Continual Multi-Robot Learning from Black-Box Visual Place
Recognition Models
Kenta Tsukah ara, Kanji Tanak a, Daiki Iwata, Jonathan Tay Yu Liang and Wu hao Xie
University of Fukui, 3-9-1 Bunkyo, Fukui City, Fukui 910-0017, Japan
Keywords:
Visual Place Recognition, Continual Multi-Robot Learning, Black-Box Teachers.
Abstract:
In the context of visual place recognition (VPR), continual learning (CL) techniques offer significant potential
for avoiding catastrophic forgetting when learning new places. However, existing CL methods often focus
on knowledge transfer from a known model to a new one, overlooking the existence of unknown black-box
models. This study explores a novel multi-robot CL approach that enables knowledge transfer from black-box
VPR models (teachers), such as those of local robots encountered by traveler robots (students) in unknown
environments. Specifically, we introduce Membership Inference Attack (MIA), a privacy attack applicable to
black-box models, and leverage it to reconstruct pseudo training sets, which serve as the transferable knowl-
edge between robots. Furthermore, we address the low sampling efficiency of MIA by leveraging prior insights
from the literature on place class prediction distributions and unseen-class detection. Finally, we analyze both
the individual and combined effects of these techniques.
1 INTRODUCTION
Visual place recognition (VPR) ena bles autonomous
robots and self-driving vehicles to classify their place
from visual input (Weyand et al., 2016)(Morita et al.,
2005)(Seo et al., 2018). While co nventional VPR
systems rely on supervised learning from direct vi-
sual experiences, they face two fundamental limita-
tions: the high cost of collecting training data in
new environments and catastrophic forgetting when
learning new places. These challenges become par-
ticularly acute in long-term autonomous operations
where robots must continuously adapt to environmen -
tal changes. Recent advancements in co ntinual learn-
ing techniques (Lange et al., 2022)—such as regu-
larization methods, experience replay, and dynamic
network exp a nsion—have yielded promising results
in mitigating catastrophic forgetting and improving
continual adaptation performance (Gao et al., 2022;
V¨odisch et al., 2023; V¨odisch et al., 2022).
This study explores multi-robot Continual Learn-
ing (CL) for Visual Place Recognition (VPR), fram-
ing CL a s knowledge transfer from an old model to a
new one. We extend conventional knowledge tr ans-
fer between different mode ls of the same robot to
knowledge transfer between different models of dif-
ferent robots. This ap proach offers key advantages,
including scalability and fault toler ance. Specifically,
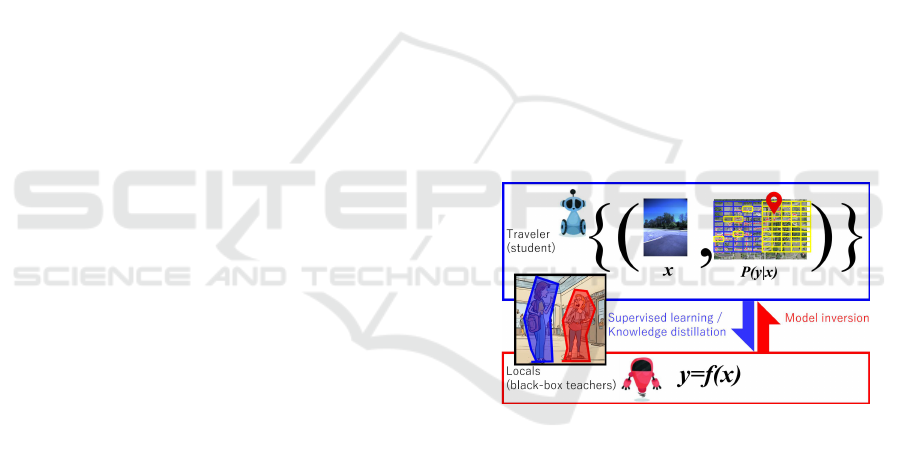
Figure 1: Illustration of human-inspired knowledge transfer
(KT) via local-to-traveler interaction, motivating robot-to-
robot KT using VPR models.
a traveling r obot can update its k nowledge by ac-
quiring information from loca l robots, avoiding the
cost and risk of collecting training data independently.
Additionally, sharing VPR knowledge ensures criti-
cal information is pre served even if some robots fail.
Despite these advantages, multi-robot CL intro duces
new challenges, such as variations in robot capabil-
ities, communication overhead, and concerns related
to privacy and security.
One of the key research challenges in m ulti-robot
systems is the question: ”Can a pseudo-training set
be reconstructed from a black-box teacher?” For ex-
ample, when a traveling robot explores an unfamiliar
city and encounters a local robot f or the first time,
it cannot access the internal parameters or tr aining
126
Tsukahara, K., Tanaka, K., Iwata, D., Liang, J. T. Y. and Xie, W.
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models.
DOI: 10.5220/0013771900003982
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 22nd International Conference on Informatics in Control, Automation and Robotics (ICINCO 2025) - Volume 1, pages 126-135
ISBN: 978-989-758-770-2; ISSN: 2184-2809
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

data of the local robot’s VPR model, which thus acts
as a black-box teacher. Gener a ting a pseudo-training
set from such a black box is essential for knowledge
transfer, yet remains a difficult and unresolved pro b-
lem. This scenario represents a typical case where
black-box teacher s naturally arise in mu lti-robot con-
tinual learning, and reconstructing pseudo-tr aining
sets is crucial for integrating new data and retraining
models.
Many existing approaches rely on the assump-
tion that the existing model is a white b ox, allow-
ing access to its internal structure or training set. In-
deed, in single-robot systems, this assumption often
holds, as the existing model belongs to the robot it-
self. However, in multi-robot systems, especially in
open-world scenarios involving heterogeneous or un-
known robots, this assumption is overly optimistic.
In fact, reconstructing a training set from a b la c k-
box model re mains an ongoing challenge in machine
learning and is largely an open problem.
In this work, we address the key challenge of re-
constructing (pseu do) training sample s from black-
box teachers using membership inference attacks
(MIAs) (Hu et al., 2022) (Fig. 1). Unlike traditional
approa c hes that analyze the model to recon struct the
training data, MIA generates samples a nd predicts the
likelihood that they were part of the model’s training
data. It is the on ly major privacy attack method effec-
tive with black-box models. However, this flexibility
comes with a downside: low sampling efficiency, par-
ticularly when dealing with high -dimensional input
data, such as images used in VPR. The naive a pproach
of randomly generating training sample candidates is
highly inefficient. To overcome this limitation, we
propose improving the sampling efficiency of MIA by
leveraging prior knowledge from the VPR literature,
such as place class predictio n distributions, and un-
learned class detectio n techniques. We also evaluate
the effects of these methods both individually and in
combination.
Throu gh extensive experiments, we demonstrate
that the proposed approac h sign ifica ntly enhan c es
performance in continual learning u nder a challeng-
ing setup where all robots a re black boxes and per-
form poorly.
Our key contributions include:
1. We extend the continual learning (CL) framework
from a single-robot to a multi-robot paradigm,
enabling knowledge transfer between distinct
robots.
2. We introduce a method for recon structing pseudo-
training samples from a black-box teacher model
using membership inference attacks (MI A), tar-
geting the teacher-student VPR knowledge trans-
fer problem.
3. We empiric ally demonstrate that even in a
near-worst-case scenario involving only low-
performing black-box robots, collaborative learn-
ing can significantly boost VPR performance.
This work generalize s earlier studies on VPR,
continual learning, and knowledge tr ansfer into a
novel data-free setting applicable to black-box teach-
ers. This study significantly extends our late-breaking
paper in ( Tsukahara et al., 2024) and generalizes our
previous research on VPR, including continu al learn-
ing (Tanaka, 2015 ), knowledge transfer from teacher
to student (Takeda and Tanaka, 2021), an d knowledge
distillation ( H iroki and Tanaka, 2 019), into a novel
data-free variant applicable to black-box teachers. As
autonomous ro bots continue to prolife rate, universal
knowledge tra nsfer protoc ols and continual domain
adaptation will become incre asingly important. This
research lays the foundation for optimizing robot-to-
robot interactions in various VPR scenarios and aim s
to enhance robotic autonomy in open-world environ-
ments.
2 RELATED WORK
Visual Place Recognition (VPR). VPR is a special-
ized self-localization task that has garnered consider-
able research attention (Weyand et al., 2016; Morita
et al., 2005; Seo et al., 2018) . Compared to othe r self-
localization tasks, including image retrieval (Gar c ia -
Fidalgo and Ortiz, 2018), map matching (Sobreira
et al., 2019), sequ ence m atching (Milf ord and Wyeth,
2012), and multiple-hypothesis tracking (Rozsypalek
et al., 2023), VPR is particularly scalable. This scal-
ability is demonstrated through the development of
compact VPR mode ls for large-scale self-localization
at a planetar y scale (Weyand et al., 2016), tuning-fre e
VPR models for diverse weath e r and seasonal con-
ditions (Morita et al., 2005), and fine-grained mod-
els with combinatorial spatial partitionin g (Seo et al.,
2018).
Continual Learning (CL). Continual learning in
robotics addre sses the challenge of maintaining and
updating knowledge over time. Recent ad vances
span loop closure detection (Gao et al., 2022), visual
odometry (V¨odisch et al., 20 23), SLAM (V¨odisch
et al., 2022), and localization (Cabrera-Ponce et al.,
2023). However, m ost existing approaches foc us on
single-robot scenarios, with limited attention to multi-
robot knowledge transfer. For an overview of CL
taxonomies and techniques, see (Lange et al., 2022).
CL methods have been incr easingly applied in both
computer vision (Lomona co et al., 2022) a nd robotics
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
127

(Lesort et al., 2020). Benefits of CL in localiza-
tion include online adaptation (Wang et al., 2021)
and real-time learning (Cabrera-Ponce et al., 2023).
While some studies address CL in multi-age nt sys-
tems (Casado et al., 202 0), resear ch o n data-free
multi-robot CL remains sparse.
According to the CL taxonomy (La nge et al.,
2022), the scenario targeted in th is study spans
domain-incremental, class-incrementa l, and
vocabulary-incremental settings, wherein a robot
learns across seasonal domain s (e.g., inter-season),
accumulates new place classes, an d adapts to new
teacher models (e.g., vocabulary changes).
Privacy Attacks. In machine learning applications
such as medical image analysis, privacy concerns
about reconstructing training samples—e.g., portraits
or sensitive images—dur ing model transfer have le d
to a gr owing body of research on privacy attacks a nd
defenses ( Liu et al., 202 1). A mong these, m odel in-
version methods (Fredrikson et al., 20 15) are of par-
ticular relevance. These aim to reconstruct pseudo-
training samples (or “impressions”) from teacher
models, which the student mode l can then learn from.
For examp le , e arly zero-shot KT approaches mod-
eled the softmax sp ace with Dirichlet distributions
and reconstructed data from the teacher accordingly
(Nayak et al., 2019). Other works such as DAFL
(Chen et al., 2019) introduced regularization ba sed o n
assumed access to activations and outpu ts. While re-
cent studies have su cceeded in re constructing pseudo-
datasets (Buzaglo et al., 2023), they still assume ac-
cess to the internal architecture of teacher models.
In contrast, me mbership infer e nce attacks (MIAs) are
the only major method applicable to black-box teach-
ers.
The MIA method proposed in this study draws on
insights from unlearned place detection in VPR (Kim
et al. , 2019), and aligns with recent metr ic -based MIA
techniques (Ko et al., 2 023). However, most prior
MIA re search has focused on one-shot attacks, and
due to p oor sampling efficiency, dataset reconstruc-
tion for VPR knowledge transfer remains an open
challenge in black-box settings.
3 FORMULATION OF
MULTI-ROBOT CONTINUAL
LEARNING
This section first reviews the conventional tasks, in-
cluding visual place recognition (VPR), supervised
learning, and single-robot continual learning (CL).
Building on this, we formulate the multi-robot CL
problem and describe membership inference attacks
(MIAs), which are central to our approac h. Further-
more, as preparation for evaluation, we in troduce a
metric for assessing knowledge transfer cost.
A VPR model is defined as a function M that takes
an input image x and o utputs a probability distribution
over place classes C:
M : x → P(y | x), y ∈ C, (1)
where, C de notes a pred efined set of pla c e classes,
each corresponding to a real-world spatial region.
For example, in the NCLT public dataset (Carlevaris-
Bianco et al., 2016) used in our experiments, grid-
based partitioning (Kim et al., 2019) is applied, divid-
ing the workspace into 10 × 10 grid cells in a bird’s-
eye coordinate sy stem, each cell representing a dis-
tinct place class (Fig. 1). This approach provides
a standardized place definition; however, it increases
intra-class variation, thereby complicating classifica-
tion
1
(Fig. 2).
In a traditional supervised learnin g setting, a robot
experiences a set of place classes C
0
, converts these
experiences into a training set T
0
, and trains a mode l
M
0
via supervised learning L:
M
0
= L(T
0
),
where
T = {(x
i
,y
i
)}
N
i=1
.
In single-robot CL, when a new cla ss set C
+
0
is ob-
served with corresp onding training data T
+
0
, the goal
is to update the existing model M
0
to a new model
M
1
. This is typically don e by first reconstructing a
pseudo training set
¯
T
0
using a model inversion func-
tion I (e.g ., MIA):
¯
T
0
= I(M
0
),
where
¯
T = {(x
i
,P(y | x
i
))}
N
i=1
.
The reconstructed pseudo set is combined with the
new training da ta:
˜
T
+
0
=
¯
T
0
∪ T
+
0
,
and a distilled model M
1
is learned using distillation
¯
L (Hinton et al., 2015):
M
1
=
¯
L(
˜
T
+
0
).
The overall update process is summarized as
M
1
=
¯
L(I(M
0
) ∪ T
+
0
). (2)
1
Optimizing place definitions to reduce intra-class vari-
ation is a fundamental, ongoing challenge in the VPR com-
munity (Seo et al., 2018). This topic lies beyond t he scope
of the present work but is considered complementary.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
128

Figure 2: Sample input images from independent sessions. Each row corresponds to distinct place classes. Gr id partitioning
introduces intra-class variation, challenging the VPR task.
In multi-robot CL, instead of receiving new train-
ing data T
+
0
, a new black-box teacher model M
+
0
is
provided. In this scenario, a specialized inversion
function I
∗
(i.e., MIA) applicable to black-box mod-
els is employed to reconstruct the pseudo training set:
¯
T
+
0
= I
∗
(M
+
0
),
where, MIAs aim to approx imate the inaccessible
training data of a black-box teacher model via queries
and responses. The overall model update can be writ-
ten as:
M
1
=
¯
L(I(M
0
) ∪ I
∗
(M
+
0
)). (3)
Finally, we consider the knowledge transfer cost
in multi-robot CL. Interactions between the student
and black-box teacher occ ur via queries (from stu-
dent) and responses (from teacher). The queries
are automatically g enerated programmatic requests,
typically consisting of sh ort code snippets, incur-
ring negligible c ommunication overhead. Responses,
however, consist of pseudo training samples rep-
resented as high-dimen sional real-valued vectors or
tensors, imposing significant communication c ost
proportional to the numb e r of samples transferred.
Therefore, this study evaluates the knowledge transfer
cost primarily based on the number of pseudo samples
sent from the teacher to the student, assuming the cost
of queries is negligible.
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
129

4 DATASET RECONSTRUCTION
USING BLACK-BOX
MEMBERSHIP INFERENCE
ATTACKS (BB-MIA)
A critical challenge in applying Mem bership Infer-
ence Attacks (MIA) to black-box models (BB-MIA)
lies in the high dimensionality of the sample space.
Since the attacker (student) has no access to the
teacher mod el’s internal parameters or its training
data distribution, generating informative samples to
effectively probe the model’s decision boundaries is
highly non-trivial.
To address this, we approximate the teacher model
with a cascade pipeline comprising two modules: a
pre-train ed embedding module and a trainable MIA
module. The embedding module projects h igh-
dimensional input images into lower-dimensional em-
bedding vectors via a scene graph classifier, a method
validated for genera liza bility a nd effectiveness in var-
ious V PR tasks (Takeda and Tanaka, 2021). The
MIA modu le then employs multiple sampling strate-
gies within the embedding space to enable efficient
MIA sample generation. D e ta ils of each modu le fol-
low.
4.1 Generic Embedding Model
Figure 3 illustrates the approximated pipeline. It c on-
sists of three key stages:
1. Semantic Segmentation: Input images are seg-
mented into regions by D eepLab v3+ (Chen et al.,
2018).
2. Scene Graph Generation: Segmented regions
form n odes in a scene graph. Each node is rep-
resented by a 189-dimension a l one-hot vector en-
coding semantic labels, orientatio n, a nd range
(Lowry et al., 2016). Edges connect spatially ad-
jacent no des, capturing multim odal features in-
cluding a ppearance, semantics, and spatial rela-
tions (Yoshida et al., 2024).
3. Graph Neural Network: Th e scene graph is fed
into a pre-trained graph convolutional network
(GCN) classifier, producing a class-specific prob-
ability map (CPM) of dimension |C| (Ohta et al.,
2023). This CPM serves as the final embedding
vector.
4.2 Black-Box Membership Inference
Attacks
The pr oblem is to reconstruct a pseudo-sample set
{(x,P(y|x))} approximating the training data of a
black-box tea cher mod e l, which takes embedding
vectors as input a nd outputs CPMs. This is an inverse
supervised learning problem.
Uniform Sampling (US) Strategy The simplest
approa c h samples vectors x ∈ R
|C|
from a uniform
distribution, normalizes them with the L1 norm, and
queries the teacher to obtain P(y|x):
x
i
=
u
i
ku
i
k
1
, u
i
∼ U, i = 1,. .., N. (4)
Reciprocal Rank (RR) Strategy. Th e Uniform
Sampling (US) strategy generates samples ran domly
and does not take into account the teacher model’s
output distribution. The RR strategy improves on this
by c onverting uniform samples into reciprocal rank
features (RRF), which reflect the relative strength of
each class in the mo del’s predictions (Takeda and
Tan aka, 2021):
x
i
= f
RR
u
i
ku
i
k
1
, u
i
∼ U, i = 1, .. .,N, (5)
where
f
RR
(x) =
1
rank
1
,
1
rank
2
,. ..,
1
rank
|C|
, (6)
and ran k
j
is the position of the j-th element in de-
scending order. In simple terms, the largest value gets
1/1 = 1, the second largest 1/2 = 0.5, the third largest
1/3 ≃ 0.33, and so on. This transforms random values
into features that encode the relative order of classes,
making the sam ples more informative for probing the
teacher model.
Entropy Strategy. While the RR strategy approxi-
mates general predictive distributions, it may not fit
the target teacher model’s specifics. The Entropy
strategy selects samples with low predictive entropy,
hypothesizing these correspond to training data mem-
bers (Kim et al., 2019). From many RR-generated
samples, the N with the lowest entropy
H(x) = −
|C|
∑
i=1
P(y
i
|x)logP(y
i
|x) (7)
are chosen.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
130

Figure 3: Overview of our VPR pipeline. The architecture includes a generic embedding module to reduce dimensionality and
multiple sampling switches for model inversion analysis (MIA). Switch states shown correspond to the proposed ”Entropy”
method.
Replay/Prior Strategies. Beyond BB-MIA,
replay-based sampling assumes partial access to
the teacher’s training samples (Isele and Cosgun,
2018), contradicting the black-box assumption . Such
settings are plausible with hig h communication and
memory capacity in mu lti- robot systems. The Prior
strategy assumes the student has acce ss to its own
training samp les for quer ying the teacher, applicable
when only the student cooperates.
Mixup Strategy. A hybrid approach co mbines a
small subset R o f retained training samples with N −R
samples from RR or Entropy strategies:
x
i
∼
(
T
Replay
, i = 1, .. .,R
T
RR/Entropy
, i = R + 1,.. .,N
, (8)
where T
Replay
is the teacher outputs for replayed
(retained) training samples, and T
RR/Entropy
is the
teacher outputs for samples gener ated by Recipr ocal
Rank or Entropy strategies. This strategy serves a s an
oracle baseline, not applicable to black-box teachers.
5 EXPERIMENTAL EVALUATION
This section evaluates the performance of the pro-
posed method in a typical multi-robot c ontinual learn-
ing (CL) scenario, where a traveling robot (student)
sequentially interacts with three teacher r obots via
wireless communication. A key focus is the trade-
off betwee n acquiring new knowledge and avoiding
forgetting previously learned place classes.
5.1 Experimental Setup
Experiments utilized the NCLT dataset (Carlevaris-
Bianco et al., 201 6), which contains sensor data from
a Segway robot navigating multiple sessions across
different seasons on the University of Michigan North
Campus. Visual Place Recognition (VPR) tasks em-
ploy onboard camera images with ground-tr uth view-
point GPS annotations. The dataset, originally col-
lected by a single robot, is adapted to multi-rob ot
scenarios by pairing distinct sessions with different
robots (Mangelson et al., 2018) .
The evaluation protocol comprises:
1. Sequential interactions with up to three teachers.
2. Utilization of 27 NCLT sessions:
• One test session: “2012/08 /04”
• One session for embedding model training:
“2012 /04/29”
• Twenty-five sessions for stude nt/teacher VPR
model training
3. Teacher and student VPR mod els implemented
as multi-layer per c eptrons ( MLPs) with a 4,096-
dimensional hidden layer.
4. Evaluation of six distinct knowledge transfer sce-
narios.
5. Perform ance metrics including:
• Top-1 VPR accuracy measured a fter:
– Student’s supervised learning
– Knowledge transfer from each teacher se-
quentially
• Knowledge transfer (K T) cost quantified by the
number of samples N used.
• Knowledge retention, assessing avoidance of
catastrophic forgetting.
• Computational efficiency.
Additional details include:
1. Each student and teacher ro bot is trained on K
place classes from its assigned session, using fully
supervised learning with the corresponding train-
ing data. Following standard continual learning
protocols, training sets are discarde d afte r train-
ing, except for Replay, Prior, an d Mixup strategies
where some samples are retained.
2. Sessions are indexed from 0 to 24 chronologically
accordin g to navigation dates.
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
131

Figure 4: Experiment design overview. At stage i = 0, VPR
model is trained on the student’s prior experience. At subse-
quent stages i = 1,2,3, it is updated via knowledge transfer
from distinct teachers.
3. Six scenarios ( j = 0,.. ., 5) evaluate different
student-teacher combinations. For the j-th sce-
nario, models with ID i ∈ {0,1,2, 3} correspond to
the student (i = 0) and teachers (i = 1, 2,3), each
trained on K = 10 random place classes from ses-
sion ((6i + j) mod 25).
4. Sample coun ts are rep orted per place class for
simplicity.
5. When encountering a teacher, pseudo-training
samples for classes known to the teacher are re-
constructed from the teacher model, while sam-
ples for classes exclusive to th e student are recon-
structed from the student model.
6. For Replay, Prior, and Mixup strategies, the num-
ber of replay samples per class R is set to 1 by
default.
7. Reciprocal Rank Fea ture (RRF) vectors are ap-
proxim ated using sparse k- hot RRF with k = 10
as in (Ohta et al. , 2023).
Computational costs were modest: MLP tr a ining
required tens of seconds, and query sample genera-
tion took ap proximately 25 millisecond s per sample.
Knowledge transfer cost f or a 100-dimensio nal k-hot
RRF sample was under 128 bits.
5.2 Results and Discussions
We first evaluated the basic performance of the pro-
posed method. Performance was measured initially
after super vised tra ining of the student, and sub-
sequently after sequential knowledge transfers from
new teachers.
At the initial stage, the student’s performa nce was
predictably low, as the test set included samples from
previously un seen pla c e classes, highlighting the in-
herent difficulty of the VPR task unde r such condi-
tions.
Figure 5 shows that performance improved with
an increasing number of samples across all five
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
Replay
Prior
US
RR
Entropy
Mixup
Figure 5: Top-1 accuracy vs. KT cost (N) under different
replay conditions. K = 10.
strategies, thou gh no ta ble differences wer e observed
among them:
Replay Strategy: When provided with sufficiently
many samples, this strategy effectively mitigated
catastrophic forgetting (Kang et al., 2023) and con-
sistently achieved the highest accu racy. However, it
does not conform to strict continual learning princi-
ples. The Prio r strategy, a variant which queries the
teacher with the student’s own training samples, ex-
hibited inferior performan ce, likely due to a low prob-
ability of overlap b etween the student’s and teacher’s
training samples.
US Strategy: Uniform Sampling (U S) showed the
lowest performance in all experiments, presumab ly
due to the un iform distribution not matching the
teacher model’s predictive distribution in the embed-
ding space.
RR Strategy: Desp ite its simplicity, the Reciproc al
Rank (RR) stra tegy surprisingly achieved high per-
formance, indicating that the reciprocal ra nk feature
distribution approxim ates the teacher’s predictive dis-
tribution well.
Entropy Strategy: The Entropy strategy performed
compara bly or better than RR, especially excelling
when the number of samples N was small by effec-
tively selecting high-quality samples.
Mixup Strategy: Mixup balances generalization and
communication c ost effectively. Though it requires
retaining a sma ll number R of replay samples, its
knowledge transfer cost is substantially lower than
Replay w hile still mitigating forgetting and achieving
compara ble performance.
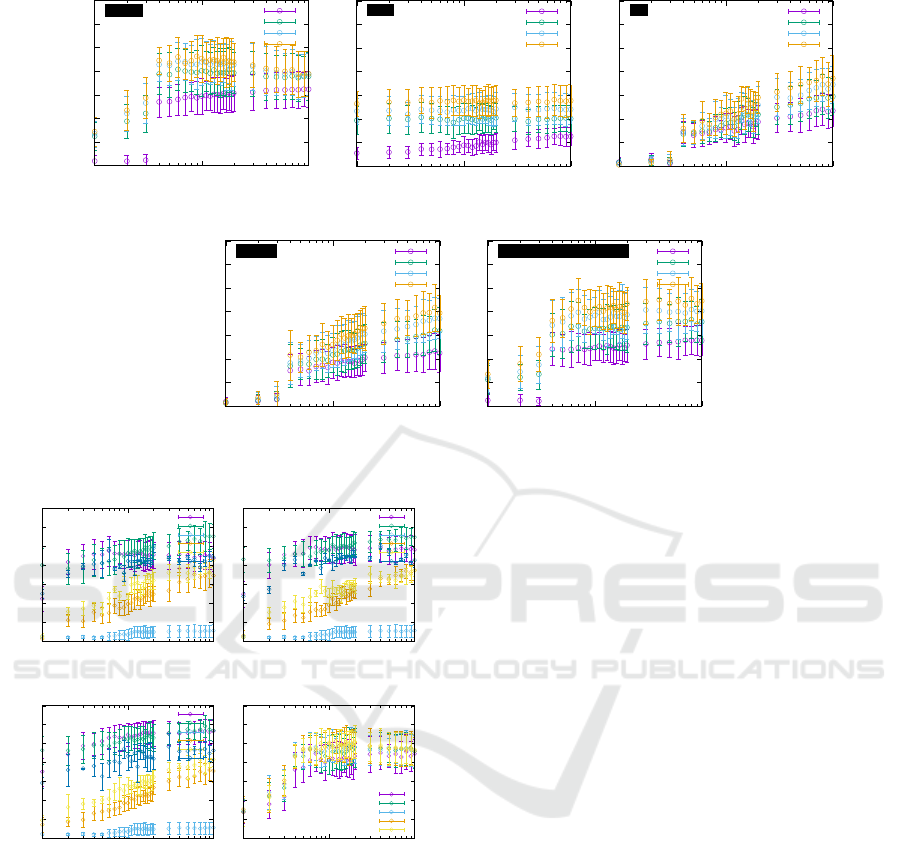
Figure 6 illustrates the student’s VPR perfor-
mance evolution thro ugh continual learning. The
Replay strategy demonstrated the greatest stability,
followed by Mixup, Entropy, RR, and US. No-
tably, Mixup closely matched Replay’s stability by
leveraging replay samples. Even strictly black-box
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
132
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
ReplayReplay
i=0
i=1
i=2
i=3
(a) Replay
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
PriorPrior
i=0
i=1
i=2
i=3
(b) Prior
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
RRRR
i=0
i=1
i=2
i=3
(c) RR
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
EntropyEntropy
i=0
i=1
i=2
i=3
(d) Entropy
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
Mixup: Replay(1)+EntropyMixup: Replay(1)+Entropy
i=0
i=1
i=2
i=3
(e) Mixup
Figure 6: Performance evolution of VPR models across continual learning stages.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
Replay
Prior
US
RR
Entropy
Mixup
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
Replay
Prior
US
RR
Entropy
Mixup
(a) K = 20 (b) K = 30
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
Replay
Prior
US
RR
Entropy
Mixup
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1 10 100
R=1
R=2
R=3
R=4
R=5
(c) K = 40 (d) R=1,2,3,4,5
Figure 7: Parameter analysis on ( a-c) known class count K
and (d) replay sample size R.
teacher-compliant strategies such as RR a nd Entropy
approa c hed the performance of non-black-box ap-
proach e s (Replay) when more than 20 samples per
class were used. Th is demonstrates the promise of
the proposed methods in challenging black-box MIA
scenarios.
Figure 7 (a–c) depicts performance variation as
the number of place classes K experienced by each
robot cha nges. While RR and Entropy stra tegies ex-
hibited a slight performance decline with increasing
K, their accuracy remained comparable to Replay, ev-
idencing robustness throughou t continual learning.
Finally, Figure 7 (d) shows the impact of varying
the number of replay sam ples R in the Mixup strategy.
Even with a small R (e.g., R = 1), increasing the num-
ber of no n-replay samples sufficiently improved VPR
accuracy, suggesting that Mixup’s practical knowl-
edge transfer cost can be minimized witho ut sacrific-
ing perfor mance.
In sum mary, the pr oposed approa c h substan tially
improved performance under cha llenging blac k-box
MIA settings. In particular, the RR strategy achieved
surprisingly strong results despite its simplicity. The
Entropy strategy further enhanced performance with
minimal addition a l cost. T hese findings build upon
insights from non -black-box MIA tasks in VPR
(Taked a and Tanaka, 2021)(K im et al., 2019) (Sec-
tion 4.2 ) and lay a foundation for future multi-robot
continual learning research.
6 CONCLUSION AND FUTURE
WORK
This study formulated co ntinual multi-robot learn-
ing for visual plac e recognition as a teacher-student
knowledge transfer problem, leveraging membership
inference attacks (MIA)— the only major privacy
attack applicable to black-box te a chers. To ad-
dress MIA’s critical bottleneck of low sampling ef-
ficiency, we prop osed utilizing the student model’s
prior knowledge to improve practical samp ling effi-
ciency. Extensive experiments demonstrated signifi-
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
133

cant effectiveness of the approach, revealing the in-
terplay between VPR accuracy, sampling efficiency,
and computational cost.
Our investigation focused on a near-worst-case
scenario where all teachers are black bo xes and all
robots have limited initial performan ce. For practi-
cal deployment, future work should explore leverag-
ing heterogen e ous teach er models, including white-
box and high-pe rforming teachers, to further enhance
learning. Moreover, improving VPR performance
may benefit from several well-k nown extension s: (1)
advancing from grid-based to adaptive workspace
partitioning for place definitions, (2) exten ding from
single-view to multi-view VPR, and (3) shifting from
passive to active VPR with r obot control.
Immediate f uture directions in c lude applying
these a dvancements to challenging real-world tasks
and addressing the lost robot problem to realize robust
long-ter m autonomy in open-world environments.
REFERENCES
Buzaglo, G., Haim, N., Yehudai, G., Vardi, G., Oz, Y.,
Nikankin, Y., and Irani, M. (2023). Deconstruct-
ing data reconstruction: Multiclass, weight decay and
general losses. In Advances in Neural Information
Processing Systems 36: Annual Conference on Neural
Information Processing Systems 2023, NeurIPS 2023,
New Orleans, LA , USA, December 10 - 16, 2023.
Cabrera-Ponce, A. A., Martin-Ortiz, M., and Martinez-
Carranza, J. (2023). Continual learning for topolog-
ical geo-localisation. Journal of Intelligent & Fuzzy
Systems, 44(6):10369–10381.
Carlevaris-Bianco, N., Ushani, A. K., and Eustice, R. M.
(2016). University of michigan north campus long-
term vision and li dar dataset. Int. J. Robotics Res.,
35(9):1023–1035.
Casado, F. E., Lema, D., Iglesias, R., Regueiro, C. V., and
Barro, S. (2020). Collaborative and continual learning
for classification tasks in a society of devices. arXiv
preprint arXiv:2006.07129.
Chen, H., Wang, Y., Xu, C., Yang, Z., Liu, C., Shi, B., Xu,
C., X u, C., and Tian, Q. (2019). Data-free learning of
student networks. In 2019 IEEE/CVF International
Conference on Computer Vision, pages 3513–3521.
IEEE.
Chen, L.-C., Zhu, Y., Papandreou, G. , Schroff, F., and
Adam, H. (2018). Encoder-decoder with atrous sep-
arable convolution for semantic image segmentation.
In ECCV.
Fredrikson, M., Jha, S., and Ristenpart, T. (2015). Model
inversion attacks that exploit confidence information
and basic countermeasures. In Proceedings of the
22nd ACM SIGSAC conference on computer and com-
munications security, pages 1322–1333.
Gao, D., Wang, C., and Scherer, S. (2022). Airloop: Life-
long loop closure detection. In 2022 International
Conference on Robotics and Automation (ICRA),
pages 10664–10671. IEEE.
Garcia-Fidalgo, E. and Ortiz, A. ( 2018). ibow-lcd: An
appearance-based loop-closure detection approach us-
ing incremental bags of binary words. IEEE Robotics
Autom. Lett., 3(4):3051–3057.
Hinton, G. E., Vinyals, O., and Dean, J. (2015). Dis-
tilling the knowledge in a neural network. CoRR,
abs/1503.02531.
Hiroki, T. and Tanaka, K. (2019). Long-term knowledge
distillation of visual place classifiers. In 2019 IEEE
Intelligent Transportation Systems Conference, ITSC,
pages 541–546. IEEE.
Hu, H., Salcic, Z., Sun, L., Dobbie, G., Yu, P. S ., and Zhang,
X. (2022). Membership inference attacks on machine
learning: A survey. ACM Computing Surveys (CSUR),
54(11s):1–37.
Isele, D. and Cosgun, A. (2018). Selective experience
replay for lifelong learning. In Proceedings of the
Thirty-Second AAAI Conference on Artificial Intelli-
gence (AAAI-18), pages 3302–3309. AA A I Press.
Kang, M., Z hang, J., Zhang, J., Wang, X., Chen, Y., Ma, Z.,
and Huang, X . (2023). Alleviating catastrophic forget-
ting of incremental object detection via within-class
and between-class knowledge distillat ion. In 2023
IEEE/CVF I nternational Conference on Computer Vi-
sion (ICCV), pages 18848–18858.
Kim, G., Park, B., and Ki m, A. (2019). 1-day learning,
1-year localization: Long-term lidar localization us-
ing scan context image. IEEE Robotics Autom. Lett.,
4(2):1948–1955.
Ko, M., Jin, M., Wang, C., and Jia, R. (2023). Practi-
cal membership inference attacks against large-scale
multi-modal models: A pilot study. In Proceedings of
the IEEE/CVF International Conference on Computer
Vision, pages 4871–4881.
Lange, M. D., Aljundi, R., Masana, M., Parisot, S., Jia,
X., Leonardis, A. , S labaugh, G. G., and Tuytelaars, T.
(2022). A continual l earning survey: Defying forget-
ting in classification tasks. IEEE Trans. Pattern Anal.
Mach. Intell., 44(7):3366–3385.
Lesort, T., Lomonaco, V., Stoian, A., Maltoni, D., Fil-
liat, D., and D´ıaz-Rodr´ıguez, N. (2020). Continual
learning for robotics: Definition, framework, learning
strategies, opportunities and challenges. Information
fusion, 58:52–68.
Liu, Y., Zhang, W., Wang, J., and Wang, J. ( 2021).
Data-free knowledge transfer: A survey. CoRR,
abs/2112.15278.
Lomonaco, V., Pellegrini, L., R odriguez, P., Caccia, M.,
She, Q., Chen, Y., Jodelet, Q., Wang, R., Mai, Z.,
Vazquez, D., et al. (2022). Cvpr 2020 continual learn-
ing in computer vision competition: Approaches, re-
sults, current challenges and future directions. Artifi-
cial Intelligence, 303:103635.
Lowry, S. M., S¨underhauf, N., Newman, P., Leonard, J. J.,
Cox, D. D., Corke, P. I., and Milford, M. J. (2016).
Visual place recognition: A survey. IEEE Trans.
Robotics, 32(1):1–19.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
134

Mangelson, J. G., Dominic, D., Eustice, R. M., and Vasude-
van, R. (2018). Pairwise consistent measurement set
maximization for robust multi-robot map merging. In
2018 IEEE international conference on robotics and
automation (ICRA), pages 2916–2923. IEEE.
Milford, M. J. and Wyeth, G. F. (2012). Seqslam: Vi-
sual route-based navigation for sunny summer days
and stormy winter nights. In 2012 IEEE international
conference on robotics and automation, pages 1643–
1649. IEEE.
Morita, H., Hild, M., Miura, J. , and Shirai, Y. (2005). View-
based localization in outdoor environments based on
support vector learning. In 2005 IEEE/RSJ Interna-
tional Conference on Intelligent Robots and Systems,
pages 2965–2970. IEEE.
Nayak, G. K., Mopuri, K. R., Shaj, V., Radhakrishnan,
V. B., and Chakraborty, A. (2019). Zero-shot knowl-
edge distillation in deep networks. In Proceedings of
the 36th International Conference on Machine Learn-
ing, ICML 2019, 9-15 June 2019, Long Beach, Cal-
ifornia, USA, volume 97 of Proceedings of Machine
Learning Research, pages 4743–4751. PMLR.
Ohta, T., Tanaka, K., and Yamamoto, R. (2023). Scene
graph descriptors for visual place classification from
noisy scene data. ICT Express, 9(6):995–1000.
Rozsypalek, Z., Rou?ek, T., Vintr, T., and Krajnik, T.
(2023). Multidimensional particle filter for long-term
visual teach and repeat in changing environments.
IEEE Robotics and Automation Letters, 8(4):1951–
1958.
Seo, P. H., Weyand, T., Sim, J., and Han, B. (2018).
Cplanet: Enhancing image geolocalization by com-
binatorial partitioning of maps. In Computer Vision
- E CCV 2018 - 15th European Conference, Munich,
Germany, September 8-14, 2018, Proceedings, Part X,
volume 11214 of Lecture Notes in Computer Science,
pages 544–560. Springer.
Sobreira, H., Costa, C. M., Sousa, I., Rocha, L., Lima,
J., Farias, P., Costa, P., and Moreira, A. P. (2019).
Map-matching algorithms for robot self-localization:
a comparison between perfect match, iterative closest
point and normal distributions transform. Journal of
Intelligent & Robotic Systems, 93:533–546.
Takeda, K. and Tanaka, K. (2021). Dark reciprocal-
rank: Teacher-to-student knowledge transfer from
self-localization model to graph-convolutional neu-
ral network. In IEEE International Conference on
Robotics and Automation, ICRA 2021, Xi’an, China,
May 30 - June 5, 2021, pages 1846–1853. IEEE.
Tanaka, K. (2015). Cross-season place recognition using
NBNN scene descriptor. In 2015 IEEE/RSJ Interna-
tional Conference on Intelligent Robots and Systems,
IROS 2015, Hamburg, Germany, September 28 - Oc-
tober 2, 2015, pages 729–735. I EEE.
Tsukahara, K., Tanaka, K., and Iwata, D. (2024). Training
self-localization models for unseen unfamiliar places
via teacher-to-student data-free knowledge transfer. In
IEEE Conference on Intelligent Robots and Systems
(IROS 2024 L ate Breaking Paper).
V¨odisch, N. , Cattaneo, D., Burgard, W., and Valada, A.
(2022). Continual slam: Beyond lifelong simultane-
ous localization and mapping through continual learn-
ing. In The International Symposium of Robotics Re-
search, pages 19–35. Springer.
V¨odisch, N. , Cattaneo, D., Burgard, W., and Valada, A.
(2023). Covio: Online continual learning for visual-
inertial odometry. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion, pages 2464–2473.
Wang, S., Laskar, Z., Melekhov, I., Li, X., and Kannala,
J. (2021). Continual learning for image-based cam-
era localization. In Proceedings of the IE EE/CVF
International Conference on Computer Vision, pages
3252–3262.
Weyand, T., Kostrikov, I., and Philbin, J. (2016). Planet
- photo geolocation with convolutional neural net-
works. In Leibe, B., Matas, J., Sebe, N., and Well ing,
M., editors, Computer Vision - ECCV 2016 - 14th
European Conference, Amsterdam, The Netherlands,
October 11-14, 2016, Proceedings, Part VIII, volume
9912 of Lecture Notes in Computer Science, pages
37–55. Springer.
Yoshida, M., Yamamoto, R., Iwata, D., and Tanaka, K.
(2024). Open-world distributed robot self-localization
with transferable visual vocabulary and both absolute
and relative features. CoRR, abs/2109.04569.
Continual Multi-Robot Learning from Black-Box Visual Place Recognition Models
135
