rate and batch size were adapted for the
different model scales: YOLOv8s used an initial
learning rate of 0.001 and a batch size of 8; YOLOv8l
used an initial learning rate of 0.0005 and a batch size
of 4. The input image size for both training and
validation was uniformly set to 640x640 pixels. For
data augmentation, a series of methods provided by
the YOLOv8 framework were used, primarily
including Mosaic, random horizontal flip, random
scaling, random translation, and HSV color space
augmentation.
A Comparative Analysis of Pedestrian Detection Performance for YOLOv8 Models on the BDD100K Dataset
223
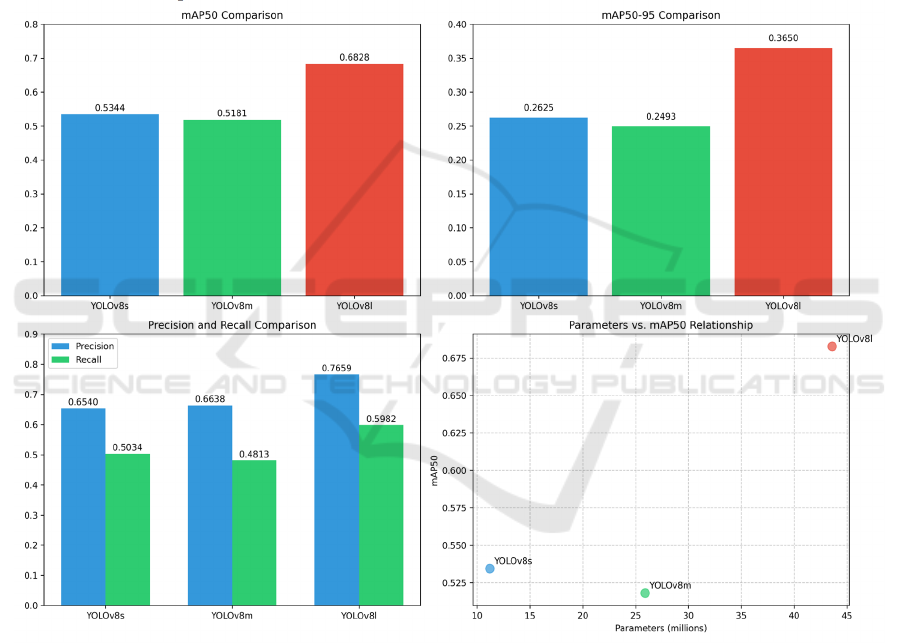
3 EXPERIMENTAL RESULTS
AND ANALYSIS
3.1 Overall Model Performance and
Efficiency Trade-Offs
The detection accuracy of a model under standard
metrics and its operational efficiency on a specific
hardware platform are critical determinants of its
practical value. The analysis revealed a clear trade-
off between model size, accuracy, and speed. As
illustrated in Figure 1, YOLOv8l, with its largest
model scale (43.7M parameters), demonstrated the
best performance, achieving a mAP50 of 0.6828 and
significantly outperforming the other models. This
indicates that for applications pursuing the highest
accuracy, YOLOv8l is the top choice. However, this
superior performance is accompanied by the slowest
inference speed at approximately 26 FPS. In contrast,
the lightweight, YOLOv8 (11.2M parameters)
showcased the best efficiency, achieving the highest
speed of about 66 FPS, though with a lower mAP50
of 0.5344. YOLOv8m offered a middle ground at
approximately 40 FPS. This clear trade-off
relationship is a core issue that system designers must
address during model selection.
Figure 1: Comparison of YOLO models on key performance metrics (Picture credit: Original).
3.2 Robustness Analysis in Different
Driving Scenarios
By comparing the mAP50 of each model in five
typical driving environments—daytime, nighttime,
crowded, foggy, and rainy—it was found that all
models achieved their respective peak performance in
the "daytime" scene. However, in challenging
scenarios, the performance of all models declined. In
this context, YOLOv8l once again demonstrated its
robustness, maintaining the highest mAP50 under all
tested conditions, with its performance advantage
being particularly pronounced in the "nighttime" and
"rainy" scenes. The absolute mAP50 values for
YOLOv8s and YOLOv8m under various challenging
conditions were generally lower, indicating a more
significant performance degradation in adverse
environments, a well-known challenge in the field
(Li, Chen, & I., 2022).
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
224
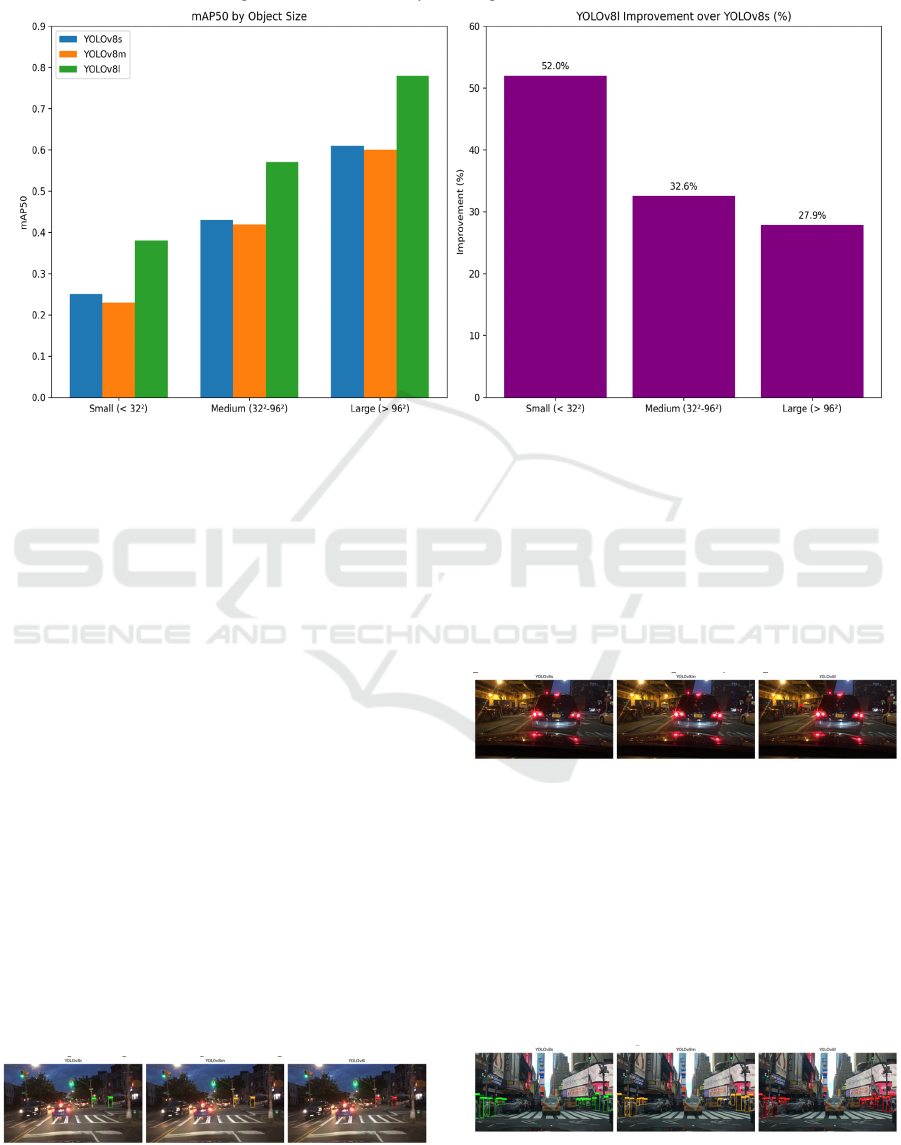
In autonomous driving scenarios, pedestrian
targets can exhibit drastic size variations. Accurate
detection of small, distant targets is crucial for early
warning and collision avoidance, and it represents a
major technical challenge for object detection
algorithms (Li et al., 2022).
Figure 2: Analysis of mAP50 by object size (Picture credit: Original).
Analysis reveals (Figure 2) that all models
perform better on large-sized targets than on medium
and small ones. However, the performance gap
between models is particularly prominent in the most
challenging task of small object detection: YOLOv8l
achieved a mAP50 of approximately 0.38. Compared
to YOLOv8s, YOLOv8l's mAP50 improvement in
small object detection was a staggering 52.0%. This
substantial improvement strongly proves that
YOLOv8l, with its deeper and wider network
structure, can learn more discriminative and subtle
features, thus exhibiting a decisive advantage in small
object detection.
4 QUALITATIVE
VISUALIZATION OF
DETECTION RESULTS
To more intuitively demonstrate the actual pedestrian
detection effects and to supplement the preceding
quantitative analysis, this section presents and
analyzes visualizations from several representative
test images (Figure 3, Figure 4, Figure 5).
Figure 3: Detection comparison in a typical nighttime urban
scene (Picture credit: Original).
In typical scenes with adequate lighting,
YOLOv8s (green boxes), YOLOv8m (orange boxes),
and YOLOv8l (red boxes) all consistently detected
the pedestrian targets, indicating that all three models
possess a fundamental capability for pedestrian recall.
Figure 4: Detection comparison in a challenging scene with
mixed lighting conditions (Picture credit: Original).
In a more challenging lighting scenario, both
YOLOv8s and YOLOv8m failed to detect a distant
pedestrian, resulting in a missed detection. However,
YOLOv8l, the largest and most complex model,
managed to identify this target. This comparison
significantly illustrates that increasing the scale and
depth of the model's network structure enhances its
ability to capture and recognize weak feature signals
and low-contrast targets.
Figure 5: Performance difference in a high-density
pedestrian crossing scene (Picture credit: Original).
A Comparative Analysis of Pedestrian Detection Performance for YOLOv8 Models on the BDD100K Dataset
225

In a high-density pedestrian scene, the models
showed clear differences. YOLOv8s detected the
highest number of pedestrians with high confidence.
YOLOv8m detected a moderate number with slightly
lower confidence. YOLOv8l, while detecting many
targets, produced some low-confidence boxes, which
highlights the importance of post-processing
parameter tuning in practical applications.
5 CONCLUSIONS
This study conducted a systematic performance
evaluation and comparative analysis of three
different-scale models from the YOLOv8 series on
the critical task of pedestrian detection using the
BDD100K dataset. The core objective was to reveal
the inherent trade-offs between detection accuracy,
operational efficiency, and adaptability to complex
environments.
The experimental results clearly indicate a
positive correlation between model scale and
detection performance. YOLOv8l, with its complex
network architecture, significantly outperformed the
other models across all core accuracy metrics
(achieving a mAP50 of 0.683) and demonstrated
superior robustness. However, this performance
enhancement comes at the cost of higher
computational resource consumption and slower
inference speed. YOLOv8s excelled in inference
efficiency but showed deficiencies in accuracy.
YOLOv8m offered an intermediate option.
The limitations of this study include that all
models were trained for only 10 epochs. Future
research could explore longer training periods,
hyperparameter tuning, and model optimization
techniques like quantization and pruning.
In conclusion, this study provides a quantitative
basis and practical reference for the autonomous
driving field to rationally select and deploy object
detection models according to specific hardware
platforms, real-time requirements, and reliability
needs.
REFERENCES
Badue, C., et al. (2021). Self-driving cars: A survey. Expert
Systems with Applications, 165, 113816.
Carion, N., et al. (2020). End-to-end object detection with
transformers. In European Conference on Computer
Vision.
Jocher, G., et al. (2023). YOLO by Ultralytics. GitHub
repository. https://github.com/ultralytics/yolov5
Li, J., et al. (2022). A survey of deep learning for small
object detection. Foundations and Trends® in
Computer Graphics and Vision, 13(3), 189–311.
Li, Y., Chen, I-K., & I. (2022). A review on deep learning-
based object detection and tracking in adverse weather.
IEEE Transactions on Intelligent Transportation
Systems, 23(7), 6046–6065.
Mishra, S., et al. (2024). Fine-tuning YOLOv8 for
enhanced accuracy in marine environments. In
TENCON 2024 – 2024 IEEE Region 10 Conference
(TENCON).
Parekh, A. (2025). Comparative analysis of YOLOv8 and
RT-DETR for real-time object detection in advanced
driver assistance systems.
Redmon, J., et al. (2016). You only look once: Unified, real-
time object detection. In Proceedings of the IEEE
Conference on Computer Vision and Pattern
Recognition.
Tan, M., Pang, R., & Le, Q. V. (2020). EfficientDet:
Scalable and efficient object detection. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition.
Vaswani, A., et al. (2017). Attention is all you need. In
Advances in Neural Information Processing Systems.
Wang, C. Y., Bochkovskiy, A., & Liao, H. Y. M. (2023).
YOLOv7: Trainable bag-of-freebies sets new state-of-
the-art for real-time object detectors. In Proceedings of
the IEEE/CVF Conference on Computer Vision and
Pattern Recognition.
Wang, C. Y., Yeh, I. H., & Liao, H. Y. M. (2024). YOLOv9:
Learning what you want to learn using programmable
gradient information. arXiv preprint arXiv:2402.13616.
Yu, F., et al. (2020). BDD100K: A diverse driving dataset
for heterogeneous multitask learning. In Proceedings of
the IEEE/CVF Conference on Computer Vision and
Pattern Recognition.
Yurtsever, E., et al. (2020). A survey of deep learning for
autonomous vehicle perception. IEEE Transactions on
Intelligent Transportation Systems, 22(1), 3–32.
Zou, Z., et al. (2023). Object detection in 20 years: A survey.
arXiv preprint arXiv:1905.05055v2.
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
226
