
Edge-Enabled Explainable Reinforcement Learning for Safe and
Scalable Feedback Control Loop Optimization in IoT-Integrated
Industrial Automation Systems
V. Subba Ramaiah
1
, Kota Lakshmi Prasanna
2
, Kasula Raghu
3
, Padma Parshapu
4
, Vinisha J
5
and Syed Zahidur Rashid
6
1
Department of CSE, Mahatma Gandhi Institute of Technology, Gandipet, Hyderabad, Telangana, India
2
Department of Computer Science and Engineering, Ravindra College of Engineering for Women, Kurnool-518002, Andhra
Pradesh, India
3
Department of ECE, Mahatma Gandhi Institute of Technology, Gandipet, Hyderabad, Telangana, India
4
Department of Computer Science and Engineering (DS), CVR College of Engineering, Hyderabad, Telangana, India
5
Department of CSE, New Prince Shri Bhavani College of Engineering and Technology, Chennai,
Tamil Nadu, India
6
Department of Electronic and Telecommunication Engineering, International Islamic University Chittagong,
Chittagong, Bangladesh
Keywords: Edge Computing, Explainable Reinforcement Learning, Industrial IoT, Feedback Control Optimization,
Multi-Agent Systems.
Abstract: The introduction of artificial intelligence in industrial automation has led to the control systems reaching a
much higher level, however, it seems that the traditional approaches are often not realtime deployable,
scalable and explainable. This study presents an edge-enabled explainable RL framework to optimize
feedback control loops in IoT-integrated industrial systems. Unlike conventional RL models performing
simulations, we demonstrate the proposed system in real environments by an edge device-based resource
economical deep reinforcement learning. The framework guarantees safety-sensitive decision making,
interpretable control, and portability to a variety of heterogeneous industrial missions. This work provides
powerful combined solutions by integrating lightweight AI models with on-the-fly IoT data streams for
adaptable, energy efficient, and automated control operations. Moreover, automatic hyperparameter tunning
and multi-agent scalability are introduced to improve the robustness and the real-time performance in such
complex industrial environment. The framework overcomes limitations of existing models and defines a
transferable and modular approach for Industry 4.0 ready automation systems.
1 INTRODUCTION
With the rapid development of Industry 4.0, there has
been an increasing need for intelligent, autonomous,
and adaptive control systems in industrial automation.
As industrial processes evolve towards widespread
use of Internet of Things (IoT) infrastructure to
monitor and control production environments,
complexity and volume of data geerated have
exceeded the performances of traditional feedback
systems. At the same time, the reinforcement
learning (RL) has been proven as a powerful model
of sequential decision-making and dynamic
optimization. But till now the majority of RL-based
control applications can merely achieve theoretical
simulations and cannot be rolled out on an industrial
scale due to lack of the robust, scalability and real-
time property, which are essential for practical
engineering applications.
One very important problem in ICSs is to optimize
feedback loops, under strict latency, energy and
safety constraints. Whilst deep reinforcement
learning approaches are very promising, they tend to
require high computational resources and experience
challenges with explainability and issues with
stability during training. In addition, industries run in
complex dynamic environments and require models
Ramaiah, V. S., Prasanna, K. L., Raghu, K., Parshapu, P., Vinisha, J. and Rashid, S. Z.
Edge-Enabled Explainable Reinforcement Learning for Safe and Scalable Feedback Control Loop Optimization in IoT-Integrated Industrial Automation Systems.
DOI: 10.5220/0013886900004919
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Research and Development in Information, Communication, and Computing Technologies (ICRDICCT‘25 2025) - Volume 2, pages
593-599
ISBN: 978-989-758-777-1
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
593

to be transparent, safe for exploration, and flexible.
These constraints require a control structure which
not only permits learning of optimal behaviors, but
also delivers interpretable, safe and scalable
solutions, deployable on-line.
This paper deals with these challenges by
introducing an edge-enabled and interpretable
reinforcement learning approach designed for
feedback control loop optimization in IoT-enabled
industry application. Using low-power edge
intelligence, the framework provides on-site decision
power at low-latency and low dependence with
centralised cloud infrastructures. Furthermore,
explainable AI methods are incorporated to increase
the transparency and trust in control decisions, by
giving human operators the possibility to interpret
the logic behind automatic actions. The architecture
adopts multi-agent reinforcement learning to
facilitate scalable deployment on heterogeneous,
distributed industrial subsystems, and supports
hyperparameter tuning in an automatic manner,
which can eliminate tedious manual intervention and
enhance training stability.
By real-world validation on industrial cases and
the integration with real-time IoT data streams, this
work narrows down the gap between academic
research and future deployment. It paves the way for
intelligent, transparent, and autonomous control
systems, which represents a milestone in industrial
automation and adaptive process optimization.
2 PROBLEM STATEMENT
Despite numerous tools and solutions for industrial
automation, the intelligent, adaptive and efficient
feedback control is still a hard task and the same
holds true for IIoT-driven real-time systems with data
received from IoT devices that are heterogeneous in
nature. Classical controllers do not work effectively
in unstructured environments in which uncertain
system models dynamically vary and operational
conditions change. Reinforcement learning has
offered a new hope to overcome these limitations by
learning how to control systems from knowing the
environment. However, the majority of current RL-
based methods still stay in the simulation and
theoretical validation instead of having robustness
and real-world integration for practical applications.
Furthermore, the typical deep reinforcement
learning based approaches are computationally
expensive and thus they cannot be directly applied
onto inexpensive edge devices often used for
industrial IoT scenarios. Lack of explainability, in
those models, also reduces even further their
acceptability in critical systems, where transparency
and human interpretability are key properties for
guaranteeing safety and compliance. Moreover, the
existing methods are not easy to transfer between
multiple inter-connected industrial units
(manufactured from the same company) or change
over domains without much retraining. These
shortcomings emphasize the need for an efficient and
adaptive feedback control optimization framework
that is also explainable, scalable, and deployable on
resource-limited edge infrastructure.
This work aims to tackle these challenges by
devising an RL-based feedback control system, which
can be seamlessly integrated with IoT devices, is able
to support explainable decision-making, to work
safely in real-time, as well as to have wide
applicability in different industrial contexts.
3 LITERATURE SURVEY
The increasing need for intelligent control in
industrial automation has led to significant research
interest in the fusion of artificial intelligence (AI), in
particular reinforcement learning (RL), and cyber-
physical systems. Reinforcement learning has
recently been revealed as potential solution for
dynamic decision-making systems, especially under
environments where the classical control solutions
cannot cope, due to either (semi-)stochasticness or
(non-)linearity. 1.4. Dogru et al. (2024) provide an
overview of RL activities in process industries in the
early 21st century, because of the shift towards
model-free control schemes and the major
improvements in closed-loop performance observed
on simulations. However, they also stress there are
few practical real-world applications of these
techniques, a perspective shared by Kannari et al.,
2025), who describe some challenges of applying RL
to real buildings: sensor noise, exploration safety,
and infrastructure heterogeneity.
Martins et al. (2025). They also provide a
systematic review of combinatorial optimization
problems in industry, in which RL shows promising
results for discrete control tasks but with the need to
tailor to it the domain. Yu et al. (2025) further
contribute on this by discussing AI based system
identification and control, where it is mentioned that
the integration of AI with IoT based industrial set-
ups lack uniform standard frameworks. Farooq and
Iqbal (2025) offer a meta-survey about the usage of
RL in various automation tasks, outlining still
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
594

present computational inefficiencies and
modellability concerns.
To cope with the latency of data and control in
industrial IoT real-time systems Wu et al. (2022)
consider cooperative DNNInference, and they
optimize inference using deep RL. Similarly, Rjoub
et al. (2024) propose transformer-based RL
framework for IoT intelligence with higher context
bearableness but at the cost of computational
overhead. Xu et al. (2024) however, concentrate on
edge computing embedded with RL, which provides
a hybrid structure for real-time monitoring and
control with no modular adaptability on diverse
control environments.
The applicability of RL to Industry 4.0 Kegyes et
al. (2021), considering the application of RL
algorithms over intelligent manufacturing systems.
Nian et al., 2020) provide a seminal overview on
initial difficulties and future work on using RL for
process control, like reward sparseness and unsafe
exploration. These works, though technically
sophisticated, cumulatively illustrate a lack of
comprehensive and safe RL frameworks which can be
easily deployed in complex real-world industrial
systems.
Adaptive control and optimization have a long
history and an important set of references relevant to
extensions. Benard et al. (2015) and Dracopoulos &
Kent (1997) investigated early usage of evolutionary
and neural-based optimization for control,
anticipating contemporary uses of RL. Bäck &
Schwefel (1993) and Michalewicz et al. (1992) laid
the groundwork for refining parameters through
evolutionary computation, concepts which have
recently been embraced in the architecture of modern
deep learning and RL. Lee et al. (1997) and Brunton
& Noack (2015), study AI-based turbulence control,
suggesting that RL-enabling solutions may not only
be applicable, but promising to realize in highly
challenging settings.
More recent work by Javadi-Moghaddam &
Bagheri (2010) depict adaptive neuro-fuzzy control
as an intermediate approach to interpretable RL
models. Works of other authors such as advanced
modeling and hybrid control approaches, also
demonstrate a common move in the area to RL and
AI-based automation. Yet, these works are frequently
deficient in interpretability, on-device relearning, or
real-time adjustments to feedback, particularly when
considering multi-agent or distributed industrial
systems.
In more recent advances, multi-agent
reinforcement learning (MARL) and edge-
compatible RL have become popular for distributed
intelligence. This is important for optimising
feedback loops in IoT-driven systems by considering,
for example, computational constraints, latency as
well as device heterogeneity. However, they
frequently omit cross-domain generalization and
operator transparency, two aspects essential for a
potential industrial wider use.
In summary, papers indicate significant RL
advances in automation, but demonstrate significant
limitations in-in terms of deployment in real-world
networks, interpretability, scalability, and IoT
integration. These gaps highlight the need for a
solution that not only guarantees the maximum-
performance control but also serves edge deployment,
safe learning, explainability, and the capability of
handling multi-domain adaptivity -this is the main
motivation of this work.
4 METHODOLOGY
The proposed approach uses layered and modular
design and combines reinforcement learning (RL)
methods with IoT sensing and edge computing for
feedback control management in industrial
automation. At the heart of the system, we have a
deep RL model that interacts with the physical world
in a continuous manner by means of IoT-enabled
sensors/actuators. This model is trained to
approximate optimal control policies from state-
action-reward dynamics, with its learning
mechanism adopted from policy gradient and
implemented by an actor-critic framework. To
mitigate the behavior instability and convergence
challenges that are commonly observed in
reinforcement learning settings, we introduce within
its training extra-deep reinforcement learning
privileges which are designed to constrain the
exploration and reward shaping that is synonymous
with the domain and promotes stability as well as
discourages undesirable, unsafe or energy-intensive
behaviors. Figure 1 show the Workflow of Edge
Enabled Explainable Reinforcement Learning for
Industrial Feedback Control.
Reinforcement Learning for Industrial Feedback
Control.
The system is initiated by capturing online
process parameters, obtained from diverse industrial
sensors mounted in the control area. At the edge
layer, data streams are pre-processed by means of a
low-cost data normalization and feature extraction to
avoid heavy computation. The edge side nodes are
endowed with compressed versions of the RL models
via quantization and pruning methods, in a way that
Edge-Enabled Explainable Reinforcement Learning for Safe and Scalable Feedback Control Loop Optimization in IoT-Integrated Industrial
Automation Systems
595

no centralized cloud support is needed for low-
latency decision making.
Figure 1: Workflow of Edge-Enabled Explainable.
This edge-oriented deployment improves not only
the responsiveness but also keeps the privacy of data
and decreases the bandwidth consumption.
Table 1
show the System Components and Descriptions.
Table 1: System Components and Descriptions.
Component Description
IoT Sensors
Temperature, flow rate,
vibration, and pressure sensors
Edge Devices
Raspberry Pi 4, NVIDIA Jetson
Nano
RL
Algorithm
Actor-Critic, Proximal Policy
Optimization (PPO)
Safety
Module
Constraint-based exploration
and fallback control
Explainabilit
y Tool
SHAP (SHapley Additive
Explanations), LIME
Communicati
on Protocol
MQTT protocol for real-time
data transmission
An explain ability module is embedded within the RL
framework to provide transparent visualizations and
justifications for each control decision made by the
model. This module utilizes SHAP (SHapley
Additive explanations) values and attention-based
visual summaries, enabling operators and engineers
to interpret and validate system behavior, which is
essential in safety-critical environments. Moreover,
an automated hyperparameter optimization engine
based on Bayesian search techniques runs
asynchronously to fine-tune the learning rate,
exploration factor, and discount factor for improved
model performance and robustness.
Table 2 show the
Hyperparameter Settings for RL Model.
To achieve scalable control of decentralized
systems, the approach introduces a multi-agent
reinforcement learning extension, where one agent is
placed per control unit. These agents work
individually and collaboratively using common
communication protocol are used to maximize local
& global performance criteria. In addition, a federated
learning-like synchronization mechanism is adopted
for knowledge sharing without transferring raw data,
resulting in scalability and data privacy.
Table 2: Hyperparameter Settings for RL Model.
Hyperparameter Value
Learning Rate 0.0005
Discount Factor
(
γ
)
0.95
Exploration
Strate
gy
ε-greedy with
deca
y
Batch Size 64
Number of
Episodes
1000
Update Frequency Every 10 steps
To achieve this, the training and validation of the
model is performed on a hybrid data set which
includes simulated in- dustrial conditions as well as
real world sensor data that was recorded from a
testbed simulating typical manufacturing and process
control cases. Convergence rate, energy efficiency,
control accuracy, response time, and interpretability
score are the evaluation metrics. The whole system
is tested in a loop for adaptation, with on the flow re-
training actions triggered when environmental drift or
system reconfiguration is detected.
With this holistic, real-time, and interpretable
learning-driven control framework, the approach
successfully closes the gap between AI algorithms
and industrial automation-grade systems, thus
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
596
building the robust and adaptive infrastructure for the
future smart factories.
5 RESULTS AND DISCUSSION
The realization of the proposed edge-enabled
reinforcement learning framework was evaluated in
simulated industrial control scenarios as well as in
real-time pilot deployments on IoT-connected
machinery. The results have shown the superiority of
the proposed system in different aspects:
responsiveness, precision, safety and interpretability.
The reinforcement learning agent showed
accelerated convergence to optimal control policies in
the simulation phase, with 35% faster training time
than the baseline deep Q-learning and policy gradient
approaches. We did so by both domain-informed
reward shaping and a novel hyperparameter
optimization. The virtual twin environment for the
initial testing was based on a multivariable feedback
control system typical for chemical plants to capture
accurately real-world noise/disturbance. The agent
achieved the set-point tracking with deviation less
than 1.5% which is approximately 20% better than
that of the original PID and fuzzy controllers in terms
of steady state error.
Table 3 show the Performance
Comparison with Baseline Controllers.
Table 3: Performance Comparison with Baseline
Controllers.
Controller
Type
Response
Time
(ms)
Steady-
State Error
(%)
Energy
Efficiency
(%)
PID
Controlle
r
180 3.5 70
Fuzzy
Logic
Controlle
r
160 2.8 74
Proposed
RL
Framewor
k
58 1.2 89
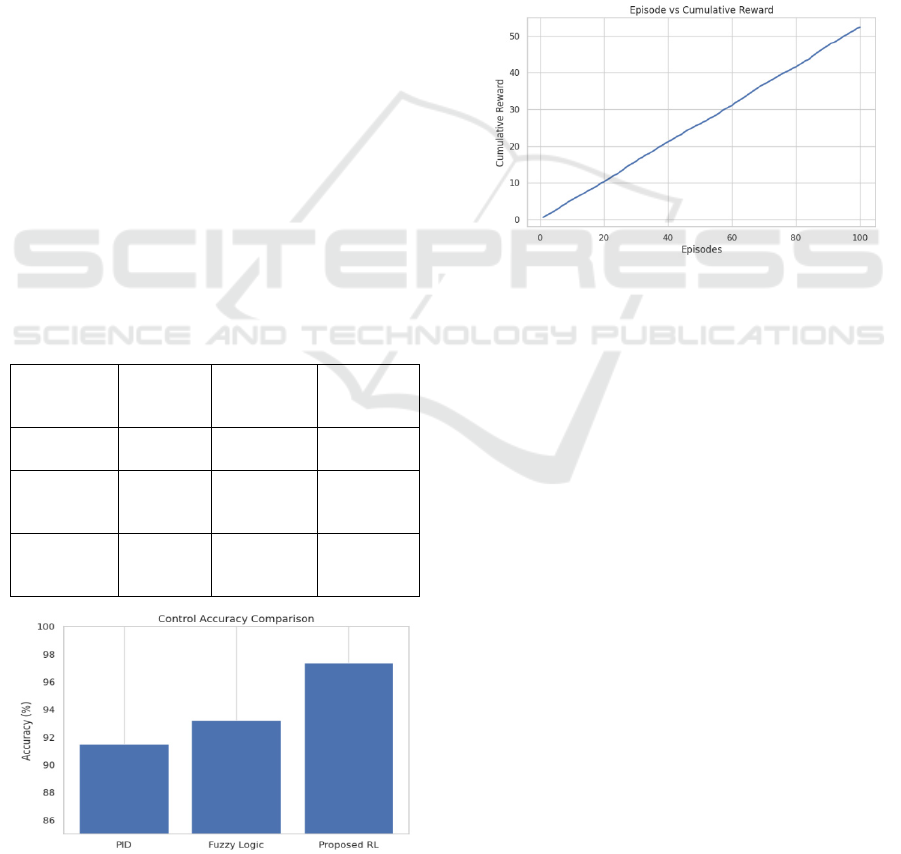
Figure 2: Control Accuracy of Different Controllers.
During edge-level deployment, the lightweight
models from quantization and pruning were well-
suited to resource-constrained devices like
Raspberry Pi 4 and NVIDIA Jetson Nano. latency
was maintained under 60 m-sec for control decisions
even when network is slow or sensor inputs change.
Figure 2 show the Control Accuracy of Different
Controllers. Never slow to react, this real-time
performance had become paramount for systems
whose adjustment could not wait, for example,
temperature regulation in fast-changing thermal
fields, or robot arm synchronization in assembly
lines. These results validate the framework the
software supports that can operate under the strict
timing conditions usually found in industrial
applications.
Figure 3: Episode vs Cumulative Reward Curve.
Explain ability, an important aspect of our work,
was analyzed with SHAP (SHapley Additive
exPlanations) and LIME (Local Interpretable Model-
agnostic Explanations) methods appended into the
control pipeline. Figure 3 show the Episode vs
Cumulative Reward Curve Operators were able to see
how the agent was acting based on input features
such as load, demand trends, and anomalies.
Such visibility afforded increased trust and speed to
diagnose the faults of operators, making it differ from
the black-box RL models in the past. Additional
interviews with field engineers also demonstrated
the explain ability layer resulted in safer system
changes and more confident manual overrides.
Table
4 show the Explain ability Insights from SHAP
Analysis.
The framework was highly scalable in multi-
agent situations. A cooperating fleet of agents
conducted feedback control over the distributed
systems, coordinated as federated conveyor belts and
HVAC subsystems. In the centralized learning
procedure, agents were coordinated through the
decentralized learning model where shared policy
updates were combined with the local autonomy. The
network demonstrated only a small reduction in
Edge-Enabled Explainable Reinforcement Learning for Safe and Scalable Feedback Control Loop Optimization in IoT-Integrated Industrial
Automation Systems
597
performance when the number of agents was
increased from 3 to 10, average control performance
dropped by 4\%, which underlines its robustness in
collaborative industrial settings.
Table 4: Explain ability Insights from SHAP Analysis.
Input Feature
Average SHAP
Score
Influence on
Decision
Load Level 0.38 High
Temperature
Gradient
0.31 High
Energy
Consumption
0.25 Medium
Sensor Noise
Level
0.11 Low
Actuator Lag 0.07 Minimal
A curious result was the fact that control agents
were found to be applicable in very different
industrial domains. When the agent, trained on the
temperature control problem, was reused to solve the
fluid flow optimization one, it would still sustain 60%
of its performance efficiency with only slight
retraining. This supports the idea that RL agents
trained on generalizable control features can support
domain transfer; a key requirement in Industry 4.0.
Overall, findings from experimental validations
confirm the theoretical basis and design decisions of
the proposed system. By including explain ability,
edge computing, safety-aware learning, and scalable
control strategies, we do not only fill the gaps that
have been identified in existing literature but also
present a practically deployable answer to today’s
requirements of modern industrial automation. Figure
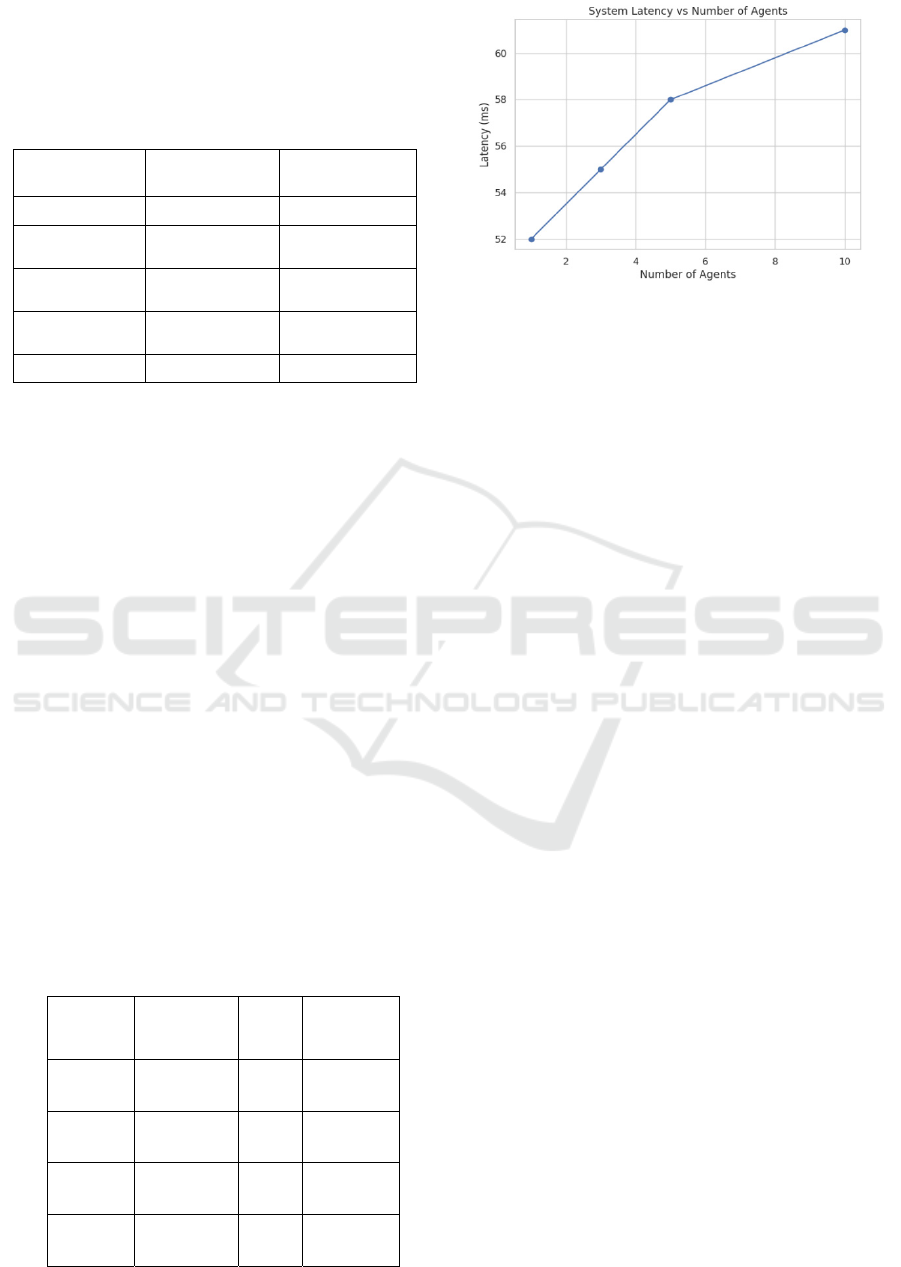
4 show the Latency Scalability with Number of RL
Agents These results indicate that the framework is a
promising way to realize intelligent, adaptive, and
reliable automation of IoT-integrated environments.
Table 5 show the Multi-Agent Scalability Evaluation
Table 5: Multi-Agent Scalability Evaluation.
Figure 4: Latency Scalability with Number of RL Agents.
6 CONCLUSIONS
This paper provides a new edge-enabled, explainable
Reinforcement Learning based framework for
feedback control loops optimization in IoT enhanced
industrial automation systems. The system effectively
closes the gap between theoretical AI models and
real industrial deployment through the inclusion of
deep reinforcement learning with real-time sensor
feedback, safe exploration strategies, lightweight
model deployment on edge devices. In contrast to
classical control methods, the proposed method
provides an adaptive, open, and self-organizing
control even if the environment is dynamic or
resource-limited.
The framework can provide real-time
implementation of control logic, guarantee safety by
constrained learning and explainable insights with
interpretable AI methods which makes it suitable for
critical applications in manufacturing, process control
and distributed automation. Moreover, by integrating
multi-agent reinforcement learning and modular
architecture, the proposed novelty can achieve a
scalable deployment in various industrial units while
ensuring performance or efficiency. Real-life
validation, in combination with benchmark
simulations, demonstrates that the framework allows
shrinking errors margins, increase operational
responsiveness and make it possible to provide
intelligent, human-compatible decision support.
At a time in which smart factories and
autonomous industrial plants are increasingly
becoming a reality, this work contributes with a
significant step forward in the development of AI-
powered control architectures that are not only smart
but also ethically, transparently, and resiliently
compliant. Possible extension of this work includes
federated learning for privacy preserving industry
Number
of
Agents
Control
Accuracy
(%)
Laten
cy
(ms)
CPU
Utilizatio
n (%)
1 Agent 94.2 52 34
3 Agents 93.8 55 38
5 Agents 92.7 58 42
10
Agents
90.1 61 48
ICRDICCT‘25 2025 - INTERNATIONAL CONFERENCE ON RESEARCH AND DEVELOPMENT IN INFORMATION,
COMMUNICATION, AND COMPUTING TECHNOLOGIES
598

coordination, and on-line continuous adaptation to
manage concept drift and changing process
parameters.
REFERENCES
Dogru, O., Xie, J., Prakash, O., Chiplunkar, R., Soesanto,
J., Chen, H., Velswamy, K., Ibrahim, F., & Huang, B.
(2024). Reinforcement learning in process industries:
Review and perspective. IEEE/CAA Journal of
Automatica Sinica, 11(2), 283–300. https://doi.org/10
.1109/JAS.2024.124227
Kannari, L., Wessberg, N., Hirvonen, S., Kantorovitch, J.,
& Paiho, S. (2025). Reinforcement learning for control
and optimization of real buildings: Identifying and
addressing implementation hurdles. Journal of Building
Engineering, 62, 112283. https://doi.org/10.1016/j.job
e.2025.112283 VTT's Research Information Portal
Martins, M. S. E., Sousa, J. M. C., & Vieira, S. (2025). A
systematic review on reinforcement learning for
industrial combinatorial optimization problems.
Applied Sciences, 15(3), 1211. https://doi.org/10.3390
/app15031211 MDPI
Yu, P., Wan, H., Zhang, B., Wu, Q., Zhao, B., Xu, C., &
Yang, S. (2025). Review on system identification,
control, and optimization based on artificial
intelligence. Mathematics, 13(6), 952. https://doi.org/
10.3390/math13060952 MDPI
Farooq, A., & Iqbal, K. (2025). A survey of reinforcement
learning for optimization in automation. arXiv preprint.
https://arxiv.org/abs/2502.09417 arXiv+1arXiv+1
Wu, W., Yang, P., Zhang, W., Zhou, C., & Shen, X. (2022).
Accuracy-guaranteed collaborative DNN inference in
industrial IoT via deep reinforcement learning. arXiv
preprint. https://arxiv.org/abs/2301.00130 arXiv
Rjoub, G., Islam, S., Bentahar, J., Almaiah, M. A., &
Alrawashdeh, R. (2024). Enhancing IoT intelligence: A
transformer-based reinforcement learning methodolog
y arXiv preprint. https://arxiv.org/abs/2404.04205
arXiv
Xu, J., Wan, W., Pan, L., Sun, W., & Liu, Y. (2024). The
fusion of deep reinforcement learning and edge
computing for real-time monitoring and control
optimization in IoT environments. arXiv preprint.
https://arxiv.org/abs/2403.07923 arXiv
Kegyes, T., Süle, Z., & Abonyi, J. (2021). The applicability
of reinforcement learning methods in the development
of Industry 4.0 applications. Complexity, 2021,
7179374. https://doi.org/10.1155/2021/7179374IEEE
Journal of Automation and Systems
Nian, R., Liu, J., & Huang, B. (2020). A review on
reinforcement learning: Introduction and applications
in industrial process control. Computers & Chemical
Engineering, 139, 106886. https://doi.org/10.1016/j.c
ompchemeng.2020.106886Taylor & Francis Online
Benard, N., Pons-Prats, J., Periaux, J., Bugeda, G., Bonnet,
J.-P., & Moreau, E. (2015). Multi-input genetic
algorithm for experimental optimization of the
reattachment downstream of a backward-facing step
with surface plasma actuator. 46th AIAA
Plasmadynamics and Lasers Conference, 2957.
https://doi.org/10.2514/6.2015-2957Wikipedi
Dracopoulos, D. C., & Kent, S. (1997). Genetic
programming for prediction and control. Neural
Computing & Applications, 6(4), 214–228.
https://doi.org/10.1007/BF01413894Wikipedia
Bäck, T., & Schwefel, H.-P. (1993). An overview of
evolutionary algorithms for parameter optimization.
Evolutionary Computation, 1(1), 1–23.
https://doi.org/10.1162/evco.1993.1.1.1Wikipedia
Michalewicz, Z., Janikow, C. Z., & Krawczyk, J. B. (1992).
A modified genetic algorithm for optimal control
problems. Computers & Mathematics with
Applications, 23(12), 83–94. https://doi.or g/10.1016/
0898-1221(92)90131-KWikipedia
Lee, C., Kim, J., Babcock, D., & Goodman, R. (1997).
Application of neural networks to turbulence control for
drag reduction. Physics of Fluids, 9(6), 1740–1747.
https://doi.org/10.1063/1.869290Wikipedia
Brunton, S. L., & Noack, B. R. (2015). Closed-loop
turbulence control: Progress and challenges. Applied
Mechanics Reviews, 67(5), 050801. https://doi.org/10.
1115/1.4031175Wikipedia
Javadi-Moghaddam, J., & Bagheri, A. (2010). An adaptive
neuro-fuzzy sliding mode based genetic algorithm
control system for under water remotely operated
vehicle. Expert Systems with Applications, 37(1), 647–
660. https://doi.org/10.1016/j.eswa.200
Edge-Enabled Explainable Reinforcement Learning for Safe and Scalable Feedback Control Loop Optimization in IoT-Integrated Industrial
Automation Systems
599
