
Multi-Detection and Segmentation of Potato Seed on Conveyor
Machines with Blur Conditions Using NAFNet and YOLO11
Nurhatinah Hr
a
and Ingrid Nurtanio
b
Departement of Informatics Hasanuddin University Makassar, Indonesia
Keywords: Seed Potato, Deep Learning, Nonlinear Activation Free Network (NAFNet), YOLO11.
Abstract: In the agricultural industry, during the potato seed sorting process, automatic seed quality detection is a crucial
requirement for enhancing production efficiency and consistency. This study proposes a potato seed detection
and segmentation system, applicable to both sprouted and unsprouted seeds, by integrating the Nonlinear
Activation Free Network (NAFNet) as the image pre-processing stage and YOLOv11s-Seg as the main
detection model. NAFNet is used to reduce the blurring effect caused by conveyor movement, while
YOLOv11s-Seg is employed to detect and segment potato seed objects. Experiments were conducted using
video data at conveyor speeds of 0.70 m/s, 0.80 m/s, and 0.90 m/s. The evaluation results show that integrating
NAFNet with YOLOv11 significantly improves performance compared to baseline YOLOv11s-Seg and
YOLOv8. At 0.90 m/s, the proposed model achieved an mAP50 of 0.970, precision of 0.941, and recall of
0.890, outperforming YOLOv8, which only reached an mAP50 of 0.880 and a recall of 0.750. Consistent
improvements were also observed at 0.70 m/s, where the system achieved an mAP50 of 0.988, precision of
0.968, and recall of 0.967. NAFNet effectively improves image quality and enhances YOLOv11s-Seg
performance, offering substantial potential for accurate and reliable automation of potato seed sorting.
1 INTRODUCTION
Potatoes are one of the world's strategic horticultural
commodities after rice, wheat, and corn. In Indonesia,
potato productivity is still relatively low at around 59
tons/ha (BPS - Statistics Indonesia, 2024), one of
which is due to the low quality and quantity of seeds.
Sprouting seeds are very important because sprouts
are a key indicator of viability in the process of plant
propagation. However, the bud selection process is
still done manually, which is time-consuming,
inefficient, and error prone.
As technology advances, the application of deep
learning in agriculture is becoming a potential
solution to detect objects automatically and
accurately. Various methods have been developed to
detect potato seed shoots, but they are still limited in
dealing with small objects and sub-ideal
environmental conditions, such as uneven lighting or
ground-like backgrounds (Qiu et al., 2024). This
study aims to improve the detection of water shoots
by using Mask R-CNN and data augmentation. In
a
https://orcid.org/0009-0006-9737-4974
b
https://orcid.org/0000-0002-3053-4201
testing, the model with a learning rate of 0.001 and
data augmentation produces an F1-score of 0.966 at a
threshold of 0.8 (Areni et al., 2023) and the research
uses the Mask R-CNN instance segmentation
algorithm with ResNet 101 to detect and classify
coconut shell quality as a raw material for charcoal
briquettes a mean precision value (mAP) of 0.98
(Zikra et al., 2023). Research Gao using the SVM
method and weighted Euclidean distance with a bud
eye recognition accuracy of 91.48%. Although
accurate under controlled conditions, this method is
conventional and cannot work in real-time, making it
less suitable for application to conveyor-based
industrial systems (Gao, 2022). Efforts to improve
performance have been carried out with a deep
learning approach. Li et al., 2025 developed YOLOv8
with a combination of ECA attention, Ghost
convolution, and BiFPN so that it can improve the
detection accuracy of potato shoots with high
efficiency. However, the model focuses more on the
speed of inference and has not yet answered the
Hr, N. and Nurtanio, I.
Multi-Detection and Segmentation of Potato Seed on Conveyor Machines with Blur Conditions Using NAFNet and YOLO11.
DOI: 10.5220/0014266700004928
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Innovations in Information and Engineering Technology (RITECH 2025), pages 17-24
ISBN: 978-989-758-784-9
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
17
challenge of detecting very small or blurry objects in
moving images.
Another problem that arises in the industrial
context is the occurrence of motion blur in the image
of potatoes moving on high-speed conveyors. This
phenomenon has a direct impact on the decline in the
accuracy of the detection system. Research gathering
emphasized that blur produced by the movement of
cameras, instruments, and objects is a crucial problem
in the field of precision agriculture, so an image
restoration strategy is needed before the detection
process is carried out (Huihui et al., 2023). Thus,
without an adequate deblurring mechanism, the
detection performance of industrial conveyor systems
will experience significant degradation.
Within this framework, NAFNet is present as one
of the cutting-edge deblurring approaches that is
simple but highly effective as an image restoration
baseline that is able to achieve superior results on
various deblurring and denoising benchmarks with
better computational efficiency than previous
methods (Chen et al., 2022), and NAFNet's
integration with segmentation models, such as
WeedSeg is able to improve the detection of small
objects in low-quality UAV imagery (Genze et al.,
2023).
In the context of the industrial environment, the
main challenge faced is the occurrence of motion blur
due to the movement of conveyors at high speeds,
which has an impact on the decrease in the accuracy
of the detection system. Therefore, an approach is
needed that not only has a high level of accuracy but
is also capable of handling blurry images. One
strategy that can be applied is to integrate image
restoration models such as NAFNet, which functions
to improve image quality through the deblurring
process, before the detection stage is carried out.
Furthermore, the object identification process can be
carried out using modern detection models such as
YOLOv11, which are able to produce more precise
detection and segmentation. The combination of these
two methods is expected to improve the system's
resistance to visual interference as well as improve
the accuracy of potato bud detection in high-speed
conveyor conditions.
2 MATERIALS AND METHODS
This research focuses on the development of multiple
detection and segmentation of potato seeds in
conveyor machines with fuzzy conditions using deep
learning algorithms. The research workflow is
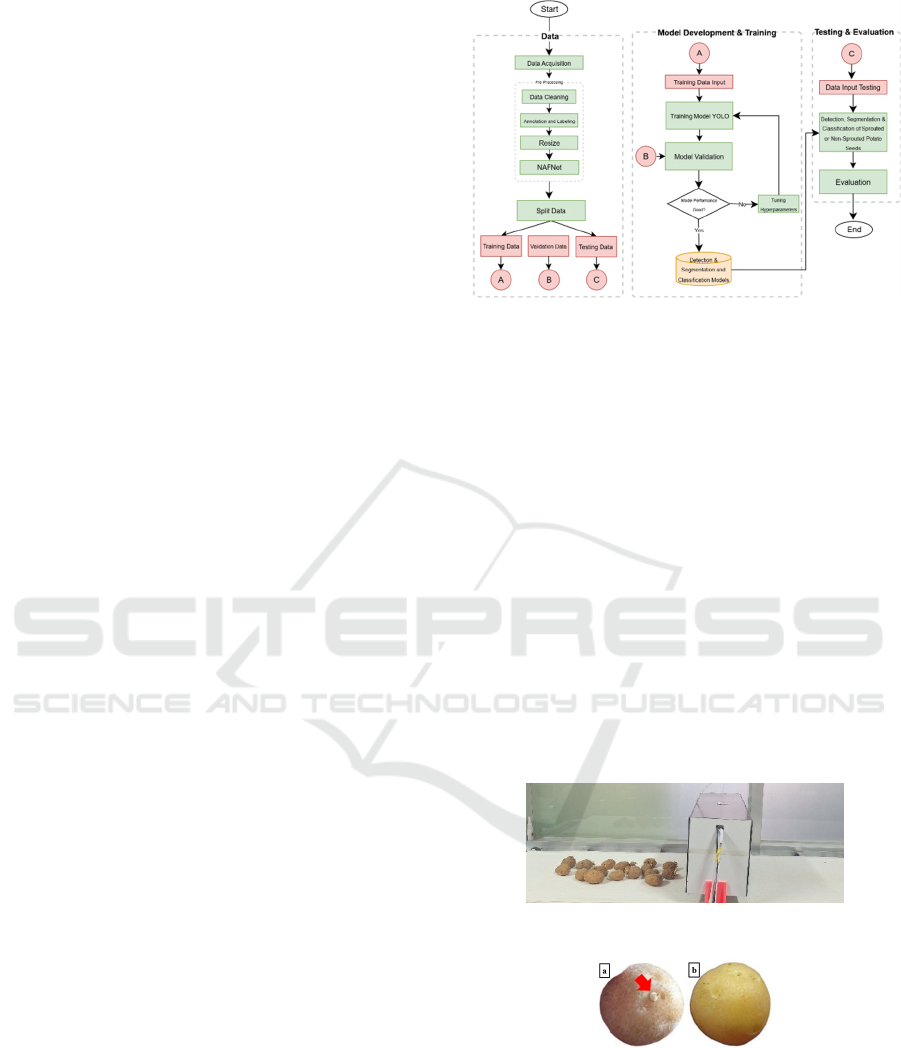
illustrated in Figure 1.
Figure 1: Research Process Workflow.
Figure 1 illustrates the proposed system design for
segmenting potato seeds in blurry conditions at
conveyor speeds of 0.70 m/s, 0.80 m/s, and 0.90 m/s,
which can be divided into several main stages as
follows:
2.1 Data Acquisition
The data collection process in this study was obtained
from real images of sprouted and unsprouted potato
seeds. The data was collected from video footage of
potato seeds moving on a conveyor with a Logitech
camera that has a resolution of 1080p and a frame rate
of 30 or 60 frames per second with a camera height of
15 cm. The data collection process was carried out at
three conveyor speeds, namely 0.70 m/s, 0.80 m/s,
and 0.90 m/s, to reflect the expected operational
variations in the industry.
Figure 2: Data collection techniques.
Figure 3: Classification of potato seeds:
(a) sprouted and
(b) non-sprouted.
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
18

(a) (b) (c)
Figure 4: Input Image with Conveyor Speeds. (a) 0,70 m/s,
(b) 0,80 m/s, (c) 0,90 m/s.
The study also included variations of potato seed
images taken at different levels of conveyor speeds in
the dataset. This approach aims to reflect more
realistic operational conditions as encountered in the
sorting process in an industrial environment. Thus,
the developed model is expected to have a higher
level of accuracy and reliability in detecting and
classifying potato seeds. In addition, this diversity of
scenarios allows the model testing and validation
process to be carried out more comprehensively, so
that model performance can be objectively assessed
against various real-world environmental conditions.
2.2 Pre-Processing
The dataset obtained has gone through an annotation
process using polygon labeling, with class categories
consisting of two main labels, namely sprouted and
non-sprouted, as shown in Figure 3. Considering that
the size of the acquired image varies, an image
resizing process is carried out so that all images have
uniform dimensions of 640 × 640 pixels.
Furthermore, the labeled datasets are divided into
three subsets, namely the train set, validation set, and
test set, with a distribution ratio of 70:20:10
sequentially. From this process, 1,365 images were
obtained for training, 390 images for validation, and
195 images for testing. The data distribution for each
class is as follows:
Table 1: Class Distribution in Potato Seeds.
Dataset S
p
route
d
Non-S
p
route
d
Train 3093 3636
Vali
d
1460 1515
Test 653 713
This distribution shows that the amount of data
between classes is relatively balanced in each subset,
with a small distribution difference (<10%). This
indicates that the dataset does not experience
significant class imbalance problems, so it can
support the model training process in a more
representative manner and reduce the risk of bias
towards one of the classes. Thus, the dataset used is
of sufficient quality to support the segmentation and
classification experiment of sprouted and non-
sprouted potato seeds. In addition to the annotation
and image size alignment process, the pre-processing
stage also includes improving image quality using the
Nonlinear Activation Free Network (NAFNet) as an
image restoration step. The application of NAFNet
aims to reduce the effect of motion blur arising from
the movement of potato seeds on the conveyor,
resulting in a sharper and more representative image.
Thus, the quality of the dataset is significantly
improved, while strengthening the accuracy of the
detection and segmentation model at the next stage of
development.
2.3 Model Development & Training
2.3.1 Nonlinear Activation Free Network
(NAFNet)
NAFNet represents an innovative deep learning
architecture. NAFNet has demonstrated outstanding
achievements in image recovery applications,
including addressing challenges in blurry image
recovery, noise reduction, and stereo super-
resolution. Specifically designed to address problems
at the pixel level, NAFNet innovatively replaces
batch normalization with layer normalization at the
pixel level to improve pixel accuracy. The use of U-
Net structures and jump connections in NAFNet
facilitates better transfer of information from input to
output, preventing the decline in accuracy associated
with information loss (Maruzuki et al., 2024). In the
context of our research on potato seeds moving over
a conveyor in classifying between sprouting and non-
sprouting, NAFNet's dense prediction capabilities at
the pixel level hold promise for accurately describing
features in regions of interest (ROI), demonstrating
potential applications in improving the accuracy of
object detection, especially in challenging image-
making conditions such as blurred images of potato
seeds. The NAFNet subblocks are shown in Figure 5.
Figure 5: NAFNet Subblock.
The formulation of Gated Linear Units (GLU) is as
follows:
𝐺𝑎𝑡𝑒(𝑋, 𝑓, 𝑔, 𝜎) = 𝑓
(
𝑥
)
⨀𝜎(𝑔
(
𝑋
)
) (1)
Multi-Detection and Segmentation of Potato Seed on Conveyor Machines with Blur Conditions Using NAFNet and YOLO11
19
where X shows a feature map, f and is a linear
transformer by representing a non-linear activation
function such as Sigmoid, along with 𝑔𝜎⊙ showing
element-by-element multiplication, has shown
potential to improve performance. However, it should
be noted that the introduction of GLU has led to an
unexpected increase in intra-block complexity.
The Gaussian Error Linear Unit (GELU) is
expressed by the following formula:
𝐺𝐸𝐿𝑈
(
𝑥
)
=𝑥∅ (𝑥) (2)
where it shows the cumulative distribution
function of the standard normal distribution, it should
be emphasized that GELU inherently integrates
nonlinearity and is free of activation functions.
Therefore, based on this concept, the feature map is
divided into two segments along the channel
dimensions, facilitating the multiplication of channels
and elements. A simplified schematic representation
of this gate is shown below, and its mathematical
expressions are provided below: ∅𝜎
𝑆𝐺
(
𝑋, 𝑌
)
= 𝑋 ⨀ 𝑌 (3)
where X and Y are feature maps of the same size.
Additionally, this paper integrates simplified channel
attention mechanisms into nonlinear networks
without activation. Spatial information undergoes
initial compression into the channel. The duct
attention mechanism has similarities to the linear unit
of the Berber and can be considered a special form of
the GLU. By maintaining the global essence of
information aggregated in channel attention and
facilitating interaction with channel-specific
information, formally simplified channel attention is
articulated as:
𝑆𝐶𝐴
(
𝑋
)
= 𝑋 ∗ 𝑊 𝑝𝑜𝑜𝑙 (𝑋) (4)
where X represents a feature map, the pool denotes
the grouping of the global average applied to the
spatial information consolidated into the channel, and
∗ denotes the channel multiplication operation.
2.3.2 YOLO (You Only Look Once)
The study leveraged the YOLOv8 and YOLOv11
models for object detection, both of which are part of
the YOLO (You Only Look Once) family, which is
renowned for its real-time detection with a high level
of accuracy.
1)
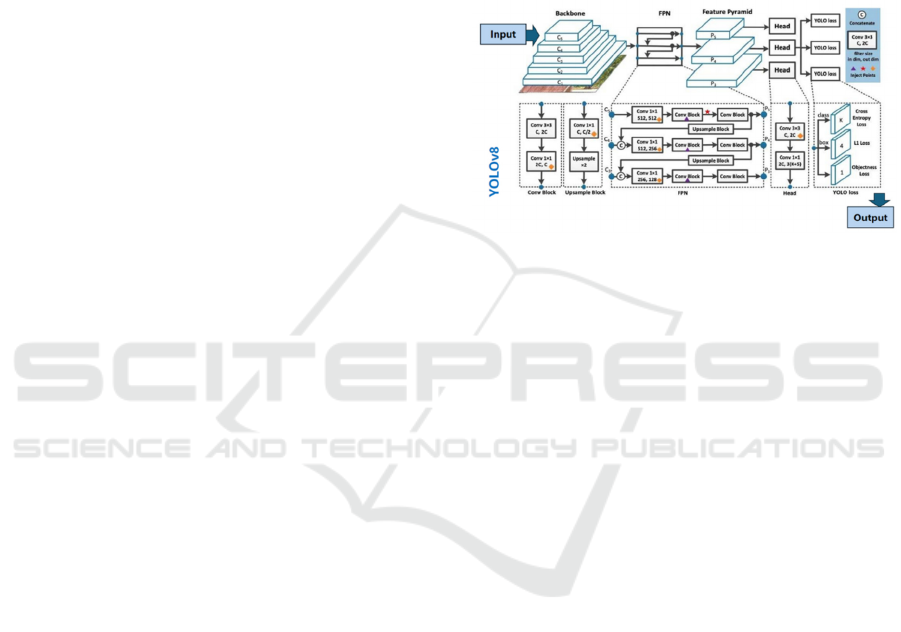
YOLOv8: YOLOv8 presents a modular
structure consisting of Backbone, Neck, and Head
structures, supporting multi-scale feature
representation for the recognition of small objects.
The Neck Module combines the Feature Pyramid
Network (FPN) and the Path Aggregation Network
(PANet) to improve object recognition at various
scales by integrating the characteristics of multiple
layers. The architecture also includes spatial pyramid
pooling (SPPF) for more efficient spatial data storage
(Jocher et al., 2023)
Figure 6: The Architecture diagram of YOLOv8.
2) YOLOv11: YOLO11, the most recent iteration
of the YOLO series, is a high-performance, low-
latency object detection method founded on
convolutional neural networks (CNN). YOLO11, in
contrast to its predecessors, incorporates an enhanced
backbone and neck architecture, which augments its
feature extraction proficiency, facilitating elevated
mAP and expedited inference rates. The YOLO11
series includes five different architectures:
YOLO11n, YOLO11s, YOLO11m, YOLO11l, and
YOLO11x. The primary distinctions among these
variants lie in the configuration of feature extraction
modules and convolutional filters at specific locations
within the network. Both model size and parameter
count increase progressively from YOLO11n to
YOLO11x (Zhao & Jiang, 2025). The introduction of
Cross Stage Partial with Spatial Attention (C2PSA)
blocks and other architectural improvements has
improved YOLOv11's real-time detection capabilities
while maintaining computational efficiency.
YOLOv11 also optimizes the Neck structure,
allowing for more efficient feature extraction and
faster convergence (Jocher et al., 2024).
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
20
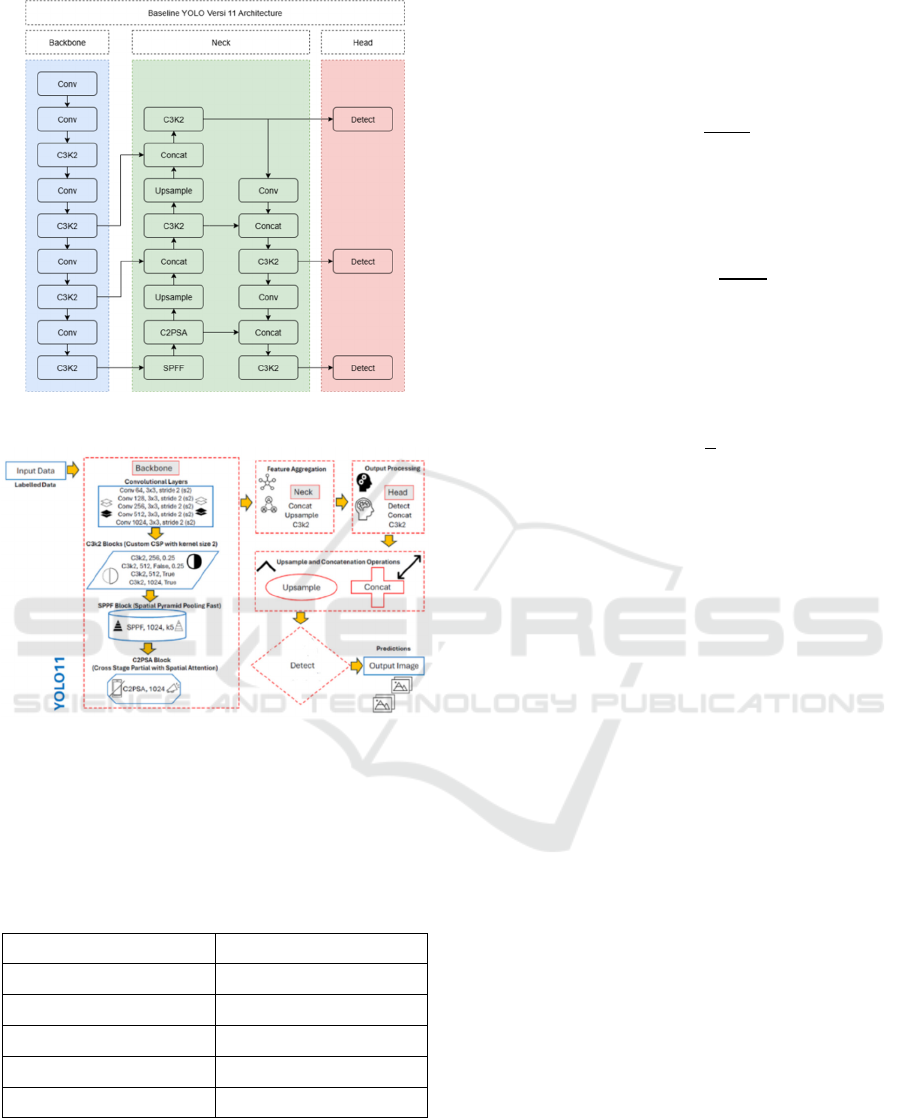
Figure 7: The Architecture of YOLO11.
Figure 8: YOLO11 builds on YOLOv8 architecture with
refined detection and segmentation efficiency and accuracy
over the benchmark dataset.
Table 2 shows the hyperparameter adjustment
configuration used in the model training process.
Table 2: Hyperparameter Adjustments.
Hyperparamete
r
Value
Image Size 640 x 640
Epochs 300
Momentum 0.937 (SDG)
weight_decay 0.0005
Learning Rate 0.01
2.4 Model Evaluation
The model evaluation approach was carried out to
assess the effectiveness in detecting and categorizing
potato seed entities. The performance measurement
method utilizes commonly used evaluation
methodologies, specifically precision, recall, and
mAP. The Confusion Matrix is obtained based on
calculations using equations (5), (6), (7) as follows:
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =
(5)
Precision measurement measures the proportion
of correctly detected potato seeds from all the
predictions the model produces.
𝑅𝑒𝑐𝑎𝑙𝑙 =
(6)
Recall measures the proportion of potato seeds
that are successfully detected correctly compared to
all potato seeds that are actually present at ground
truth.
𝑚𝐴𝑃 =
∑
𝐴𝑃
(7)
Where represents the Average Precision value for
the second class.𝐴𝑃
i, while N indicates the total
number of classes. Mean Average Precision (mAP) is
widely used in the field of object detection as a key
metric to assess the overall performance of the model
across the entire evaluated class (Li et al., 2025b).
For the complexity aspect of the model, there are
three metrics: Params, GFlops, and Size, which are
calculated according to equations (8) and (9):
𝑃𝑎𝑟𝑎𝑚𝑠 =
𝑟 x
(
𝑓 x 𝑓
)
x 𝑜
𝑜 (8)
𝐹𝑙𝑜𝑝𝑠 = 𝑜
(∑
𝑘
x 𝐶
x 𝐶
∑
𝑀
x 𝐶
)
(9)
3 RESULTS AND DISCUSSION
3.1 Model Training Configuration
In the results of the experiment, the impact of
hyperparameter combinations on the model was
evaluated. The main metrics used for comparison are
Mean Average Precision (mAP), Precision and
Recall. The following sections present a quantitative
and qualitative analysis of these metrics, comparing
the performance of YOLOv8-seg and YOLOv11-seg.
Multi-Detection and Segmentation of Potato Seed on Conveyor Machines with Blur Conditions Using NAFNet and YOLO11
21

Table 3: Comparison of YOLOv8s-seg and YOLOv11s-seg
Models on Various Metrics.
Metric
Model
YOLOv8 YOLOv11
YOLOv11
with
NAFNet
mAP 50 0,938 0,942 0,948
mAP 50-95 0,91 0,919 0,928
Accurac
y
0,861 0,881 0,894
Recall 0,898 0,901 0,902
Speed (GPU) 3.4 ms 3.4 ms 3.4 ms
Params 11 M 10 M 10 M
FLOPs 39.9 B 35.3 B 35 B
Table 3 shows that YOLOv11s have performance
advantages over YOLOv8s, especially in terms of
detection accuracy, precision, and recall, while
maintaining computational efficiency. The
application of NAFNet on YOLOv11s-Seg further
improves model performance, especially in
overcoming images that experience degradation due
to blur from the movement of objects on the
conveyor.
3.2 Segmentation Potato Seed Testing
The model was tested using a test dataset to verify its
performance in detecting, segmenting, and
classifying potato seeds under real conditions. In the
early stages, NAFNet was applied as an image
restoration method to reduce the effect of motion blur
that arises due to the movement of seeds on the
conveyor. The test was carried out under various
conditions of conveyor speed, namely 0.70 m/s, 0.80
m/s, and 0.90 m/s, which significantly caused
variations in the blur level in the test image. After
going through the restoration process, the image is
then processed by YOLOv11-seg to detect objects,
segment them, and classify potato seeds into two
main categories, namely Sprouted and Non-Sprouted.
Table 4: Model Test Results.
Method
Speed
(m/s)
mAP 50
(%)
P (%) R (%)
YOLOv8s-Seg
0,70 0,91 0,93 0,790
0,80 0,90 0,838 0,770
0,90 0,88 0,830 0,750
YOLOv11s-Seg
0,70 0,925 0,951 0,794
0,80 0,908 0,86 0,789
0,90 0,873 0,842 0,754
YOLOv11s-Seg
with NAFNet
0,70 0,98 0,968 0,967
0,80 0,972 0,955 0,90
0,90 0,97 0,941 0,89
Based on the test results in Table 4, it can be seen
that the YOLOv11s-Seg model consistently shows
better performance than YOLOv8s-Seg across all
conveyor speed variations. For example, at a speed of
0.90 m/s, YOLOv11s-Seg obtained an mAP value of
0.873 with a precision of 0.842, surpassing
YOLOv8s-Seg, which only achieved an mAP of 0.88
with a precision of 0.830. This finding confirms that
the YOLOv11s-Seg architecture has an advantage in
maintaining detection accuracy at high speeds.
Furthermore, the integration of NAFNet as a pre-
processing stage resulted in a significant performance
improvement. At a speed of 0.90 m/s, the
combination of YOLOv11s-Seg with NAFNet
achieved an mAP of 0.970 with a precision of 0.941
and a recall of 0.890, which is substantially higher
than the two previous models. This upward trend is
consistent across all speeds; for example, at a speed
of 0.70 m/s, the mAP increases to 0.988 with a
precision of 0.968 and a recall of 0.967. This shows
that the application of NAFNet can effectively
overcome image quality degradation due to blurring
effects on the conveyor, thereby maintaining model
performance stability.
Overall, the experimental results show that the
integration of NAFNet with YOLOv11s-Seg is
capable of producing an optimal combination of
accuracy, precision, and recall. This makes the
approach more reliable in supporting the detection
and segmentation of potato seeds under various
conveyor speed conditions. Visualization of the
detection results in the test image shows that
YOLOv11s-Seg, after undergoing pre-processing
with NAFNet, can accurately recognize and segment
potato seed objects. This is indicated by the
appearance of bounding boxes and segmentation
areas that correspond to the position of the objects.
The role of NAFNet is proven to be significant in
reducing the blur effect that occurs due to conveyor
movement, so that the contours and structure of the
seeds appear clearer. Thus, the application of
NAFNet not only improves the quality of the input
image but also directly contributes to improving the
performance of YOLOv11s-Seg in detecting and
segmenting potato seeds at varying conveyor speeds.
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
22
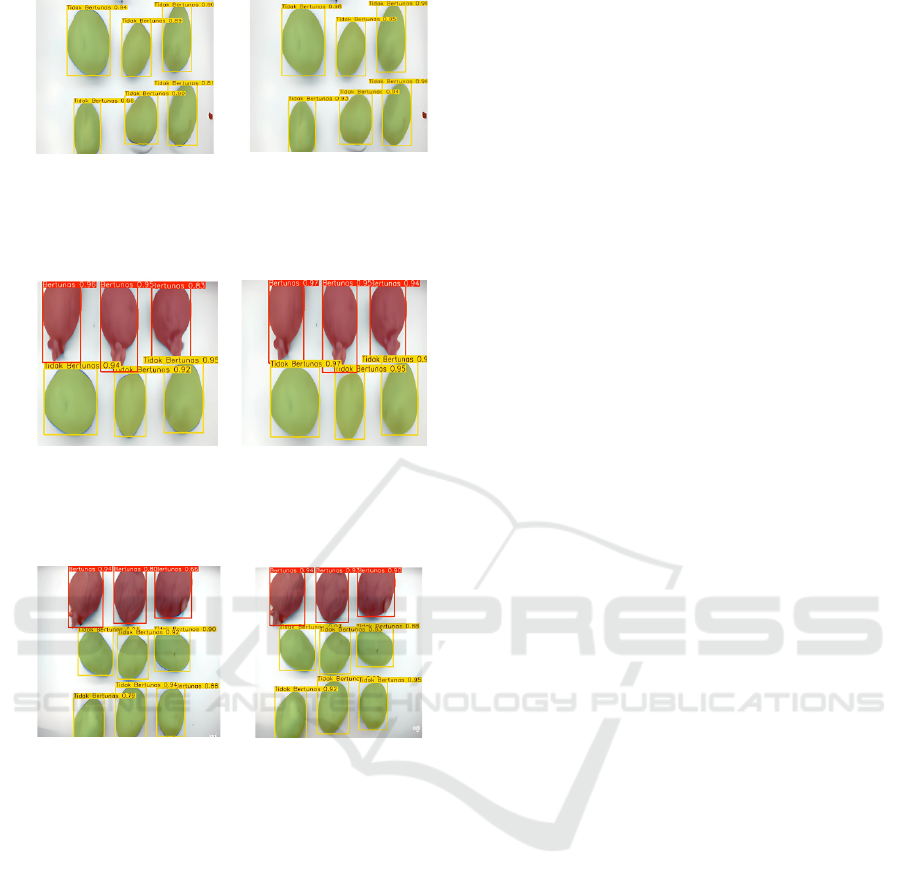
(a) (b)
Figure 9: Testing on real images, conveyor speed 0.70 m/s
with Model (a) YOLOv11 Baseline and (b) YOLOv11 with
NAFNet.
(a) (b)
Figure 10: Testing on real images, conveyor speed 0.80 m/s
with Model (a) YOLOv11 Baseline and (b) YOLOv11 with
NAFNet.
(a) (b)
Figure 11: Testing on real images, conveyor speed 0.90 m/s
with Model (a) YOLOv11 Baseline and (b) YOLOv11 with
NAFNet.
4 CONCLUSIONS
This study proposes an automatic detection and
segmentation system based on YOLOv11s-Seg
combined with NAFNet as a pre-processing stage to
overcome image quality degradation caused by
conveyor movement. Experimental evaluation results
show that the integration of NAFNet consistently
improves model performance across all conveyor
speed variations. This improvement is reflected in the
increase in mAP, precision, and recall values
compared to YOLOv8s-Seg and YOLOv11s-Seg
without pre-processing.
At a conveyor speed of 0.90 m/s, the combination
of YOLOv11s-Seg with NAFNet achieved an mAP
of 0.970, precision of 0.941, and recall of 0.890,
surpassing the performance of YOLOv8s-Seg, which
only achieved an mAP of 0.88 with a precision of
0.830 under the same conditions. A similar upward
trend was also observed at a speed of 0.70 m/s, where
the integration of NAFNet resulted in an mAP of
0.988, precision of 0.968, and recall of 0.967, which
was significantly higher than the model without pre-
processing. Thus, the application of NAFNet not only
serves to improve the quality of the input image but
also proves to strengthen the robustness and stability
of YOLOv11s-Seg detection in a dynamic industrial
environment with varying conveyor speeds.
Although the results obtained show a significant
improvement in performance, this study still has a
number of limitations. The evaluation was conducted
on a dataset with limited coverage and relatively
controlled environmental conditions, so the system's
ability to generalize to real-world situations with
higher complexity still needs to be further validated.
Furthermore, although the integration of NAFNet has
been proven to improve image quality and does not
cause a significant decrease in inference time, further
optimization is still needed so that the system can be
applied efficiently on a large scale and in real-time
applications with high computational loads. For
further research, testing in actual industrial
environments, development of model architecture
optimization strategies—for example, based on
attention mechanisms—and expansion of the dataset
are needed so that the system can be more adaptive to
varying field conditions. This direction of
development is expected to improve the efficiency
and accuracy of detection, thereby strengthening the
potential for applying computer vision technology in
the automatic selection and segmentation of potato
seeds in the modern agricultural sector.
ACKNOWLEDGEMENTS
The authors would like to thank the Master’s Program
in Informatics Engineering at Hasanuddin University
and the Artificial Intelligence and Multimedia
Processing (AIMP) Thematic Research Group for
their support and facilities during this research. The
authors also acknowledge colleagues who provided
constructive feedback and assistance throughout the
research process. Additionally, the authors
acknowledge the use of a generative AI tool to
enhance the clarity and grammar of this manuscript.
All contents, analyses, and conclusions remain the
sole responsibility of the authors.
Multi-Detection and Segmentation of Potato Seed on Conveyor Machines with Blur Conditions Using NAFNet and YOLO11
23

REFERENCES
Areni, I. S., Maulidyah, N., Indrabayu, Bustamin, A., &
Arief, A. B. (2023). Increasing Precision of Water
Sprout Detection based on Mask R-CNN with Data
Augmentation. International Journal on Advanced
Science, Engineering and Information Technology,
13(2), 794–800.
https://doi.org/10.18517/ijaseit.13.2.16468
BPS - Statistics Indonesia. (2024). Produksi Tanaman
Sayuran - Tabel Statistik - Badan Pusat Statistik
Indonesia. https://www.bps.go.id/id/statistics-
table/2/NjEjMg==/produksi-tanaman-sayuran.html
Chen, L., Chu, X., Zhang, X., & Sun, J. (2022). Simple
Baselines for Image Restoration. Lecture Notes in
Computer Science (Including Subseries Lecture Notes
in Artificial Intelligence and Lecture Notes in
Bioinformatics), 13667 LNCS, 17–33.
https://doi.org/10.1007/978-3-031-20071-7_2
Gao, S. (2022). Research on detection method of sprouted
potato based on SVM and weighted Euclidean distance.
6th International Conference on Mechatronics and
Intelligent Robotics, 92.
https://doi.org/10.1117/12.2644666
Genze, N., Wirth, M., Schreiner, C., Ajekwe, R., Grieb, M.,
& Grimm, D. G. (2023). Improved weed segmentation
in UAV imagery of sorghum fields with a combined
deblurring segmentation model. Plant Methods, 19(1).
https://doi.org/10.1186/S13007-023-01060-8
Huihui, Y., Daoliang, L., & Yingyi, C. (2023). A state-of-
the-art review of image motion deblurring techniques in
precision agriculture. Heliyon, 9(6).
https://doi.org/10.1016/j.heliyon.2023.e17332
Jocher, G., Chaurasia, A., & Qiu, J. (2023). Ultralytics
yolov8.
Jocher, G., Qiu, J., & Chaurasia, A. (2024). Ultralytics
yolo11. GitHub Repository.
Li, Y., Zhao, Q., Zhang, Z., Liu, J., & Fang, J. (2025a).
Detection of Seed Potato Sprouts Based on Improved
YOLOv8 Algorithm. Agriculture 2025, Vol. 15, Page
1015, 15(9), 1015.
https://doi.org/10.3390/AGRICULTURE15091015
Li, Y., Zhao, Q., Zhang, Z., Liu, J., & Fang, J. (2025b).
Detection of Seed Potato Sprouts Based on Improved
YOLOv8 Algorithm. Agriculture (Switzerland), 15(9).
https://doi.org/10.3390/agriculture15091015
Maruzuki, M. I. F., Osman, M. K., Shafie, A. S., Setumin,
S., Ibrahim, A., Saleh, H. M., Tahir, M. S. M., &
Rabiain, A. H. (2024). Road Image Deblurring with
Nonlinear Activation Free Network. 14th IEEE
International Conference on Control System,
Computing and Engineering, ICCSCE 2024 -
Proceedings, 288–293.
https://doi.org/10.1109/ICCSCE61582.2024.10696495
Qiu, Z., Wang, W., Jin, X., Wang, F., He, Z., Ji, J., & Jin,
S. (2024). DCS-YOLOv5s: A Lightweight Algorithm
for Multi-Target Recognition of Potato Seed Potatoes
Based on YOLOv5s. In Agronomy (Vol. 14, Issue 11).
https://doi.org/10.3390/agronomy14112558
Zhao, Y., & Jiang, Z. (2025). YOLO-WWBi: An Optimized
YOLO11 Algorithm for PCB Defect Detection. IEEE
Access
, 13(May), 74288–74297.
https://doi.org/10.1109/ACCESS.2025.3564734
Zikra, A. A., Ilham, A. A., Nurtanio, I., & Saptadi, N. T. S.
(2023). Multi Detection and Segmentation Coconut
Shell for Charcoal Briquette Using Mask R-CNN. 2023
International Seminar on Intelligent Technology and Its
Applications: Leveraging Intelligent Systems to
Achieve Sustainable Development Goals, ISITIA 2023 -
Proceeding, c, 615–620.
https://doi.org/10.1109/ISITIA59021.2023.10221025
RITECH 2025 - The International Conference on Research and Innovations in Information and Engineering Technology
24
