
Optimizing DeBERTa V3 for Accurate Automated Essay Evaluation
in the Indonesian Educational Context
Muhammad Rahmat
a
, Muhammad Niswar
b
and Ady Wahyudi Paundu
c
Department of Informatics,Hasanuddin University, Makassar, Indonesia
Keywords: Automatic Essay Scoring, DeBERTa-v3, Bahasa Indonesia, Quadratic Weighted Kappa, Natural Language
Processing.
Abstract: Automated Essay Scoring (AES) has emerged as a practical solution to address the limitations of manual
essay evaluation, particularly in educational contexts where scalability, consistency, and efficiency are critical.
This study investigates the effectiveness of the DeBERTa v3 model for automatically scoring Indonesian-
language essays. We fine-tuned the model using a dataset of student essays that were manually rated by human
evaluators and optimized it with the Quadratic Weighted Kappa (QWK) metric to better align with ordinal
scoring systems. Through 5-fold cross-validation, the model achieved an average QWK of 0.558, MAE of
0.748, and RMSE of 0.894. These results demonstrate that the model can generate consistent and reliable
scores that closely approximate human judgment. The findings suggest that DeBERTa v3 holds significant
potential for supporting automated assessment systems in Indonesian education and advancing natural
language processing applications in low-resource languages.
1 INTRODUCTION
Automatic Essay Scoring (AES) systems are
increasingly gaining traction in educational settings,
especially for large-scale assessments and in
providing personalized feedback to learners (Imawan,
2024). Traditional essay scoring is often inefficient,
time-consuming, and inconsistent—particularly in
classrooms with high student-to-teacher ratios
(Ramesh, 2021). In response to these challenges,
Automated Writing Evaluation (AWE) systems offer
fast and consistent feedback (Dronen, 2015).
The subjectivity of manual grading often leads
to inconsistent scores, underscoring the need for
reliable and objective automated systems (Borade,
2021). The core challenge of building effective AEE
systems lies in the ability to evaluate the content,
coherence, and linguistic quality of essays with
precision, mirroring the reasoning process of human
raters (Ramesh, 2021). These systems aim to reduce
the manual grading burden while delivering timely
assessments and grammatical corrections (Wang,
2024).
a
https://orcid.org/0009-0007-5527-223X
b
https://orcid.org/0000-0003-2118-9482
c
https://orcid.org/0000-0002-8761-7892
Natural Language Processing (NLP) plays a
pivotal role in enabling these systems by supporting
consistent and efficient essay analysis (Roshanaei,
2023). The integration of NLP and machine learning
facilitates a more in-depth analysis of linguistic
features, thereby supporting objective and scalable
assessment mechanisms. Current AES systems apply
various NLP and machine learning techniques to
assess student responses by aligning them with pre-
established rubrics or scoring guidelines (Dikli,
2006). AES, in particular, focuses on assigning a
numeric score to written text commonly in language
learning or standardized assessment contexts
(Shermis, 2003).
Transformer-based models like BERT
(Bidirectional Encoder Representations from
Transformers) have driven major progress in NLP by
allowing for context-aware text understanding in both
directions (Sagama, 2023). BERT’s strength lies in its
pre-training and fine-tuning paradigm, where the
model learns language structure through Masked
Language Modelling and Next Sentence Prediction
(Devlin, 2018). DeBERTa, short for Decoding-
Rahmat, M., Niswar, M. and Paundu, A. W.
Optimizing DeBERTa V3 for Accurate Automated Essay Evaluation in the Indonesian Educational Context.
DOI: 10.5220/0014272600004928
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Innovations in Information and Engineering Technology (RITECH 2025), pages 217-223
ISBN: 978-989-758-784-9
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
217
enhanced BERT with Disentangled Attention,
improves upon BERT by using a disentangled
attention approach along with an improved mask
decoding component. It represents each word with
two distinct vectors for content and position and uses
disentangled matrices to compute attention weights.
This model further utilizes two unsupervised tasks
during pre-training to enhance its semantic
understanding (Asri, 2025).
The relevance of DeBERTa v3 for Automated
Essay Scoring (AES) tasks has been empirically
validated. Studies on English-language datasets have
shown excellent performance (Wang et al., 2024).
Specifically for the Indonesian language, where
earlier models such as BERT and IndoBERT
typically achieved QWK scores in the range of 0.52–
0.55 (Setiawan et al., 2021), DeBERTa v3 has
demonstrated a significant advantage. A recent study
by Rahmat et al. (2024) reported that a fine-tuned
DeBERTa v3 model on Indonesian student essays
achieved an average QWK score of 0.558. This score
reflects a moderate level of agreement with human
raters (Landis & Koch, 1977) and outperforms
popular baseline models for Indonesian AES.
Therefore, this study proposes the use of an optimized
DeBERTa v3 model with QWK as the primary metric
to improve accuracy and fairness in automated essay
evaluation.
Against this backdrop, the present study
explores the application of the DeBERTa v3 model
for the automatic scoring of essays written in
Indonesian. It particularly focuses on optimizing the
model's performance using the Quadratic Weighted
Kappa (QWK) metric, which is well-suited for
assessing agreement on ordinal scales and serves as a
robust indicator of alignment between machine-
predicted and human-assigned scores.
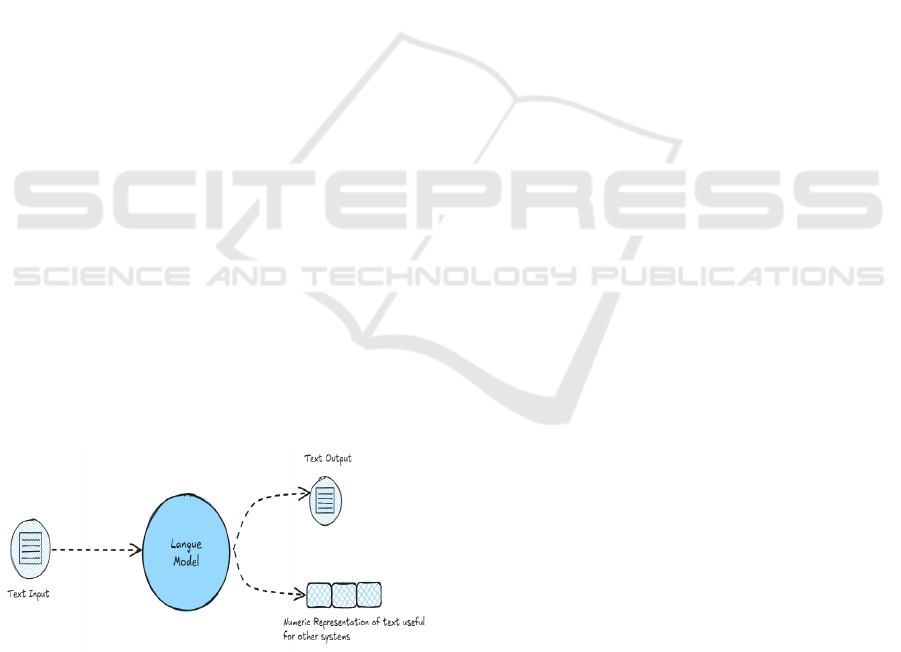
Figure 1: Overview of how Large Language Models
(LLMs) process text input and generate meaningful output.
2 METHODOLOGIES
2.1 Overview of the Methodology
This study implements an AES system using a state-
of-the-art Transformer-based model, namely
DeBERTa v3 (Decoding-enhanced BERT with
disentangled attention), which is known for its
superior ability to understand textual context and
semantics. The proposed system consists of three
major stages: (1) data preprocessing, (2) training and
fine-tuning of the DeBERTa v3 model, and (3)
performance evaluation using the Quadratic
Weighted Kappa (QWK) metric. The research
process is conducted systematically to ensure
objectivity, reliability, and measurable outcomes.
2.2 Dataset Description
The dataset used in this study comprises 500 open-
ended essay responses written in Bahasa Indonesia by
undergraduate students of the Informatics Program at
Universitas Sulawesi Barat. These essays were
collected from actual coursework and assessments
and reflect authentic student writing in an academic
setting. Each essay was manually scored by
university instructors using an ordinal scale ranging
from 1 to 5. Although the specific rubric dimensions
were not standardized across all courses, the scores
generally reflected aspects such as content relevance,
argumentation, coherence, and grammar. These
instructor-assigned scores served as ground truth
labels for supervised training.
In total, the dataset contained 500 data points,
with an average essay length of approximately 20–
120 words. After cleaning and preprocessing, all
samples were retained for model training and
evaluation. A 5-fold cross-validation scheme was
employed, with roughly 100 essays per fold, to ensure
stability and generalizability of the results across data
partitions. Inter-rater agreement was not directly
computed between multiple human scorers; however,
model performance was benchmarked using the
Quadratic Weighted Kappa (QWK) metric to capture
alignment between ordinal predictions and human
scores.
This dataset represents a realistic and domain-
specific resource for advancing Automated Essay
Scoring (AES) research in Bahasa Indonesia.
2.3 Data Preprocessing
The first step in this study involves preprocessing of
Indonesian-language essay texts. This stage is crucial
because raw data often contains noise such as spelling
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
218

errors, irrelevant symbols, and inconsistent structure,
all of which can affect model performance.
Preprocessing aims to simplify the data structure and
help the model focus on essential linguistic
information. The preprocessing pipeline in this study
includes the following steps:
1. Case Folding
All characters in the text are converted to
lowercase to ensure consistency in word
representation, as the model may treat
“Indonesia” and “indonesia” as two distinct
tokens if left unnormalized.
Table 1: Case Folding Example.
Original Text Result
algoritma adlah serangkaian
instruksi
algoritma adalah
serangkaian instruksi
2. Punctuation and Symbol Removal
Punctuation marks such as periods, commas,
exclamation points, and special symbols like #,
@, or & are removed, as they generally carry
limited semantic meaning in essay scoring tasks.
Table 2: Punctuation and Symbol Removal Example.
Original Text Result
algoritma adlah
serangkaian instruksi
100% 😄!
algoritma adlah
serangkaian instruksi
100% 😄
3. Numbers and Non-Alphabetic Characters
Removal
Numerical values and non-alphabetic characters
such as 123, !, *, and emoji are removed, as they
are not considered relevant in natural language
evaluation for essay assessment.
Table 3: Numbers and Non-Alphabetic Characters Removal
Example.
Original Text Result
algoritma adlah
serangkaian instruksi 100%
😄
algoritma adlah
serangkaian
instruksi
4. Whitespace Normalization
Multiple or excessive spaces due to typing
inconsistencies are normalized into single spaces
to maintain clean and consistent text formatting.
Table 4: Whitespace Normalization Example.
Original Text Result
algoritma adlah
serangkaian instruksi
algoritma adlah
serangkaian instruksi
5. Typo Correction
Although not applied to the entire dataset,
typo correction was performed on selected
samples using dictionary-based or model-based
approaches to fix frequent misspellings
commonly found in student essays.
Table 5: Typo Correction Example.
The preprocessing process was carried out
through a Python pipeline, incorporating
libraries like re for regular expressions,
string, and the Natural Language Toolkit
(nltk). In the experimental phase, this
preprocessing was followed by tokenization and
padding before fine-tuning the DeBERTa v3
model.
2.4 DeBERTa Architecture
The core model employed in this study is DeBERTa
v3, a recent advancement in the Transformer
architecture. DeBERTa v3 offers superior capabilities
in processing complex sentence contexts through two
major innovations: disentangled attention and an
enhanced mask decoder. This model is fine-tuned
using a specific essay dataset in Bahasa Indonesia,
adapting the pretrained language understanding
capabilities to the AES task.
DeBERTa, or Decoding-enhanced BERT with
Disentangled Attention, builds upon the original
BERT architecture by introducing two structural
improvements (He, 2021):
1. Disentangled Attention: Each input token is
represented using two separate vectors: a
content vector 𝐻
𝑖
and a relative position vector
𝑃
𝑖
,,
𝑗
. Attention scores between tokens 𝑖 and 𝑗 are
calculated by explicitly separating the
contributions from both content and positional
information. As a result, the total attention score
incorporates four distinct components:
● Content-to-Content
● Content-to-Position
Original Text Result
Algoritma adlah
SerangKaian Instruksi
100% 😄!
algoritma adlah
serangkaian instruksi
100% 😄!
Optimizing DeBERTa V3 for Accurate Automated Essay Evaluation in the Indonesian Educational Context
219

● Position-to-Content
● Position-to-Position
2. This approach differs from traditional relative
position attention, where positional information
is typically fused into a single representation. By
disentangling content and position, DeBERTa
enables more granular and context-aware
attention mechanisms, thus capturing semantic
and syntactic dependencies with higher
precision. Mathematically, the attention score
A
i,j
between token i and j is computed as:
𝐴
,
=𝐻
,𝐻
|
𝑥 𝐻
,𝐻
|
=𝐻
𝐻
+ 𝐻
𝐻
|
+
𝑃
|
𝐻
+ 𝑃
|
𝐻
|
(1)
This disentangled attention mechanism allows the
model to better differentiate between the semantic
meaning of tokens and their positions in a sentence,
which is critical for understanding complex textual
structures in essay writing. In addition, DeBERTa
employs a rescaled attention function and relative
position bias, which are implemented on the query
and key vectors projected separately. This design
produces the final attention score as a combination of
content-to-content, content-to-position, and position-
to-content components, before being passed through
the SoftMax function to generate the final token
representation.
In contrast, BERT represents each word at the
input layer using a single vector obtained by summing
the word embedding (content) and position
embedding. This combined vector is then forwarded
into the self-attention layers to compute inter-word
dependencies.
Figure 2: Architecture of DeBERTa. DeBERTa improves
the BERT and the base model of RoBERTa by 1) using a
disentangled attention mechanism where each word is
represented by two vectors that encode its content and
relative position respectively, and 2) a superior mask
decoder (He, 2021).
2.5 Model Training and Fine-Tuning
In this study, the Mean Squared Error (MSE) loss
function is used to optimize the model weights during
training. The MSE is calculated as follows:
MSE =
∑
(𝑦
(
)
− 𝑦
()
)
(2)
Where:
● 𝑦
(
)
is the human-assigned essay score.
● 𝑦
()
is the model-predicted score.
● 𝑛 is the total number of essays in the training set.
The model is optimized using the AdamW
optimizer with an adaptive learning rate, a method
widely recognized for its effectiveness in fine-tuning
Transformer-based models. The update rule is as
follows:
𝜃
= 𝜃
− 𝜂
∈
(3)
Where:
● θ is the model parameter.
● η is the learning rate; and
● 𝑚
and 𝑣
are the bias-corrected estimates of the
first and second moments, respectively.
2.6 Model Evaluation with Quadratic
Weighted Kappa (QWK)
To ensure that the automatic scoring results align with
human judgment, this study uses Quadratic Weighted
Kappa (QWK) as the primary evaluation metric.
Unlike simple accuracy, QWK accounts for the
ordinal nature of the scoring task by weighting the
disagreement between predicted and true scores
based on their distance. The QWK is calculated using
the following formula (Chivinge, 2022):
𝑄𝑊𝐾 = 1 −
∑
∑
∑
∑
(4)
Where:
● O
ij
is the observed count of essays with true
score 𝑖 and predicted score 𝑗
● E
ij
is the expected count of such cases based
on marginal distributions.
● 𝑤
=
()
()
, is the quadratic weight.
● k is the number of distinct score categories.
The QWK value ranges from -1 to 1, where a
value close to 1 indicates a strong agreement between
model predictions and human raters.
To assess the effectiveness of the proposed
approach, a comparative evaluation is conducted
against several baseline models, including IndoBERT
and an LSTM-based approach. All models are trained
and tested using the same dataset, and evaluated using
multiple metrics: MSE, Mean Absolute Error (MAE),
Root Mean Squared Error (RMSE), and QWK. This
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
220
ensures the validity of the results and highlights the
specific contributions of the proposed method to the
performance improvement of AES systems for the
Indonesian language.
3 RESULT AND DISCUSSION
3.1 Performance Evaluation of the
DeBERTa V3 Model
This section presents the evaluation results of the
AES model developed using the DeBERTa v3
architecture, with performance optimization based on
the Quadratic Weighted Kappa (QWK) evaluation
metric. The model is designed to automatically assess
student essays written in formal academic contexts.
The evaluation data were collected from actual essay
assessments conducted in a university course in
Indonesia. The dataset consists of open-ended student
essay responses that were previously scored manually
by instructors. The use of real educational data aims
to assess how well the AES model replicates or
approximates human scoring in the local context and
linguistic characteristics of the Indonesian language.
The model was evaluated using three main metrics:
Mean Absolute Error (MAE), Root Mean Square
Error (RMSE), and QWK.
A 5-fold cross-validation scheme was applied to
ensure stability and robustness of the results across
different data partitions. The summary of evaluation
results per fold is presented in Table 5.
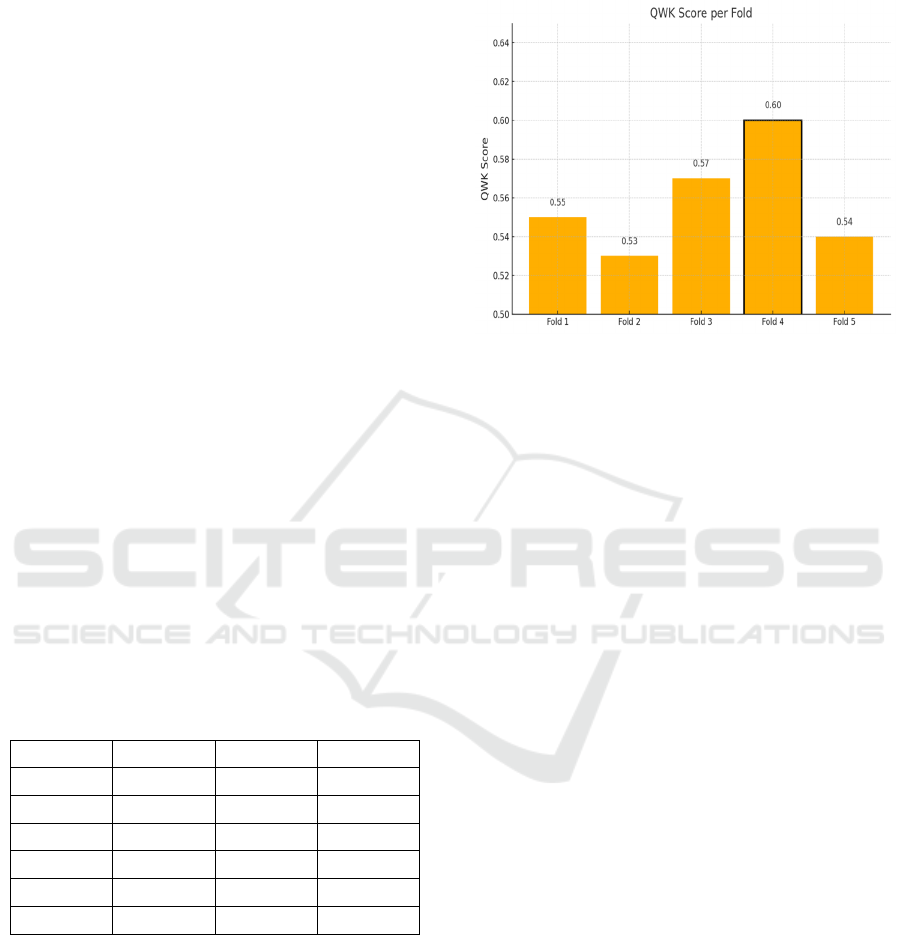
Table 6: AES Model Evaluation Results.
Fol
d
MAE RMSE QW
K
1 0.75 0.90 0.55
2 0.78 0.93 0.53
3 0.73 0.88 0.57
4 0.71 0.85 0.60
5 0.77 0.91 0.54
Avera
g
e 0.748 0.894 0.558
Based on the table above, the model achieves an
average MAE of 0.748, RMSE of 0.894, and QWK of
0.558. The relatively low and consistent MAE and
RMSE values across the folds suggest that the model
yields reasonably accurate and stable predictions.
Furthermore, the average QWK score falls within the
“moderate agreement” range, as defined by Landis
and Koch (1977), who classify values between 0.41
and 0.60 as indicative of moderate agreement
between two raters. To illustrate the model's
performance trends for QWK values, evaluation
graphs for each metric are presented in Figure 3.
Figure 3: Illustrates a bar chart of QWK (Quadratic
Weighted Kappa) scores across the five folds. Fold 4
achieves the highest QWK score of 0.60, demonstrating the
model's strongest alignment with human scoring in that data
partition.
3.2 Discussion
The results show that DeBERTa v3 achieves
competitive performance and, in some cases,
outperforms prior AES models for the Indonesian
language. A previous study by Setiawan et al. (2021)
reported QWK values ranging from 0.52 to 0.55 using
the BERT model. Other studies exploring pretrained
models for Indonesian language processing (e.g.,
Wijayanti & Widyantoro, 2021; Fauziati et al., 2021)
have not reached the performance level shown in this
study. The DeBERTa v3 model in this research
achieved a maximum QWK of 0.60 and an average of
0.558, indicating a notable improvement.
This improvement is likely due to DeBERTa
v3’s architectural innovations, particularly its
disentangled attention mechanism, which separates
content and positional information. This allows the
model to capture semantic relationships more
effectively critical for essay evaluation. Additionally,
direct optimization toward the QWK metric during
training enhances both accuracy and consistency with
human scoring.
Unlike earlier studies that relied on synthetic or
simulated data, this research utilizes authentic essay
submissions, this study employs real-world essay
data from Indonesian university students. Therefore,
the results better reflect the practical challenges of
implementing AES systems in real educational
contexts, including diverse essay topics, lengths, and
writing styles.
Optimizing DeBERTa V3 for Accurate Automated Essay Evaluation in the Indonesian Educational Context
221

Due to time and resource limitations, we did not
re-implement baseline models such as IndoBERT or
LSTM on the same dataset used in this study. Instead,
we refer to results reported in prior research for
comparison. Previous studies using IndoBERT for
Indonesian Automated Essay Scoring have achieved
QWK scores in the range of 0.52–0.55 (Setiawan et
al., 2021), while LSTM-based models have generally
shown lower performance. In contrast, our DeBERTa
v3 model achieved a QWK score of 0.558 on a real-
world Indonesian student essay dataset,
demonstrating a slight but meaningful improvement.
While differences in dataset and scoring rubric may
exist, this comparative context supports the observed
advantage of DeBERTa v3 for this task.
3.3 Error Analysis
To examine model behaviour in edge cases, we
performed a qualitative error analysis. Table 7 shows
examples where predicted scores diverged from
human ratings, often due to fluent but shallow
answers or strong content with informal writing.
These cases help reveal potential inconsistencies in
scoring.
Table 7: Examples of Model Misclassifications in Essay
Scoring.
Full text
Manual /
Predicted
score
Observation
/ Likely Cause
keamanan
jaringan adalah
usaha untuk
melindungi
jaringan
komputer dari
orangorang
yang tidak
b
erha
k
2/3
Model
overestimates
due to formal
grammar and
clarity
3.4 Limitations
Despite promising results, the proposed system has
several limitations. First, the model may exhibit bias
if the input essays differ significantly from the
training data in writing style, sentence structure, or
language variety. This could lead to unfair scoring for
students whose writing deviates from the dominant
patterns learned by the model. Second, fairness
concerns arise when dealing with informal language
or regional dialects, which may not be well-
represented in the training set — putting certain
student groups at a disadvantage. Lastly, scalability
remains a challenge. DeBERTa v3 is a large
transformer model requiring substantial
computational resources, which limits its practical
deployment in classroom settings with low-resource
hardware or limited internet access. These factors
must be addressed in future work, possibly through
lightweight model compression, fairness-aware
training, and broader, more inclusive datasets.
4 CONCLUSIONS
This study confirms that using the DeBERTa v3
model optimized with the Quadratic Weighted Kappa
(QWK) metric delivers strong results for AES in
Indonesian texts. The evaluation scores QWK of
0.558, MAE of 0.748, and RMSE of 0.894 show that
the model consistently aligns with human scoring.
DeBERTa v3 effectively captures contextual and
semantic meaning, outperforming traditional
Transformer models like BERT and IndoBERT.
QWK-based optimization further improves
score alignment by accounting for the ordinal nature
of essay ratings, making this approach particularly
valuable for low-resource languages such as
Indonesian.
REFERENCES
Asri, Y., Kuswardani, D., Suliyanti, W. N., Manullang, Y.
O., & Ansyari, A. R. (2025). Sentiment analysis
based on Indonesian language lexicon and IndoBERT
on user reviews PLN mobile application. Indonesian
Journal of Electrical Engineering and Computer
Science, 38(1), 677–688.
https://doi.org/10.11591/ijeecs.v38.i1.pp677-688
Borade, J. G., & Netak, L. D. (2021). Automated grading
of essays: A review. In Lecture Notes in Computer
Science (pp. 238–249). Springer.
https://doi.org/10.1007/978-3-030-68449-5_25
Chivinge, L., Nyandoro, L. K., & Zvarevashe, K. (2022).
Quadratic weighted kappa score exploration in diabetic
retinopathy severity classification using EfficientNet.
In 2022 1st Zimbabwe Conference of Information and
Communication Technologies (ZCICT) (pp. 1–9).
IEEE.
https://doi.org/10.1109/ZCICT56750.2022.9997890
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018).
BERT: Pre-training of deep bidirectional transformers
for language understanding. arXiv.
https://doi.org/10.48550/arxiv.1810.04805
Dikli, S. (2006). An overview of automated scoring of
essays. Journal of Technology Studies, 5(1). Retrieved
May 2025, from
http://files.eric.ed.gov/fulltext/EJ843855.pdf
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
222

Dronen, N., Foltz, P. W., & Habermehl, K. (2015).
Effective sampling for large-scale automated writing
evaluation systems. In Proceedings of the 2015 ACM
Conference on Learning at Scale.
https://doi.org/10.1145/2724660.2724661
He, P., Liu, X., Gao, J., & Chen, W. (2021). DeBERTa:
Decoding-enhanced BERT with disentangled attention.
In Proceedings of the International Conference on
Learning Representations (ICLR).
He, P., Liu, X., Gao, J., & Chen, W. (2021, January 6).
Microsoft DeBERTa surpasses human performance on
the SuperGLUE benchmark. Microsoft Research Blog.
https://www.microsoft.com/en-
us/research/blog/microsoft-deberta-surpasses-human-
performance-on-the-superglue-benchmark/
Irmawan, O. A., Budi, I., Santoso, A. B., & Putra, P. K.
(2024). Improving sentiment analysis and topic
extraction in Indonesian travel app reviews through
BERT fine-tuning. Jurnal Nasional Pendidikan Teknik
Informatika (JANAPATI), 13(2), 359.
https://doi.org/10.23887/janapati.v13i2.77028
Ramesh, D., & Sanampudi, S. K. (2021). An automated
essay scoring system: A systematic literature review.
Artificial Intelligence Review, 55(3), 2495.
https://doi.org/10.1007/s10462-021-10068-2
Roshanaei, M., Olivares, H., & Lopez, R. R. (2023).
Harnessing AI to foster equity in education:
Opportunities, challenges, and emerging strategies.
Journal of Intelligent Learning Systems and
Applications, 15(4), 123.
https://doi.org/10.4236/jilsa.2023.154009
Sagama, Y., & Alamsyah, A. (2023). Multi-label
classification of Indonesian online toxicity using BERT
and RoBERTa. In 2023 International Advanced
Informatics: Concepts, Theory and Applications
(IAICT) (p. 143). IEEE.
https://doi.org/10.1109/iaict59002.2023.10205892
Shermis, M. D., & Burstein, J. (2003). Automated essay
scoring. Informa.
https://doi.org/10.4324/9781410606860
Wang, I. X., Lee, C., & Yoon, H. (2024). Neural
automated writing evaluation with corrective feedback.
arXiv. https://doi.org/10.48550/arxiv.2402.17613
Optimizing DeBERTa V3 for Accurate Automated Essay Evaluation in the Indonesian Educational Context
223
