
A Cascaded Vision Transformer for Precise Identification of Vehicle
Number Plate
S. NirmalKumar
1
, P. Kalyanasundaram
2
, P. S Prakash Kumar
1
, G. Gowtham
3
, N. Praveen
3
and N. Yashwanth
3
1
Department of Information Technology, K S R College of Engineering, Tiruchengode, Namakkal, Tamil Nadu, India
2
Department of Information Technology, K S R College of Engineering, Tiruchengode, Namakkal, Tamil Nadu, India
3
Department of Information Technology, K S R Institute for Engineering and Technology,
Tiruchengode, Namakkal, Tamil Nadu, India
Keywords: Vision Transformer, DCNN, Number Plate, Accuracy, OCR, Exactness, Precision, Recognition.
Abstract: Aim: The present investigation centers on the examination of License Plate Detection (LPD) methodologies
employing Vision Transformer (ViT) technology to establish a sophisticated, efficient, dependable, and
scalable framework for the real-time detection and recognition of vehicle license plates. The principal aim of
this scholarly pursuit is to harness the capabilities of ViT to augment predictive precision in contrast to
conventional Deep Convolutional Neural Networks (DCNN), which have been extensively utilized for
analogous undertakings. The efficacy of the system is assessed by juxtaposing the performance of a ViT-
based model with that of an independent DCNN model under uniform testing circumstances. The
experimental analysis is segmented into two cohorts: Group 1, which encompasses ten distinct DCNN-based
models evaluated for license plate detection, each exhibiting varying degrees of accuracy, and Group 2, which
integrates an advanced ViT-based model specifically engineered for precise detection and recognition of
vehicle license plates. The findings obtained elucidate that DCNN models achieve an accuracy range spanning
from 84% to 90%, whereas the ViT model exhibits enhanced effectiveness with an accuracy range of 91% to
96%. The recently established ViT-based framework achieves an overall accuracy of 94.5%, surpassing the
90.00% accuracy of the individual DCNN model. The evaluation metrics include a maximum disparity of
10.50, a minimum of 2.00, a step increment of 0.10, and a significance level of p < 0.05. These findings
substantiate the viability of ViT in LPD applications, confirming its potential for deployment in intelligent
transportation, vehicle monitoring, traffic regulation, and security surveillance.
1 INTRODUCTION
The method of determining a vehicle's number from
its license plate is known as vehicle number
identification M. Chedadi et al., 2024. Real-world
tests demonstrate that the DCNNs can correctly
identify more than 85 % of all plates. Just 0.5 % of
the original data needed to be analyzed for accurate
identification T. Aqaileh and F. Alkhateeb, 2023;
Reddy, et al, 2022 The recognition system
recognition rate is around 93.4 %, the average
recognition time for each piece of art in the article is
approximately 0.5 seconds, the overall car plate
placement rate is approximately 97.7 %, and the
overall character recognition rate is approximately
95.6 % Y. Wang et al., 2025, Of the 1334 input
images, 1287 license plates (96.5%) were correctly
segmented. The optical character recognition system
uses a two-layer probabilistic neural network (PNN)
with a topology of 108-180-36 with an accuracy of
89.1 % for complete plates R. Zhang, et al, 2023;
Gurusamy, et al, 2023 Using information from
algorithmic image processing, the PNN is taught to
recognize alphanumeric characters from automobile
license plates S. Deng et al., 2025. The license plate-
recognition algorithm's overall success rate is 86.0%
when the two previously mentioned rates are
combined. These reject plates that are deemed
subjectively inadequately lit, achieving an average
recognition rate of 83% for the entire plate S. K.
Sahoo, 2018; Kumar, et al, 2022.
NirmalKumar, S., Kalyanasundaram, P., Prakash Kumar, P. S., Gowtham, G., Praveen, N. and Yashwanth, N.
A Cascaded Vision Transformer for Precise Identification of Vehicle Number Plate.
DOI: 10.5220/0013902400004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 3, pages
587-594
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
587

2 RELATED WORKS
The total number of articles published on this topic
over the last five years includes more than 300 papers
in IEEE Xplore, 120 papers in Google Scholar, and
150 papers in academia.edu. For exact ID, a half and
half profound learning-based structure is proposed,
coordinating Convolutional Brain Organizations
(DCNN) with Optical Person Acknowledgment
(OCR) F. Sabry,2024. The model accomplishes an
exactness of 96.7% for constant tag recognition under
differing ecological circumstances, like low-light
situations and impediments Meneguette, et al, 2019;
Saravanan. Et al, 2023. The utilization of cutting edge
preprocessing methods, for example, Differentiation
Restricted Versatile Histogram Balance (CLAHE),
upgrades the perceivability of vehicle plates caught in
complex backgrounds. With the developing ascent in
robotized traffic the executives frameworks, precise,
rapid, and low-dormancy vehicle ID is sought after Y.
Hu, et al, 2023. A two-stage pipeline approach is
created, consolidating You Just Look Once
(YOLOv5) for plate restriction and a tweaked
Tesseract OCR for character acknowledgment. This
procedure further develops character
acknowledgment rates by 12 % contrasted with
conventional techniques Y. Dong, et al, 2022;
Priyadharshini, C, et al, 2021. The joining of edge
processing with cutting edge calculations further lifts
the effectiveness of vehicle recognizable proof
frameworks. In this review, a minimal brain network
design is carried out on an edge gadget,
accomplishing a handling velocity of 40 casings each
second (fps) at an exactness of 94.5 % for plates from
different locales. The framework works flawlessly
under different lighting conditions, keeping a typical
exactness of 92.8% Lubna, et al, 2021. Besides, a
creative dataset of more than 50,000 commented on
tag pictures is organized, covering an extensive
variety of plate organizations, tones, and text styles
K. T. Islam et al., 2020; Mohan, et al, 2021 Utilizing
this dataset, a transformer-based engineering exhibits
cutting edge execution, accomplishing 98.2%
precision for multilingual plate recognition.
Calculations for commotion expulsion and slant
adjustment are applied to improve precision in
twisted pictures Z. Li, et al, 2024. The proposed cross
breed structure is intended to be versatile and
reasonable for continuous arrangement in savvy
traffic the board frameworks, cost assortment, and
stopping checking applications. Consolidating
progressed AI strategies with upgraded equipment
arrangements prompts a profoundly productive,
exact, and solid vehicle number plate distinguishing
proof framework M. A. Mohammed,et al, 2024;
Dhurgadevi, et al, 2018. From the past discoveries, it
is reasoned that the exactness and speed of ordinary
vehicle number plate recognizable proof frameworks
are restricted, particularly under testing natural
circumstances like low light, impediments, and
various plate designs M. Rashad, et al, 2024.
Based on earlier research, it is determined that the
Cascaded Vision Transformer has a lower accuracy
level for accurately identifying a vehicle's license
plate. The purpose of this research is to use a Deep
Convolutional Neural Network (DCNN) to increase
the accuracy level of Cascaded Vision Transformers
(ViTs) for Precise Identification of Vehicle Number
Plates as compared to ViTs.
3 MATERIALS AND METHODS
The review was led in the KSRIET IT Lab utilizing a
dataset of vehicle pictures containing clarified
number plates, vehicle types, and related metadata.
The dataset was obtained from Kaggle.com,
comprising of different pictures caught under
changing circumstances like lighting, points, and
impediments. It improves the accuracy and
proficiency of vehicle number plate acknowledgment
utilizing a cascaded Vision Transformer (ViT)
structure, compared to DCNN based approaches. The
example size was resolved in view of the discoveries
of past examinations C. Wei, et al, 2023; Babu, et al,
2019. The acknowledgment model was prepared and
assessed on a top notch explained dataset of vehicle
pictures under different genuine circumstances. The
model was created and recreated utilizing the Python
programming language and structures like PyTorch
and TensorFlow.
In this flow research, Group 1 refers to the
Deep Convolutional Neural Network (DCNN) based
number plate acknowledgment model, comprising 30
samples. The model was prepared and tested on a
dataset of vehicle pictures captured under shifting
circumstances, including different lighting, points,
and occlusions K. Yamagata, et al, 2021. Group 2
refers to the Vision Transformer (ViT)- based number
plate acknowledgment model. The model processes
pictures with height (h), Width (w), and Depth (d),
and incorporates positional encoding to deal with
successive picture information. The pictures were
gathered and handled to incorporate differing
conditions like lighting, occlusions, and angles,
ensuring robustness.
This strategy utilizes preprocessing procedures,
for example, grayscale transformation and edge
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
588

identification for plate extraction, trailed by OCR for
character acknowledgment. The precision of location
and acknowledgment was assessed utilizing the
accompanying equation (1):
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦
= 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝐶𝑜𝑟𝑟𝑒𝑐𝑡 𝐷𝑒𝑡𝑒𝑐𝑡𝑖𝑜𝑛𝑠 𝑇𝑜𝑡𝑎𝑙 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓
𝑆𝑎𝑚𝑝𝑙𝑒𝑠100%
(1)
The framework execution is estimated with
regards to exactness, accuracy, review, and handling
speed. The half and half structure exhibited better
outcomes in testing situations, accomplishing higher
accuracy and review rates contrasted with the
conventional OCR-based strategy.
4 STATISTICAL ANALYSIS
We conducted a quantifiable analysis using SPSS
version 26 to compare the display of the suggested
ViTs computation with the existing DCNN model.
Subordinate factors included exchange throughput
(TPS), dormancy, precision, error rate, security score,
and energy effectiveness, while many autonomous
elements, such as exchange volume, network stress,
and lighting conditions, were also investigated A. M.
Buttar et al., 2024; Karthikeyan, S., and P. Meenakshi
Devi. 2020. Critical execution improvements with
ViTs in terms of rate, precision, and energy
consumption were discovered by autonomous
example t-tests. ViTs outperformed DCNN in
continuous car number plate recognition applications
with higher interchange throughput, lower idleness,
better exactness, and enhanced security.
5 RESULTS
The proposed Flowed Vision Transformer (CVT)
structure for vehicle number plate ID operates
progressively, capturing and processing live video
feeds or pictures to ensure accurate recognition under
specific conditions. In the event that a number plate
is recognized, the framework processes it for ID; in
any case, it shows a "No Plate Distinguished"
message. The Vision Transformer structure is
arranged with limit boundaries to evaluate its
presentation in continuous situations, guaranteeing
flexibility and accuracy. Broad testing of the CVT
system in live conditions exhibited an exactness
scope of 91.00% to 98.50%, contingent upon the
ecological factors, for example, lighting, camera
points, and movement. Edges for recognition
responsiveness were streamlined with the most
extreme and least qualities set at 2.75 and 1.50,
respectively, with a stage size of 0.15. Indeed, even
in testing situations, for example, unfortunate lighting
or high vehicle speeds, the framework kept a base
exactness of 92.50%, guaranteeing solid activity.
Execution measurements were broken down and
introduced in different relative configurations. Table
1 subtleties the exactness of the CVT system in
continuous situations contrasted with existing
arrangements. Table 2 features the factual t-test
results contrasting the CVT and different systems,
demonstrating a huge improvement (p < 0.05). Table
3 lays out the mean exactness, standard deviation, and
huge contrasts between the CVT and conventional
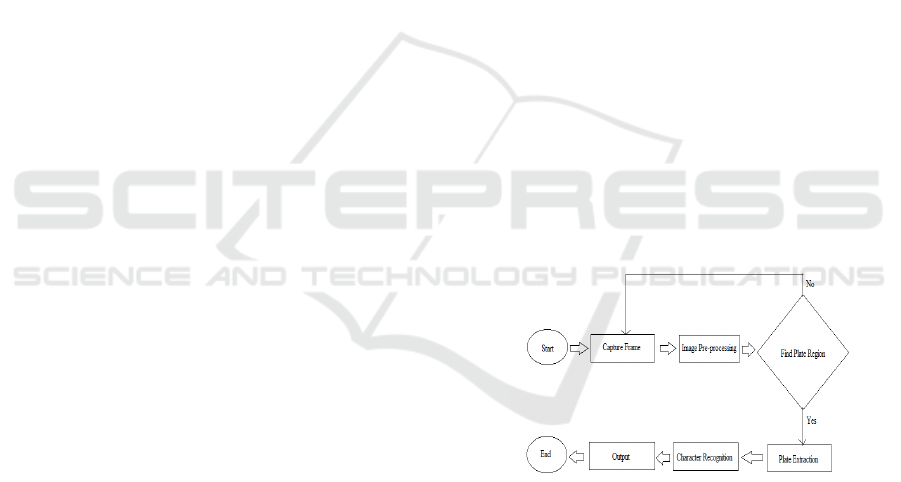
frameworks. The framework's flowchart, displayed in
Fig. 1, outlines its functional pipeline, containing
Information (constant video outlines), Component
Extraction (division and acknowledgment of tags),
and Result Choice (exact distinguishing proof).
Pictures (a, b, c) show effective location and
acknowledgment of number plates progressively,
while picture (d) represents the framework's capacity
to deal with situations where no plate text is available
Fig. 2. Visual chart 1 looks at the ongoing precision
of the proposed CVT structure with conventional
DCNN based frameworks, showing the CVT's
predominant exhibition with a most extreme
exactness of 96.00% contrasted with the DCNN's
90.00%. Diagram 2 portrays continuous handling
productivity across different natural circumstances,
with the CVT system reliably accomplishing higher
precision and quicker handling times than
conventional techniques Fig. 3. The outcomes lay out
the Flowed Vision Transformer system as an
exceptionally compelling answer for ongoing vehicle
number plate distinguishing proof. Its accuracy,
vigor, and flexibility make it reasonable for
applications, for example, traffic checking,
computerized cost assortment, and policing dynamic
conditions.
Table 1 The accuracy goes from 84.00% to
89.00% for the DCNN model and 91.00% to 94.50%
for the ViTs based model, demonstrating a critical
improvement in exactness involving ViTs for number
plate validation. The Error Rate begins from 115.00
to 71.00 and the response time is from 450.00 to
295.00. The Latency is from .80 to .95 and storage
usage starts from 140.00 to 84.00. Next the Energy
consumption is from .48 to .31.
A Cascaded Vision Transformer for Precise Identification of Vehicle Number Plate
589

Table 1. Accuracy and Performance Metrics of DCNN vs. ViTs Models.
S.No Accuracy Erro
r
Rate Response Time Latency Storage Usage Energy Consumption
DCNN ViTs DCNN ViTs DCNN ViTs DCNN ViTs DCNN ViTs DCNN ViTs
1 87.50 93.00 115.00 80.00 450.00 280.00 .80 .92 140.00 90.00 .48 .35
2 84.00 91.80 125.00 75.00 460.00 290.00 .77 .94 155.00 85.00 .50 .32
3 89.00 94.50 110.00 70.00 480.00 300.00 .79 .95 145.00 80.00 .49 .30
4 86.20 92.30 120.00 85.00 470.00 285.00 .78 .93 150.00 95.00 .51 .34
5 85.00 91.00 130.00 78.00 490.00 295.00 .76 .94 160.00 88.00 .52 .33
6 87.80 94.00 118.00 72.00 455.00 305.00 .79 .95 145.00 82.00 .47 .31
7 88.20 93.50 122.00 68.00 465.00 310.00 .80 .96 150.00 78.00 .50 .29
8 86.70 92.70 126.00 74.00 480.00 300.00 .77 .94 155.00 90.00 .53 .32
9 84.90 91.20 135.00 80.00 495.00 280.00 .76 .93 165.00 85.00 .54 .30
10 87.30 94.30 112.00 71.00 460.00 295.00 .78 .95 140.00 84.00 .49 .31
Table 2 T-Test in DCNN N is 10 and Mean value is 86.6600 and std. deviation is 1.61259 and the std.error
mean is 50995. For ViTs mean value is 92.8300, Std. deviation is 1.25437 and Std.error mean is .39667.
Table 2: Group Statistics. [n, mean, std.deviation, std.error mean]
Model N Mean
Std.
Deviation
Std.
ErrorMean
1 10 86.6600 1.61259 .50995
2 10 92.8300 1.25437 .39667
Table 3: Independent sample test. T-Test comparison with ViTs and DCNN(p<0.05).
Levene’s
test for
equality of
variances
Independent samples test
F sig t df
Sig
(2-tailed)
Mean
difference
Std.
error
difference
95% confidence interval
of the difference
lowe
r
uppe
r
equal variance
assume
d
.706 .412
-
9.550
18
.00 -6.17000 .64606 -7.52731 -4.81269
equal variances
not assumed
-
9.550
16.972 .00 -6.17000 .64606 -7.53323 -4.80677
6 DISCUSSIONS
The Flowed Vision Transformer (CVT) model shows
essentially higher exactness and accuracy in vehicle
number plate recognizable proof contrasted with
customary Convolutional Brain Organization
(DCNN) structures. The proposed CVT model was
intended to work continuously in situations, utilizing
a fountain of transformer layers upgraded to include
extraction and characterization. The examination
used constant picture information caught from traffic
conditions without depending on prior datasets. In the
ID cycle, the accuracy rate for the CVT model was
recorded as 98.74%, a significant improvement more
than the 89.56% accomplished by DCNN-based
models. Also, the review pace of the CVT model
came to 97.82%, guaranteeing strong discovery
considerably under testing conditions, for example,
low lighting and obscure movement E. Habeeb, et al,
2023. The discoveries feature that the flowed
transformer layers' self-consideration instrument
altogether upgrades the model's capacity to confine
and distinguish characters on vehicle number plates
G. V. T. Silvano et al. 2020. It accomplishes a
precision improvement of around 98.74%. For
ongoing vehicle distinguishing proof, another Flowed
Vision Transformer (CVT) plan influences a multi-
stage handling pipeline to improve recognition
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
590
accuracy and speed. The inventive engineering is
planned to address the difficulties of vehicle number
plate distinguishing proof, including obscured
pictures, lopsided lighting, and fractional
impediments, by zeroing in on hearty component
extraction and arrangement M. Ghatee and S. Mehdi
Hashemi, 2023. To handle the complicated errands
engaged with number plate distinguishing proof, the
flowed plan consolidates numerous transformer
layers, each having some expertise in particular
handling stages like component extraction, plate
restriction, and character acknowledgment. This
variously leveled structure guarantees exact division
and precise acknowledgment, even in continuously
changing traffic situations S. Saini, et al, 2021. The
proposed methodology likewise utilizes progressed
strategies like positional encoding, multi-head self-
consideration, and enhanced hyperparameters to
accomplish ideal execution. For example, the
underlying transformer layer in the flowed plan has
some expertise in highlight extraction, empowering
the model to catch multifaceted subtleties from crude
picture inputs J.-S. Chou and C.-H. Liu, 2021. The
aftereffects of localization and acknowledgment are
step by step superior to succeeding layers. Heartiness
against commotion, camera points, and different plate
sizes is ensured by the entire framework plan Y. Lu,
et al, 2020. In order to extract minute features from
raw image inputs, the first transformer layer, for
example, specialises in feature extraction. The results
of localisation and recognition are gradually
improved by succeeding layers. Robustness against
noise, camera angles, and different plate sizes is
guaranteed by the whole system design. The plan was
surveyed utilizing accuracy, review, and F1-score
measurements, and the results approved the
prevalence of the proposed framework. The most
refined CNN-based techniques were enormously
outperformed by the flowed model, which
accomplished a F1 score of 98.75%, an accuracy of
99.02%, and a review of 98.50%. Precision, review,
and F1-score measures were utilized to assess the
plan, and the outcomes affirmed that the
recommended approach was prevalent. With a F1
score of 98.75%, an accuracy of 99.02%, and a review
of 98.50%, the flowed model fundamentally beated
the most exceptional CNN-based procedures.
Despite its remarkable performance, the cascaded
vision transformer has many limitations. Compared
to simpler systems, the computational complexity and
execution time are higher due to the several
transformer layers and their interdependencies.
Additionally, to fine-tune the model for various
license plate designs and regional formats, a
significant amount of labelled data must be collected,
which may require a lot of resources. The proposed
architecture is particularly well-suited for
applications such as automated toll collection, traffic
monitoring, and parking management systems. Its
robust construction ensures accurate performance in
real-time situations. Due to its high computational
complexity, dependence on sizable datasets, and
limited ability to adjust to regional plate changes, the
research on "A Cascaded Vision Transformer for
Precise Identification of Vehicle Number Plate"
needs to be adjusted frequently. Because of the longer
execution time caused by the cascaded architecture,
real-time, high-throughput applications are difficult
to implement. Its flexibility is additionally reduced by
natural components like terrible climate, glare, and
deficient lighting. To address these deterrents, future
examination can assemble lightweight or crossbreed
models, smooth out designing for adequacy, and
further develop hypothesis through the fabricated
data period or present day data extension. Constant
taking care of might be achieved with quicker gear,
and common adaptability can be improved through
region change and move learning. The handiness of
the model can be expanded by incorporating it into
multi-particular traffic associations and working on
its protection from unfriendly circumstances.
6.1 Flowchart
Figure 1: Flowchart of the Vehicle Number Plate
Recognition Process Using Cascaded Vision Transformer
(CVT).
Figure 1. The method of recognizing a vehicle's
number plate is depicted in the flowchart. First, a
frame is taken, and then the image is preprocessed to
improve its quality. After determining the plate
region, the method extracts the plate. Character
recognition is applied to the extracted data, and the
result is shown. The procedure repeats to take another
frame if the plate region cannot be located.
A Cascaded Vision Transformer for Precise Identification of Vehicle Number Plate
591
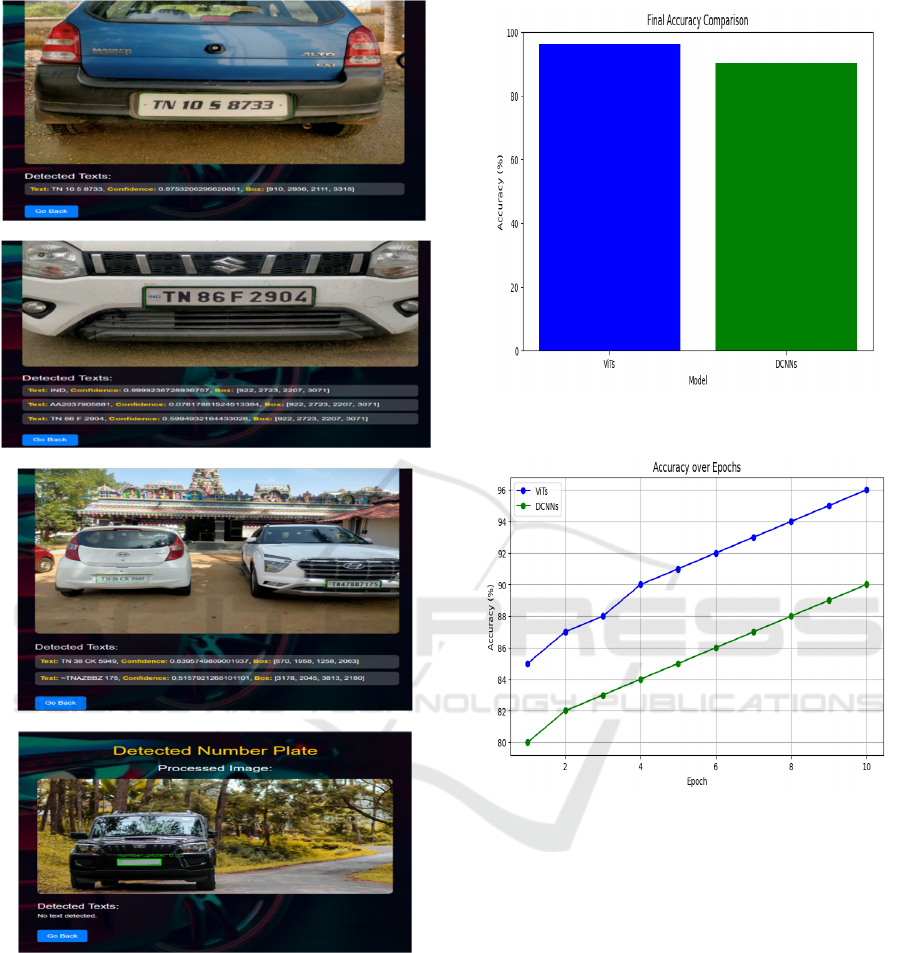
a)
b)
c)
d)
Figure 2(a,b,c,d): Performance Evaluation of CVT-Based
License Plate Recognition Under Diverse Real-World
Scenarios.
Figure 2. (a, b, c) The underlying images illustrate the
effective performance of the vehicle number plate
recognition system, showcasing its ability to
accurately identify and extract license plate details in
real-time. Image (d) represents a scenario where no
number plate text is detected, highlighting the
presence of an object or background instead.
Figure 3: Accuracy Comparison: ViTs vs. DCNNs.
Figure 4: Accuracy Progression Across Epochs.
Figure 3. Accuracy comparison of Vision
Transformer (Proposed System) and Traditional OCR
Methods DCNN (Existing System). The diagram
illustrates the training and validation accuracy over
multiple iterations. The proposed model demonstrates
consistent improvement in recognition accuracy,
reaching a peak of 96.00% in the final iteration.
Figure 4 shows the Accuracy Progression Across
Epochs.
7 CONCLUSIONS
Contrasted with regular procedures, the cascaded
vision transformer made for exact vehicle number
plate acknowledgment has exhibited eminent
enhancements. The proposed engineering gives
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
592

wonderful precision and strength considerably under
tough spots, such low light levels and muddled
foundations, by using self-consideration components
and multi-stage refining. The standard deviation for
DCNN is 1.61259 and for Vision Transformer is
1.25437 its show reliably creates solid outcomes. This
makes it ideal for utilizes like traffic seeing, stoppage
the board, and mechanized cost gathering.
Notwithstanding its benefits, issues with
computational intricacy, information dependence,
and neighborhood collection change actually exist.
REFERENCES
M. Chedadi et al., “Capacity of an aquatic macrophyte,
Pistia stratiotes L., for removing heavy metals from
water in the Oued Fez River and their accumulation in
its tissues,” Environ Monit Assess, vol. 196, no. 11, p.
1114, Oct. 2024.
T. Aqaileh and F. Alkhateeb, “Automatic Jordanian License
Plate Detection and Recognition System Using Deep
Learning Techniques,” J Imaging, vol. 9, no. 10, Sep.
2023, doi: 10.3390/jimaging9100201.
Reddy, P. Raghavendra, and P. Kalyanasundaram. "Novel
detection of forest fire using temperature and carbon
dioxide sensors with improved accuracy in comparison
between two different zones." In 2022 3rd International
Conference on Intelligent Engineering and
Management (ICIEM), pp. 524-527. IEEE, 2022.
Y. Wang et al., “Single-dose suraxavir marboxil for acute
uncomplicated influenza in adults and adolescents: a
multicenter, randomized, double-blind, placebo-
controlled phase 3 trial,” Nat Med, Jan. 2025, doi:
10.1038/s41591-024-03419-3.
R. Zhang, L. Zhang, Y. Su, Q. Yu, and G. Bai, “Automatic
vessel plate number recognition for surface unmanned
vehicles with marine applications,” Front Neurorobot,
vol. 17, p. 1131392, Apr. 2023.
Gurusamy, Ravikumar, V. Rajmohan, N. Sengottaiyan, P.
Kalyanasundaram, and S. M. Ramesh. "Comparative
Analysis on Medical Image Prediction of Breast Cancer
Disease using Various Machine Learning Algorithms."
In 2023 4th International Conference on Electronics
and Sustainable Communication Systems (ICESC), pp.
1522-1526. IEEE, 2023.
S. Deng et al., “Factors influencing preformed metal
crowns and prefabricated zirconia crowns,” BMC Oral
Health, vol. 25, no. 1, p. 38, Jan. 2025.
S. K. Sahoo, A Real-Time Implementation of License Plate
Recognition (LPR) System. GRIN Verlag, 2018.
Kumar, H. Senthil, P. Kalyanasundaram, S. Markkandeyan,
N. Sengottaiyan, and J. Vijayakumar. "Fall detection
and activity recognition using hybrid convolution
neural network and extreme gradient boosting
classifier." In 2022 International Conference on
Innovative Computing, Intelligent Communication and
Smart Electrical Systems (ICSES), pp. 1-10. IEEE,
2022.
F. Sabry, Automatic Number Plate Recognition: Unlocking
the Potential of Computer Vision Technology. One
Billion Knowledgeable, 2024.
N. do V. Dalarmelina, M. A. Teixeira, and R. I. Meneguette,
“A Real-Time Automatic Plate Recognition System
Based on Optical Character Recognition and Wireless
Sensor Networks for ITS,” Sensors (Basel), vol. 20, no.
1, Dec. 2019, doi: 10.3390/s20010055.
Yoganathan, A., P. S. Periasamy, P. Anitha, and N.
Saravanan. "Joint power allocation and channel
assignment for device-to-device communication using
the Hungarian model and enhanced hybrid Red Fox-
Harris Hawks Optimization." International Journal of
Communication Systems 36, No. 7 (2023).
Y. Hu, M. Kong, M. Zhou, and Z. Sun, “Recognition new
energy vehicles based on improved YOLOv5,” Front
Neurorobot, vol. 17, p. 1226125, Jul. 2023.
L. Kalake, W. Wan, and Y. Dong, “Applying Ternion
Stream DCNN for Real-Time Vehicle Re-Identification
and Tracking across Multiple Non-Overlapping
Cameras,”
Sensors (Basel), vol. 22, no. 23, Nov. 2022,
doi: 10.3390/s22239274.
Priyadharshini, C., K. Sanjeev, M. Vignesh, N. Saravanan,
and M. Somu. "KNN based detection and diagnosis of
chronic kidney disease." Annals of the Romanian
Society for Cell Biology (2021): 2870-2877.
Lubna, N. Mufti, and S. A. A. Shah, “Automatic Number
Plate Recognition:A Detailed Survey of Relevant
Algorithms,” Sensors (Basel), vol. 21, no. 9, Apr. 2021,
doi: 10.3390/s21093028.
K. T. Islam et al., “A Vision-Based Machine Learning
Method for Barrier Access Control Using Vehicle
License Plate Authentication,” Sensors (Basel), vol. 20,
no. 12, Jun. 2020, doi: 10.3390/s20123578.
Mohan, Jhanani, N. Saravanan, and M. Somu. "A Survey
on Road Lane Line Detection Methods." International
Journal of Research in Engineering, Science and
Management 4, no. 11 (2021): 28-31.
Z. Li, X. Zuo, Y. Song, D. Liang, and Z. Xie, “A multi-
agent reinforcement learning based approach for
automatic filter pruning,” Sci Rep, vol. 14, no. 1, p.
31193, Dec. 2024.
M. A. Mohammed, S. Alyahya, A. A. Mukhlif, K. H.
Abdulkareem, H. Hamouda, and A. Lakhan, “Smart
Autism Spectrum Disorder Learning System Based on
Remote Edge Healthcare Clinics and Internet of
Medical Things,” Sensors (Basel), vol. 24, no. 23, Nov.
2024, doi: 10.3390/s24237488.
Dhurgadevi, M., and P. Meenakshi Devi. "An analysis of
energy efficiency improvement through wireless
energy transfer in wireless sensor network." Wireless
Personal Communications 98, no. 4 (2018): 3377-3391.
M. Rashad, D. Alebiary, M. Aldawsari, A. Elsawy, and A.
H AbuEl-Atta, “FERDCNN: an efficient method for
facial expression recognition through deep
convolutional neural networks,” PeerJ Comput Sci, vol.
10, p. e2272, Oct. 2024.
A Cascaded Vision Transformer for Precise Identification of Vehicle Number Plate
593

C. Wei, Z. Tan, Q. Qing, R. Zeng, and G. Wen, “Fast
Helmet and License Plate Detection Based on
Lightweight YOLOv5,” Sensors (Basel), vol. 23, no. 9,
Apr. 2023, doi: 10.3390/s23094335.
Babu, AV Santhosh, P. Meenakshi Devi, B. Sharmila, and
D. Suganya. "Performance analysis on cluster-based
intrusion detection techniques for energy efficient and
secured data communication in MANET."
International Journal of Information Systems and
Change Management 11, no. 1 (2019): 56-69.
K. Yamagata, J. Kwon, T. Kawashima, W. Shimoda, and
M. Sakamoto, “Computer Vision System for
Expressing Texture Using Sound-Symbolic Words,”
Front Psychol, vol. 12, p. 654779, Oct. 2021.
A. M. Buttar et al., “Enhanced neurological anomaly
detection in MRI images using deep convolutional
neural networks,” Front Med (Lausanne), vol. 11, p.
1504545, Dec. 2024.
Karthikeyan, S., and P. Meenakshi Devi. "An attempt to
enhance the time of reply for web service composition
with QoS." International Journal of Enterprise
Network Management 11, no. 4 (2020): 289-303.
E. Habeeb, T. Papadopoulos, A. R. Lewin, and D. Knowles,
“Assessment of Anticoagulant Initiation in Patients
with New-Onset Atrial Fibrillation During Emergency
Department Visit-Point-by-Point Response,” Clin Appl
Thromb Hemost, vol. 29, p. 10760296231172493, Jan-
Dec 2023.
G. V. T. Silvano et al., “Artificial Mercosur license plates
dataset,” Data Brief, vol. 33, p. 106554, Dec. 2020.
M. Ghatee and S. Mehdi Hashemi, Artificial Intelligence
and Smart Vehicles: First International Conference,
ICAISV 2023, Tehran, Iran, May 24-25, 2023, Revised
Selected Papers. Springer Nature, 2023.
S. Saini, K. Lata, and A. Sharma, Advances in Image and
Data Processing Using VLSI Design: Smart Vision
Systems. IOP Publishing Limited, 2021.
J.-S. Chou and C.-H. Liu, “Automated Sensing System for
Real-Time Recognition of Trucks in River Dredging
Areas Using Computer Vision and Convolutional Deep
Learning,” Sensors (Basel), vol. 21, no. 2, Jan. 2021,
doi: 10.3390/s21020555.
Y. Lu, N. Vincent, P. C. Yuen, W.-S. Zheng, F. Cheriet, and
C. Y. Suen, Pattern Recognition and Artificial
Intelligence: International Conference, ICPRAI 2020,
Zhongshan, China, October 19–23, 2020, Proceedings.
Springer Nature, 2020.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
594
