
The Prophet Predicting Ischaemic Stroke: Transformer-Based
Multimodal Classification
Yuhang Dong
a
Data Science, Nanjing University of Information Science and Technology, Nanjing, China
Keywords: Transformer, Multimodal, Ischaemic Stroke, Morbid Prediction.
Abstract: Ischemic stroke is a common and extremely harmful cerebrovascular disease. It develops suddenly, has a high
mortality rate and high disability rate, and seriously threatens the life and health of patients. Early and accurate
prediction of stroke is of great significance for timely intervention and improving the success rate of treatment.
With the continuous accumulation of medical data and the rapid development of artificial intelligence
technology, stroke prediction models based on machine learning and deep learning have gradually become a
research hotspot. Based on the MR CLEAN clinical trial dataset, this study constructed and trained three
models with significant structural differences: a combination model of XGBoost and xDeepFM, a SSMMSRP
model, and a TranSOP model, aiming to explore the performance differences of different modeling methods
in stroke prediction tasks. Preliminary comparative experimental results show that the TranSOP model shows
the best cost-effectiveness in various performance indicators and has good promotion potential and
application prospects. This study provides multiple feasible paths for the construction of stroke prediction
models, verifies the advantages of multimodal fusion models in this task, and lays the foundation for further
optimization of clinical decision support systems.
1 INTRODUCTION
Ischaemic stroke refers to cerebral infarction or
cerebral artery blockage caused by the formation of
cerebral thrombosis, incurring hemiplegia and
consciousness disorders. However, ischaemic stroke
can be diagnosed by virtue of its prodromal
symptoms, such as dizziness, numbness, or weakness
in one side of the body, which are more likely to
emerge with low blood pressure.
Machine learning has mostly domineered over
much morbid prediction, thus there existed varieties
of machine learning algorithms that had all focused
on certain particular strokes. No matter what kind of
stroke they are directed against, this cornucopia of
methods has enlightened many state-of-the-art and
novel theses to take a further step to prefigure the
probability of stroke. In spite of some basic and
simple approaches such as Random Forest(RF),
Logistic Regression(LR), Support Vector Machines
(SVM), and Decision Tree (DT) etc, they have been
introduced in stroke forecast as Zhiwan Y. et al.
discussed above-mentioned seven methods through
a
https://orcid.org/0009-0008-1061-8310
classifiers, Random Forest, eXtreme Gradient
Boosting and Histogram-Based Gradient Boosting
(Zhiwan et al., 2025). Chadha A. et al. compared
CNN and logistic regression and Pan H. et al.
Assessed nuanced performance between XGBoost,
CatBoost, SVM and logistic regression (Chadha,
2025; Pan et al., 2025). Fernandez-Lozano C. et al.
adopted the primitive version of RF to implement
stroke prediction (Fernandez Lozano et al., 2021).
Furthermore, XGBoost is an updated algorithm
derived from RF. Khosla, A. et al. deployed XGBoost
and Dai W. et al. employed a fusion with XGBoost
and xDeepFM to do so (Khosla et al., 2010; Dai et al.,
2023). Subsequently, CNN and LSTM were also
playing an important part in stroke prediction. Based
on the two mindsets, incorporated CNN and LSTM to
bolster up model’s performance and precision.
Around 2020, Large Language Models(LLM) were
sprung up and abundant archetypal and hackneyed
Transformers laid the foundation for LLMs as a
profound trove. Jia Q.et al. devised a combination of
CNN and Transformer to confront challenges from
stroke prediction and ameliorated Vision
116
Dong, Y.
The Prophet Predicting Ischaemic Stroke: Transformer-Based Multimodal Classification.
DOI: 10.5220/0014322100004718
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 2nd International Conference on Engineering Management, Information Technology and Intelligence (EMITI 2025), pages 116-122
ISBN: 978-989-758-792-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

Transformer(ViT) to refine clinical imaging records
(Jia & Shu, 2021; Chen et al., 2021). And
surprisingly, Samak and his team have been
unfailingly researching and continually optimizing
cutting-edge LLM to better monitor and foreshadow
ischaemic stroke since 2020 (Samak et al., 2020;
Samak et al., 2022; Samak, Clatworthy, & Mirmehdi,
2023). In 2023, their achievements reached a peak
and they integrated information from an MR CLEAN
Trial dataset into TranSOP, a brand new LLM
invented by Samak ’ s research team (Samak,
Clatworthy, & Mirmehdi, 2023).
The paper introduces three models, which are
XGBoost&xDeepFM, SSMMSRP, TranSOP, and
information about ischaemic stroke in the MR
CLEAN Trial dataset, where the three models were
tested to performance and accuracy. SSMMSRP
employs a self-supervised learning approach.
TRANSOP is a Large Language model based on a
specific Transformer architecture.
XGBoost&xDeepFM is a fusion module, where
XGBoost is a gradient-boosting-based ensemble
learning algorithm and xDeepFM is a deep learning
model for recommendation systems mixed with the
advantages of factorization machines and deep neural
networks. This paper concludes that Large Language
models achieve higher accuracy compared to the
other two types of models and the precision of
TRANSOP under the condition of single-modality
(image and tabular input) and multi-modality inputs
was in a radical departure from each other. Multi-
modal Large Language models have still set the trend
in precisely heralding ischemic stroke.
2 DATASET AND
METHODOLOGY
2.1 Dataset Source and Trait
The dataset chosen derives from the MR CLEAN
Trial Dataset, whose samples are gleaned from an
elaborate clinical and imaging investigation on
subjects suffering from an ischaemic stroke in 16
medical centers in the Netherlands. It catalogues 500
patients’ copious physiological indices with 233
people receiving mechanical thrombectomy and 267
counterparts treated with usual care. MR CLEAN
Trial Dataset proffers a comprehensive and
professional insight into the correlation between the
probability of ischaemic stroke and numerous health
indices.
2.2 Data Preprocessing
In the process of data processing, there have been six
approaches to be adopted to refine and incorporate
previous datasets to break through limitations and to
train a more robust and accurate ischaemic stroke
prediction model.
First is Resampling. The dataset connotates such
discordant imaging information as image quality,
resolution, and intensity values. The sort of
discrepancy is likely to impinge on the model's
capacity to learn consistent features. Furthermore,
voxel size can be a crux in medical imaging and
various scanning equipment, such as CT, has
universally different measurement and magnitude.
Hence, the original dataset possesses inconsistent
voxel sizes. Rather difficult is the untamed dataset for
the model to process the data uniformly due to
numerous results in calculating volume data and
imposing three-dimensional construction. To prevent
these two problems, the entire dataset is resampled to
the same voxel size of 3x1x1mm³ to standardize the
input data across different acquisition protocols.
Second is Intensity Clipping. The initial dataset
including CT scans has a wide range of intensity
values, which emanates many outliers and much
noise. As for models selected to predict ischaemic
stroke, it can be exceedingly laborious to distinguish
between relevant and irrelevant information. Similar
to the patterns of imaging magnitude and veracity of
medical apparatuses, types of scanners and protocols
generate images with unequal intensity scales,
degrading models ’ performances. Therefore,
standardization serves as a salvage of reduced model
performances. This standardization approach makes
the intensity range clipped to 0-80 Hounsfield Units
to subside the impact of outliers and normalize the
intensity values.
Third is Skull Removal. Those data that have an
incomparably low degree of correlation should be
weeded out. Since NCCT scans stored in the previous
version of the dataset entail skull data, which tends to
be irrelevant for analyzing cranial tissue. If the data
about the skull were preserved, there would have been
exceptional noise and features perplexing models.
Additionally, non-brain tissue makes a scarce
contribution to the analysis of ischaemic stroke-
related characteristics. For example, apparently, air
teeming in the brain matters a whit. The results
related to skull structure have been removed from
NCCT scans to lay stress on ischaemic stroke.
Forth is Cropping. Its size of 500 patients may be
paltry for deep learning models and can not meet the
demands of deep learning. After all, deep learning
The Prophet Predicting Ischaemic Stroke: Transformer-Based Multimodal Classification
117
algorithms nearly always benefit from larger and
larger datasets. By contrast, overfitting and low-
quality generalizability problems will make an
appearance. As a matter of fact, the volumes were
cropped to 32 × 192 × 128 from the center to
concentrate on regions of interest and whittle the
computational load down.
Fifth is Data Augmentation. As Samak et al. had
applied to the dataset in their discourse, horizontal
and vertical flips and Gaussian noise are exerted on
the data to increase variation and amount of input
samples, thereby reinforcing the robustness of models
(Samak, Clatworthy, & Mirmehdi, 2023).
The Sixth is Normalization. Normalization
effectuates abating noise caused by these irrelevant
regions. The voxels of the NCCT scans are
normalized to X~N(1,1), vouchsafing that the input
data has a consistent scale, which is more
instrumental for training deep learning models.
Consequently, the initial NCCT image and
preprocessed imaging result are presented as Figure 1
and Figure 2, and then a reconstructive 3D image has
already been created to show all global physical
features in Figure 3.
Figure 1: Original image of NCCT (Picture credit:
Original).
Figure 2: Preprocessed image of NCCT (Picture credit:
Original).
Figure 3: 3D reconstructive cephalic imaging (Picture
credit: Original).
2.3 Models
2.3.1 XGBoost & xDeepFM
XGBoost incorporates such weak prediction models
as decision trees to construct a strong predictive
model. And LASSO regularization(L1) and Ridge
regularization(L2) are deployed to constrain the model
’ s complexity and prevent the model from
overfitting problems. Another key structure,
xDeepFM reconciles factorization machines with
deep neural networks to capture high-dimensional
feature interactions. At a level of hierarchical
structure, it consists of three principal layers,
embedding layer, Cross-Network layer, and deep
network layer. Embedding layer functions on mapping
categories of features into low-dimensional dense
vectors. The cross-section layer arrests interlocking
features through the cross-product operation method.
Deep network layer draws support from these fully-
connected layers to learn complex feature
representations. During the training process, XGBoost
and xDeepFM will be separately on the same given
dataset and they are about to be fused at the stage
where they will have drawn a predicted conclusion.
Ensemble coefficients, which are identified to two
dependent models when fusion, are determined by
Grid Search, as Grid Search can systematically seek
optimal coefficients to maximize overall performance.
Figure 4 shows the structure of xDeepFM.
Figure 4: The structure of xDeepFM (Dai et al., 2023).
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
118
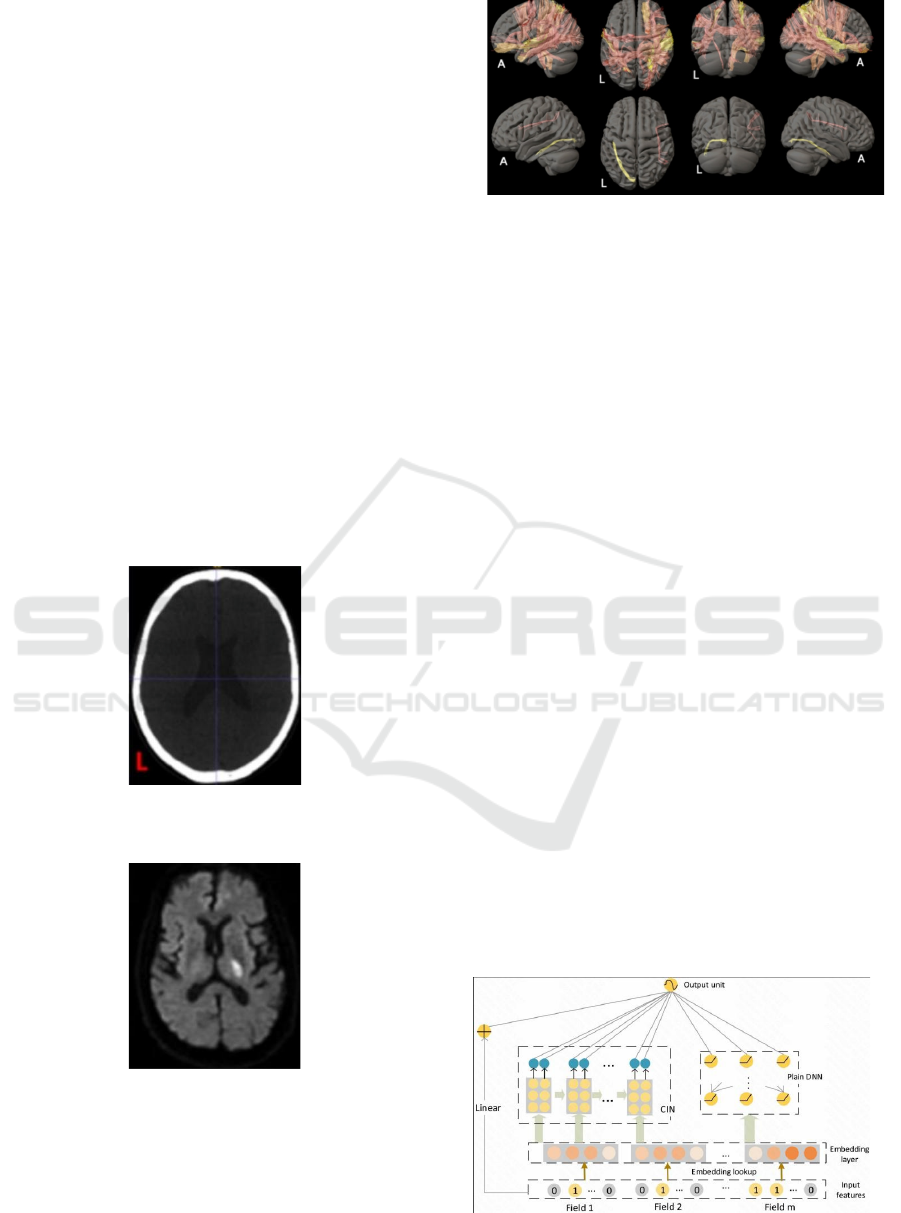
2.3.2 SSMMSRP
SSMMSRP is a self-supervised model for multi-
modal prediction, which upholds multi-modal data as
its input for it has an integrated system combining 3D
imaging, clinical data and image-derived features
altogether. The most significant mechanism of its
self-supervised learning framework is the Contrastive
Learning Framework, stemming from contrastive
learning. It makes full use of contrastive language-
image pretraining (CLIP) and image-tabular
matching (ITM) to align input data representations
within a shared latent space. During the pre-training
stage, image and tabular Encoders encode for image
and tabular data respectively and a myriad of data
augmentation finesses, including random cropping,
affine transforms for images, and random feature
corruption for tabular data, are employed
simultaneously. Apart from the pre-training part,
downstream task fine-tuning must be of equal
preponderant at the end of the scheme, where the
Multimodal Interaction Module applies cross-
attention so as to sanction tabular embeddings for
exhuming relevant image embeddings and the
classifier aggregates information by adopting a token,
marked as “ CLS” for downstream classification
tasks. Figure 5 shows the structure of SSMMSRP.
Figure 5: The structure of SSMMSRP (Ma et al., 2024).
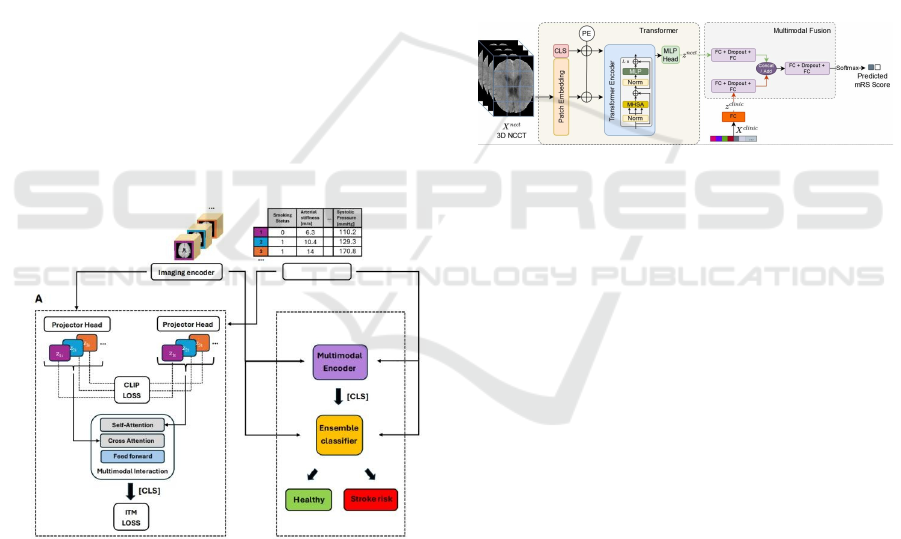
2.3.3 TranSOP
Transformer-Based Network (TranSOP) is an
archetypal multi-modal Large Language model,
indicating that it can amalgamate 3D non-contrast
computed tomography (NCCT) images and clinical
metadata such as gender, age, hypertension and
glucose level. TranSOP is constituted by a
Transformer Encoder and Multimodal Fusion
Module.
The Transformer Encoder encompassed three
following layers. Patch Embedding splits 3D NCCT
volumes into 1D vectors and projects them to an
embedding space passing through a convolutional
layer. Positional Encoding adds learnable positional
encodings to maintain spatial information. The last
layer, Transformer Blocks adopts normalization,
multi-head self-attention (MHSA), and multi-layer
perceptron (MLP) layers.
The Multimodal Fusion Module is sustained by
two sections, feature extraction and fusion strategies.
Feature extraction spontaneously extracts features
from NCCT and clinical metadata and fusion
strategies concatenate and add outputs from
preceding blocks to merge image and clinical
features. Eventually, the final prediction stage is a
good hunting ground for a classifier utilizing fully-
connected layers and a Softmax layer. Figure 6 shows
the structure of TranSOP.
Figure 6: The structure of TranSOP (Samak, Clatworthy, &
Mirmehdi, 2023).
3 EXPERIMENT
3.1 Condition
In the experiment, three models are detached from
their respective situation, which contains four
essential conditions, Epoch, Learning Rate(LR), Loss
Function(LF) and Optimizer. Via configuration(as is
shown in Table 1) of three dissimilar kinds of models,
these models can be adjusted to their best
performance, respectively as soon as
possible.XGBoost&xDeepFM model combines two
genres of algorithms and is predisposed to implement
its execution rapidly so that by and large, it only needs
100 epochs to prompt results to reach convergence.
And SSMMSRP model converges at around 280
epochs of multiple pre-experiments, consequently,
the Epoch is set to 300, ensuring guaranteed
convergence. Nevertheless, for TranSOP, the Large
Language Model, the lack of epochs touches off
oscillation of result or divergence readily. The pre-
training process for TranSOP has proclaimed that 500
epochs suffice to shore up its convergence. Learning
rate could be another vital parameter for experiments,
and the Cosine Annealing algorithm is devoted to
The Prophet Predicting Ischaemic Stroke: Transformer-Based Multimodal Classification
119

assisting us in finding an appropriate Learning
Rate(LR), with 0.01 for XGBoost&xDeepFM and
0.0003 for TranSOP. Apropos the SSMMSRP model,
LR is defined as 0.01 manually by repeated attempts.
To streamline models, Loss Function(LF) poses as a
beacon to represent the accuracy of models ’
prediction conclusion. The smaller the value of LF,
the more precisely the model forecasts. In
XGBoost&xDeepFM, cross-modal interactions are
going to be measured via the average of CLIP loss
(Ma et al., 2024) and image-tabular matching (ITM)
loss (Radford et al., 2021; Du et al., 2024). CLIP and
ITM are calculated to be its LF. CLIP Loss Function
maximizes similarity between augmented views of a
certain set of samples and minimizes similarity with
other samples. ITM Loss Function presages whether
image-tabular pairs are matched to enhance cross-
modal interactions. Correspondingly, Binary Cross
Entropy(BCE) will be LF for SSMMSRP, with
meanwhile Cross Entropy(CE) for TranSOP. Finally,
Adam optimizer has been deployed into three models.
Table 1: Configuration.
Model Epoch Learning Rate Loss Function Optimize
r
XGBoost&
xDeepFM
100 0.01(based on Cosine Annealing) Binary Cross Entropy(BCE) XDeepFM: Adam
XGBoost: None
SSMMSRP 300 0.01 The average of CLIP and ITM Adam
TRANSOP 500 0.0003(based on Cosine Annealing) Cross Entropy(CE) Adam
3.2 Evaluation
Peculiarly imperative are evaluation indicators which
need to be potent and comprehensible to discern
which model has the best performance and precision,
after setting the experimental circumstances. On
account of this primary principle, three indicators, F1-
score, AUC, and Accuracy are selected and will
become arbitrators to adjudicate which one runs most
effectively and predicts concisely in the follow-up
sections.
F1-score is the harmonic mean of precision and
recall, calculated as
F1 = 2 ×
Precision × Recall
Precision
+
Recall
(1
)
which takes both Precision and Recall into
consideration. Especially in medical diagnosis, it has
already been crucial to ensure most cases are
definitely diagnosed, and to minimize the number of
misdiagnosed cases through a high Precision and
Recall. In summary, the F1-score provides a balanced
measure of these two aspects. When a dataset slants
on positive or negative samples, accuracy must be
malleable. F1-score is extraordinarily sensitive to the
distribution of positive and negative samples, which
endues it with better reflection on models'
performance on the minority class.
AUC represents the area encircled by coordinates
and the ROC curve (Receiver Operating
Characteristic curve). The ROC curve plots the true
positive rate (TPR) against the false positive rate
(FPR). A model obtaining a higher AUC value
elucidates that it owns more eminent talent to rank
positive samples higher than negative ones. AUC
encompasses all plausible classification threshold
settings. Even if a classification threshold was
changed, the AUC value could have remained stable
and still betokened the model's performance.
Undoubtedly a useful metric AUC can be while
comparing different models, particularly when the
optimal classification threshold is unknown.
Accuracy is the proportion of correctly predicted
samples out of the total samples, calculated as
Accurac
y
=
TP + TN
TP
+
TN
+
FP
+
FN
(2
)
where TP, TN, FP and FN denote the number of
true positives, true negatives, false positives and false
negatives, respectively. ACC directly reflects the
overall correctness of models’ prediction results, as
a good initial metric for model performance
assessment.
3.3 Result
Through executing codes of three models, the
difference among the three disparate models has been
showcased(Table 2). TranSOP remarkably outwits
the other two models on AUC and ACC, with 88.41
and 80.02, respectively. Albeit its prominent forecast
accuracy, TranSOP performs incomparably worst
among the models, with merely 59.72 of the F1-score
and whereas the scope of the F1-score of
XGBoost&xDeepFM and SSMMSRP both lies from
65 to 70. Owing to the fact that the F1-score is
comprised of Recall and Precision and Recall and
Precision are equally bestowed on the same weight
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
120

0.5, the F1-score can not fully reference the priorities
of Recall or Precision in a certain realistic application.
Notably in an ischaemic stroke forecast, Recall is far
more important to declare the model’s performance
than Precision. TranSOP just right gains a relatively
high score in Recall yet a rather low value of
Precision. Hence, the F1-score can not play a
dominant part in indicators to conjecture which model
performs best. From a comprehensive perspective,
TranSOP indisputably becomes the most appropriate
model to predict ischaemic stroke.
Table 2: Comparison between three models.
Model F1-score AUC ACC
XGBoost&xDeepFM 68.69 71.37 73.91
SSMMSRP 65.96 85.65 75.73
TRANSOP 59.72 88.41 80.02
The next experiment is devised to discriminate
whether unimodal or multimodal input can train
TranSOP to forecast a more fastidious upshot. In the
pre-training process, two forms of unimodal, image
and text solely, were pitched on to input TranSOP.
Based on a primitive version of TRANSOP, image or
textual modal has been previously processed into ViT
(Chen et al., 2021), DeiT (Li et al., 2021), SwinT
(Touvron et al., 2022) or BERT, ALBERT (Liu et al.,
2021), and RoBERTa (Liu et al., 2019). Finally, as is
exposed (Table 3), almost all multimodal inputs
outmaneuver unimodal inputs, which suggests that
multimodal data are dedicated to better performance
for TranSOP and to spur TranSOP to be increasingly
precise.
Table 3: Comparison between unimodal and
multimodal.
Model Image
modal
Text
modal
F1-
score
AUC ACC
Unimodal None BERT 0.87 0.74 0.82
Unimodal None RoBERTa 0.85 0.72 0.82
Unimodal None ALBERT 0.87 0.76 0.87
Unimodal ViT None 0.56 0.36 0.65
Unimodal DeiT None 0.55 0.40 0.65
Unimodal SwinT None 0.55 0.39 0.60
Multimodal DeiT BERT 0.89 0.75 0.84
Multimodal SwinT BERT 0.89 0.75 0.84
Multimodal SwinT RoBERTa 0.89 0.78 0.84
In the meantime, the discourse (Lan et al., 2019)
also suggested that SSMMSRP outperforms single-
modality methods by 2.6% for both image and tabular
input in ROC-AUC, ameliorating by 3.3%, 5.6% for
image and tabular single-modality respectively in
balanced accuracy terms. Meanwhile, the
experimental outcome is nearly similar to (Delgrange
et al., 2024), which vindicates the legitimacy of this
experiment.
4 CONCLUSIONS
In this paper, three disparate models
XGBoost&xDeepFM, SSMMSRP and TranSOP are
selected to participate in the ischaemic stroke
prediction performance test and detect diverse
Transformer architecture-based Large Language
models, based on MR CLEAN dataset gleaned and
collated by an professional American disease
institution center. The upshot has disclosed that
TranSOP possessed the best comprehensive
performance in portending ischaemic stroke among
all the modules selected, and combined multimodality
data came to more remarkable fruition than any single
modality. Despite rigmarole in processing billions of
parameters, high complexity in the hierarchical
structure and deficiency in distinguishing exclusive
textual single-modality, a Transformer structure-
based Large Language model still takes on a role as
an augur for predicting ischaemic stroke. In future
work, such Transformer-based Multimodal Large
Language models like TranSOP are hopeful to be
prophets for a wide range of cardiovascular and
cranial diseases.
REFERENCES
Chadha A. Stroke Prediction using Clinical and Social
Features in Machine Learning. arXiv. 2025.
Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., ... &
Zhou, Y. TransUNet: Transformers make strong
encoders for medical image segmentation. arXiv
preprint arXiv:2102.04306. 2021.
Dai W., Jiang Y., Mou C., Zhang C. An Integrative
Paradigm for Enhanced Stroke Prediction: Synergizing
XGBoost and xDeepFM Algorithms. ICBDT 2023.
2023.
Delgrange C., Demler O., Mora S., Menze B., de la Rosa
E., Davoudi N. A Self-Supervised Model for Multi-
modal Stroke Risk Prediction. arXiv. 2024.
Du S., Zheng S., Wang Y., Bai W., O’Regan D. P., Qin C.
TIP: Tabular-Image Pre-training for Multimodal
Classification with Incomplete Data. arXiv. July 2024.
Fernandez Lozano C., Hervella P., Mato Abad V., et al.
Random forest based prediction of stroke outcome.
Scientific Reports, 11:10071. doi:10.1038/s41598-021-
89434-7. 2021.
hosla A., Cao Y., Lin C. C. Y., Chiu H. K., Hu J., & Lee H.
An integrated machine learning approach to stroke
prediction. Proceedings of the 16th ACM SIGKDD
The Prophet Predicting Ischaemic Stroke: Transformer-Based Multimodal Classification
121

International Conference on Knowledge Discovery and
Data Mining, pp. 183–192. 2010.
Jia Q., Shu H. BiTr-Unet: a CNN-Transformer Combined
Network for MRI Brain Tumor Segmentation. arXiv
preprint arXiv:2109.12271. 2021 Dec 30.
Lan Z., Chen M., Goodman S., Gimpel K., Sharma P., &
Soricut R. ALBERT: A lite BERT for self-supervised
learning of language representations. arXiv preprint
arXiv:1909.11942. 2019.
Li J., Selvaraju R. R., Gotmare A. D., Joty S., Xiong C., Hoi
S. C. Align before Fuse: Vision and Language
Representation Learning with Momentum Distillation.
Advances in Neural Information Processing Systems,
12:9694–9705. ISBN 9781713845393. 2021.
Liu Y., Ott M., Goyal N., Du J., Joshi M., Chen D., ... &
Stoyanov V. RoBERTa: A robustly optimized BERT
pretraining approach. arXiv preprint arXiv:1907.11692.
2019.
Liu Z., Lin Y., Cao Y., Hu H., Wei Y., Zhang Z., ... & Guo
B. Swin Transformer: Hierarchical vision transformer
using shifted windows. Proceedings of the IEEE/CVF
International Conference on Computer Vision, pp.
10012–10022. 2021.
Ma D., Wang M., Xiang A., Qi Z., Yang Q. Transformer-
Based Classification Outcome Prediction for
Multimodal Stroke Treatment. arXiv. 2024.
Pan H., Chen S., Pishgar E., Alaei K., Placencia G., Pishgar
M. Machine Learning-Based Model for Postoperative
Stroke Prediction in Coronary Artery Disease. arXiv.
2025.
Radford A., Kim J. W., Hallacy C., et al. Learning
Transferable Visual Models from Natural Language
Supervision. Proceedings of Machine Learning
Research, 139:8748–8763. ISBN 9781713845065.
2021.
Samak Z. A., Clatworthy P., & Mirmehdi M. TransOp:
Transformer-Based Multimodal Classification for
Stroke Treatment Outcome Prediction. 2023 IEEE 20th
International Symposium on Biomedical Imaging
(ISBI), pp. 1–5. IEEE. April 2023.
Samak Z. A., et al. FeMA: Feature Matching Auto Encoder
for Predicting Ischaemic Stroke Evolution and
Treatment Outcome. Computerized Medical Imaging
and Graphics, 99:102089. 2022.
Samak Z. A., et al. Prediction of thrombectomy functional
outcomes using multimodal data. In MIUA, Cham, pp.
267–279. 2020.
Touvron H., Cord M., & Jégou H. Deit III: Revenge of the
ViT. European Conference on Computer Vision, pp.
516–533. Cham: Springer Nature Switzerland. October
2022.
Y., Zhiwan, Zarrab R., Dubois J. Enhancing Stroke
Diagnosis in the Brain Using a Weighted Deep
Learning Approach. arXiv. 2025.
Zeynel A. Samak, et al. Prediction of thrombectomy
functional outcomes using multimodal data. In MIUA,
Cham, pp. 267–279. 2020.
EMITI 2025 - International Conference on Engineering Management, Information Technology and Intelligence
122
