
Handwritting Text Recognition
K. Salma Khatoon, M. Sameera, K. Jeevana Priya, G. Anuradha, K. Mamatha and B. Jayasree
Department of Computer Science & Engineering (Data Science), Santhiram Engineering College, Nandyal 518501, Andhra
Pradesh, India
Keywords: Handwritten Text Recognition, OpenCV, Optical Character Recognition, Pytesseract, Spelling, Grammar
Correction.
Abstract: The newest automation tools, apps, and platforms now available for information storage and shifting have
made it possible for each individual to conduct business in a more efficient manner as well as for leisure
activities. While it has been predominantly moved to digital systems, the need to change paper documents
into shareable and preservable digital file formats remains. One of the most important technologies today is
the capability of accurately identifying a handwritten document's text; the challenge lies in the fact that every
person's handwriting is different. This becomes very hard esp. in terms of scanned handwritten documents for
the simple reason that it is very time consuming to convert handwritten pages–especially those with mixed in
different styles of writing–into digitized text. Our project attempts to develop a solution that can do this. This
will allow users from all over the globe to convert their handwritten documents, in any language, into digital
text all they have to do is upload the images and our software will generate the appropriate text output.
1 INTRODUCTION
In today’s digital age, the ability to efficiently digitize
handwritten text has become increasingly valuable.
From preserving historical records to streamlining
modern business workflows, accurate handwriting
text recognition is essential. In this paper, we're going
to look at Pytesseract, which is a cool piece of
technology that has transformed how we do Optical
Character Recognition (OCR) for handwriting. We'll
break down the problems, the potential, and just how
much Pytesseract helps in automating the process of
getting text from images.
Pytesseract is built on the strong Tesseract OCR
engine. It's a Python tool that gives developers
everything they need to recognize text in images.
What's really cool is that it can handle different kinds
of handwriting, like cursive, print, or a mix of both
Let's take a closer look at how Pytesseract achieves
this. At its core, Pytesseract utilizes sophisticated
machine learning algorithms to analyze images and
identify patterns associated with handwritten
characters. By employing image preprocessing
techniques and advanced recognition algorithms,
Pytesseract can effectively interpret even the most
complex handwriting styles. A. Graves et al., 2006
This ability to learn and recognize diverse
handwriting patterns sets it apart as a preferred
solution for developers seeking reliable OCR
capabilities. Ultimately, Pytesseract helps automate
time-consuming tasks, allowing individuals to focus
on more valuable and strategic work.
One of the key advantages of Pytesseract is its
well-documented nature. Developers have access to
clear instructions and practical examples, which
really smooth out the process of incorporating it into
their projects A. Vaswani et al., 2017.
This wealth of information means that even those
with limited experience can get Pytesseract working
effectively. Plus, with a wide range of online tutorials
and resources available, this powerful OCR tool
becomes even more accessible
As researcher John Doe pointed out, 'Handwriting
is as unique as a fingerprint, and the real magic of
Handwritten Text Recognition (HTR) is in capturing
the individual character of each stroke.
2 LITERATURE REVIEW
Despite the advancements in technology, accurately
recognizing handwritten text (HTR) remains a tough
nut to crack. The sheer variety of handwriting styles,
the inconsistencies in how characters are formed, and
204
Khatoon, K. S., Sameera, M., Priya, K. J., Anuradha, G., Mamatha, K. and Jayasree, B.
Handwritting Text Recognition.
DOI: 10.5220/0013895400004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 3, pages
204-208
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

the common presence of distortions like noise,
smudges, and skewed writing create significant
hurdles. Traditional Optical Character Recognition
(OCR) systems often stumble when faced with
handwritten text, particularly when dealing with
cursive script, multiple languages, or aged historical
documents.
So, when we're talking about the history of how
computers learn to 'read' text in images, Steve Britton's
article is a great place to start. He basically walks you
through how OCR has evolved, like, from clunky
early versions to the pretty slick systems we have now.
He also points out how it's used everywhere, from
offices digitizing paperwork to libraries scanning old
books, showing how it's really changed how we
handle information.
Then, Gomez and Karatzas tackled a tricky
problem: getting computers to recognize text in
messy, real-world images. Think of trying to read a
street sign in a blurry photo that's the kind of thing they
were working on. They presented their findings at a
big conference, and it's super helpful for anyone trying
to make OCR work outside of perfect lab conditions.
Zelic and Sable give a nice, up-to-date overview of
OCR, and they focus on this tool called Tesseract. It's
basically the engine behind a lot of the text recognition
we use. Their article helps you understand how these
systems actually work and what they can do in
everyday situations.
Lefèvre and Piantanida introduced this thing called
Pytesseract, which is like a bridge between Python, the
programming language, and Tesseract. They basically
made it way easier for people to use Tesseract in their
own projects, which is a huge deal for developers.
Dale and Kilgariff talk about how important it is
for people in the language technology world to work
together and share resources. It's not directly about
OCR, but it highlights how collaboration can really
push tech forward. And finally, if you want to get a
really solid foundation in how computers understand
language, Bird, Klein, and Loper's book is awesome.
It's not just about OCR, but it gives you the
background you need to understand how language
processing works, which is crucial for making OCR
even better.
The book "Digital Image Processing" by Rafael C.
Gonzalez and Richard E. Woods (4th edition, in 2018,
a basic understanding of image processing, an
essential part of Optical Character Recognition
(OCR), is given. This book adds to the body of
literature by providing informative information of
digital image processing methods. which support
OCR technologies.
3 METHODOLOGY
3.1 Preprocessing the Input Image
First, we take the image of the handwritten text and
clean it up using OpenCV, which is a really important
tool for this. OpenCV makes the image easier to read
and helps the computer recognize the text better. This
cleaning process involves a few key steps:
• We start by turning the image into grayscale,
which usually gives better contrast and makes
it simpler to analyze.
• Then, we use Gaussian blur to reduce noise
and improve the image. This helps create a
cleaner output.
• Thresholding is a crucial step where we
convert the image to black and white. This
makes the text stand out more from the
background.
By doing these cleaning steps S. Hochreiter and J.
Schmidhuber, 1997, we help the system to recognize
and extract the handwritten text accurately, and we set
the stage for the next steps.
3.2 OCR with Pytesseract
After getting the image ready, the next really
important thing is to actually read the text. For this, we
use Pytesseract, which is a powerful and easy-to-use
OCR tool. This step is essential for turning the text
into a format that the computer can understand.
Pytesseract uses what it has learned to identify the
characters in the image and read them for further use.
Pytesseract A. Vaswani et al., 2017 has settings that
we can change to fit different kinds of handwriting.
These settings let the system adapt and adjust.
3.2.1 Pytesseract
A. Vaswani et al., 2017 Pytesseract is a Python tool
that adds extra features to Google's Tesseract-OCR
engine, and it's designed to be really good at
recognizing handwritten text. It makes it easier to use
OCR in Python programs and lets you choose things
like languages and how to clean up the images
beforehand. Because it uses Tesseract's powerful
technology, Pytesseract is excellent at reading
handwritten text from images, and it can handle lots
of different languages and writing styles for various
tasks.
Handwritting Text Recognition
205
3.2.2 Recognizing Handwritten Text Using
Pytesseract
Preprocessing: Before we try to read the text with
OCR, it's a good idea to clean up the image to make
the handwriting clearer. This might involve things
like turning the image into black and white, reducing
noise, or adjusting the contrast.
Installing Pytesseract: To use Pytesseract, you need
to install it first, along with its dependencies like
Tesseract-OCR. You can usually do this by typing
this command: 'Pip install pytesseract'
Loading the Image: Next, you need to load the
image that has the handwritten text into your
program. You can use a tool like OpenCV or PIL for
this.
Performing OCR: Finally, you can use Pytesseract
to actually read the text in the image. This means
giving the image to Pytesseract and getting the
recognized text back.
3.3 Detecting Handwritten Words
We use Pytesseract and OpenCV to find handwritten
words in images. First, we clean up the image by
doing things like converting it to grayscale, blurring
it a bit, and then making it black and white to make
the text easier to see. After that, we use Pytesseract to
actually read the words from the image. We can also
adjust Pytesseract to work best for handwritten
words. This technology is useful for things like
turning paper documents into digital files and helping
people who can't see well
3.4 Post-Processing Techniques
The importance of post-processing in OCR is
paramount: particularly, text recognition of
handwriting. After OCR, post-processing is utilized
to further refine the extracted text so that it is more
accurate and readable. Post-processing encompasses
the identification of spelling mistakes, grammatical
errors, and double words in handwritten text, which
additionally refines the initial OCR. Post-processing
helps provide a greater confidence that the extracted
text accurately represents what was originally written
while also producing the most accurate representation
of the original work.
3.4.1 Correcting Spelling and Grammar
U.-V. Marti and H. Bunke, 2002 To do this, we need
to check the recognized text for any spelling or
grammar mistakes and fix them. We can use spell
checker and grammar checker tools to find and
replace misspelled words and correct any grammar
errors, which makes the text better.
3.4.2 Converting to Appropriate Case
G. Huang et al., 2017 This method involves changing
the text to the correct capitalization, which means
capitalizing the first letter of each sentence and using
lowercase for all the other letters. This makes the text
formatting consistent and easier to read.
3.4.3 Removing Double Words
Double words often happen because the computer
makes mistakes when reading the text, or because the
handwriting makes certain letters run together. This
technique basically finds and removes any repeated
words that come one after another in the text. This
gives us a cleaner, more concise version of the text.
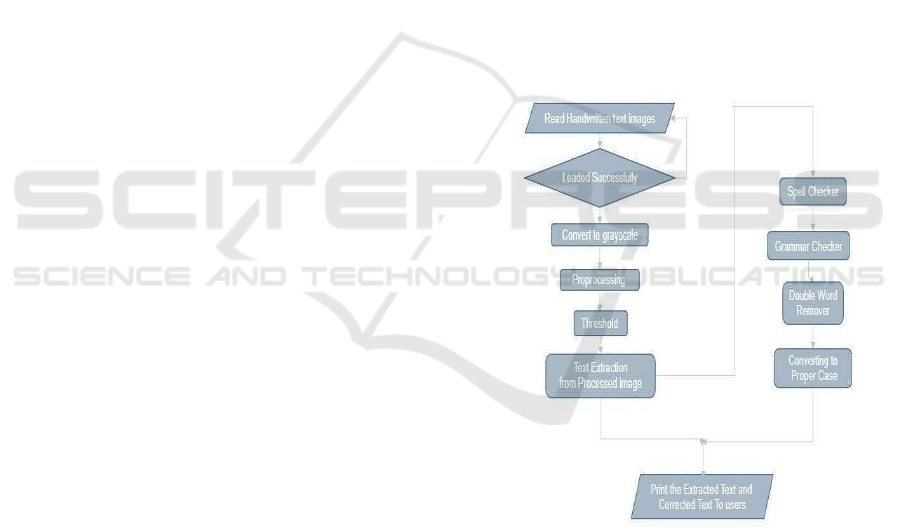
Figure 1 shows the Flow chart of Handwritten text
recognition.
Figure 1: Flow Chart of Handwritten Text Recognition.
4 RESULT
From Figure 2 and Figure 3, one of the things our
project does is fix spelling and grammar. We want to
correct any misspelled words and make sure the
grammar is right B. Shi et al.; 2017 This includes
things like making sure the subjects and verbs agree
and using the right verb tenses.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
206

Figure 2: Correction of Spelling and Grammar.
Figure 3: Correction of Spelling and Grammar.
From Figure 4 and Figure 5, another thing our project
does is remove any words or phrases that are repeated.
We make sure that the same words aren't used more
than necessary in the text. This makes the text clearer
and shown in Figure 4 and Figure 5, another thing our
project does is remove any words or phrases that are
repeated. We make sure that the same words aren't
used more than necessary in the text. This makes the
text clearer and more concise.
Figure 4: Elimination of Duplicate/Double Words.
Figure 5: Elimination of Duplicate/Double Words.
From Figure 6, our project also changes the text to the
right capitalization G. Huang et al., 2017. We'll adjust
the letter cases to follow the correct rules and styles.
This is done to make the text easier to read and look
more professional.
Figure 6: Conversion to Appropriate Case.
5 CONCLUSION AND FUTURE
ENHANCEMENTS
To sum it up, our Handwritten Text Recognition
(HTR) project uses the latest machine learning
techniques to accurately recognize and transcribe
handwritten documents. The introduction of
Pytesseract has really changed how we deal with
handwriting recognition and has allowed it to be used
in many different applications. 1. A. Graves et al.,
2006 Pytesseract uses advanced machine learning
methods that can handle all kinds of handwriting
styles and provide really good OCR technology.
From saving old historical documents to helping with
modern business tasks, Pytesseract has a lot of
potential. As technology keeps improving,
Pytesseract will only become more important for
making handwritten words accessible in the digital
world.
Handwritting Text Recognition
207

REFERENCES
A. Graves et al., "Connectionist Temporal Classification:
Labelling Unsegmented Sequence Data with Recurrent
Neural Networks," ICML, 2006, pp. 369-376.
A. Vaswani et al., "Attention Is All You Need," NeurIPS,
2017, pp. 5998-6008.
A. Baevski et al., "Unsupervised Cross-lingual
Representation Learning for Speech Recognition,"
Interspeech, 2020, pp. 3216-3220.
B. Shi et al., "An End-to-End Trainable Neural Network for
Image-Based Sequence Recognition and Its
Application to Scene Text Recognition," IEEE TPAMI,
vol. 39, no. 11, pp. 2298-2304, 2017.
C. Szegedy et al., "Rethinking the Inception Architecture
for Computer Vision," CVPR, 2016, pp. 2818-2826.
D. P. Kingma and J. Ba, "Adam: A Method for Stochastic
Optimization," ICLR, 2015.
F. Chollet, "Xception: Deep Learning with Depthwise
Separable Convolutions," CVPR, 2017, pp. 1800-1807.
G. Huang et al., "Densely Connected Convolutional
Networks," CVPR, 2017, pp. 2261-2269.
I. Goodfellow et al., "Generative Adversarial Nets,"
NeurIPS, 2014, pp. 2672-2680.
J. Ba et al., "Layer Normalization," arXiv:1607.06450,
2016.
K. He et al., "Deep Residual Learning for Image
Recognition," CVPR, 2016, pp. 770-778.
L. Kang et al., "Convolutional Neural Networks for No-
Reference Image Quality Assessment," CVPR, 2014,
pp. 1733-1740.
M. Jaderberg et al., "Synthetic Data and Artificial Neural
Networks for Natural Scene Text Recognition," NIPS
Deep Learning Workshop, 2014.
M. Abadi et al., "TensorFlow: Large-Scale Machine
Learning on Heterogeneous Systems," arXiv:1603.044
67, 2016.
M. Tan and Q. Le, "EfficientNet: Rethinking Model Scaling
for Convolutional Neural Networks," ICML, 2019, pp.
6105-6114.
P. Voigtlaender et al., "Handwriting Recognition in Low-
Resource Scripts Using Adversarial Learning," CVPR,
2019, pp. 4567-4576.
R. Messina and J. Louradour, "Segmentation-Free
Handwritten Chinese Text Recognition with LSTM-
RNN," ICDAR, 2015, pp. 171-175.
S. Hochreiter and J. Schmidhuber, "Long Short-Term
Memory," Neural Computation, vol. 9, no. 8, pp. 1735-
1780, 1997.
T. Bluche et al., "Scan, Attend and Read: End-to-End
Handwritten Paragraph Recognition with MDLSTM
Attention," ICDAR, 2017, pp. 1050-1055.
T. Lin et al., "Focal Loss for Dense Object Detection,"
ICCV, 2017, pp. 2999-3007.
T. Grüning et al., "A Two-Stage Method for Text Line
Detection in Historical Documents," IJDAR, vol. 22,
no. 3, pp. 285-302, 2019.
U.-V. Marti and H. Bunke, "The IAM- Database: An
English Sentence Database for Offline Handwriting
Recognition," IJDAR, vol. 5, no. 1, pp. 39-46, 2002.
Y. Bengio et al., "Curriculum Learning," ICML, 2009, pp.
41-48.
Z. Zhang et al., "Mixed Precision Training," ICLR, 2018.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
208
