
Analysis on Fraudulent Bank Account Data Detector Using Ensemble
Learning
Marvel Lemuel Junaidi, Farrell Marcello Lienardi, Nathan Setiawan and Hidayaturrahman
School of Computer Science, Bina Nusantara University, Jalur Sutera Road, Jakarta, Indonesia
Keywords: Fraud Detection, Ensemble Learning, Bank Account, RFNet, Logistic Regression.
Abstract: As the modern age has expanded in recent years, complications such as fraudulent data in the banks follow
as well. As one of the efforts for countermeasure, a study is conducted to analyze an ensemble learning method,
namely RFNet and compare it to two other models, namely XBNet and DevNet, using Logistic Regression to
stack the models. The study is conducted on a publicly available bank account dataset to evaluate the
performance of these models based on their respective accuracy, precision, recall, and ROC-AUC scores, as
well as their execution times. As for the statistical approach, we also measured the confidence interval with
95% confidence, along with the standard deviation to show model reliability, stability, and consistency. The
results of this study show that XBNet still outperforms the other methods in terms of overall performance,
consistency, and reliability. Even so, the RFNet model can be an applicable alternative for fraud detection in
certain scenarios and can compete in consistency in some metrics, while also outdoing a well-known DevNet
across several metrics. These results highlight the importance of model choice and tuning when conducting
tasks involving large amounts of data, especially when dealing with imbalanced data.
1 INTRODUCTION
Fraudulent bank data has escalated in recent years due
to the rise of digital banking and e-commerce
platforms and continues to be a critical threat to
businesses and economies worldwide, necessitating
advanced detection techniques (Adewumi et al.,
2024). This creates the need for modern fraud
detection systems to accurately identify fraud and
while being able to constantly adapt to this ever-
changing landscape.
The Suspicious Transaction Report or STR, which
enlists the statistics of suspicious transactions yearly,
from the state government in Indonesia displays a
significant increase in suspicious transactions for
both bank and non-bank transactions in 2 years from
2021, with around a 14% increase in STR from 2021
to 2022 and a huge 43% increase from 2022 to 2023.
In addition, the DKI Jakarta province had the most
STR numbers throughout these years, making up
approximately 97% of the data, and cases related to
gambling contributed about 50% of said data (Pusat
Pelaporan dan Analisis Transaksi Keuangan
[PPATK], 2024). Furthermore, suspicious bank data
have consistently increased over the years, suggesting
the need for improvement in countering the
development and implementation of financial attacks.
With that said, the scope of the research includes
providing a deep analysis on a proposed ensemble
learning model named RFNet, along with a
comparative analysis in detecting fraudulent bank
data, including XBNet and DevNet. The research
encompasses bank data that are indicative of fraud,
utilizing a reliable and validated dataset which was
mainly used for research on a new fraud detection
approach inspired by real-life human brain
mechanisms called Spiking Neural Network or SNN
(Perdigão et al., 2025). The research revealed
interesting breakthroughs that led to the use of said
dataset for this paper. Moreover, this study aims to
evaluate the effectiveness of each method in detecting
fraudulent data based on metrics such as accuracy,
precision, and recall while also highlighting the
challenges faced in fraud detection within the digital
era, contributing to the development of faster and
more reliable fraud detection methods that can be
applied by the banking industry in Indonesia.
One study highlights that credit card fraud is one
of the most common forms of fraud in the financial
industry, and although machine and deep learning
models have been widely used to predict this fraud,
196
Lemuel Junaidi, M., Marcello Lienardi, F., Setiawan, N. and Hidayaturrahman,
Analysis on Fraudulent Bank Account Data Detector Using Ensemble Learning.
DOI: 10.5220/0014268100004928
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Innovations in Information and Engineering Technology (RITECH 2025), pages 196-202
ISBN: 978-989-758-784-9
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
there are still several challenges to predict credit card
fraud transactions (Ekiye and Hewage, 2024). A
possible solution to this is ensemble learning, which
are methods that aim to integrate data fusion, data
modeling, and data mining into a unified framework
(Dong et al., 2020). One such method that fits into this
category is the XBNet (or XGNet) method, being a
framework that is known for its efficiency on tabular
datasets. Its ability to incorporate regularization and
handle missing values makes it a strong candidate for
fraud detection.
In relation to that, one of the methods this study
aims to compare is the XBNet, which combines
gradient boosted trees with a feed-forward neural
network architecture (Sarkar, 2022). The model is
trained using an optimization technique where the
weights of the neural network are updated using
traditional gradient descent, and feature importance is
used to adjust the weights in the intermediate layers
of the network, boosting performance by
incorporating insights from the tree-based model and
helping fine-tune the network.
Moreover, another possible approach is the
DevNet method, which is a method that excels at
identifying anomalies when learning features. One
study showed that DevNet achieves excellent results
in fraud detection, as it is more efficient and addresses
data imbalance issues better than the other methods
that were tested in the study. The framework uses a
Gaussian prior to generate reference scores and uses
a Z-score-based deviation loss function to push the
anomaly scores of normal objects close to the
reference score and anomalies far away, making it
excel in scenarios with high anomaly contamination
(Pang et al., 2019).
However, the proposed approach of this study
aims to implement ensemble learning on the random
forest method, which one study has been proven to be
potent at fraud detection tasks (Xuan et al., 2018),
with a neural network, that another study has proven
to be similarly potent at the task, albeit significantly
harder to train, to produce a method that can
complement each other and perform better at the task
overall (Asha et al., 2021).
2 RESEARCH METHODOLOGY
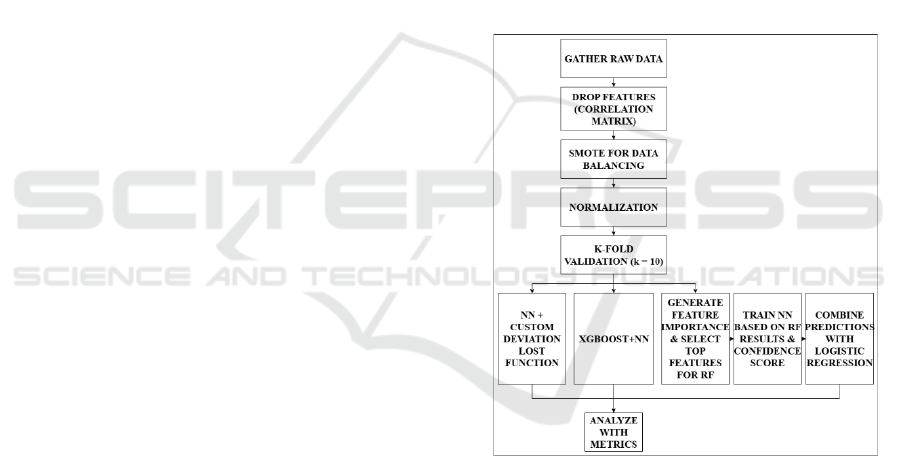
The research timeline is shown on Figure 1. Firstly,
the study begins by gathering the dataset,
preprocessing the data, training the individual
models, combining the models, and ends with
comparing the individual performances of the three
proposed ensemble models. The metrics used to
measure the performance of the XBNet, RFNet, and
DevNet approaches respectively are accuracy,
precision which evaluates the number of non-fraud
cases being labeled as fraud, recall for the ability to
determine fraud data as fraud, Receiver Operating
Characteristic Area Under Curve (ROC AUC), and
execution time to see which algorithm can make
predictions the fastest. Apart from that, the standard
deviation of both RFNet and XBNet are calculated to
measure model consistency. For the statistical
approach, we use confidence interval (CI) of 95% to
test model reliability or stability. The dataset used in
this research is acquired from Kaggle, with a total size
of one million rows and thirty-two columns and
comprises of information of fraud and non-fraud
data at a bank. As for data privacy protection, this
dataset has performed noise addition and feature
encoding, modifying the value to disguise the actual
content.
Figure 1: Flowchart of Research Methodology.
The data gathered goes through several data
preprocessing techniques to improve the quality of
data input for the models. The first step taken here
was to check for null values and remove them to
ensure the models will not break down during
training. Then, a correlation matrix is applied to every
feature, with the results being printed afterwards. The
results will be the basis of the decision when
performing feature selection. The columns are then
narrowed down to identify the ones needed to predict
fraudulent data. Subsequently, several features that
were deemed as irrelevant to the consideration of
Analysis on Fraudulent Bank Account Data Detector Using Ensemble Learning
197
determining whether a data is fraudulent or not were
dropped.
Since the data is imbalanced, Synthetic Minority
Oversampling Technique or SMOTE data
augmentation was employed to create synthetic
samples for the minority class, which in this case is
the fraud boolean label 1. This technique, also known
as data augmentation, adds random small changes
based on normal distribution. It helps to balance the
dataset and improve models’ performance.
Afterwards, data normalization was applied to ensure
every row of data contributes evenly to the prediction.
The algorithms used in this study are Neural
Networks, XGBoost, Random Forest, and Logistic
Regression. RFNet, as the focus machine learning
model, uses top features based on feature importance
value with k = 7, which then will be passed to the
Neural Network model with the chosen confidence
score value (based on multiple testings). This is what
makes the model unique, since each model influences
one another instead of being distinct models
combined into one. The Neural Network model uses
the parameters generated or used for the Random
Forest model, which are selected features based on
feature importance and confidence score, making NN
results reliant on the RF model performance for
model novelty.
For XBNet, Neural Network will be combined
with XGBoost to create a stacking model. Finally,
Logistic Regression will be the meta model of those
two stack ensemble models. Its job is to learn the
prediction output and produce final predictions.
Additionally, the models undergo cross validation,
which results in more robust models. For Devnet, the
Neural Network model uses a custom deviation loss
function due to its nature as an unsupervised model.
The process of RFNet model is shown in more detail
based on Figure 1 since it is the main model to be
analyzed, while the other model uses similar methods
in reference to previous works.
3 RESULTS AND DISCUSSION
The code execution was primarily done on a Jupyter
Notebook on Kaggle, as it has a 12-hour execution
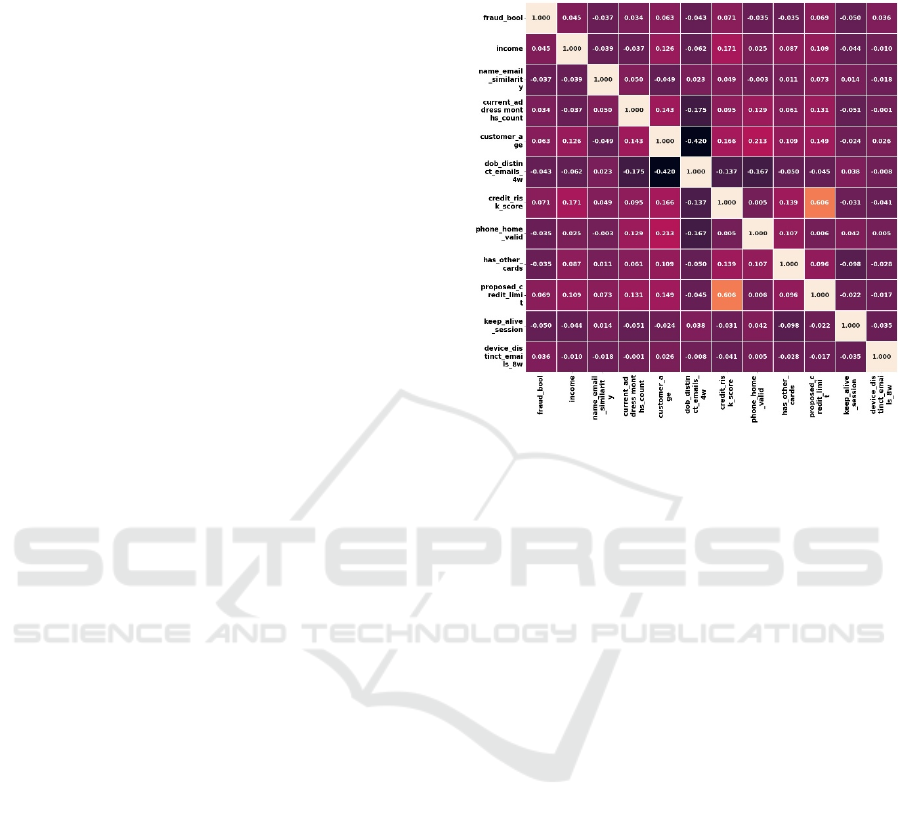
time limit. Out of 32 features, 12 features were chosen
to be the criterion to identify fraud data, and the
features are selected based on the correlation matrix
shown in Figure 2, which only shows features with
the correlation value > 0.03 or < -0.03 with
fraud_bool (criteria), and such range is used to
minimize the number of features. For the data split,
the ratio for train and tests was 8 by 2 as it is known
as one of the standard ratios.
Figure 2: Correlation Matrix Heatmap.
One of the main considerations during the
selection of the respective model features was the
results of a heatmap of attribute correlations, or
correlation matrix in Figure 2. The previous selected
12 features will be measured their correlation with
one another. This method was used to select strongly
correlated features so that none of the selected
attributes are highly correlated to avoid overlapping
information and overfitting. The credit_ risk_score
attribute, for example, is selected over the proposed
credit_limit since both are highly correlated, and
because the former attribute seems to be more related
to the fraud bool than the latter attribute, so the latter
attribute is not used.
Several features have been shown in both figures,
and there seems to be some common ground in this
case along with several differences. Both XGBoost
and Random Forest use decision trees in learning the
data pattern. They have a built-in feature importance
calculator to determine which features contribute
highly to the prediction. In Figure 3 and Figure 4, it is
evident that the keep alive session has the highest
importance value for XGBoost, while the income
attribute seems to be more insightful for Random
Forest. On the other hand, device distinct email has
the lowest value for feature importance in both
models. In addition, other features rank differently
between both models, with Random Forest having
high importance value across multiple features, while
XGBoost focuses on fewer features. For the RFNet
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
198
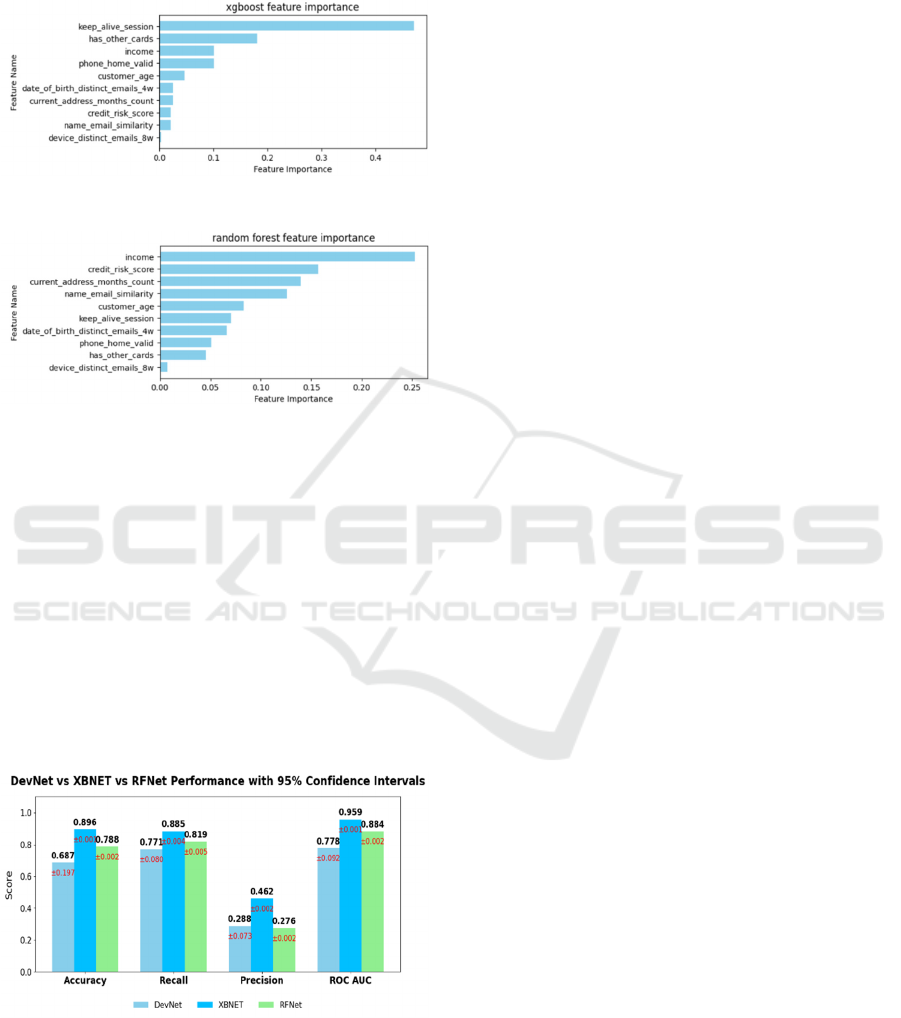
model, the top 7 features from Figure 4 are passed to
the Neural Network model to be trained alongside the
confidence score, which we obtained the value as 0.5.
Figure 3: XGBoost Feature Importance.
Figure 4: Random Forest Feature Importance.
Based on the results in Figure 5, it can be
concluded that the recall of each approach in
classifying fraud data is of satisfactory value, with
each of them being above 75%. That means that the
models are capable of classifying fraud data among
the non-fraud ones. However, the presence of
imbalanced data (even after applying SMOTE) due to
fraud cases makes up one-tenth of the non-fraud
cases, while precision is also very sensitive towards
false positives that the models generate, the precision
values of each approach are significantly lower than
the recall.
Figure 5: Classification Result.
On the other hand, ROC-AUC values above 0.8
indicate that the models can separate both fraud and
non-fraud data, and the accuracy of the three models
also indicates the overall prediction being a reliable
method for fraud detection. Additionally, there seems
to be a high time and resource requirement to run such
models based on the amount of time needed for each
model, approximately 3364.2, 7247.9, and 16533.4
seconds for XBNet, RFNet, and DevNet respectively.
Furthermore, the value range with 95%
confidence of each comparison between XBNet and
RFNet based further that XBNet is still a more
reliable model, however RFNet can still follow due to
the small differences between both model CI values.
In terms of precision, both are in equal footing or have
similar values. With enough training and testing on
the model, it is possible that RFNet can roughly
compete with XBNet.
Overall, the XBNet prevails over the other two
models. It results in the highest accuracy, precision,
recall, and ROC-AUC values with the lowest
execution time. Not only is the model efficient, but
this also suggests that the model is effective in dealing
with imbalanced tabular fraud data. This is possibly
caused by the algorithm which utilizes corrective
trees, which helps identifying rare fraud cases that
RFNet and DevNet lacks. Nevertheless, the RFNet is
still a respectable alternative that may perform better
should the data be more balanced, while DevNet can
also be another model to be utilized but might be more
suitable for unlabeled data as an unsupervised
learning-based model.
In comparison with previous works, XBNet,
specifically, has been tested to have a higher recall
and precision, which are approximately 0.96 and 0.95
respectively with accuracy ranging from 85-100% on
different datasets, which are all template or baseline
(example: Iris, Breast Cancer, etc) (Sarkar, 2022).
Apart from that, other works on anomaly detection,
one being multi-class IoT attacks dettection which
resulted in above 90% accuracy on XBNet (Iman et
al., 2025), along with a different hybrid model of
XGBoost with LSTM application with similar results
as the IoT detection model (Yousef et al., 2025). This
could indicate that apart from different kind of
anomaly, although XBNet is a reliable model, other
hybrid methods can outperform the current ensemble
model. Further testing with a more similar dataset can
be done to compare both cases.
Regarding the DevNet model, as presented in a
previous work, it is shown to require significantly
fewer labelled anomalies than other methods to reach
a respectable level of performance, using 75%–88%
fewer labelled anomalies than other methods
depending on the dataset used (Pang et al., 2019).
Other related works dived deeper into specific use
case for DevNet, with one suggesting that DevNet’s
performance leaves room for improvement when
Analysis on Fraudulent Bank Account Data Detector Using Ensemble Learning
199

identifying fraud, which can be done by incorporating
a variational loss function and weighing the loss
accordingly (Piyush et al., 2024), and the other
pointing out that DevNet performs well in key
evaluation indicators such as AUC-ROC when used
to develop network security detection solutions with
its effective use of limited marked abnormal data
(Hao et al., 2025).
The proposed RFNet model, which is a novel
approach to the matter, may not have directly similar
previous works, but the concept of Random Forest
being used for similar use cases can be seen. One such
previous work that was done using on a dataset of
credit card transactions showed that although random
forest by itself obtains good results on small set data,
the results can be negatively impacted due to factors
such as imbalanced data (Xuan et al., 2018). Other
previous works proposed approaches that utilise
random forest by combining it with data processing
algorithms beforehand, such as one that first utilised
an autoencoder to extract features before using
random forest for classification to detect credit card
fraud that resulted in an AUC score of 0.962 (Tzu and
Jehn, 2021), further showing random forest’s
potential suitability for the task of credit card fraud
detection, and another previous work tackling
imbalanced data by using SMOTE, before using
random forest, resulting in a model that has reduced
undetected fraudulent transactions, particularly in
scenarios with imbalanced data (Sorin and Ștefania,
2025).
Table 1: Standard Deviation Values.
Metrics XBNet RFNet DevNet
Accurac
y
0.001 0.0025 0.302
Precision 0.0028 0.0023 0.1117
Recall 0.0054 0.0082 0.1225
ROC AUC 0.0015 0.0028 0.1403
To further validate each model, the variabbility or
range of values of each model is also measured.
XBNet, based on Table 1, has lower standard
deviation values in almost all metrics, which indicates
that the model still prevails in consistency in
comparison with RFNet since lower values of
variance and standard deviation equals fewer varying
results. Despite all that, RFNet can still compete
against XBNet in terms of consistency, such as the
precision, which matches the result of previous
comparison in consistency, as RFNet have higher
advantage in model precision. On the other hand,
DevNet model consistency is proven to be the least
reliable in this study case.
4 CONCLUSION
The proposed method, RFNet, has proven to be a
reliable model to detect fraudulent data, especially
compared to XBNet which is a well-tuned model that
still outperforms the proposed model. Even so,
XBNet is still the preferred model due to the low
resource cost and model quality based on the
precision, recall, value range, and model accuracy. Be
that as it may, RFNet is proven to be able to compete
with XBNet in fraud detection, specifically in bank
data. Moreover, RFNet also outperforms a well-
known fraud detection model, namely Devnet, with a
noticeable difference in results. Be that as it may, if
compared with several previous works, it is appearant
that model tuning and optimization across all tested
models are still needed for a more reliable result.
Research limitations include the data used in this
research which is limited to publicly available
historical bank data accessible to the researcher that
may not cover all types of fraud cases occurring in
recent times, which may affect the generalizability of
the findings to the entire banking industry.
Furthermore, the study compares a more in-depth
model with several tunings, RFNet, with pre-existing
models, XBNet and DevNet, with less parameter
changes, which makes the comparative analysis lacks
fairness, and it is one of the deployment challenges
faced in this research. Apart from that, the time
consumption for running machine learning models is
known to be abundant, which also occurs in this
research. Therefore, any changes made in the model,
including parameters or based model rework can be
challenging as well.
Future research can consider using RFNet if other
well-known and effective models do not perform as
expected or used for more in-depth comparative
analysis with more fairness in tuning, since further
model tuning can be done for better and more
accurate results. On top of that, a better version of
RFNet can be applied in real life banking systems in
the digital side, including mobile banking or financial
tracking applications or system changes in the ATM
machines to apply the machine learning logic.
ACKNOWLEDGEMENTS
The authors would like to give their heartfelt gratitude
and respect to all contributions provided by both
internal and external parties, including references and
sources which provide useful insights for this
research to be properly conducted, along with BINUS
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
200

University contribution in providing financial
support. Furthermore, feedback and critiques are also
appreciated for refining this paper. In addition, we
hope that this paper could provide valuable insights
for other researchers to gain more knowledge and
improvements for existing works related to this
research.
OPEN CONTRIBUTIONSHIP
All base concepts and models used for this research
are mainly sourced or referenced from multiple
respectable author works, with a paper titled "XBNet:
An extremely boosted neural network” by Tushar
Sarkar for developing the XBNet model, “Deep
anomaly detection with deviation networks” by
Guansong Pang for the Devnet design, and “Random
forest for credit card fraud detection” by Shiyang
Xuan as a reference for the base RF model, which
then we develop into RFNet as the ensemble learning
model. Apart from that, Hidayaturrahman has also
made a significant contribution in supervising and
providing guidance in paper refinement and ideas on
the model preprocessing method, along with several
other pieces of advice for paper submission.
OPEN DATA
This research fundamentally used a public dataset
from Kaggle, which can also be accessed using web
browser at
https://www.kaggle.com/datasets/sgpjesus/bank-
account-fraud-dataset-neurips-2022, which had also
been used for research published in NeurlIPS 2022.
Under the CC BY-NC-SA 4.0 license, this dataset is
freely available to access, share, and transform with
accreditation.
REFERENCES
Adewumi, A., Ewim, S. E., Sam-Bulya, N. J., & Ajani, O.
B. (2024). Enhancing financial fraud detection using
adaptive machine learning models and business
analytics. International Journal of Scientific Research
Updates, 8(2), 12–21.
https://doi.org/10.53430/ijsru.2024.8.2.0054
PPATK. (2024). Buletin Statistik APUPPT Vol. 11, No. 12
- Edisi Desember 2023.
https://www.ppatk.go.id/publikasi/read/213/buletin-
statistik-apuppt-vol-11-no-12---edisi-desember-
2023.html
Perdigão, D., Antunes, F., Silva, C., Ribeiro, B. (2025).
Exploring Neural Joint Activity in Spiking Neural
Networks for Fraud Detection. In: Hernández-García,
R., Barrientos, R.J., Velastin, S.A. (eds) Progress in
Pattern Recognition, Image Analysis, Computer
Vision, and Applications. CIARP 2024. Lecture Notes
in Computer Science, vol 15369. Springer, Cham.
https://doi.org/10.1007/978-3-031-76604-6_4
A. E. Ekiye and P. Hewage. (2024). Comparative Analysis
of Machine and Deep Learning Techniques for Credit
Card Fraud Prediction in The Financial Sector, 2024
OPJU International Technology Conference (OTCON)
on Smart Computing for Innovation and Advancement
in Industry 4.0, Raigarh, India, 2024, pp. 1-6, doi:
10.1109/OTCON60325.2024.10688293.
Dong, X., Yu, Z., Cao, W., Shi, Y., & Ma, Q. (2020). A
survey on ensemble learning. Frontiers of Computer
Science, 14(2), 241–258.
https://doi.org/10.1007/s11704-019-8208-z
Sarkar, T. (2022). XBNet: An extremely boosted neural
network. Intelligent Systems with Applications, 15,
200097. https://doi.org/10.48550/arXiv.2106.05239
Pang, G., Shen, C., & van den Hengel, A. (2019). Deep
anomaly detection with deviation networks.
Proceedings of the 25th ACM SIGKDD International
Conference on Knowledge Discovery & Data Mining,
353–362. https://doi.org/10.1145/3292500.3330871
Xuan, S., Liu, G., Li, Z., Zheng, L., Wang, S., & Jiang, C.
(2018). Random forest for credit card fraud detection.
2018 IEEE 15th International Conference on
Networking, Sensing and Control (ICNSC).
https://doi.org/10.1109/ICNSC.2018.8361343
RB, Asha., & KR, Suresh K. (2021). Credit card fraud
detection using artificial neural network. Global
Transitions Proceedings, 2(1), 35–41.
https://doi.org/10.1016/j.gltp.2021.01.006
Akour, I., Alauthman, M., Almomani, A., Raman, R., &
Arya, V. (2025). Comprehensive Evaluation of XBNet
for Multi-Class IoT Attack Detection. International
Journal of Cloud Applications and Computing
(IJCAC), 15(1), 1-26.
https://doi.org/10.4018/IJCAC.386134
Alraba'nah, Al Sharaeh, & Ghosoun-Yousef, Saleh Al
Hindi. (2025). Enhancing Intrusion Detection Using
Term Memory and XGBoost. -Hybrid Long Short
-, 6(1), 247Journal of Soft Computing and Data Mining
61. 2
https://publisher.uthm.edu.my/ojs/index.php/jscdm/arti
cle/view/20781
Nikam, P., Vijjali, R., Masihullah, S., Negi, M., & Mathew,
J. (2024). Utilizing DevNet with variational loss for
fraud detection in hyperlocal food delivery.
Proceedings of the 7th Joint International Conference
on Data Science & Management of Data (11th ACM
IKDD CODS and 29th COMAD) (CODS-COMAD '24),
459–463. Association for Computing Machinery.
https://doi.org/10.1145/3632410.3632460
Zheng, H., Sun, D., Han, X., Zhang, X., & Zhao, Y. (2025).
Research on network security intrusion detection based
on DevNet. Proceedings of the 3rd International
Analysis on Fraudulent Bank Account Data Detector Using Ensemble Learning
201

Conference on Signal Processing, Computer Networks
and Communications (SPCNC '24), 251–256.
Association for Computing Machinery.
https://doi.org/10.1145/3712335.3712379
Lin, T.-H., & Jiang, J.-R. (2021). Credit Card Fraud
Detection with Autoencoder and Probabilistic Random
Forest. Mathematics, 9(21), 2683.
https://doi.org/10.3390/math9212683
Mihali, S.-I., & Niță, Ș.-L. (2024). Credit card fraud
detection based on random forest model. 2024
International Conference on Development and
Application Systems (DAS), 111–114. IEEE.
https://doi.org/10.1109/DAS61944.2024.10541240
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
202
