
Facttrace: Designing a News Fact-Checking Tool with Large
Language Models
Andy Wahyu Mardiansyah, Tiyas Yulita, Susila Windarta, Rahmat Purwoko and I Gede Maha Putra
Cyber Security Engineering, National Cyber and Crypto Polytechnic, Ciseeng, Bogor Regency, Indonesia
Keywords: FactTrace, Large Language Model, Retrieval Augmented Generation, Web Chatbot.
Abstract: The development of information technology has driven digitalization, which has had a positive impact on the
dissemination of information. However, this has also contributed to the increase in hoaxes. The spread of
hoaxes in Indonesia has increased year by year. This can cause division among Indonesian society. The main
problem is the lack of tools to automatically verify news validity. This study developed a news fact-checking
tool using large language models (LLMs) such as GPT-3.5 Turbo 0125, GPT-4o, Llama 3.1-8B, and
DeepSeek-R1-7B, integrated with retrieval-augmented generation (RAG). The approach used to improve
RAG is a hybrid retrieval and reranking method. The news validity verification tool (FactTrace) was designed
using the Waterfall model of the System Development Lifecycle (SDLC), developed with the n8n platform.
Testing was conducted using an evaluation matrix to assess the performance of the four LLMs used based on
accuracy, precision, recall, and F1 score. Based on the test results, FactTrace was implemented into a web
chatbot using LLM GPT-4o, which had an accuracy value of 0.989, precision of 0.991, recall of 0.987, and
F1 Score of 0.989.
1 INTRODUCTION
Digitalization in information technology allows
information to be disseminated widely and quickly,
enabling people to access information anywhere
(Kaliyar et al., 2021). This development has had a
positive impact on humanity, but the information
obtained may not be entirely accurate, which could
increase the spread of fake news (Rahmanto et al.,
2023). Hoax news is invalid information that is
believed to be true by someone without validation,
causing misunderstanding (Phan et al., 2023).
The Indonesian Ministry of Communication and
Digital Affairs recorded 1.923 pieces of fake news
circulating in Indonesia (Kementerian Komunikasi
dan Digital, n.d.). This shows that there is a large
spread of hoaxes in Indonesia. Hoaxes can influence
public opinion, leading to divisions between
individuals, groups, or classes (Kuntarto et al., 2021).
One of the efforts that can be made to curb the surge
in hoax news is the monitoring and control of
information in cyberspace by each individual
(Sahputra et al., 2023).
These efforts have been carried out in the form of
research, with several studies attempting to develop
automated news fact-checking tools based on large
language models (LLMs) and retrieval augmented
generation (RAG). There is research comparing the
performance of LLMs without RAG with LLMs
integrated with RAG for fact-checking tools (Nezafat
& Samet, 2024). There is also research comparing the
GPT 3.5 model with GPT 4, both of which are
integrated with RAG for fact-checking (Baltes et al.,
2024). In addition, there is research comparing the
LLM GPT model integrated with RAG and GPT
without RAG (Uhm et al., 2025). None of these
studies included a news fact-checking tool
specifically for Indonesians.
Based on related research, this study developed a
fact-checking tool called FactTrace with four LLM
models, namely GPT-3.5 Turbo 0125, GPT-4o,
Llama 3.1-8B, and DeepSeek-R1-7B, which are
integrated with RAG. The RAG technique used is a
hybrid retriever that combines a dense retriever
(based on vector representations) and a sparse
retriever (based on keywords), and employs reranking
techniques to reorganize the retrieved information
based on the relevance of the information used (Zhao
et al., 2024). FactTrace was developed using n8n,
employing the Waterfall software development
Mardiansyah, A. W., Yulita, T., Windarta, S., Purwoko, R. and Putra, I. G. M.
FactTrace: Designing a News Fact-Checking Tool with Large Language Models.
DOI: 10.5220/0014270800004928
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Innovations in Information and Engineering Technology (RITECH 2025), pages 203-208
ISBN: 978-989-758-784-9
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
203

lifecycle (SDLC) method. The n8n platform is an
open-source automation platform that enables users
to connect various applications and services to
automate business operations by leveraging the
capabilities of artificial intelligence, eliminating the
need for source code implementation (n8n, n.d.).
FactTrace was implemented into a web chatbot.
Previous studies have primarily focused on
evaluating the accuracy of Large Language Models
(LLMs) on general natural language processing tasks
or developing chatbot-based fact-checking systems
using a single model. However, there remains a lack
of research directly comparing the performance of
different LLMs in detecting factual versus hoax news,
particularly within the Indonesian news ecosystem.
Moreover, few studies have attempted to bridge the
gap between model benchmarking and real-world
application by integrating evaluation results into a
practical system. This study aims to address these
gaps by conducting a comparative performance
analysis of two state-of-the-art LLMs in identifying
factual and hoax news, and developing an integrated
chatbot system that leverages the best-performing
model for real-time news verification using the
Indonesian language. By combining empirical
evaluation with practical implementation, this work
provides both scientific insights into LLM
performance and a direct contribution to combating
misinformation through a usable tool.
2 METHODOLOGY
This research is a quantitative study that utilizes data
obtained by evaluating the performance of four LLM
models using an evaluation matrix that includes
accuracy, precision, recall, and F1 score. The study
was designed using the waterfall SDLC model, which
is a method for developing software with sequential
and interrelated stages (Saravanos & Curinga, 2023).
The stages of research design are shown in Figure 1.
2.1 Analysis
This stage includes a literature review and
observation to design the FactTrace system. The
literature review is used to gather information about
LLM- and RAG-based news fact-checking
technology from 2020 to 2025. The sources used
include journals, conferences, papers, books, articles,
and websites. Observations were conducted to
determine the components used for FactTrace,
including actual news sources and hoaxes, embedding
models, retriever enhancement methods for RAG,
LLM models, and evaluation matrices for assessing
classification performance.
Figure 1: Software Development Lifecycle Waterfall.
2.2 Design
This stage involves designing the FactTrace system.
FactTrace operates by creating a FactTrace function
that is executed when the user provides an input.
When the user inputs a news topic to be verified, the
input is processed by FactTrace through several
integrated techniques: embedding, which converts
text into vectors; RAG with a hybrid retrieval
approach that combines dense retrievers with sparse
retrievers; and a reranking approach to reorder the
retrieved documents based on their relevance scores.
The system then utilizes an LLM as a generator to
analyze the user’s input in relation to the retrieved
information from the news database. After FactTrace
processes the input, the result is displayed on the
FactTrace interface. The design of FactTrace
incorporates four LLM models, which are compared
to determine the best-performing model for news
classification using evaluation metrics consisting of
accuracy, precision, recall, and F1-score. Figure 2
illustrates the design of FactTrace, which connects
the user input with the FactTrace function.
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
204
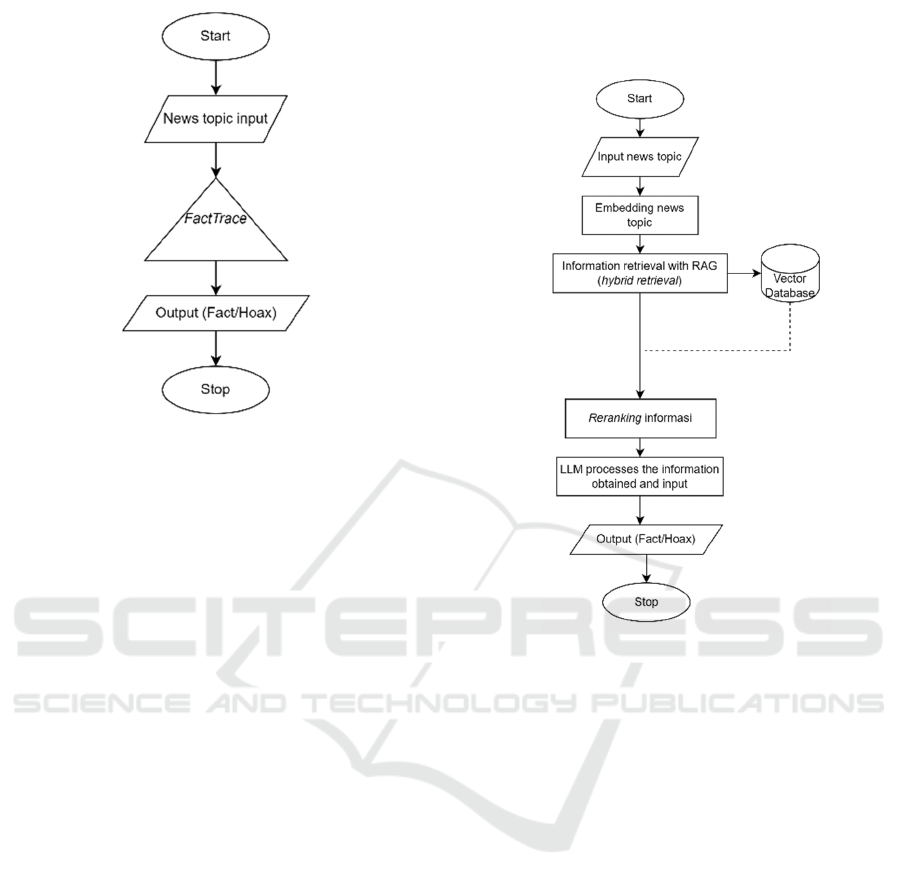
Figure 2: FactTrace workflow design.
2.3 Implementation
The FactTrace system was implemented on n8n by
integrating all the necessary techniques and
components. The system was developed using four
different LLM models and compared their
performance in checking news validity using the
same news source database.
Before creating FactTrace, a news database was
compiled, comprising factual news and hoax news.
Factual news was obtained from Detik.com and
Kompas Online, the two most widely used news
platforms in Indonesia, according to the Digital News
Report 2025 by the Reuters Institute for the Study of
Journalism. Meanwhile, hoax news was obtained
from TurnBack Hoax, which has official
authorization to publish hoax-related content. The
news data was limited to January 1, 2024, to July 22,
2025. The news source collection process was carried
out using an automated scraping program developed
in the Python programming language and the
Selenium library. The scraping results were stored in
CSV format, with each article labeled as either "fact"
for factual news or "fake" for hoax news. The CSV
file is then converted into a vector using an
embedding technique, which transforms text into a
vector representation. The embedding process is
implemented in the n8n backend using the Text-
Embedding-3-Small model. Next, the vector values
from each news article are automatically entered into
a vector database by n8n. This database is then used
as a knowledge source for the FactTrace system.
Figure 3 shows the specific workflow of the
FactTrace system implemented through n8n.
Figure 3: FactTrace system workflow.
Based on Figure 3, FactTrace begins by entering
a news topic in the chat column. The input is
connected to the FactTrace system. FactTrace first
converts the input into a vector to facilitate
information retrieval using RAG. The embedding
process uses the Text-Embedding-3-Small model.
After being converted into a vector, the input is used
as a reference in information retrieval by RAG with a
hybrid retrieval approach that combines dense
retrievers and sparse retrievers to optimise
information retrieval based on semantic meaning and
keywords from the document (Mandikal & Mooney,
2023). The retrieved information is information that
has similarities, both in semantic meaning through
vector values and keywords that match the user's
input. After the information is retrieved, it is reranked
based on its relevance value to the user's input.
Reranking is helpful in prioritising information that
has the most significant similarity to the user's input,
so that the LLM can process it appropriately. After
sorting, the information is processed by the LLM.
LLM works with engineering prompts provided by
the developer. Prompt engineering aims to provide
specific tasks to the LLM. In this study, LLM is
FactTrace: Designing a News Fact-Checking Tool with Large Language Models
205
specified to classify user input, including factual or
hoax news, based on information obtained from a
news source database. In this study, the LLM is
integrated with RAG, enabling it to make decisions
based on information obtained from the RAG
process. After the LLM processes the input and
information provided, it provides output in the form
of a hoax or factual news classification, accompanied
by a specific explanation based on the news source
database. This output is displayed in the facttrace chat
column with the user.
2.4 Testing
This stage involves testing to compare the
performance of four LLM models (GPT-3.5 Turbo
0125, GPT-4o, Llama 3.1-8B, and DeepSeek-R1-7B)
using an evaluation matrix that includes accuracy,
precision, recall, and F1 score. Testing is conducted
by providing input to the FactTrace system for each
LLM model. The input is generated from a database
of scraped news sources. This is useful for ensuring
the accuracy of the output generated by FactTrace for
each model based on predictions in the news source
database.
Of the 10.073 news items obtained, 8.000 were
selected for testing. This input consisted of 4.000
factual news items and 4.000 hoax news items.
Testing is conducted by inputting each input into an
automated program connected to the FactTrace
system. FactTrace processes each input using a
predetermined workflow, and then the results
obtained for each LLM model are matched with
predictions made based on the news source database.
The matching is intended to calculate the confusion
matrix value, which is then used to calculate the
evaluation matrix for each LLM model. The
performance comparison of each model is explained
from the resulting evaluation matrix value.
2.5 Maintenance
This step helps maintain the FactTrace system in the
event of system failures, whether due to feature issues
or errors during input processing. This ensures that
the FactTrace system remains available to users at all
times.
3 RESULTS
In testing 8.000 inputs for each model, the confusion
matrix values were calculated with facts as positive
and hoaxes as negative, resulting in True Positive
(TP) when the prediction and result were both facts,
True Negative (TN) when both were hoaxes, False
Positive (FP) when the prediction was a hoax. Still,
the result is a False Negative (FN) when the
prediction is fact but the result is a hoax. Based on
these criteria, the evaluation matrix results, consisting
of accuracy, precision, recall, and F1 score for each
model, were obtained. These values are shown in
Table 1.
Table 1: Evaluation matrix results for each LLM model.
Model Accuracy Precision Recall F1 Score
GPT-3.5
Turbo 0125
0.957 0.972 0.941 0.956
GPT-4o 0.989 0.991 0.987 0.989
Llama 3.1-
8B
0.937 0.937 0.938 0.937
DeepSeek-
R1-7B
0.940 0.941 0.938 0.940
Table 1 presents the evaluation results. GPT-4o
achieved the highest performance (Accuracy = 0.989,
F1 = 0.989), followed by GPT-3.5 (0.956), DeepSeek
(0.940), and Llama (0.937).) Based on these results,
the GPT-4o model has the highest evaluation matrix
score for all aspects. Therefore, the LLM model
selected for the FactTrace system is GPT-4o.
Furthermore, the GPT-4o model is implemented as
the FactTrace web chatbot. Its use is explained as
follows.
Figure 4: FactTrace interface.
Figure 4 shows the initial display of FactTrace. To
use it, enter the summary, keywords, or title of the
news item you want to check in the input field at the
bottom of FactTrace. After entering the input,
FactTrace will process it using the flow shown in
Figure 3.
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
206

Figure 5: FactTrace output for hoax news.
Figure 6: FactTrace output for fact news.
After processing the input, FactTrace provides
output in the form of a classification indicating
whether the input is fake news or a fact, along with an
accompanying explanation. Figures 5 and 6 show the
FactTrace output for fake news and factual news
4 DISCUSSIONS
Based on Table 1, GPT-4o yields the best results in
classifying hoaxes and facts, achieving the highest
scores in all aspects of the evaluation matrix. GPT-
3.5 Turbo 0125 follows it for all evaluation matrix
scores, but this model has the most outstanding score
in precision, indicating that it can minimize false
positives. Next is the DeepSeek-R1-7B model, which
consistently yields stable results across all evaluation
matrix aspects, despite ranking below the two GPT
models. Last in the ranking is Llama 3.1-8B, though
its scores remain stable across all evaluation matrix
aspects, indicating that this model maintains
consistency in classifying fake news and factual
news.
5 CONCLUSIONS
Based on the analysis conducted, the LLM model
with the best performance among the four models
tested is GPT-4o. This model achieved the highest
and most consistent scores across all evaluation
metrics compared to the other models. This indicates
that GPT-4o is accurate in classifying fake news and
facts, capable of minimizing both false positives and
false negatives, and consistently and stably produces
correct values in line with predictions during
classification. These factors make GPT-4o the chosen
LLM model for FactTrace with the highest accuracy,
thereby serving as a reliable solution for quickly and
accurately verifying the validity of news.
REFERENCES
Baltes, B. A., Cardinale, Y., & Arroquia-Cuadros, B.
(2024). Automated Fact-checking based on Large
Language Models: An application for the press.
Kaliyar, R. K., Fitwe, K., Rajarajeswari, P., & Goswami, A.
(2021). Classification of Hoax/Non-Hoax News
Articles on Social Media using an Effective Deep
Neural Network. Proceedings - 5th International
Conference on Computing Methodologies and
Communication, ICCMC 2021, 935–941.
https://doi.org/10.1109/ICCMC51019.2021.9418282
Kementerian Komunikasi dan Digital. (n.d.). Siaran Pers
No. 08/HM-KKD/01/2025. Retrieved July 20, 2025,
from https://www.komdigi.go.id/berita/siaran-
pers/detail/komdigi-identifikasi-1923-konten-hoaks-
sepanjang-tahun-2024
Kuntarto, Widyaningsih, R., & Chamadi, M. R. (2021). The
Hoax of Sara (Tribe, Religion, Race, and Intergroup) as
a Threat to The Ideology of Pancasila Resilence. Jurnal
Ilmiah Peuradeun, 9(2), 413–434.
https://doi.org/10.26811/peuradeun.v9i2.539
Mandikal, P., & Mooney, R. (2023). Sparse Meets Dense:
A Hybrid Approach to Enhance Scientific Document
Retrieval. https://priyankamandikal.github.io/
n8n. (n.d.). Welcome to n8n Docs. Retrieved May 29, 2025,
from https://docs.n8n.io/#where-to-start
Nezafat, M. V., & Samet, S. (2024). Fake News Detection
with Retrieval Augmented Generative Artificial
Intelligence. 2024 2nd International Conference on
Foundation and Large Language Models (FLLM), 160–
167.
https://doi.org/10.1109/FLLM63129.2024.10852474
Phan, H. T., Nguyen, N. T., & Hwang, D. (2023). Fake
news detection: A survey of graph neural network
methods. In Applied Soft Computing (Vol. 139).
Elsevier Ltd.
https://doi.org/10.1016/j.asoc.2023.110235
Rahmanto, A. N., Yuliarti, M. S., & Naini, A. M. I. (2023).
Fact Checking dan Digital Hygiene: Penguatan Literasi
Digital sebagai Upaya Mewujudkan Masyarakat Cerdas
Anti Hoaks. PARAHITA : Jurnal Pengabdian Kepada
Masyarakat, 3(2), 77–85.
https://doi.org/10.25008/parahita.v3i2.85
Sahputra, I., Pratama, A., Fachrurrazi, S., & Ari Saptari, M.
(2023). Meningkatkan Semangat Literasi Digital Pada
FactTrace: Designing a News Fact-Checking Tool with Large Language Models
207

Generasi Millenial Dalam Penangkalan Berita Hoaks.
Jurnal Malikussaleh Mengabdi, 2(1), 2829–6141.
https://doi.org/10.29103/jmm.v2i1.12358
Saravanos, A., & Curinga, M. X. (2023). Simulating the
Software Development Lifecycle: The Waterfall
Model. Applied System Innovation, 6(6).
https://doi.org/10.3390/asi6060108
Uhm, M., Kim, J., Ahn, S., Jeong, H., & Kim, H. (2025).
Effectiveness of retrieval augmented generation-based
large language models for generating construction
safety information. Automation in Construction, 170.
https://doi.org/10.1016/j.autcon.2024.105926
Zhao, P., Zhang, H., Yu, Q., Wang, Z., Geng, Y., Fu, F.,
Yang, L., Zhang, W., Jiang, J., & Cui, B. (2024).
Retrieval-Augmented Generation for AI-Generated
Content: A Survey. http://arxiv.org/abs/2402.19473
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
208
