
Towards Industry 5.0: AAS/MLOps-Driven Model Maintenance for
Data-Centric Production
∗
Kiavash Fathi
1,2
, Marcin Sadurski
2
, Stefan Waskow
3
,
Tobias Kleinert
1
and Hans Wernher van de Venn
2
1
Chair of Information and Automation Systems for Process and Material Technology, RWTH Aachen University,
52064 Aachen, Germany
2
Institute of Mechatronic Systems, Zurich University of Applied Sciences, 8400 Winterthur, Switzerland
3
OEE Improvement team, ABB, 8200 Schaffhausen, Switzerland
Keywords:
Model and Data Life-Cycle, Machine Learning Operations (MLOps), Asset Administration Shell (AAS),
Human-in-the-Loop Design, Industry 5.0.
Abstract:
Despite the advancements brought by digitalization across industries, only a few state-of-the-art data-driven
methods successfully transition to production and remain viable. The sheer volume of physical assets in pro-
duction lines, combined with constantly evolving requirements, makes model deployment and maintenance
highly complex. This paper presents a production-ready architecture developed for data-driven digital assets
at ABB Schaffhausen AG. The solution integrates MLOps best practices orchestrated via MLRun with the
industry-standard metadata modeling system, Asset Administration Shell (AAS). We demonstrate how con-
trolled artifact generation from MLRun facilitates experiment tracking and knowledge sharing while AAS
ensures standardization and long-term maintenance. By combining MLOps and AAS, we effectively manage
the ever-growing artifacts of data-driven solutions. Additionally, we explore how controlled artifact genera-
tion enables role-based MLOps by restricting access to relevant information based on industrial roles. This
architecture supports a smooth transition to Industry 5.0.
1 INTRODUCTION
One of the main focuses of production lines compliant
with Industry 4.0 standards is flexibility in produc-
tion which is normally implemented and deployed
as modular automation. Due to the short lifespan
of products and manufacturing technologies, modu-
lar automation helps ensure that final products meet
constantly evolving customer requirements with min-
imal engineering effort. (Xia et al., 2023). Addition-
ally, it makes sure that the production line is capa-
ble of coping with unforeseen situations in a safe and
secure manner (Huang et al., 2021). This flexibility
and adaptability will not only ensure fully personal-
ized product for the market but also helps to achieve
a more sustainable production (Ghobakhloo, 2020;
Brettel et al., 2016).
*
This project is part of the research conducted at Com-
petence Centre for Automation and Digitalisation entitled
Pre-Prime (Pre-Process Refinement for Improved Manufac-
turing Efficiency) in collaboration with ABB Schaffhausen
AG.
The demand for production flexibility has driven
extensive research into the management and orches-
tration of physical and digital assets (DAs) in smart
factories. In fact, deploying modular automation re-
quires not only the integration of different assets,
such as robots and automation systems (M
¨
uller et al.,
2021c; M
¨
uller et al., 2021b), but also reconfigurable
assets and processes (M
¨
uller et al., 2021a; Kozma
et al., 2019).
All the changes induced in the physical assets is
reflected in the data readings from them, ultimately
impacting the related DAs. In that regard, given the
fact that majority of the DAs implemented in Industry
4.0 settings for production monitoring and optimiza-
tion are data-driven, there have been numerous re-
search on data handling and data-driven model adap-
tation given changes in the production and processes.
(Further details can be found in (Polke et al., 2023;
Yue and Wang, 2022; Morgan et al., 2021)).
In all the above-mentioned research, one of the
main concerns during the solution development is
changes in the data exposed during data-driven model
Fathi, K., Sadurski, M., Waskow, S., Kleinert, T. and van de Venn, H. W.
Towards Industry 5.0: AAS/MLOps-Driven Model Maintenance for Data-Centric Production.
DOI: 10.5220/0013716300003982
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 22nd International Conference on Informatics in Control, Automation and Robotics (ICINCO 2025) - Volume 2, pages 495-502
ISBN: 978-989-758-770-2; ISSN: 2184-2809
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
495

training compared to model deployment and testing
data. This discrepancy between the two data distribu-
tions, and also changes in the data in general, is an
active research area in the field of Machine Learning
Operations (MLOps).
As the matter of fact, MLOps aims to facilitate the
efficient deployment and serving of machine learning
(ML) models in production which consequently also
constantly improves the business activities (Haviv and
Gift, 2023). In that regard, for tracking changes in the
production line and adapting the DAs, it is crucial to
version the data, models and also the code. Doing
so makes the entire pipeline repeatable and traceable
for performance evaluation and comparison (Faubel
et al., 2023). To this regards, we aim to answer the
following research question (RQ) concerning model
serving:
RQ1: How can an orchestration tool like MLRun
efficiently
1
track experiments, data, and models in
artifact form for knowledge sharing in data-centric
production?
In what follows, we use predictive maintenance
(PdM) as an example to explain the deployment re-
lated problems in industry. Nonetheless, the pro-
posed architecture can be generalized to any other
data-driven solution such as zero defect manufactur-
ing (ZDM), C O
2
emission tracking (CO2-T), etc.
In the field of PdM, as an important concept in
Industry 4.0, research dealing with MLOps tries to
ensure the performance of deployed solution despite
the changes in the production line. Such solutions
suggest to have triggers for retraining the data-driven
model either given a drop in the accuracy, or other
performance indicators (Raj et al., 2021; Fathi et al.,
2024b), or instead doing it periodically (Oluyisola
et al., 2020; Shakhovska and Campos, 2024).
There are several issues for model maintenance
using the aforementioned approaches. Firstly, the
lack of annotated data in PdM is a well-known but still
unresolved issue. Thus, accuracy-based triggers are
inefficient, as model adaptation occurs too late—only
after downtime has already occurred. Secondly, these
approaches neglect the operator’s domain knowledge
for maintaining a physical asset which is counter pro-
ductive. Numerous successful production lines have
operators which have years of experience working
with different production assets. Therefore, it is of
utmost importance to integrate their knowledge into
the MLOps design and deployment cycle. Lastly and
most importantly, high model accuracy does not au-
1
Efficient in terms of reducing excessive overhead gen-
eration and preventing bursts of excessive information.
tomatically translate into more profit, increased sus-
tainability, etc., for the company and rather the im-
pact of the deployed model should be monitored and
evaluated by the plant or asset operator (Haviv and
Gift, 2023).
Unfortunately, MLOps studies trying to include
the business side’s opinion and/or expertise into the
design and deployment, when at all, merely con-
sider their expertise only in the initial concept devel-
opment (Faubel et al., 2023; Colombi et al., 2024;
Kreuzberger et al., 2023; Salama et al., 2021). How-
ever, we believe a more effective solution would be
to integrate the asset operator in the maintenance of
the PdM models as well. This will allow the op-
erator to make requests to the ML engineer directly
(Fathi et al., 2024a). Fig. 1 shows our proposal for
this integration which is heavily based on the work
from Faubel et al. (Faubel et al., 2023). The arrows
in this figure, indicate the actions performed by the
roles within the dashed rectangles to reach the next
step. Furthermore, each dashed rectangle describes
the contributions of these roles in the corresponding
MLOps step. With this solution we aim to answer the
following RQ:
RQ2: How can domain knowledge from the shop
floor be effectively
2
integrated with artifacts gener-
ated in data-driven architectures?
In that regard, another important improvement
in our proposed solution for maintaining data-driven
models is the integration of different required roles.
As a generic and high-level solution, instead of break-
ing down the roles needed for developing and deploy-
ing a data-driven solution given MLOps requirements
(Colombi et al., 2024; Kreuzberger et al., 2023),
namely data scientist, data engineer, etc., we divide
them in the following ones (refer to Section 3 for more
details):
1. Operator
2. ML engineer
3. Ecosystem manager
The main reason for defining the roles as suggested
above is effective information sharing between dif-
ferent actors working in a company on a specific prod-
uct or a production asset (Milicic et al., 2016).
After integrating domain knowledge in the pro-
posed solution and also defining roles the last and
most important step would be to choose a represen-
2
Effective in terms of providing added value and se-
mantic meaning (Zhou et al., 2023) to different parts of a
pipeline.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
496
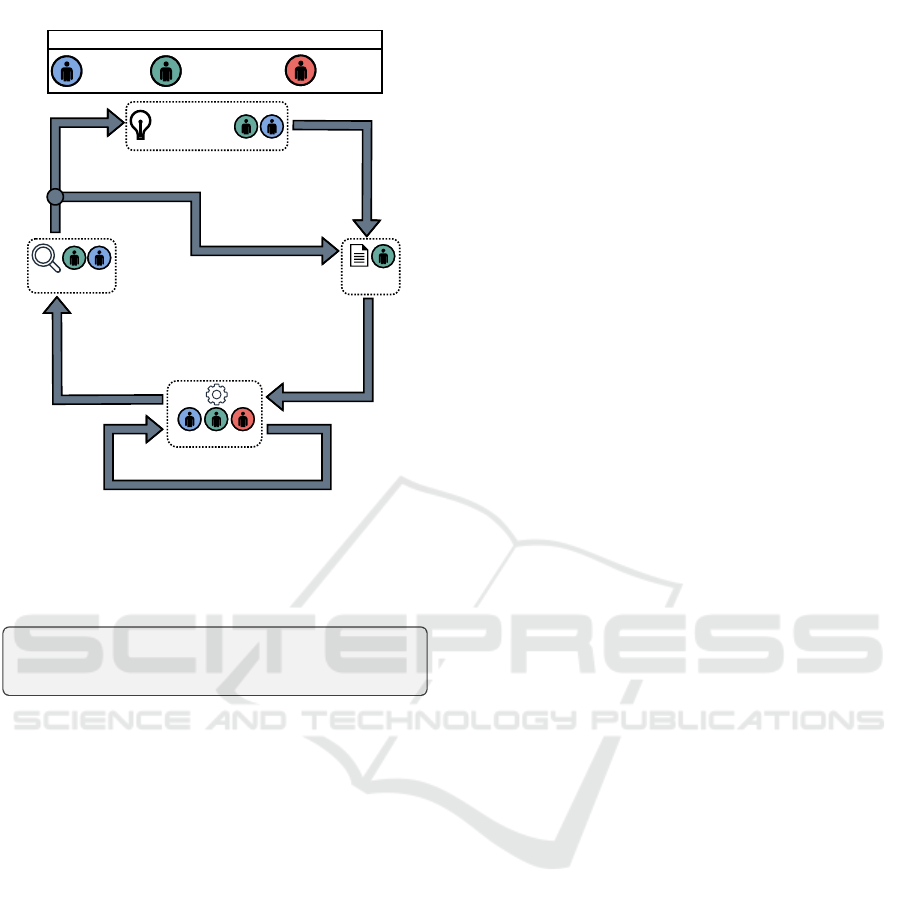
Business idea
(problem)
High level
architecure
Monitoring
Business value to
machine learning
problem conversion
Machine learning
solution preparation,
training, testing and
deployment
Integrating the
machine learning
model in the
existing process
Feedback
Deployed model
Updating the model given
operator needs/domain knowledge
Machine learning
Engineer
Ecosystem
Manager
Operator
Roles
Figure 1: Overview of the DA maintenance cycle (refer to
Section 3 for detailed role descriptions).
tation for sharing information between different ac-
tors. This leads to the following RQ:
RQ3: How can information from data-driven solu-
tions be structured in an industry-approved format?
For addressing this issue, we utilize the Asset Ad-
ministration Shell (AAS) (Wei et al., 2019) as a stan-
dardized digital representation of digital and physical
assets in industry.
These steps will enable successful product life cy-
cle management in industrial use cases, where prod-
uct is the deployed DA in smart factories.
Lastly, as a closing statement of this section, by
highlighting the roles in the proposed ecosystem, we
aim to shift the current model-driven design towards
a product-oriented one as suggested by Kreuzberger
et al. (Kreuzberger et al., 2023). Only then it is pos-
sible to implement the concepts required by Industry
5.0 for bringing human in model maintenance loop
and increasing the acceptance of models in the mod-
ern and complex industrial plants. As the final goal
of this paper we hope to pave the way for a balance
between automatization and collaboration as intro-
duced by (Ruppert et al., 2022; Sabuncu and Bilge-
han, 2025).
As a short summary, our main contributions are
thus 3-fold. We:
1. pinpoint the importance of efficient artifact gener-
ation,
2. provide a systematic way for coupling informa-
tion from shopfloor to the developed and deployed
DAs (and their artifacts),
3. propose an industry approved system to handle ar-
tifacts from MLRun.
2 PROBLEM SETTING AND
FOCUS AREA
During the development of this solution, we focused
heavily on two distinctive aspects of production lines.
Namely, the lack of (annotated) historical data and
therefore the importance of human feedback and also
the overwhelming number of physical assets to be
monitored. The former results in excessive number
of (experimental) implementations with their corre-
sponding artifacts containing data, metadata, models,
etc., which need to be versioned for improved trace-
ability. The later further exacerbates the problem by
extending this issue across multiple physical assets,
whose performance is decisive in the productivity of
the production line.
On top of that, various aspects of the production
potentially require dedicated models for monitoring
for enhancing their performance. These aspects in-
clude but are not limited to PdM, ZDM, CO2-T, etc.,
which we collectively refer to as tasks in this paper.
As a result, these monitoring systems will also lead
to more artifact generation from the solution. Fig. 2,
from a machine and not component point of view,
shows how the number of artifacts can exponentially
grow given the scale of the production line.
We aim to highlight the pivotal role of managing
data and metadata generated by DAs. In fact, in In-
dustry 4.0/5.0, physical assets are not the only type of
assets that firstly produce data and secondly require
maintenance in response to changes occurring in the
production line.
In addition, given the current digitalization state
of different industries, our observations are mostly in
Switzerland, it is rarely the case that the available data
is annotated for solving the optimization problem at
hand. Therefore, the heavily focused automation in
MLOps for model training and serving, e.g., using
AutoML, becomes obsolete. Please refer to (Salama
et al., 2021; Colombi et al., 2024; Cerquitelli et al.,
2021). This characteristic highlights the importance
of implementation and artifact tracking and also hu-
man feedback for ensuring the performance of the
system. After defining the boundaries for the prob-
lem at hand, in what follows, the architecture of the
proposed method is introduced.
Towards Industry 5.0: AAS/MLOps-Driven Model Maintenance for Data-Centric Production
497
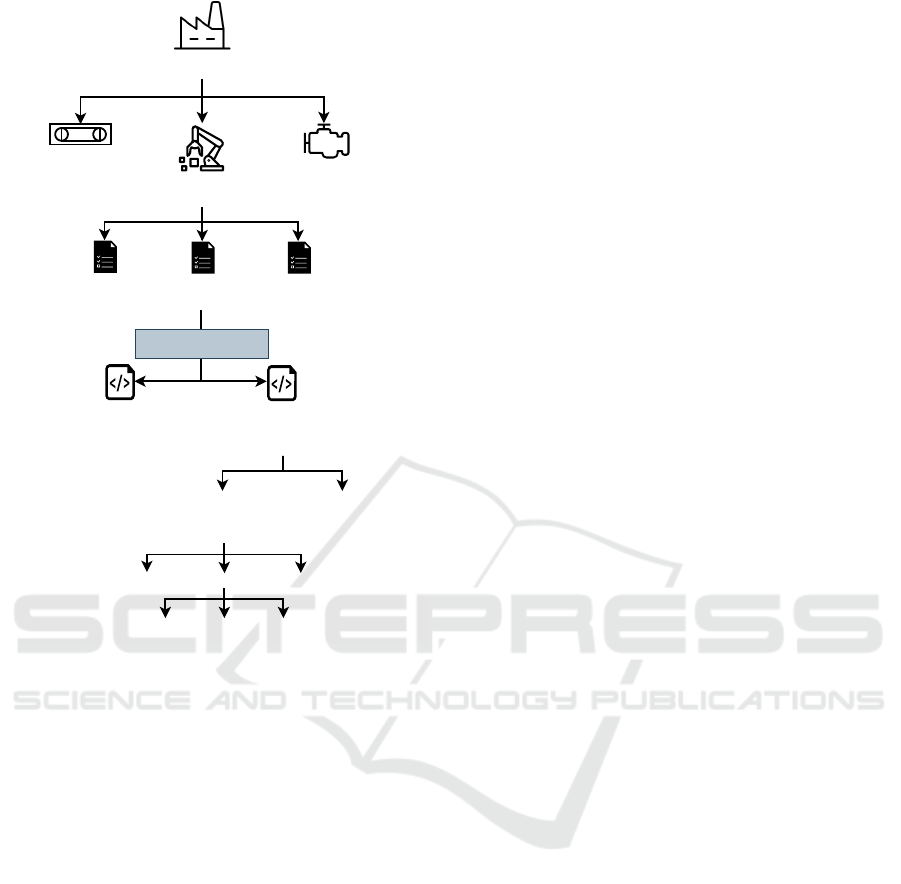
Data-centric
production line
Production asset 2
(physical asset)
Production asset 1
(physical asset)
Production asset 3
(physical asset)
Task 1:
ZDM
Task 2:
PdM
Task 3:
CO2-T
Digital asset 1:
PdM for production
procedure A
Digital asset 2:
PdM for production
procedure B
Implementation 1:
physical asset running at
90% capacity
(e.g., day shift)
Implementation 2:
physical asset running at
60% capacity
(e.g., night shift)
Scripts Artifacts
Metadata
Report Data Pipeline
models
ML engineer translates
tasks into digital assets
Figure 2: Exponential growth in artifact generation in data-
centric production.
3 SYSTEM ARCHITECTURE
In industrial settings, model verification and deploy-
ment are inherently experimental due to the scarcity
of annotated data. High model accuracy does not nec-
essarily correlate with improved productivity or sus-
tainability, making human involvement critical.
To address these challenges, our proposed system
provides a foundation for generating and archiving
DA implementations, along with corresponding infor-
mation from human operators. This information pro-
vides sentiment for the generated DA. This in the long
run facilitates DA tracking and matching developed
for different physical assets or tasks. Our proposed
architecture (Fig. 3) integrates three key roles:
1. Operator: Defines tasks and provides feedback.
2. ML Engineer: Develops and maintains DAs.
3. Ecosystem Manager: Oversees data aggregation
and solution inspection.
The system workflow is as follows. Operators define
tasks requiring DA development. Afterwards, ML en-
gineers develop solutions and generate artifacts using
MLRun.
Thereafter, the generated artifacts (data, metadata,
models and their hyperparameters, etc.) are encap-
sulated within AAS submodel instances along with
the task description. These artifacts contain the min-
imum information required to recreate the entire
pipeline for the solution. In fact, despite the con-
venience of tools like MLRun and MLFlow, exces-
sive artifact generation can make it difficult to orga-
nize and use this information effectively for decision-
making. Lastly, the ecosystem manager inspects and
manages DAs across production lines. Ultimately,
this structure ensures traceability, effective feedback
integration, and reduced model development costs.
For adapting and/or improving the deployed DA,
the operator and the ecosystem manager can actively
provide feedback to the ML engineer for further ad-
justment of the DA leading to new instances from
these DAs in the database. Human agency is a key
design choice in the proposed system. It is therefore
assumed that provided feedback is deliberate, accu-
rate and aligns with production requirements.
In what follows, our proposed structure for gen-
erating DA implementations in ABB Schaffhausen is
provided. Please note that this structure is referred to
as Pre-Prime Ecosystem.
4 INDUSTRIAL USE CASE: ABB
PLANT
The Pre-Prime ecosystem developed for ABB
Schaffhausen AG is shown in Fig. 4. Once the op-
erator defines a new task for the ML engineer, they
can use the provided Jupyter notebooks to work on
different parts of the ML project. Given the require-
ments from ABB, we divided these Jupyter notebooks
into the following:
1. Data preparation and preprocessing: contains
all the operations needed for making the data vec-
tor ready for different algorithms.
2. Model training and validation: contains all the
steps to go from an idea for solving the task to a
verified and functional model(s).
3. Model serving: contains the logic for running the
model and integrating it into the existing IT in-
frastructure of the target company.
However, these can change given the needs and/or
limitations.
In addition, the parameters, hyperparameters, etc.,
impacting the behavior of the implementation are also
stored separately as a metadata file. Once the solution
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
498

ML Engineer
Ecosystem Manager
Defines a new task /
Provides feedback
Generating
AAS submodel
instance
Digital asset
Creates/
Updates
Storing encapsulated information
(context pairs of task and artifacts)
Database
Inspects instances
Operator
Generating
artifacts
Figure 3: System overview.
Pre-Prime Ecosystem instance
powered by:
Jupyter notebook(s)
Operator
ML Engineer
Ecosystem Manager
Defines a new task /
Provides feedback
Script(s)
metadata
01
Influences
Exports
Pipeline Model(s)
Reports
Generates
Sends output from
digital asset
api
Updates
Calls
Connects
and reads
Data
01
Database(s)
Sends signals
Physical asset(s)
User interface
Provides input
Sends operator input
Provides insights
into physical assests
Inspects instances
Figure 4: Overview of Pre-Prime ecosystem. Based on feedback from the ecosystem manager or operator, the ML engineer
designs a new DA in Jupyter notebooks, generating updated scripts, models, reports, and data. These newly created artifacts
are then integrated into the API during model serving to meet shopfloor requirements.
has reached the maturity level to be tested in the pro-
duction line, scripts, models, reports and data (specifi-
cally used for model training, testing and verification)
are extracted as a form of artifact. For the sake of
traceability, the data before and after being vectorized
are stored separately, so that in case of erroneous pre-
dictions, the pipeline can be debugged easier. This
separation is also in accordance with the demands of
the EU AI Act for safety critical systems (ISACA,
2024; Dorigo et al., 2025).
Later on, the designated API uses these artifacts to
serve the operator and the rest of the implementation
is frozen. The API basically contains all the endpoints
for its different functionalities. Thereafter, in case the
performance of the DA implementation is not accept-
able, given the feedback from the operator and/or the
ecosystem manager, the ML engineer can go thorough
the development cycle and update the solution.
5 INTEGRATION WITH AAS
For having the most efficient and easily standardiz-
able solution for industry, in this section we demon-
strates how a data-centric production lines can lever-
age various official AAS submodels to optimize its
operations.
As the main motivation, we aim to use the avail-
able AAS submodels for different physical and DAs
to ease communication between them. As an ex-
ample, an OEM provides submodels for their assets,
which as a result help different customers access in-
formation from the assets in a unified way.
As shown in Fig. 5, the information about the
physical asset is contained within the digital name-
plate. This information is useful when the operator is
defining a new task for which a DA is to be imple-
mented.
Furthermore, for ensuring structural and
schematic consistency of the data, we propose
to use the time series data submodel. In fact, this
submodel can also be used to detect potential data
shifts impacting DA which are developed later.
In addition, the (data-driven) DAs are in accor-
dance with the AI submodel
3
to ensure all the re-
quired information for model development, deploy-
ment and serving are contained.
3
As of the writing this paper, this submodel is not yet
published.
Towards Industry 5.0: AAS/MLOps-Driven Model Maintenance for Data-Centric Production
499
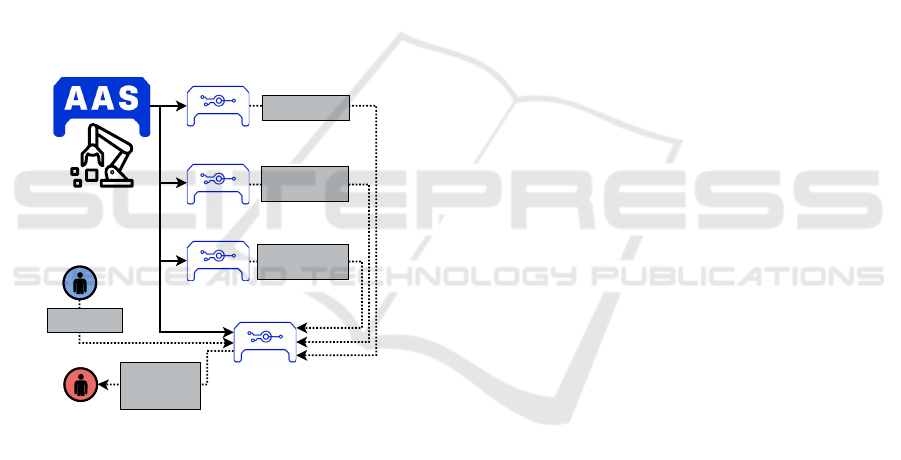
As a side note, the data-driven DAs can potentially
benefit from other submodels as well. As of the writ-
ing this paper, these submodels include but are not
limited to Carbon footprint, Predictive maintenance,
etc. In fact, these submodels help the ML engineer
incorporate the required domain knowledge, enhanc-
ing traceability and making troubleshooting easier for
the solution.
Lastly, all these submodel instances along with
their artifacts are encapsulated into the data-driven
model maintenance submodel instance. In addition,
the task description from the operator is also included
in this submodel to provide the required sentiment to
the implementation. The ecosystem manager then by
looking at different instances of our proposed sub-
model can have all the required information for so-
lution inspection, model and data aggregation, etc.
Moreover, information from this submodel then can
be filtered according to different access permissions
of different roles, adding even more value to this sub-
model.
Physical asset
Provides physical
asset information
Submodel:
Digital nameplate
Provides physical
asset signal
readings
Submodel:
Timeseries
Provides digital
assets for different
tasks
Submodel:
AI model
Provides insight
about tasks,
digital and
physical assets
Submodel:
Data-driven model
maintenance
Operator
Provides
task description
Ecosystem
Manager
Figure 5: Physical and DA management via human-in-the-
loop AAS.
6 DISCUSSION
In this paper, the foundation required for DA life-
cycle management was presented. Such a solution
can later be adapted for creating digital product pass
(Psarommatis and May, 2024) for DAs in an Indus-
try 4.0/5.0 setting. Furthermore, with the increasing
use of advanced models, such as large language mod-
els (LLMs), traceability becomes a vital characteris-
tic of AI-powered solutions. In fact, by generating
controlled artifacts, it is possible to pave the way for
trustworthy AI in industry. This is facilitated by the
availability of information and logs for model behav-
ior inspection in case of a system failure. As an addi-
tional benefit of this architecture, it is also possible to
track the CO
2
emissions of a given DA, which is very
relevant for resource intensive solutions employing
LLMs. As an example, it can be inspected whether
an LLM-based sustainability model emits more CO
2
than it can optimize or not. Nonetheless, since all de-
cisions regarding different DA implementations rely
on information from the proposed architecture, au-
tomating instance-specific verification remains a chal-
lenge for future work. Furthermore, for future work
will need to explore LLM-assisted DA creation, inte-
grating operator-defined tasks into an AutoML work-
flow for task-specific model generation.
7 CONCLUSION
In this paper an architecture for encapsulating in-
formation from different DA implementations along
with their designated tasks was introduced. We aimed
to point out the fact that, the MLOps cycle is a small
part of the entire solution development given the over-
whelming number of assets and experimental solu-
tions developed for them. Furthermore, we discussed
how important it is to prune the artifact generation
from different parts of the DA to keep it traceable
for debugging as well as data and model aggrega-
tion. In addition, we introduced a human-in-the-loop
design for AAS creation of a physical asset, aiming
for maximized operator involvement in the designing
process of different DAs. For future work, we aim
to feed prompts containing operator generated tasks
with corresponding solutions from the model mainte-
nance submodel to train a LLM for creating new DAs
for new tasks. The ultimate goal is to incorporate task
descriptions into the AutoML solution development
process, making it more relevant to real-world indus-
try use cases.
ACKNOWLEDGMENT
The authors of this paper would like to express their
deep sense of gratitude to SMC Schweiz AG, espe-
cially Mr. Alessandro Grizzetti, for their unceasing
assistance in promoting Competence Centre for Au-
tomation and Digitalisation among different industrial
partners in Europe. Additionally, we extend our grat-
itude to the amazing team at ABB OEE team (Marko
Barutcu and Patrick Henzi) for their invaluable sup-
port in ensuring the success of this project.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
500

REFERENCES
Brettel, M., Klein, M., and Friederichsen, N. (2016). The
relevance of manufacturing flexibility in the context of
industrie 4.0. Procedia Cirp, 41:105–110.
Cerquitelli, T., Nikolakis, N., Morra, L., Bellagarda, A.,
Orlando, M., Salokangas, R., Saarela, O., Hietala, J.,
Kaarmila, P., and Macii, E. (2021). Data-driven pre-
dictive maintenance: A methodology primer. Predic-
tive Maintenance in Smart Factories: Architectures,
Methodologies, and Use-cases, pages 39–73.
Colombi, L., Gilli, A., Dahdal, S., Boleac, I., Tortonesi,
M., Stefanelli, C., and Vignoli, M. (2024). A ma-
chine learning operations platform for streamlined
model serving in industry 5.0. In NOMS 2024-2024
IEEE Network Operations and Management Sympo-
sium, pages 1–6. IEEE.
Dorigo, T., Brown, G. D., Casonato, C., Cerd
`
a, A., Cia-
rrochi, J., Da Lio, M., D’souza, N., Gauger, N. R.,
Hayes, S. C., Hofmann, S. G., et al. (2025). Artifi-
cial intelligence in science and society: The vision of
usern. IEEe Access.
Fathi, K., Kleinert, T., and van de Venn, H. W. (2024a).
Trustworthy machine learning operations for predic-
tive maintenance solutions. In PHM Society European
Conference, volume 8, pages 4–4.
Fathi, K., Ristin, M., Sadurski, M., Kleinert, T., and van de
Venn, H. W. (2024b). Detection of novel asset failures
in predictive maintenance using classifier certainty. In
2024 32nd Mediterranean Conference on Control and
Automation (MED), pages 50–56. IEEE.
Faubel, L., Schmid, K., and Eichelberger, H. (2023). Mlops
challenges in industry 4.0. SN Computer Science,
4(6):828.
Ghobakhloo, M. (2020). Industry 4.0, digitization, and op-
portunities for sustainability. Journal of cleaner pro-
duction, 252:119869.
Haviv, Y. and Gift, N. (2023). Implementing MLOps in the
Enterprise. ” O’Reilly Media, Inc.”.
Huang, Y., Dhouib, S., and Malenfant, J. (2021). Aas
capability-based operation and engineering of flexible
production lines. In 2021 26th IEEE International
Conference on Emerging Technologies and Factory
Automation (ETFA), pages 01–04. IEEE.
ISACA (2024). Understanding the eu ai act: Requirements
and next steps. Accessed: 2025-02-06.
Kozma, D., Varga, P., and Larrinaga, F. (2019). Data-
driven workflow management by utilising bpmn and
cpn in iiot systems with the arrowhead framework. In
2019 24th IEEE International Conference on Emerg-
ing Technologies and Factory Automation (ETFA),
pages 385–392. IEEE.
Kreuzberger, D., K
¨
uhl, N., and Hirschl, S. (2023). Ma-
chine learning operations (mlops): Overview, defini-
tion, and architecture. IEEE access, 11:31866–31879.
Milicic, A., Kiritsis, D., and Efendioglu, N. (2016). From
english to rdf-a meta-modelling approach for predic-
tive maintenance knowledge base design. In Advances
in Production Management Systems. Initiatives for a
Sustainable World: IFIP WG 5.7 International Con-
ference, APMS 2016, Iguassu Falls, Brazil, September
3-7, 2016, Revised Selected Papers, pages 214–224.
Springer.
Morgan, J., Halton, M., Qiao, Y., and Breslin, J. G. (2021).
Industry 4.0 smart reconfigurable manufacturing ma-
chines. Journal of Manufacturing Systems, 59:481–
506.
M
¨
uller, M., M
¨
uller, T., Ashtari Talkhestani, B., Marks,
P., Jazdi, N., and Weyrich, M. (2021a). Industrial
autonomous systems: a survey on definitions, char-
acteristics and abilities. at-Automatisierungstechnik,
69(1):3–13.
M
¨
uller, T., Jazdi, N., Schmidt, J.-P., and Weyrich, M.
(2021b). Cyber-physical production systems: en-
hancement with a self-organized reconfiguration man-
agement. Procedia CIRP, 99:549–554.
M
¨
uller, T., Lindemann, B., Jung, T., Jazdi, N., and Weyrich,
M. (2021c). Enhancing an intelligent digital twin
with a self-organized reconfiguration management
based on adaptive process models. Procedia CIRP,
104:786–791.
Oluyisola, O. E., Sgarbossa, F., and Strandhagen, J. O.
(2020). Smart production planning and control: Con-
cept, use-cases and sustainability implications. Sus-
tainability, 12(9):3791.
Polke, D., Surjana, A., Diepers, F., Ahle, E., and S
¨
offker,
D. (2023). Development of a modular automation
framework for data-driven modeling and optimization
of coating formulations. In 2023 IEEE 28th Interna-
tional Conference on Emerging Technologies and Fac-
tory Automation (ETFA), pages 1–8. IEEE.
Psarommatis, F. and May, G. (2024). Digital product pass-
port: A pathway to circularity and sustainability in
modern manufacturing. Sustainability, 16(1):396.
Raj, E., Buffoni, D., Westerlund, M., and Ahola, K. (2021).
Edge mlops: An automation framework for aiot ap-
plications. In 2021 IEEE International Conference on
Cloud Engineering (IC2E), pages 191–200. IEEE.
Ruppert, T., L
¨
ocklin, A., Romero, D., and Abonyi, J.
(2022). Intelligent collaborative manufacturing space
for augmenting human workers in semi-automated
manufacturing systems. In 2022 IEEE 27th Interna-
tional Conference on Emerging Technologies and Fac-
tory Automation (ETFA), pages 1–7. IEEE.
Sabuncu,
¨
O. and Bilgehan, B. (2025). Human-centric iot-
driven digital twins in predictive maintenance for op-
timizing industry 5.0. Journal of Metaverse, 5(1):64–
72.
Salama, K., Kazmierczak, J., and Schut, D. (2021). Prac-
titioners guide to mlops: A framework for continuous
delivery and automation of machine learning. Google
Could White paper.
Shakhovska, N. and Campos, J. (2024). Predictive mainte-
nance for wind turbine bearings: An mlops approach
with the diafs machine learning model.
Wei, K., Sun, J. Z., and Liu, R. J. (2019). A review of as-
set administration shell. In 2019 IEEE International
Conference on Industrial Engineering and Engineer-
ing Management (IEEM), pages 1460–1465.
Towards Industry 5.0: AAS/MLOps-Driven Model Maintenance for Data-Centric Production
501

Xia, Y., Shenoy, M., Jazdi, N., and Weyrich, M. (2023).
Towards autonomous system: flexible modular pro-
duction system enhanced with large language model
agents. In 2023 IEEE 28th International Conference
on Emerging Technologies and Factory Automation
(ETFA), pages 1–8. IEEE.
Yue, F. and Wang, Y. (2022). Cross-domain fault diagno-
sis via meta-learning-based domain generalization. In
2022 IEEE 18th International Conference on Automa-
tion Science and Engineering (CASE), pages 1826–
1832. IEEE.
Zhou, B., Nikolov, N., Zheng, Z., Luo, X., Savkovic, O.,
Roman, D., Soylu, A., and Kharlamov, E. (2023).
Scaling data science solutions with semantics and ma-
chine learning: Bosch case. In International Semantic
Web Conference, pages 380–399. Springer.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
502
