
MemeCheck: Automated Meme Analysis for Identifying Offensive
Text and Visuals
Jaganath M., Jothika R., Keerthika S., Pranishka N. and Vinoharsitha A. S.
Department of Artificial Intelligence, M. Kumarasamy College of Engineering, Karur, Tamil Nadu, India
Keywords: CNN, Deep Learning, Meme Sentiment Analysis, OCR, Offensive Content Detection, VADER.
Abstract: As a model that has emerged as a key aspect in the field and foundation of discovering Human emotions and
sentiment in the digital world. Given that memes are much meme owe popular than smoke signals, they seem
to cover most feelings in a funky pictoral way. The popularity of multimodal content, which often involves
combining text with images, has also been the subject of much scrutiny in online communication for the
potential amplification of hateful and damaging content. In such a regard, this study introduces a brand-new
method for branded offensive memes classification relying on deep learning strategies to deal with multimodal
datasets. To accurate identify and categorise inappropriate contents. It is crucial to conduct analysis both
textual and visual components. In this study, we propose a novel approach for sentiment analysis from meme
images using Optical Character Recognition (OCR) technology combined with deep learning algorithms for
text classification and image classification. Our method consists of performing OCR on meme images to
extract text content for dissection in textual analysis and drawing inferences for sentiment induction. The
analyzed text, utilizing VADER and NLP, takes the next step by deducing sentiments based on the recognized
text. The same results are used to take detects any kind of offensive content from annoyingly unwanted images
through a Sequential CNN model. This very particular CNN was modelled and has been trained from scratch
for the accuracy of classifying offensive images and enhancing the solution of recognizing inappropriate
visual content. With this novel multimodal technique, detection of offensive content from text and image is
done efficiently, providing a safer and more responsible platform in social networking. The proposed
methodology shows good promise in introducing an effective OCR-driven VADER sentiment analysis and
performing Sequential CNN-based image classification for both the identification and control of offensive
content on social networks.
1 INTRODUCTION
The rise in social-media users for the last few years
has been driven by the avail and accessibility of
Internet. Individuals-too-many in number-are also
becoming as vocal-wanting to have their considerable
audience. A person and society have the possibility to
be swayed by any one social media post. As with
many times, the Muslim Association of Canada states
that a Facebook post resulted in riots and hate crimes
directed against the Muslim group. A social media
meme can get people into depression and even
suicidal thoughts. A meme has been a favourite
means of giving opinions over social media in the
recent, modern world. A meme-something amusingly
silly, be it a funny image, clip, or phrase. It moves fast
from internet user to internet user, often unchanged.
Memes are a way of conveying the views and feelings
of a given audience, although social media is a
gigantic medium of communication. A meme may be
termed offensive to someone who has been or is
infuriated, annoyed, or made other people feel bad.
Memes are evidently considered offensive when the
attack is directed or targeted at societal concepts,
events, or cultural icons through incisive criticism,
mostly aimed at minorities or homophobes. Memes
can also be used to convey political hatred. It is
widely recognized that memes will require a filter
before they really go viral. One method of analysing
this would be to manually track all memes that have
been posted, or are posting on social media in other
forms; however, it is not practically possible to
manually vet every meme. Done so, memes must be
discursively filtered before sunlight shares them, so
that fiery offensive content is quenched at source and
never gets further. Memes often have the picture on
676
M., J., R., J., S., K., N., P. and S., V. A.
MemeCheck: Automated Meme Analysis for Identifying Offensive Text and Visuals.
DOI: 10.5220/0013918900004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 4, pages
676-682
ISBN: 978-989-758-777-1
Proceedings Copyright © 2026 by SCITEPRESS – Science and Technology Publications, Lda.

which the text is overlaid. In other words, the memes
can also be seen as multimodal; therefore, it is not
always clear whether the offensive content is
attributed to the embedded text or the main image.
Different single modal waves of content can hardly
be singled out as offensive. Through very limited
observations of the image or the text, one cannot
discern and ascertain any offensiveness-but as the full
content is pieced together contextually, the entire
picture changes. In this light, the present study
attempts to delve into combining multimodal features
in analysing images-not simply extract such images
for analysis and treatment as offensive or non-
offensive cues. Offensive content can thus be
determined from both the text part and the unwanted
visual clues of the meme. Optical character
recognition was adapted to identify the text and a
sequential CNN had been used to classify images as
offensive or non-offensive. Examples of the offline
dataset are seen in Figure 1.
Figure 1: Dataset Images for memes.
2 RELATED WORK
(Rui Cao, etal, 2023) A suggested multimodal prompt-
based approach named PromptHate, which prompts
and takes advantage of the implicit knowledge of the
PLM to classify hateful memes. The extracted entities
and demographic data are the extra information that
will be added to the image captions as input for the
PLMs. It should be mentioned that although extracting
some relevant information regarding the meme from
the extracted supporting information, background
knowledge from the context is still lacking in the
image caption and supporting information. For
instance, while extracting an entity-from the image,
we can recognize a pig in the meme and extract the
word "Muslim" from the text of the meme. Yet,
contextual information/Muslims don't consume pork-
lacks in supplement data. It is a feasible cause that may
reasonably be, in the few-shot scenario, because
PromptHate is based more on meaning of label terms
for implicit knowledge extraction to sort out hateful
memes. Their conclusion is that label words with
semantics most similar to the semantic class will give
more context in the prompt for hateful meme
classification improvement when there are enough
few training instances. Alternatively, as more
instances are trained using PromptHate, i.e., one in
enough number, the word representations of the label
words have become increasingly similar to the hateful
meme classification task.
(Shardul Suryawanshi, et.al,2023) In the designing
process, a properly organized framework based on the
NLI task to transform the multi-modal tasks into
unimodal tasks is present here. The data first shifts
from an image-text-label format to a premise-
hypothesis-label format. The newly converted data is
utilized for fine-tuning three different pre-fine-tuned
models on Emotion Analysis, Sentiment Analysis,
Offensive Tweet Classification, and NLI task
respectively. Three ablations were performed for
every one of the models to comprehend their
behaviors appropriately. In addition, we present an
exhaustive quantitative and qualitative error analysis
of the task. The multi-modal state-of-the-art is highly
complicated and demands monstrous computing
characterization, approximately in millions of
trainable parameters. In addition, they ensemble
multiple VL models, which is practically infeasible
because these modes are difficult to deploy to real-
world scenarios. Thus, to simplify the solution and
make it more convenient, we would prefer to reduce
the multi-modal offensive meme classification task to
the unimodal offensive text classification task based
on the use of NLI tasks.
(Abhinav Kumar Thakur, et.al, 2023)
Investigating explainable multimodal approaches to
classifying instant messages. We employ the general
concept of Case-Based Reasoning (CBR), in which a
prediction could refer to similar memes that the
algorithm learned. Due to the nature of IMs being
complex, CBR is attractive since it is able to yield a
more explainable insight into the reasoning process of
the model while taking advantage of SOTA models'
ability to learn representations. An easy-to-use
interface is created that facilitates comparative
MemeCheck: Automated Meme Analysis for Identifying Offensive Text and Visuals
677

analysis across examples pulled through all our
models for any IM. The user interface will be utilized
to find various explainable models' ability in CBR to
pull useful instances and guide future work on the
strength and limitations of these approaches. The
neuro-symbolic approach would be employed with
explainable example- and prototype-based predictions
for IM classification tasks. A pre-trained model is
used, frozen, which feature extracts from a meme in a
transfer learning configuration with a distinct
downstream classification model making a final
decision based on the extracted features. The
modularity of the framework allows for ease in
comparing the pair-wise combination of the
explanation method and feature extraction model
employed.
(Biagio Grasso, et.al, 2024) demonstrate that the
capacity of KERMIT to learn context-dependent
information from ConceptNet and apply it to the task
of classification improves its performance.
Specifically, the proposed system achieves state-of-
the-art performance on the Facebook Hateful Memes
dataset and is comparable with the latest challengers
on all other datasets. Overall, the paper showcases the
significance of injecting external knowledge into the
process of classification and sets the door ajar for
potential future studies on meme harm detection,
exemplifying the massive scope of AI and knowledge
discovery to aid in moderation. Our KERMIT
framework thus uses a MANN to cache the
knowledge-enriched information graph representing
the entities of the meme and their associated
commonsense knowledge in ConceptNet. KERMIT's
memory block consists of several buckets, one with a
piece of the information network enhanced with
knowledge. In addition, KERMIT is burdened with
the weight of a learnable attention mechanism,
dependent on present input, the bucket(s) with enough
information to offer accurate classification of
hazardous memes. This enables our model to leverage
contextual information and applicable knowledge
from external sources to bypass content moderation on
posts by including external knowledge in the decision-
making process.
(Yang, Chuanpeng, et.al, 2025) ISM learns
modality-invariant and modality-specific
representations using graph neural networks that
complement the dual-stream models with the gap
bridged between them because ISM projects each
modality into two different spaces to retain different
features but merge the others to deal with the modality
gap. ISM uses state-of-the-art multi-modal dual-
stream models (e.g., CLIP, ALBEF and BLIP) as its
backbone, which is a testament to the scalability of
ISM. Based on experimental results, ISM outperforms
baselines and achieves competitive performance
compared to the state-of-the-art methods for toxic
meme detective. The functionality and effectiveness
of the components are also enhanced through ablation
and case studies. By filling the modality gap and
aligning image-text pairs, an ISM is proposed to be a
scalable malicious meme detection framework that
learns modality-specific and modality-invariant
representations through graph neural networks, finally
reaching a holistic and disentangled understanding of
memes.
3 BACKGROUND OF THE
WORK
Two essential natural language processing methods,
Count Vectorizer and TF-IDF, are essential for
obtaining significant characteristics from textual data
in the field of meme text classification. A collection
of text documents is mapped into a matrix form by
Count Vectorizer such that each document is
represented by a row and each vocabulary term is
represented by a column. The matrix contains
numbers representing the frequency of occurrence of
each word in the given document. As a result, every
document would be mapped to a vector such that the
entries represent the number of occurrences of each
word. But Count Vectorizer is not sophisticated in
determining the importance of words beyond
frequency. TF-IDF, by contrast, extends this by
including both the proportion of a term in a document
(Term Frequency) and how rare it is in the full corpus
(Inverse Document Frequency). This approach more
heavily weights the terms that have high frequency
within a document and low frequency overall in the
corpus, thus getting at their discrimination power.
Fundamentally, although Count Vectorizer
provides a straightforward representation by term
frequencies, TF-IDF provides a richer interpretation
by considering the importance of words within the
overall context of the corpus, thus rendering it very
valuable in memes text classification issues where it
is necessary to identify outstanding features for
accurate classification. Graph Neural Networks
(GNNs) offer a robust architecture for memes
classification by exploiting the inherent structure and
relationships of meme data. In memes classification,
A graph can be utilized to model the data, where
nodes are employed to denote items such as images,
text, or users, and edges denote relationships or
interactions among the items. GNNs can effectively
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
678
model and utilize these complex, interdependent
relationships to improve classification performance.
GNNs operate by iteratively aggregating information
from neighbouring nodes in the graph to update the
feature representation of each node. This allows
GNNs to learn both local and global dependencies
within the graph, enabling them to effectively capture
the semantics and context of meme data.
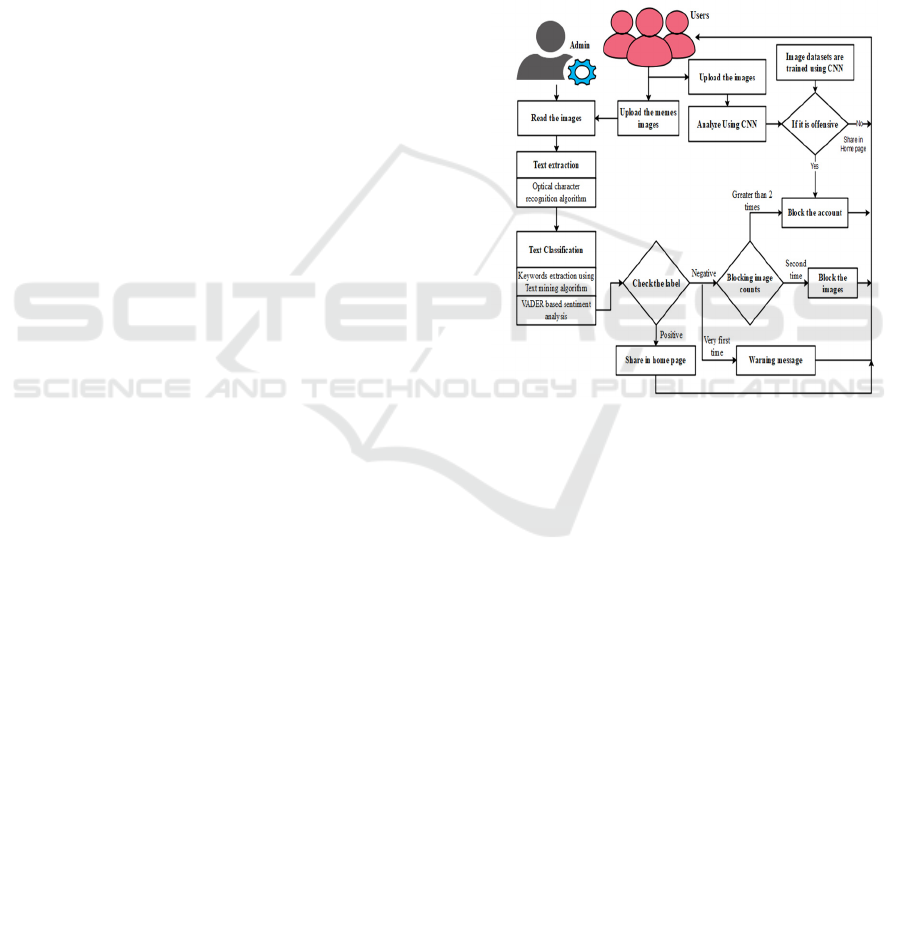
4 PROPOSED SYSTEM
The system will contain several unique elements
designed to effectively examine and classify memes.
First among those will be the process of collecting a
diverse dataset of labeled memes reflecting various
types of content. styles, and origins. That dataset is
what will serve as the very foundation for both
training and testing of the classification algorithm.
After assembling the dataset, the subsequent action
would be to apply the general framework of
classification to classify memes from any of the social
network applications. This will further involve
deploying the trained model to classify memes
automatically on various social networking
platforms. One sanctioned application programming
interface (API) from the social network can be used
to retrieve meme contents and classify memes in real-
time. For the purposes of classification, the system
has evolved machine learning algorithms such as
Optical Character Recognition (OCR) and the
VADER algorithm. The OCR feature is used to refer
to the extraction of text from the memes which is then
processed by Natural Language Processing (NLP)
algorithms and also by enables the system to identify
unwanted and unwanted visual material in memes
that can carry offensive images or symbols. The CNN
is learned from scratch on image data with labels to
recognize offensive content patterns and features.
Blending text and image analysis delivers a complete
multimodal classification approach that greatly
enhances the accuracy of offensive meme
recognition. Second, the classification scheme has
built-in learning and adaptive capabilities that can
change it in response to changes in user sentiment and
new meme emergence over time. In order to ensure
effectiveness of the classification model in sentiment
analysis to determine if the textual content is
offensive or not.
VADER is used to examine the text that has been
extracted and determine whether it is offensive or not.
Besides text examination, the system incorporates
Sequential Convolutional Neural Network (CNN) to
determine whether offensive images are offensive.
This method categorizing memes amid the dynamic
and ever-evolving social media scenario, the same
needs to be retrained based on newer information on
a constant basis. In general, the suggested meme
categorization system combines data gathering, text
and image processing, machine learning model
training, and real-time classification functionalities to
present a complete solution to analyze and categorize
memes in social networks. Text and image content
recognition for offensive content detection assures
that the system effectively flags offending content.
Figure. 2 presents an illustration of the proposed
framework.
Figure 2: Proposed architecture.
4.1 Optical Character Recognition
(OCR)
This step focuses on extracting text content from
meme images using OCR. The key stages involved in
OCR are:
• Extraction of Character Boundaries from the
Image: Identifying and isolating character
regions from the image.
• Establishing the Bag of Visual Words
(BOW) Framework: building a visual
dictionary as a foundation for identifying
and retaining character patterns.
• Loading the Trained Model: Utilizing a pre-
trained OCR model to detect and recognize
text.
• Consolidating Predictions of Characters:
Combining predictions from individual
character detections to form complete words
and sentences.
MemeCheck: Automated Meme Analysis for Identifying Offensive Text and Visuals
679

4.2 Text Mining Algorithm
Once text is extracted, it undergoes preprocessing to
remove noise and prepare it for analysis. The basic
steps are:
• Tokenisation is the process of treating the
provided text as a string and dividing it into
discrete words or phrases, or tokens.
• Removal of Stop Words: Common words
like "a," "an," "but," "and," "of," "the," etc.,
which do not contribute to meaning, are
removed.
• Stemming: This step reduces words to their
root form (e.g., "playing" → "play").
• Inflectional Stemming: Removes endings
like -ing, -ed.
• Derivational Stemming: Removes suffixes
to find the base word.
4.3 VADER Algorithm for Sentiment
Analysis
VADER (Valence Aware Dictionary for Sentiment
Reasoning) is used to analyze the polarity and
intensity of the extracted text. The process involves
the following steps:
• Import the Required Library: Load the
VADER sentiment analysis library.
• Prepare Text for Analysis: Take the
extracted text for which polarity and
intensity need to be calculated.
• Apply Loop for Analysis: Determine each
sentence's or text's VADER score using a
loop.
• Determine the VADER Scores: Four
components are returned by VADER:
compound, neutral, negative, and positive.
• Determine Sentiment:
1. Compound Score > 0: Text is
considered positive.
2. Compound Score < 0: Text is
considered negative.
3. Compound Score = 0: Text is
considered neutral.
4.4 Offensive Image Classification
Using Sequential CNN
The image content in memes is analyzed to detect
offensive visual elements using a Sequential CNN
model. The steps involved are:
Data Collection and Preprocessing: Collect
offensive and non-offensive images, resize them, and
normalize pixel values.
Designing the Sequential CNN Model:
• Input layer: Accepts pre-processed image
data.
• Convolutional layers: Extract features such
as edges, patterns, and shapes from the
images.
• Pooling layers: Minimise feature maps'
spatial dimensions without sacrificing
crucial information.
• Fully connected layers: Perform high-level
reasoning to classify images as offensive or
non-
• offensive.
• Output layer: Generates the final prediction
(offensive or non-offensive).
• Model Training: Train the CNN on the
labelled dataset using backpropagation and
optimize it using appropriate loss and
activation functions.
• Prediction and Classification: Use the
trained model to classify new images as
offensive or non-offensive based on learned
patterns.
5 RESULT AND DISCUSSION
In the present study, we are able to enter meme photos
and extract the text in order to determine whether or
not they are objectionable. The true positive, false
positive, true negative, and false negative rates are
then used to evaluate the performance.
True positive (TP): the text exists in the sample and
the detection system produces a positive diagnosis for
it.
False positive (FP): even though the sample lacks the
text, the detection system still generates a definitive
result for it.
True negative (TN): even though the sample lacks
the text, the detection method yields a positive test
outcome for it.
False negative (FN): even with text in the sample,
the detection system yields a positive test result for it.
Precision =
(1)
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
680
That the FP is zero.The reverse of what we desire
occurs when FP increases since the precision value
decreases while the denominator value increases.
Recall =
(2)
The recall of a good classifier is one, or high.
Recollect equals one only if the denominator and
numerator are equal, say TP = TP + FN, where it
means that FN needs to be zero. The value of recall
decreases (which is bad) with increased FN, and the
lowest common value is larger.
Therefore, in the case of an ideal model for
classification, the best precision and recall are both
one, i.e., FP and FN are both zero.
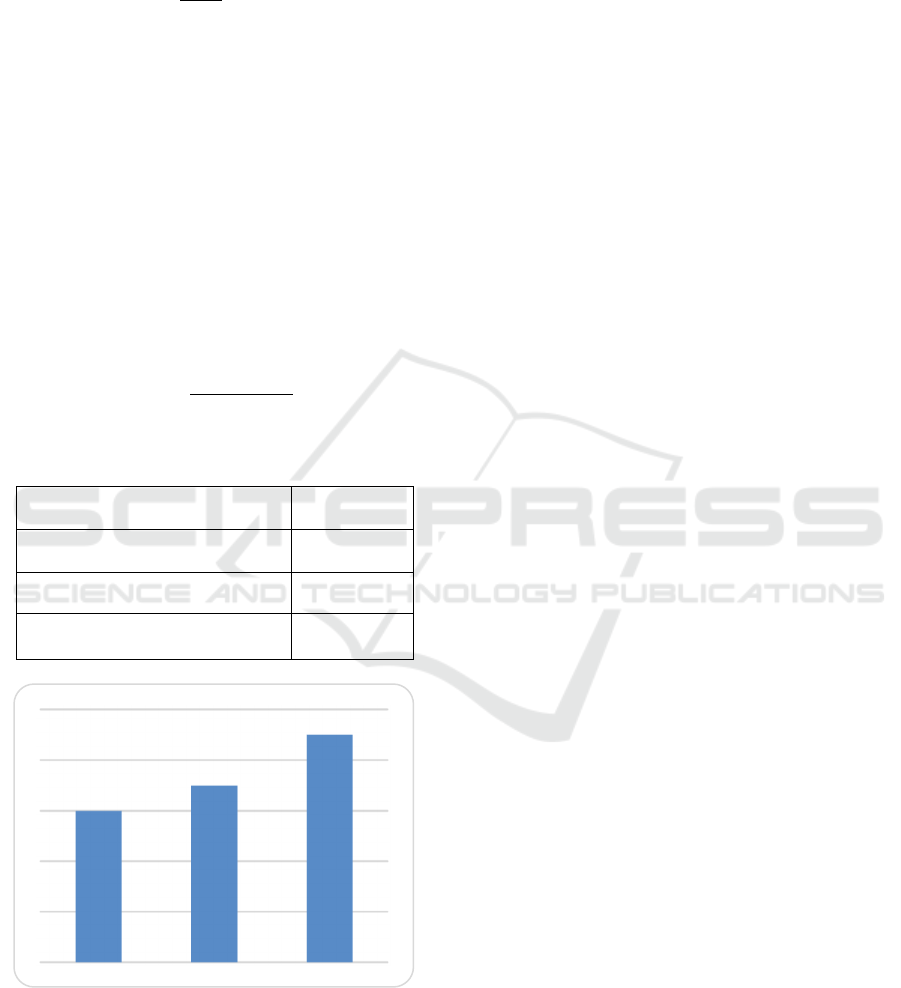
Therefore, we require a measure that considers
both precision and recall. Figure 3 show the
Performance chart. Table 1 show the F1-score is a
calculation that takes both recall and precision into
account:
F1 Score = 2 ∗
∗
(3)
Table1: F1 Score Comparison of Sentiment Analysis
Models.
ALGORITHM F1 SCORE
Naives Bayes 60%
Random forest 70%
Text mining with VADER
Algorithm
90%
Figure 3: Performance chart.
6 CONCLUSIONS
Thus, one may conclude that this combination of
OCR, text mining techniques, VADER sentiment
analysis, and Sequential CNN forms an all-rounded
approach to meme classification, creating a multi-
perspective methodology for the understanding and
categorization of meme content. The text from the
meme images is extracted by the system to inform the
analysis of the fact with regards to the text parts that
often pair with visual elements. Such an approach
allows for greater depth in the analysis of meme
content and future information mined from memes
regarding their nuanced angles and subtleties that
otherwise would not pop out based solely on images.
VADER sentiment analysis is of supreme importance
in sussing out the polarity and intensity of extracted
text while allowing the entire system to flag a meme
caption or an overlay as positive, negative, or neutral.
Significant features and trends can be mined from the
textual material of the meme through text mining
methods. This allows the algorithm to recognize the
primary concepts, emotions, and language features
present in meme captions or overlays. And it also
facilitates enhancing the classification process with
context-granting information and thus more complete
understanding of meme content based on beyond
visual presentation. This sentiment analysis provides
an additional level of depth, further boosting the
overall classification process and allowing a finer
interpretation of meme content. Aside from text-
based analysis, the system uses Sequential CNN for
detecting offensive images, which aims to identify
undesirable and offensive visual content in meme
images. The CNN model learns well the patterns in
offending images, so it is possible to identify
offensive symbols or content that cannot be detected
using text analysis alone. Blending text and image
analysis guarantees a solid and stable classification
system that can deal with the multimodal
characteristic of memes. Fusing these innovative
technologies, the suggested system gives an effective
and adaptive solution for automatically identifying
offending content in memes, hence building a safer
and more respectful social media space.
REFERENCES
Alkomah, Fatimah, and Xiaogang Ma "A literature review
of textual hate speech detection methods and
datasets" Information 136 (2022): 273
F1 SCORE
MemeCheck: Automated Meme Analysis for Identifying Offensive Text and Visuals
681

Aluru, Sai Saketh, et al "Deep learning models for
multilingual hate speech detection" arXiv preprint
arXiv:200406465 (2020)
Cao, Rui, Roy Ka-Wei Lee, and Tuan-Anh Hoang
"DeepHate: Hate speech detection via multi-faceted
text representations" Proceedings of the 12th ACM
Conference on Web Science 2020
Cao, Rui, etal "Promptingfor multimodal hatefull meme
classification" arXiv preprint arXiv:230204156 (2023)
Grasso, Bigio, et al "KERMIT: Knowledge-Empowered
Model In harmful meme deTection" Information
Fusion 106 (2024): 102269
Khan, Shakir, et al "BiCHAT: BiLSTM with deep CNN and
hierarchical attention for hate speech detection" Journa
l of King Saud University-Computer and Information
Sciences 347 (2022): 4335-4344
Khan, Shakir, et al "HCovBi-caps: hate speech detection
using Convolutional and Bi-directional gated recurrent
unit with Capsule network" IEEE Access 10 (2022):
7881-7894
Kumar, Gokul Karthik, and Karthik Nandakumar "Hate-
CLIPper: Multimodal hateful meme classification
based on cross- modal interaction of CLIP features" ar
Xiv preprintt arXiv:221005916 (2022)
Ling, Chen, et al "Dissecting the meme magic: Understan
ding indicators of virality in image memes" Proceedin
gs of the ACM on human- computer interaction 5CSC
W1 (2021): 1-24
Malik, Jitendra Singh, Guansong Pang, and Anton van den
Hengel "Deep learninging for hate speech detection: a
comparative study" arXiv preprint arXiv:220209517 (
2022)
Mozafari, Marzieh, Reza Farahbakhsh, and Noel Crespi "A
BERT-based transfer learning approach for hate speech
detection in online social media" Complex Networks
and Their Applications VIII: Volume 1 Proceedings of
the Eighth International Conference on Complex
Networks and Their Applications COMPLEX NETW
ORKS 2019 8 Springer International Publishing, 2020
Mullah, Nanlir Sallau, and Wan Mohd Nazmee Wan
Zainon "Advances in machine learning algorithms for
hate speech detection in social media: a review" IEEE
Access 9 (2021): 88364-88376
Pramanick, Shraman, et al "Detecting harmful memes and
their Targets" arXiv preprint arXiv:211000413 (2021)
Rabiul Awal, Md, et al "AngryBERT: Joint Learning
Target and Emotion for Hate Speech Detection" arXiv
e-prints (2021): arXiv-2103
Roy, Pradeep Kumar, et al "A framework for hate speech
detection using deep convolutional neural network" IE
EE Access 8 (2020): 204951-204962
Suryawanshi, Shardul, et al "A dataset for troll classificati
on of Tamil Memes" Proceedings of the WILDRE5–
5th workshop on indian language data: resources and
evaluation 2020
Suryawanshi, Shardul, et al "Multimodal Offensive Meme
Classification ith Natural Language Inference" Procee
dings of the 4th Conference on Language, Data and
Knowledge 2023
Thakur, Abhinav Kumar, et al "Explainable Classification
of Internet Memes" (2023)
Yang, Chuanpeng, et al "Invariant Meets Specific: A
Scalable Harmful Memes Detection Framework" Proc
eedings of the 31st ACM International Conference on
Multimedia 2023
Zhong, Xiayu "Classification of Multimodal Hate Speech
the Winning Solution of Hateful Memes Challenge" ar
Xiv preprint arXiv:201201002 (2020)
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
682
