
Winning the IPL with Data: Machine Learning Powered Match
Outcome Predictions
V. Ajitha, Jallepalli Namratha, Gangula Charitha,
Danturi Sai Manikanta and Bontha Ranjith Kumar Reddy
Department of Computer Science and Engineering (AIML), Nalla Malla Reddy Engineering College, Hyderabad,
Telangana, India
Keywords: Indian Premier League, IPL, Match Outcomes, Prediction, F1 Score, Feature Engineering, Statistics, Player
Performance, Weather Conditions, Team Data, Player Data, Match Context, External Factors.
Abstract: The challenge addressed is the prediction of match outcomes in the Indian Premier League, a prominent and
exciting Twenty20 cricket tournament. This forecast is essential for the strategic benefit of clubs, coaches,
and players, as well as for enhancing fan involvement and aiding stakeholders like as sponsors and betting
companies. Huge volumes of data are needed on statistics of each player and match results played over time,
together with environmental elements like weather conditions. Feature engineering is then undertaken to
extract relevant indicators affecting the results of a match. A combination of different machine learning
algorithms, such as decision trees, random forests, and KNN, is applied, with the F1 score acting as the key
metric for evaluation. This approach distinguishes the research from other studies by showing model
performance in projecting contradictory results characteristic of sports. Preliminary data suggest that
ensemble strategies, such as random forests, thrashed simpler tactics, earning a large F1 score that signals
better prediction reliability. The findings seem to suggest that extensive analysis of data and complex
modelling can provide a sound structure for predicting the outcome of IPL matches, which would be very
useful for the teams, spectators, and the entire sports analytics landscape. Future improvements could involve
bringing in real-time data as well as studying more relevant variables that would strengthen the validity of the
proposed model.
1 INTRODUCTION
Cricket, notably the Indian Premier League (IPL), has
developed into a worldwide spectacle, merging
sports, entertainment, and commerce into a multi-
billion-dollar industry. The IPL is more than just a
cricket competition; it is a cultural phenomenon that
involves millions of spectators, stimulates economic
growth, and encourages technology innovation. With
its dynamic structure, the IPL provides a unique
challenge for predicting match outcomes, making it a
fantastic subject for data-driven study. The potential
to precisely forecast IPL results has far-reaching
repercussions, from boosting team tactics and fan
engagement to optimizing economic decisions for
sponsors and broadcasters. However, the
unpredictability of cricket, driven by aspects such as
player performance, pitch conditions, weather, and
team chemistry, makes this undertaking difficult and
challenging. This paper explores the use of machine
learning models to forecast IPL match results, filling
the gaps in existing research and giving practical
insights for stakeholders. Machine learning, with its
ability to process enormous datasets and discover
complicated patterns, has emerged as a possible
option. However, existing research in this region is
fragmented, with limited studies concentrating
particularly on the IPL. This study intends to
overcome this gap by employing machine learning
models to predict IPL match outcomes, providing a
complete analysis of the elements that influence
results and delivering practical advice for
stakeholders.
2 LITERATURE REVIEW
The Indian Premier League is one of the most famous
professional cricket leagues in India. Many research
studies have been conducted to understand the
Ajitha, V., Namratha, J., Charitha, G., Manikanta, D. S. and Reddy, B. R. K.
Winning the IPL with Data: Machine Learning Powered Match Outcome Predictions.
DOI: 10.5220/0013904800004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 3, pages
745-749
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
745

different aspects of the IPL, including match outcome
predictions, as well as fan engagement and their
association with the players. A specific study by S
(2020) is on the prediction of IPL match results using
data mining techniques. This technique helps the
cricket match predictions and provides useful insights
to the viewers as well as stakeholders. Similarly, (Jain
et. al., 2020) proposed a strategy based on data
mining for result prediction in sports, notably
focusing on the IPL matches. Research has also
explored fan engagement and emotional attachment
to players in the IPL. Kamath et al. (2020) did a study
leveraging Twitter analytics to get insights on fans'
attachment to players in the IPL. The research showed
the value of social media in comprehending fan
behavior and preferences. Furthermore, (Sur et. al.,
2020) studied consumer discrimination in the IPL,
examining if supporters have distinct personal
preferences toward players depending on their place
of origin and religion. This study gives information
on the role of personal biases and preferences in the
context of sports fanaticism. Alongside fan
participation and match forecasts, governance in
Indian cricket has also been a topic of investigation.
Ghai et al. (2020) employed a good governance
paradigm to analyse the Board of Control for Cricket
in India (BCCI). The study explored several
components of governance inside the BCCI,
encompassing organization, communication,
standards, and policies. Moreover, the role of
machine learning and analytics in cricket has been
investigated in various research. (Kapadia et. al.,
2020) did an experimental study on sport analytics for
cricket game results utilizing machine learning
approaches. The project tries to evaluate the potential
that machine learning has for constructing cricket
match results predictors. Another research by
(Nirmala et. al., 2023) focuses on evaluating and
projecting winning IPL matches with aid of machine
learning algorithms. The research used logistic
regression techniques in forecasting match outcome
and grading players in consideration of their
performances. This work adds to the burgeoning
corpus of research on how data-driven approaches
could be applied in sports analytics. In general, the
literature on the Indian Premier League spans a wide
array of problems, including match predictions, fan
involvement, governance, and machine learning in
cricket. These studies provide essential insights to
stakeholders in the cricket business such as team
management, betting markets, and cricket enthusiasts
and also add to the current conversation regarding the
future direction of the IPL.
3 METHODOLOGY
This issue of expecting IPL match outcomes is crucial
and captivating for a lot of explanations. Firstly, exact
projections can considerably affect strategic decision
making inside teams, supporting coaches and analysts
in their choices concerning strategy, player selection,
and resource allocation for upcoming matches by
delivering data-driven insights. Additionally, the
attention of cricket fans, especially in a game as
popular as the IPL, can be considerably heightened
using predictive analytics, improving their experience
and encouraging intriguing discussions about match
outcomes. Furthermore, multiple stakeholders,
including sponsors, broadcasters, and betting
businesses, have a vested interest in match results, as
enhanced prediction accuracy can boost advertising
and promotional efforts, optimize betting odds, and
ultimately produce economic value in the sports
ecosystem.
Inputs.
Team data: Historical performance measures such
as win-loss records, average scores, and individual
player data are assessed. Recent form, including
triumphs or defeats in the last several matches, and
head-to-head performance history between the two
teams are also evaluated.
Player Data: Individual player statistics, similar as
batting averages, bowling averages, strike rates, and
wicket counts, are reviewed. Player fitness and
availability, including injuries or rest periods, are
weighed in as well.
Match Context: Venue information (home vs.
away matches), projected weather conditions on
match day, pitch qualities (historical data on how
pitches favour batting or bowling), and the team’s
playing XI are analysed.
External Factors: Recent news, off-field
difficulties, or changes in team management that
could affect team morale and performance are also
considered.
Outputs.
Predicted Winner: The output will be a binary
classification showing the anticipated winning team
(Team A or Team B) for the match based on the
examined data.
Confidence value: A probability value (0 to 1)
connected with the anticipated winner, showing the
model's confidence in its forecast.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
746

Algorithm.
To predict IPL match outcome, we use Random
Forest Classifier method. Random forest is a
supervised machine learning algorithm. With the help
of this algorithm, we can use the predictions of
several decision trees. So, this method increases
accuracy and controls overfitting. The Random Forest
method is best for the job due to the complex and
widespread density of data as well as its ability to
cope with a myriad of feature classes and
associations. The Random Forest Classifier operates
by following key steps that enhance its predictive
capability. Initially, it involves bootstrap sampling,
where random observations are selected from the
training dataset with replacement to build numerous
subsets. For each of these subgroups, a decision tree
is generated using a random subset of features at each
split, introducing unpredictability that minimizes the
correlation across the various trees. After
constructing the trees, the voting process occurs. Each
tree votes for a class label. The class that gets the
majority in a tree is selected as final output. Further,
the method evaluates the importance of features by
assessing how much uncertainty is reduced by each
item. Gini impurity and entropy are common
measures used. This method makes prediction more
accurate and also sheds light on how different factors
are contributing in the making of the decision. The
methodology comprises the following steps:
1. Data Collection. Reliable sources like
databases for IPL statistics are used for
gathering historical match data. The historical
match data consists of various match
parameters like current form, average score,
rank, and many more crucial aspects.
2. Data Preparation. The data we collect is
processed to fill in missing values, encoding
category variables, and normalization of
numerical features. The dataset is then
partitioned into training (i.e., 70%) and test
(i.e., 30%) subsets to mimic future games on
the test set.
3. Forest Creation: A specified number of
decision trees (e.g., 10) are built using
bootstrapped samples of the training data to
ensure variation among the trees.
4. Training Decision Trees: Each tree is trained
on distinct subsets of data and features. For
example, one tree might determine that if
Team A’s average score exceeds 175 and they
have more recent wins than Team B, they are
likely to win. Suppose Tree 1 finds that if
Team A's average score is above 175 and they
have more recent wins than Team B, they are
likely to win. The outcome (match result:
win/loss) serves as the dependent variable (Y).
5. Voting and Prediction: For a fresh match
prediction, we feed the new data for Team A
and Team B into the forest. For instance, if
Team A has recent wins of 5, an average score
of 180, and is of rank 1, whereas Team B has
3 recent wins, an average score of 160, and is
of rank 4, each tree will independently predict
Team A with 7 votes, Team B with 3 votes the
majority vote suggests Team A as the
anticipated winner for this match.
Pseudocode of the Random Forest Classifier:
function
RandomForestClassifier(training_data,
num_trees):
forest = []
for i from 1 to num_trees:
sample =
random_sample(training_data,
with_replacement=True)
tree =
DecisionTreeClassifier(sample,
max_features=random_subset_of_features(
))
# Add tree to the forest
forest.append(tree)
return forest
function predict (forest, test_data):
votes = []
for tree in forest:
prediction =
tree.predict(test_data)
votes.append(prediction)
# Take the majority vote
return majority_vote(votes)
function majority_vote(votes):
return mode(votes)
4 EXPERIMENTAL RESULTS
With the highest average F1 score of 0.5858, the
Random Forest (rf) model is the most reliable for this
task and performs the best. Figure 1 shows
Comparison of machine learning models for
predicting IPL match outcomes across teams,
highlighting F1 scores for each team. In contrast,
Naive Bayes is the worst-performing model,
demonstrating its inadequacy for this prediction task
with weak F1 scores where data is available (e.g.,
SRH: 0.1961) and missing values for numerous
teams. Among the teams, MI presents as the most
predictable team, with the maximum F1 score of
Winning the IPL with Data: Machine Learning Powered Match Outcome Predictions
747
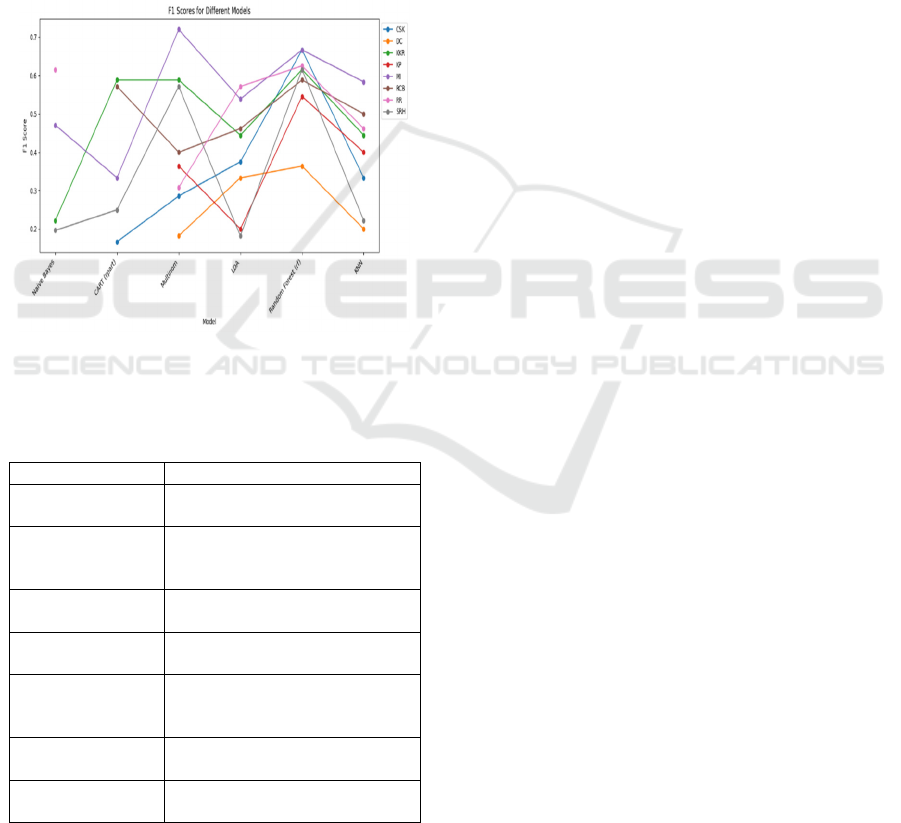
0.7200 using the Multinorm model, while SRH is the
least predictable, coping with low F1 scores across
most models. Table 1 shows Summary Table of Key
Insights. With no missing variables and an average F1
score of 0.4273 for all teams, Multinorm is the most
reliable model. Teams like CSK and MI are easy to
anticipate, performing well across various models,
however SRH and DC are tougher to predict,
presumably due to inconsistent performance or lack
of significant trends in their data. These insights
underline the necessity of employing Random Forest
(rf) for accurate predictions and imply that teams like
SRH and DC may require more advanced models or
extra data to increase prediction accuracy.
Figure 1: Comparison of machine learning models for
predicting IPL match outcomes across teams, highlighting
F1 scores for each team.
Table 1: Summary Table of Key Insights.
Insight Details
Best Model
Random Forest (rf) with an
avera
g
e F1 score of 0.5858.
Worst Model
Naive Bayes, with missing
values and low F1 scores (e.g.,
SRH: 0.1961).
Most Predictable
Team
MI (highest F1 score: 0.7200
with Multinom
)
.
Least Predictable
Team
SRH (lowest F1 scores across
most models).
Most Consistent
Model
Multinom, with no missing
values and an average F1 score
of 0.4273.
Teams with High
Predictabilit
y
CSK and MI perform well
across multiple models.
Teams with Low
Predictabilit
y
SRH and DC struggle across
most models.
5 CONCLUSIONS
The findings contribute to the increasing body of
knowledge in sports analytics by highlighting the
usefulness of machine learning in forecasting match
outcomes, particularly in a high-stakes and dynamic
setting like the IPL. Inputs like team statistics
(historical performance, recent form, head-to-head
records), player data (batting and bowling averages,
fitness status), match context (venue, weather, pitch
conditions), and external factors (team morale,
management changes) were crucial in creating strong
predictive models, which further emphasizes the
significance of feature engineering. This study has
practical implications for a number of stakeholders,
including fan engagement through data-driven
predictions, team management using the insights for
strategic planning, player selection, and resource
allocation, and businesses like betting platforms and
sponsors optimizing their strategies based on
increased prediction accuracy.
REFERENCES
A. Halder, "Capitalism and the ethics of sport governance:
a history of the board of control for cricket in India,"
Sport in Society, vol. 24, pp. 1291-1304, 2021.
A. Singh and R. Sharma, "Fan engagement on select social
media platforms: A study of the Indian Premier
League," Journal of Cultural Marketing Strategy, 2022.
B. Annamalai et al., "Social media content strategy for sport
clubs to drive fan engagement," Journal of Retailing
and Consumer Services, vol. 62, p. 102648, 2021.
C. Prakash and A. Majumdar, "Analyzing the role of
national culture on content creation and user
engagement on Twitter: The case of Indian Premier
League cricket franchises," International Journal of
Information Management, 2021.
D. P. V. Modekurti, "Setting final target score in T-20
cricket match by the team batting first," Journal of
Systems Architecture, vol. 6, pp. 205-213, 2020.
doi: 10.1109/AIMLA59606.2024.10531489.
G. B. Kamath et al., "Fans' Attachment to Players in the
Indian Premier League: Insights from Twitter
Analytics," TDIT, 2020.
G. B. Kamath et al., "Attachment Points, Team
Identification and Sponsorship Outcomes: Evidence
from the Indian Premier League," International Journal
of Sports Marketing and Sponsorship, vol. ahead-of-
print, no. ahead-of-print, Aug. 11, 2020. [Online].
Available: https://doi.org/10.1108/ijsms-01-2020-
0008. [Accessed: Nov. 23, 2020].
H. Barot et al., "Analysis and Prediction for the Indian
Premier League," in 2020 International Conference for
Emerging Technology (INCET), 2020, pp. 1-7.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
748

I. P. Wickramasinghe, "Naive Bayes approach to predict the
winner of an ODI cricket game," Journal of Sports
Analytics, 2020.
K. Kapadia, H. Abdel-Jaber, F. Thabtah, and W. Hadi,
"Sport Analytics for Cricket Game Results using
Machine Learning: An Experimental Study," 2019, vol.
18, pp. 256-266. [Online]. Available:
https://doi.org/10.1016/j.aci.2019.11.006.
M. Quazi, J. Clifford, and P. Datta, "Predicting Cricket
Outcomes using Bayesian Priors," arXiv preprint
arXiv:2203.10706, 2022.
M. Sumathi et al., "Cricket Players Performance Prediction
and Evaluation Using Machine Learning Algorithms,"
in 2023 International Conference on Networking and
Communications (ICNWC), 2023.
N. Ravichandran et al., "Optimal IPL Playing 11 Team
Selection," in 2023 IEEE 8th International Conference
for Convergence in Technology (I2CT), 2023, pp. 1-6.
P. V. Ranjith and A. Varma, "Indian Premier League –
Cricket, Entertainment or Business?" Social Science
Research Network, 2020.
P. K. Jain et al., "Sports result prediction using data mining
techniques in comparison with base line model,"
OPSEARCH, vol. 58, pp. 54-70, 2020.
P. K. Sur and M. Sasaki, "Measuring Customer
Discrimination: Evidence from the Professional Cricket
League in India," Journal of Sports Economics, vol. 21,
pp. 420-448, 2020.
P. Singh, J. Kaur, and L. Singh, "Predicting IPL Victories:
An Ensemble Modeling Approach Using
Comprehensive Dataset Analysis," in 2024 2nd
International Conference on Artificial Intelligence and
Machine Learning Applications Theme: Healthcare and
Internet of Things (AIMLA), Namakkal, India,
2024, pp. 1-6.
S. Priyanka, "Prediction of Indian Premier League-IPL
2020 using Data Mining Algorithms," International
Journal for Research in Applied Science and
Engineering Technology, vol. 8, pp. 790-795, 2020.
Y. Kumar, H. Sharma, and R. Pal, "Popularity Measuring
and Prediction Mining of IPL Team Using Machine
Learning," in 2021 9th International Conference on
Reliability, Infocom Technologies and Optimization
(Trends and Future Directions) (ICRITO), Noida,
India, 2021, pp. 15. doi: 10.1109/ICRITO51393.2021
.9596405.
Winning the IPL with Data: Machine Learning Powered Match Outcome Predictions
749
