
Peer-to-Peer Federated Learning with Trusted Data Sharing for Non-IID
Mitigation
Mahran Jazi
a
and Irad Ben-Gal
b
Department of Industrial Engineering, Tel Aviv University, Tel Aviv, Israel
Keywords:
Federated Learning, Data Sharing, Non-IID Data, Decentralized Machine Learning, Edge Intelligence,
Distributed Optimization.
Abstract:
Collaboration between edge devices without a central server defines the foundation of Peer-to-Peer Feder-
ated Learning (P2P FL), a decentralized approach to machine learning that preserves user privacy. However,
P2P FL faces significant challenges when data distributions across clients are non-independent and identically
distributed (non-IID), which can severely degrade learning performance. In this work, we propose an enhance-
ment to P2P FL through direct data sharing between trusted peers, such as friends, colleagues, or collaborators,
where each client shares a small, controlled portion of its local dataset with a selected set of neighbors. While
this data-sharing mechanism enhances consistency in learning and improves model performance across the
decentralized network, it introduces a trade-off between privacy and performance, as limited data sharing may
increase privacy risks. To mitigate these risks, our approach assumes a trusted peer-to-peer network and avoids
reliance on any central authority. We evaluate our approach using standard datasets (MNIST, CIFAR-10, and
CIFAR-100) and models, including logistic regression, multilayer perceptron, convolutional neural networks
(CNNs), and DenseNet-121. The results demonstrate that even modest amounts of peer data sharing signif-
icantly improve performance in non-identically distributed (non-IID) settings, offering a simple yet effective
strategy to address the challenges of decentralized learning in peer-to-peer federated learning (P2P FL) sys-
tems.
1 INTRODUCTION
Edge devices such as smartphones, IoT sensors, and
embedded systems increasingly serve as the primary
source of private user data. These devices collect and
process sensitive information, from health metrics to
personal media, and support applications powered by
machine learning (ML). Although traditional machine
learning (ML) pipelines rely on aggregating data on
centralized servers, this architecture raises significant
concerns about user privacy, communication over-
head, and system scalability (McMahan et al., 2017;
Kone
ˇ
cn
`
y et al., 2015).
Federated Learning (FL) is recognized as a
privacy-preserving alternative to traditional central-
ized ML, enabling distributed training of models
while clients retain their data locally and only share
model updates (McMahan et al., 2017). This ap-
proach mitigates privacy concerns and reduces the
need for transferring raw data to centralized servers.
a
https://orcid.org/0000-0001-6432-3800
b
https://orcid.org/0000-0003-2411-5518
This architecture introduces challenges such as com-
munication bottlenecks, system scalability issues, and
a single point of failure, which can hinder the robust-
ness and efficiency of FL systems.
To overcome these limitations, Peer-to-Peer Fed-
erated Learning (P2P FL) has gained traction. In
P2P FL, clients collaborate over a decentralized net-
work without a central aggregator(Lalitha et al., 2019;
Heged
¨
us et al., 2022; Tang et al., 2018). Clients
share and update their models through local interac-
tions with neighbors, forming communication graphs
such as rings, meshes, or random networks. This de-
centralized setup enhances fault tolerance and elimi-
nates reliance on a central authority, making it suit-
able for dynamic or large-scale systems, such as ad
hoc networks or IoT environments.
However, a core challenge remains: heterogene-
ity of the data. In real-world scenarios, clients typ-
ically possess non-independent and identically dis-
tributed (non-IID) data due to their unique usage pat-
terns, local contexts, or environments (Zhao et al.,
2018; Kairouz et al., 2019). This heterogeneity can
248
Jazi, M. and Ben-Gal, I.
Peer-to-Peer Federated Learning with Trusted Data Sharing for Non-IID Mitigation.
DOI: 10.5220/0013685100004000
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 17th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2025) - Volume 1: KDIR, pages 248-256
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
lead to divergent local model updates, degraded con-
vergence, and suboptimal global performance.
To address this, we propose a novel enhance-
ment to P2P FL: data sharing between trusted peers.
In many practical scenarios, such as those involv-
ing friends, colleagues, or family, privacy concerns
are often minimized due to social trust, and data
sharing is already common (e.g., through messaging
apps, shared documents, or collaborative platforms).
Inspired by this natural behavior, we enable peers
to share a small, controlled portion of their private
datasets with their neighbors. This peer-level data
sharing introduces beneficial overlap in local train-
ing sets, smoothing the non-IID effects and improving
model convergence.
While the core philosophy of Federated Learning
(FL) avoids sharing raw data to preserve privacy, our
work explores a controlled extension of Peer-to-Peer
FL (P2P FL) for contexts where limited data shar-
ing is acceptable. Specifically, we assume settings
such as small research collaborations, corporate de-
partments, or circles of peers with established confi-
dentiality agreements, where participants are willing
to share a small, predefined subset of their data with
trusted neighbors.
We fully acknowledge that this assumption does
not hold in all FL scenarios and that any sharing of
raw data introduces privacy risks. Rather than claim-
ing zero privacy cost, we position our approach as a
trade-off between improved learning performance in
highly non-IID environments and a consciously ac-
cepted level of privacy risk in domains with existing
trust relationships. This approach is not intended as a
general replacement for FL, but as a targeted strategy
for specific, privacy-aligned networks.
In our design, data exchange is limited to such
trusted peers, where the benefits of improved per-
formance are considered to outweigh the controlled
risks. We argue that this assumption is both realis-
tic and practical in modern edge-computing environ-
ments involving social, collaborative, or co-located
devices. Furthermore, we investigate how P2P FL
performs when users generate non-IID data but share
a small portion with peers, an environment where ad-
versarial threats are less prevalent and privacy or se-
curity concerns are comparatively minimal (Lyu et al.,
2022; Chen et al., 2022; Liu et al., 2022; Jazi and
Ben-Gal, 2024; Zang et al., 2024).
The remainder of this paper is organized as fol-
lows: Section 2 discusses the contributions of this
work. Section 3 provides a detailed review of the
related work in the domain. Section 4 presents the
problem formulation and its theoretical framework.
Section 5 introduces and explains the proposed peer-
level data sharing mechanism and the P2P algorithm.
Section 6 highlights the experimental results and their
analysis, section 7 delves into non-IID partitioning in
P2P-FL, exploring its implications on the proposed
methodology. Finally, Section 8 concludes the paper,
summarizing the contributions and providing direc-
tions for future research.
2 CONTRIBUTIONS
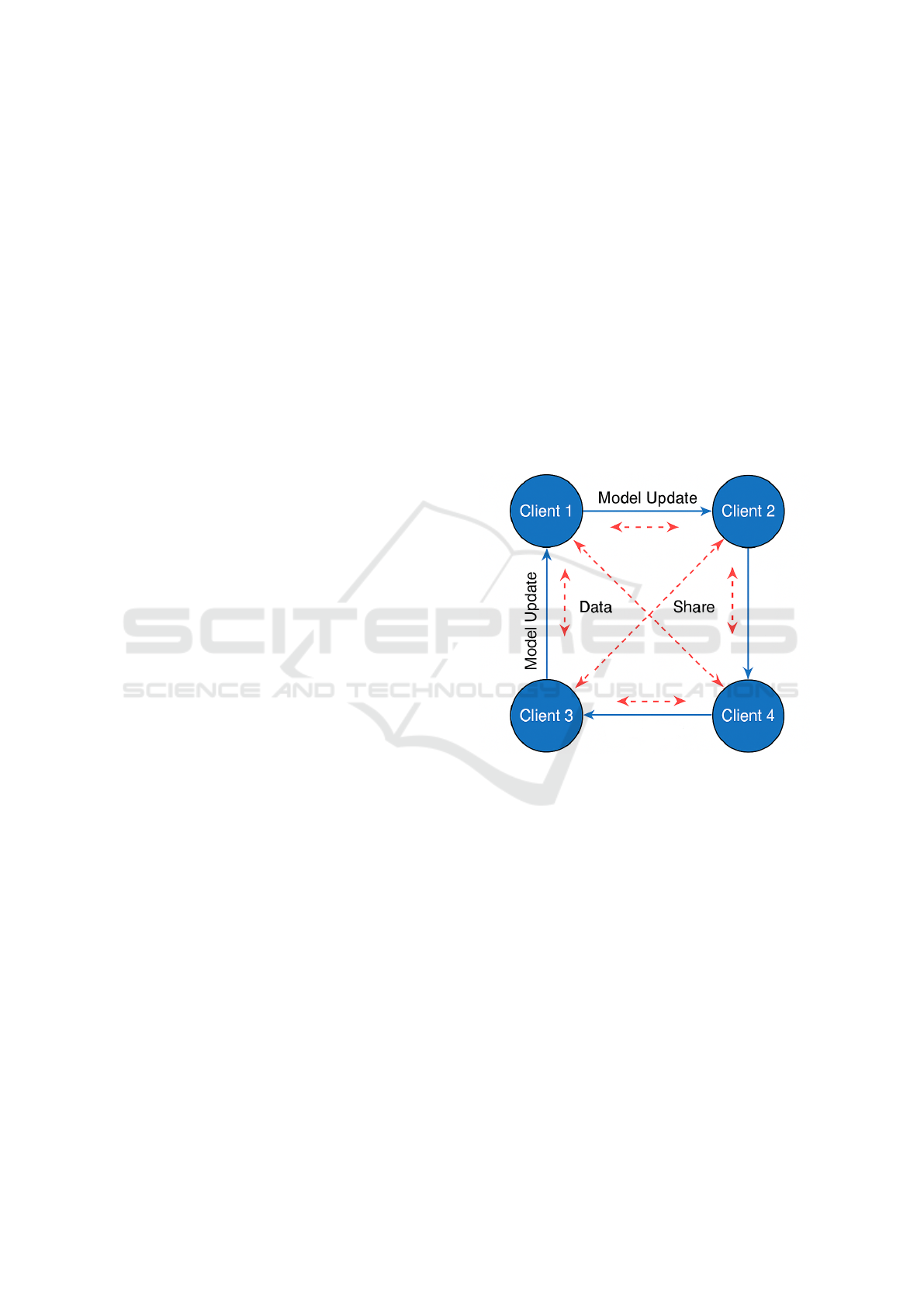
We propose trusted peer-level data sharing as a sim-
ple and efficient technique to boost the performance
of peer-to-peer federated learning (P2P FL), as illus-
trated in Figure 1. Our findings apply to two distinct
scenarios: active and passive data sharing among de-
centralized clients.
Figure 1: Illustration of Peer-to-Peer Federated Learning
with Data Sharing. Clients exchange model updates with
neighbors in a decentralized fashion (solid blue arrows)
while optionally sharing a portion of their data with trusted
peers (dashed red arrows) to mitigate non-IID effects.
In active data sharing, clients are explicitly en-
couraged to share a portion of their data with a se-
lected set of trusted neighbors within the communica-
tion graph. While this involves a partial relaxation of
local data privacy, it is essential to note that no data is
transmitted to any centralized server; data instead is
shared only between peers with pre-established trust
relationships (e.g., friends, family, or colleagues). In
practical implementations, this can be supported by
device-level applications that enable users to share
data with specific peers selectively. The dynamics of
such interactions can be further modeled using incen-
tive mechanisms or game-theoretic frameworks (Bu-
ratto et al., 2024).
In passive data sharing, we assume that data ex-
Peer-to-Peer Federated Learning with Trusted Data Sharing for Non-IID Mitigation
249

change naturally exists within certain peer groups
due to ongoing digital interactions, such as shared
cloud folders, group chats, or collaborative devices.
When P2P FL is executed over such socially con-
nected clients, the implicit overlap in their datasets
results in improved data diversity across the network.
Our results demonstrate that natural groupings can
significantly enhance model performance, even when
the total number of data samples per client remains
constant.
Importantly, our experiments abstract away from
the specific sharing mechanism (active or passive) and
instead evaluate the effect of sharing varying percent-
ages of data among clients. We demonstrate that peer-
level data sharing improves model accuracy and con-
vergence under non-IID data distributions. Moreover,
we find that a relatively small fraction of shared data
(e.g., 20,40%) is sufficient to yield near-optimal im-
provements.
The principal finding of this study is, therefore,
that Running decentralized FL on socially connected
peers who share data either actively or passively out-
performs training on arbitrarily grouped clients, even
under identical data volumes.
3 RELATED WORK
Federated Learning (FL) has emerged as a leading
approach to enable collaborative machine learning
across multiple clients while preserving data privacy
(McMahan et al., 2017). In its canonical form, FL re-
lies on a centralized server that orchestrates commu-
nication rounds and aggregates model updates from
clients, as exemplified by the widely-used FedAvg al-
gorithm (McMahan et al., 2016). This architecture,
however, introduces potential bottlenecks and single
points of failure, raising concerns over scalability, ro-
bustness, and trust in large-scale and dynamic envi-
ronments.
To address these limitations, decentralized FL ar-
chitectures have been proposed, where clients inter-
act directly with each other in a peer-to-peer (P2P)
manner, thereby removing the dependency on a cen-
tral aggregator (Lalitha et al., 2019; Heged
¨
us et al.,
2022; Tang et al., 2018). A popular and effective
communication paradigm in this domain is the use
of gossip-based protocols, where clients iteratively
exchange and average model parameters with ran-
domly selected neighbors (Boyd et al., 2006). Gos-
sip algorithms enhance scalability, fault tolerance,
and privacy by leveraging localized communication
and avoiding central coordination (Mishchenko et al.,
2021). Recent works have demonstrated the theo-
retical convergence and practical viability of gossip-
based federated learning (FL), especially in decentral-
ized and infrastructure-less networks (Heged
¨
us et al.,
2022; Mishchenko et al., 2021). However, these ap-
proaches primarily focus on model parameter aggre-
gation without explicitly addressing the heterogene-
ity of client data distributions, and they do not con-
sider non-convex problems such as those encountered
in deep neural networks (DNNs).
Data heterogeneity, or non-independent and iden-
tically distributed (non-IID) data across clients, re-
mains a fundamental challenge in both centralized
and decentralized federated learning (FL) (Zhao et al.,
2018; Kairouz et al., 2019; Hsieh et al., 2020; Sery
et al., 2021). Non-IID data can cause local mod-
els to diverge significantly, leading to slower con-
vergence and reduced global model accuracy (Zhu
et al., 2021). Various strategies have been proposed
to mitigate these issues, including personalized fed-
erated learning (FL) (Smith et al., 2017), client clus-
tering (Sattler et al., 2020; Ouyang et al., 2021; Yang
et al., 2023), and adaptive aggregation techniques (Li
et al., 2020c). While these approaches improve per-
formance at the model or algorithmic level, they do
not directly modify the underlying data distributions.
To address this limitation, (Zhao et al., 2018) pro-
posed using a shared synthetic dataset, uniformly dis-
tributed over the data space and generated by a central
server. This dataset is then distributed to all clients to
make their local data more independent and identi-
cally distributed (IID). Although the approach is con-
ceptually simple and effective, it has significant draw-
backs: it requires the central server to be aware of the
global data distribution and imposes a storage burden
on clients. Alternatively, (Yoshida et al., 2020) pro-
posed a hybrid scheme in which only a small portion
of private data is shared with the server to enhance
privacy. While this reduces the amount of shared sen-
sitive information, it still poses a risk of privacy leak-
age.
Limited and controlled data sharing between
clients has been explored as a complementary ap-
proach to enhance learning under non-identical and
independent (non-IID) conditions. Although conven-
tional federated learning (FL) aims to avoid raw data
exchange to protect privacy in specific trusted envi-
ronments, such as among social peers, collaborative
organizations, or co-located devices, small-scale data
sharing is practical and beneficial (Li et al., 2020a).
Hybrid frameworks that integrate model distillation
with selective data sharing have been proposed to
enrich client datasets and improve global learning
(Jeong et al., 2019; Li et al., 2020a). Nevertheless,
these frameworks typically operate within centralized
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
250

federated learning (FL) paradigms and do not lever-
age data sharing in fully decentralized peer-to-peer
(P2P) networks.
Despite these prior advancements, the relationship
between data-sharing mechanisms and decentralized
federated learning in P2P networks remains under-
explored. Existing gossip-based frameworks focus
heavily on scalability and fault tolerance but neglect
the complexities introduced by data heterogeneity
(Boyd et al., 2006; Heged
¨
us et al., 2022). Similarly,
hybrid approaches for data sharing (Jeong et al., 2019;
Li et al., 2020a) are limited to centralized settings
and do not address the unique challenges of decentral-
ized, infrastructure-less networks. Our work builds on
these foundations by combining structured peer-level
data-sharing mechanisms with gossip-based commu-
nication to directly address non-IID data challenges
in decentralized P2P FL environments. This integra-
tion positions our framework as a practical and scal-
able solution for real-world deployments, advancing
beyond the state-of-the-art in both centralized and de-
centralized FL paradigms.
Our work advances the state-of-the-art by in-
troducing a novel P2P FL framework that explic-
itly incorporates a structured data-sharing mechanism
among trusted peers. This approach leverages the
advantages of gossip-based decentralized communi-
cation while addressing data heterogeneity through
peer-level data exchange. By doing so, it mitigates
non-IID challenges without sacrificing privacy and
decentralization. Our theoretical analysis and empiri-
cal results across diverse datasets and models demon-
strate that even modest data sharing significantly en-
hances convergence speed and model accuracy, of-
fering a practical and scalable solution for real-world
P2P FL deployments.
4 PROBLEM FORMULATION
We propose a peer-to-peer federated learning (P2P-
FL) framework enhanced with selective data sharing,
where N clients collaboratively train a shared model
by directly communicating model updates with their
peers, eliminating the need for a centralized server. To
counter the challenges posed by non-IID data distri-
butions, each client is permitted to share a portion of
its local data with neighboring clients. This targeted
data sharing enhances convergence and alignment of
distribution.
Inspired by prior work on decentralized training
algorithms (He et al., 2020; Heged
¨
us et al., 2019),
we extend the Federated Averaging (FedAvg) algo-
rithm to function in a fully peer-to-peer (P2P) envi-
ronment. Our model synchronization process is based
on gossip-based communication protocols(Heged
¨
us
et al., 2019), where each client periodically exchanges
model parameters with a subset of its neighboring
peers. After averaging these parameters, clients up-
date their local models accordingly and proceed with
further local training. This decentralized adaptation
eliminates the need for a central server, enhancing
scalability and robustness while preserving the col-
laborative benefits of federated learning.
Our primary objective is to investigate how the in-
clusion of a shared data component affects model per-
formance in decentralized, non-i.i.d. settings. Rather
than enforcing a fixed method for sharing (e.g., ac-
tive vs. passive ), we focus on the statistical effect
of data overlap. Our findings demonstrate that even
modest data sharing can significantly enhance per-
formance, outperforming purely decentralized setups
with equivalent total data volumes. This suggests that
distribution alignment, not just increased data quan-
tity, plays a critical role.
We consider a peer-to-peer federated learning
(P2P-FL) setting involving N clients collaboratively
engaged in a classification task, where the objective
is to learn a model that maps each input to one of
K possible classes. Each client n holds a private lo-
cal dataset denoted by D
n
=
{
x
n
i
}
M
n
i=1
, consisting of
M
n
data samples and their corresponding labels {y
i
}.
Each client maintains its model, parameterized by
ω
n
∈ R
p
, where p is the total number of trainable pa-
rameters. All clients share an identical model archi-
tecture.
Let l(ω, x, y) represent the loss incurred on a sin-
gle data point (x, y). The local loss function for client
n is given by:
L
n
(ω
n
) ≜
∑
x∈D
n
l (ω
n
, x, y(x)). (1)
The global learning objective in this decentralized
setting is to train models that collectively minimize
the total loss across all clients:
L(ω) =
N
∑
n=1
L
n
(ω). (2)
Unlike centralized FL, where a central server co-
ordinates aggregation, in P2P-FL, each client inde-
pendently exchanges model updates with a randomly
selected subset of peers at each round t. Let S
n
t
⊆ N
n
denote the set of m peers that client n communicates
with at round t. The client computes a weighted aver-
age of the model parameters received from its peers,
along with its locally updated model:
ω
n
t
=
M
n
M
n
t
ω
n
local
+
∑
j∈S
n
t
M
j
M
n
t
ω
j
t
, (3)
Peer-to-Peer Federated Learning with Trusted Data Sharing for Non-IID Mitigation
251

where M
n
t
= M
n
+
∑
j∈S
n
t
M
j
denotes the total number
of samples considered in the local peer aggregation.
This averaged model ω
n
t
serves as the reference model
for the next local update.
Each client then updates its model using a local
stochastic gradient descent (SGD) step with momen-
tum 0 ≤ β < 1:
ω
n
t+1
= ω
n
t
− η
t
v
n
t+1
, (4)
where η
t
is the learning rate at round t, and v
n
t+1
is the
momentum-augmented gradient defined as:
v
n
t+1
= βv
n
t
+ g
n
(ω
n
t
). (5)
The stochastic gradient g
n
(ω
n
t
) is computed over a
mini-batch S
n
⊂ D
n
of size B:
g
n
(ω
n
t
) =
∑
x∈S
n
∇l(ω
n
t
, x, y(x)). (6)
This decentralized protocol enables each client to
iteratively refine its model by leveraging knowledge
from a dynamically selected neighborhood, thereby
promoting robustness and scalability in the absence
of a central server.
5 PEER-LEVEL DATA SHARING
AND P2P ALGORITHM
To tackle the limitations introduced by non-IID data,
we incorporate a data exchange protocol among
clients. Each client contributes a fraction ∆ ∈ [0, 1]
of its local dataset to selected neighbors. The updated
dataset at client n becomes:
˜
D
n
= D
n
∪
[
m∈S
n
D
m→n
, (7)
where S
n
⊆ N
n
represents the set of contributing
peers, and D
m→n
⊆ D
m
is the subset of data points
(with |D
m→n
| = ∆ · M
m
) transferred from client m.
This setting mirrors practical environments where
users already share data in socially trusted relation-
ships (e.g., family, friends, coworkers), allowing us
to assume reduced privacy concerns. Importantly, no
data is transferred to any central authority, preserving
the decentralized and privacy-conscious nature of the
system.
Through this lens, we evaluate how data sharing
impacts learning quality under diverse model struc-
tures and datasets, focusing on realistic non-IID sce-
narios.
We investigate the impact of data sharing on the
performance of Federated Learning (FL). Once data
sharing is complete, the FL process proceeds using
the previously outlined decentralized algorithm. A
critical feature of our approach is that client data is
never transmitted to a central server. Instead, data
is exchanged exclusively among socially connected
peers, maintaining the privacy of individual clients.
This form of data sharing can occur organically with-
out the need for centralized orchestration.
Algorithm 1 describes the procedure for assigning
data to each client. It is designed to ensure that every
client ends up with a fixed number of data points, re-
gardless of the degree of data sharing. While sharing
data naturally leads to an increase in the total number
of samples available to a client, we aim to isolate the
effect of data distribution rather than data volume. To
achieve this, the baseline FL setup with ∆ = 0% (no
data sharing) is constructed to match the final dataset
size per client (M
n
). However, it contains more unique
data samples than the setup involving shared data.
This approach allows for a fair comparison that fo-
cuses on distributional benefits rather than data size
advantages.
We adopt the simplifying assumption that all
client pairs share an equal amount of data. This en-
sures the sharing process can be captured using a sin-
gle, interpretable parameter ∆, representing the pro-
portion of shared data per client.
6 EXPERIMENTAL RESULTS
In this section, we evaluate the performance of our
proposed Peer-to-Peer Federated Learning (P2P-FL)
framework with data sharing. Data sharing in P2P-FL
facilitates improved learning outcomes by guiding the
optimization process toward better stationary points,
particularly under non-convex loss landscapes that are
common in real-world machine learning models.
The experiments were conducted using Google
Colab Pro, which provides access to high-
performance resources, including an A100 GPU
and extended RAM, to support the execution of
computationally intensive models and large-scale
datasets in a Python-based environment.
The evaluation metric used is classification accu-
racy, defined as the percentage of correctly classified
samples in the test dataset after the training phase us-
ing the P2P-FL model.
To ensure a fair and comprehensive assessment,
we employed the following widely used benchmark
datasets:
• MNIST: A dataset of 70,000 grayscale images
of handwritten digits (0–9), with 60,000 samples
used for training and 10,000 for testing (LeCun
et al., 1998).
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
252

Algorithm 1: P2P Data Sharing and Training Procedure.
Require: Number of clients N, initial dataset size
M
0
, final dataset size M, data sharing ratio ∆,
communication graph G = (V , E)
1: Initialize each client n ∈ V with M
0
private data
samples D
n
2: for all client pairs (n, m) such that (n, m) ∈ E do
3: Client n shares ∆ · M
0
randomly selected sam-
ples from D
n
with client m
4: Client m augments its dataset: D
m
← D
m
∪
D
n→m
5: end for
6: for all clients n ∈ V do
7: Compute |D
n
| after sharing
8: Add new (non-overlapping) samples from a
global pool to reach final size |D
n
| = M
9: end for
10: Initialize local model parameters ω
n
for each
client n
11: for each communication round t = 1 to T do
12: for all clients n ∈ V do
13: Perform local SGD on D
n
to compute
g
n
(ω
n
t
)
14: Receive ω
j
t
from neighbors j ∈ N
n
15: Compute weighted average:
ω
n
t
=
M
n
M
n
t
ω
n
t
+
∑
j∈N
n
M
j
M
n
t
ω
j
t
16: Update model with momentum:
v
n
t+1
= βv
n
t
+ g
n
(ω
n
t
)
ω
n
t+1
= ω
n
t
− η
t
v
n
t+1
17: end for
18: end for
19: return Final model parameters ω
n
for all clients
• CIFAR-10: A dataset consisting of 60,000
32×32 color images across 10 object classes. It is
split into 50,000 training images and 10,000 test
images (Krizhevsky and Hinton, 2009).
• CIFAR-100: Similar to CIFAR-10, but with 100
classes, using the same 50,000/10,000 split for
training and testing, respectively (Krizhevsky and
Hinton, 2009).
To establish the general applicability of P2P-FL, we
tested it using four standard machine-learning models
with varying levels of complexity:
• Logistic Regression (LR): A baseline linear clas-
sifier.
• 2NN: A simple multilayer perceptron with two
hidden layers, each containing 200 ReLU-
activated units (McMahan et al., 2017; Zhao et al.,
2018).
• LeNet-5: A convolutional neural network (CNN)
for image recognition (LeCun et al., 1998).
• DenseNet-121: A deeper CNN model represent-
ing a high-complexity architecture (Huang et al.,
2017).
Each model was trained using stochastic gradient de-
scent (SGD) over 100 communication rounds. The
hyperparameters used were batch size B = 32, local
epoch E = 1 (i.e., one pass over the local dataset),
learning rate η = 0.01, and momentum parameter
β = 0.9. Each experiment was repeated 10 times in-
dependently, and we report the average results. The
error bars represent one standard deviation above and
below the average.
To assess the benefits of our data-sharing mecha-
nism in the P2P-FL setting, we compared it against
the classical Federated Averaging (FedAvg) algo-
rithm (McMahan et al., 2017), which does not involve
peer-to-peer data sharing. Additionally, we included
the Federated Proximal (FedProx) algorithm (Li et al.,
2020b) as a benchmark, as it is designed to address
heterogeneity in federated learning environments. We
benchmark our results against three scenarios:
• No Data Sharing (FedAvg): Standard FL with
no overlap in data between clients.
• Federated Proximal (FedProx): A variant of FL
that incorporates a proximal term to better handle
statistical heterogeneity across clients, serving as
a benchmark for heterogeneous federated learning
settings.
• Full Data Sharing (Centralized Baseline): All
data is shared among all clients, effectively equiv-
alent to a centralized model with access to the full
dataset. Training proceeds by averaging the gra-
dients from all N clients as if the data were fully
centralized.
These comparisons highlight the potential of P2P data
sharing to bridge the performance gap between decen-
tralized and centralized learning settings, while pre-
serving privacy and avoiding dependency on a central
server.
7 NON-IID PARTITIONING IN
P2P-FL
The results for our proposed P2P-FL approach un-
der non-IID data distribution are presented in Fig-
ure 2. In this setting, ten clients participate in train-
ing, each starting with local data that only includes
Peer-to-Peer Federated Learning with Trusted Data Sharing for Non-IID Mitigation
253
MNIST CIFAR-100CIFAR-10
LR
DenseNet
-121
CNN
DNN
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.1
0.2
0.3
0.4
0.5
0.6
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
Average Accuracy with 20% Shared Data Average Accuracy with 40% Shared Data 100% Shared Data Zero Shared Data Average Accuracy with Fed Prox
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
0.18
0.2
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.05
0.1
0.15
0.2
0.25
0.3
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
0 20 40 60 80 100
Global Test Accuracy
Communication Rounds
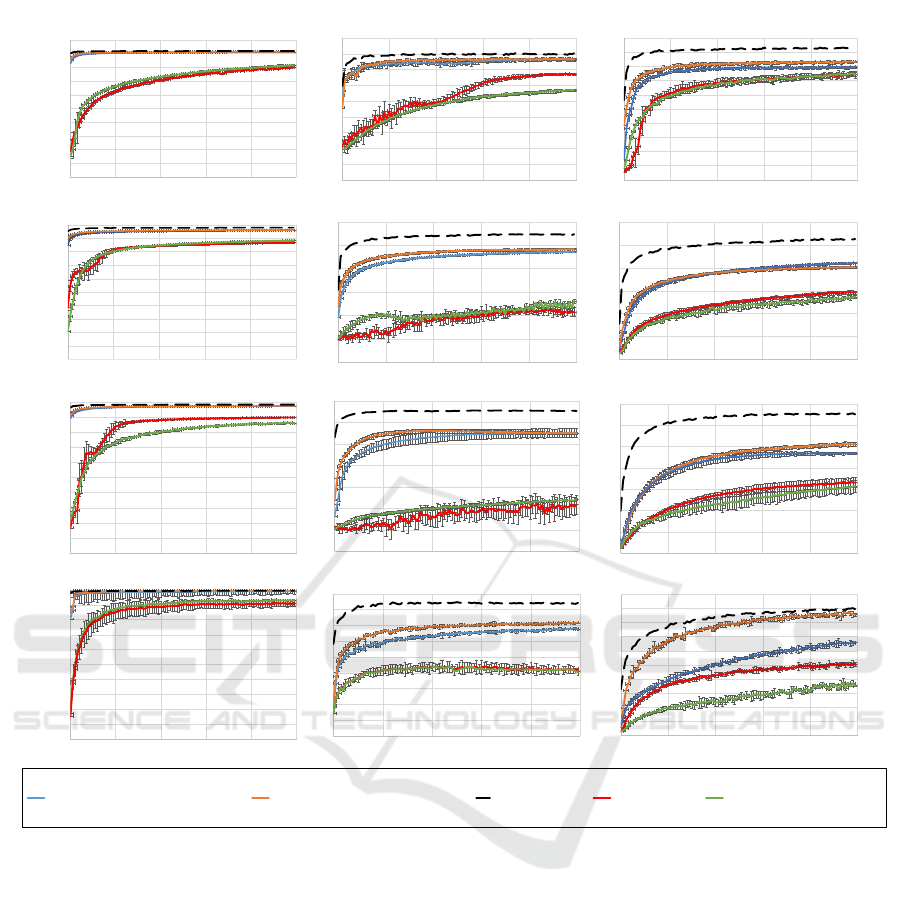
Figure 2: Data sharing with non-IID data distributions. The columns correspond to the MNIST, CIFAR-10, and CIFAR-100
datasets. The rows correspond to the models LR, 2NN, LeNet-5, and DenseNet-121. The comparison includes FedAvg (red),
FedProx (green), and SFL with various data sharing levels.
exclusive classes: for MNIST or CIFAR-10, client i
contains data solely from class i, for i = 1, . . . , 10, and
for CIFAR-100, client i contains classes indexed as
10(i − 1), 10(i − 1) + 1, . . . , 10(i − 1) + 9. Thus, no
class overlap occurs across clients, representing an
extreme non-IID scenario.
Each client initially holds M
0
= 1000 data sam-
ples. After applying the peer-to-peer data-sharing
mechanism, the final number of local data points per
client becomes M = 6000. In our framework, ’20%
data sharing’ refers to each client randomly select-
ing 20% of its local dataset and independently shar-
ing that subset with its connected peers, rather than
broadcasting to a central server. This behavior aligns
with the decentralized P2P communication paradigm
(see Algorithm 1).
Our empirical results demonstrate that a fully de-
centralized P2P-FL system with no data sharing (red
line in Figure 2) performs poorly in the presence of
extreme non-IID distributions, consistent with obser-
vations in prior work (Zhao et al., 2018). In addition,
FedProx (µ = 0.01, represented by the green line),
which incorporates a proximal term to mitigate client
drift, demonstrates marginal improvements over Fe-
dAvg in specific datasets and models. However, it
continues to face significant challenges when operat-
ing under highly non-IID data distributions. The mod-
est peer-level data sharing (e.g., 20%) significantly
improves learning outcomes across all tested models
and datasets.
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
254

The figure illustrates a diminishing return effect
with respect to the percentage of shared data and the
number of communication rounds. We evaluate shar-
ing levels of 0%, 20%, 40%, and 100%, with each
client maintaining a consistent private dataset size of
6,000 points. This ensures that performance gains
stem from better statistical diversity rather than in-
creased data quantity. Notably, increasing the data-
sharing level beyond 20% yields only marginal bene-
fits, especially after 40 communication rounds.
The performance boost is more pronounced in
complex scenarios, such as DenseNet-121 on CIFAR-
100, where the interplay between model capacity
and data heterogeneity becomes increasingly critical.
These findings suggest that P2P-FL with partial data
sharing not only mitigates statistical heterogeneity but
also aligns better with task complexity when deeper
models or more nuanced datasets are used.
8 CONCLUSION
In this paper, we propose a novel peer-to-peer feder-
ated learning framework enhanced with a structured
data-sharing mechanism among trusted peers. Our
approach addresses the critical challenge of non-IID
data distributions in fully decentralized FL systems by
enabling clients to exchange small subsets of their lo-
cal data directly with neighboring clients. This strat-
egy enhances dataset diversity and significantly miti-
gates the adverse effects of data heterogeneity, result-
ing in faster convergence and improved model accu-
racy.
Through extensive experiments on diverse
datasets and models, we demonstrated that even
modest data sharing substantially enhances learning
performance compared to P2P FL without data
sharing. Importantly, our method preserves the core
principles of privacy and decentralization in federated
learning by eliminating reliance on a central server
and restricting data exchange to trusted peers.
Future work includes exploring adaptive data-
sharing strategies to optimize the trade-off between
privacy and performance, as well as extending the
framework to dynamic and large-scale P2P networks
with varying trust relationships. To further address
privacy concerns, future work can focus on integrat-
ing privacy-preserving techniques such as differential
privacy (Dwork et al., 2006), secure multiparty com-
putation (Bonawitz et al., 2017), or homomorphic en-
cryption (Aono et al., 2017) with our proposed ap-
proach. These extensions could reduce the risks asso-
ciated with data sharing while maintaining the perfor-
mance benefits demonstrated in this study. Our find-
ings open up promising avenues for the practical de-
ployment of decentralized federated learning (FL) in
real-world applications where privacy, scalability, and
data heterogeneity coexist.
ACKNOWLEDGEMENTS
The authors gratefully acknowledge funding from the
Koret Foundation Grant for Smart Cities and Digital
Living 2030 and the Neubauer Family Foundation.
REFERENCES
Aono, Y., Hayashi, T., Abadi, M., Kono, K., and Han, S.
(2017). Privacy-preserving deep learning via addi-
tively homomorphic encryption. IEEE Transactions
on Information Forensics and Security, 13(5):1333–
1345.
Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A.,
McMahan, H. B., Patel, S., Ramage, D., Segal, A., and
Seth, K. (2017). Practical secure aggregation for fed-
erated learning on user-held data. In Proceedings of
the 24th ACM SIGSAC Conference on Computer and
Communications Security, pages 1175–1191. ACM.
Boyd, S., Ghosh, A., Prabhakar, B., and Shah, D. (2006).
Randomized gossip algorithms. IEEE Transactions
on Information Theory, 52(6):2508–2530.
Buratto, A., Guerra, E., Miozzo, M., Dini, P., and Badia,
L. (2024). Energy minimization for participatory fed-
erated learning in iot analyzed via game theory. In
2024 International Conference on Artificial Intelli-
gence in Information and Communication (ICAIIC),
pages 249–254. IEEE.
Chen, Y., Gui, Y., Lin, H., Gan, W., and Wu, Y. (2022).
Federated learning attacks and defenses: A survey. In
2022 IEEE International Conference on Big Data (Big
Data), pages 4256–4265. IEEE.
Dwork, C., McSherry, F., Nissim, K., and Smith, A. (2006).
Calibrating noise to sensitivity in private data analysis.
In Proceedings of the Third Theory of Cryptography
Conference, pages 265–284. Springer.
He, X. et al. (2020). Training linear models in a fully de-
centralized environment. In Proceedings of the Inter-
national Conference on Machine Learning.
Heged
¨
us, I., Berta, D., and Jelasity, M. (2019). Gos-
sip learning as a decentralized alternative to feder-
ated learning. In Proceedings of the ACM Interna-
tional Conference on Autonomous Agents and Multia-
gent Systems (AAMAS).
Heged
¨
us, I., Danner, G., and Schad, J. (2022). Decen-
tralized federated learning: A survey and perspective.
ACM Computing Surveys, 55(11):1–37.
Hsieh, K., Phanishayee, A., Mutlu, O., and Gibbons, P.
(2020). The non-iid data quagmire of decentralized
machine learning. In International Conference on Ma-
chine Learning, pages 4387–4398. PMLR.
Peer-to-Peer Federated Learning with Trusted Data Sharing for Non-IID Mitigation
255

Huang, G., Liu, Z., Van Der Maaten, L., and Weinberger,
K. Q. (2017). Densely connected convolutional net-
works. In Proceedings of the IEEE Conference on
Computer Vision and Pattern Recognition (CVPR),
pages 4700–4708.
Jazi, M. and Ben-Gal, I. (2024). Federated learning for
xss detection: A privacy-preserving approach. In Pro-
ceedings of the 16th International Joint Conference on
Knowledge Discovery, Knowledge Engineering and
Knowledge Management - Volume 1: KDIR, pages
283–293. INSTICC, SciTePress.
Jeong, E., Oh, S., Kim, S., Kang, J., Kim, J.-S., and Lee,
S.-E. (2019). Communication-efficient on-device ma-
chine learning: Federated distillation and augmenta-
tion under non-iid private data. In Proceedings of
the AAAI Conference on Artificial Intelligence, vol-
ume 33, pages 5713–5720.
Kairouz, P., McMahan, H. B., et al. (2019). Advances and
open problems in federated learning. Foundations and
Trends in Machine Learning, 14(1–2):1–210.
Kone
ˇ
cn
`
y, J., McMahan, B., Ramage, D., et al. (2015). Fed-
erated optimization: Distributed optimization beyond
the datacenter. arXiv preprint arXiv:1511.03575.
Krizhevsky, A. and Hinton, G. (2009). Learning multiple
layers of features from tiny images. Technical Report,
University of Toronto.
Lalitha, A., Javidi, T., and Koushanfar, F. (2019). Fully
decentralized federated learning. In 2019 53rd Asilo-
mar Conference on Signals, Systems, and Computers,
pages 582–586. IEEE.
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998).
Gradient-based learning applied to document recogni-
tion. Proceedings of the IEEE, 86(11):2278–2324.
Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. (2020a).
Fedmd: Heterogeneous federated learning via model
distillation. In Proceedings of the AAAI Conference on
Artificial Intelligence, volume 34, pages 3542–3549.
Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. (2020b).
Fedprox: A scalable federated learning framework
with heterogeneity. arXiv preprint arXiv:1812.06127.
Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A.,
and Smith, V. (2020c). Federated optimization in het-
erogeneous networks. Proceedings of Machine Learn-
ing and Systems, 2:429–450.
Liu, P., Xu, X., and Wang, W. (2022). Threats, attacks and
defenses to federated learning: Issues, taxonomy and
perspectives. Cybersecurity, 5(1):1–19.
Lyu, L., Yu, H., Ma, X., Chen, C., Sun, L., Zhao, J., Yang,
Q., and Yu, S. (2022). Privacy and robustness in fed-
erated learning: Attacks and defenses. IEEE Transac-
tions on Neural Networks and Learning Systems.
McMahan, B., Moore, E., Ramage, D., Hampson, S., and
Aguera y Arcas, B. (2017). Communication-efficient
learning of deep networks from decentralized data. In
Proceedings of the 20th International Conference on
Artificial Intelligence and Statistics (AISTATS), vol-
ume 54, pages 1273–1282. PMLR.
McMahan, H. B., Moore, E., Ramage, D., et al. (2016).
Federated averaging: Communication-efficient learn-
ing of deep networks from decentralized data. arXiv
preprint arXiv:1602.05629.
Mishchenko, K., Khaled, A., and Richtarik, P. (2021). Dis-
tributed stochastic gradient tracking methods. Journal
of Machine Learning Research, 22(153):1–54.
Ouyang, X., Xie, Z., Zhou, J., Huang, J., and Xing, G.
(2021). Clusterfl: A similarity-aware federated learn-
ing system for human activity recognition. In Pro-
ceedings of the 19th Annual International Conference
on Mobile Systems, Applications, and Services, pages
54–66.
Sattler, F., M
¨
uller, K.-R., and Samek, W. (2020). Clustered
federated learning: Model-agnostic distributed mul-
titask optimization under privacy constraints. IEEE
Transactions on Neural Networks and Learning Sys-
tems, 32(8):3710–3722.
Sery, T., Shlezinger, N., Cohen, K., and Eldar, Y. C.
(2021). Over-the-air federated learning from hetero-
geneous data. IEEE Transactions on Signal Process-
ing, 69:3796–3811.
Smith, V., Chiang, C.-K., Sanjabi, M., and Talwalkar, A.
(2017). Federated multi-task learning. Advances in
Neural Information Processing Systems, 30.
Tang, H., Dube, X., Wang, S., Joshi, G., and Kar, S. (2018).
D2: Decentralized training over decentralized data.
In International Conference on Learning Representa-
tions (ICLR).
Yang, L., Huang, J., Lin, W., and Cao, J. (2023). Person-
alized federated learning on non-iid data via group-
based meta-learning. ACM Transactions on Knowl-
edge Discovery from Data, 17(4):1–20.
Yoshida, N., Nishio, T., Morikura, M., Yamamoto, K.,
and Yonetani, R. (2020). Hybrid-fl for wireless net-
works: Cooperative learning mechanism using non-iid
data. In ICC 2020 - IEEE International Conference on
Communications, pages 1–7. IEEE.
Zang, M., Zheng, C., Koziak, T., Zilberman, N., and
Dittmann, L. (2024). Federated in-network machine
learning for privacy-preserving iot traffic analysis.
ACM Transactions on Internet Technology, 24(4):1–
24.
Zhao, Y., Li, M., Lai, L., Suda, N., Civin, D., and Chandra,
V. (2018). Federated learning with non-iid data. arXiv
preprint arXiv:1806.00582.
Zhu, H., Xu, J., Liu, S., and Jin, Y. (2021). Federated
learning on non-iid data: A survey. Neurocomputing,
465:371–390.
KDIR 2025 - 17th International Conference on Knowledge Discovery and Information Retrieval
256
