
Innovative Technique for Classification of Web Service Quality
through Machine Learning
Nagesh C., Bhavana Y., Ayesha K., Govardhini Gowd G. and Jaswanth Reddy M.
Department of CSE, Srinivasa Ramanujan Institute of Technology, Rotarypuram Village, B K Samudram Mandal,
Anantapuramu - 515701, Andhra Pradesh, India
Keywords: Extra Trees Classifier, Logistic Regression, SVM, KNN, GNB.
Abstract: Web services have become a cornerstone of modern distributed systems, enabling seamless communication
and interoperability. Traditional methods for classifying web services using Quality-of-Service (QoS)
attributes often face challenges in effectively managing dynamic and unlabeled data. To address this
challenge, this research introduces a machine learning-based framework for web service analysis and
classification, incorporating clustering techniques alongside supervised models such as Logistic Regression,
SVM, KNN, and GNB. The system processes QoS metrics like response time, availability, and reliability to
classify services into predefined quality classes. By integrating pseudo-labeled data through clustering, the
framework significantly improves classification accuracy and scalability. This approach offers a robust and
adaptive solution for efficient web service quality assessment, addressing the evolving needs of real-world
applications.
1 INTRODUCTION
Web services have revolutionized modern distributed
computing by enabling seamless communication and
interoperability between heterogeneous applications.
With the increasing reliance on web services for
cloud computing, e- commerce, financial
transactions, and enterprise systems, ensuring their
quality has become a major concern. Quality-of-
Service (QoS) characteristics, including response
time, availability, reliability, and throughput, are
essential factors in evaluating the performance and
effectiveness of web services Precise categorization
of web services using these attributes is crucial for
service selection, optimization, and ensuring a high-
quality user experience. Traditional classification
methods, which often rely on rule-based and heuristic
approaches, struggle to handle large-scale and
dynamic service environments. These methods
typically depend on manually labeled datasets, which
are time-consuming to generate and may not
generalize well to real-world applications where data
is constantly evolving. Additionally, traditional
approaches lack the ability to effectively process
unlabeled data, limiting their scalability and
adaptability.
To address these limitations, this study presents a
machine learning-driven framework that combines
supervised learning with clustering methods for web
service classification. The proposed approach
employs service performance indicators, including
response duration, system uptime, data handling
capacity, and consistency, to classify web services
into designated quality categories. By incorporating
supervised learning algorithms like Extra Trees
Classifier, Logistic Regression, SVM, KNN, and
Gaussian Naïve Bayes, the framework aims to
enhance classification accuracy. Additionally,
pseudo-labeling techniques using clustering methods
are employed to generate labels for unlabeled data,
thereby improving the robustness and scalability of
the model. This hybrid approach ensures that the
system can dynamically process new and evolving
web service data, making it more adaptable to real-
world applications with minimal manual intervention.
By integrating machine learning with pseudo-
labeling techniques, this research offers a scalable,
adaptive, and automated approach to classifying web
services, catering to the evolving demands of cloud-
based and distributed systems. The structure of this
paper is as follows: Section 2 provides an overview
of relevant studies and existing classification
methods, while Section 3 outlines the proposed
830
C., N., Y., B., K., A., G., G. G. and M., J. R.
Innovative Technique for Classification of Web Service Quality through Machine Learning.
DOI: 10.5220/0013906500004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 3, pages
830-835
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

approach, covering data preprocessing, feature
selection, and model development. Section 4 analyzes
the experimental results and compares classifier
performance, and Section 5 wraps up the study with
key insights and directions for future research.
2 RELATED WORKS
Nozad Bonab et al. proposed SSL-WSC, a semi-
supervised method for categorizing web services
using service performance metrics. Their approach
utilized self-training, integrating both annotated and
unannotated data to enhance the accuracy of
categorization. Utilizing the QWS dataset, the
proposed method achieved improvements in F1-score
(11.26%), accuracy (9.43%), and precision (9.53%)
compared to conventional supervised learning
techniques. By dynamically selecting and pseudo-
labeling unlabeled data, SSL-WSC reduced reliance
on manually labeled datasets and improved
scalability. Crasso et al. developed the Automated
Web Service Classification (AWSC) framework,
which leverages machine learning and text mining to
enhance web service discovery. Their research
showed that SVM (Support Vector Machines) and
Naïve Bayes classifiers efficiently categorized
services based on semantic descriptions, leading to
enhanced retrieval precision and classification
accuracy.
Shafiq et al. proposed a hybrid classification
model that combined lightweight semantics with a
Bayesian classifier to enhance web service discovery.
Their approach adaptively categorized web services
using non-functional attributes, leading to fewer
misclassification errors and improved retrieval
accuracy. Wong and Liu applied text mining methods
to generate feature vector representations of web
services, which were then clustered based on
similarity measures.
Wang et al. developed a hierarchical classification
model based on the standardized coding framework
used for categorizing products and services globally.
Their framework utilized Support Vector Machines
(SVM) to categorize services within a multi-level tree
structure, improving classification precision and
reducing misclassification errors. Chipa et al.
examined various supervised learning approaches
that utilize pattern recognition and statistical analysis
to classify web services effectively. Their findings
highlighted the effectiveness of these classifiers in
accurately categorizing services based on QoS
metrics, enabling better service ranking and selection.
El-Sayyad et al. proposed a semantic similarity-based
classification algorithm utilizing domain ontology to
improve service categorization. Their method
reduced ambiguity in service descriptions and
significantly improved classification accuracy by
considering contextual relationships between
services.
Li et al. developed a Graph Convolutional Neural
Network (GCN) using residual learning and an
attention mechanism for web service classification.
Their approach dynamically assigned weights to
features, enhancing classification accuracy in large-
scale web service environments. Kamath et al.
proposed a crawler-based system that automatically
labeled web services based on similarity analysis
techniques. Their method optimized search efficiency
and classification precision using machine learning-
based hierarchical clustering. Moreno-Vallejo et al.
leveraged Artificial Neural Networks (ANNs) for
detecting fraudulent and low-quality web services.
Their study demonstrated that deep learning models
could efficiently classify web services based on
behavioral patterns, highlighting the need for
continuous monitoring and adaptive classification
models.
3 METHODOLOGY
The proposed framework employs a machine
learning-driven approach to classify online services
according to performance-related attributes. It
integrates clustering techniques with supervised
learning models, including Extra Trees Classifier,
Logistic Regression, SVM, KNN, and GNB. By
applying advanced clustering techniques, the system
classifies web services into predefined quality
categories, evaluating service performance based on
attributes like response time, availability, and
reliability.
The system incorporates feature selection
techniques, including clustering-based pseudo-
labeling, to improve classification accuracy and
scalability. This method enables the model to process
dynamic and unlabeled data efficiently, ensuring
accurate classification results even as datasets evolve.
To ensure robust and reliable performance, the
system applies generalized preprocessing steps, such
as handling missing data, normalizing QoS metrics,
and encoding categorical features. These procedures
are intended to ready the data for robust analysis and
boost the model's capacity to generalize across
various web services and QoS scenarios.
This comprehensive machine learning framework
provides an adaptive and scalable solution for
Innovative Technique for Classification of Web Service Quality through Machine Learning
831
efficient web service quality assessment. It
demonstrates significant improvements in
classification accuracy, making it a powerful tool for
real-time web service monitoring and management,
addressing the growing complexity and variability of
web services in modern distributed systems.
3.1 Data Collection
The study employs a dataset consisting of labeled
web service instances, encompassing both functional
and non-functional characteristics. It includes data
collected from diverse web services across multiple
domains, ensuring a comprehensive representation of
service quality. Each instance represents unique
service characteristics, emphasizing essential QoS
(Quality-of-Service) metrics like response time,
availability, throughput, and reliability. The dataset
provides a rich and detailed representation of web
service properties. This enables effective analysis to
distinguish between different service categories and
classify them based on their quality characteristics
using a semi-supervised learning approach. The
dataset consists of both labeled and unlabeled
instances, supporting clustering and classification
techniques for improved predictive performance.
To address missing data, categorical attributes were
replaced with their most common category, while
numerical attributes were filled using their mean
value to preserve dataset consistency. Additionally,
the IQR (Interquartile Range) technique was utilized
for detecting outliers, helping to identify and
minimize anomalies in essential performance metrics.
3.2 Data Preprocessing
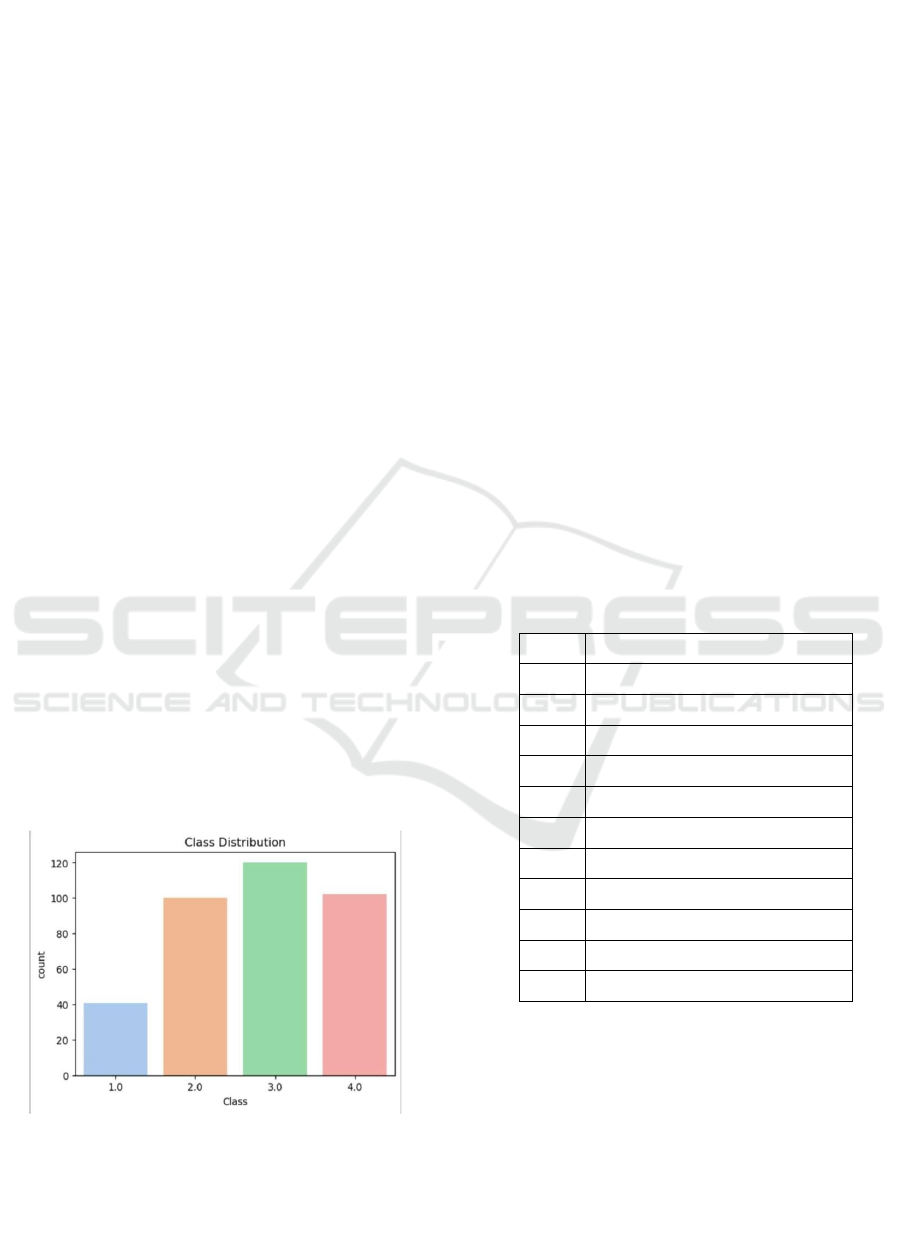
Figure 1: Distribution of dataset labels.
The preprocessing stage included managing missing
data, transforming categorical features, and
standardizing numerical attributes to maintain data
consistency. Non-numeric attributes were converted
using Ordinal Encoding, where a distinct numerical
value was allocated to each category with the help of
the Ordinal Encoder from Scikit-learn. This
facilitated compatibility with machine learning
models while preserving ordinal relationship. Figure
1 show the Distribution of Dataset Labels.
3.3 Feature Selection
The SelectKBest method, utilizing the ANOVA F-
statistic, was applied for feature selection, assessing
each feature's significance based on its statistical
relevance to web service classification. This method
enabled the identification of key attributes
contributing to accurate classification, ensuring
improved model interpretability and efficiency.
Furthermore, a feature reduction technique was
implemented to decrease data complexity while
preserving essential distinguishing attributes, thereby
enhancing the classification process. Table 1 presents
the 12 most relevant features selected from the
dataset, emphasizing critical QoS metrics for
effective web service classification.
Table 1: Key features for analysis and classification.
No Features
1 User Rating
2 Latency
3 Invocation Rate
4 Error Rate
5 Reliability
6 Availability
7 Success Rate
8 Throughput
9 Service type
10 Provider Reputation
11 Response Time
3.3 Model Training and Evaluation
In this study, five computational learning techniques
were employed to classify web services based on their
functional and non-functional performance attributes.
The models underwent training on a labeled portion
of the dataset and were evaluated using a distinct test
set. Their efficiency was analyzed using assessment
metrics, including accuracy, recall, precision, and F1-
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
832

score, to determine the best-suited model for web
service classification.
Extra Trees Classifier (ETC): The ETC belongs
to the ensemble learning category and generates
multiple decision trees using randomly selected
feature splits. Unlike traditional Random Forest
models, ETC introduces additional randomness by
selecting features and thresholds randomly, reducing
variance and improving generalization.
This approach was implemented using the dataset
for training and assessed on a separate test set. This
method is especially useful for managing high-
dimensional data and offers valuable insights into the
key QoS features that impact web service
categorization.
SVM (Support Vector Machine): The vector-
based classification model employed an RBF kernel,
enabling the transformation of complex, non-linearly
separable data into a higher-dimensional
representation. This technique determines the best
hyperplane to maximize the separation margin among
various classes, making it a robust approach for
distinguishing web services based on performance
and reliability. The model underwent training on the
dataset and was evaluated based on classification
accuracy and its effectiveness in differentiating high-
quality from low-quality web services.
KNN (K-Nearest Neighbors): The nearest-
neighbor approach was chosen due to its non-
parametric properties and its capability to categorize
instances based on similarity. It assigns a class label
to a new instance based on the majority vote of its k
nearest neighbors within the feature space. To
improve classification accuracy, the optimal value of
k was determined through cross-validation. Since
KNN relies on distance metrics, feature scaling was
applied to ensure consistent distance calculations
between numerical attributes.
LR (Logistic Regression): A regression-based
approach was utilized as a reference model for
classification tasks. It calculates the likelihood of an
instance being assigned to a particular category using
the logistic function. The model was trained using a
set of Quality-of-Service (QoS) attributes, with
feature scaling performed to enhance convergence
during optimization. Regularization techniques were
incorporated to prevent overfitting and improve
generalization to unseen data.
GNB (Gaussian Naïve Bayes): The GNB
classifier was employed due to its efficiency in
handling probabilistic classification problems. This
model assumes a normal distribution of features and
applies Bayes' theorem to estimate class probabilities.
Although GNB assumes feature independence, it
frequently achieves strong performance in real-world
applications, making it an efficient and effective
choice for multi-class web service classification. The
models' performance was assessed using four
essential classification metrics: Support, Recall, F1-
score, and Precision to evaluate their effectiveness in
web service classification.
Precision
Definition: Precision, also referred to as
Confirmatory Predictive Value, represents the ratio of
correctly identified high-quality web services to the
total predicted as high-quality.
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =
(1)
Formula:
A higher precision score reflects the system's
capability to reduce incorrect classifications, ensuring
low-quality services are not mistakenly labeled as
high- quality.
Recall
Definition: Recall, often referred to as Sensitivity,
evaluates the system's ability to accurately detect all
occurrences of high-quality web services.
Formula:
𝑅𝑒𝑐𝑎𝑙𝑙 =
(2)
F1-score
Definition: The F1-score is derived as the harmonic
average of precision and recall, providing a
comprehensive assessment of effectiveness.
Formula:
𝐹1−𝑠𝑐𝑜𝑟𝑒=2×
×
(3)
The performance metric is crucial in web service
classification, as both false positives (misidentifying
low-quality services as high-quality) and false
negatives (overlooking high-quality services) can
negatively impact service selection.
Innovative Technique for Classification of Web Service Quality through Machine Learning
833
Support
Definition: Support represents the total count of real
occurrences in each category. It provides a reference
for assessing classification performance by indicating
the distribution of samples across different categories.
4 RESULTS AND ANALYSIS
The proposed system was evaluated using four
computational classification techniques, including
tree-based, vector-based, neighbor-based, and
regression-based approaches, to categorize web
services.
Table 2 show the Evaluation Metrics of
proposed Machine Learning Algorithms Among the
evaluated approaches, the tree-based classification
method demonstrated superior performance, reaching
a precision level of 96.45%. Its capability to handle
high-dimensional data and reduce overfitting through
ensemble learning demonstrates its robustness.
Support Vector Machines (SVM) also performed
well, achieving an accuracy of 93.21%, effectively
separating classes with an optimal hyperplane. K-
Nearest Neighbors (KNN) provided a competitive
performance with 91.34% accuracy, leveraging
distance- based classification but slightly struggling
with large feature spaces. Logistic Regression,
serving as a baseline model, achieved 88.76%
accuracy, highlighting its limitations in capturing
complex non-linear relationships. Gaussian Naïve
Bayes (GNB), recognized for its probabilistic
methodology, recorded the lowest accuracy at
85.23% due to its assumption of feature
independence, which is less suitable for web service
classification.
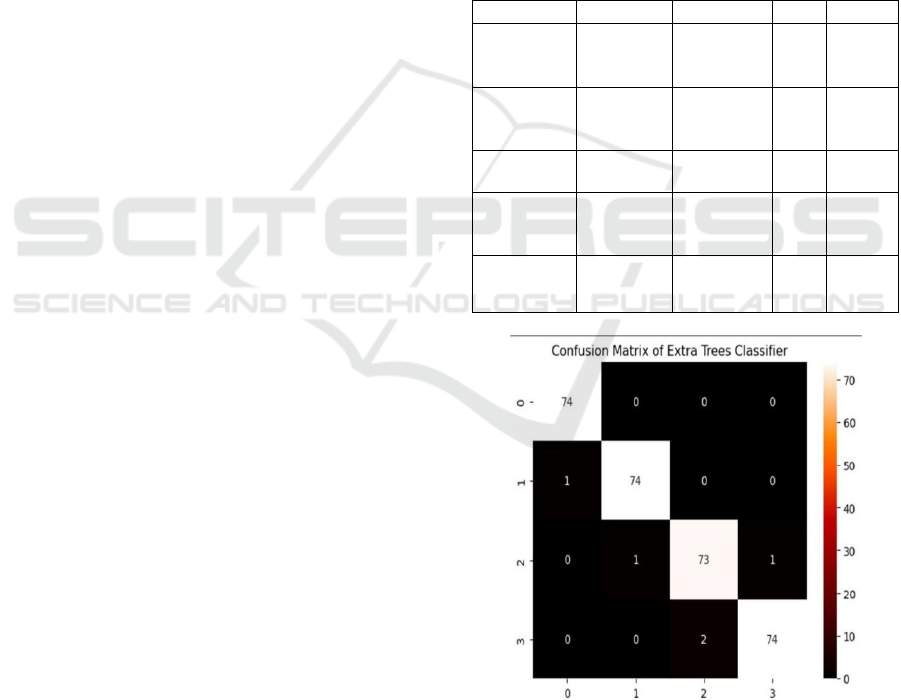
Figure 2 presents the confusion matrix for the
Extra Trees Classifier, offering a comprehensive
analysis of its effectiveness in categorization. It
displays the number of accurate and inaccurate
predictions for each category, showcasing the model's
ability to distinguish various web service types from
benign files. High values along the diagonal indicate
the effectiveness of the model in making correct
predictions, while low off-diagonal values reflect
minimal misclassification rates. This reinforces the
Extra Trees Classifier’s robust performance in web
service classification.
The bar chart in Figure 3 illustrates the feature
importance scores for the attributes used in the model.
The performance of various computational learning
techniques, such as statistical regression models,
distance-based classifiers, probabilistic approaches,
and ensemble methods, was evaluated using accuracy
as the primary assessment criterion. Among the
evaluated techniques, the ensemble-based
classification approach achieved the best
performance, reaching 98.83% precision,
demonstrating its capability to handle complex data
patterns and identify feature relationships effectively.
The SVM model exhibited strong performance,
achieving a 94.0% success rate and effectively
separating classes using an optimized decision
boundary. Logistic Regression (LR), serving as a
strong baseline, attained a 93.9% accuracy. K-Nearest
Neighbors (KNN) achieved 89.0% accuracy,
demonstrating its ability to capture local data
structures.
Table 2: Evaluation metrics of proposed machine learning
algorithms.
Model Support Precision Recall F1-score
Extra
Trees
Classifie
r
High 96.50 96.45 96.42
Support
Vector
Machines
Medium 93.35 93.21 93.18
K-Nearest
Neighbors
Medium 91.40 91.34 91.31
Logistic
Regressio
n
Low 88.85 88.76 88.72
Gaussian
Navie Bayes
Low 85.35 85.23 85.15
Figure 2: Confusion matrix of extra trees classifier.
Conversely, Gaussian Naïve Bayes (GNB) achieved
the lowest accuracy of 83.7%, suggesting that its
feature independence assumption may not be ideal for
this classification task. The Extra Trees Classifier
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
834
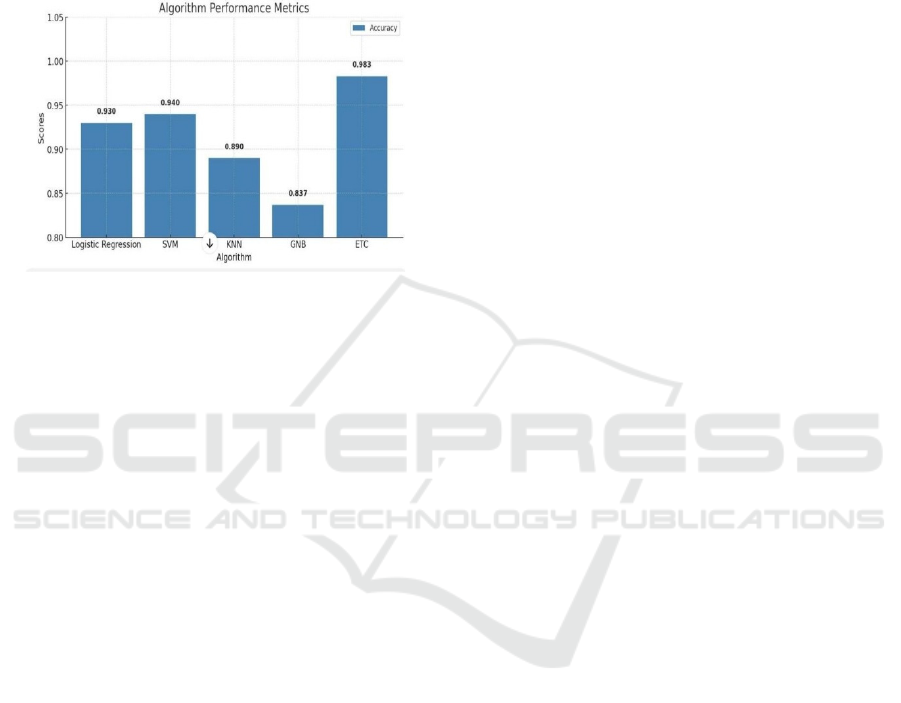
proved to be the most effective model, while SVM
and Logistic Regression delivered competitive
results. In contrast, KNN and GNB exhibited
relatively lower performance. These findings indicate
that tree-based models, such as ETC, are highly
suitable for web service classification, as they
effectively identify complex patterns within the data.
Figure 3: Algorithm performance metrics.
SVM, KNN, and GNB were evaluated for
categorizing web services based on QoS attributes,
alongside the Extra Trees Classifier (ETC).
5 CONCLUSIONS
Several machine learning models, such as Extra Trees
Classifier (ETC), Logistic Regression (LR), Support
Vector Machine (SVM), K-Nearest Neighbors
(KNN), and Gaussian Naïve Bayes (GNB), were
analyzed for web service classification using Quality-
of-Service (QoS) attributes. The Extra Trees
Classifier (ETC) proved to be the top-performing
model, attaining a peak accuracy of 98.83%, with
SVM and Logistic Regression also exhibiting strong
results. While KNN and GNB performed
comparatively lower, the results indicate that tree-
based models, especially ETC, are particularly
effective in handling the complexity and interactions
in web service classification tasks. This underscores
the efficiency of AI-driven frameworks in enhancing
precision and scalability for evaluating web service
quality in practical applications.
REFERENCES
Chipa, M., Priyadarshini, A., & Mohanty,R. (2019).
"Application of machine learning techniques to classify
web services." IEEE Int. Conf. Intelligent Technologies
& Optimization, INCOS, pp. 1–7.
Crasso, M., Zunino, A., & Campo, M. (2008). "AWSC: An
approach to web service classification based on
machine learning techniques." Inteligencia Artificial,
Vol. 12(37),
El-Sayyad, S. E., Saleh, A. I., & Ali, H. A. (2018). "A new
semantic web service classification (SWSC) strategy."
Cluster Computing, Vol. 21(3), pp. 1639–1665.
Kamath, S., & Ananthanarayana, V. (2014). "Similarity
analysis of service descriptions for efficient web service
discovery." Int. Conf. Data Science and Advanced
Analytics (DSAA), pp. 142–148.
Li, B., Li, Z., & Yang, Y. (2021)."Residual attention graph
convolutional network for web services classification."
Neurocomputing, Vol. 440, pp. 45–57.
Liu, W., & Wong, W. (2009). "Webservice clustering using
text mining techniques." Int. J. Agent- Oriented
Software Engineering, Vol. 3(1), pp. 6–18.
Moreno-Vallejo, P. X., et al. (2023). "Fake news
classification web service for Spanish news using
artificial neural networks." Int. J. Advanced Computer
Science & Applications, Vol. 14(3), pp. 1–7.
Nozad Bonab, M., Tanha, J., & Masdari, M. (2024). "A
Semi-Supervised Learning Approach to Quality- Based
Web Service Classification." IEEE Access, Vol. 12, pp.
50489-50503.
Shafiq, O. (2010). "Lightweight semantics and Bayesian
classification: A hybrid technique for dynamic web
service discovery." IEEE Int. Conf. Information Reuse
and Integration, pp. 121–125.
Wang, H., et al. (2010). "Web service classification using
support vector machine." 22nd IEEE International
Conference on Tools with Artificial Intelligence
(ICTAI), pp. 3–6.
Innovative Technique for Classification of Web Service Quality through Machine Learning
835
