
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and
Retrieval Algorithms for Algorithmic Gender Fairness
Stefanie Urchs
1,2 a
, Veronika Thurner
1 b
, Matthias Aßenmacher
2,3 c
, Ludwig Bothmann
2
,
Christian Heumann
2 d
and Stephanie Thiemichen
1 e
1
Faculty for Computer Science and Mathematics, Hochschule M
¨
unchen University of Applied Sciences, Munich, Germany
2
Department of Statistics, LMU Munich, Munich, Germany
3
Munich Center for Machine Learning (MCML), LMU Munich, Munich, Germany
{stefanie.urchs, veronika.thurner, stephanie.thiemichen}@hm.edu,
Keywords:
Algorithmic Fairness, Academic Visibility, Information Retrieval, Search Engines, Gender Fairness.
Abstract:
Algorithmic systems such as search engines and information retrieval platforms significantly influence aca-
demic visibility and the dissemination of knowledge. Despite assumptions of neutrality, these systems can
reproduce or reinforce societal biases, including those related to gender. This paper introduces and applies
a bias-preserving definition of algorithmic gender fairness, which assesses whether algorithmic outputs re-
flect real-world gender distributions without introducing or amplifying disparities. Using a heterogeneous
dataset of academic profiles from German universities and universities of applied sciences, we analyse gender
differences in metadata completeness, publication retrieval in academic databases, and visibility in Google
search results. While we observe no overt algorithmic discrimination, our findings reveal subtle but consistent
imbalances: male professors are associated with a greater number of search results and more aligned publi-
cation records, while female professors display higher variability in digital visibility. These patterns reflect
the interplay between platform algorithms, institutional curation, and individual self-presentation. Our study
highlights the need for fairness evaluations that account for both technical performance and representational
equality in digital systems.
1 INTRODUCTION
Algorithms are increasingly embedded in nearly ev-
ery aspect of our daily lives, shaping the information
we encounter and influencing our perceptions and de-
cisions. From social media recommendations to on-
line shopping suggestions, algorithmic processes im-
pact what we see, how we engage, and ultimately
how we make choices. Among these, algorithms in
search engines and publication databases have signif-
icant power in determining which information, con-
tent, and experts are made visible to users, directly in-
fluencing public knowledge, career opportunities, and
academic visibility. For instance, studies have shown
that job advertisements displayed by search engines
a
https://orcid.org/0000-0002-1118-4330
b
https://orcid.org/0000-0002-9116-390X
c
https://orcid.org/0000-0003-2154-5774
d
https://orcid.org/0000-0002-4718-595X
e
https://orcid.org/0009-0001-8146-9438
can be targeted by gender (Datta et al., 2015; Eren
et al., 2021), image search results prefer white in-
dividuals (Makhortykh et al., 2021) and text-based
search results sexualise woman, especially from the
global south (Urman and Makhortykh, 2022), raising
significant concerns about the presence and impact of
gender-based bias in these systems. Such examples
underscore the urgency of examining and defining al-
gorithmic fairness, particularly regarding gender rep-
resentation, as these biases risk perpetuating and am-
plifying existing societal inequities.
Algorithmic gender fairness is essential because
these biases are not merely technical flaws but reflec-
tions of deeper societal structures embedded in data
and system design. Algorithms do not operate in iso-
lation; they are shaped by the data they are trained on,
the objectives they are optimised for, and the societal
context in which they function. Addressing gender
fairness requires navigating the intersection of math-
ematical criteria and social implications, as technical
fixes alone cannot resolve biases rooted in historical
Urchs, S., Thurner, V., Aßenmacher, M., Bothmann, L., Heumann, C. and Thiemichen, S.
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and Retrieval Algorithms for Algorithmic Gender Fairness.
DOI: 10.5220/0013835600004000
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2025) - Volume 1: KDIR, pages 489-500
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
489

and structural inequalities. Without a well-defined
framework for fairness, efforts to mitigate algorithmic
discrimination risk being inconsistent or even coun-
terproductive. Therefore, a clear and robust definition
of algorithmic gender fairness is crucial, not only to
prevent direct and indirect discrimination but also to
establish transparency, accountability, and trust in au-
tomated systems.
Building upon existing research in algorithmic
fairness and algorithmic gender fairness, this work
contributes to the ongoing discourse by proposing and
empirically testing a definition of algorithmic gender
fairness. While many studies have explored fairness
in algorithms, our approach focuses on evaluating two
influential types of systems: publication database re-
trieval algorithms and Google’s search engine. These
algorithms play a crucial role in shaping public visi-
bility and access to information, making them particu-
larly impactful subjects for analysis. By applying our
fairness definition to these systems, we aim to offer
insights into their performance, identify improvement
areas, and contribute to developing more transparent,
accountable, and inclusive algorithmic designs.
2 BACKGROUND
To define algorithmic gender fairness, we begin by
outlining how we understand the core concepts of
gender and fairness. Given the interdisciplinary na-
ture of this work, the section is deliberately extensive.
In the final part of the section, we first introduce how
information retrieval and search engines work in gen-
eral, providing the necessary technical background
for readers unfamiliar with the field. We then review
existing research on algorithmic fairness in these do-
mains and highlight how our approach differs from
previous work.
2.1 Gender
The term “gender” encompasses at least three dis-
tinct concepts: linguistic gender, sex, and social
gender. Each concept has unique implications in
various professional and private contexts, especially
when considering algorithmic representation, iden-
tity, and fairness issues. Linguistic or grammatical
gender is defined as “[...] grammatical gender in
the narrow sense, which involves a more or less ex-
plicit correlation between nominal classes and bio-
logical gender (sex).” (Janhunen, 2000). In many
languages, nouns and pronouns are assigned a gen-
der, classified as feminine, masculine, or neutral, of-
ten loosely correlated with perceived biological char-
acteristics (Kramer, 2020). This linguistic categori-
sation can affect the way gender roles and identities
are understood culturally, as language shapes and re-
inforces social expectations (Konishi, 1993; Phillips
and Boroditsky, 2013).
“Sex”, on the other hand, is traditionally under-
stood as a biological categorisation, regarded as “bi-
nary, immutable and physiological” (Keyes, 2018).
However, a strict binary framework is increasingly
recognised as insufficient for representing the full
spectrum of human diversity. Intersex individuals,
who may not fit the conventional definitions of fem-
inine or masculine due to variations in physiological
characteristics (Carpenter, 2021), and transgender in-
dividuals, whose gender identity differs from their sex
assigned at birth (Beemyn and Rankin, 2011), exem-
plify the limitations of this binary, immutable per-
spective. The presence of these identities challenges
the conventional definitions of sex.
In our work, we embrace the concept of social
gender, which goes beyond biological and linguis-
tic classifications to encompass a socially constructed
identity shaped by behaviours, expressions, and self-
presentation. Social gender is fluid, non-binary, and
co-constructed through social interactions, allowing it
to evolve over time in alignment with an individual’s
sense of self. This perspective aligns with research
that views gender not as an inherent or static charac-
teristic but as a performative act shaped by personal
expression and social context (West and Zimmerman,
1987; Devinney et al., 2022).
Although we adopt this inclusive understanding of
gender, our study faces limitations due to the con-
straints in our data. The available information only
allows for analysing participants within the binary
gender spectrum, and we were thus unable to iden-
tify trans or intersex individuals in the dataset. As a
result, our empirical analysis focuses on binary gen-
der categories. However, the underlying framework
of our proposed definition of algorithmic gender fair-
ness remains rooted in the concept of social gender –
emphasising its non-binary, flexible, and socially co-
constructed nature. We aim to contribute to a broader,
more inclusive understanding of gender fairness in al-
gorithmic systems, even as we acknowledge the cur-
rent limitations of our dataset.
2.2 Fairness
The term “fairness” is increasingly used in the field
of algorithmic decision-making and “fairness-aware
machine learning” [fairML, surveys can be found,
e.g., in (Caton and Haas, 2024; Verma and Rubin,
2018)]. However, few contributions concretely define
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
490

the meaning of this term as a philosophical concept,
with positive exceptions to be found in (Bothmann
et al., 2024; Loi and Heitz, 2022; Kong, 2022). Fair-
ness is usually described by synonyms such as equal-
ity, justice, or the absence of bias or discrimination.
A crucial component of fairness as a philosoph-
ical concept is that it concerns the treatment of in-
dividuals (Aristotle, 2009; Dictionary, 2022; Dator,
2017; Kleinberg et al., 2017). The basic structure of
the concept can be traced back to Aristotle and relates
fairness to equality: A decision or treatment is fair if
equals are treated equally and unequals are treated un-
equally. As (Bothmann et al., 2024) point out, this re-
quires the normative definition of task-specific equal-
ity, that is: Two individuals may be equal in one task
(e.g., buying a croissant in a bakery), but unequal in
another task (e.g., paying taxes). Deciding how to
treat unequals is also a normative task.
The role of protected attributes such as gender or
race is that they can normatively alter the definition
of task-specific equality. For example, a society may
decide that the grievance of the gender pay gap is not
the responsibility of an individual and that in deciding
whether to grant a loan, income should therefore be
fictitiously corrected for this real-world bias; (Both-
mann et al., 2024) call this a fictitious, normatively
desired (FiND) world, and advocate making decisions
using data from this world rather than real-world data.
(Wachter et al., 2021) describe such an approach as
“bias-transforming”, aiming at “substantive equality”,
because a real-world bias should be “actively eroded”
to make the world fairer.
In contrast, (Wachter et al., 2021) describes ap-
proaches as “bias-preserving”, aiming at “formal
equality”, if they try to reflect the real world as accu-
rately as possible, i.e., without introducing new biases
that may even increase the real-world biases. Many
fairML metrics, such as equalised odds or predictive
parity, can be categorised as bias-preserving because
they measure against real-world labels but try to bal-
ance the errors thus measured across levels of the
protected attribute. Sometimes the concept of bias-
transforming methods is referred to as aiming for “eq-
uity”, while bias-preserving approaches are referred
to as aiming for “equality”. In our work, we will fol-
low a bias-preserving approach to adequately or “cor-
rectly” reflect individuals in the real world while pro-
hibiting the introduction of gender bias by informa-
tion retrieval algorithms or search engines (in addition
to the already existing gender bias in the real world).
2.3 Information Retrieval and Search
Engines
Information Retrieval (IR) focuses on finding relevant
material, typically text documents, to satisfy a user’s
information need. An information need represents
the user’s underlying intention or goal when seek-
ing information. At the same time, a query explic-
itly represents this need, usually entered as keywords
or phrases in a search engine. These concepts are
fundamental in bridging the gap between human in-
tentions and computational processing, ensuring that
search systems accurately interpret and address user
needs (Sch
¨
utze et al., 2008).
An Information Retrieval System (IRS) is a soft-
ware system that efficiently stores, manages, and re-
trieves information from large datasets. An IRS re-
lies on indexing and searching algorithms to match
user queries with relevant documents. Retrieval sys-
tems can be categorised based on their retrieval mod-
els, with the two primary examples being Boolean
Retrieval and Vector Space Retrieval. Boolean Re-
trieval allows users to formulate queries using log-
ical operators such as AND, OR, and NOT, ensur-
ing that documents are returned only if they satisfy
the Boolean expression. On the other hand, the Vec-
tor Space Model represents documents and queries
as vectors in a multi-dimensional space, using simi-
larity measures like cosine similarity to rank results
by relevance. In document retrieval, user queries are
matched against different parts of documents, such as
title, keywords, author name(s), and abstract. These
metadata fields often provide valuable signals for rel-
evance, enabling the system to prioritise results more
effectively. An IRS typically employs inverted in-
dexes, which map each term to a list of documents
containing it, facilitating rapid query processing. Ad-
ditionally, ranking algorithms ensure that results are
retrieved and presented in an order reflecting their rel-
evance to the user’s query (Sch
¨
utze et al., 2008).
Recent research highlights a critical issue within
IRS: the presence of biases in their structure and out-
comes (Fang et al., 2022). These biases can emerge
from relevance judgment datasets, neural representa-
tions, and query formulation. Relevance judgment
datasets, often regarded as gold-standard benchmarks,
may carry stereotypical gender biases, propagating
into ranking algorithms when IRS are trained on such
datasets (Bigdeli et al., 2022). Additionally, neu-
ral embeddings used for query and document rep-
resentations, pre-trained on large corpora, are sus-
ceptible to inheriting societal biases present in those
datasets (Bolukbasi et al., 2016). Retrieval meth-
ods, especially those using neural architectures, have
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and Retrieval Algorithms for Algorithmic Gender Fairness
491

shown a tendency to intensify pre-existing gender
biases (Francazi et al., 2024). Bias-aware ranking
strategies, such as adversarial loss functions, bias-
aware negative sampling, and query reformulation
techniques (e.g., AdvBERT), have been proposed to
reduce these biases while maintaining retrieval effec-
tiveness. Researchers emphasise the importance of
balancing retrieval performance with fairness, advo-
cating for systematic evaluation metrics and datasets
explicitly designed for measuring and mitigating gen-
der biases in IRS (Bigdeli et al., 2022). Prior work on
fairness in information retrieval has largely focused
on technical interventions in ranking systems (e.g.,
(Singh and Joachims, 2018); (Geyik et al., 2019)) or
on consumer-side fairness (Ekstrand et al., 2022), typ-
ically evaluating search and recommendation systems
in general-purpose digital platforms. In contrast, few
empirical studies have investigated gender fairness in
academic retrieval contexts. Our work bridges this
gap by conducting a fairness audit of academic vis-
ibility, applying a bias-preserving fairness perspec-
tive to both domain-specific publication databases and
general-purpose search engines. In doing so, we ex-
tend the methodological orientation of studies like
(Bigdeli et al., 2022) and (Fang et al., 2022) to a
new sociotechnical domain. For instance, Singh and
Joachims (Singh and Joachims, 2018) propose formal
fairness constraints on exposure in rankings, ensuring
that protected groups receive visibility proportional to
their relevance. Their framework relies on probabilis-
tic rankings to balance user utility and provider fair-
ness in expectation.
Search engines are advanced Information Re-
trieval Systems tailored for web-scale datasets. They
consist of three primary components: crawling, in-
dexing, and query processing. Crawlers systemati-
cally fetch web pages indexed using data structures
like inverted indexes. Query processing involves pars-
ing the user’s input and matching it with indexed
documents. The PageRank algorithm, introduced by
Google, revolutionised web search by considering the
hyperlink structure of the web. Each webpage is as-
signed a numerical score based on the quantity and
quality of incoming links. The algorithm models a
“random surfer” who follows hyperlinks or randomly
jumps to other pages. This behaviour is mathemati-
cally represented using Markov Chains, and steady-
state probabilities are computed iteratively to deter-
mine the importance of each page. Search engines
blend PageRank with other ranking factors, including
content relevance, term proximity, and user-specific
data, creating a hybrid scoring system that delivers
highly accurate search results (Sch
¨
utze et al., 2008).
However, search engines are not immune to bi-
ases. Biases in search engines can emerge from
data sources, crawling strategies, and ranking algo-
rithms, resulting in the reinforcement of stereotypes,
underrepresentation of marginalised groups, or dis-
criminatory exposure of content. Biases may also
be amplified over time through dynamic adaptation
mechanisms, where user interactions create feedback
loops that reinforce pre-existing biases. Address-
ing these biases requires mitigation strategies such as
bias-aware re-ranking algorithms, adversarial train-
ing, and query reformulation techniques (Ekstrand
et al., 2022).
Additionally, fairness concerns in search engines
align with consumer fairness (ensuring users receive
equally relevant and satisfying results across diverse
groups) and provider fairness (ensuring content cre-
ators or document providers receive equitable expo-
sure in rankings). Evaluation methodologies play a
key role in addressing these concerns, often com-
bining relevance metrics with fairness-aware met-
rics to strike a balance between accuracy and eq-
uity (Ekstrand et al., 2022). In industrial applica-
tions, (Geyik et al., 2019) present a fairness-aware
re-ranking framework deployed at scale in LinkedIn
Talent Search. Their system enforces minimum rep-
resentation thresholds through post-processing algo-
rithms, demonstrating that fairness and utility can co-
exist in production systems. However, their approach
is grounded in fairness-transforming principles such
as demographic parity.
In practice, search engines represent a complex
interplay between technical architecture, algorithmic
fairness, and societal values. Continuous research and
refinement are essential to ensure these systems meet
efficiency and fairness criteria simultaneously (Ek-
strand et al., 2022).
3 ALGORITHMIC GENDER
FAIRNESS
To define algorithmic gender fairness, we build upon
the theoretical framework presented in Section “Fair-
ness” and the practical insights discussed in Section
“Information Retrieval and Search Engines”. Our ap-
proach adopts a bias-preserving perspective, aiming
to reflect real-world distributions without introducing
new distortions or exacerbating existing gender bi-
ases.
Bias in algorithmic systems can arise from sev-
eral sources, including biased training datasets, pre-
existing societal inequalities, and the interaction be-
tween users and algorithmic feedback loops (for Jus-
tice et al., 2021). Gender biases, in particular, are
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
492

often perpetuated through historical inequalities en-
coded in data, proxies that stand in for protected at-
tributes, and opaque decision-making processes in-
herent to many machine-learning systems.
At the data stage, biases can emerge from train-
ing datasets that reflect societal inequalities, includ-
ing historical gender pay gaps or occupational stereo-
types. These biases are often amplified when algo-
rithms learn patterns from these datasets without crit-
ical oversight. From a bias-preserving perspective,
systems should strive to reflect gender distributions
accurately without further entrenching societal dis-
parities. However, achieving this requires ongoing
monitoring and transparency to detect and address un-
intended distortions.
At the algorithmic stage, gender biases can mani-
fest in ranking systems, recommendation algorithms,
or classification processes. Proxy variables, such
as zip codes, browsing behaviour, or inferred de-
mographic data, often serve as indirect markers for
gender, leading to indirect discrimination. Mitigat-
ing these biases involves identifying such proxies and
adjusting algorithmic models to ensure they do not
disproportionately disadvantage individuals based on
gender (for Justice et al., 2021).
From a bias-transforming perspective, algorithms
may be adjusted proactively to counteract historical
inequalities and actively reshape outcomes. Such ap-
proaches aim for substantive equality, where systems
not only avoid perpetuating existing biases but ac-
tively correct for them by introducing calibrated ad-
justments to outputs (for Justice et al., 2021). Such
fairness interventions are often formalised as con-
strained optimisation problems, where utility (e.g.,
accuracy or public safety) is maximised subject to
fairness constraints. (Corbett-Davies et al., 2017)
demonstrate that implementing common fairness defi-
nitions, such as statistical parity or predictive equality,
typically requires group-specific decision thresholds,
a trade-off that can reduce utility or violate principles
of equal treatment.
Transparency and explainability remain central
challenges in algorithmic gender fairness. The opac-
ity of many systems, particularly those based on deep-
learning architectures, makes it difficult to detect and
address gender biases effectively. Without clear ex-
planations of how decisions are reached, it becomes
challenging to hold systems accountable for gender-
discriminatory outcomes.
Additionally, intersectionality plays a crucial role
in algorithmic gender fairness. Gender does not ex-
ist in isolation but intersects with other protected at-
tributes such as race, age, or socio-economic status,
leading to compounded forms of bias and discrimina-
tion. Addressing intersectionality requires fairness-
aware metrics that account for these overlapping di-
mensions (for Justice et al., 2021).
Our approach focuses on bias-preserving fairness
as the guiding principle, ensuring that algorithmic
systems in information retrieval and search engines
reflect real-world gender distributions without intro-
ducing additional biases. While our approach focuses
on preserving bias patterns as they exist in real-world
data, many prior works have proposed alternative fair-
ness frameworks.
¨
Zliobait
˙
e (
¨
Zliobait
˙
e, 2017) offers
a systematic overview of such fairness definitions in
algorithmic decision-making, highlighting group fair-
ness notions such as statistical parity, conditional par-
ity, and predictive parity, as well as individual fairness
principles based on similarity of treatment. While
bias-transforming approaches, which aim to correct
historical inequalities proactively, offer an appeal-
ing vision of fairness, they require defining an ideal
dataset or outcome, a “perfect world”, to serve as a
benchmark. However, defining such an ideal world
is inherently challenging, given the vast diversity of
cultural, social, and political value systems across the
globe. Even if we attempted to define it, measuring
an ideal world would remain an insurmountable task,
as no dataset could comprehensively capture such a
reality.
Given these constraints, we adopt a bias-
preserving approach, which evaluates whether algo-
rithms accurately reflect and replicate the analogue
reality within the digital domain without amplifying
existing biases. This approach leverages measurable
real-world data, allowing us to assess algorithmic out-
comes in relation to observed societal distributions.
Therefore, we define algorithmic gender fairness
as:
The ability of algorithmic systems, particu-
larly in information retrieval and search en-
gines, to accurately reflect real-world gender
distributions and representations in their out-
puts without introducing, amplifying, or rein-
forcing existing biases.
In this paper, we apply the above definition of al-
gorithmic gender fairness to evaluate real-world sys-
tems that mediate academic visibility. While prior
studies have primarily focused on technical fairness
interventions or theoretical proposals, our contribu-
tion lies in conducting a fairness audit grounded
in this definition, using empirical data from both
domain-specific academic databases and a general-
purpose search engine. By doing so, we extend the
application of fairness frameworks to a previously un-
derexplored domain: the digital representation of aca-
demic expertise.
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and Retrieval Algorithms for Algorithmic Gender Fairness
493

4 EXPERIMENTS
We test our notion of algorithmic gender fairness by
analysing the online visibility of professors through
two distinct types of algorithmic systems: search
algorithms, exemplified by Google, and informa-
tion retrieval algorithms used in academic publica-
tion databases. While Google clearly ranks results
through its proprietary search algorithm, the publi-
cation databases return results based on ”relevance”,
a criterion that remains undefined by the platforms.
Consequently, we do not compare the results directly
but instead analyse each system separately to explore
how algorithmic structures may influence visibility
across gender lines.
4.1 Data
The data for this study stems from a broader research
project that investigated the visibility of female pro-
fessors at universities of applied sciences (UAS)
1
in
Germany. The full dataset includes professors from
different institutional types (universities and univer-
sities of applied sciences) and academic disciplines
(computer science and social work/social pedagogy).
This heterogeneity was intentional: to capture a broad
spectrum of academic visibility, we aimed for max-
imum variation within the German academic land-
scape. Including both institutional types reflects
structural differences in prestige, mission, and digital
presence. Moreover, computer science and social sci-
ences follow distinct publication cultures: computer
science is predominantly conference-driven, while so-
cial scientists typically publish in journals.
As the main focus of the project lay on female pro-
fessors at UAS, we manually collected the full pop-
ulation of women professors working in the depart-
ments of computer science and social work at these
institutions. To provide a meaningful comparison, we
additionally included random samples of male pro-
fessors at UAS, as well as female and male professors
from traditional universities in comparable fields. For
university-level social science, we focused on social
pedagogy, as the field of social work is not formally
established at universities. The comparison samples
were drawn from all German UAS and universities
1
UAS are a distinct feature of the German higher ed-
ucation system. They focus on practice-oriented teaching
and maintain close ties to industry. Compared to traditional
universities, they generally have smaller student groups and
place less emphasis on theoretical research. Within the Ger-
man academic system, traditional universities often view
UAS as less prestigious due to their more applied, less
theory-driven orientation.
that host relevant departments in the selected disci-
plines. Table 1 summarises the resulting sample sizes
for both the full dataset and the balanced subsample
used in downstream analyses.
For the Google-based analysis, we used the full
dataset. For the publication database analysis, we
drew on a balanced subsample of 80 professors (40
female, 40 male), randomly selected to ensure equal
representation across institutional types. We relied
on a subsample of the full dataset because extract-
ing publication lists required manual effort. Since
each professor curated their own list individually and
in non-standardised formats, the extraction process
could not be automated.
Gender was inferred from the presentation on uni-
versity profiles and treated as binary due to the limi-
tations of available data. Public websites typically in-
cluded names and profile pictures only, so gender was
manually inferred based on these attributes. We ac-
knowledge that this is not best practice, as it does not
allow individuals to self-identify. However, contact-
ing each professor individually was not feasible. The
student responsible for data collection was instructed
to assign a gender only when absolutely certain; oth-
erwise, entries were to be marked as unknown. In
practice, no such cases occurred.
Table 1: Sample size of professors of the full data set and
the subsample. The full dataset contains all female profes-
sors at UAS in the departments of computer science and
social work. For all other categories, a random sample of
50 professors was used. The random sample was used as a
comparison group for the main focus of the project, female
professors at UAS.
Full
Dataset
Subsample
Female Professors UAS
Computer Science
219 10
Female Professors UAS
Social Work
863 10
Female Professors Uni
Computer Science
50 10
Female Professors Uni
Social Pedagogy
50 10
Male Professors UAS
Computer
Science
50 10
Male Professors UAS
Social Work
50 10
Male Professors Uni
Computer Science
50 10
Male Professors Uni
Social Pedagogy
50 10
For each professor, the following information was
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
494

collected:
• Name and title
• Gender (inferred)
• Institutional affiliation
• Reported keywords
• Presence of a CV and/or picture on the university
profile
• Publication list on the university profile
Because professors manage their own profiles and
present publication lists in diverse formats, all data
was manually extracted.
4.2 Experimental Design
To examine gendered visibility in digital environ-
ments, we analyse three interconnected layers of rep-
resentation: Google search results, academic publica-
tion databases, and university profiles. Each serves a
distinct role in how professors are made visible, dis-
covered, and contextualised online.
Google Search Results. We began our analy-
sis by examining broader forms of digital visibility
through Google Search. For each professor in the
full sample, we conducted a name-based search that
included their institutional affiliation and collected
the first 100 search results. These results were cat-
egorised into the following types:
• university
• social media
• research institutes
• newspapers/media
• research profiles
• publication databases/preprint servers
We analysed the number, type, and ranking position
of these results to identify gendered patterns in digital
visibility, with a particular focus on whether algorith-
mic search systems shape differential representations
of female and male professors. Given the broader
reach of search engines and the structured nature of
Google results, this part of the analysis serves as the
primary basis for evaluating algorithmic gender fair-
ness in our study.
Publication Databases. To complement the
Google-based visibility analysis, we also examined
how academic content is retrieved in publication
databases, a step that reflects common search strate-
gies used by science journalists and other knowledge
intermediaries. It is a typical workflow to begin by
querying databases for topic-relevant keywords, and
only after identifying promising names, turn to search
engines like Google for more context. To honour this
process, we conducted an additional exploratory anal-
ysis based on academic keyword searches.
For this analysis, we focused on a balanced sub-
sample of 80 professors. From their university pro-
files, we compiled all self-reported keywords and
queried them individually in three major academic
databases: the ACM Digital Library
2
(used for publi-
cation in computer science), Springer Link
3
(used for
publication in computer science and social sciences),
and Beltz
4
used for publication in social sciences).
For each professor in our subsample, we extracted all
self-reported keywords from their university profiles
and compiled them into a single list. Each keyword
in the list was queried individually in the respective
databases, and for each query, we collected the top
1,000 results. We then attempted to match retrieved
publications to professors based on their names. We
attempted to match retrieved publications to profes-
sors based on their names, using either the full first
and last name or the first initial and last name. Given
the limited available information, this was the most
feasible matching strategy, despite the potential for
false positives. However, a manual review of the
matches confirmed that they appeared valid.
Because publication lists were not uniformly
available for all individuals in the full dataset, this
analysis was limited to a balanced subsample of 80
professors. While this sample size does not support
generalisable claims, it provides initial insights into
how academic content is retrieved and associated with
named individuals in these databases. The results
should be interpreted with caution, particularly as the
databases do not disclose how their ranking is deter-
mined; search results are typically ordered by “rele-
vance,” but the underlying criteria remain opaque. As
a result, this part of the analysis serves primarily as
an exploratory context. However, following our def-
inition of algorithmic gender fairness introduced in
Section “Algorithmic Gender Fairness”, we use the
gender composition of this subsample as a reference
for the real-world distribution against which retrieval
outputs are compared.
University Profile Completeness. In addition to
Google search results and publication databases, we
analysed the content of university profiles to capture
how professors are presented on their institutional
websites. As detailed in Subsection “Data”, this infor-
mation was manually extracted and includes the pres-
ence of a CV, a profile picture, and a publication list.
These profiles represent structured, publicly accessi-
2
https://dl.acm.org/
3
https://link.springer.com/
4
https://www.beltz.de/
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and Retrieval Algorithms for Algorithmic Gender Fairness
495
ble data curated by the professors themselves or their
institutions. In line with our definition of algorith-
mic gender fairness, we treat them as a form of real-
world data that serves as a reference point for evalu-
ating how academic professionals are represented in
digital environments such as search engines.
4.3 Findings
This section presents the main findings from our anal-
ysis, structured across three areas: Google search re-
sults, academic publication databases and the com-
pleteness of university profiles.
Publication Databases. Across all keyword-
based database queries, we retrieved a total of 48,541
unique publications. However, only 44 of these could
be matched to professors in our subsample, using ei-
ther their full name or first initial and surname. This
surprisingly low match rate highlights a significant
disconnect between the academic work professors re-
port and what is discoverable through our keyword-
based database searches.
Several factors likely contribute to this outcome.
Most importantly, our queries were limited to three
specific publication outlets, the ACM Digital Library,
Springer Link, and Beltz, chosen because they allow
for automated querying and due to their relevance in
informatics and social sciences. As a result, publi-
cations in other venues were not included. In addi-
tion, professors may not have published under the ex-
act keywords they listed on their university profiles,
or the terms may have been too broad or too specific
to yield meaningful matches. Keyword searches may
also miss publications where the terms are not promi-
nent in titles or abstracts. Further limitations stem
from the databases themselves: relevance-based rank-
ing may exclude pertinent results, and name matching
can lead to both, false negatives and false positives.
If multiple individuals share the same name, our ap-
proach may have incorrectly assigned a publication to
a professor in the sample.
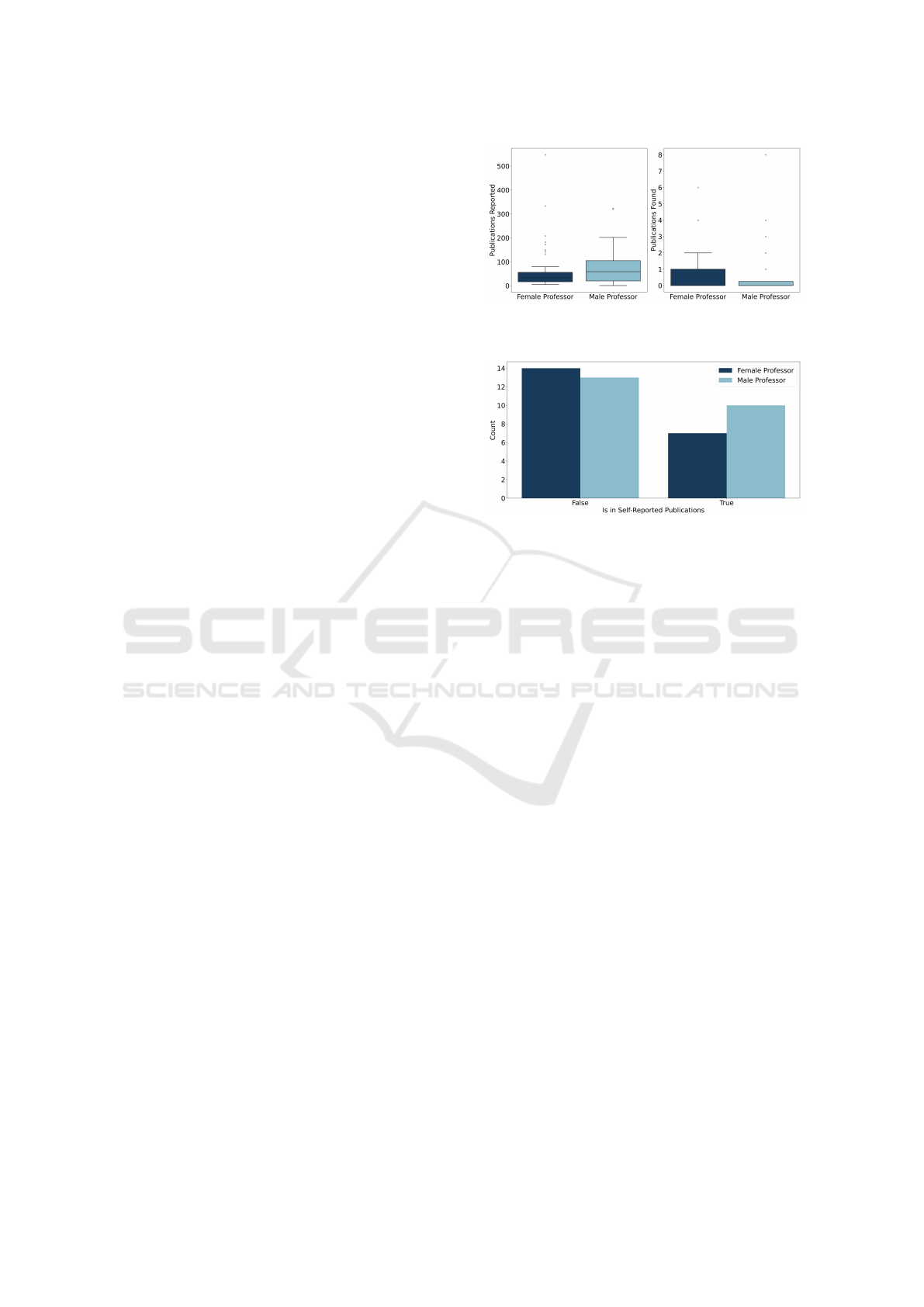
Figure 1 shows that male professors generally re-
ported more publications, including several extreme
outliers. However, very few publications were actu-
ally found through database searches for either gen-
der, highlighting the limited recall of keyword-based
retrieval in this context.
Figure 2 shows how many of the matched publi-
cations were also part of the professors’ self-reported
publication lists. While female professors had a
slightly higher number of matches, the majority of re-
trieved publications were not part of the self-reported
lists for either group. This again suggests that key-
word selection and platform coverage substantially
Figure 1: Self-reported versus found publications (via key-
words), per person.
Figure 2: Publications retrieved from databases (via key-
words) that also appeared in self-reported lists.
shape which publications become visible through
database queries.
Google Results. We next examined how profes-
sors are represented across broader digital platforms
using Google search results. For each professor in
the full sample, we retrieved and categorised the first
100 results. Figure 3 shows the number of links per
category, grouped by gender. University-related links
were the most common for both female and male pro-
fessors. Overall, male professors had more links, with
a higher median and more variation. Female profes-
sors showed a tendency for outliers and more individ-
uals having few or very few links.
Figure 4 presents the ranking positions of these
links. Female professors’ university links tended to
appear slightly higher in the result lists, while male
professors had better visibility in categories like re-
search profiles and social media. Although the differ-
ences are subtle, they contribute to an overall pattern
of gendered variation in search engine visibility.
University Profile Completeness. We also exam-
ined the content of university profiles for all profes-
sors in the full dataset. As shown in Table 2, most pro-
fessors included both a CV and a profile picture, and
over two-thirds also provided a publication list. Fe-
male professors were slightly more likely to include a
CV and a publication list, while male professors were
marginally more likely to include a picture.
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
496
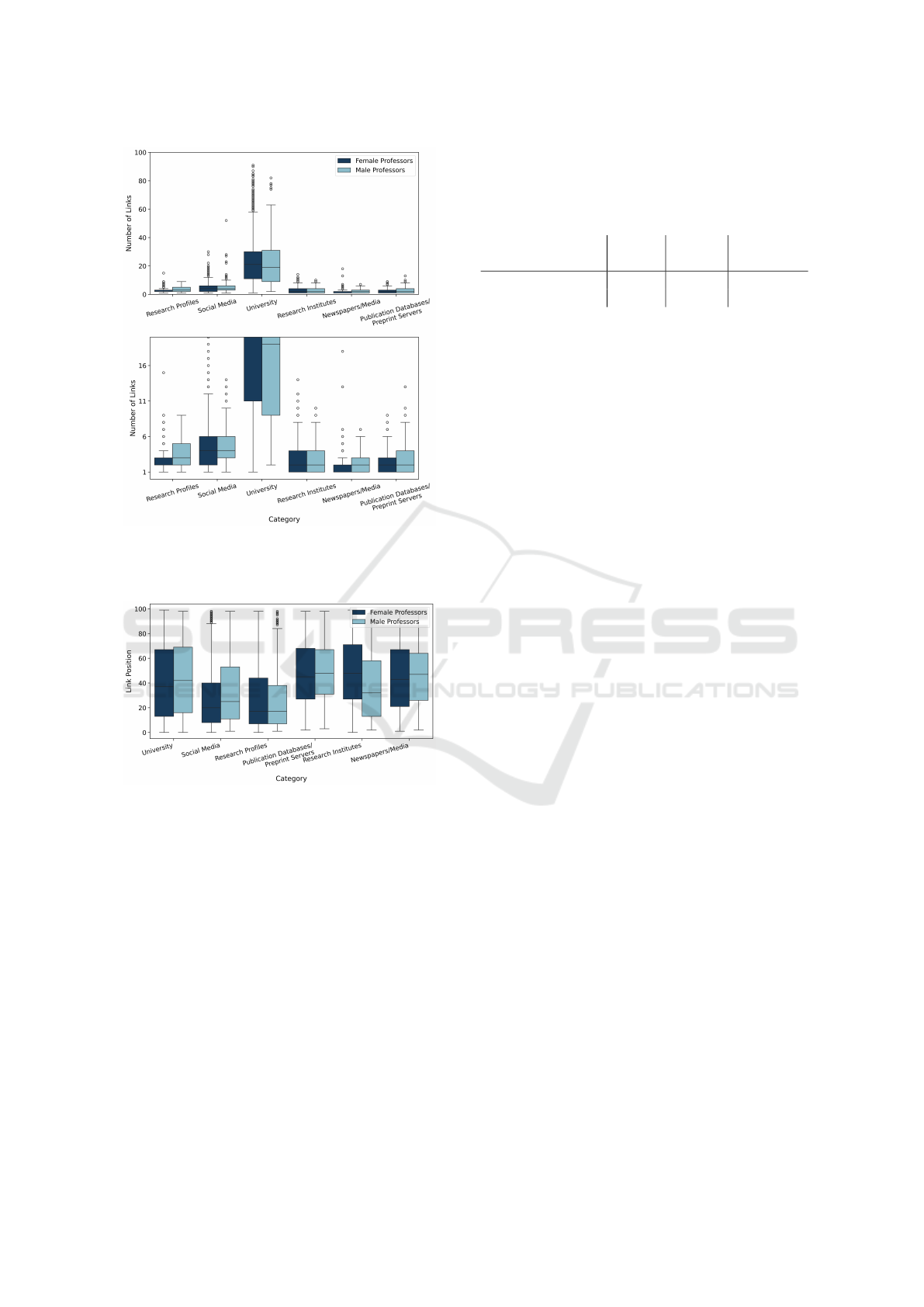
Figure 3: Number of links per category for female and male
professors. The top plot shows full data; the bottom plot
zooms into low-frequency categories.
Figure 4: Ranking position of Google search results across
categories, by gender. Lower values indicate higher rank-
ing.
4.4 Discussion
Our findings indicate that digital visibility in aca-
demic contexts is subtly but consistently gendered.
This becomes particularly evident when analysing
how algorithmic systems represent female and male
professors across different platforms. While we did
not observe overt algorithmic discrimination, patterns
in both database retrieval and Google search results
suggest that gender affects how academic expertise is
surfaced and made visible.
In publication databases, we found a substantial
gap between self-reported and retrieved publications.
This gap stems from multiple sources: limited plat-
form coverage (restricted to three specific outlets), re-
Table 2: University profile completeness for the full dataset:
CV, picture and publication list inclusion. The numbers
should be interpreted as a percentage of female professors
or a percentage of male professors, depending on the line.
Therefore, rows do not add up to 100%.
CV Picture Publication
Lists
Female Professor 68.9% 85.0% 70.2%
Male Professor 62.5% 85.9% 66.2%
liance on self-reported keywords that often did not
align with actual publication metadata, and opaque
“relevance”-based ranking mechanisms that are not
designed to ensure fair or comprehensive represen-
tation. Additionally, name-based matching intro-
duces ambiguity, especially for common names. Al-
though the sample was too small to draw general-
isable conclusions, male professors showed slightly
higher match rates, pointing to possible gendered dif-
ferences in how academic outputs are indexed and
surfaced.
In contrast, our analysis of Google search results,
conducted on the full dataset, revealed clearer pat-
terns. Male professors were consistently associated
with a higher number of links across most categories.
However, the distributions were not uniformly more
concentrated for male professors. While they had
higher medians in several categories, the spread of re-
sults varied by category and was not consistently nar-
rower than that of female professors. Female profes-
sors showed greater variability overall, with more fre-
quent low-end outliers, particularly in categories such
as university and research profiles. When consider-
ing the ranking of results, female professors’ links
tended to appear slightly higher in several categories,
including social media, research profiles, and publi-
cation databases. In other categories, such as univer-
sity and newspapers/media, the ranking distributions
were largely comparable across genders. These find-
ings suggest that while female professors are not dis-
advantaged in terms of ranking within categories, the
lower number of links may still reduce their overall
discoverability in search results.
A possible factor contributing to the lower num-
ber of search results for female professors is the way
academic profiles are structured on institutional web-
sites. While profile completeness was generally high
across the sample, we observed small gender differ-
ences: female professors were slightly more likely
to include CVs and publication lists, whereas male
professors more frequently provided a profile pic-
ture. Since images and structured information (such
as publication entries or CVs) can be indexed dif-
ferently by search engines, these differences in self-
presentation may influence how easily professors are
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and Retrieval Algorithms for Algorithmic Gender Fairness
497

linked to relevant content. What is particularly strik-
ing, however, is that despite female professors pro-
viding slightly more structured academic informa-
tion on their university profiles, they were less vis-
ible in several key categories of Google search re-
sults, most notably “research profiles,” “publication
databases/preprint servers,” “newspapers/media,” and
“university.” In other words, even though they appear
to invest more in curating their institutional presence,
this effort does not translate into greater discoverabil-
ity. Thus, while search rankings within categories do
not appear systematically biased, the reduced number
of visible links may still disadvantage female profes-
sors in terms of overall digital visibility.
Taken together, these results highlight how digital
visibility is shaped by the interaction between algo-
rithmic systems, individual presentation choices, and
institutional infrastructure. They also reflect broader
structural patterns: who appears where, how promi-
nently, and through what types of content is not ran-
dom; it is filtered through technical systems that rely
on data structures, which may themselves encode or
reflect gendered norms.
In light of our definition of algorithmic gender
fairness, our findings suggest that current systems
fall short of this ideal. Even when the intent may
not be discriminatory, existing systems amplify dis-
parities through uneven coverage, limited keyword
matching, unclear ranking mechanisms, and visibility
differences in general-purpose search results. These
systems do not just reflect the real world—they ac-
tively reshape which parts of it are seen.
Fairness, therefore, cannot be evaluated purely by
the absence of discriminatory intent or overt exclu-
sion. It must also consider the cumulative effects of
design decisions, platform constraints, and structural
imbalances in source data. Gendered visibility gaps,
even if subtle, are a form of representational inequal-
ity that algorithmic systems may unintentionally per-
petuate.
5 CONCLUSION AND FUTURE
WORK
In this paper, we introduced the concept of algorith-
mic gender fairness and evaluated it using hetero-
geneous data on German professors. By analysing
gendered patterns in academic visibility across differ-
ent institutional contexts and disciplines, we aimed to
identify structural imbalances that may arise in algo-
rithmic representations of expertise.
Our findings reveal nuanced but consistent gen-
der differences in digital visibility. Search and re-
trieval algorithms do not exhibit overt forms of gen-
der discrimination; however, subtle imbalances ap-
pear across various dimensions. Female profes-
sors were slightly more likely to complete their in-
stitutional profiles with CVs and publication lists,
while male professors reported higher median num-
bers of publications. Yet, only a small number of
self-reported publications could be retrieved from
academic databases, highlighting mismatches be-
tween metadata, keyword representation, and retrieval
mechanisms.
In Google search results, male professors were as-
sociated with a greater number of links overall, while
female professors showed more variability, including
more frequent cases of low link counts. Link categori-
sation and ranking further revealed gendered patterns:
female professors’ links tended to appear in higher
positions (i.e., closer to the top of the results list) in
categories such as university websites, research pro-
files, and social media. Male professors’ links, by
contrast, were often ranked slightly lower (i.e., fur-
ther down in the result list) in university websites
and social media, but were more numerous overall.
These differences likely reflect an interplay between
platform algorithms, institutional curation, and self-
presentation strategies.
While these patterns point to structural imbal-
ances, they should be interpreted with caution. Fac-
tors such as outdated publication lists, common nam-
ing conventions, and differing levels of online activity
likely contribute to the observed visibility gaps. The
imbalances we observed are therefore not attributable
to algorithmic bias alone, but emerge from the in-
teraction of algorithmic processes with broader so-
ciotechnical contexts.
Future research should expand on this foundation
by incorporating more inclusive gender categories,
extending the analysis beyond German academia, and
examining additional disciplines. Integrating data
from more publication databases and search engines
would also allow for a broader assessment of visibil-
ity dynamics across digital ecosystems.
Longitudinal analyses and larger, more diverse
datasets will be essential for disentangling the specific
roles played by algorithmic systems, institutional in-
frastructures, and individual behaviours. In parallel,
collaborative efforts involving academic institutions,
search engine providers, and fairness researchers are
needed to improve algorithmic transparency and ac-
countability. Only by addressing both data and design
can we move toward systems that fairly represent the
diversity of academic expertise online.
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
498

AI USAGE
The authors are not native English speakers; there-
fore, ChatGPT and Grammarly were used to assist
with writing English in this work.
6 ETHICAL CONSIDERATIONS
This paper did not involve direct interaction with hu-
man participants and relied solely on publicly avail-
able information found on university websites. As
such, ethics approval from an institutional review
board was not required. Personal data were collected
manually with the intent to minimise misclassifica-
tion, particularly in regard to gender inference. The
student responsible for data collection was instructed
to assign gender only when certainty was high and to
otherwise mark entries as unknown. No personal or
sensitive data beyond what was already publicly ac-
cessible were stored or analysed.
To protect the privacy and anonymity of the pro-
fessors included in the dataset, we will not publish
or share the collected data. We acknowledge the eth-
ical limitations of inferring gender from names and
pictures, and we explicitly address these limitations
in the paper to promote transparency and encourage
more inclusive data practices in future research.
7 ADVERSE IMPACT
STATEMENT
This paper adopts a bias-preserving definition of algo-
rithmic gender fairness, aiming to reflect real-world
gender distributions without introducing or amplify-
ing existing biases. While this approach supports
transparency and alignment with observed data, it
may also carry certain risks.
First, reflecting real-world distributions without
intervention could be misused to justify existing gen-
der inequalities, especially in contexts where struc-
tural bias is already present. Second, although we
acknowledge the existence and importance of non-
binary and gender-diverse identities, our empirical
analysis is limited to binary gender categories due to
data constraints. This limitation may contribute to the
erasure of individuals who do not identify within the
binary framework, especially if such approaches are
widely adopted without critical adaptation. Finally,
bias-preserving fairness may be misinterpreted as ev-
idence of algorithmic neutrality, potentially obscur-
ing the broader sociotechnical dynamics that shape
inequality.
We therefore emphasise that fairness assessments
should always be interpreted in light of context, data
limitations, and the values underlying system design.
We encourage future work to engage critically with
fairness definitions and to explore approaches that ad-
dress structural imbalances more directly.
ACKNOWLEDGEMENTS
This work was written by an author team work-
ing on different projects. Stefanie Urchs’ project
”Prof:inSicht” is promoted with funds from the Fed-
eral Ministry of Research, Technology and Space
under the reference number 01FP21054. Matthias
Aßenmacher is funded with funds from the Deutsche
Forschungsgemeinschaft (DFG, German Research
Foundation) as part of BERD@NFDI - grant num-
ber 460037581. Responsibility for the contents of this
publication lies with the authors.
REFERENCES
Aristotle (2009). The Nicomachean ethics (book V). Oxford
World’s Classics. Oxford University Press.
Beemyn, B. G. and Rankin, S. (2011). The lives of trans-
gender people. Columbia University Press.
Bigdeli, A., Arabzadeh, N., SeyedSalehi, S., Zihayat, M.,
and Bagheri, E. (2022). Gender fairness in informa-
tion retrieval systems. In Proceedings of the 45th In-
ternational ACM SIGIR Conference on Research and
Development in Information Retrieval, SIGIR ’22,
page 3436–3439, New York, NY, USA. Association
for Computing Machinery.
Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., and
Kalai, A. T. (2016). Man is to computer programmer
as woman is to homemaker? debiasing word embed-
dings. Advances in neural information processing sys-
tems, 29.
Bothmann, L., Peters, K., and Bischl, B. (2024). What Is
Fairness? Philosophical Considerations and Implica-
tions For FairML. arXiv:2205.09622.
Carpenter, M. (2021). Intersex human rights, sexual ori-
entation, gender identity, sex characteristics and the
yogyakarta principles plus 10. Culture, Health & Sex-
uality, 23(4):516–532. PMID: 32679003.
Caton, S. and Haas, C. (2024). Fairness in Machine Learn-
ing: A Survey. ACM Comput. Surv., 56(7):166:1–
166:38.
Corbett-Davies, S., Pierson, E., Feller, A., Goel, S., and
Huq, A. (2017). Algorithmic decision making and the
cost of fairness. KDD ’17, page 797–806, New York,
NY, USA. Association for Computing Machinery.
Dator, J. (2017). Chapter 3. What Is Fairness? In Dator, J.,
Pratt, R. C., and Seo, Y., editors, Fairness, Globaliza-
Are all Genders Equal in the Eyes of Algorithms? Analysing Search and Retrieval Algorithms for Algorithmic Gender Fairness
499

tion, and Public Institutions, pages 19–34. University
of Hawaii Press, Honolulu.
Datta, A., Tschantz, M. C., and Datta, A. (2015). Auto-
mated experiments on ad privacy settings. Proceed-
ings on Privacy Enhancing Technologies, 2015(1):92–
112.
Devinney, H., Bj
¨
orklund, J., and Bj
¨
orklund, H. (2022).
Theories of “gender” in nlp bias research. In Pro-
ceedings of the 2022 ACM Conference on Fairness,
Accountability, and Transparency, FAccT ’22, page
2083–2102, New York, NY, USA. Association for
Computing Machinery.
Dictionary, C. (2022). fairness.
Ekstrand, M. D., Das, A., Burke, R., and Diaz, F.
(2022). Fairness in information access systems.
Foundations and Trends® in Information Retrieval,
16(1–2):1–177.
Eren, E., Hondrich, L., Huang, L., Imana, B., Kettemann,
M., Kuai, J., Mattiuzzo, M., Pirang, A., Pop Stefanija,
A., Rzepka, S., Sekwenz, M., Siebert, Z., Stapel, S.,
and Weckner, F. (2021). Increasing Fairness in Tar-
geted Advertising. The Risk of Gender Stereotyping by
Job Ad Algorithms.
Fang, Y., Liu, H., Tao, Z., and Yurochkin, M. (2022). Fair-
ness of machine learning in search engines. In Pro-
ceedings of the 31st ACM International Conference on
Information & Knowledge Management, CIKM ’22,
page 5132–5135. ACM.
for Justice, E. C. D. G., Consumers., network of legal ex-
perts in gender equality, E., and non discrimination.
(2021). Algorithmic discrimination in Europe: chal-
lenges and opportunities for gender equality and non
discrimination law. Publications Office, LU.
Francazi, E., Lucchi, A., and Baity-Jesi, M. (2024). Initial
guessing bias: How untrained networks favor some
classes. In Forty-first International Conference on
Machine Learning.
Geyik, S. C., Ambler, S., and Kenthapadi, K. (2019).
Fairness-aware ranking in search & recommendation
systems with application to linkedin talent search. In
Proceedings of the 25th ACM SIGKDD International
Conference on Knowledge Discovery & Data Mining,
KDD ’19, page 2221–2231, New York, NY, USA. As-
sociation for Computing Machinery.
Janhunen, J. (2000). Grammatical gender from east to west.
TRENDS IN LINGUISTICS STUDIES AND MONO-
GRAPHS, 124:689–708.
Keyes, O. (2018). The misgendering machines: Trans/hci
implications of automatic gender recognition. Proc.
ACM Hum.-Comput. Interact., 2(CSCW).
Kleinberg, J., Mullainathan, S., and Raghavan, M.
(2017). Inherent Trade-Offs in the Fair De-
termination of Risk Scores. In Papadimitriou,
C. H., editor, 8th Innovations in Theoretical Com-
puter Science Conference (ITCS 2017), volume 67
of Leibniz International Proceedings in Informat-
ics (LIPIcs), pages 43:1–43:23, Dagstuhl, Germany.
Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik.
Kong, Y. (2022). Are “Intersectionally Fair” AI Algorithms
Really Fair to Women of Color? A Philosophical
Analysis. In 2022 ACM Conference on Fairness, Ac-
countability, and Transparency, pages 485–494, Seoul
Republic of Korea. ACM.
Konishi, T. (1993). The semantics of grammatical gender:
A cross-cultural study. Journal of Psycholinguistic
Research, 22(5):519–534.
Kramer, R. (2020). Grammatical gender: A close look at
gender assignment across languages. Annual Review
of Linguistics, 6(1):45–66.
Loi, M. and Heitz, C. (2022). Is Calibration a Fairness Re-
quirement? An Argument from the Point of View of
Moral Philosophy and Decision Theory. In 2022 ACM
Conference on Fairness, Accountability, and Trans-
parency, FAccT ’22, pages 2026–2034, New York,
NY, USA. Association for Computing Machinery.
Makhortykh, M., Urman, A., and Ulloa, R. (2021). Detect-
ing race and gender bias in visual representation of
ai on web search engines. In Boratto, L., Faralli, S.,
Marras, M., and Stilo, G., editors, Advances in Bias
and Fairness in Information Retrieval, pages 36–50,
Cham. Springer International Publishing.
Phillips, W. and Boroditsky, L. (2013). Can quirks of gram-
mar affect the way you think? grammatical gender
and object concepts. In Proceedings of the 25th An-
nual Cognitive Science Society, pages 928–933. Psy-
chology Press.
Sch
¨
utze, H., Manning, C. D., and Raghavan, P. (2008). In-
troduction to information retrieval, volume 39. Cam-
bridge University Press Cambridge.
Singh, A. and Joachims, T. (2018). Fairness of exposure in
rankings. KDD ’18, page 2219–2228, New York, NY,
USA. Association for Computing Machinery.
Urman, A. and Makhortykh, M. (2022). “foreign beau-
ties want to meet you”: The sexualization of women
in google’s organic and sponsored text search results.
New Media & Society, 26(5):2932–2953.
Verma, S. and Rubin, J. (2018). Fairness Definitions Ex-
plained. In Proceedings of the International Workshop
on Software Fairness, Gothenburg Sweden. ACM.
Wachter, S., Mittelstadt, B., and Russell, C. (2021). Bias
Preservation in Machine Learning: The Legality of
Fairness Metrics Under EU Non-Discrimination Law.
West Virginia Law Review, 123(3):735–790.
West, C. and Zimmerman, D. H. (1987). Doing gender.
Gender & Society, 1(2):125–151.
¨
Zliobait
˙
e, I. (2017). Measuring discrimination in algorith-
mic decision making. Data Mining and Knowledge
Discovery, 31:1060–1089.
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
500
