
Large Language Models in Open Government Data Analysis:
A Systematic Mapping Study
Alberto Luciano de Souza Bastos
a
, Luiz Felipe Cirqueira dos Santos
b
,
Shexmo Richarlison Ribeiro dos Santos
c
, Marcus Vinicius Santana Silva
d
,
Marcos Cesar Barbosa dos Santos
e
, Marcos Venicius Santos
f
, Marckson F
´
abio da Silva Santos
g
,
Mariano Florencio Mendonc¸a
h
and Fabio Gomes Rocha
i
Federal University of Sergipe, S
˜
ao Crist
´
ov
˜
ao, Sergipe, Brazil
{betobastos.ba, lfcs18ts,shexmor, lowpoc.developer, marcos.cesar.se, Marcksonfabio22,
Keywords:
Large Language Models, Open Government Data, Systematic Mapping Study, Public Administration, Artificial
Intelligence, Digital Government, Evidence-Based Software Engineering, Government Technology Adoption.
Abstract:
Background: The convergence of Large Language Models (LLMs) and open government data presents
transformative potential for public administration, yet there exists a significant gap in understanding adoption
patterns in this emerging domain. Aim: This study analyzes adoption patterns of Large Language Models
in open government data analysis, characterizing researchers’ perceptions about benefits, limitations, and
methodological implications. Method: We conducted a systematic mapping study following Petersen et
al. (2008) guidelines, searching six academic databases. After screening, 24 primary studies were analyzed
covering contribution types, validation methods, government domains, and LLM models. Results: Analysis
revealed GPT model family predominance, with health as priority domain (4 studies), followed by security
and justice (3 studies each). Conversational interfaces and information extraction were dominant functions (9
studies each). Conclusions: The field demonstrates evolution toward hybrid solutions integrating LLMs with
structured knowledge resources. Consistent challenges across technologies—ethical issues, privacy concerns,
and data quality—indicate the need for unified frameworks. Future research should focus on developing
practical solutions to achieve technical maturity comparable to established software engineering fields.
1 INTRODUCTION
The digital era has transformed government-citizen
relationships through Open Government Data (OGD) -
information produced by government entities for un-
restricted access (Wang et al., 2024). Simultaneously,
Large Language Models (LLMs) emerge as promis-
ing AI technology with remarkable natural language
processing capabilities (Cabral et al., 2024).
The convergence between LLMs and OGD
a
https://orcid.org/0009-0002-3911-9757
b
https://orcid.org/0000-0003-4538-5410
c
https://orcid.org/0000-0003-0287-8055
d
https://orcid.org/0000-0002-1234-5678
e
https://orcid.org/0000-0002-7929-3904
f
https://orcid.org/0009-0006-1645-6127
g
https://orcid.org/0009-0001-6479-1900
h
https://orcid.org/0000-0003-0732-3980
i
https://orcid.org/0000-0002-0512-5406
presents unexplored transformative potential. While
governments digitize public information, much re-
mains in unstructured formats, which limits its prac-
tical use (Siciliani et al., 2024). LLMs can transform
this data into actionable information, enhancing trans-
parency and innovation.
However, a significant gap exists in understanding
how LLMs are effectively applied in OGD analysis.
The urgency is justified by the rapid advancement of
LLMs and their potential for a disruptive impact on
public sector transformation (Androutsopoulou et al.,
2024). Models like GPT-4, Claude and Gemini present
unprecedented capabilities, while ethical and gover-
nance issues emerge as fundamental considerations
(Mureddu et al., 2025; Dua et al., 2025).
This research addresses this gap through systematic
analysis of LLM adoption patterns in OGD contexts,
characterizing researchers’ perceptions about benefits,
limitations, and methodological implications to inform
strategic technology investment decisions and data
404
Bastos, A. L. S., Cirqueira dos Santos, L. F., Ribeiro dos Santos, S. R., Silva, M. V. S., Barbosa dos Santos, M. C., Santos, M. V., Santos, M. F. S., Mendonça, M. F. and Rocha, F. G.
Large Language Models in Open Government Data Analysis: A Systematic Mapping Study.
DOI: 10.5220/0013777300003985
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Web Information Systems and Technologies (WEBIST 2025), pages 404-411
ISBN: 978-989-758-772-6; ISSN: 2184-3252
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

policy implementation in the public sector.
The article is organized as follows: Section 2
presents the theoretical background; Section 3 details
the methodology; Section 4 presents results; Section 5
discusses implications; and Section 6 concludes with
future directions.
2 BACKGROUND
This section provides a theoretical foundation struc-
tured in three parts: Large Language Models funda-
mentals, open government data concepts, and their
intersection in public administration applications.
2.1 Large Language Models:
Fundamentals and Evolution
Large Language Models represent significant advances
in natural language processing, demonstrating capa-
bilities in text analysis, content generation, and in-
formation extraction (Bronzini et al., 2024). These
technologies have particular relevance for governmen-
tal applications where automated processing of pub-
lic information becomes critical (Alexopoulos et al.,
2024). Contemporary LLM implementations have
opened possibilities for enhancing public sector effi-
ciency through intelligent data processing and natural
language interfaces (Siciliani et al., 2024).
LLM evolution has been marked by advances in
parameter scale, training data quality, and model archi-
tectures (Donner et al., 2024), enabling sophisticated
applications while questions about reliability and trans-
parency remain crucial (Germani et al., 2024).
2.2 Open Government Data: Concepts
and Challenges
Open Government Data constitutes a fundamental pil-
lar of transparency and innovation in the public sec-
tor (Nikiforova et al., 2024), presenting challenges in
quality, interoperability, and usability (Alexopoulos
et al., 2024). Public data ecosystem evolution has been
driven by standardization and demand for efficient
processing tools (Mureddu et al., 2025), with recent
initiatives focusing on integrating advanced technolo-
gies to improve data accessibility and utility (Siciliani
et al., 2024).
2.3 LLMs in Public Administration
LLM application in governmental contexts has ex-
panded rapidly, covering public policy analysis, citizen
services, and document processing (Androutsopoulou
et al., 2024), demonstrating transformative poten-
tial in modernizing public administration (Sandoval-
Almazan et al., 2024). Practical implementations en-
compass automated document classification systems
(Kliimask and Nikiforova, 2024), conversational inter-
faces for public services (Cort
´
es-Cediel et al., 2023),
and analysis tools for government reports (Pesqueira
et al., 2024), though ethical and legal considerations
remain central to adoption debates (Dua et al., 2025).
Integration with government data shows particular po-
tential in public health trend analysis (Tornimbene
et al., 2025), regulatory document processing (Rizun
et al., 2025), and sustainable development goals moni-
toring (Benjira et al., 2025).
3 RESEARCH METHOD
This study adopts the Systematic Mapping Study
(SMS) approach (Petersen et al., 2008) to organize
and analyze scientific production about LLM applica-
tions in government open data, allowing identification
of trends, gaps, and categorization of contributions.
The methodological structure follows the GQM
(Goal-Question-Metric) model with the objective:
Analyze the adoption of LLMs to characterize their
application from researchers’ perspectives in the con-
text of government open data analysis.
The mapping process followed five main steps (Pe-
tersen et al., 2008): (1) research questions definition,
(2) search conduction, (3) screening and selection, (4)
classification scheme construction, and (5) data extrac-
tion and mapping, as illustrated in Figure 1.
3.1 Research Questions
Seven exploratory research questions were formulated
(Petersen et al., 2008):
•
RQ1 - What types of research contributions
were produced? This question investigates the
nature of contributions according to established
taxonomies (Shaw, 2003), examining whether stud-
ies focused on theoretical frameworks, empirical
models, practical solutions, or procedural method-
ologies.
•
RQ2 - What validation approaches were em-
ployed in the articles? This question analyzes the
methodological strategies used to validate research
findings, including evaluation-based assessments,
example-driven demonstrations, experiential evi-
dence, persuasive arguments, and analytical frame-
works.
Large Language Models in Open Government Data Analysis: A Systematic Mapping Study
405
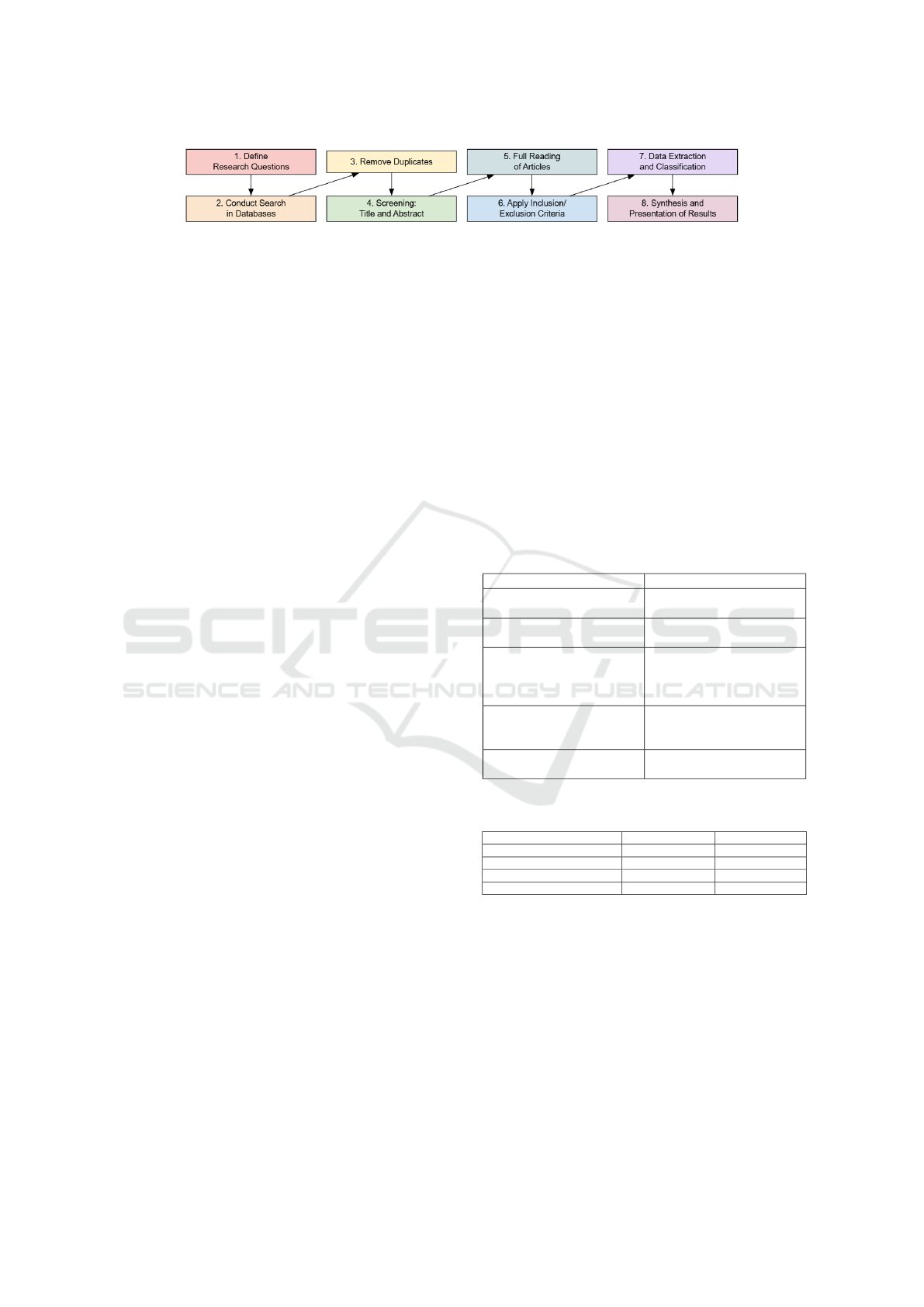
Figure 1: Mapping process, adapted from (Petersen et al., 2008).
•
RQ3 - Which governmental domains were inves-
tigated in the research? This question examines
the specific public sector areas and governmental
functions where Large Language Model applica-
tions were studied, identifying the scope and focus
of implementation contexts.
•
RQ4 - Which Large Language Model architec-
tures were utilized? This question identifies the
specific LLM technologies, frameworks, and ar-
chitectural approaches employed in the studies,
examining both proprietary and open-source solu-
tions.
•
RQ5 - What functional roles did LLMs serve
in the research? This question investigates the
primary purposes and applications of LLMs within
governmental contexts, examining their roles in
data processing, analysis, generation, and decision
support systems.
•
RQ6 - Which technical tools and methodologies
were employed? This question analyzes the com-
plementary technologies, platforms, and method-
ological frameworks used alongside LLMs to im-
plement solutions in open government data con-
texts.
•
RQ7 - What types of public datasets were uti-
lized? This question examines the characteristics,
formats, and domains of governmental open data
employed in the studies, investigating data sources
and their structural properties.
3.2 Search Strategy
The search strategy used the PIC model (Kitchenham
et al., 2007): P (Population): Public Data; I (Interven-
tion): LLMs; C (Context): Government. The search
string was:
("Public Data" OR "Open data" OR
"Open information" OR "Transparent
data" OR "Transparent information")
AND ("LLM" OR "Generative AI") AND
("Government" OR "Administration"
OR "Governance" OR "Public
Administration" OR "Public sector"
OR "State")
Searches were conducted in six databases: ACM
Digital Library (559), IEEE Xplore (8), Web of
Science (8), ScienceDirect (317), Scopus (17), and
Springer Link (459). After removing duplicates
(n=34), 1,334 unique articles were screened.
The search of the databases occurred between
March and April 2025.
3.3 Selection Process
Three sequential screening stages were conducted:
1st Reading (title, abstract, keywords) resulted in
86 studies; 2nd Reading (introduction, objectives,
results, conclusions) yielded 43 articles; 3rd Read-
ing (complete analysis) included 24 final studies. Ta-
ble 1 presents inclusion/exclusion criteria, and Table 2
shows selection evolution.
Table 1: Inclusion and Exclusion Criteria.
Inclusion Criteria Exclusion Criteria
Articles published between
2017 and 2025.
Duplicate articles identified
across databases.
Peer-reviewed studies with
full text available.
Works not written in En-
glish.
Studies addressing the appli-
cation of LLMs to open gov-
ernment data.
Partial publications such as
extended abstracts, posters,
or abstracts without com-
plete articles.
Studies that answer, even
partially, one of the defined
research questions.
Studies dealing exclusively
with private data or non-
governmental use of LLMs.
Secondary and tertiary stud-
ies (literature reviews).
Table 2: Evolution of Study Selection.
Stage Excluded Articles Retained Articles
1st Reading (exploratory) 1,282 86
2nd Reading (cross-sectional) 43 43
3rd Reading (analytical) 19 24
Initial Total 1,344 24 final articles
Cross-validation between researchers was applied
with complete traceability via Parsifal tool, ensuring
reliability and replicability.
3.4 Data Extraction and Mapping
Categorization used keywording technique (Petersen
et al., 2008) with three facets: Type of Contribution
(Shaw, 2003) (Table 3), Type of Validation (Table 4),
and Application Domain (Table 5). Frequency analysis
generated visualizations of contribution types, tempo-
ral distribution, technologies, and government areas.
WEBIST 2025 - 21st International Conference on Web Information Systems and Technologies
406
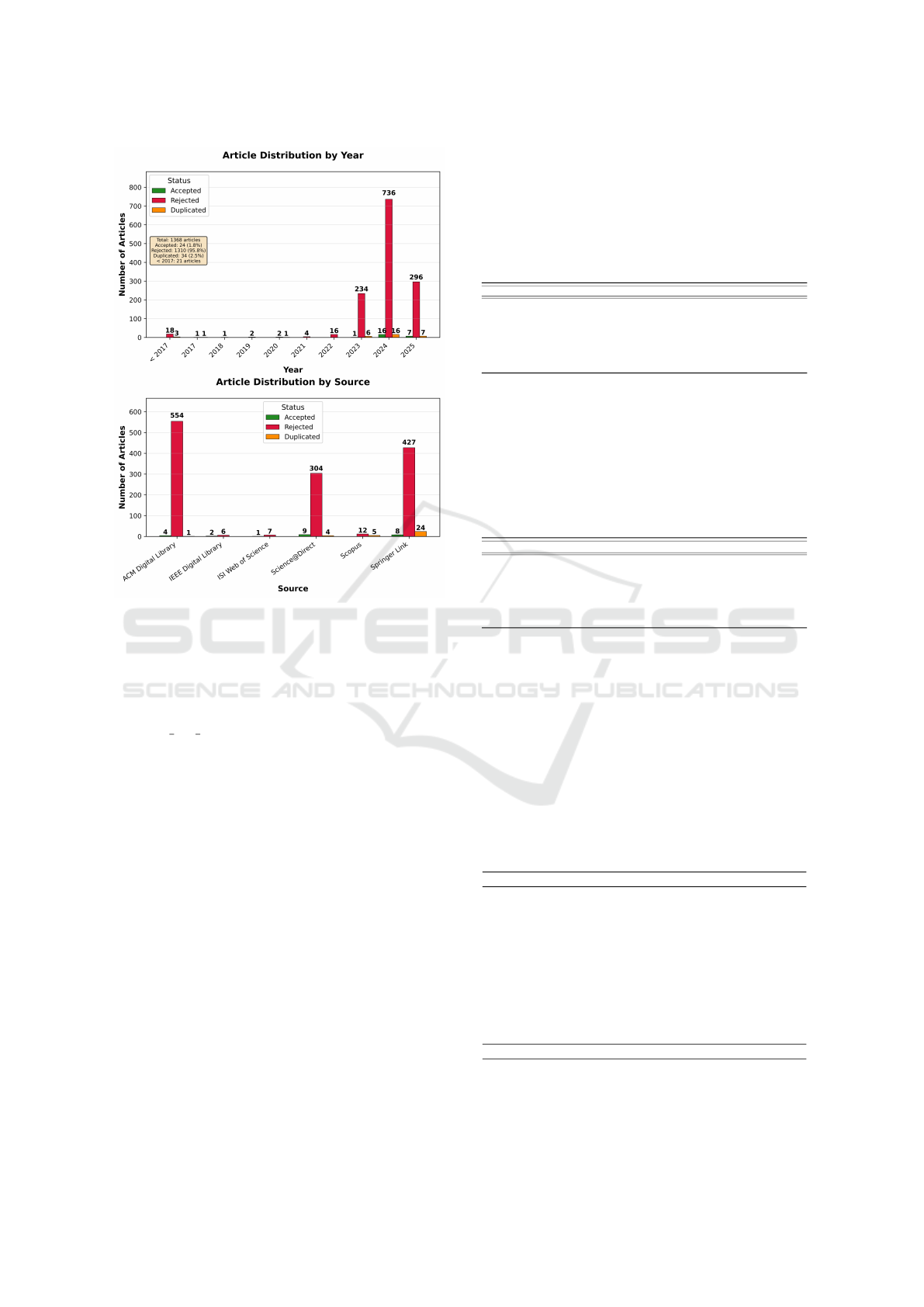
Figure 2: Article Distribution by Year, Source and Status.
This study followed validity recommendations (Pe-
tersen et al., 2008) through cross-validation, explicit
criteria, complete traceability via Parsifal, ensuring
transparency and replicability. Data and protocols
are available at: https://github.com/AlbertoBastosMe/
mapping llm ogd.
4 RESULTS
This section presents systematic mapping results
across five dimensions: study characteristics, method-
ological approaches, application domains, LLM mod-
els, and technological ecosystem.
4.1 Study Selection and Characteristics
The systematic mapping identified 24 primary studies
meeting the inclusion criteria. Temporal distribution
shows increasing research interest (Figure 2), with
significant growth from 2023 onwards, coinciding with
ChatGPT’s widespread adoption.
4.2 Methodological Approaches
Shaw’s taxonomy (Shaw, 2003) reveals qualitative/de-
scriptive models predominance (50.00%, n=12), as
shown in Table 3. Empirical models and proce-
dures/techniques present equivalent representation
(16.67% each, n=4). Specific solutions constitute
8.33% (n=2), while tools/notations and reports show
the lowest representation (4.17% each, n=1).
Table 3: Distribution of Research Result Types (RQ1).
Result Type Freq. % Articles
Qualitative or descriptive model 12 50.00%
P4; P5; P8; P9; P10; P15; P18; P19;
P20; P22; P23; P24
Empirical model 4 16.67% P2; P3; P6; P12
Procedure or technique 4 16.67% P14; P16; P17; P21
Specific solution/prototype 2 8.33% P7; P11
Tool or notation 1 4.17% P1
Report 1 4.17% P13
Validation approaches (Table 4) show evaluation as
most prevalent (45.8%, n=11), followed by example-
based validation (25.0%, n=6). Experience and per-
suasion present equivalent representation (12.5% each,
n=3), while analysis represents the least frequent type
(4.2%, n=1).
Table 4: Validation Types by Article (RQ2).
Response Type Freq. % Articles
Evaluation 11 45.8%
P6; P16; P14; P15; P1; P12; P17; P11; P2;
P7; P20
Example 6 25.0% P5; P21; P18; P24; P8; P22
Experience 3 12.5% P10; P3; P13
Persuasion 3 12.5% P19; P4; P9
Analysis 1 4.2% P23
4.3 Application Domains
Analysis reveals concentrated adoption across key gov-
ernmental domains (Table 5). Open data management
dominates (n=5), followed by Health (n=4), and Secu-
rity, Justice, e-Government (n=3 each). This distribu-
tion reflects growing maturity in transparency initia-
tives and diversification across critical public adminis-
tration sectors.
Table 5: Distribution of primary studies by government do-
main (RQ3).
Government Domain Frequency Studies
Health 4 P3, P4, P13, P20
Security 3 P18, P19, P21
Justice 3 P9, P17, P22
Budget 2 P5, P14
Procurement 1 P7
Open data management 5
P6, P11, P16, P23,
P24
e-Government 3 P2, P10, P15
AI public policies 1 P12
Citizen participation 1 P8
Disinformation 1 P1
Total 24
Data types analysis (Table 6) shows Statistical Data
and Metrics, and Transparency and Accountability
Large Language Models in Open Government Data Analysis: A Systematic Mapping Study
407

Data as most prevalent (n=11 each), evidencing ori-
entation toward government transparency. High fre-
quency of Norms and Legislation (n=10) indicates an
important trend in regulatory text processing.
Table 6: Types of Data Used in Studies (RQ7).
Data Types Frequency Articles
Statistical Data and Metrics 11
P1; P2; P5; P6; P13; P14; P16; P19; P22;
P23; P24
Transparency and Accountability Data 11
P5; P6; P7; P8; P9; P10; P11; P14; P15;
P16; P24
Norms and Legislation 10
P3; P4; P9; P14; P17; P18; P19; P21; P22;
P24
Textual Data and Documents 4 P1; P12; P8; P15
AI and Machine Learning Data 5 P1; P4; P17; P18; P22
Research and Methodology Data 2 P3; P20
Health and Surveillance Data 3 P5; P13; P21
Social Media and Participation Data 3 P8; P15; P13
Metadata and Knowledge Graphs 4 P6; P11; P14; P17
Structured and Semantic Data 3 P7; P12; P16
Geospatial and IoT Data 2 P10; P23
Personal Data and Privacy 3 P9; P13; P21
Multimodal and Emerging Data 3 P18; P10; P13
4.4 LLM Models and Technological
Ecosystem
Clear GPT family predominance emerges (Table 7),
establishing it as the primary governmental choice.
Alternative models like Claude, Llama, and Gemini
appear concentrated in comparative studies (Hannah
et al., 2025).
Table 7: Large Language Models identified in studies (RQ4).
LLM Frequency Studies
ChatGPT 8
P2; P8; P12; P1; P24; P19;
P4; P13
BERT 6 P1; P16; P14
GPT-4 4 P19; P11; P4; P14
GPT-3.5 2 P19; P11
Gpt 2 P16; P14
GPT-3 1 P4
Ibm Watson Health 1 P5
Rebel 1 P7
Large Language Models 1 P10
Text-Davinci-003 1 P11
Claude 1 P11
T5 1 P11
PaLM 1 P11
Wizardlm 1 P14
Ada 1 P16
Gpt4 Vision 1 P18
Gemini 1 P18
Phi3 1 P18
Sora 1 P19
Bard 1 P24
Functional analysis (Table 8) reveals diverse appli-
cations with information extraction and conversational
interfaces predominating (9 studies each), indicating a
focus on data accessibility and citizen interaction.
Technological ecosystem analysis (Table 9) shows
ChatGPT predominance (3 occurrences), followed by
Hugging Face, BERT, and GPT-4. Five custom tools
were identified, including TAGIFY (Kliimask and
Nikiforova, 2024), OIE4PA (Siciliani et al., 2024), and
SATIKAS (Sandoval-Almazan et al., 2024), demon-
Table 8: Large Language Model Functions (RQ5).
LLM Function Frequency Studies
Information extraction 9
P5; P11; P1; P14;
P19; P7; P13; P3;
P16
Conversational interface 9
P5; P1; P12; P17; P2;
P18; P24; P8; P20
Content generation 7
P22; P19; P21; P17;
P2; P18; P4
Classification 5 P11; P1; P19; P7; P8
Data analysis 4 P5; P3; P17; P6
Summarization 3 P12; P8; P13
NLP 3 P22; P10; P15
Fact-Checking 1 P4
Sentiment analysis 1 P8
NLP in medical records 1 P13
Semantic understanding 1 P14
Structured knowledge generation 1 P14
Information search and retrieval 1 P15
Schema Mapping 1 P16
Multimodal processing 1 P18
Automatic text analysis 1 P20
Analysis support 1 P24
Community facilitator 1 P24
Table 9: Tools and frameworks used in studies with LLMs
(RQ6).
Tool/Framework Frequency Studies
ChatGPT 3 P4; P19; P8
Hugging Face 3 P18; P1; P14
BERT 3 P16; P1; P14
GPT-4 3 P19; P4; P11
Gemini 2 P17; P18
RoBERTa 1 P1
DistilBERT 1 P1
TrustServista API 1 P1
SATIKAS 1 P2
GPT-3 1 P4
IBM Watson Health 1 P5
Python 1 P6
math 1 P6
Pandas 1 P6
regular expressions 1 P6
strating emerging specialization for governmental de-
mands.
5 DISCUSSION
This systematic mapping study provides a compre-
hensive analysis of Large Language Models applica-
tions in open government data contexts, revealing both
significant opportunities and critical challenges that
define the current state of this emerging field. The
investigation demonstrates that while LLMs possess
considerable potential for transforming government
data analysis and citizen services, their effective imple-
mentation requires careful consideration of technical,
ethical, and governance factors that span multiple in-
terconnected dimensions of public administration.
WEBIST 2025 - 21st International Conference on Web Information Systems and Technologies
408

5.1
Technological Landscape and Model
Adoption Patterns
The analysis reveals a clear predominance of propri-
etary models in governmental applications, with GPT
family models dominating the landscape (ChatGPT
appearing in 8 studies, GPT-4 in 4 studies, as shown
in Table 7). This concentration reflects both acces-
sibility considerations and proven capabilities, but
raises important concerns for public sector implemen-
tations. The reliance on proprietary models creates
potential risks regarding data privacy, vendor lock-
in, and long-term sustainability of governmental AI
initiatives. There exists a significant opportunity for
research exploring open-source alternatives such as
Llama, which appeared only in comparative studies
by (Hannah et al., 2025), despite potential advantages
for government use, including enhanced data control,
reduced costs, and greater transparency.
The temporal distribution evidences that research
activity intensified markedly from 2023 onwards, coin-
ciding with the public release and widespread adoption
of ChatGPT, as shown in Figure 2. This pattern sug-
gests that the field’s development has been largely
reactive to commercial technology availability rather
than proactive in addressing specific governmental re-
quirements.
5.2 Application Domains and Research
Gaps
The domain analysis reveals significant imbalances in
research focus that highlight both established strengths
and critical gaps. Health applications represent the
most mature area (4 studies), followed by security
and justice domains (3 studies each), as detailed in
Table 5. However, fundamental governmental areas
remain severely underexplored, particularly education,
which is essential for public service delivery but re-
ceived minimal attention in the analyzed corpus.
The concentration in open data management (5
studies) demonstrates growing recognition of LLMs’
potential for enhancing government transparency ini-
tiatives. Yet, the limited exploration of geospatial data
applications represents a substantial missed opportu-
nity, given the importance of location-based services
and spatial analysis in urban planning, emergency re-
sponse, and infrastructure management.
Furthermore, the geographic and linguistic limita-
tions of current research constrain its global applica-
bility. The predominance of English-language studies
and Western legal frameworks limits the generaliz-
ability of findings to diverse governmental contexts,
particularly those operating in different languages or
legal traditions. This represents a critical gap, as lin-
guistic and cultural particularities significantly impact
LLM performance in governmental applications.
5.3 Methodological Maturity and
Validation Approaches
The distribution of research types according to Shaw’s
taxonomy reveals that 50% of studies employ qualita-
tive or descriptive models (Table 3), indicating the field
remains in a theoretical consolidation phase rather than
operational maturity. The limited presence of empiri-
cal models (16.67%) and experimental approaches sug-
gests a critical need for rigorous validation methodolo-
gies that can establish definitive performance bench-
marks for governmental applications.
The predominance of evaluation-based validation
(45.8% of studies, Table 4) demonstrates methodolog-
ical awareness, yet the scarcity of longitudinal stud-
ies limits understanding of long-term impacts on gov-
ernment efficiency and citizen satisfaction. This gap
becomes particularly problematic when considering
the substantial investments required for governmental
AI implementations and the need for evidence-based
decision-making in public sector technology adoption.
5.4 Data Types and Processing
Challenges
The analysis of utilized data types (Table 6) reveals that
Statistical Data and Metrics, along with Transparency
and Accountability Data, dominate applications (11
studies each). While this focus aligns with core govern-
mental transparency objectives, it also highlights the
underutilization of LLMs for processing more com-
plex data types such as multimedia content, citizen
feedback, and real-time sensor data that could enhance
smart city initiatives.
The significant representation of Norms and Leg-
islation (10 studies) underscores both the promise
and complexity of applying LLMs to regulatory texts.
However, the concentration on English-language legal
frameworks limits practical applicability to diverse le-
gal systems, particularly those operating under civil
law traditions or incorporating customary legal prac-
tices.
5.5 Research Agenda and Future
Directions
The identified gaps collectively point toward several
critical research priorities that could advance the field
toward operational maturity. First, there is an urgent
Large Language Models in Open Government Data Analysis: A Systematic Mapping Study
409

need for comprehensive comparative studies exam-
ining open-source versus proprietary model perfor-
mance in governmental contexts, particularly address-
ing privacy, security, and cost considerations that are
paramount for public sector implementations.
Second, the development of domain-specific eval-
uation frameworks for governmental AI applications
represents a fundamental requirement. Unlike general-
purpose AI applications, governmental implementa-
tions must address unique requirements, including
transparency, accountability, fairness, and legal com-
pliance that are not adequately captured by existing
benchmarks.
Third, the expansion of research to underexplored
domains such as education, environmental monitoring,
and citizen engagement platforms could significantly
broaden the impact of LLM applications in public ad-
ministration. These areas present substantial opportu-
nities for enhancing service delivery while addressing
critical societal challenges.
Fourth, multilingual and cross-cultural studies are
essential for developing globally applicable govern-
mental AI solutions. Research examining LLM per-
formance across different languages, legal systems,
and cultural contexts would provide crucial insights
for international cooperation and technology transfer
initiatives.
Finally, longitudinal studies examining the sus-
tained impact of LLM implementations on governmen-
tal efficiency, citizen satisfaction, and democratic par-
ticipation represent critical knowledge gaps that must
be addressed to inform strategic technology adoption
decisions in the public sector.
The research landscape demonstrates that while
significant progress has been made in exploring LLM
applications for open government data, achieving tech-
nical maturity comparable to established software en-
gineering fields requires coordinated efforts to address
methodological limitations, develop empirical valida-
tion frameworks, and establish ethical governance stan-
dards that can guide responsible innovation in public
sector AI implementations.
6 CONCLUSIONS
This systematic mapping study analyzed LLM adop-
tion patterns in open government data analysis through
a comprehensive examination of 24 primary studies,
providing a consolidated overview of current appli-
cations in governmental contexts and characterizing
researchers’ perceptions about benefits, limitations,
and methodological implications.
Key findings reveal proprietary model predomi-
nance, particularly GPT family, indicating commercial
solution accessibility while highlighting underexplo-
ration of open-source alternatives better serving gov-
ernmental transparency and data sovereignty require-
ments. Research concentration in health, security, and
open data management demonstrates established ap-
plications, yet significant gaps remain in fundamental
services like education and geospatial data processing.
Methodologically, the field exhibits theoretical con-
solidation characteristics rather than operational ma-
turity, with 50% employing qualitative/descriptive ap-
proaches, suggesting substantial opportunities for ad-
vancing toward empirical validation and experimen-
tal methodologies establishing definitive performance
benchmarks.
Despite contributions, several limitations constrain
generalizability. Temporal coverage (2023-2025), 2,
reflects the nascent stage but limits the longitudinal per-
spective on technological evolution. English-language
study predominance and Western legal framework fo-
cus constrains applicability to diverse governmental
contexts.
Future research directions emerge from identified
gaps. Developing standardized evaluation metrics for
LLM performance in government applications repre-
sents a fundamental requirement for evidence-based
practices. Longitudinal studies examining long-term
impacts on transparency, efficiency, and citizen engage-
ment constitute critical priorities, while comparative
analyses of open-source versus proprietary models
offer substantial opportunities for advancing public
sector AI governance.
Expanding research to underexplored domains
such as education, environmental monitoring, and mul-
tilingual applications could significantly broaden the
transformative potential. Developing domain-specific
solutions addressing unique governmental require-
ments, including transparency, accountability, and le-
gal compliance, represents an essential pathway to-
ward technical maturity.
While LLM application in open government data
analysis represents a rapidly evolving field with trans-
formative potential, achieving operational maturity
requires coordinated efforts addressing methodologi-
cal limitations, developing empirical validation frame-
works, and establishing ethical governance standards.
The comprehensive framework established serves as a
valuable reference for researchers, practitioners, and
policymakers seeking to understand and contribute to
this emerging interdisciplinary domain at the intersec-
tion of artificial intelligence and digital government.
WEBIST 2025 - 21st International Conference on Web Information Systems and Technologies
410

REFERENCES
Alexopoulos, C., Ali, M., Maratsi, M. I., Rizun, N., Charal-
abidis, Y., Loukis, E., and Saxena, S. (2024). Assessing
the availability and interoperability of open govern-
ment data (ogd) supporting sustainable development
goals (sdgs) and value creation in the gulf cooperation
council (gcc). Quality & Quantity.
Androutsopoulou, M., Askounis, D., Carayannis, E. G., and
Zotas, N. (2024). Leveraging ai for enhanced egovern-
ment: Optimizing the use of open governmental data.
Journal of the Knowledge Economy.
Benjira, W., Atigui, F., Bucher, B., Grim-Yefsah, M., and
Travers, N. (2025). Automated mapping between sdg
indicators and open data: An llm-augmented knowl-
edge graph approach. Data & Knowledge Engineering,
156:102405.
Bronzini, M., Nicolini, C., Lepri, B., Passerini, A., and
Staiano, J. (2024). Glitter or gold? deriving structured
insights from sustainability reports via large language
models. EPJ Data Science, 13:41.
Cabral, B., Souza, M., and Claro, D. B. (2024). Open infor-
mation extraction with llm for the portuguese language.
LINGUAMATICA, 16:167–182.
Cort
´
es-Cediel, M. E., Segura-Tinoco, A., Cantador, I., and
Rodr
´
ıguez Bol
´
ıvar, M. P. (2023). Trends and chal-
lenges of e-government chatbots: Advances in explor-
ing open government data and citizen participation con-
tent. Government Information Quarterly, 40:101877.
Donner, C., Danala, G., Jentner, W., and Ebert, D. (2024).
Truext: Trustworthiness regressor unified explainable
tool. pages 5325–5334.
Dua, M., Singh, J. P., and Shehu, A. (2025). The ethics of
national artificial intelligence plans: an empirical lens.
AI and Ethics.
Germani, F., Spitale, G., and Biller-Andorno, N. (2024). The
dual nature of ai in information dissemination: Ethical
considerations. JMIR AI, 3.
Hannah, G., Sousa, R. T., Dasoulas, I., and d’Amato, C.
(2025). On the legal implications of large language
model answers: A prompt engineering approach and a
view beyond by exploiting knowledge graphs. Journal
of Web Semantics, 84:100843.
Kitchenham, B., Budgen, D., and Brereton, P. (2007). Guide-
lines for performing systematic literature reviews in
software engineering. Information and Software Tech-
nology, 49(5–6):481–495.
Kliimask, K. and Nikiforova, A. (2024). Tagify: Llm-
powered tagging interface for improved data findability
on ogd portals. page 18 – 27. Institute of Electrical and
Electronics Engineers Inc.
Mureddu, F., Paciaroni, A., Pavelka, T., Pemberton, A., and
Remotti, L. A. (2025). Rights and responsibilities: Le-
gal and ethical considerations in adopting local digital
twin technology. pages 291–317.
Nikiforova, A., Lnenicka, M., Mili
´
c, P., Luterek, M., and
Rodr
´
ıguez Bol
´
ıvar, M. P. (2024). From the evolution
of public data ecosystems to the evolving horizons of
the forward-looking intelligent public data ecosystem
empowered by emerging technologies. volume 14841
LNCS, page 402 – 418. Springer Science and Business
Media Deutschland GmbH.
Pesqueira, A., de Bem Machado, A., Bolog, S., Pereira,
R., and Sousa, M. J. (2024). Exploring the impact of
eu tendering operations on future ai governance and
standards in pharmaceuticals. Computers & Industrial
Engineering, 198:110655.
Petersen, K., Feldt, R., Mujtaba, S., and Mattsson, M. (2008).
Systematic mapping studies in software engineering.
International Conference on Evaluation and Assess-
ment in Software Engineering. Available via Research-
Gate.
Rizun, N., Revina, A., and Edelmann, N. (2025). Text
analytics for co-creation in public sector organizations:
a literature review-based research framework. Artificial
Intelligence Review, 58:125.
Sandoval-Almazan, R., Millan-Vargas, A. O., and Garcia-
Contreras, R. (2024). Examining public managers’
competencies of artificial intelligence implementation
in local government: A quantitative study. Government
Information Quarterly, 41:101986.
Shaw, M. (2003). Writing good software engineering re-
search papers. In Proceedings of the 25th International
Conference on Software Engineering, ICSE ’03, pages
726–736, Washington, DC, USA. IEEE Computer So-
ciety. Minitutorial.
Siciliani, L., Ghizzota, E., Basile, P., and Lops, P. (2024).
Oie4pa: open information extraction for the public
administration. J. Intell. Inf. Syst., 62(1):273–294.
Tornimbene, B., Rioja, Z. B. L., Brownstein, J., Dunn, A.,
Faye, S., Kong, J., Malou, N., Nordon, C., Rader, B.,
and Morgan, O. (2025). Harnessing the power of ar-
tificial intelligence for disease-surveillance purposes.
BMC Proceedings, 19:7.
Wang, S., Sun, K., and Zhai, Y. (2024). Dye4ai: Assur-
ing data boundary on generative ai services. page
2281–2295.
Large Language Models in Open Government Data Analysis: A Systematic Mapping Study
411
