
Fraud Detection in Financial Transaction Using Advanced Analytical
Techniques
S. Md Riyaz Naik, Syed Mohammad Arif, Donthala Rakesh, Shaik Khaja Peer,
Battu Sai Deepak and Kasetty Sandeep
Department of Computer Science and Engineering, Santhiram Engineering College, Nandyal‑518501, Andhra Pradesh,
India
Keywords: Financial Transactions, Fraud, Detection, Fraudulent Activity.
Abstract: Fraud detection for financial transactions is a challenging issue that is crucial to customers, merchants and
financial service providers alike. Rule based detection that is typical cannot keep up with the increasing
complexity of fraud. A need to develop robust and scalable systems that exploit state-of-the-art technology
such as Artificial Intelligence (AI), Data Analytics (DA) and Machine Learning (ML) for this purpose are the
subject of this issue statement. A primary objective is to develop models and algorithms that are able to
accurately identify fraudulent transactions while minimizing false positives. This requires analysing large
volumes of transaction data in real-time or near-real-time to identify any suspicious trends or anomalies.
Iteach8 How do you keep the model updated with latest fraud patterns? Learning and updating must continue
since system should also evolve/respond to new types of fraud when they occur. Managing imbalanced
datasets, where fraudulent transactions are uncommon in comparison to legal ones, protecting sensitive
financial data, and keeping latency low to avoid processing delays are some of the primary issues.
1 INTRODUCTION
In the financial domain, fraud is a recurring issue,
which has been threatening the safety of people,
companies and financial institutions.
The methods and sophistication of fraud evolve
with technology and the increased digitalization of
financial services. In the last decade, due to this
ongoing threat, Financial Transaction fraud detection
has taken a significant role of interest for companies
around the world.
Fraud detection in financial transactions employs
artificial intelligence, machine learning algorithms,
and advanced analytics to identify peculiar patterns
or behaviors that may indicate fraudulent activities.
By examining enormous
Banks can quickly prevent and halt fraudulent
behavior by leveraging transaction data in real time,
protecting funds, preserving trust, and maintaining
financial stability.
Sophisticated Fraud Methods: Identity theft,
account takeover and social engineering are just a
few tactics that scammers employ to circumvent
detection systems.
Data volume and Velocity: Handling the large
volume and velocity at which financial transactions
occur in real-time presents a challenge that demands
scalable algorithms and powerful infrastructure.
False positives: In order to avoid angering
genuine customers and delivering a poor user
experience, it’s important to walk the fine line
between spotting genuine fraudulent activity and
minimizing false positives.
Financial institutions are able to quickly identify
and prevent fraud by leveraging real-time
transactional information, safeguarding funds and
trust, and maintaining the integrity of the financial
system.
Advanced Fraud Techniques: Identity theft, acco
unt takeover, and social engineering are just a few o
f the strategies that scammers use to get around dete
ction systems.
Data number and Velocity: Processing and inter
preting data in realtime is difficult due to the sheer n
umber and velocity of financial transactions, necessi
tating scalable algorithms and a strong infrastructure
False Positives: To prevent upsetting real consu
mers and creating a bad user experience, it's critical
Naik, S. M. R., Arif, S. M., Rakesh, D., Peer, S. K., Deepak, B. S. and Sandeep, K.
Fraud Detection in Financial Transaction Using Advanced Analytical Techniques.
DOI: 10.5220/0013905200004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 3, pages
765-769
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
765

to strike a balance between identifying authentic fra
udulent activity and reducing false positives.
Regulatory Compliance: While maintaining
efficient fraud detection systems, financial
institutions must abide by strict regulatory standards,
such as Know Your Customer (KYC) and anti-
money laundering (AML) laws.
Cross-Channel Fraud: As omnichannel banking
and payment systems proliferate, it becomes more
difficult to identify fraud across many platforms and
channels
.
2 REVIEW OF LITERATURE
Conventional Statistical Methods: For fraud
detection, traditional statistical techniques including
Bayesian networks, decision trees, and logistic
regression have been employed.
Among the notable papers is "Detecting
fraudulent transactions in financial data sets" by Liu,
Lai, and Ma (1999). The authors of the 2002
publication "A Survey of Credit and Behavioural
Scoring: Forecasting Financial Risk of Lending to
Consumers" were Thomas and associates.
Methods of Data Mining and Machine Learning:
These methods' capacity to manage massive data sets
and spot intricate patterns has led to their rise in
popularity. Neural networks, support vector
machines, random forests, and ensemble approaches
are examples of common algorithms.
"Credit Card Fraud Detection Using Artificial
Neural Networks" by Bhattacharyya et al. (2011) is
one of the notable papers.
The study "Credit Card Fraud Detection Using
Machine Learning: A Survey" was published in 2019
by Bhattacharyya and colleagues.
Finding Anomalies:
Finding transactions that differ
from the typical conduct of authorized users is the
main goal of anomaly detection. Autoencoders,
clustering, and statistical methods are among the
techniques.
Among the notable papers is Zhang et al.'s "Fraud
detection in financial data using unsupervised
learning" (2005).
According to Phua et al. (2007), "Credit Card
Fraud Detection: A Realistic Modeling and a Novel
Learning Strategy"
Analytics of Behavior: This method looks at trends
in behavior over time to find irregularities that could
be signs of fraud. Among the methods are user
profiling, Markov models, and sequence analysis.
One of Lee and Stolfo's notable papers is
"Detecting anomalous and unknown intrusions
against programs" (2000).
"Using Behavioral Analysis to Improve Fraud
Detection" by Axelsson (2000).
Processing streams and big data: The development
of big data technologies has made it possible to detect
fraud in real time. Scalable algorithms, distributed
computing, and stream processing frameworks are
some of the methods. Notable Papers: Kantarcioglu et
al.'s "Real-time fraud detection in high-velocity data
streams" (2008). By Jajodia et al. (2016), "Big Data
and Data Mining Challenges on Scalable and High-
Performance Cyber Threat Analytics" is discussed.
Blockchain and the Identification of
Cryptocurrency Fraud: The detection of fraud in
cryptocurrency transactions has been the focus of
research since the advent of blockchain technology.
Graph analysis, transaction pattern recognition,
and smart contract auditing are some of the methods.
Prominent Articles: Bartoletti et al.'s "Bitcoin Heist:
Topological Data Analysis for Ransomware
Detection on the Bitcoin Blockchain"(2018).
By Yli-Huumo et al. (2016), "Blockchain: A
review on applications and potential challenges"
Methods of Data Mining and Machine Learning:
The use of data mining methods and machine learning
algorithms to identify fraudulent transactions is the
subject of numerous studies. Decision trees, random
forests, support vector machines, neural networks,
and clustering algorithms are some of these
techniques. Scholars frequently investigate how well
these methods categorize authentic and fraudulent
transactions according to attributes including
transaction amounts, transaction time, location, and
user behaviour
Identifying Deviations: Anomaly detection, which
searches for deviations from normal behavior, is a
widely used technique for identifying fraudulent
transactions. This could involve statistical
techniques like clustering or Gaussian mixture
models, or more sophisticated tactics like
autoencoders in neural networks. Research in this
area frequently aims to identify novel features or
feature combinations that can improve anomaly
detection systems' accuracy.
Analyzing Behavior: Users' behavior should be in
relevant to detect purposes fraud on financial
transactions. Studies in this area are generally focused
on the analysis of behaviors (such as spending
measures, transaction frequencies, or deviations from
normal behavior). Also consider behavioral
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
766

biometrics, for example mouse movements, or
keyboard dynamics, that could potentially be
considered as fraud indicators.
For some financial fields such as banking, credit
card transactions or online payment system,
researchers develop and evaluate fraud detection
schemes and algorithms. In order to efficiently detect
and prevent fraud these systems often use a variety
of methodologies, including rule-based, machine-
learning and real-time monitoring.
Privacy and Security for Data: The challenges of
security and privacy are also the focus of research
while implementing the fraud detection systems as
the information that fraud detection analysis work
with Identifiers sensitive financial information.
Ensuring that encrypted data is protected from
leakage during detection, this work even provides
encryption and secure data sharing, also privacy
preserving analytics.
Case Studies and Evaluation Metrics: The
validation of the fraud detection methods based on
empirical data is often presented by the literature.
Performance is measured using metrics such as
accuracy, precision, recall, and false positive rate as
researchers try to determine how effective different
approaches are, and what their pros and cons might
be.
Regulations within financial transaction fraud
detection, such as those required for compliance and
best practices for fraud prevention may also be
investigated. This encompasses the conversation on
Know Your Customer (KYC) regulations, anti-
money laundering (AML) mandates and other
regulatory mechanisms intended to fight financial
fraud.
3 METHODOLOGY
Research Design: Start by outlining the general
research strategy you used for your investigation.
This could be a case study, observational,
experimental, or a mix of approaches. Justify the
design's suitability for achieving the study's goals.
Data Collection: Describe the data sources you used
for your research. Transaction logs, historical
financial data, publicly accessible information, and
synthetic data created for research purposes are a few
examples of this. Explain the data collection process,
including any sample strategies used.
Describe the procedures used to preprocess the
data prior to analysis. To get rid of duplicates,
missing numbers, or outliers, data cleaning may be
necessary. Describe any feature engineering,
normalization, or transformations that were done to
get the data ready for analysis.
Feature Engineering and Selection: Explain how
pertinent features or variables are chosen for the fraud
detection model. Describe the feature selection
criteria and any expert or subject knowledge that was
taken into account. Talk about any extra features that
were created using the raw data to improve the
model's performance.
Model Creation: Describe the statistical or machine
learning methods that were applied to create the fraud
detection model. This could involve unsupervised
learning methods (like clustering, anomaly
detection), supervised learning algorithms (like
logistic regression, decision trees, and support vector
machines), or hybrid strategies. Justify the models'
selection by stating that they are appropriate for the
problem domain.
Model Evaluation: Describe the process by which
the fraud detection model's performance was
assessed. This could involve using cross-validation
methods to evaluate the model's capacity for
generalization, including holdout validation or k-fold
cross-validation. Explain the evaluation measures
that are employed, such as area under the ROC curve
(AUC), recall, accuracy, precision, and F1-score, and
talk about how to interpret them in relation to fraud
detection.
Configuration for the Experiment: Describe the
experimental setting in full, including any model
optimization or parameter tuning that was done.
Specify any hyperparameters selected for the models
and explain the process of dividing the data into
training, validation, and test sets.
Ethical Issues: Talk about any ethical issues
pertaining to the study, such as confidentiality, data
privacy, and the possible effects of false positives or
false negatives on fraud detection. Describe how
these factors were taken into account at every stage of
the study process.
Restrictions: Recognize any restrictions or limits
imposed by the approach used in your research. This
could involve restrictions on processing resources,
assumptions made in the modeling approach, or limits
of the dataset.
Reliability and Validation:
Discuss measures taken to ensure the validity and
reproducibility of the research findings. This could
be data-sharing procedures, code accessibility, or
Fraud Detection in Financial Transaction Using Advanced Analytical Techniques
767
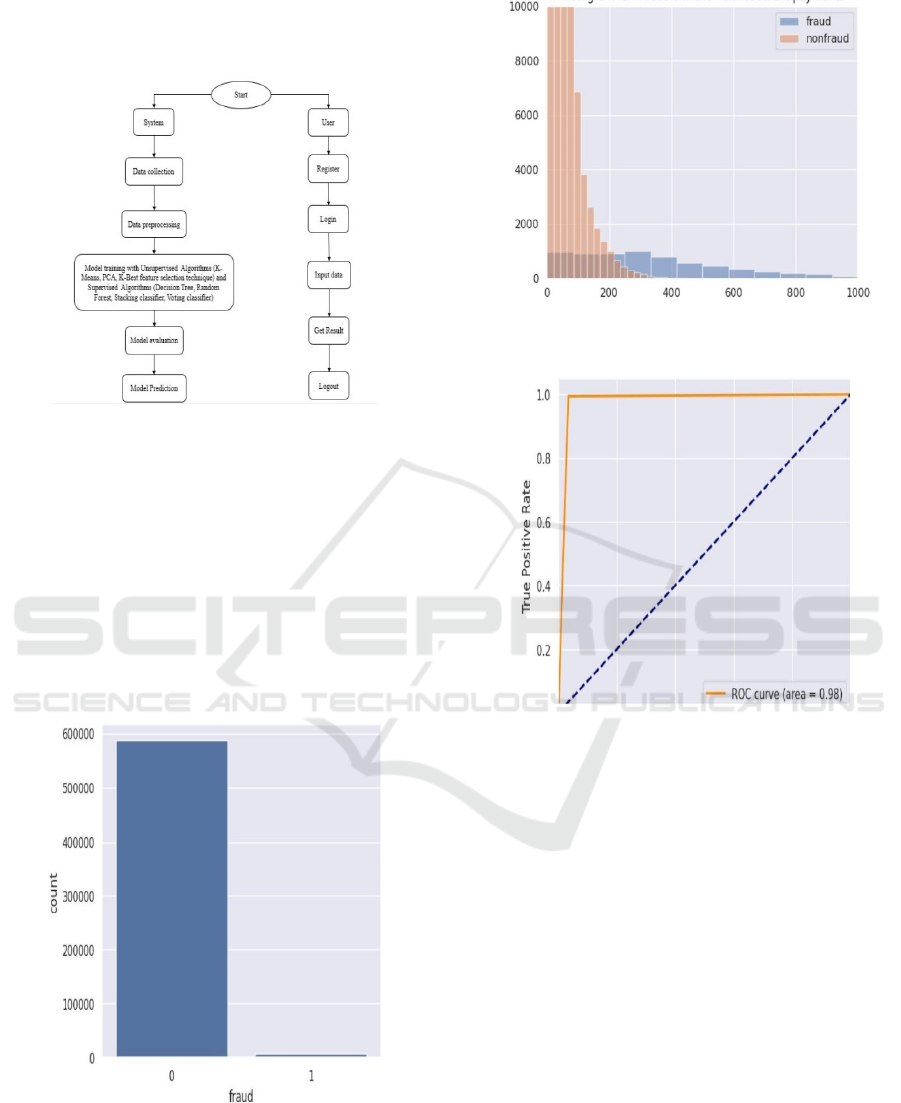
experimental procedure to allow the study to be
repeated by other scholars.
Figure 1 show the ML
System Workflow.
Figure 1: ML system workflow.
1. Gather data
2. Put data in
3. Prepare the data
4. Display the information
5. Divide the data set between testing and training.
6. Use any ML model to train the data 7. Use testing
data to assess the data.
4 EXPERIMENTAL RESULTS
Figure 2: Count of fraudulent payments.
Figure 2 show the Count of Fraudulent payments.
Figure 3: Histogram for fraudulent and non-fraudulent
payments.
Figure 4: Receiver operating characteristic (ROC) curve.
Figure 3 and 4 shows the Histogram for Fraudulent
and Non-Fraudulent Payments and Receiver Operating
characteristic (ROC) Curve respectively.
5 CONCLUSIONS
The findings of financial transaction fraud detection
highlight the vital role that data analytics and cutting-
edge technologies play in thwarting fraudulent
activity. Financial institutions can successfully spot
unusual trends and suspicious activity suggestive of
fraudulent transactions by utilizing advanced
algorithms, machine learning models, and artificial
intelligence.
Furthermore, it emphasizes the value of a multi-
pronged strategy for fraud detection that includes
behavioral analytics, predictive modeling, anomaly
detection, and real-time monitoring. Organizations
can improve their capacity to identify and stop several
forms of fraud, such as identity theft, credit card
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
768

fraud, insider trading, and money laundering, by
utilizing a combination of these strategies.
The conclusion also emphasizes how important it
is for financial institutions, regulatory organizations,
law enforcement, and other stakeholders to work
together and share information. The sector may
improve risk mitigation and fortify its collective
defenses against fraudulent activity by cultivating
relationships and sharing intelligence.
In conclusion, detecting fraud in financial
transactions is a constant task that calls for constant
creativity, teamwork, and attention to detail. In an
increasingly digital and connected world, businesses
may better protect themselves and their clients from
financial fraud by embracing cutting-edge
technologies, implementing a multi-layered strategy,
and encouraging information sharing.
REFERENCES
Alhaimer, R., Alshaheen, A., Alkhaldi, A., Malik, S., &
Lytras, M. D. (2024). Research-based evidence from
Kuwaiti higher education supports the translation of a
value-based paradigm for resilient e-learning impact in
the post-COVID-19 era. Heliyon, 10 (2).
Chaitanya, V. Lakshmi, et al. "Identification of traffic sign
boards and voice assistance system for driving." AIP
Conference Proceedings. Vol. 3028. No. 1. AIP
Publishing, 2024
Devi, M. Sharmila, et al. "Extracting and Analyzing
Features in Natural Language Processing for Deep
Learning with English Language." Journal of Research
Publication and Reviews 4.4 (2023): 497-502
In 2024, Chanane, F. Investigating Optimization
Synergies: Enhancing Rock Shear Velocity Prediction
using Neural Networks and Differential Evolution.
Knowledge and Applications in Earth Sciences,
International Journal, 6(1), 21–28.
Liu, J., and Miloud, M. O. B. (2023, April). An application
service that helps software-defined networks with
security management. Pages 129–133 of the 7th
International Conference on Cryptography, Security,
and Privacy (CSP) in 2023. IEEE.
Mahammad, Farooq Sunar, et al. "Key distribution scheme
for preventing key reinstallation attack in wireless
networks." AIP Conference Proceedings. Vol. 3028.
No. 1. AIP Publishing, 2024.
MILOUD, M. O. B., & Kim, E. Improving Cryptocurrency
Market Analysis through the Optimization of
Multivariate LSTM Networks.
Mr. Amareswara Kumar, Effective Feature Engineering
Technique for Heart Disease Prediction with Machine
Learning" in International Journal of Engineering &
Science Research, Volume 14, Issue 2, April-2024 with
ISSN 2277-2685.
Paradesi Subba Rao, "Detecting malicious Twitter bots
using machine learning" AIP Conf. Proc. 3028, 020073
(2024), https://doi.org/10.1063/5.0212693
Parumanchala Bhaskar, et al. "Incorporating Deep Learning
Techniques to Estimate the Damage of Cars During the
Accidents" AIP Conference Proceedings. Vol. 3028.
No. 1. AIP Publishing, 2024,
S. Md. Riyaz Naik, Farooq Sunar Mahammad, Mulla
Suleman. S Danish Hussain, S Waseem Akram,
Narasimha Reddy, N Naresh, "Crowd Prediction at
Various Public Places for Covid-19 Spread Prevention
Employing Linear Regres
Sunar, Mahammad Farooq, and V. Madhu Viswanatham.
"A fast approach to encrypt and decrypt of video
streams for secure channel transmission." World
Review of Science, Technology and Sustainable
Development 14.1 (2018): 11-28.
Fraud Detection in Financial Transaction Using Advanced Analytical Techniques
769
