
Elevating Data Science Maturity: Toward a Process Model that
Harnesses MLOps
Christian Haertel
1 a
, Daniel Staegemann
1 b
, Matthias Pohl
2 c
and Klaus Turowski
1 d
1
Magdeburg Research and Competence Cluster VLBA, Otto-von-Guericke-University, Magdeburg, Germany
2
Institute of Data Science, German Aerospace Center (DLR), Jena, Germany
Keywords:
Data Science, Project Management, Machine Learning, MLOps.
Abstract:
Data Science (DS) uses advanced analytical methods, such as Machine Learning, to extract value from data to
improve organizational performance. However, numerous DS projects fail due to the complexity and difficulty
of handling various managerial and technical challenges. Because of shortcomings in existing DS methodolo-
gies, new standardized approaches for DS project management are needed that respect both the business and
data perspectives. In this paper, the concept for a DS process model to address common problems in DS,
including a low level of process maturity and a lack of reproducibility, is outlined. This artifact is developed
using the Design Science Research methodology and relies on MLOps principles to support the development
and operationalization of the analytical artifacts in DS projects.
1 INTRODUCTION
With the prospect of improving firm performance
in various aspects by extracting valuable knowledge
from data (M
¨
uller et al., 2018; Wamba et al., 2017;
Chen et al., 2012), Data Science (DS) has attracted
significant interest. DS constitutes an interdisci-
plinary field, involving a complex socio-technical
process (Sharma et al., 2014; Thiess and M
¨
uller,
2018), different technologies (Haertel et al., 2023b),
and diverse competencies (Holtkemper and Beecks,
2024). Unfortunately, most DS projects fail (Venture-
Beat, 2019; Hotz, 2024), indicating a low maturity
in DS for many organizations. According to G
¨
okalp
et al. (2021), achieving success in DS initiatives re-
quires managing organizational and technical aspects
and their various challenges, including poor team co-
ordination, reproducibility, and low process maturity
(Martinez et al., 2021).
Hence, effective project management (PM) is con-
sidered fundamental for positive project outcomes,
especially in DS (Martinez et al., 2021; Saltz and
Shamshurin, 2016). The particularities of DS ne-
cessitate dedicated DS methodologies for its unique
a
https://orcid.org/0009-0001-4904-5643
b
https://orcid.org/0000-0001-9957-1003
c
https://orcid.org/0000-0002-6241-7675
d
https://orcid.org/0000-0002-4388-8914
tasks and skillsets. While multiple DS process mod-
els (e.g., CRISP-DM) from academic and industry
backgrounds are available (Haertel et al., 2022), the
literature suggests several shortcomings, imposing
the need for new standardized approaches (Saltz and
Krasteva, 2022). Beyond their underutilization in real
DS projects, aspects such as the definition of roles
and responsibilities, dependency on certain service
providers, and reproducibility stand out as worth im-
proving in contemporary DS process models (Mar-
tinez et al., 2021; Schulz et al., 2020).
Furthermore, PM encompasses more than plan-
ning, budgeting, solving conflicts, and managing re-
quirements (Iriarte and Bayona, 2020; G
¨
okay et al.,
2023) and also extends to supporting technical facets
of the undertaking (Haertel et al., 2023b). In DS, this
relates to advanced analytics like Machine Learning
(ML), which are often leveraged to gain value from
data (Rahlmeier and Hopf, 2024). Yet, the develop-
ment, deployment, and maintenance of ML is a diffi-
cult venture, suffering from poor traceability, (data)
quality assurance (Sculley et al., 2015), and a lack
of automation (Kreuzberger et al., 2023). Nonethe-
less, guidance for analytics is often neglected in cur-
rent DS process models (Martinez et al., 2021). For
these aspects, ML Operations (MLOps) is a promis-
ing paradigm that extends the DevOps principles
(Symeonidis et al., 2022) to DS to support the cre-
ation of mature, efficient, and robust ML systems by
550
Haertel, C., Staegemann, D., Pohl, M. and Turowski, K.
Elevating Data Science Maturity: Toward a Process Model that Harnesses MLOps.
DOI: 10.5220/0013841000004000
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2025) - Volume 2: KEOD and KMIS, pages
550-557
ISBN: 978-989-758-769-6; ISSN: 2184-3228
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

leveraging principles such as data, model, and code
versioning, workflow orchestration, Continuous Inte-
gration (CI), Deployment (CD), and Training (CT)
(Kreuzberger et al., 2023).
Generally, an effective methodology for DS
management should cover the areas of project, team,
data, and information management (Martinez et al.,
2021). Therefore, we argue that the incorporation of
MLOps into a standardized DS lifecycle workflow
that prescribes common tasks, deliverables, and
defines team roles and responsibilities can mitigate
common managerial and technical challenges and
thus contribute to increasing maturity in DS. Yet,
despite its potential, to the best of our knowledge, no
process model for DS currently integrates MLOps
principles to guide analytical model building, op-
erationalization, and maintenance. Therefore, the
following research question (RQ) is formulated:
RQ: How can a Data Science process model
be designed that incorporates MLOps principles to
improve end-to-end Data Science maturity?
Such an artifact can provide valuable contribu-
tions for scholars and practitioners. For the former,
the development of a holistic DS process model fea-
turing the integration of MLOps principles addresses
a significant gap in the academic body of knowledge.
Furthermore, DS practitioners can apply this artifact
to manage DS initiatives since it aims to address both
organizational and technical process aspects.
The rest of the manuscript is structured as follows.
After introducing the methodology and the theoreti-
cal foundation for this research, typical DS challenges
and avenues to address them are discussed. This es-
tablishes the basis for the concept of the MLOps-
based DS process model, which is presented in de-
tail in the fifth section. The paper closes with an out-
look on the next steps for progressing this research
endeavor in the future, emphasizing artifact formal-
ization and evaluation.
2 METHODOLOGY
To ensure rigor, the Design Science Research (DSR)
methodology is adopted (Hevner et al., 2004). In par-
ticular, we rely on the DSR approach of Peffers et al.
(2007), encompassing a nominal process of six stages
for the design, development, and evaluation of an ar-
tifact. Taking a problem-centered entry point, the first
stage involves problem identification.
Problem Identification and Motivation. The high
failure rate in conducting DS initiatives (Hotz, 2024)
is attributed to numerous managerial and technical
difficulties, including a low level of process matu-
rity, poor team coordination, a lack of knowledge re-
tention, reproducibility, quality assurance checks, and
low data quality (Martinez et al., 2021). While mul-
tiple DS process models can be found in the litera-
ture (Haertel et al., 2022), these methodologies dis-
play several flaws (Martinez et al., 2021) in providing
sufficient support for addressing common DS chal-
lenges. Hence, the call for new approaches for DS
PM (Saltz and Krasteva, 2022) indicates a low matu-
rity in DS.
Objectives of a Solution. Accordingly, an artifact in
this regard should primarily contribute to standardiz-
ing and consistently implementing DS processes, as
the success of DS projects depends, inter alia, on the
comprehensive management of their managerial and
technical aspects (G
¨
okalp et al., 2021). Consequently,
the frequently encountered issues, which are detailed
in the next section, need to be addressed (Haertel
et al., 2023a; Martinez et al., 2021) by the solution
to support DS project execution.
Design and Development. Therefore, this research
aims to develop a DS process model that tackles the
aforementioned obstacles and contributes to improv-
ing end-to-end DS maturity. This artifact is designed
by integrating a standardized DS project workflow,
including common tasks, team roles and responsibili-
ties, and deliverables with MLOps principles from the
literature. In DSR terms, the artifact is characterized
as a method, since it offers ”actionable instructions
that are conceptual” (Peffers et al., 2012). A draft of
this artifact is described in the fifth section.
Demonstration. To showcase the applicability of the
artifact for addressing the problem, it will be demon-
strated through various DS case studies in the future.
Evaluation. To verify the suitability of the arti-
fact to fulfill the formulated objectives, the evalu-
ation of the proposed method is conducted accord-
ing to the Build-Evaluate pattern of Sonnenberg and
vom Brocke (2012), consisting of ex ante and ex post
evaluation activities. In particular, evaluation crite-
ria such as feasibility, clarity, understandability, com-
pleteness, and effectiveness need to be considered to
assess the artifact’s asserted contribution (knowledge
claims) (Larsen et al., 2025). Thus, we will mainly
rely on case studies and expert feedback from practi-
tioners with different roles in the context of DS.
Communication. The intermediate and completed
results of this research endeavor are and will be dis-
seminated to different scientific outlets.
Elevating Data Science Maturity: Toward a Process Model that Harnesses MLOps
551

3 THEORETICAL BACKGROUND
First, key terminology needs to be clarified. DS de-
notes the interdisciplinary field that aims to synthe-
size ”useful knowledge directly from data through a
process of discovery or of hypothesis formulation and
hypothesis testing“ (Chang and Grady, 2019). The
concept of maturity, generally understood as a mea-
sure of the quality of an organization’s operations in
a certain domain, can also be applied to DS. In this
context, DS maturity indicates how well an organi-
zation standardizes and consistently implements DS
processes (G
¨
okalp et al., 2021). To support DS initia-
tives in this regard, DS process models aim to provide
a chronological and logical sequence of stages, tasks,
and best practices. For example, based on the work
of Haertel et al. (2022), a DS project can be roughly
structured into six stages, as shown in Figure 1.
As the entry point, Business Understanding in-
volves a situation assessment, defining project ob-
jectives, forming a project team, and creating a
project plan. Next, the Data Collection, Exploration
and Preparation phase includes data acquisition, ex-
ploratory analysis, and consequent data preparation.
This leads to the Analysis stage, where analytical
models are developed and assessed based on the DS
objectives. Here, the process of extracting knowl-
edge from large datasets typically requires advanced
analytics techniques like ML (Rahlmeier and Hopf,
2024). ML encompasses algorithms that learn from
training data to uncover hidden insights and com-
plex patterns without explicit programming (Janiesch
et al., 2021; Bishop, 2006). This capability enables
reliable, data-driven decisions across various applica-
tions. Evaluation reviews whether the models meet
the initial business goals. For a positive checkpoint
decision, Deployment entails planning, testing, and
implementing the analytical artifacts into the produc-
tion environment, depending on the type of DS prod-
uct. Utilization includes monitoring and maintenance
tasks (Haertel et al., 2022).
Recently, MLOps emerged as a paradigm that in-
cludes best practices, concepts, and cultural aspects
for the end-to-end implementation and scalability of
ML products (Kreuzberger et al., 2023). MLOps is
based on key DevOps principles (Symeonidis et al.,
2022) that are extended to the analytics domain. For
example, CI/CD is in place for build, test, deliv-
ery, and deployment steps for data and ML pipelines,
enabling automation together with a workflow or-
chestration engine. Components such as a source
code repository, feature store, metadata store, and
model registry implement versioning of data, mod-
els, and code in addition to ensuring reproducibility
and traceability of processes (e.g., for ML experi-
ments) (Kreuzberger et al., 2023). While CI/CD han-
dle the deployment of the ML pipelines, in produc-
tion, Continuous Monitoring (CM) periodically eval-
uates ML components (data, model, and infrastruc-
ture) to detect quality issues (Makinen et al., 2021)
like concept drift, which denotes changes between in-
put data and the target variables that occur over time
(Gama et al., 2014), potentially necessitating peri-
odic retraining (Continuous Training (CT)) on new
data (Kreuzberger et al., 2023). MLOps can be im-
plemented at varying maturity and automation lev-
els, with Google defining three degrees of MLOps
(Kazmierczak et al., 2024).
4 DATA SCIENCE CHALLENGES
AND THEIR MITIGATION
STRATEGIES
DS projects often fail to reach a successful conclu-
sion (Hotz, 2024), which is, inter alia, attributed to
challenges related to PM, team management, and data
and information management (Martinez et al., 2021).
Therefore, to improve the maturity in DS, frequently
encountered obstacles need to be addressed by a DS
PM approach (Martinez et al., 2021; Haertel et al.,
2023a). In the following, some key issues in DS and
propositions to mitigate them are discussed. The first
subsection focuses on aspects related to the project
and team. Afterward, data- and information-centric
obstacles are addressed.
4.1 Process Maturity and Team
Coordination
While several DS process models can be found in
gray and academic literature, various shortcomings
are evident, undermining the availability of integral
DS methodologies (Kutzias et al., 2023; Martinez
et al., 2021; Schulz et al., 2020). According to an ex-
tensive survey of DS process models, many method-
ologies underrepresent management tasks, and con-
crete deliverables for the individual DS tasks are lack-
ing (Haertel et al., 2022). Consequently, in practice,
lots of DS projects are managed ad-hoc and forego
the use of DS methodologies to support the execution
(Kutzias et al., 2023). Accordingly, a fundamental
prerequisite of a DS process model to address the low
level of process maturity is a well-defined DS lifecy-
cle workflow to determine which and how tasks need
to be performed throughout the initiative (Martinez
et al., 2021).
KMIS 2025 - 17th International Conference on Knowledge Management and Information Systems
552
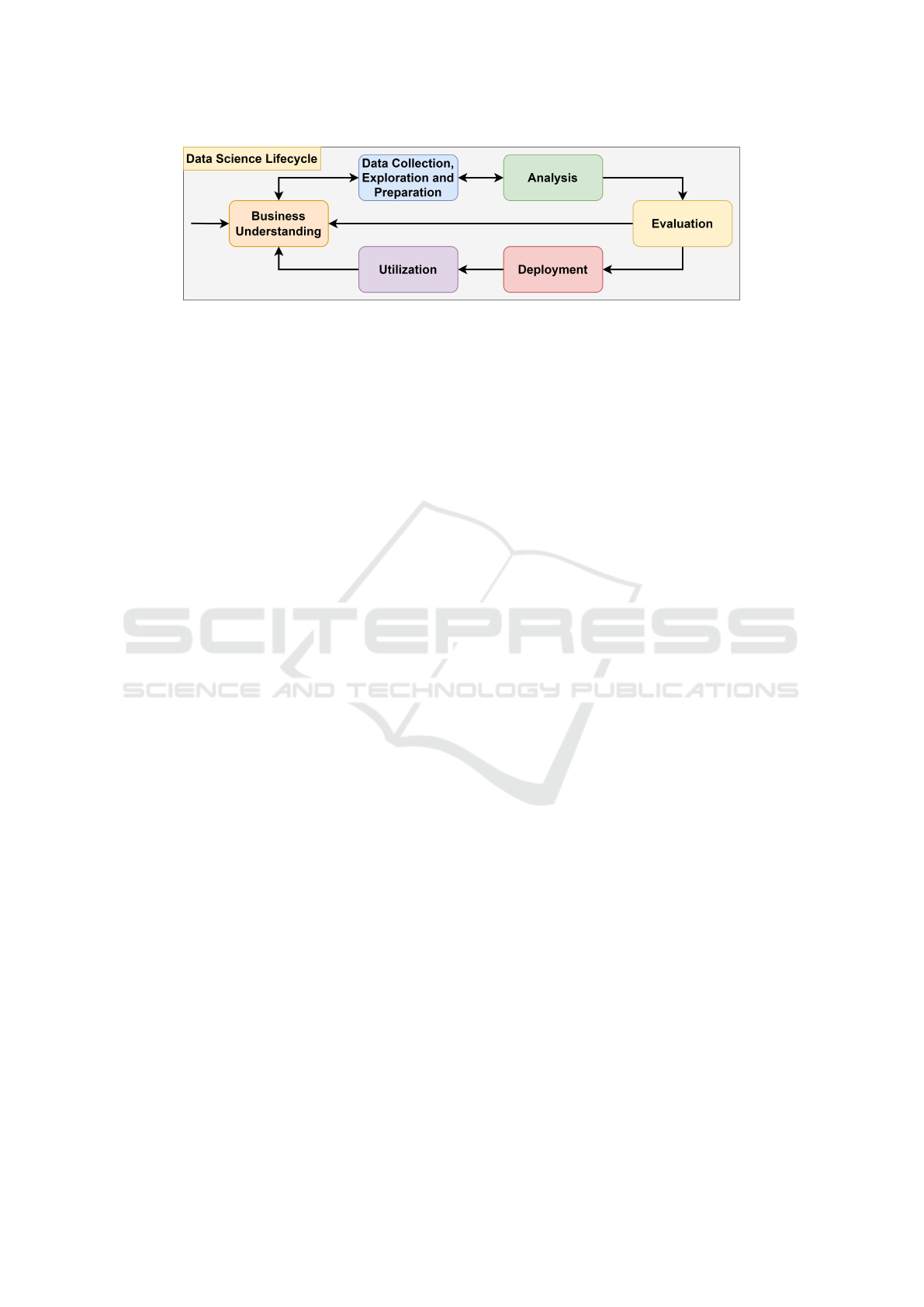
Figure 1: Data Science Lifecycle, adapted from Haertel et al. (2022).
Due to the variety and complexity of DS tasks,
diverse competencies are required in a DS team
(Holtkemper and Beecks, 2024), and effective coor-
dination is crucial (Martinez et al., 2021). As defin-
ing team roles and responsibilities is considered inte-
gral in PM (Mishra et al., 2022), DS process models
should also cover this aspect. However, most method-
ologies (e.g., CRISP-DM), do not adequately address
roles and responsibilities throughout the DS lifecycle
(Haertel et al., 2022; Saltz and Krasteva, 2022). Tra-
ditionally, the Data Scientist has been the key figure
in DS, requiring a diverse skillset (e.g., Data Anal-
ysis, Data Engineering, software development, PM,
domain knowledge) (Demchenko et al., 2016), which
is rarely consolidated in one individual (Schumann
et al., 2016). Accordingly, a DS methodology needs
to account for team coordination between different,
interdisciplinary actors (Martinez et al., 2021). As
the literature features a plethora of job profiles related
to DS and their specific demand can differ depend-
ing on project scope and scale, or industry, it is sen-
sible to define broader DS role categories that cover
the general responsibilities necessary across the DS
lifecycle. Therefore, typical DS team role groups are
Domain Expertise, Strategy & Project Management,
Data Management & Analysis for aspects around data
access, exploration, and preparation, Data Infrastruc-
ture & Operations responsible for the technological
basis for data analyses and all modeling activities,
and Analytical Modeling, which is leading the devel-
opment and evaluation of ML models (Haertel et al.,
2025). To facilitate team coordination with a process
model, the individual DS workflow tasks need to be
assigned to the respective responsible actors.
4.2 Reproducibility and Analytical
Models
In many DS process models, a guiding framework for
analytics (i.e., ML) is only superficially covered, and
vendor dependencies aggravate adoptability (e.g., Mi-
crosoft’s Team DS Process) (Martinez et al., 2021).
Building ML models, which involves data input, fea-
ture extraction, model construction, and assessment
(Janiesch et al., 2021), can be complicated, with nu-
merous pitfalls (Kreuzberger et al., 2023). Develop-
ment is just one aspect, and the deployment and main-
tenance of the models are equally important, specif-
ically in the context of changing data and business
environments (Gerhart et al., 2023). In DS projects,
these activities are often accompanied by issues with
reproducibility, knowledge retention, a lack of qual-
ity assurance checks, and low data quality for ML
(Martinez et al., 2021), which hinder leveraging the
full potential of ML. These challenges stress the need
for including ML guidance, particularly with empha-
sis on traceability and preservation of knowledge and
versions about data, models, and code in DS method-
ologies (Martinez et al., 2021).
This requirement aligns with the objectives of
MLOps, which address the typical challenges in
DS around ML. CI and CD automation foster de-
ployment, quality assurance, and flexibility. Trace-
ability and reproducibility of experiments, artifacts,
and pipelines are achieved through components such
as the feature store, model registry, and metadata
store. Thus, MLOps contributes to enhanced trans-
parency in ML processes, improving collaboration
(Kreuzberger et al., 2023). For operationalization, the
literature suggests that strong capabilities in DevOps
are crucial to ensure and maintain the quality of ML
systems and the consequent realization of business
value (Shollo et al., 2022), which MLOps accounts
for with CM and CT (Kreuzberger et al., 2023).
Thus far, no DS process model integrates MLOps
practices and components. Despite its potential to
standardize ML development, deployment, and moni-
toring, MLOps cannot address all challenges encoun-
tered in DS projects. Existing MLOps frameworks
mostly neglect the aspects of Business Understand-
ing and Evaluation (Haertel et al., 2023c). A missing
link between organizational objectives and the tech-
nical perspective can lead to the DS results not be-
ing used by the business (Martinez et al., 2021), espe-
cially when investigating the wrong or no analytical
question (Leek and Peng, 2015; Thiess and M
¨
uller,
2018). Therefore, MLOps practices should be embed-
Elevating Data Science Maturity: Toward a Process Model that Harnesses MLOps
553

ded in a DS methodology to combine the data-centric
view with the management perspective to effectively
support DS project execution (Haertel et al., 2023c;
Martinez et al., 2021).
5 A CONCEPT FOR AN
MLOps-BASED DATA SCIENCE
PROCESS MODEL
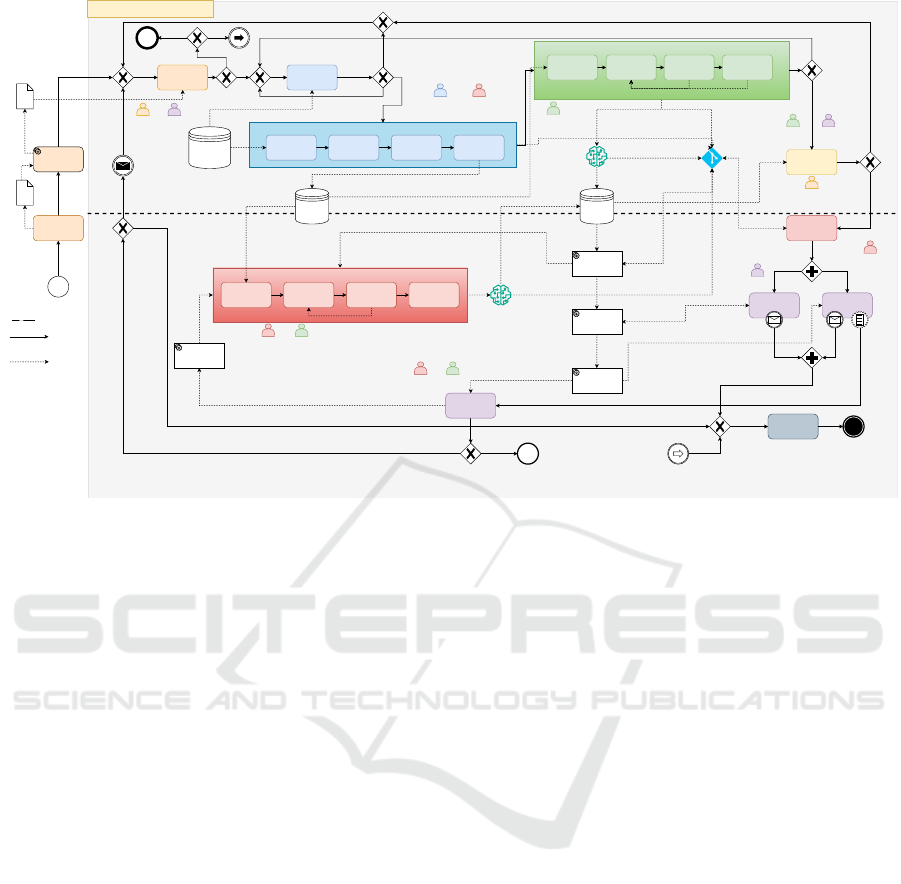
This section presents the high-level concept of the
MLOps-based DS process model, illustrated in Fig-
ure 2. For this draft, the notation is oriented toward
the Business Process Model and Notation (BPMN)
standard and will be formalized and detailed with ap-
propriate submodels as a next step. The model aims
to address the discussed managerial and technical is-
sues in DS from the literature by incorporating the
proposed solutions to mitigate them. In particular, for
its construction, the MLOps principles and compo-
nents (Kreuzberger et al., 2023) are integrated into the
DS workflow of Haertel et al. (2022) due to its origins
in the best practices of 28 existing DS process mod-
els. Furthermore, the method indicates the responsi-
ble team roles of major DS tasks, identified based on
a survey of DS roles and competencies (Haertel et al.,
2025). Consequently, this artifact combines a struc-
ture for managing organizational and technical pro-
cess aspects, which is crucial for the maturity and suc-
cess of data-driven initiatives (G
¨
okalp et al., 2021).
The process model is technology-agnostic, allowing
the realization of the individual components through
different tool vendors and (MLOps) automation lev-
els.
First, a notable challenge is bridging the gap be-
tween the business aspects and technical realization.
DS projects come in different variations (e.g., data
characteristics, type of ML product, timeliness of an-
alytics, type of analytical problem), imposing differ-
ent implications for the undertaking. Essentially, the
encountered challenges in DS project execution are
influenced by the project characteristics (Saltz et al.,
2017). Therefore, a DS categorization model, devel-
oped based on the analysis of a significant number of
DS case studies, aims to assign the DS project pro-
posal at hand to a cluster of similar undertakings to
allow for drawing inferences for guiding the project
execution based on the assigned category. This con-
stitutes valuable input for the Business Understanding
phase and can include aspects such as tools, required
data analysis and preparation activities, suitable ana-
lytical models, and conclusions for deployment and
monitoring.
Depending on the requirements of the use case
and the conclusions drawn from the categorization
model output, the actual DS lifecycle (Haertel et al.,
2022) starts with the Business Understanding activ-
ity to plan and prepare the project. Afterward, in
case of continuation, relevant data from the identified
data sources are acquired and explored to enable de-
veloping the data pipeline to streamline data prepara-
tion steps. Created features and processed datasets
are provided to a feature store to accelerate model
building and predictions (Kreuzberger et al., 2023)
and promote reusability. In the experimentation con-
ducted in the development environment, various (ML)
models are trained and tested based on the feature
data to fulfill the DS objectives. Due to the explo-
rative nature of DS (Das et al., 2015), a separation of
environments is essential. To ensure reproducibility
and traceability, tracking and logging of ML metadata
(e.g., training time, (hyper)parameters, performance
metrics, and model lineage) and models are imple-
mented for all training runs and stored in the model
registry and metadata store (Kreuzberger et al., 2023).
All code artifacts for data and modeling are further
held in a source code repository for improved collab-
oration.
After a positive conclusion regarding the satisfac-
tion of business goals in the Evaluation, the Deploy-
ment phase commences, primarily executed by the
Data Infrastructure & Operations team. Instead of
merely commissioning an analytical model, an entire
orchestrated ML pipeline is deployed to the produc-
tion environment. Therefore, the CI/CD component is
leveraged to quickly execute the build, test, delivery,
and deployment tasks, enhancing productivity and en-
abling fast adaptability of the system (Kreuzberger
et al., 2023).
Fed with curated feature data from the feature
store, the deployed ML pipeline is executed, resulting
in production-ready model(s) that are, similar to the
training metadata, recorded in the model registry. Via
CD, the generated model is made available to the ap-
plication domain through the serving component, en-
abling it to support business value creation. Further-
more, a monitoring component supervises model and
system performance and health through a broad set
of metrics (e.g., model accuracy, resource utilization).
Anomalies are investigated and handled by the oper-
ations and analytics team. For instance, the retraining
of the model is enabled via the CT component, which
can trigger the ML pipeline automatically or be sub-
ject to human evaluation beforehand. If the mainte-
nance activities fail to mitigate errors or revert model
and system performance to an acceptable threshold, a
reinitiation of the DS project can be decided when the
KMIS 2025 - 17th International Conference on Knowledge Management and Information Systems
554
Business
Understanding
Data Collection
& Exploration
ML training & workflow code
plan and prepare
ML pipeline
for production
Deployment
and Business
Integration
Model predictions
Value Creation
Logs, reports & alerts
Monitoring
Evaluation
Strategy &
Project
Management
Domain
Expertise
Data
Management
& Analysis
Analytical
Modeling
Data Science Lifecycle
Data
Infrastructure
& Operations
Data Extraction
Data Pipeline
Data
Transformation
& Cleaning
Feature
Engineering
Feature Data
Ingestion
Data Sources
Experiment &
metadata tracking
Data Analysis
Model
Selection
Model
Development
Model
Assessment
build, test, push
Source code
repository
provide feature data
Model
Data pipeline code
Model training code
Training and
metadata tracking
build, test, deploy
feedback
Model
(Prod ready)
Data Extraction
provide feature data
Maintenance &
Infrastructure
Management
trigger
Continuation of the solution?
Model Training
Model
Assessment
Push to
registry
Experimentation
Production ML Pipeline
DS process
flow
Data &
artifact flow
Business goals
satisfied?
CI/CD
component
Serving
component
Monitoring
component
CT component
Problem still
relevant
for business?
Data
Infrastructure
& Operations
Analytical
Modeling
Strategy &
Project
Management
Domain
Expertise
Data
Infrastructure
& Operations
Data
Infrastructure
& Operations
Draft Data
Science Project
Proposal
guides
Proposal
Categorization
Model
DS project
categorization
No Yes
Performance
Insufficient
Yes
No
Data
sufficient?
Yes
Additional or other
data needed and
available
Yes
No
Model
performance
sufficient?
Yes
No
Satisfaction of
business goals
not possible
Stop
project?
Yes
No
System
discontinuation
inform about
new solution
development
No Yes
Solution
exists?
Analytical
Modeling
Analytical
Modeling
Domain
Expertise
Legend
Discontinuation ordered
Feature Store Model Registry and
Metadata Store
Development Environment
Production Environment
Figure 2: DS process model (concept) based on Haertel et al. (2022) and Kreuzberger et al. (2023).
objective of the solution is still considered relevant for
the organization. Otherwise, the system is discontin-
ued.
In summary, the proposed artifact aims to ad-
dress common DS challenges as follows. The fea-
ture store, model registry, metadata store, and the
source code repository enable versioning, knowledge
retention, transparency, and reproducibility. CI/CD
and the orchestration of data and ML pipelines fos-
ter automation and efficiency. Through the separation
of environments and the components for monitoring
and CT, system quality and robustness are ensured.
These MLOps practices are incorporated into an end-
to-end DS workflow with defined team roles to es-
tablish process maturity and aid coordination. Never-
theless, while the artifact prescribes the relevant ab-
stract technical components, it does not provide con-
crete guidance for setting up the generally necessary
IT infrastructure for DS projects.
For the future formalization of the process model,
the involvement of the actors can be clarified more
clearly (e.g., via swimlanes). Furthermore, the data
and artifact flow between the components is subject
to a detailed specification. The verification of the arti-
fact’s utility to fulfill the intended objectives requires
a comprehensive evaluation. Therefore, we rely on
the Build-Evaluate pattern of Sonnenberg and vom
Brocke (2012). Briefly, the applicability of the model
is demonstrated by its instantiation in multiple DS
case studies. This will be supplemented by detailed
expert feedback. Here, beyond the artifact’s effective-
ness, its understandability and clarity are major con-
cerns to ensure that practitioners are able to use this
approach for managing DS projects. Accordingly, ex-
perts with different roles and skillsets in the context
of DS should be considered.
6 CONCLUSION AND FUTURE
WORK
The need for new approaches (e.g., process models)
for DS (Saltz and Krasteva, 2022) is motivated by the
high failure rates of DS initiatives (Hotz, 2024) due to
various managerial and technical challenges. Many
DS projects do not follow an established methodol-
ogy, and gaps in current DS process models are high-
lighted in the literature (Kutzias et al., 2023; Martinez
et al., 2021; Schulz et al., 2020). Consequently, this
paper reports on an ongoing research endeavor that
aims to develop an MLOps-based process model for
DS through the adoption of the DSR methodology of
Peffers et al. (2007). A high-level concept of this
artifact is presented, including a discussion on how
it aims to address managerial and data-centric chal-
lenges in DS. The focus of future work will be placed
on continuing the development of the artifact and its
components, including formalization with established
modeling notation. Furthermore, the evaluation will
play a major role in assessing its feasibility for the
Elevating Data Science Maturity: Toward a Process Model that Harnesses MLOps
555

different flavors of DS projects. Moreover, the poten-
tial of incorporating Generative AI capabilities into
DS process models for increasing automation and ef-
ficiency in DS project tasks can be explored.
REFERENCES
Bishop, C. M. (2006). Pattern Recognition and Machine
Learning.
Chang, W. L. and Grady, N. (2019). NIST Big Data Inter-
operability Framework: Volume 1, Definitions.
Chen, H., Chiang, R. H. L., and Storey, V. C. (2012). Busi-
ness Intelligence and Analytics: From Big Data to Big
Impact. MIS Quarterly, 36(4):1165–1188.
Das, M., Cui, R., Campbell, D. R., Agrawal, G., and Ram-
nath, R. (2015). Towards Methods for Systematic Re-
search on Big Data. 2015 IEEE International Confer-
ence on Big Data, pages 2072–2081.
Demchenko, Y., Belloum, A., Los, W., Wiktorski, T.,
Manieri, A., Brocks, H., Becker, J., Heutelbeck, D.,
Hemmje, M., and Brewer, S. (2016). EDISON Data
Science Framework: A Foundation for Building Data
Science Profession for Research and Industry. In 2016
IEEE International Conference on Cloud Computing
Technology and Science (CloudCom), pages 620–626.
IEEE.
Gama, J.,
ˇ
Zliobait
˙
e, I., Bifet, A., Pechenizkiy, M., and
Bouchachia, A. (2014). A survey on concept drift
adaptation. ACM Computing Surveys, 46(4):1–37.
Gerhart, N., Torres, R., and Giddens, L. (2023). Challenges
in the Model Development Process: Discussions with
Data Scientists. Communications of the Association
for Information Systems, 53(1):591–611.
G
¨
okalp, M., G
¨
okalp, E., Kayabay, K., Kocyigit, A., and
Eren, P. (2021). Data-driven manufacturing: An as-
sessment model for data science maturity. Journal of
Manufacturing Systems, 60:123–132.
G
¨
okay, G. T., Nazlıel, K., S¸ener, U., G
¨
okalp, E., G
¨
okalp,
M. O., Genc¸al, N., Da
˘
gdas¸, G., and Eren, P. E. (2023).
What Drives Success in Data Science Projects: A Tax-
onomy of Antecedents. In Garc
´
ıa M
´
arquez, F. P.,
Jamil, A., Eken, S., and Hameed, A. A., editors, Com-
putational Intelligence, Data Analytics and Applica-
tions, volume 643 of Lecture Notes in Networks and
Systems, pages 448–462. Springer International Pub-
lishing, Cham.
Haertel, C., Daase, C., Staegemann, D., Nahhas, A., Pohl,
M., and Turowski, K. (2023a). Toward Standard-
ization and Automation of Data Science Projects:
MLOps and Cloud Computing as Facilitators. In
Proceedings of the 15th International Joint Confer-
ence on Knowledge Discovery, Knowledge Engineer-
ing and Knowledge Management, pages 294–302.
SCITEPRESS - Science and Technology Publications.
Haertel, C., Holtkemper, M., Staegemann, D., Beecks, C.,
and Turowski, K. (2025). Unveiling Data Science
Team Roles and Competencies: A Literature-Based
Analysis. AMCIS 2025 Proceedings.
Haertel, C., Pohl, M., Nahhas, A., Staegemann, D., and Tur-
owski, K. (2022). Toward A Lifecycle for Data Sci-
ence: A Literature Review of Data Science Process
Models. PACIS 2022 Proceedings.
Haertel, C., Pohl, M., Nahhas, A., Staegemann, D., and Tur-
owski, K. (2023b). A Survey of Technology Selection
Approaches in Data Science Projects. AMCIS 2023
Proceedings.
Haertel, C., Staegemann, D., Daase, C., Pohl, M., Nahhas,
A., and Turowski, K. (2023c). MLOps in Data Science
Projects: A Review. 2023 IEEE International Confer-
ence on Big Data (BigData), pages 2396–2404.
Hevner, A. R., March, S. T., and Park, J. (2004). Design
Science in Information Systems Research. MIS Quar-
terly, Vol. 28(No. 1):75–106.
Holtkemper, M. and Beecks, C. (2024). Empowering Data
Science Teams: How Automation Frameworks Ad-
dress Competency Gaps Across Project Lifecycles.
In 2024 IEEE International Conference on Big Data
(BigData), pages 3134–3142. IEEE.
Hotz, N. (2024). Why Big Data Science & Data Analytics
Projects Fail.
Iriarte, C. and Bayona, S. (2020). IT projects success fac-
tors: a literature review. International Journal of In-
formation Systems and Project Management, 8(2):49–
78.
Janiesch, C., Zschech, P., and Heinrich, K. (2021). Ma-
chine learning and deep learning. Electronic Markets,
31(3):685–695.
Kazmierczak, J., Salama, K., and Huerta, V. (2024).
MLOps: Continuous delivery and automation
pipelines in machine learning.
Kreuzberger, D., K
¨
uhl, N., and Hirschl, S. (2023). Machine
Learning Operations (MLOps): Overview, Definition,
and Architecture. IEEE Access, 11:31866–31879.
Kutzias, D., Dukino, C., K
¨
otter, F., and Kett, H. (2023).
Comparative Analysis of Process Models for Data
Science Projects. Proceedings ofthe 15th Interna-
tional Conference on Agents and Artificial Intelli-
gence (ICAART 2023), pages 1052–1062.
Larsen, K. R., Lukyanenko, R., Mueller, R. M., Storey,
V. C., Parsons, J., VanderMeer, D., and Hovorka, D. S.
(2025). Validity in Design Science. MIS Quarterly.
Leek, J. T. and Peng, R. D. (2015). What is the ques-
tion? Mistaking the type of question being considered
is the most common error in data analysis. Science,
347(6228):1314–1315.
Makinen, S., Skogstrom, H., Laaksonen, E., and Mikkonen,
T. (2021). Who Needs MLOps: What Data Scientists
Seek to Accomplish and How Can MLOps Help? In
2021 IEEE/ACM 1st Workshop on AI Engineering -
Software Engineering for AI (WAIN), pages 109–112.
IEEE.
Martinez, I., Viles, E., and Olaizola, I. G. (2021). Data Sci-
ence Methodologies: Current Challenges and Future
Approaches. Big Data Research 24.
Mishra, A., Tripathi, A., and Khazanchi, D. (2022). A Pro-
posal for Research on the Application of AI/ML in
ITPM. International Journal of Information Technol-
ogy Project Management, 14(1):1–9.
KMIS 2025 - 17th International Conference on Knowledge Management and Information Systems
556

M
¨
uller, O., Fay, M., and vom Brocke, J. (2018). The Ef-
fect of Big Data and Analytics on Firm Performance:
An Econometric Analysis Considering Industry Char-
acteristics. Journal of Management Information Sys-
tems, 35(2):488–509.
Peffers, K., Rothenberger, M., Tuunanen, T., and Vaezi, R.
(2012). Design Science Research Evaluation. Design
Science Research in Information Systems. Advances in
Theory and Practice. DESRIST 2012., Vol. 7286.
Peffers, K., Tuunanen, T., Rothenberger, M. A., and Chat-
terjee, S. (2007). A Design Science Research Method-
ology for Information Systems Research. Journal of
Management Information Systems, 24(3):45–77.
Rahlmeier, N. and Hopf, K. (2024). Bridging Fields of Prac-
tice: How Boundary Objects Enable Collaboration in
Data Science Initiatives. Wirtschaftsinformatik 2024
Proceedings, 55.
Saltz, J., Shamshurin, I., and Connors, C. (2017). Predict-
ing data science sociotechnical execution challenges
by categorizing data science projects. Journal of the
Association for Information Science and Technology,
68(12):2720–2728.
Saltz, J. S. and Krasteva, I. (2022). Current approaches for
executing big data science projects - a systematic lit-
erature review. PeerJ Computer Science, 8(e862).
Saltz, J. S. and Shamshurin, I. (2016). Big data team pro-
cess methodologies: A literature review and the iden-
tification of key factors for a project’s success. In
2016 IEEE International Conference on Big Data (Big
Data), pages 2872–2879. IEEE.
Schulz, M., Neuhaus, U., Kaufmann, J., Badura, D.,
Kuehnel, S., Badewitz, W., Dann, D., Kloker, S.,
Alekozai, E. M., and Lanquillon, C. (2020). Introduc-
ing DASC-PM: A Data Science Process Model. Aus-
tralasian Conference on Information Systems 2020.
Schumann, C., Zschech, P., and Hilbert, A. (2016). Das auf-
strebende Berufsbild des Data Scientist. HMD Praxis
der Wirtschaftsinformatik, 53(4):453–466.
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips,
T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-
F., and Dennison, D. (2015). Hidden Technical Debt
in Machine Learning Systems. Advances in Neural
Information Processing Systems, 28.
Sharma, R., Mithas, S., and Kankanhalli, A. (2014).
Transforming decision-making processes: a research
agenda for understanding the impact of business ana-
lytics on organisations. European Journal of Informa-
tion Systems, 23(4):433–441.
Shollo, A., Hopf, K., Thiess, T., and M
¨
uller, O. (2022).
Shifting ML value creation mechanisms: A process
model of ML value creation. The Journal of Strategic
Information Systems, 31(3):101734.
Sonnenberg, C. and vom Brocke, J. (2012). Evaluations
in the Science of the Artificial – Reconsidering the
Build-Evaluate Pattern in Design Science Research.
Design Science Research in Information Systems. Ad-
vances in Theory and Practice. DESRIST 2012., Vol.
7286:381–397.
Symeonidis, G., Nerantzis, E., Kazakis, A., and Papakostas,
G. A. (2022). MLOps - Definitions, Tools and Chal-
lenges. In 2022 IEEE 12th Annual Computing and
Communication Workshop and Conference (CCWC),
pages 0453–0460. IEEE.
Thiess, T. and M
¨
uller, O. (2018). Towards Design Prin-
ciples for Data-Driven Decision Making - An Ac-
tion Design Research Project in the Maritime Industry.
ECIS 2018 Proceedings.
VentureBeat (2019). Why do 87% of data science projects
never make it into production?
Wamba, S. F., Gunasekaran, A., Akter, S., Ren, S. J.-f.,
Dubey, R., and Childe, S. J. (2017). Big data analytics
and firm performance: Effects of dynamic capabili-
ties. Journal of Business Research, 70.
Elevating Data Science Maturity: Toward a Process Model that Harnesses MLOps
557
