
Innovative Machine Learning Approaches for Early Diabetes
Prediction: Enhancing Accuracy and Timeliness in Disease Detection
through Advanced Predictive Analytics
S. Prasanna
1
, S. Karimulla
2
, K. Yella Reddy
3
, K. Tharakananda
3
, P. Sateesh Kumar
3
and G. Suneel
3
1
Department of AI&DS, Annamacharya University, Rajampet, Andhra Pradesh, India
2
Department of ECE, Annamacharya Institute of Technology and Sciences, Rajampet, Andhra Pradesh, India
3
Department of AI&DS, Annamacharya Institute of Technology and Sciences, Rajampet, Andhra Pradesh, India
Keywords: Early Detection, Diabetes Prediction, Machine Learning, Random Forest, Logistic Regression, Deep
Learning, Hybrid Models, Ensemble Learning, Reinforcement Learning, Public Health.
Abstract: Detection at an early stage is important so that diabetes can be managed properly and severe complications
like heart disease, stroke, renal failure, and vision loss are avoided complication about early detection.
Currently, more than 420 million people in the world have diabetes, and it is expected that this prevalence
will continue to increase; hence there is a need for new predictive methods. Traditional diagnosis depends on
biochemical tests and clinical assessments that do not always reveal early warning signs. However, advanced
machine learning techniques present exciting alternatives by sifting through massive amounts of complex data
to find early signs of diabetes development. This study surveys multiple machine learning models: random
forests, logistic regression-nearest neighbors, decision trees, gradient boosting, LGBM deep learning
networks, hybrid models. Each model introduces unique strengths; random forests are highly robust, gradient
boosting predictive performance is maximally enhanced plus deeplearning networks are particularly
proficient in pattern recognition. Hybrid and ensemble methods are basically multiple models for higher
accuracy reinforcement learning can also adapt itself with changing data patterns. This research will use all
these diverse machine learning techniques to improve diabetic prediction's accuracy as well as speed to
eventually enhance patient outcomes along with public health strategies.
1 INTRODUCTION
Diabetes is a significant global health problem.
According to the world’s health agency, more than
420 million people worldwide have diabetes and it is
expected to increase in coming years. It’s a leading
cause of lower limb amputations, heart attacks,
strokes, kidney problems and blindness.
Growing obesity along with an aging population
and sedentary lifestyles and poor diets are all driving
a rise in diabetes. In addition to the burden of diabetes
on the individual, its associated economic costs put a
strain on healthcare systems, primarily driven by high
costs of treating and managing the disease and its
complications. Good approaches to early detection
and management are key to addressing this growing
epidemic and easing healthcare costs. Long story
short: It is hard to detect diabetes early. Traditional
diagnostic methods, such as fasting blood glucose and
oral glucose tolerance tests, might miss the disease in
its earliest stages. Such approaches usually require
lab environments, which makes them inconvenient
for patients. Also, many people with pre-diabetes or
early-stage diabetes have no symptoms, so it can be
difficult to diagnose without regular screenings. In
addition, there is an individual variation in response
to risk factors that complicates diabetes prediction.
These difficulties underscore the necessity for
better diagnostic probes that sound the alarm earlier
and with greater precision. Machine learning (ML)
Healthcare development stands to open great
opportunities for the early detection of diabetes. For
instance, machine learning in healthcare has great
potential to uncover wide
datasets and spot correlations and dependencies
that are distinguishable by traditional ways. Along
with the use of large amounts of data, ML models can
840
Prasanna, S., Karimulla, S., Reddy, K. Y., Tharakananda, K., Kumar, P. S. and Suneel, G.
Innovative Machine Learning Approaches for Early Diabetes Prediction: Enhancing Accuracy and Timeliness in Disease Detection through Advanced Predictive Analytics.
DOI: 10.5220/0013890700004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 2, pages
840-845
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

also make an advancement by the increased precision
of the prediction and Early identification by finding
of individuals at the risk before the occurrence of
clinical signs. Moreover, a combination of data
sources like genetic data, lifestyle variables, and EHRs
is used to provide a comprehensive risk evaluation.
The success of disease prediction and management
can be achieved through data modeling in health care,
therefore the outcomes are improved and the costs are
reduced. Diabetes is a metabolic condition
characterized by hyperglycemia and it occurs either
due to the lack of insulin, insulin resistance, or a
combination of the two components lasting for a
longer time. Timely detection of diabetes is necessary
for not only treating the disease but also saving lives
and avoiding complications. Early identification
enables prompt intervention through lifestyle
changes, dietary adjustments, regular exercise, and
medication. This approach can help regulate blood
sugar levels, lower complication risks, and enhance
overall well- being. Additionally, early detection
identifies individuals at elevated risk, facilitating
preventive measures to delay or even prevent diabetes
onset, thereby lessening healthcare burdens and
improving patient outcomes. Worldwide, the stats in
the area of Diabetes are still growing at an average
rate, so it follows there will be an increased demand
for the development of more accurate, efficient and
timely methods of diagnosis.
2 RELATED WORK
In trying to predict the onset of diabetes based on
clinical metrics, lifestyles and demographic data,
diabetes prediction systems typically use statistical
methods and basic machine learning algorithms like
decision trees, logistic regression, and support vector
machines. These approaches are relatively successful
but have some serious limitations. Most existing
models are trained on small homogeneous datasets
which can lead to biased predictions and low
predictive performance. The predictive performance
of traditional machine learning models is limited due
to their ineffectiveness in capturing the non- linear
complex nature of healthcare data. The data
preprocessing and feature selection steps in these
systems are typically performed manually, which
makes them susceptible to inconsistencies and human
error. Moreover, existing systems do not encompass a
comprehensive view of a patient’s health condition as
they are unable to combine and analyze information
from multiple sources such as wearables, electronic
medical records (EHRs) and patient surveys.
Generally, these systems are static; they are not
updated with new information or changing trends in
patient health, and this eventually leads to outdated
projections. And, many of the models are not
interpretable making it challenging for a medical
practitioner to understand the underlying assumptions
behind the predictions and therefore, limits its use in
clinical settings. The issues of data privacy and
security also continue to be a major concern, as many
of these systems struggle to deliver adequate data
protection solutions, resulting in compliance gaps and
the threat of information loss through data breaches.
These limitations regarding data integration,
precision, interpretability, and privacy highlight the
need for more advanced, adaptable, and secure
predictive systems for
diabetes mitigation and early
diagnosis.
3 METHODOLOGY
The method for this diabetes forecasting project is a
systematic method, that uses several different steps to
guarantee accurate and reliable results. Initially, data
is obtained from several sources such as wearable
technology, patient questionnaires, and electronic
healthcare records (EHRs) which offer a
comprehensive database about essential health metrics
including blood sugar levels, activity levels, medical
details, and lifestyle factors. After that, a proper
preparing phase is used over the data, which even
tends to clear it to get rid of mistakes, inconsistencies,
or void values that it will blur the
analysis.{‘Cleaning’ Process} Normalization is then
used to standardize the range of features to ensure that
characteristics such as age, weight and blood sugar
levels will lie in the same scale and that any single
feature does not dominate the model of numerical
values. As it turns out, the CNN model architecture is
optimized for healthcare data, including layers such as
pooling layers to down-sample data and avoid
overfitting excitation and algorithm layers such as
ReLU for nonlinearity and convolutional layers for
the highlighting. We can feed CNN preprocessed data
using SGD or Adam training, we calculate the
prediction error from back propagation to update
weights. Model evaluation is performed with metrics
like precision, recall, precision, and F1 score. Hyper
parameter tweaking minimizes the variables such as
batch size and learning rate. Finally, it continuously
applies the model to inflowing data, constantly
updating based on new information to enhance
clinical relevance and predictive performance.
Data Collection and Preprocessing The first phase
Innovative Machine Learning Approaches for Early Diabetes Prediction: Enhancing Accuracy and Timeliness in Disease Detection through
Advanced Predictive Analytics
841

involves gathering data from a number of sources
including wearable technology, patient
questionnaires and electronic medical records
(EHRs). After the data is collected, it is preprocessed
to ensure that it is ready for analysis. One of the steps
of preprocessing is data cleaning that deals with
outliers, correcting inconsistencies and removing or
imputing missing values. Normalization then makes
for consistency by bringing numerical attributes to a
common range. Feature mining extracts and
processes relevant features to match the CNN model
with the initial data.
3.1 CNN Architecture Design
The CNN model is particularly developed to handle
the complexity of healthcare data. The architecture
consists of the following key components:
•
Input Layer: Handles preprocessed data. This
layer handles
time-series data in the form of sequences of
medical readings, while static data inputs
include demographic and clinical
characteristics.
•
Convolutional Layers: These layers enhance
the model’s ability to detect patterns by
applying filters to recognize essential
components and features from the data.
•
Activation Functions: The addition of non-
linearity to functions (ReLU, for instance)
allows the model to learn complicated
patterns.
•
Pooling Layers: Down-sampling data while
keeping only the most important features
means that the number of parameters is
reduced, which lowers both computational
costs and overfitting.
•
Fully Connected Layers: This layer
combines the unrelated high-level features
into one and connects them to the fully
connected layers to predict the final output.
3.2 Model Training
Training consists of feeding the CNN model
preprocessed data and updating weight according to
prediction errors.
Training steps include:
• Loss Function: A binary cross-entropy loss
function is used to measure the difference
between expected and actual outcomes is
utilized.
• Backpropagation: Intent updates Error is
slogged through the gross- work, weights vie
changed (stochastic gradient).
• Epochs and Batches: To learn efficiently, data
is splinting batches and training occurs over
the previous epochs.
3.3 Model Evaluation
The model is validated with a different dataset upon
training, its performance is calculated on:
Accuracy: The percentage of the correct predictions.
Precision and Recall: This measures the model’s
precision positive rates identification and capture of
true predicts.
F1 Score: Balancing precision and recall the mean of
both provides us a balanced score measure.
3.4 Hyperparameter Tuning
Hyperparameters are tuned for better performance
when it comes to layer depth/depth/number of
filters/models of different sizes (non-consolidated,
storied) or learning rates or batch size et cetera This
considers testing different configurations and
choosing ones that produce the best performance on
a validation set.
3.5 Deployment and Real-Time
Processing
After training and validation, this model is placed in a
clinical environment where it continuously receives
real- time data inputs and adjusts predictions based.
This ensures accuracy and relevance, leveraging the
CNN’s capability to handle complex healthcare data
for reliable diabetes predictions. Through advanced
preprocessing, tailored CNN design, robust training,
and adaptive real-time functionality, this system aims
to improve the timeliness and precision of diabetes
detection.
4 SYSTEM IMPLEMENTATIONS
The system includes a web/mobile app for healthcare
providers to interact with, data ingestion from sources
like EHRs and IoT, preprocessing,
structured/unstructured data storage, model training
(CNN, SVM, etc.), deployment via REST APIs, real-
time prediction, analytics with dashboards, and strict
security compliant with HIPAA and GDPR. Figure 1
shows the Architecture Diagram.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
842
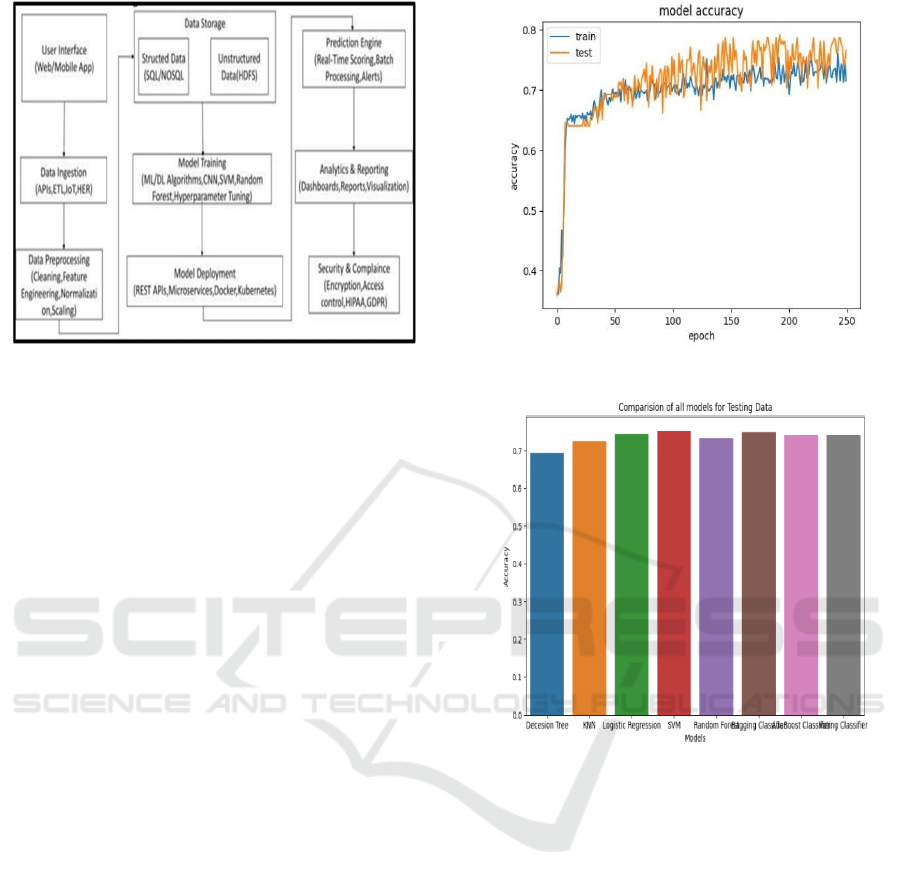
Figure 1: Architecture Diagram.
5 RESULTS
The df.info () output gives a brief overview of the
dataset stating that it has 768 rows and 9 columns:
'Pregnancies' 'Glucose' 'Blood-Pressure' 'Skin-
Thickness' 'Insulin' 'BMI' 'Diabetes- Pedigree-
Function' 'Age' and 'Out-come.' All of the columns
have non-null values indicating that there are no
missing entries in this information set. The data types
are integers (int64) and floating-point numbers
(float64) with a total memory usage of about 54.1 KB,
indicating a dataset of moderately large. The
df.describe([0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.99]). T
results gives a detailed statistical overview for each
column, with specific percentages like the 10th, 25th,
50th (median), 75th, 90th, 95th, and 99th percentiles,
along with mean, standard deviation, minimum as
well as maximum values provide information. For
example, z-scores or high standard deviation values
will signify high spread or range of data within a
column, particular percentiles represent
concentration of data and detection of outliers. It is an
important statistical summary for machine learning
data preprocessing or analysis. Finding outliers and
the distribution shapes can guide the decisions of
scale, normalization, or imputation technologies
when extreme values exist. And also insights from
df. The describe () aids in making decisions of feature
engineering techniques to boost predictive role and
aid model selection. In summary, such details help
make educated decisions regarding data
preprocessing steps involving this dataset to ensure
steady model development.
Figure 2: CNN Model Training and Testing Accuracy.
Figure 3: Comparison of Various Models.
Shows individual density plots for the different
features in a dataset (likely from a health/medical
dataset for diabetes prediction, along with diabetes
prediction). Each subplot shows a feature’s histogram
with a kernel density estimate (KDE) curve over laid
to highlight the distribution shape. Figure 2 and
Figure 3 shows the CNN models and comparison of
the models.
•
Age: Skewed to the right, with a peak around 20–
40, indicating that most individuals are in this age
range.
•
Pregnancies: Right-skewed, with most values
between 0 and 5, suggesting lower pregnancy
counts for most.
•
Glucose: Appears normally distributed, centered
around 100-150, indicating glucose levels
common to the dataset. This range represents the
typical glucose levels observed in the data.
Innovative Machine Learning Approaches for Early Diabetes Prediction: Enhancing Accuracy and Timeliness in Disease Detection through
Advanced Predictive Analytics
843

Figure 4: User Interface for Detection.
Figure 5: Predictions Based on Inputs.
A box plot illustrating the efficiency (likely accuracy)
of three distinct machine learning models Random
Forest (RF), XG- Boost (XGB), and Light-GBM is
displayed in this figure. While the horizontal axis lists
the models, the y-axis shows the performance metric,
which has values between 0.84 and 0.94. Figure 4 and
5 shows the User Interface for detection and
predictions based on inputs.
6 CONCLUSIONS
To avoid serious consequences like stroke, coronary
artery disease, renal failure and visual loss, diabetes
must be detected early. Early warning indicators are
frequently missed by conventional diagnostic
techniques like HbA1c measures and fasting blood
sugar tests. A useful substitute is machine learning
which can analyze big datasets such as clinical,
lifestyle and demographic data to find trends before a
clinical diagnosis is made. This work investigates the
potential of deep learning methods (CNNs and RNNs),
logistic regression, random forests and other machine
learning models to improve diabetes prediction.
Particularly promising are ensemble and hybrid
models which combine the advantages of several
algorithms to increase forecast accuracy and pinpoint
intricate risk variables.
7 FUTURE SCOPE
The future of diabetes prediction using machine
learning is brimming with possibilities. Enhanced
access to diverse and high-quality datasets, coupled
with advancements in model interpretability, can
make these systems more transparent and widely
adoptable in clinical settings. Furthermore,
integrating wearable technology and real-time data
analysis could enable continuous monitoring,
providing instant feedback and facilitating proactive
management of diabetes risk factors.
REFERENCES
B. Kurt, B. Gu¨rlek, S. Keskin, S. O¨ zdemir, O¨.
Karadeniz,I. B. Kırkbir, T. Kurt, S. U¨nsal, C. Kart, N.
Baki, and K. Turhan, “Prediction of gestational diabetes
using machine learning and Bayesian optimization and
traditional machine learning techniques,” Med. Biol.
Eng. Comput., vol. 61, no. 7, pp. 1649–1660, Jul. 2023.
F. Alaa Khaleel and A. M. Al-Bakry, “Diagnosis of
diabetes using ma- chine learning algorithms,” Mater.
Today, Proc., vol. 80, pp. 3200–3203, Jan. 2023.
H. El Bouhissi, R. E. Al-Qutaish, A. Ziane, K. Amroun, N.
Yaya, and M. Lachi, “Towards diabetes mellitus
prediction based on machine learning,” in Proc. Int.
Conf. Smart Comput. Appl. (ICSCA), Feb. 2023, pp. 1–
6.
H. N. Lakshmi, A. S. Reddy, and K. Naidu, “Analysis of
diabetic prediction using machine learning algorithms
on BRFSS dataset,” in Proc. 7th Int. Conf. Trends
Electron. Informat. (ICOEI), Apr. 2023, pp. 1024–
1028.
I. Shaheen, N. Javaid, N. Alrajeh, Y. Asim and S.
Aslam,”Hi-Le and HiTCLe: Ensemble Learning
Approaches for Early Diabetes Detection Using Deep
Learning and Explainable Artificial Intelligence,” in
IEEE Access, vol. 12, pp. 66516-66538, 2024, doi:
10.1109/AC- CESS.2024.3398198.
J. J. Sonia, P. Jayachandran, A. Q. Md, S. Mohan, A., K.
Sivaraman, and K. F. Tee, “Machine-learning-based
diabetes mellitus risk prediction using multi-layer
neural network no-prop algorithm,” Diagnostics, vol.
13, no. 4, p. 723, Feb. 2023.
J. Q. Toledo-Mar´ın, T. Ali, T. van Rooij, M. Go¨rges, and
W. W. Wasserman, “Prediction of blood risk score in
diabetes using deep neural networks,” J. Clin. Med.,
vol. 12, no. 4, p. 1695, Feb. 2023.
K. Abnoosian, R. Farnoosh, and M. H. Behzadi, “Prediction
of diabetes disease using an ensemble of machine
learning multi-classifier models,” BMC
Bioinformatics, vol. 24, no. 1, p. 337, 2023.
M. A. H. Saeed, “Diabetes type 2 classification using
machine learning algorithms with up-sampling
technique,” J. Electr. Syst. Inf. Technol., vol. 10, no. 1,
pp. 1–10, Feb. 2023.
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
844

O. Yakut, “Diabetes prediction using colab notebook based
machine learning methods,” Int. J. Comput. Experim.
Sci. Eng., vol. 9, no. 1, pp. 36–41, Mar. 2023.
pp. 121–130, Mar. 2024.
S. C. Shekhar and D. V. S. Rao, “Diabetes prediction using
machine learning algorithms,” Diabetes, vol. 52, no. 5,
2023.
X. Xie, J. Liu, A. Garc´ıa-Patterson, A. Chico, M. Mateu-
Salat, J. Amigo´, J. M. Adelantado, and R. Corcoy,
“Gestational weight gain in women with type 1 and type
2 diabetes mellitus is related to both general and
diabetes- related clinical characteristics,” Hormones,
vol. 23, no. 1,
Innovative Machine Learning Approaches for Early Diabetes Prediction: Enhancing Accuracy and Timeliness in Disease Detection through
Advanced Predictive Analytics
845
