
Contrastive Learning for Conversational Emotion Recognition Using
Knowledge Enhancement of Large Language Models
Andrew L. Mackey, B. Israel Cuevas and Susan Gauch
Computer Science and Engineering, University of Arkansas, Fayetteville, Arkansas, U.S.A.
Keywords:
Emotion Analysis, Language Models, Natural Language Processing.
Abstract:
Emotion recognition in conversation (ERC) is the task of classifying the emotion of each utterance in a con-
versation while learning the underlying latent representations. However, the representations for utterances are
challenging to produce effectively given semantic and contextual information in the conversation. Large Lan-
guage Models (LLMs) have demonstrated performance in various forms of emotion classification, including
in zero-shot and few-shot settings, but their usage may be curtailed in some settings, particularly in limited
resource environments. In this work, we propose a contrastive learning framework for the ERC task that
leverages emotional anchors with semantic information encoded from an LLM to facilitate the learning of rep-
resentations using a lightweight pretrained langauge model (PLM). Experimental results on benchmark ERC
datasets demonstrate the effectiveness of our approach to baseline models while simultaneously reducing the
inference cost of LLMs.
1 INTRODUCTION
Emotion recognition in conversation (ERC) is an ac-
tive research area in the natural language processing
(NLP) community that is concerned with the classi-
fication of utterances in a conversation. Unlike the
traditional task of classifying a document (i.e. social
media post) as being one emotion from a discrete set
of possible emotions (i.e. happy, sad, etc.), the ERC
task involves conversations where the dynamic inter-
actions create changes between the context, speakers,
and dialogue. As demonstrated in Figure 1, the emo-
tion for each state of the conversation can easily shift
depending on the state of the dialogue, speaker, utter-
ance context, etc.
In recent years, contrastive learning and knowl-
edge enhancement techniques have demonstrated suc-
cess as frameworks for representation learning and
deep contextual information, respectively. Several
approaches have leveraged contrastive learning to
learn the latent representations whereby closely or
semantically-related representations are pulled closer
to one another while pushing dissimilar representa-
tions further apart in the latent space. Knowledge
enhancements techniques allow for the transfer of
knowledge from significantly larger teacher models
to smaller models to improve or enhance inputs using
techniques such as semantic augmentation, input re-
structuring, or semantic augmentation. This is partic-
ularly advantageous when you require the deployment
of models in a resource-constrained environment.
In this paper, we investigate a supervised con-
trastive learning framework combined with knowl-
edge enhancement techniques for the ERC task on
class-imbalanced data. We utilize a pretrained lan-
guage model with a contrastive learning framework
that leverages semantically-enhanced emotion label
anchors extracted from an LLM to guide the contex-
tual representations during training. Our study inves-
tigates the impact of combining knowledge enhance-
ment with contrastive learning to the ERC task.
2 BACKGROUND INFORMATION
The primary approaches for the ERC task in re-
cent times coalesce around sequence-based, graph-
based, and knowledge-enhanced methodologies. Di-
alogRNN modeled temporal dynamics and dependen-
cies of dialogue by using RNNs (Majumder et al.,
2019). DialogCRN introduced a contextual recurrent
network that modeled the dialogue history and tem-
poral dependencies for emotion recognition by utiliz-
ing cognitive factors (Hu et al., 2021). DialogGCN
is a graph neural network-based approach to the ERC
task that uses nodes to model the utterances (Ghosal
330
Mackey, A. L., Cuevas, B. I. and Gauch, S.
Contrastive Learning for Conversational Emotion Recognition Using Knowledge Enhancement of Large Language Models.
DOI: 10.5220/0013720100004000
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2025) - Volume 1: KDIR, pages 330-336
ISBN: 978-989-758-769-6; ISSN: 2184-3228
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
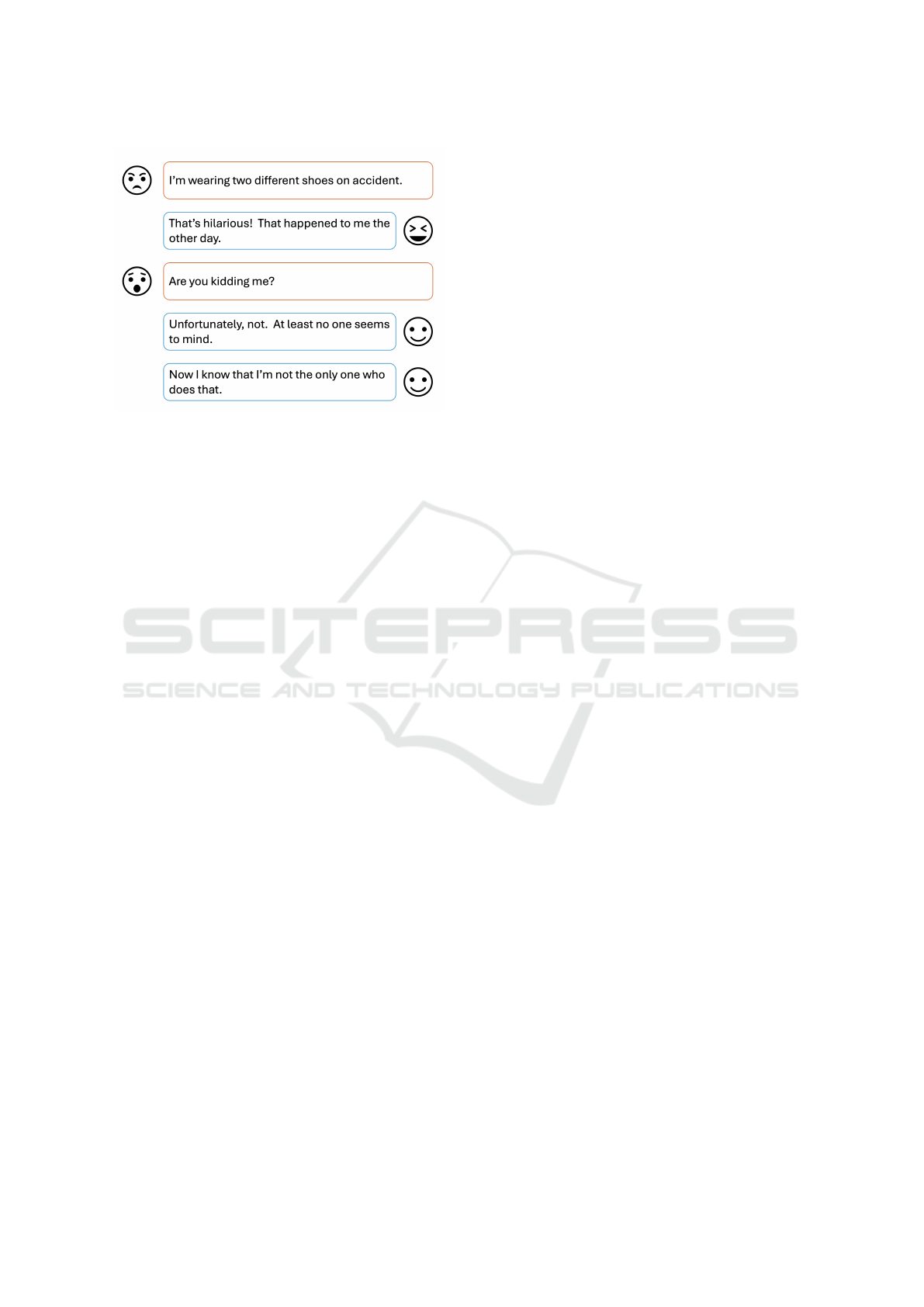
Figure 1: Example conversation and emotion recognition
from utterances.
et al., 2019). DAG-ERC uses a directed acyclic graph
(DAG) to model the structure within a conversation
(Shen et al., 2021). The Knowledge-Enriched Trans-
former (KET) was proposed as a transformer model
that enhanced emotion detection by leveraging ex-
ternal knowledge with the transformer architecture
(Zhong et al., 2019).
Contrastive learning has demonstrated success in
the field of natural language processing with respect
to self-supervised learning frameworks. In contrastive
learning, the primary objective is to learn representa-
tions where we can distinguish similar and dissimilar
samples from one another. The process involves the
construction of positive and negative examples and
pairings, where positive pairs must share some type of
similarity and negative pairs have some differences.
Models aim to move positive examples closer to one
another by positioning them closer some anchor in the
latent embedding space while pushing apart the an-
chor for dissimilar examples and making them farther
apart (Khosla et al., 2020). Prior work as also demon-
strated that it is possible to extract useful representa-
tions from high-dimensional data in some latent space
through Contrastive Predictive Coding (van den Oord
et al., 2019).
SimCLR proposed a simple framework for learn-
ing visual representations by leveraging a contrastive
loss by investigating data augmentations, learnable
nonlinear transformations, and the benefits of con-
trastive learning from varying sizes of batch sizes and
training steps (Chen et al., 2020). SimCSE presented
a simple contrastive framework that used dropout as
a data augmentation approach to advanced sentence
embeddings (Gao et al., 2021). With Supervised Pro-
totypical Contrastive Learning (SPCL), the authors
leveraged a contrastive learning loss for the ERC task
on class-imbalanced data while combining it with
curriculum learning (Song et al., 2022). Emotion-
Anchored Contrastive Learning (EACL) utilized tex-
tual emotion labels that were used to generate emo-
tion anchor representations (Yu et al., 2024).
Several techniques have been proposed to im-
prove or enhance smaller models from larger mod-
els, such as knowledge distillation and knowledge en-
hancement techniques. Knowledge distillation has
been demonstrated as a model compression technique
where information from a teacher model is transferred
to a smaller student model that is more efficient (Bu-
cila et al., 2006). The work presented in (Hinton
et al., 2015) demonstrated an ability for the complex
model to transfer not just the final predictions, but also
on the soft targets that were produced by the teacher
model to facilitate the student model learning nuanced
knowledge. In NLP, DistilBERT represents a PLM
that is a distilled version of BERT which reduces the
model’s size by 40%, being 60% faster, and retains
97% of its language understanding capabilities (Sanh
et al., 2020).
Knowledge enhancement improves the under-
standing of text inputs by providing additional con-
text from domain-specific sources, tagging from lexi-
cons, restructuring the inputs, etc. In (Qu et al., 2019),
the authors enhanced a BERT-based model through
a history answer embedding where prior knowledge
was necessary in conversational settings. The au-
thors in (Zhang et al., 2019) incorporated the use of
knowledge graphs to improve a BERT-based model
by providing structured knowledge facts from exter-
nal sources.
3 METHODOLOGY
3.1 Definition
Each of the datasets evaluated in this work con-
sists of the following: conversations, speakers, and
emotions. The set of conversations C consists of
utterances and emotion labels for each conversa-
tion turn. We represent a single conversation c ∈
C as a collection of utterances and speakers c =
[(s
1
,u
1
),(s
2
,u
2
),...,(s
N
,u
N
)], where s
i
∈ S refers to
the speaker, u
i
is the utterance for the i
th
turn, and S is
the set of speakers. We define E as the set of emotion
labels where E = {e
1
,e
2
,..., e
k
} for the corresponding
dataset.
Contrastive Learning for Conversational Emotion Recognition Using Knowledge Enhancement of Large Language Models
331

LLM
Knowledge Enhanced
Emotion Label
Language Model
Emotion Label
<Speaker 1>: The weather
is nice today. Isn’t it great?
<Speaker 2>: I know,
right?
<Speaker 1>: It is a great
day and I’m glad I’m
outside. The emotion of
<Speaker 1> is [MASK].
Language Model
Figure 2: Emotion frequency for the labels in the MELD
dataset.
3.2 Model Overview
The proposed model for this work features a
pretrained language model for learning the represen-
tations of the utterances, a knowledge enhancement
approach to extract information from large language
models to improve ERC task performance of PLMs,
the incorporation of semantically-enhanced emotion
anchors, and a contrastive learning framework that
utilizes these enhanced emotion anchors. In the
sections that follow, we will define and outline the
purpose of each of these components of our proposed
model.
Table 1: Frequency metrics for the IEMOCAP and MELD
datasets by the number of utterances, dialogues, and label
classes.
IEMOCAP MELD
Uttr. Dia. Uttr. Dia.
Train 4,810 100 9,989 1,038
Val 1,000 20 1,109 114
Test 1,523 31 2,610 280
Total 7,333 151 13,708 1,432
Classes 6 7
3.3 Context Encoding
We adopt a contrastive learning framework with emo-
tion anchors by utilizing pretrained language mod-
els along with a prompt-based approach to implement
masked language modeling following previous work
(Song et al., 2022). Our prompt-based contextual rep-
resentations are formed at utterance time t by using
turns (s,u) ∈ {(s
j
,u
j
) | t − k ≤ j ≤ t} where k rep-
resents the window length of most recent turns. The
emotion for utterance u
t
is predicted by using the fol-
lowing prompt:
c
t
= [s
t−k
,u
t−k
,..., s
t
,u
t
, p
t
] (1)
p
t
= ”For u
t
, s
t
feels ⟨MASK⟩”. (2)
The last hidden state of the ⟨MASK⟩ token as the rep-
resentation for the utterance. The model attends to the
target sentence when training in this manner so that it
is able to produce usable representations.
3.4 Contrastive Learning and
Knowledge Enhancement
Our model leverages a supervised contrastive learning
framework that utilizes both learned contextual rep-
resentations and semantically-enhanced emotion an-
chors from an LLM. A batch of N conversation ex-
amples X = {x
1
,x
2
,..., x
N
} where X ∈ R
n×ℓ
where n
represents the batch size and ℓ is the maximum length
of the input. The last hidden state of the input of the
language model is obtained in:
Z = PLM(X) (3)
We use the hidden state of the ⟨MASK⟩ token
Z
⟨MASK⟩
and feed this into a multilayer perceptron
(MLP) network to obtain the representations for the
utterances:
R = MLP
CL
(Z
⟨MASK⟩
) (4)
Prior work leveraged anchors where PLMs were
used to encode the emotion labels (Yu et al., 2024).
In our approach, we leverage LLMs to expand the se-
mantic and contextual representations of each emo-
tion label in the set of emotions emo to form an en-
hanced emotion label representation emo
′
. We ob-
tain the embedding representations from the LLM for
emo
′
and use an MLP network to obtain a set of pa-
rameterized representations for our model as R
′
:
emo
′
= LLM
1
(emo) (5)
R
′
= MLP(LLM
2
(emo
′
)) (6)
We let sim(z
i
,z
k
) be some similarity function for
inputs z
i
and z
k
, where the use of cosine similarity
employed for this task. For the given batch represen-
tations R along with semantically-enhanced and en-
coded emotion labels R
′
, we combine the represen-
tations together to form T = R ∪ R
′
for use with the
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
332
contrastive learning loss that leverages the anchors to
improve the alignment of representations. We define
Pos(i) to return all members in the representations T
with the same emotion as member i. We define τ to
represent a temperature hyperparameter for the loss
function.
f (z
i
,z
k
) = exp(sim(z
i
,z
k
)/τ) (7)
L
CL
=
n+|emo|
∑
i=1
−log
∑
r
j
∈Pos(i)
f (r
i
,r
j
)
|Pos(i)|
∑
r
j
∈T
f (r
i
,r
j
)
(8)
The effects from the L
CL
function can be observed
in the movements of related representations becoming
nearer and unrelated representations becoming more
distant. In addition, the anchors serve as a guide when
learning the representations for the utterances while
also learning how to increase the distance between
emotion anchor representations. A cross entropy loss
is combined with the supervised contrastive loss to
improve the model’s discriminative capabilities:
ˆ
y = Softmax
MLP
CE
(Z
⟨MASK⟩
)
(9)
L
CE
= −
1
n
n
∑
i=1
|emo|
∑
k=1
y
ik
log( ˆy
ik
) (10)
The final loss function uses the λ hyperparameter to
serve as a weighted average between the supervised
contrastive loss and the cross entropy loss functions.
L = λ ·L
CE
+ (1 − λ)· L
CL
(11)
4 EXPERIMENTAL DESIGN
4.1 Setup
The language models used for experiments include
BERT, RoBERTa, and ModernBERT from the Hug-
gingFace Transformers library. The PyTorch frame-
work was used on a single NVIDIA A6000 GPU. The
OpenAI GPT-4o LLM was used for knowledge en-
hancement tasks. We use the AdamW optimizer, a
dropout rate of 0.1, maximum length of 512, temper-
ature τ = 0.1, and a learning rate of 1e
−5
.
neutral
joy
surprise
anger
sadness
disgust
fear
0
500
1,000
1,500
2,000
2,500
3,000
3,500
4,000
4,500
5,000
4,710
1,743
1,205
1,109
683
271
268
1,256
402
281
345
208
68
50
Number of Utterances
Train Test
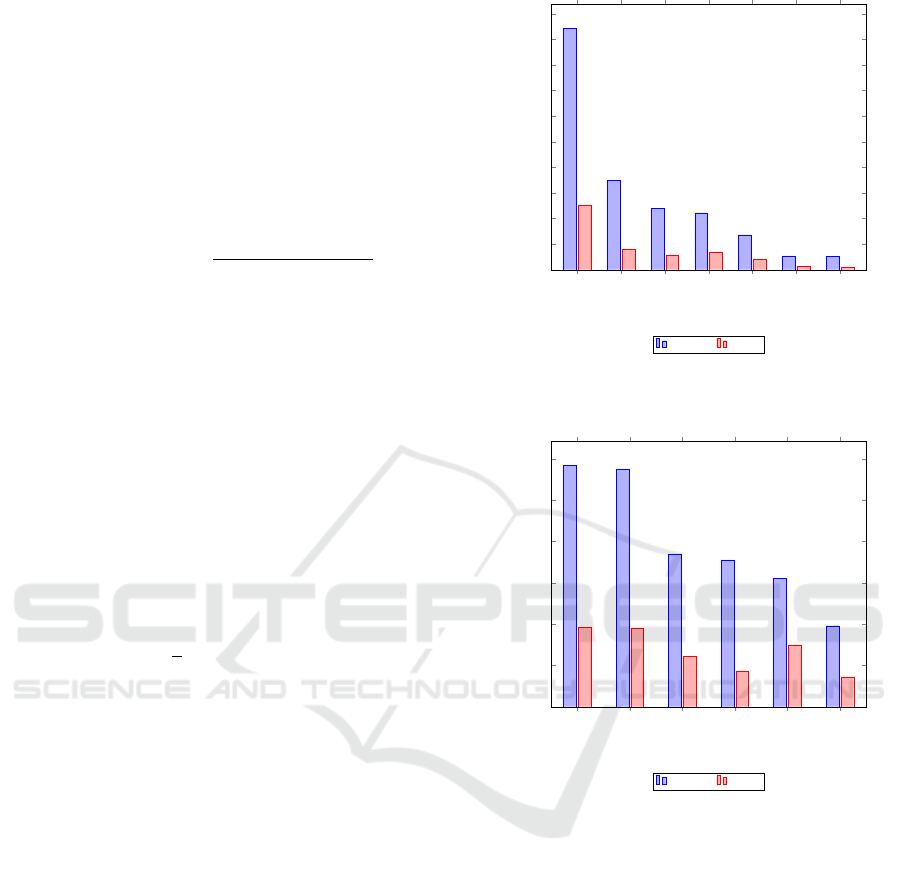
Figure 3: Emotion frequency for the labels in the MELD
dataset.
neutral
frustrated
sad
angry
excited
happy
0
200
400
600
800
1,000
1,200
1,167
1,149
739
711
620
392
384
381
245
170
299
143
Number of Utterances
Train Test
Figure 4: Emotion frequency for the labels in the IEMO-
CAP dataset.
4.2 Datasets
Experiments are conducted on two major benchmark
datasets: MELD and IEMOCAP (Poria et al., 2019)
(Busso et al., 2008).
MELD. The MELD (Multimodal EmotionLines
Dataset) is a multimodal emotion recognition dataset
that contains utterances and conversations extracted
from the TV show Friends (Poria et al., 2019). Each
utterance contains an emotion label from one of the
following: surprise, anger, neutral, sadness, disgust-
ing, joy, and fear. The emotion distribution between
the training and testing sets can be found in Figure 3.
Contrastive Learning for Conversational Emotion Recognition Using Knowledge Enhancement of Large Language Models
333

Table 2: Comparison of Weighted F1 Average Metric for IEMOCAP and MELD Datasets. The bold font indicates the best
performance.
Baseline Models IEMOCAP MELD
BERT (Devlin et al., 2019) 64.87 63.45
RoBERTa (Liu et al., 2019) 63.98 64.62
ModernBERT (Warner et al., 2024) 66.11 61.80
ChatGPT 3-shot (Zhao et al., 2023) 48.58 58.35
Experimental Models IEMOCAP MELD
BERT+ECL 65.28 64.91
RoBERTa+ECL 67.72 66.31
ModernBERT+ECL 71.25 65.67
IEMOCAP. The IEMOCAP dataset consists of 151
videos of two speakers per session. These clips
are spread across five sessions per actor and include
both scripted and improvised dialogues (Busso et al.,
2008). The dataset is multimodal, providing video
recordings of the actors’ facial expressions and body
language. Each segment is annotated for the presence
of the following emotions: excited, frustrated, neu-
tral, sad, happy, and angry. The emotion distribution
between the training and testing sets can be found in
Figure 4.
4.3 Metrics
Due to the imbalance that exists between the differ-
ent target classes as seen in (Lee and Lee, 2022), (Yu
et al., 2024), and (Song et al., 2022), we report the re-
sults using the weighted F1 score in the sections that
follow.
5 RESULTS
The results for our proposed methods and baseline ex-
periments are reported in Table 2. The mean weighted
F1 score is reported after n = 5 successive runs of
each experiment. As demonstrated in the results, we
observed that our experimental models outperform
the baseline pretrained langauge models on both the
IEMOCAP and MELD datasets. For the BERT mod-
els, we observe a difference of ∆ = 0.41 and ∆ = 1.46
for the IEMOCAP and MELD datasets, respectively.
For the RoBERTA models, we observe a difference of
∆ = 3.74 and ∆ = 1.69 for the IEMOCAP and MELD
datasets, respectively. For the ModernBERT models,
we observe a difference of ∆ = 5.14 and ∆ = 3.87,
respectively.
We observe that the choice of pretrained language
model with the proposed constrastive learning frame-
work affects the overall performance, but all evaluated
pretrained language models demonstrate an improve-
ment in performance when combined with the con-
trastive learning framework. The mean performance
gain across all datasets and PLMs is
¯
∆
ALL
= 2.718
(s
∆
= 1.800) where the performance gain for the
IEMOCAP dataset is
¯
∆
IEMO
= 3.097 (s
∆
= 2.430) and
for the MELD dataset is
¯
∆
MELD
= 2.34 (s
∆
= 1.33).
In comparison to the model proposed by (Zhao
et al., 2023), we observe an improvement from our
best performing model ModernBERT+ECL over the
previous work by a large margin of ∆ = 22.67 and ∆ =
7.32 for the IEMOCAP and MELD datasets, respec-
tively. This may be due to the limitations of the origi-
nal experiment under a few shot prompt approach and
further exploration is needed to understand whether
more recent version of the models demonstrate im-
proved performance for the ERC task.
6 CONCLUSION
In this paper, we presented an approach that com-
bined a contrastive learning framework with knowl-
edge enhancement from large language models to im-
prove representation learning for the ERC classifi-
cation task. Our experiments demonstrated that us-
ing LLM-generated anchors as guidance led to trans-
ferable representations that could be leveraged in a
resource-constrained environment. We also demon-
strate that the proposed framework would be effective
across different pretrained language models.
Our findings suggest that LLMs can be leveraged
as a source to extract the semantic representations for
emotion labels that can be used in a contrastive learn-
ing framework. Future work can explore further re-
finements in the knowledge enhancement process to
improve the label imbalances to provide the PLMs
with additional context to improve underperforming
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
334

label classification. Furthermore, contrastive learning
methods could potentially be expanded by exploring
the relationship of hard negative selection based on
emotion relationships. Lastly, multimodal data could
be incorporated to further enhance the model’s perfor-
mance.
REFERENCES
Bucila, C., Caruana, R., and Niculescu-Mizil, A. (2006).
Model compression. In Proceedings of the 12th
ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining, KDD ’06, page
535–541, New York, NY, USA. Association for Com-
puting Machinery.
Busso, C., Bulut, M., Lee, C.-C., Kazemzadeh, A., Mower,
E., Kim, S., Chang, J. N., Lee, S., and Narayanan,
S. S. (2008). IEMOCAP: interactive emotional dyadic
motion capture database. Language Resources and
Evaluation, 42(4):335–359.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. (2020).
A simple framework for contrastive learning of visual
representations.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2019). Bert: Pre-training of deep bidirectional trans-
formers for language understanding.
Gao, T., Yao, X., and Chen, D. (2021). SimCSE: Sim-
ple contrastive learning of sentence embeddings. In
Moens, M.-F., Huang, X., Specia, L., and Yih, S.
W.-t., editors, Proceedings of the 2021 Conference on
Empirical Methods in Natural Language Processing,
pages 6894–6910, Online and Punta Cana, Dominican
Republic. Association for Computational Linguistics.
Ghosal, D., Majumder, N., Poria, S., Chhaya, N., and Gel-
bukh, A. (2019). Dialoguegcn: A graph convolutional
neural network for emotion recognition in conversa-
tion.
Hinton, G., Vinyals, O., and Dean, J. (2015). Distilling the
knowledge in a neural network.
Hu, D., Wei, L., and Huai, X. (2021). DialogueCRN: Con-
textual reasoning networks for emotion recognition in
conversations. In Zong, C., Xia, F., Li, W., and Nav-
igli, R., editors, Proceedings of the 59th Annual Meet-
ing of the Association for Computational Linguistics
and the 11th International Joint Conference on Nat-
ural Language Processing (Volume 1: Long Papers),
pages 7042–7052, Online. Association for Computa-
tional Linguistics.
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian,
Y., Isola, P., Maschinot, A., Liu, C., and Krish-
nan, D. (2020). Supervised contrastive learning. In
Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.,
and Lin, H., editors, Advances in Neural Information
Processing Systems, volume 33, pages 18661–18673.
Curran Associates, Inc.
Lee, J. and Lee, W. (2022). CoMPM: Context model-
ing with speaker’s pre-trained memory tracking for
emotion recognition in conversation. In Carpuat, M.,
de Marneffe, M.-C., and Meza Ruiz, I. V., editors,
Proceedings of the 2022 Conference of the North
American Chapter of the Association for Computa-
tional Linguistics: Human Language Technologies,
pages 5669–5679, Seattle, United States. Association
for Computational Linguistics.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D.,
Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov,
V. (2019). Roberta: A robustly optimized BERT pre-
training approach. CoRR, abs/1907.11692.
Majumder, N., Poria, S., Hazarika, D., Mihalcea, R., Gel-
bukh, A., and Cambria, E. (2019). Dialoguernn: an
attentive rnn for emotion detection in conversations.
In Proceedings of the Thirty-Third AAAI Conference
on Artificial Intelligence and Thirty-First Innovative
Applications of Artificial Intelligence Conference and
Ninth AAAI Symposium on Educational Advances in
Artificial Intelligence, AAAI’19/IAAI’19/EAAI’19.
AAAI Press.
Poria, S., Hazarika, D., Majumder, N., Naik, G., Cambria,
E., and Mihalcea, R. (2019). MELD: A multimodal
multi-party dataset for emotion recognition in conver-
sations. In Korhonen, A., Traum, D., and M
`
arquez,
L., editors, Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics, pages
527–536, Florence, Italy. Association for Computa-
tional Linguistics.
Qu, C., Yang, L., Qiu, M., Croft, W. B., Zhang, Y., and
Iyyer, M. (2019). Bert with history answer embedding
for conversational question answering. In Proceedings
of the 42nd International ACM SIGIR Conference on
Research and Development in Information Retrieval,
SIGIR’19, page 1133–1136, New York, NY, USA.
Association for Computing Machinery.
Sanh, V., Debut, L., Chaumond, J., and Wolf, T. (2020).
Distilbert, a distilled version of bert: smaller, faster,
cheaper and lighter.
Shen, W., Wu, S., Yang, Y., and Quan, X. (2021). Di-
rected acyclic graph network for conversational emo-
tion recognition. In Zong, C., Xia, F., Li, W., and Nav-
igli, R., editors, Proceedings of the 59th Annual Meet-
ing of the Association for Computational Linguistics
and the 11th International Joint Conference on Nat-
ural Language Processing (Volume 1: Long Papers),
pages 1551–1560, Online. Association for Computa-
tional Linguistics.
Song, X., Huang, L., Xue, H., and Hu, S. (2022). Su-
pervised prototypical contrastive learning for emo-
tion recognition in conversation. In Goldberg, Y.,
Kozareva, Z., and Zhang, Y., editors, Proceedings of
the 2022 Conference on Empirical Methods in Natural
Language Processing, pages 5197–5206, Abu Dhabi,
United Arab Emirates. Association for Computational
Linguistics.
van den Oord, A., Li, Y., and Vinyals, O. (2019). Represen-
tation learning with contrastive predictive coding.
Warner, B., Chaffin, A., Clavi
´
e, B., Weller, O., Hallstr
¨
om,
O., Taghadouini, S., Gallagher, A., Biswas, R., Lad-
hak, F., Aarsen, T., Cooper, N., Adams, G., Howard,
J., and Poli, I. (2024). Smarter, better, faster, longer:
Contrastive Learning for Conversational Emotion Recognition Using Knowledge Enhancement of Large Language Models
335

A modern bidirectional encoder for fast, memory effi-
cient, and long context finetuning and inference.
Yu, F., Guo, J., Wu, Z., and Dai, X. (2024). Emotion-
anchored contrastive learning framework for emotion
recognition in conversation. In Duh, K., Gomez,
H., and Bethard, S., editors, Findings of the Associ-
ation for Computational Linguistics: NAACL 2024,
pages 4521–4534, Mexico City, Mexico. Association
for Computational Linguistics.
Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., and Liu,
Q. (2019). ERNIE: Enhanced language representation
with informative entities. In Korhonen, A., Traum,
D., and M
`
arquez, L., editors, Proceedings of the 57th
Annual Meeting of the Association for Computational
Linguistics, pages 1441–1451, Florence, Italy. Asso-
ciation for Computational Linguistics.
Zhao, W., Zhao, Y., Lu, X., Wang, S., Tong, Y., and Qin, B.
(2023). Is chatgpt equipped with emotional dialogue
capabilities?
Zhong, P., Wang, D., and Miao, C. (2019). Knowledge-
enriched transformer for emotion detection in textual
conversations. In Inui, K., Jiang, J., Ng, V., and Wan,
X., editors, Proceedings of the 2019 Conference on
Empirical Methods in Natural Language Processing
and the 9th International Joint Conference on Nat-
ural Language Processing (EMNLP-IJCNLP), pages
165–176, Hong Kong, China. Association for Com-
putational Linguistics.
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
336
