
Support Tools for Hybrid Research, EDIGA Project
Libertad Tansini
a
and Regina Motz
b
Instituto de Computaci
´
on, INCO, Facultad de Ingenier
´
ıa,
Universidad de la Rep
´
ublica, Uruguay
fi
Keywords:
Research Support Tools, EDIGA Project, Field Diary, Data Collection, Organization Management and
Analysis.
Abstract:
In the digital age, where social interactions extend into complex virtual environments, digital ethnographies
have become essential methodologies for understanding identity and community formation. However, the in-
tegration of diverse data types (textual, visual, and relational) poses significant technological challenges. This
paper presents an integrated platform designed to address the fragmentation of tools in qualitative research
workflows. The system comprises: (1) a mobile application for multimodal data collection; (2) a digital field
diary with collaborative annotation features; (3) an image anonymization tool with automatic face/blurred text
detection; and (4) a web portal for unified data visualization and analysis. Developed through an iterative
design process with researchers from the EDIGA project, a transnational study on teenage gender identities
in digital spaces, the platform solves critical points identified in traditional approaches: data silos in cloud
storage, inconsistent file naming, and disconnection between collection and analysis tools. The proposed ar-
chitecture enables end-to-end management of ethnographic data while maintaining GDPR compliance through
built-in anonymization features. The paper contributes both a technical framework for integrated ethnographic
tools and practical insights on overcoming interoperability challenges in qualitative research software.
1 INTRODUCTION
This paper presents the design and development of an
information system to support researchers working on
the EDIGA (Digital Environments and Gender Iden-
tities in Adolescence) ethnographic research project
(Ediga, 2023). The system aims to facilitate the col-
lection, management, and analysis of data in the field
of digital ethnography, ensuring the ethical treatment
of sensitive data.
The EDIGA project examines how digital envi-
ronments influence the gender identities of adoles-
cents in different sociocultural contexts, specifically
in Spain, Mexico, and Uruguay. To this end, the
project uses digital ethnography, a research method-
ology focused on the study of the cultural and so-
cial practices of individuals and communities in dig-
ital spaces (Pink et al., 2019; Barajas and Carre
˜
no,
2019). Digital ethnography is based on qualitative
methods such as participant observation, structured
interviews, and online data analysis, with the aim of
examining the dynamics of interaction between indi-
a
https://orcid.org/0000-0001-6017-0114
b
https://orcid.org/0000-0002-1426-562X
viduals and digital technologies, as well as the socio-
cultural impact of these practices on their daily lives.
However, although direct observation of adolescent
interactions on social media is a valuable source of in-
formation, manual data collection has significant lim-
itations. These include: (1) the demand for intensive
human resources to monitor profiles and record rele-
vant activities, and (2) the risk of systematic biases or
errors during collection, derived from the subjectivity
of the researcher.
To address these challenges, our study explores
the potential of automated data extraction techniques
combined with the active participation of adolescents
through mobile applications. As a main contribu-
tion, we present AppEDIGA (Luongo and Colombo,
2021), a platform designed for the collection of data
on social media use and exposure, ensuring robust
privacy mechanisms. This approach not only in-
creases the efficiency and accuracy of digital ethno-
graphic studies, but also reduces dependence on man-
ual methodologies, enabling proactive and scalable
data acquisition directly from study subjects.
The rest of the article is organized as follows: Sec-
tion 2 presents the proposed mobile application for
data collection. Section 3 presents the data manage-
534
Tansini, L. and Motz, R.
Support Tools for Hybrid Research, EDIGA Project.
DOI: 10.5220/0013831000004000
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2025) - Volume 2: KEOD and KMIS, pages
534-541
ISBN: 978-989-758-769-6; ISSN: 2184-3228
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

ment portal, Section 4 presents the general architec-
ture of the system, and Section 5 shows aspects of
the implementation and the first results. Section 6
presents a proposed tool for image anonymization. Fi-
nally, Section 7 presents some conclusions and lines
of future work.
2 MOBILE APPLICATION FOR
DATA COLLECTION
Prior to the development of a mobile application for
data collection for the EDIGA project, the EDIGA
team studied the current social context to find out
which social networks were being used by teenagers
at that time. It was concluded that the most widely
used applications are: Discord, TikTok, and Insta-
gram. Therefore, the functionalities offered by the
APIs of these platforms for data extraction were ana-
lyzed.
Discord API: In order to use the Discord API, authen-
tication is required. The process includes the use of
OAuth2, which requires a valid redirect URI to obtain
a code that is then sent in a request to the server to ob-
tain a token (Discord, 2023). With regard to the user,
the data obtained is very basic (Discord-gui, 2023):
username, email, and other information that indicates
usage and interactions on the network but is not in-
tended to provide information about a particular user.
Hence, it is not very useful for the intended purpose
of the application.
TikTok API: TikTok’s official material for developers
is designed for embedding videos or sharing links,
not for obtaining user information. There are several
unofficial APIs, but their use can be risky. If Tik-
Tok makes changes to its software structure, it is very
likely that these unofficial APIs will stop working.
Instagram API: The social network Instagram has two
APIs: the Graph API, for business or creator ac-
counts, and the basic display API for regular users.
The accounts of the individuals subject to EDIGA’s
investigation are not businesses, so the second API
applies. This API provides restricted information
about the user; only some data about the multimedia
files that the user has published can be obtained. The
information of interest to the project, such as num-
ber of followers, likes, among others, is only accessi-
ble from the Graph API, which does not apply in this
case for the reasons mentioned above. The alterna-
tive of scraping directly from the Instagram website
was not considered, as scraping violates Instagram’s
terms of service (item 10 of the terms). On the other
hand, the Instagram API does not allow logging in,
but rather requires using Facebook login if authenti-
cation is desired. Facebook login was therefore im-
plemented, although this implies some limitations to
the project: first, it is necessary to have the Facebook
application on the device. Second, since the intention
is to use Facebook information to obtain an Instagram
session, it is necessary for the teenager to link their
Instagram and Facebook accounts. These two restric-
tions mean that users must take action to participate in
the project, which is a risk because it may not happen,
and therefore the expected data could not be obtained.
In order to obtain information from the API, it is nec-
essary to have permission from Instagram so that the
application to be developed can request the relevant
permissions from the user (application review). This
process requires the application to be in an advanced
state, as it is necessary to upload the application in its
near-final version and create a screenshot video show-
ing exactly how the data will be used, among other
elements (Instagram-gui, 2023). Given the character-
istics of the EDIGA project, this option was ruled out.
Despite the limitations encountered, it can be con-
cluded that Instagram is the network that has an API
available to query some of the data that users upload
to their accounts. Instagram is a primarily visual so-
cial network where users can post photos and short
videos, apply effects to them, and also interact with
other people’s posts through comments, messages,
and emoticons such as likes and dislikes.
As a result of this analysis, the EDIGA project de-
cided to work with Instagram, and a series of forms
were defined in advance as a source of quantitative
and qualitative data collection. These forms were de-
signed for teenagers between the ages of 13 and 17
and included an informed consent clause whereby, if
they so wished, participants agreed to have their Insta-
gram accounts monitored by an assigned researcher
who would make observations about the subject’s be-
havior on the social network. These were referred to
as “friend accounts,” and were necessary because they
allow the researchers to view the teenagers’ activity
even if their profiles are private. In addition, it was de-
cided to supplement the observations of Instagram ac-
counts with a mobile application (AppEDIGA) whose
main functionality is to automate the process of col-
lecting data from study participants through forms de-
signed to be answered at different stages of the re-
search. Through the use of the application in the back-
ground, information regarding the time spent on In-
stagram is captured. This data is uploaded directly to
a relational database.
The application was used by research teams in
Mexico and Spain, which together collected around
450 records, 400 of which came from Mexico and the
Support Tools for Hybrid Research, EDIGA Project
535

rest from Spain. In addition, 50 images were volun-
tarily submitted. The fact that the second and third
forms were not mandatory meant that the number of
responses decreased, with just over 100 for the in-
termediate form and 33 for the final form. Most of
the data entered came from Mexico because the re-
searchers held a face-to-face meeting where they ex-
plained the app installation process to the teenagers
and answered the most common questions.
3 DATA COLLECTION WITHIN
THE EDIGA PROJECT
One of the most critical stages in digital ethnographic
research is fieldwork, where the behavior of study
subjects on social media is analyzed. During this
phase, qualitative data is generated through system-
atic observations and field notes, which require spe-
cialized tools for organization and analysis. In the
case of the EDIGA team, this process relied on Mi-
crosoft Teams for collaborative file management and
Atlas.ti (AtlasTI, 2024) for qualitative data process-
ing. However, this approach had significant limita-
tions: (1) the lack of a unified standard in the nam-
ing and categorization of attached images, which led
to inconsistencies among researchers, and (2) the ab-
sence of a defined methodology for integrating quan-
titative data from the project’s mobile application
(AppEDIGA) with qualitative observations.
In particular, the data generated by the mobile ap-
plication were not centrally accessible, forcing the
team to query the database directly. This fragmen-
tation between the qualitative and quantitative com-
ponents made data triangulation and comprehensive
analysis difficult.
To address these challenges, PortalEDIGA was
designed, a unified platform that allows for: (1) stan-
dardized collection of qualitative data (observations,
field diaries, and metadata), (2) qualitative analysis
assisted by computational tools, and (3) visualization
of quantitative metrics in real time. This integration
not only optimizes methodological consistency but
also facilitates interoperability between the qualitative
and quantitative dimensions of the research.
3.1 Functional Requirements
This section describes the five categories of functional
requirements that were identified and later guided the
implementation of PortalEDIGA.
In terms of User Administration, the goal is to be
able to: create new researcher users and assign roles
(administrator/researcher), edit researcher user roles,
and view a list of all registered researcher users.
For Session, the goal is for a researcher to be able
to: log in with a username and password and log out.
For Subjects, researchers should be able to: view
a list of subjects and their aliases, Instagram user-
name, age, gender, and country; search for a sub-
ject by Instagram username or alias; filter subjects by
age, gender, and country; create a new subject with an
alias, age, country, gender, and Instagram username;
edit all subject data; and delete a subject.
With regard to Subject Profile, researchers should
be able to: view a subject’s profile with all their ac-
tivity in the AppEDIGA; view the gallery with all the
photos that the subject uploaded through the appli-
cation; add a comment to an image uploaded by the
subject; view a list of all comments made about the
subject along with their creation date and the user who
made them. They can also create a comment for a sub-
ject, attach a photo, and indicate the title, type of post,
number of likes, number of comments, date and time
of publication, whether it contains music and what
kind, and the text of the comment. Delete a comment,
view a list of field diary entries for the subject, cre-
ate a new field diary entry, reference photos uploaded
to the portal and save the creation date, delete a field
diary entry. Download a field diary entry in docx for-
mat Edit a field diary entry and save the edit date, add
tags for all images on the portal. When adding a new
tag, it must be saved for later use, receive suggestions
when tagging an image, export images with blurred
areas so that subjects and places are not recognizable.
3.2 Non-Functional Requirements
This section describes the non-functional require-
ments defined in conjunction with the researchers.
Free open source software, throughout develop-
ment, the use of free and open source software is pri-
oritized. Among its advantages are freedom of cus-
tomization, ease of integration, access to source code,
and no additional costs to the project.
Economical infrastructure, the EDIGA team ex-
pressed interest in keeping costs low without affecting
the performance and operation of the system. Span-
ish language: since all EDIGA researchers are from
Spanish-speaking countries (Uruguay, Mexico, and
Spain), the language of the portal must be Spanish.
Web adaptability, implement the web portal in
a responsive manner (ability of HTML code to adapt
to different device screen sizes). That is, ensure its
proper functioning on mobile and desktop devices.
Security and privacy, the research handles sen-
sitive data and has a confidentiality agreement with
KMIS 2025 - 17th International Conference on Knowledge Management and Information Systems
536

the subjects. In order to comply with this agreement,
handling data securely is a fundamental requirement.
Concurrency, ensure proper functioning with
multiple users using the system in parallel without af-
fecting its performance.
Usability, it is important to ensure the usability of
the system through a user-friendly and intuitive inter-
face that can be operated without the need for training
or support.
4 DESIGN AND TOOLS
This section presents the proposed solution that meets
most of the requirements detailed in the previous sec-
tions.
The portal architecture was divided into five main
modules: the mobile application, the web application,
the mobile server, the web server, and the database.
These are shown in Figure 1.
Figure 1: Architecture of the field diary system for EDIGA.
This architecture is a variation of the classic three-
layer Client/Server architecture, which consists of
two servers, one for each type of client, mobile and
web, and a shared database. This type of architecture
involves three main types of components: servers,
clients that use the services offered by the servers, and
database servers that store the data.
4.1 Relational Model
For the web portal, we decided to work on the same
relational database used by the mobile application,
since it had to consume the data collected by the ap-
plication and at the same time store new data gener-
ated by the researchers. The entities of the relational
database are briefly described in this section.
• User: This entity is inherited from the existing
database design used by the ediga-app. Before the
development of the web portal, it only hosted sub-
jects registered through the mobile application,
storing an identifier and their country of origin.
Once the development of the portal began, it was
also used to store subjects who are manually reg-
istered by researchers through the web portal.
• UserRegisterInfo: This entity stores subject reg-
istration data, such as gender, age, and Instagram
username. Like the User entity, it is inherited
from the mobile application and stores informa-
tion about subjects registered through the ediga-
app and entered through the web portal.
• MiddleFormAnswers and EndFormAnswers:
Entities inherited from the ediga-app model. They
store the subjects’ responses to the mid- and end-
of-research process forms. These responses are
consumed by the web portal and displayed in each
subject’s profile.
• DailyUsage: Entity inherited from the ediga-app
model. Stores the daily use of Instagram for each
subject registered in the application. The portal
consumes this data and displays it on its general
metrics screen.
• Photo: Entity inherited from the ediga-app
model. Stores images shared by the user during
the research process, along with their answers to
a series of three questions about that image.
• EdigaUser: Models the users of the ediga-app,
i.e., the researchers. Among the users of the por-
tal, there are administrator users who have permis-
sions to register and/or delete other users, as well
as assign roles to them.
• Observation: Represents the observations that
researchers create about the subjects’ posts. These
observations can be either about images uploaded
through the ediga app, in which case they are
linked to them through the photo id attribute,
or about posts that subjects made on Instagram.
In the latter case, attributes such as likes,
comments, and type are used to record the partic-
ularities of each post. Each observation has a free
text field in which the researcher records any com-
ments they deem relevant about the subject and
the publication in question.
• DiaryEntry: Represents entries to the Field Di-
ary section, in which each researcher can en-
ter notes on the daily fieldwork they carry out
throughout the research.
4.2 Tools
For the implementation of the frontend (the part of a
program that a user can access directly) of the web
portal, it was decided to use the React library. This
is an open-source library used when building inter-
faces. Through the use of JavaScript, it offers a robust
Support Tools for Hybrid Research, EDIGA Project
537
working environment for programming and facilities
for generating dynamic user interfaces. For the imple-
mentation of the interface, Material (MUI, 2023), Re-
act’s user interface component library, was used. For
some functionalities, it was necessary to add a text
editor, ReactQuill (Reactquill, 2023) was chosen. For
requirements related to exporting the subject list and
field diary, it was necessary to use libraries that would
allow this information to be downloaded in docx and
xlsx/csv format (an XML-based file format enabled
for Excel 2007 to 2013 macros, and CSV (Comma
Separated Values) The backend was implemented as
a REST API (API, 2023).
5 IMPLEMENTATION AND
RESULTS
The structure of the web portal follows the layout of
a control panel. There is a vertical menu on the left
side of the screen with the following options: Metrics,
Subjects, Administrator Section, and Log Out. There
are two types of users who can access the web por-
tal: those with an administrator role, who have access
to all menu options, and users with a researcher role,
who can access all options except the Administrator
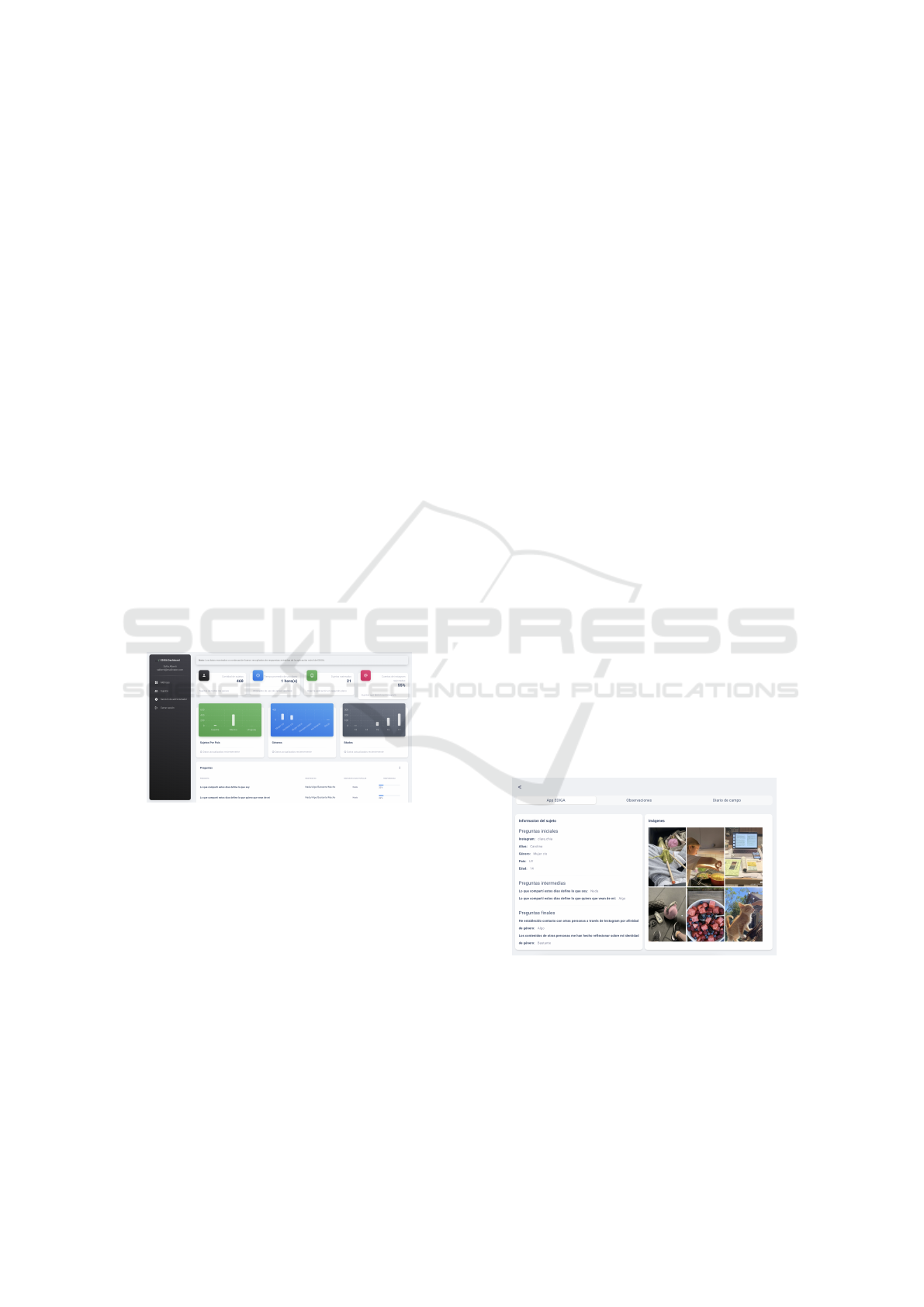
Section, see Figure 2.
Figure 2: Panel layout.
5.1 Web Portal Access
When accessing the web portal for the first time, the
login screen is displayed. To log in, the user must
enter their email address and password. An adminis-
trator user was created in the database so that different
researcher users could then be created through it. Re-
searchers are stored in the EdigaUser table, and each
password is encrypted using the bcrypt library (By-
cript, 2023), which implements the Blowfish block ci-
pher algorithm (Schneier, 1994). This algorithm has a
good level of protection against attacks and has been
used by Linux distributions such as SUSE Linux and
OpenBSD.
5.2 Metrics
The home page is the metrics page. It displays data
corresponding to those subjects who use the mobile
application, such as the number of subjects per coun-
try, gender, and age, as well as the most common re-
sponses to the different questions asked. All data col-
lected through the mobile application is used as quan-
titative data.
5.3 Subjects
The Subjects section lists all participants, including
those created using the mobile app and those created
by researchers on the portal. The list of subjects can
be filtered by registration data (age, gender, and coun-
try) and allows searching by alias or Instagram ac-
count. A file in xlsx or csv format can be downloaded
with the data shown in the list, either with or without
filters applied. This file includes the registration infor-
mation and intermediate and final responses that the
research subjects entered in the mobile application.
The xlsx library, mentioned above, was used to im-
plement this functionality. Since not all participants
agree to use the mobile app or have an Android phone
to install it, subject creation and editing features were
added to the panel. The fields requested are the same
as those requested by the mobile app, with the addi-
tion of the alias field. When creating or editing a sub-
ject, the following checks are performed: uniqueness
of the Instagram user (if provided) and that the basic
data is not empty. If these conditions are not met, the
registration or editing cannot be completed. In addi-
tion, it is possible to delete a subject from the editing
screen.
Figure 3: Subject profile.
By selecting one of the subjects, you can access
their profile, which is divided into three tabs, Figure
3. The first is the ediga-app, which displays the initial,
intermediate, and final responses that have been en-
tered into the mobile application, along with a gallery
of images that were voluntarily uploaded by the sub-
jects also through the application. The images can be
KMIS 2025 - 17th International Conference on Knowledge Management and Information Systems
538

viewed individually. In this view, it is possible to cre-
ate an observation related to the image, allowing the
researcher to write a title and an observation in the
text editor. The editor is obtained from the ReactQuill
library, mentioned above. The comment created will
be found in the list of comments made on the subject
(a feature explained later). When returning to the pro-
file, the Comments tab can be selected, which lists all
the comments made on images or specific comments
that the researcher made on the research subject, Fig-
ure 4.
Figure 4: List of observations created for a subject.
The functions for viewing, adding, deleting, and
editing observations are implemented. For specific
observations, in conjunction with the researchers, it
was considered important to be able to record the type
of publication on which the observation was made,
the number of likes and comments, the date it was
published, and, if it contained music, to record certain
data about it, such as the author and lyrics, Illustration
6. It is also possible to upload an image associated
with the observation, which will be saved in Base64
format in the database. By editing an observation, the
researcher has the possibility of deleting it.
The last tab in the subject’s profile is the field di-
ary, with all the entries that have been made. In this
view, it is possible to create, view, edit, and delete a
field diary entry. When creating an entry, as in the
case of the observation, the researcher is presented
with a free text field. This functionality was created
with the intention of allowing researchers to express
the conclusions they reach based on their observa-
tions. ReactQuill is again used as the editor, and its
main advantage is the ability to cross-reference other
observations or any page within or outside the portal
that you want to refer to. This way, if you reach a con-
clusion based on a certain observation, the latter can
be easily referenced and, when accessed, opens in a
new tab. It also allows to upload images and videos
that enrich the research.
The view, edit, and modify options also allow
users to download the text of the field entry along
with all its components in docx format. This is done
using the library mentioned earlier in the description
of technologies, html-docx-js, which transforms the
content into Word Processing ML (markup language).
This allows researchers to migrate entries to their per-
sonal devices or continue analysis from AtlasTI.
5.4 Researcher Administration
Only researchers with an administrator role have ac-
cess to the administrator section. This section lists
the different researchers with their role and country.
In this view, a researcher can be deleted by clicking
on the trash can icon. For double confirmation, this
icon will change to a button with the word delete, and
once clicked, the researcher will be deleted. In this
view, the registration and editing of a researcher has
been implemented, which consists of a form that in-
cludes the entry of a name, email, password, selection
of the country to which they belong, and the role to be
assigned, either researcher or administrator.
5.5 Platform Deployment
For the deployment of the web portal, work was done
on automating the compilation process, updating the
database, downloading and updating dependencies,
creating deployable packages, and making the server
available, with the intention of orienting the project
toward continuous integration and continuous deliv-
ery (CI/CD).
6 IMAGE ANONYMIZATION
Anonymization is the act of removing any reference
to the identity of entities or individuals in specific
data, it involves removing information that could
identify a specific individual.
The EDIGA research project works with images
uploaded by participants via the mobile app or im-
ported by the EDIGA team. Researchers have access
to the Instagram accounts of participants who have
given their consent to be followed. There, they ob-
serve the participants’ behavior on social media, tak-
ing screenshots of their posts on the home screen, sto-
ries, live videos, and comments. These screenshots
can be imported to the web portal in order to record
observations about them. These images often contain
the subject’s face, the faces of other people, parts of
their bodies, as well as identifiable physical locations,
such as street signs or recognizable buildingsAt the
end of the investigation, the EDIGA team must pub-
lish the results of the work carried out, presenting the
evidence of the process and a set of the images stud-
ied with their corresponding observations. When pre-
Support Tools for Hybrid Research, EDIGA Project
539
senting them, it is necessary to edit these images in
order to protect the privacy of the subjects, ensuring
that they are not identifiable, but without losing the
essence of the image.
A key aspect of achieving automatic anonymiza-
tion of an image is the detection of the object or sec-
tion relevant to this process. To understand how cur-
rent tools with this functionality work, this section
studies academic publications, selecting and high-
lighting the most widely used object detection mod-
els. This allows them to be compared based on scien-
tific publications and community support. Some com-
parisons are made using comparative tables present in
each scientific publication, since, in general, the same
data sets are used for the evaluations.
The essential requirements for the anonymization
tool include aspects of Session, User Configuration,
Manual Anonymization, and Automatic Anonymiza-
tion. It is necessary for researchers registered on the
platform to be able to log in and log out at any time
to ensure account privacy. Authenticated researchers
must be able to modify their user data to keep their ac-
counts up to date. Authenticated researchers must be
able to upload image sets from the file system to apply
selectable obfuscation filters and send the processed
images to the server, as well as have options to down-
load the anonymized images and save them. There
should be the possibility of automatic anonymization
by uploading a set of images from the file system to
automatically apply obfuscation methods to areas that
a trained model considers to be regions of interest, as
well as the ability to download them.
The architecture of the anonymization tool is orga-
nized into three main modules: the web application,
the server, and the database. These are shown in Fig-
ure 5.
Figure 5: Architecture diagram of the anonymization tool.
For face detection in images, the YOLO (You
Only Look Once) algorithm (Redmon et al., 2015)
was used, known for its high accuracy and speed
in object detection tasks. YOLO was integrated
with OpenCV (Opencv, 2023), an open-source library
specializing in image processing, to apply different
anonymization methods, such as blurring, pixelation,
and region blocking. In addition, ONNX Runtime
(ONNXRuntime, 2024) was used to run the machine
learning model. The prototype was also designed to
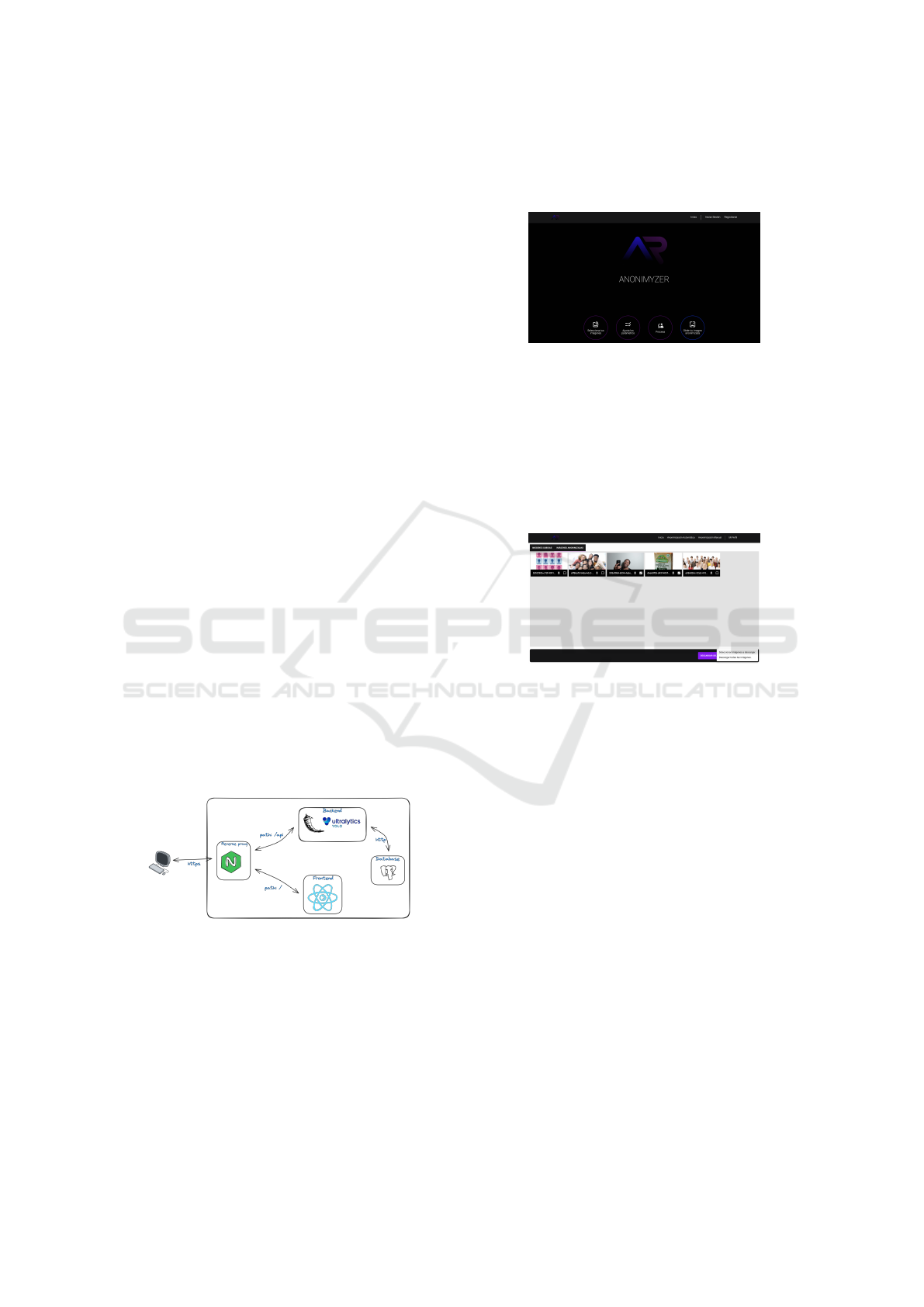
be deployed in both local and in cloud environments.
Figure 6: Interface of the anonymization tool “Anon-
imyzer”.
In terms of evaluation, the tool underwent vari-
ous tests that demonstrated its ease of use, efficiency,
and security. The integration of different technologies
and tools made it possible to develop a robust solution
that meets the requirements offering an effective and
ethical way to anonymize images for use in social re-
search, see Figure 7.
Figure 7: Example of image anonymization with the
“Anonymizer” tool.
The strengths of the tool include the ability to han-
dle large volumes of data, flexibility to integrate with
other tools, and the possibility of deployment in both
local and cloud environments, offering scalability and
remote accessibility while preserving the privacy of
individuals and maintaining the data for research.
7 CONCLUSIONS AND FUTURE
LINES OF WORK
The system developed within the framework of the
EDIGA Project shows the inherent complexity of col-
lecting data on social media, mainly due to privacy
policies that restrict access to detailed information
about users. These structural limitations, common on
platforms such as Facebook, make it necessary to es-
tablish institutional agreements with service providers
to access relevant data, which constitutes a significant
challenge in digital social research.
Faced with these restrictions, our team imple-
mented an alternative solution by developing a mobile
KMIS 2025 - 17th International Conference on Knowledge Management and Information Systems
540

application that allows for the proactive collection of
data directly from the study subjects. This method-
ological approach proved particularly effective in the
Mexican context, where researchers conducted face-
to-face sessions to: (1) facilitate the installation of the
application, (2) explain the research objectives, and
(3) address concerns.
The iterative incremental development allowed for
feedback at different stages of development by re-
searchers through demonstrations, guided presenta-
tions, and usability tests. The latter were conducted
with a small number of researchers to obtain an initial
idea of the product’s conformity. For proper valida-
tion, it would be necessary to increase the number of
users testing the portal in production in order to ob-
tain suggestions for subsequent iterations. The tech-
nologies used met the initial requirement of being free
and open source. They were tailored to development
needs and were easy for the team to adopt. The archi-
tecture planned during the design of the solution was
implemented using services such as CodePipeline to
comply with the CI/CD method.
Most of the functional requirements were met,
and a step-by-step deployment guide was generated,
which may be useful for future projects. The platform
is considered adaptable to projects on different topics
that share characteristics such as the entry and anal-
ysis of qualitative data and the management of infor-
mation entered by external means, such as the mobile
application.
As a side result of the implementation, the
achievements in terms of interdisciplinary work be-
tween the technical development team and EDIGA
researchers stand out. There was a clear contrast
between the beginning and the end of the project.
Thanks to the collaboration of the two teams, greater
interest in the development of the portal was gener-
ated, and researchers began to participate more ac-
tively in proposing new functionalities. Bringing re-
searchers closer to this type of technology is a valu-
able result and opens the door to the development of
new tools.
The complementary modules for labeling and data
cleaning are considered essential for the future devel-
opment of the platform, as they complement the solu-
tion developed in this project.
In addition, training of facial detection algorithms
should continue using real images from the EDIGA
study. This would help to obtain more accurate re-
sults and avoid errors. Finally, as future work in this
area of research, the functionality could be extended
to other types of images where it is necessary to hide
parts of the body, street names, or identifiable physi-
cal locations.
ACKNOWLEDGEMENTS
We thank Sof
´
ıa Alberti, Martina Font, Luc
´
ıa Nocetti,
Cecilia Toledo, Aymara Melo, Guillermo Maiese,
Mart
´
ın Corredera, Viviana Luongo and Lea Colombo
for their work in this project, and all the EDIGA re-
searchers.
REFERENCES
API, R. (2023). Microsoft. best practices for restful
api design. https://learn.microsoft.com/en-us/azure/
architecture/best-practices/api-design.
AtlasTI (2024). AtlasTI. https://atlasti.com/es/.
Barajas, K. B. and Carre
˜
no, N. P. (2019). Desaf
´
ıos de la
etnograf
´
ıa digital en el trabajo de campo onlife. Virtu-
alis, 10(18):134–151.
Bycript (2023). Bycript. https://www.npmjs.com/package/
bcrypt.
Discord (2023). Discord developer portal, documentation,
reference, guild object (2021). https://discord.com/
developers/docs/resources/guild#guild-object.
Discord-gui (2023). Discord: Discord developer por-
tal, documentation, reference, user object (2021).
https://discord.com/developers/docs/resources/user#
user-object.
Ediga (2023). Proyecto EDIGA: Entornos Digitales e Iden-
tidades de G
´
enero en la Adolescencia. http://stellae.
usc.es/ediga/.
Instagram-gui (2023). Facebook: Contenido multimedia
de instagram - plataforma de instagram (2021).
https://developers.facebook.com/docs/instagram-api/
reference/ig-media.
Luongo, V. and Colombo, L. (2021). Aplicaci
´
on para
proyecto ediga. Proyecto de grado. Facultad de In-
genier
´
ıa, Universidad de la Rep
´
ublica (Uruguay).
MUI (2023). MUI: React component library. https://mui.
com/.
ONNXRuntime (2024). ONNX Runtime. https://
onnxruntime.ai/index.html.
Opencv (2023). Opencv. https://opencv.org/.
Pink, S., Horst, H., Postill, J., Hjorth, L., Lewis, T., and Tac-
chi, J. (2019). Etnograf
´
ıa digital. Ediciones Morata.
Reactquill (2023). Reactquill. https://github.com/
zenoamaro/react-quill.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.
(2015). You only look once: Unified, real-time ob-
ject detection. cite arxiv:1506.02640.
Schneier, B. (1994). Description of a new variable-length
key, 64-bit block cipher (blowfish). In Anderson,
R., editor, Fast Software Encryption, pages 191–204,
Berlin, Heidelberg. Springer Berlin Heidelberg.
Support Tools for Hybrid Research, EDIGA Project
541
