
Anime Face Generating Using Deep Learning
Shaik Muskan Begum, Desam Yashoda, P. Raga Chandrika, Veena Madhuri and Sura Sravani
Department of Computer Science and Engineering, Ravindra College of Engineering for Women, Kurnool,
Andhra Pradesh, India
Keywords: Convolutional Neural Networks (CNNs), Generative Adversarial Networks (GANs), Variational
Autoencoders (VAEs), Pre-Processing.
Abstract: In recent years, the rise of deep learning technologies has greatly enhanced the capabilities of generating
realistic and artistic images. One area that has gained significant attention is the automatic generation of anime
faces. These images, characterized by distinct features such as large eyes, exaggerated facial expressions, and
vibrant hair colors, have seen widespread use in both entertainment and art. The task of generating such faces
requires an effective combination of deep learning techniques, including Convolutional Neural Networks
(CNNs), Generative Adversarial Networks (GANs), and Variational Autoencoders (VAEs). This paper
proposes a novel approach for generating anime faces using deep learning methods. Our model leverages a
GAN architecture, where the generator creates high-quality anime faces, and the discriminator ensures that
these faces appear realistic and true to the style. To train this model, we use a large dataset of labeled anime
face images, ensuring diversity in terms of facial expressions, hair styles, and other unique anime traits. The
dataset is preprocessed to extract important facial features, which allows the model to focus on learning the
abstract characteristics of anime faces, such as the stylized proportions and exaggerated features.
1 INTRODUCTION
Anime face generation using deep learning is a
fascinating application of artificial intelligence,
where neural networks are trained to create realistic
and stylistic anime character faces. This technology
leverages generative models, particularly Generative
Adversarial Networks (GANs) or Variational
Autoencoders (VAEs), to learn the patterns and
features commonly found in anime artwork.
The process typically involves training a model on
a large dataset of anime faces, which allows the
network to learn and replicate the distinctive features
such as large eyes, unique expressions, and specific
styles of shading and coloring. Once trained, the
model can generate new anime faces based on
random inputs or specific conditions (like gender,
hairstyle, etc.). This technology has been used in
applications like generating character designs for
anime and video games, art creation, and even
personal avatars. It also highlights the power of deep
learning in creative fields, making it possible for
anyone to create unique anime-style artwork through
AI tools.
2 RELATED WORKS
Anime face generation using deep learning has
garnered significant attention in recent years, with
many advancements in both research and practical
applications. Below is a brief overview of key related
works in the area:
2.1 GANs for Anime Face Generation
(Generative Adversarial Network) generative
adversarial network (GAN) represents a deep
learning framework. It consists of two neural
networks that work against each other to create more
realistic data based on a provided training dataset. For
example, you can produce new images from an
existing image collection or compose original music
using a library of songs. The term adversarial is used
because it involves two distinct networks competing
with one another. One network generates new data by
altering an input sample as much as possible, while
the other network attempts to identify if the generated
data belongs to the original dataset. In simpler terms,
the second network assesses whether the data
202
Begum, S. M., Yashoda, D., Chandrika, P. R., Madhuri, V. and Sravani, S.
Anime Face Generating Using Deep Learning.
DOI: 10.5220/0013910400004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 4, pages
202-207
ISBN: 978-989-758-777-1
Proceedings Copyright © 2026 by SCITEPRESS – Science and Technology Publications, Lda.
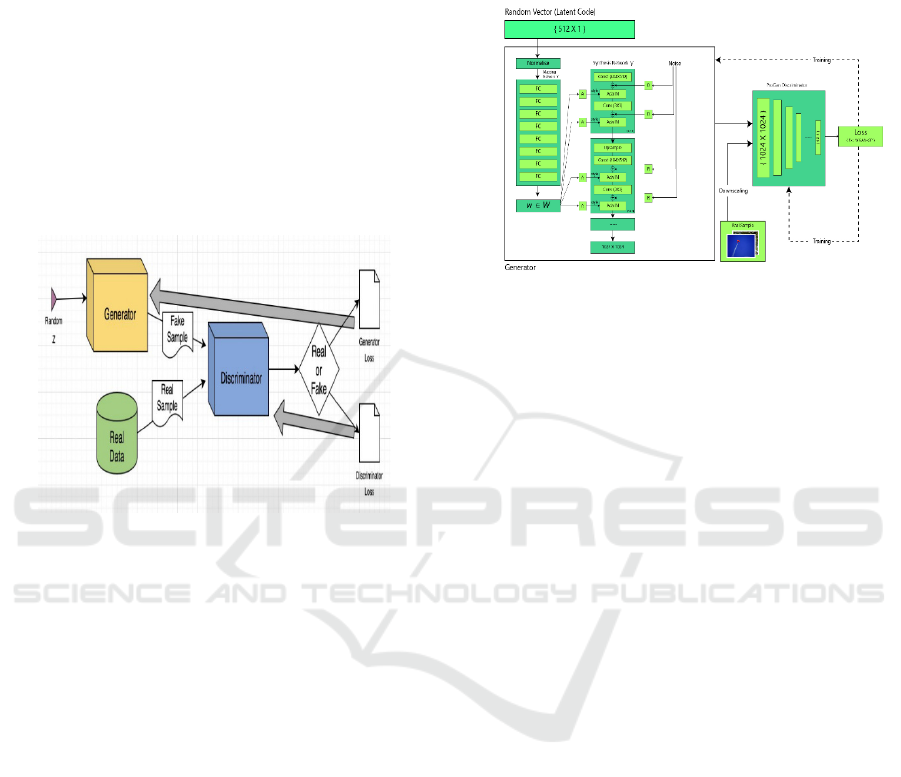
produced is genuine or fabricated. The system
continues to refine and enhance the fake data until the
guessing network is unable to tell the difference
between fake and original data.
Creating an anime face using deep learning,
particularly Generative Adversarial Networks
(GANs), has been an interesting field of research in
the AI community. GANs are often used to generate
realistic images, and for anime faces, they are trained
on large datasets of anime images to generate new,
unique anime-style faces. Figure 1 Shows the
Generative adversarial network.
Here are some relevant works and approaches
related to GANs that have been used for generating
anime faces:
Figure 1: Generative adversarial network.
2.2 StyleGAN and StyleGAN2
StyleGAN
(and its improved version StyleGAN2) are among the
most famous GAN architectures used for generating
high-quality images. StyleGAN allows for more
control over the generated images by manipulating
the "style" or latent space at various levels, making it
highly suitable for generating faces. These models
can be used to generate realistic or stylized faces,
including anime faces, when trained on a specific
dataset of anime artwork.
2.2.1 Anime Faces with StyleGAN
There has been significant work where StyleGAN is
fine-tuned on large datasets of anime faces, such as
the Danbooru dataset. These models can generate
high-quality anime faces with fine details like eyes,
hair, and facial expressions.
2.3 AnimeGAN
AnimeGAN is a specific GAN-based model that was
designed to generate anime-style faces from real
images. The model is trained to convert real human
faces into anime-like faces by learning the specific
stylizations used in anime artwork. Style GAN
Architecture Shown in Figure 2.
Figure 2: Style GAN Architecture.
It’s a specialized model designed to ensure that
the generated image maintains the unique
characteristics of anime, such as large eyes,
simplified facial features, and bright colors.
2.4 DeepAnime
This is a deep learning framework that leverages
GANs to create anime faces. It includes several
architectures, including convolutional neural
networks (CNNs) and GANs, for the task of
translating or generating anime characters. One
example is DeepAnime, which can convert real-world
faces into anime-style versions or generate unique
anime-style faces from scratch.
2.5 CycleGAN for Anime Faces
CycleGAN is another GAN variant that is used for
image-to-image translation. It can be trained to
convert real human faces into anime-style faces
without the need for paired data. By using
unsupervised learning, CycleGAN learns to map
images between two domains (real faces and anime
faces). This allows it to generate anime faces from
photographs or create variations of anime characters.
Like all the adversarial network CycleGAN also has
two parts Generator and Discriminator, the job of
generator to produce the samples from the desired
distribution and the job discriminator is to figure out
the sample is from actual distribution (real) or from
the one that are generated by generator (fake). Figure
3 Shows the CycleGAN Architecture for Unpaired
Image-to-Image Translation Between Domains X and
Y.
Anime Face Generating Using Deep Learning
203
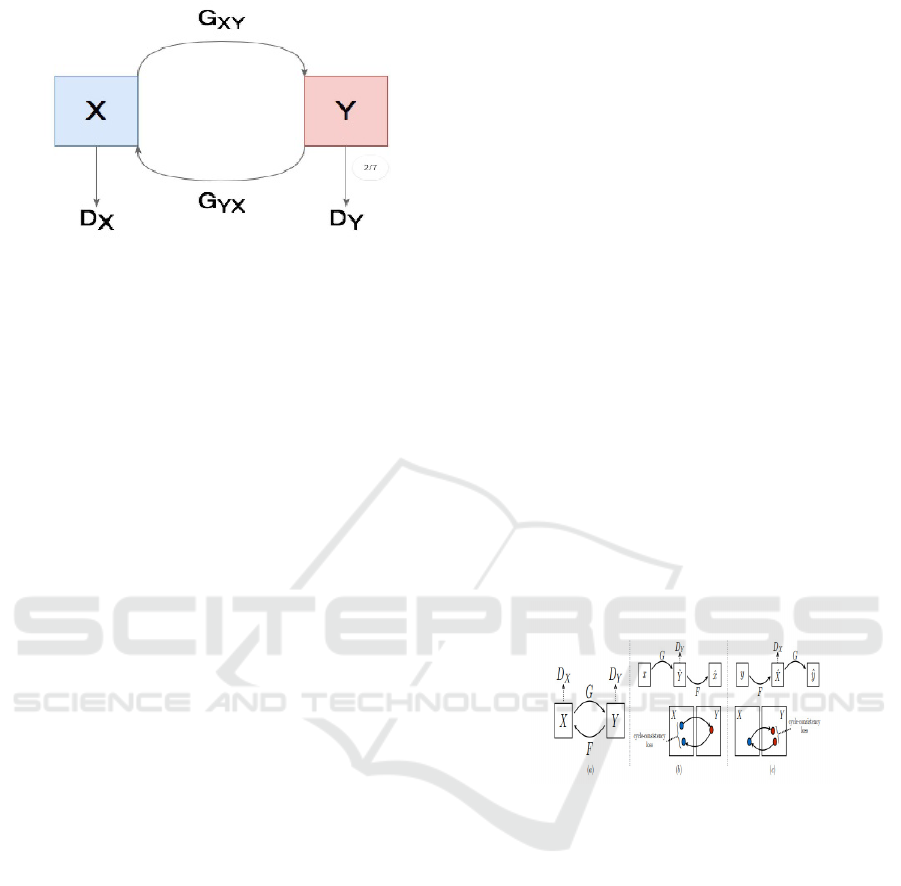
Figure 3: CycleGAN Architecture for Unpaired Image-to-
Image Translation Between Domains X and Y.
CycleGAN is a fascinating deep learning model
designed for unpaired image-to-image translation.
Unlike traditional GANs that generate images from
random noise, CycleGAN transforms images from
one domain (say, horses) to another (like zebras)
without needing paired examples. Let’s break down
its architecture in a clear, natural way.
2.5.1 Core Idea
CycleGAN tackles the challenge of translating
images between two domains—let’s call them
Domain X and Domain Y—without a direct one-to-
one mapping in the training data. It uses two
generators and two discriminators, tied together with
a unique "cycle consistency" concept. The idea is
simple yet clever: if you translate an image from X to
Y and back to X, you should end up close to where
you started. This enforces consistency without paired
data.
Components of the Architecture
The CycleGAN architecture has four main neural
networks working in harmony:
Generator G (X → Y)
● Takes an image from Domain X
(e.g., a horse) and generates a
version in Domain Y (e.g., a zebra).
● Think of it as an artist who learns to
paint zebras when given horse
pictures.
Generator F (Y → X)
● Does the reverse: takes an image
from Domain Y and generates one
in Domain X.
● This is the artist flipping the task,
turning zebras back into horses.
Discriminator D_Y
● Looks at images from Domain Y
(real zebras) and generated images
from G (fake zebras) and tries to tell
them apart.
● It’s like a critic who decides if a
zebra painting looks real.
2. Discriminator D_X
● Does the same for Domain X,
distinguishing real horses from fake
ones produced by F.
● Another critic, this time for horse
authenticity.
How It Works
The training process is where the magic happens.
Here’s the flow:
• Forward Cycle: Start with an image from X.
Generator G transforms it into a fake Y image
(X → G(X)). Then, Generator F takes that fake
Y and tries to reconstruct the original X (G(X)
→ F(G(X))). The goal? F(G(X)) should look
very close to the original X.
• Backward Cycle: Flip it. Start with a Y image,
use F to make a fake X (Y → F(Y)), then G to
get back to Y (F(Y) → G(F(Y))). Again,
G(F(Y)) should resemble the original Y.
This back-and-forth cycle is what makes CycleGAN
special it’s self-regulating. The generators aren’t just
making random images;
they’re constrained to preserve the essence of the
input through this loop.
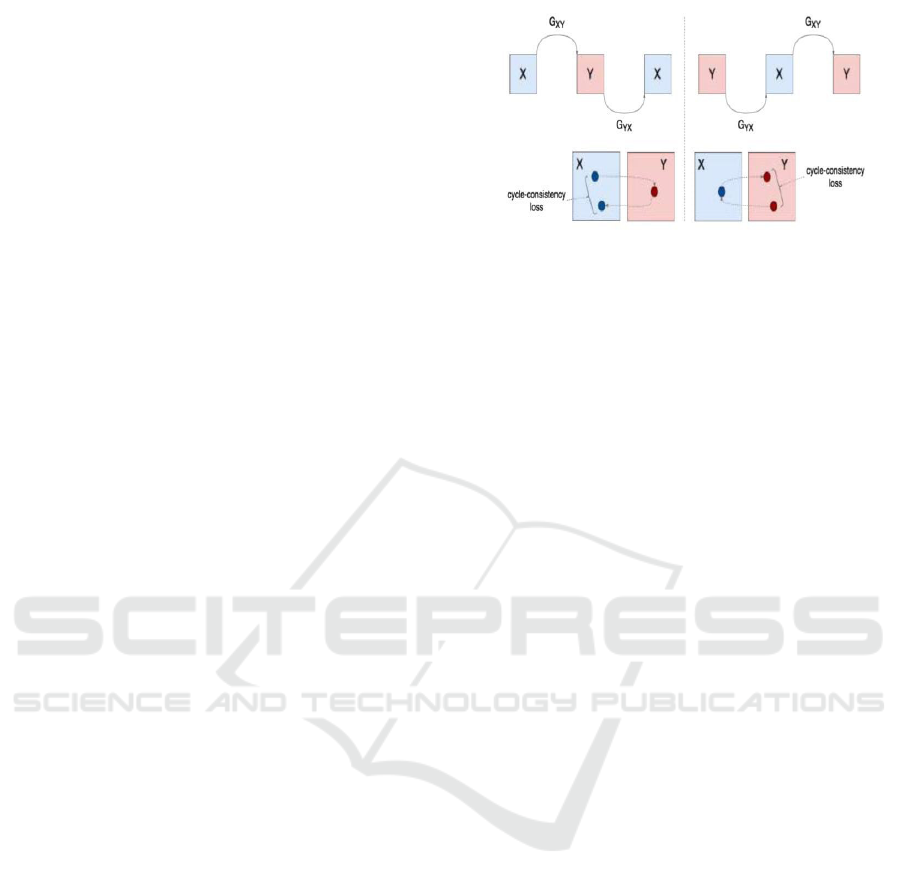
Figure 4: Cycle GAN Framework with Generators and
Discriminators Demonstrating Cycle-Consistency Loss.
Network Design
Let’s get into the nuts and bolts of the architecture:
2.5.2 Generators
The generators typically follow a structure inspired
by image-to-image translation models:
• Encoder: Downsamples the input image (e.g.,
256x256x3 for RGB) using convolutional layers
with stride 2. This shrinks the spatial size while
increasing the number of feature channels (e.g.,
64, 128, 256 filters).
• Transformer: A set of residual blocks (often 6
or 9) with skip connections. These keep the core
features intact while applying the stylistic
changes between domains. Each block has
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
204
convolutions, normalization, and ReLU
activation.
• Decoder: Upsamples back to the original size
using fractionally-strided convolutions
(sometimes called transposed convolutions)
with stride ½. This rebuilds the image with the
new style.
Normalization is key here CycleGAN often uses
Instance Normalization (normalizing each sample’s
feature maps independently) instead of Batch
Normalization, which works better for style transfer
tasks.
2.5.3 Discriminators
The discriminators use a PatchGAN design, which is
different from a typical GAN discriminator:
Instead of judging the whole image as real or fake,
it evaluates small patches (e.g., 70x70 regions).
The architecture is a series of convolutional layers
(e.g., 64, 128, 256, 512 filters) with 4x4 kernels,
stride 2, and LeakyReLU activation. No
normalization on the first layer, but Instance
Normalization elsewhere.
The output is a grid (e.g., 30x30 for a 256x256
input), where each value says if its patch is real or
fake. The final score averages these patch predictions.
This patch-based approach focuses on local
texture and style, which suits image translation well.
2.5.4 Loss Functions
Cycle GAN’s training balances three types of losses:
Adversarial Loss
For G and D_Y: G tries to fool D_Y by making G(X)
look like real Y images. D_Y fights back by getting
better at spotting fakes.
For F and D_X: Same deal, but F(Y) must trick
D_X into thinking it’s a real X.
● Often uses Least Squares Loss (L2) instead of
the classic cross-entropy, making training
more stable.
CycleConsistency Loss
● Measures how close F(G(X)) is to X and
G(F(Y)) to Y using an L1 (mean absolute
error) norm.
● This is the heart of unpaired training ensuring
the mappings are reversible.
● Weighted by a factor λ (typically 10) to
balance it against adversarial loss.
LGAN(G, DY, X, Y) = Ey ∼ pdata(y)
[logDY(y)] + Ex ∼ pdata(x)[log(1 − DY
(G(x)))] (1)
Figure 5: Visualization of Cycle-Consistency Loss in
Bidirectional Translation Between Domains X and Y Using
Cycle GAN.
2.5.5 Identity Loss (Optional)
If you feed G an image already from Y, it should
output something close to that input (G(Y) ≈ Y).
Same for F(X) ≈ X.
Helps preserve color and structure, especially for
subtle translations. Weighted lower (e.g., 0.5λ).
The total loss combines these, optimizing G and F
to minimize it while D_X and D_Y maximize their
adversarial terms.
Putting It Together
Imagine training CycleGAN to turn horses into
zebras:
● G learns to add stripes to horses.
● F learns to remove stripes from zebras.
● D_Y checks if zebra images (real or fake) look
legit.
● D_X ensures horse images pass muster.
LGAN(F, DX, Y, X) = Ex ∼ pdata(x)[logDX
(x)] + Ey ∼ pdata(y)[log(1 − DX(F(y)))] (2)
● The cycle loss keeps the horse’s pose and
background intact through the transformation
loop.
3 METHODOLOGY
3.1 Data Collection and Preprocessing
• Data Collection: For the training of a deep
learning model, a large dataset of high-quality
anime face images is required. Common
datasets used for anime generation include
• Anime Face Dataset: A large-scale dataset of
labeled anime images, containing thousands of
different character faces.
• Other Annotated Datasets: A collection of
anime characters with tagged attributes like
Anime Face Generating Using Deep Learning
205
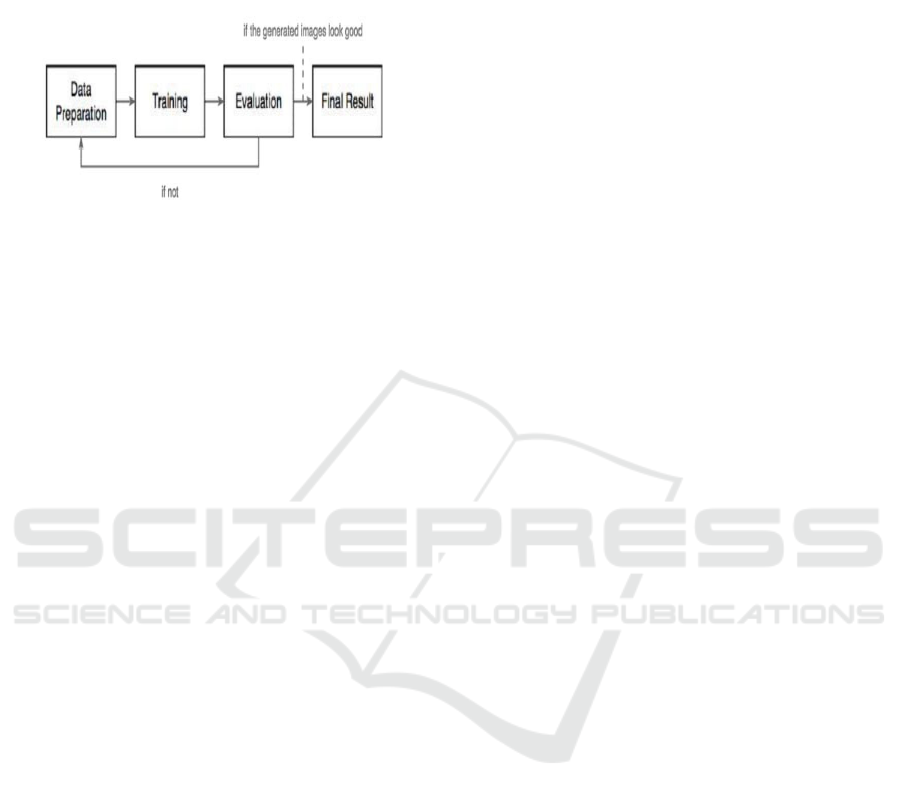
gender, expression, etc. Figure 6 Shows the
High-level procedure of anime face generating
using deep learning.
Figure 6: High level procedure of anime face generating
using deep learning.
3.2 Data Preprocessing
• Image Resizing: All images are resized to a
fixed resolution (e.g., 64x64 or 256x256
pixels) for input consistency.
• Normalization: Pixel values are normalized
to the range [0, 1] or [-1, 1] to speed up
training.
• Augmentation: Random horizontal flipping,
rotation, and other techniques to increase the
diversity of the training data and improve
generalization.
3.2.1 Choose a Deep Learning Framework
• Options: Use TensorFlow, PyTorch, or Keras
(PyTorch is popular for GANs due to its
flexibility).
• Hardware: Ensure access to a GPU (e.g.,
NVIDIA) for faster training. Google Colab or
a local setup with CUDA support works well.
• Libraries: Install dependencies like NumPy,
OpenCV, and Matplotlib for data handling and
visualization.
3.2.2 Select a Model Architecture
• Model Type: Use a GAN, which consists of
two networks:
• Generator: Takes random noise as input and
generates fake anime faces.
• Discriminator: Evaluates whether an image is
real (from the dataset) or fake (from the
generator).
• Specific Architecture: Start with a simple
DCGAN (Deep Convolutional GAN) or
upgrade to StyleGAN for higher quality.
• Generator: Convolutional layers with
upsampling (e.g., transposed convolutions).
• Discriminator: Convolutional layers with
downsampling.
• Hyperparameters: Set learning rate (e.g.,
0.0002), batch size (e.g., 64), and latent space
size (e.g., 100-dimensional noise vector).
3.2.3 Implement the Training Loop
• Epochs: The model is trained over several
epochs, with frequent checkpoints to save
progress.
• Batch Size: Choose an appropriate batch size
(e.g., 16, 32) based on GPU memory
limitations.
• Learning Rate: A learning rate scheduler or
decayed learning rate is used to stabilize the
training process.
• Optimization Algorithm: The Adam
optimizer is commonly used for both
generator and discriminator.
Loss Functions
● Adversarial Loss: The GAN's training is
based on the adversarial loss, where the
generator tries to fool the discriminator, and
the discriminator tries to correctly classify
images as real or fake.
● Feature Matching Loss: In addition to
adversarial loss, feature matching loss (to
ensure high-level consistency in generated
features) can be added forbetter performance.
● L2 Loss / Content Loss: For enhanced image
quality, an L2 loss can be used to minimize
pixel-wise differences between the generated
images and the real images.
3.2.4 Evaluation and Post-Processing
Quantitative Evaluation
● Frechet Inception Distance (FID): Measures
the similarity between generated images and
real images, evaluating the quality and
diversity of generated anime faces.
● Inception Score (IS): Another metric for
evaluating the quality of generated images
based on the classifier’s predictions.
Qualitative Evaluation
● Human Evaluation: Conduct surveys with
human evaluators to assess the realism and
diversity of generated anime faces.
● Attribute-based Evaluation: For conditional
models, check the correctness of the
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
206

conditional attributes (e.g., matching the
gender or facial expressions).
Output’s
Visual Results of Image-to-Image Translation Using
CycleGAN for Face Style Transformation Shown in
Figure 7.
Figure 7: Visual Results of Image-to-Image Translation
Using CycleGAN for Face Style Transformation.
4 CONCLUSIONS
In conclusion, generating anime faces using deep
learning has revolutionized the way we create and
personalize animated characters. By utilizing
advanced models such as GANs and VAEs,
researchers have been able to generate highly realistic
and expressive anime faces. These models learn
intricate patterns and details from large datasets,
enabling the creation of diverse and unique
characters.
The ability to customize facial features allows for
endless possibilities, making anime face generation a
powerful tool in both creative and commercial
industries. While challenges such as training stability
and dataset bias remain, advancements in AI continue
to push the boundaries of what’s possible. As deep
learning technologies evolve, we can expect even
more realistic, nuanced, and creative anime
characters in the future. This progress opens doors for
further exploration in animation, gaming, and virtual
reality applications. Ultimately, AI-driven anime face
generation represents a significant leap toward a more
personalized, immersive, and creative digital
landscape.
REFERENCES
X. Zeng, H. Wang, Y. Yang, and Z. Yang, "Face image
generation for anime characters based on generative
adversarial network," ResearchGate, 2023. [Online].
Available: https://www.researchgate.net/publication/3
88057590_Face_Image_Generation_for_Anime_Char
acters_based_on_Generative_Adversarial_Network
B. H. Assefa and C.-C. J. Kuo, "Graph convolutional
networks with edge-aware message passing for
skeleton-based action recognition," TNS Proceedings,
2023. [Online]. Available: https://www.ewadirect.co
m/proceedings/tns/article/view/20348/pdf
Y.-C. Chen, K.-Y. Hsu, and C.-S. Fuh, "Generating anime
faces from human faces with adversarial networks,"
National Taiwan University, 2018. [Online].
H. Ding, C. Jin, and G. Xu, "Anime character face
generation based on GAN and transfer learning,"
Research Square, preprint, 2023. [Online]. Available:
https://www.researchsquare.com/article/rs-2530988/v1
L. Zhang, Y. Lin, Y. Wang, and S. Liu, "StyleFaceGAN:
Face stylization with generative adversarial networks,"
in 2022 IEEE International Conference on Image
Processing (ICIP), 2023, pp. 3366–3370.
Doi:10.1109/ICIP46576.2022.9897875. [Online].
Available: https://ieeexplore.ieee.org/document/1000
9693
M.-Y. Liu, X. Huang, A. Mallya, T. Karras, T. Aila, J.
Lehtinen, and J. Kautz, "Few-shot unsupervised image-
to-image translation," in 2019 IEEE/CVF International
Conference on Computer Vision (ICCV), 2019, pp.
10551–10560. Doi: 10.1109/ICCV.2019.01065.
[Online].
Y. Zheng, J. H. Liew, Z. Lin, and Y. Liu, "Appearance-
preserved portrait-to-anime translation via proxy-
guided domain adaptation," Singapore Management
University, 2022. [Online]. Available:
https://ink.library.smu.edu.sg/sis_research/8362
Anime Face Generating Using Deep Learning
207
