
AI-Driven Emotional Intelligence
Shirley Selvan, M Apoorvan and Alan A Aloysius
Department of Electronics and Communication Engineering, St Joseph’s College of Engineering Chennai,
Tamil Nadu, India
Keywords: Mental Health, Artificial Intelligence, Intervention, Accessibility, Emotion Analysis, Counseling,
Well-Being.
Abstract: This research brings to the forefront the potential for transformative use of Artificial Intelligence (AI)
techniques, specifically Natural Language Processing (NLP), in the augmentation of mental health care
services. Mental health disorders, including conditions of stress, depression, and anxiety, are widespread
across the world, but the availability of proper care and interventions is mostly suboptimal. With the use of
frontier advances in AI and NLP, this research suggests a new paradigm for addressing this gap through the
creation of intelligent systems capable of comprehending and responding to human expression in the area of
mental health. Through the processing of text-based data from sources like social media, chat records, and
self-reporting measures, AI-supported natural language processing (NLP) systems are capable of identifying
useful information regarding individuals' emotional states, cognitive patterns, and behavioral tendencies. Such
information can be used for the creation of personalized interventions like crisis management chatbots, mood-
tracking systems, and virtual counseling services. With its capability for timely and personalized assistance,
this AI-based model has the potential to revolutionize mental health services to make them more accessible,
affordable, and inclusive for global populations.
1 INTRODUCTION
As mental health issues become increasingly
important aspects of overall well-being, the demand
for new solutions to deliver effective care and support
has expanded exponentially. "Revolutionizing
Mental Health with AI and Natural Language
Processing" is a bold effort to harness the potential of
Artificial Intelligence (AI) and Natural Language
Processing (NLP) to revolutionize the mental health
care sector. Mental health disorders like depression,
stress, and anxiety afflict millions of people across the
globe, often resulting in severe personal and societal
issues. (Sutskever et al.2014). Conventional methods
of diagnosing and treating mental health can be time-
consuming and may not always provide timely or
effective solutions to the concerned individuals. This
project overcomes (O. Vinyals and Q. Le, 2015).
these limitations by using sophisticated NLP methods
to analyze and interpret human language, deriving
actionable insights into mental health issues, and
facilitating timely support (V. Serban et al. 2016). By
combining cutting-edge AI technologies, the project
seeks to create tools to quantify emotional health,
identify patterns characteristic of psychological
issues, and offer personalized advice or interventions
(J. Li et al. 2015). By leveraging the state-of-the-art
capabilities of NLP, these tools are intended to
improve the accuracy and accessibility of mental
health diagnostics and services, facilitating a more
responsive and dynamic mental health ecosystem (C.
Xing et al. 2017). This project combines cutting-edge
AI innovation with a user-centered design
philosophy, ensuring solutions are not only
scientifically sound but also empathetic and intuitive
(T. Zhao et al.2017). It is a significant leap forward in
enhancing the accessibility, personalization, and
effectiveness of mental health support, demonstrating
the potential of technology to improve global mental
well-being (H. Zhou et al.2018).
The relationship between the family and
individual characteristics, both socioeconomic and
demographic, and their physical and mental well-
being has been the focus of extensive studies in many
fields, such as data science, medicine, and public
health. The research offers outstanding insight into
determinants of well-being and informs intervention.
But the incorporation of other forms of data, i.e.,
Selvan, S., Apoorvan, M. and Aloysius, A. A.
AI-Driven Emotional Intelligence.
DOI: 10.5220/0013926600004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 5, pages
273-281
ISBN: 978-989-758-777-1
Proceedings Copyright © 2026 by SCITEPRESS – Science and Technology Publications, Lda.
273

mobility data (obtained from sensor-based activity
tracking) and contextual data (related to background
data) makes it more complex as it involves an
enormous amount, uncertainty, and data complexity.
Conventional approaches, including hypothesis-
driven statistical modeling and machine learning, are
generally not able to capture the intricate
interdependence of multimodal features and
multidimensional health measures. To address these
shortcomings, we present HealthPrism, an interactive
system that combines multimodal learning with a
gating mechanism for identifying health profiles and
comparing the relative significance of cross-modal
features, with further support through visualization
tools for exploratory analysis of complex datasets. It
was developed via systematic review of the literature
and expert consultation to better understand the
effects of contextual and motion information on
children's health. Nevertheless, despite its strengths,
it has limitations such as reduced coverage of
physical and mental health, absence of chatbot
capabilities, data integration problems, and
computationally intensive requirements.
The suggested solution is designed to foster
emotional well-being through artificial intelligence-
powered Natural Language Processing (NLP) based
on the Multi-Layer Perceptron (MLP) architecture.
The system is designed to offer personalized and
accessible care to those in need of mental health care.
Through NLP, the system is able to read and process
natural language inputs—such as text-based dialogue,
journaling, or social media updates—to evaluate
users' emotional state, concerns, and needs. The MLP
architecture is the core component for evaluating and
interpreting this text-based information, identifying
meaningful patterns, and offering personalized
feedback or recommendations in line with each
individual's mental wellness journey. Through
continuous adaptation and learning, the system
evolves to meet users' changing needs, establishing a
nurturing and supportive virtual environment for
mental health care. The key strengths are the
development of a Chatbot platform, cross-lifestyle
applicability, improved scalability, and faster
processing, making it a stable and efficient solution
for personalized mental health care.
2 RELATED WORKS
(Sutskever et al.2014) proposes that the prevalence of
mental illness and addiction disorders among adults
and children is evidence of a considerable emotional
as well as financial burden on individuals, families,
and society as a whole. The economic impact due to
mental illness affects individual earnings, the
continuity of employment of individuals with mental
illnesses and sometimes the caregivers as well—and
workplace productivity, national economic health,
and healthcare as well as helping services demand.
O. Vinyals (2015) reports that in industrial
nations, mental illness is estimated to account for 3%
to 4% of the Gross National Product (GNP). The total
economic burden to national economies is worth
billions of dollars when direct expenditures and loss
of productivity are accounted for. Depressed workers,
for instance, have medical, pharmaceutical, and
disability costs which can be as high as 4.2 times
higher compared to a typical worker. Still, such
medical costs are often offset by diminished
absenteeism and increased workplace efficiency.
V. Serban et al. 2016 contends that most of the
population in the world has access to the internet
nowadays, and access to the internet is almost
universal in the OECD countries (Echazarra, 2018).
Access to the internet and the use of social media are
a norm in the life of teenagers. As of 2015, the
average
J. Li and M. Galley 2015 talk about growing
reliance on digital technology, which has raised
concern among parents, educators, government, and
even young people themselves. These concerns are
based on the belief that social media and online sites
are fueling increased anxiety and depression,
interfering with sleep, promoting cyberbullying, and
altering body image expectations. In response to these
concerns, some nations are legislating, such as South
Korea's legislation that restricts children's
participation in online gaming between the hours of
midnight and 6 a.m. without parental consent, and the
UK government's ongoing inquiry into the effects of
social media on children's wellbeing and the
development of guidelines for screen time
restrictions.
C. Xing 2017 posits that the impact of mental
health on the academic performance of students is a
complicated issue with severe implications. Research
continuously identifies that mental health is one of the
determinants of the academic performance of
students, affecting cognitive functioning, emotional
stability, and general interest in study content. Mental
health disorders such as depression and anxiety can
impair concentration, interfere with memory, and
affect problem-solving skills, thereby interfering with
the learning process.
T. Zhao 2017 is of the opinion that the given
conditions can be blamed for impaired academic
performance, higher absenteeism, and difficulty
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
274

managing academic stressors. Mental health needs to
be prioritized in schools so that a learning
environment can be fostered that enables academic
achievement as well as overall wellness.
Incorporation of mental health services within
schools can go a long way in enabling students to
succeed and become resilient in the long run.
H. Zhou 2018 argues that the psychological
welfare of adolescents is now a matter of public
concern, especially against the backdrop of the rising
occurrence of mental disorders among them. Even in
those countries with a well-developed healthcare
system, a substantial number of youths avoid seeking
assistance for their mental health problems. The
research sought to answer two key aims: critically
appraise literature on young people's experiences
after seeking help for mental health concerns and
explore the viability of the "Lost in Space" model as
a fitting theoretical framework for the help-seeking
process. Scoping review was conducted, using studies
between the years 2010 and 2020 from different
databases. Out of 2,905 studies, 12 papers were
selected to be reviewed. Results showed that youths
often feel insecurity and uncertainty over mental
health matters and the process of seeking help.
N. Asghar et al. 2018 recognizes a high desire for
autonomy and independence, because many of them
found support systems either unobtainable or
insufficient. In addition, the review confirmed that the
process of seeking help is dynamic and psychosocial,
as specified by the model.
Wang W. Y. 2017 argues that all individuals have
the right to participate in meaningful and equitable
employment in an environment that promotes
freedom, equality, security, and dignity. For
individuals with mental illness, the realization of this
right is usually particularly difficult. The ILO
Convention on Vocational Rehabilitation and job of
Disabled Persons No. 159 (1983) codifies the
organization's policy on disability issues and places a
strong emphasis on equitable job opportunities and
the non-discrimination principle for people with
impairments.
M. Peters et al. 2017 claims that a person whose
capacity to obtain, hold, and progress in appropriate
employment is significantly hampered by a
recognized physical or mental handicap is considered
a disabled person under the convention.
Cho et al. 2014 introduces the encoder-decoder
recurrent neural network (RNN) architecture, which
served as the foundation for natural language
processing (NLP) sequence-to-sequence models.
Through input sequence mapping to a fixed-size
vector and subsequent decoding into an output
sequence, the approach effectively tackles statistical
machine translation (SMT) difficulties. Furthermore,
it demonstrated the advantage of co-training the
encoder and decoder, which results in improved
phrase representations.
Bahdanau et al. 2014 includes the attention
mechanism, which enables the model to generate
each element of the output sequence by selectively
attending to portions of the input sequence. This
innovation marked a significant shift from neural
machine translation (NMT) and improved
performance on longer sequences by reducing the
limitation with fixed-size encoding.
Fang et al. 2015 suggests the relationship between
picture captioning and the creation of visual concepts.
They closed the gap between vision and language by
combining recurrent neural networks (RNNs) for
language modeling with convolutional neural
networks (CNNs) for visual feature extraction. Their
research had broad ramifications for tasks such as
visual question answering (VQA) and image
description.
Vaswani et al. 2017 presents the transformer
model, which replaced recurrent models with the use
of self-attention mechanisms. The groundbreaking
architecture significantly reduced training times and
improved scalability. As a result, transformers paved
the way for high-end NLP models like BERT, GPT,
and others, revolutionizing the deep learning space.
Hochreiter and Schmidhuber et al. 1997 introduce
Long Short-Term Memory (LSTM) networks, which
solved the vanishing gradient issue of the standard
RNNs. With the introduction of memory cells and
gates, LSTMs made it possible to learn long-distance
dependencies in sequence data. They are still
employed in time-series analysis, speech recognition,
and NLP applications.
3 METHODOLOGY
3.1 Emotion Detection Using NLTK
The initial step of emotion analysis and pre-
processing of the text is done using the Natural
Language Toolkit (NLTK). The approach begins with
text pre-processing, involving various techniques like
lemmatization, tokenization, and removal of stop-
words. Tokenization simplifies the analysis by
breaking the raw text into separate words or
sentences. Stop-word removal eliminates very
frequent, less helpful words like "the" and "and" that
are of no use in the detection of emotions.
Lemmatization reduces words to their root form,
AI-Driven Emotional Intelligence
275

thereby making it consistent and enhancing the
accuracy of the analysis to be done subsequently.
Once the pre-processing is done, NLTK applies
lexicon-based techniques to identify emotions. This is
achieved by employing external resources like the
NRC Emotion Lexicon to transform textual words
into predefined emotion sets. The words are matched
against respective emotions like happiness, sadness,
or anger, and the total emotional polarity of the text is
calculated by summing all identified emotions. Apart
from that, sentiment analysis is also done using
NLTK's VADER (Valence Aware Dictionary and
Sentiment Reasoned) tool. VADER assigns polarity
scores (positive, negative, or neutral) to the text,
which are further translated to emotions like
happiness or sadness. Finally, NLTK enhances the
understanding of the emotional content of the text by
calculating emotion scores based on the frequency of
emotion words and analyzing their significance in
context.
3.2 Machine Learning Support for
Emotion Detection
Machine learning enhances the capability of NLTK
by offering more advanced and precise emotion
detection through data-driven techniques. After
NLTK pre-processes the text, it is transformed into
numerical features that are then fed into machine
learning algorithms. TF-IDF (Term Frequency-
Inverse Document Frequency), Bag-of-Words
(BoW), and word embeddings (e.g., Word2Vec and
GloVe) are some of the methods used for text
representation. These methods make the semantic
linkages between words obvious while allowing the
text's emotional component to be encoded. Cutting-
edge models like as BERT (Bidirectional Encoder
Representations from Transformers) and GPT
(Generative Pretrained Transformers) are used to
build contextual word embeddings because they are
able to comprehend the fine-grained semantics of text
based on its contextual environment. Labeled datasets
are used to train supervised machine learning models
for emotion categorization once the text has been
converted to feature vectors. Algorithms like Naive
Bayes, Support Vector Machines (SVM), and
Logistic Regression are frequently used to estimate
the text's emotional tone. Furthermore, emotion
detection makes advantage of deep learning
frameworks, which can recognize intricate patterns
and connections in sequential data. Recurrent neural
networks (RNNs), transformers, and Long Short-
Term Memory (LSTM) networks are the most well-
known types of these architectures. These structures
improve the effectiveness of emotion recognition by
utilizing long-range dependencies and contextual
information that are not represented by simpler
models. To make them accurate, these models are
trained and tuned with emotion-labeled datasets, and
evaluation metrics like accuracy, precision, recall,
and F1-score are used to measure their performance.
3.3 Integration of NLTK and Machine
Learning for Emotion Detection
The combination of machine learning with NLTK
offers a robust and integrated solution to emotion
detection in text. NLTK performs a number of basic
operations such as tokenization, removal of stop
words, lemmatization, and initial emotion detection
using lexicon-based methods. Machine learning
models are utilized to augment this initial evaluation
by identifying and classifying emotions according to
patterns in pre-processed input. NLTK's output, i.e.,
sentiment score and word frequency of words
corresponding to certain emotions, is also used as a
rich source of input for machine learning models.
Using these, a variety of machine learning models
ranging from deep architectures such as LSTMs and
BERT to baseline classifiers such as Naive Bayes and
SVM are trained to output predictions on emotional
responses. This combination also facilitates the
detection of subtle patterns and contexts that may not
be identifiable by the lexicon-based approaches,
further increasing the accuracy of emotion
classification. A feedback loop is also established
through which detection of errors or
misclassifications by the machine learning models
lends itself to optimization in the pre-processing
stage. The output by the machine learning models is
also used to augment tokenization, improve the
emotional vocabulary, or update the stop word lists.
Through this loop, not only are the machine learning
frameworks optimized but also the pre-processing
techniques of NLTK are made more robust,
eventually leading to better end-to-end performance.
The combined system is also able to handle all
varieties of text inputs and rich emotional subtleties,
leveraging the strengths of both approaches to
produce accurate, scalable, and robust emotion
detection.
4 BLOCK DIAGRAMS
In Python machine learning, structuring the
framework consists of creating a robust and malleable
infrastructure to execute models and algorithms. It
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
276

entails focusing on cleaning data, algorithm selection,
and adjustment techniques, all with an eye towards
creating malleable and scalable code to facilitate easy
testing and deployment under real-world situations.
Figure 1: Block diagram of emotion detection using
machine learning.
• User: In Figure 1, User interacts with the
Chatbot using text or voice input. That
interaction serves as the system access point
where the User instruction or query is processed
via the Chatbot.
• Messenger: Shown in Figure 1, the Messenger
is an intermediary that enables the passing of
user input to the backend of the Chatbot and
sends forward the responses. This could be a
messaging application, Chatbot interface, or
web API.
• Natural Language Processing: As shown in
Figure 1, the Natural Language Processing
(NLP) module processes the user input by
parsing and understanding the text information.
This involves a range of sub-tasks such as
tokenization, syntactic parsing, intent detection,
and semantic analysis.
• Information Sources: Information Sources is
shown in Figure 1 as a knowledge base
repository that the Chatbot refers to in order to
provide accurate answers. The information
sources are user inputs, databases, and APIs,
which the Chatbot gets the information needed
to provide informative responses.
• Chatbot Logic: As shown in Figure 1, the
Chatbot Logic determines the system's output
by combining processed input from Natural
Language Processing (NLP) with information
from different information repositories. It uses
known rules, algorithms, or machine learning
models to generate responses that are both
meaningful and contextually appropriate.
• Machine Learning: Figure 1 illustrates how the
Machine Learning module accentuates the
feature of the system to learn to perform better
in the future from its past experiences.
Techniques like supervised learning,
reinforcement learning, and feedback are used
by the Chatbot to improve its output.
Architecture defines the end-to-end process of the
Chatbot system: user input is sent through the
messenger layer, processed by the NLP unit, and
interpreted into data from pre-determined sources.
Chatbot logic involves a response, and machine
learning allows the system to get better on a
continuous basis. The end-to-end architecture allows
the Chatbot to deliver correct, dynamic, and user-
relevant information.
5 MODULE DESCRIPTION
5.1 Data Pre-Processing
In machine learning, validation techniques are used to
estimate the model's error rate in an attempt to closely
approximate the dataset's real error rate. These
methods might not be required if the dataset is sizable
and representative of the general population.
Validation approaches are required in the real world
since sample data could not be representative of the
entire population. These techniques assist in the
detection of missing values, elimination of duplicate
values, and checking for correct classification of data
types (e.g., float or integer). A validation set offers an
objective assessment of a model learned from the
training data while adjusting its hyperparameters. The
more the model design relies on the validation set, the
more the evaluation becomes subjective. The
validation set is typically used for testing and assists
machine learning engineers in adjusting the model's
hyperparameters. Acquiring, checking, and
correcting content, quality, and structure issues may
take time. Having a clear understanding of the data
and its nature while identifying enables one to select
the most suitable algorithms in developing a model.
5.1.1 Algorithm Implementation
The steps in implementing the algorithm are as follows:
• Use scikit-learn and Python to design a testing
platform that will allow different machine learning
methods to be compared.
• Add different machine learning models into the
framework such that new methods of analysis can be
incorporated.
AI-Driven Emotional Intelligence
277

• Preprocess the dataset by systematically dividing it
and normalizing it for every model.
• Employ resampling techniques to provide predictions
of model performance on novel data, e.g., cross-
validation.
• Employ a variety of methodologies to graph the data
and conduct analyses from various points of view to
aid in model selection.
• Evaluate models using different measures, such as
accuracy and variance, and also in addition to giving
the distribution of accuracy and other statistical
properties.
• Use the same dataset and evaluation procedures for
all models in the same parameters to maintain
consistency.
• Choose the best model by comparison analysis and
visual evaluation.
• The entire process is methodically implemented in
Python using the Scikit-learn library to enable
effective implementation in actual situations.
5.2 Multi-Layer Perceptron
(Feed-Forward Neural Network)
A feedforward neural network, often known as a
Multi-Layer Perceptron (MLP), is a basic artificial
neural network model. It consists of an input layer, a
few hidden layers, and an output layer. All of the
neurons in each layer are connected to all of the other
neurons in the same layer, and the data only flows in
one direction. Figure 2 depicts the design of a Multi-
Layer Perceptron (MLP), including the data flow and
crucial elements such as the activation functions and
weights. Each connection between the layers of
neurons has a weight, which is tuned throughout
training. The rectified linear unit (ReLU) and other
non-linear activation functions add complexity,
allowing the model to pick up on minute subtleties in
the pattern. Dropout layers are often used to prevent
overfitting by randomly disabling some of the
neurons during training. MLPs are very versatile and
have applications in every field, like image
recognition, text, and regression problems. In order to
minimize the specified loss function, the MLP is
trained by varying the weights using methods such as
stochastic gradient descent. The output layer often
uses the softmax activation function to provide a
probability distribution across many classes in
classification issues. MLPs are a fundamental
component of more complex neural network models
because of their effectiveness and simplicity. The
neural network probably fires the "POSITIVE"
output if the input is "HAPPY," with a corresponding
happy output. The neural network triggers a
reassuring or sympathetic output if the input is "SAD"
by enabling the SUPPORTIVE output. The neural
network OBJECTIVE or SUPPORTIVE output fires
if the input is "ANGRY" to relax tension or produce
a neutral output. The SUPPORTIVE output of the
neural network giving soothing or reassuring
responses, is called whenever the input is "FEAR".
Figure 2: Multi-Layer Perceptron.
5.3 Natural Language Tool Kit
(NLTK)
The NLTK is a Python library that has been
developed with the aim of supporting an array of
functions for natural language processing (NLP). It
provides an extensive array of text-processing tools in
addition to a complete array of example datasets.
Figure 3 depicts the structure of NLTK, along with
the interactions between its modules in order to attain
varied NLP tasks. NLTK allows users to perform an
array of NLP operations, including tokenization,
parsing tree visualization, and other similar tasks. In
the following article, instructions on the installation
of NLTK on your system and how to make use of its
features effectively for the execution of an array of
NLP operations in the text analysis process are
provided.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
278
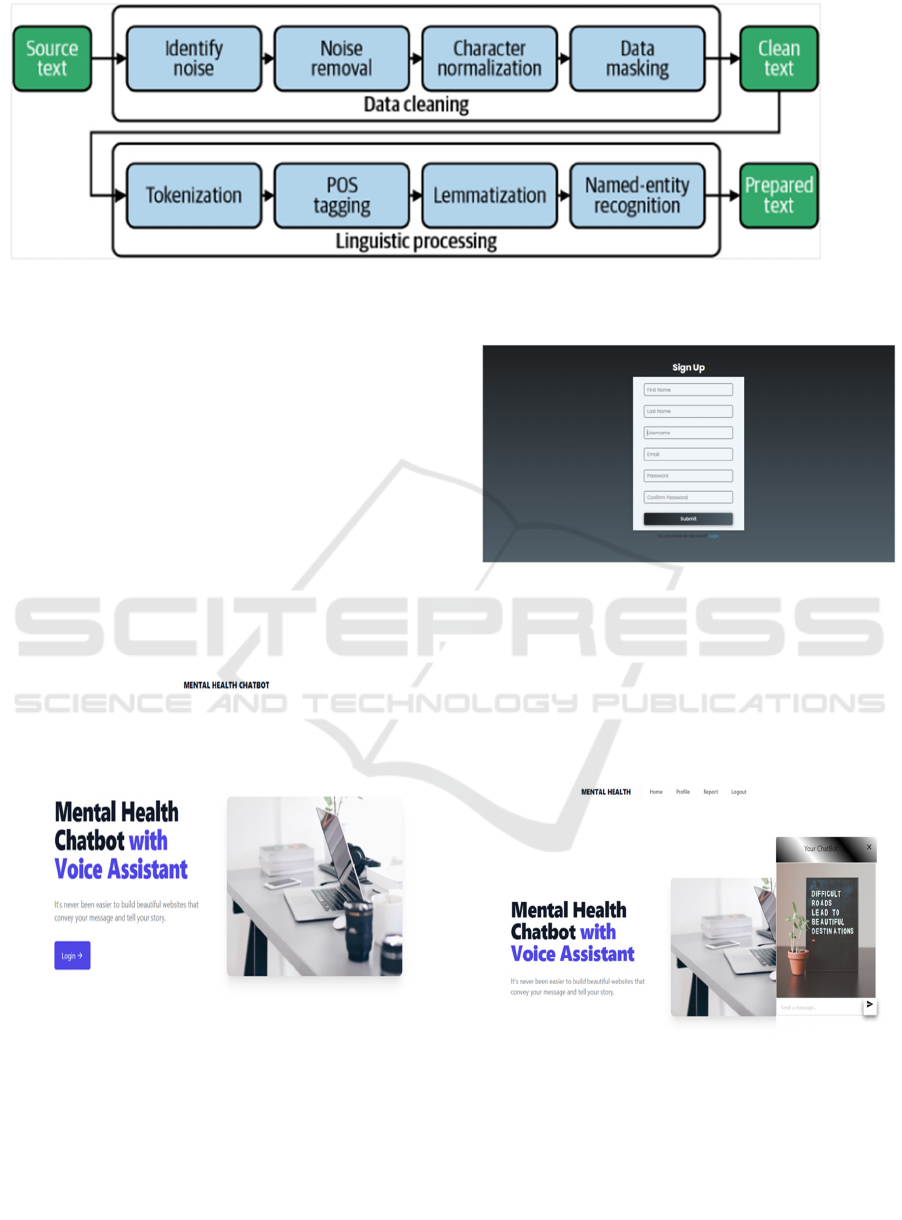
Figure 3: Natural Language Tool Kit (NLTK).
6 RESULTS AND DISCUSSION
6.1 Webpage
The result of the project is evidenced here, presenting
the Mental Health Chatbot with Voice Assistant's
user interface and functionality:
Figure 4 depicts the homepage upon which the
users use to begin engaging with the chatbot. The
name "Mental Health Chatbot with Voice Assistant"
is highly visible, and the user interface is simple and
clean. The users can activate the features of the
system with the login facility.
Figure 4: Home Page of website.
Figure 5 depicts the registration page designed for
new users to create an account. It contains spaces
where users can input personal information, including
the name, email address, and password. This will
ensure it is safe for users to communicate with the
chatbot and customized based on their requirements.
Figure 5: Register Page of website.
Figure 6 reflects that the users are redirected to the
landing page after successful registration or login.
The page summarizes the features of the chatbot,
including voice interaction and mental health
resource lookup. The arrangement should be eye-
catching as well as easy to use.
Figure 6: Landing Page of website.
The output page, which is presented in Figure 7,
is an illustration of the capability of the chatbot to
generate responses to the questions posed by users.
The responses' grammar is proof of the capability of
the chatbot to respond to questions posed by users.
AI-Driven Emotional Intelligence
279

Figure 7: Output Page of website.
6.2 Testing the bot in real time
Step 1 - Go to the home page of the website
Step 2 - User should register their information in the
registration page.
Step 3 – After successful registration, the user can
access the chat interface.
Step 4 – The user enters the desired Pattern.
Step 5 – After processing the queries, it provides the
accurate responses according to the message
If the user gives the pattern: “Ways to cope with
depression”,
It checks for the necessary tag and gives the
response:” Coping strategies for mental health
include relaxation techniques like deep breathing and
meditation, engaging in physical activity,
maintaining a routine, and practicing positive self-
talk. Other coping mechanisms include journaling,
spending time with supportive people, seeking
professional help, and finding creative outlets for
expression. It's important to experiment with different
strategies and find what works best for you.”
6.3 Performance Analysis of the
Chatbot
Table 1: Accuracy of Response Detection for Mental
Health-Related Tags.
Tags
No. of
Patterns
No. of
Correctly
detected
responses
Accuracy
Stress
management
5 5
5/5 X
100 =
100%
Mental
Health in
Work Place
5 5
5/5 X
100
= 100%
We have tested 16 Tags with 5 patterns in each. To
know the performance of the chatbot, we have
displayed two tags in which every one of the tags has
5 Patterns. By testing the 5 patterns, we will obtain
the same responses from each pattern under each tag.
Here the tags are Stress management and mental
health in workplace. So, after testing the patterns of
these tags, I obtained the desired results with 100%
accuracy. Table 1 Shows the Accuracy of Response
Detection for Mental Health-Related Tags.
7 FUTURE SCOPE
Emerging trends must be directed towards the
cultivation of emotional intelligence among AI-
powered chatbots. Through improved natural
language processing and emotional recognition, the
chatbots will be in a position to better read and
respond to students' emotional signals, hence offering
more tailored and empathetic support. Proactive
machine learning-driven systems have the potential to
identify early warning signs of emotional distress and
provide instant mental health intervention. There
must also be addressing of privacy and consent
concerns to establish trust in these AI systems. Lastly,
the incorporation of emotional intelligence in AI can
potentially improve students' academic performance
and emotional resilience substantially.
8 CONCLUSIONS
Overall, the use of artificial intelligence and Natural
Language Processing (NLP) for enhanced
psychological well-being is a groundbreaking
advancement in mental health care. By processing
large volumes of text data, NLP models are capable
of identifying trends and indications of mental health
disorders such as anxiety, depression, and stress with
remarkable precision. Such technology enables the
prospect of early intervention and tailor-made
treatment, leading to optimized and targeted
treatment plans. On top of this, NLP-enabled tools
enable continuous support and surveillance, defying
the confines of traditional care systems and opening
mental health support up to around-the-clock
convenience and flexibility. With further
advancement in these technologies, they stand poised
to fundamentally shift our vision of mental well-
being, creating proactive, bespoke, and omnipresent
mental health support.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
280

REFERENCES
I. Sutskever, O. Vinyals, and Q. V. Le, ‘‘Sequence to
sequence learning with neural networks,’’ in Proc. Adv.
Neural Inf. Process. Syst., 2014, pp. 3104–3112.
O. Vinyals and Q. Le, ‘‘A neural conversational model,’’
2015, arXiv:1506.05869. [Online].
I. V. Serban, A. Sordoni, Y. Bengio, A. C. Courville, and J.
Pineau, ‘‘Building end-to-end dialogue systems using
generative hierarchical neural network models,’’ in
Proc. AAAI, vol. 16, 2016, pp. 3776–3784.
J. Li, M. Galley, C. Brockett, J. Gao, and B. Dolan, ‘‘A
diversity promoting objective function for neural
conversation models,’’ 2015, arXiv:1510.03055.
[Online].
C. Xing, W. Wu, Y. Wu, J. Liu, Y. Huang, M. Zhou, and
W. Y. Ma, ‘‘Topic aware neural response generation,’’
in Proc. AAAI, vol. 17, Feb. 2017, pp. 3351–3357.
T. Zhao, R. Zhao, and M. Eskenazi, ‘‘Learning discourse-
level diversity for neural dialog models using
conditional variational auto encoders,’’ 2017,
arXiv:1703.10960. [Online].
H. Zhou, M. Huang, T. Zhang, X. Zhu, and B. Liu,
‘‘Emotional chatting machine: Emotional conversation
generation with internal and external memory,’’ in
Proc. 32nd AAAI Conf. Artif. Intell., Apr. 2018, pp. 1–
25s.
N. Asghar, P. Poupart, J. Hoey, X. Jiang, and L. Mou,
‘‘Affective neural response generation,’’ in Proc. Eur.
Conf. Inf. Retr., 2018, pp. 154–166
X. Zhou and W. Y. Wang, ‘‘Mojitalk: Generating
emotional responses at scale,’’ 2017,
arXiv:1711.04090. [Online].
M. Peters, W. Ammar, C. Bhagavatula, and R. Power,
‘‘Semi-supervised sequence tagging with bidirectional
language models,’’ in Proc. 55th Annu. Meeting Assoc.
Comput. Linguistics, vol. 1, 2017, pp. 1756–1765.
K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F.
Bougares, H. Schwenk, and Y. Bengio, ‘‘Learning
phrase representations using RNN encoder-decoder for
statistical machine translation,’’ 2014,
arXiv:1406.1078. [Online].
D. Bahdanau, K. Cho, and Y. Bengio, ‘‘Neural machine
translation by jointly learning to align and translate,’’
2014, arXiv:1409.0473. [Online].
H. Fang et al., ‘‘From captions to visual concepts and
back,’’ in Proc. IEEE Conf. Comput. Vis. Pattern
Recognit. (CVPR), 2015, pp. 1473–1482.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones,
A. N. Gomez, Ł. Kaiser, and I. Polosukhin, ‘‘Attention
is all you need,’’ in Proc. Adv. Neural Inf. Process.
Syst., 2017, pp. 5998–6008.
S. Hochreiter and J. Schmidhuber, ‘‘Long short-term
memory,’’ Neural Comput., vol. 9, no. 8, pp. 1735–
1780, 1997.
AI-Driven Emotional Intelligence
281
