
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for
Automated Exercise Evaluation
Ahmed Hassan
1 a*
, Abdelaziz Serour
1 b*
, Ahmed Gamea
1 c*
and Walid Gomaa
1,2 d
1
Department of Computer Science and Engineering, Egypt-Japan University of Science and Technology (E-JUST),
Alexandria, Egypt
2
Faculty of Engineering, Alexandria University, Alexandria, Egypt
Keywords:
Multi-Modal Deep Learning, Exercise Assessment, Computer Vision, Pose Estimation, Human Movement
Analysis, Fitness Monitoring.
Abstract:
Improper gym exercise execution often leads to injuries and suboptimal training outcomes, yet conventional
assessment relies on subjective human observation. This paper introduces ALEX-GYM-1, a novel multi-
camera view dataset with criterion-specific annotations for squats, lunges, and Romanian deadlifts, alongside
a complementary multi-modal architecture for automated assessment. Our approach uniquely integrates: (1)
a vision-based pathway using 3D CNN to capture spatio-temporal dynamics from video, and (2) a pose-based
pathway that analyzes biomechanical relationships through engineered landmark features. Extensive experi-
ments demonstrate the superiority of our Multi-Modal fusion architecture over both single-modality methods
and competing approaches, achieving Hamming Loss reductions of 30.0% compared to Vision-based and
79.5% compared to Pose-based models. Feature-specific analysis reveals key complementary strengths, with
Vision-based components excelling at contextual assessment (89% error reduction for back knee positioning)
while Pose-based components demonstrate precision in specific joint relationships. The computational effi-
ciency analysis enables practical deployment strategies for both real-time edge applications and high-accuracy
cloud computing scenarios. This work addresses critical gaps in exercise assessment technology through a
purpose-built dataset and architecture that establishes a new state-of-the-art for automated exercise evaluation
in multi-camera view settings.
1 INTRODUCTION
Improper execution of resistance exercises represents
a significant public health concern, with epidemi-
ological studies revealing alarming injury patterns
among strength athletes. Research by (Winwood
et al., 2014) documented that 82% of strongman com-
petitors experienced training-related injuries, with the
lower back (24%) and knees (11%) being the most
commonly affected anatomical locations. Similarly,
(Wushao et al., 2000) reported high incidence rates
among weightlifters, with lower back injuries ac-
counting for 19% in male athletes and 18% in fe-
male athletes, while knee injuries represented 29%
in males and 32% in females. These statistics un-
a
https://orcid.org/0009-0000-9177-3815
b
https://orcid.org/0009-0007-9601-9759
c
https://orcid.org/0009-0004-6023-4420
d
https://orcid.org/0000-0002-8518-8908
∗
These authors contributed equally to this work.
derscore the critical need for improved exercise form
monitoring, as injuries not only disrupt training pro-
gression but often lead to chronic conditions requir-
ing extensive rehabilitation (Keogh and Winwood,
2017). While professional trainers provide personal-
ized feedback, this traditional approach is limited by
subjectivity, variability across trainers, and accessi-
bility challenges, especially in remote or home-based
training environments (Clark et al., 2021).
Recent technological solutions have attempted to
address these limitations through automated exer-
cise assessment systems. Kotte et al. (Kotte et al.,
2023) introduced a computer vision approach using
YOLOv7-pose for keypoint detection, offering real-
time posture correction feedback through compari-
son with expert demonstrations. Similarly, Duong-
Trung et al. (Duong-Trung et al., 2023) developed
a pose tracking system that learns from either live
professional trainer demonstrations or recorded ex-
pert videos to provide automated guidance. Neha and
24
Hassan, A., Serour, A., Gamea, A. and Gomaa, W.
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for Automated Exercise Evaluation.
DOI: 10.5220/0013669400003982
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 22nd International Conference on Informatics in Control, Automation and Robotics (ICINCO 2025) - Volume 2, pages 24-34
ISBN: 978-989-758-770-2; ISSN: 2184-2809
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

Manju (Neha and Manju, 2023) utilized MediaPipe
with OpenCV to implement a virtual fitness trainer
that evaluates form and technique through computer
vision. VCOACH (Youssef et al., 2023) presented
a more sophisticated approach using distance matri-
ces derived from MediaPipe pose estimations as in-
put to a residual neural network for simultaneous ex-
ercise recognition and error assessment. However,
these solutions face critical limitations: they predom-
inantly rely on binary correctness assessment rather
than detailed biomechanical criteria, depend heav-
ily on exact reference poses from experts that may
not accommodate individual body proportions, lack
fine-grained analysis of exercise-specific biomechan-
ical principles, or utilize single-modality inputs that
miss complementary information available in direct
visual analysis. Additionally, most existing systems
rely exclusively on either raw visual data or skele-
tal landmarks, missing the complementary benefits of
integrating both modalities for comprehensive assess-
ment.
In this research, exercise assessment is formulated
as a multi-label binary classification task for prede-
termined exercise types. For each exercise—squat,
lunge, or Romanian deadlift—5-7 biomechanical cri-
teria identified by professional trainers are evalu-
ated simultaneously, enabling specific identification
of form deficiencies rather than providing simplistic
binary judgments. A dual-stream architecture pro-
cesses both visual data through 3D convolutional neu-
ral networks and biomechanical relationships through
engineered pose features. Visual streams capture
contextual movement qualities and temporal dynam-
ics, while pose streams quantify precise joint re-
lationships, with these complementary information
sources integrated through a multi-stage fusion net-
work. This approach transcends the limitations of
single-modality systems by enabling assessment ca-
pabilities unachievable through either visual or skele-
tal analysis alone.
Leveraging this approach, our study introduces
ALEX-GYM-1, a purpose-built dataset for exercise
analysis, alongside a novel hybrid assessment system
designed to address the identified limitations. The pri-
mary contributions of this work are as follows:
• Novel Multi-View Dataset: Development of
ALEX-GYM-1, featuring synchronized frontal
and lateral recordings with criterion-specific an-
notations across fundamental training exercises,
providing the comprehensive reference data nec-
essary for detailed biomechanical assessment.
• Multi-Modal Architecture: Design of a hybrid
framework that integrates complementary visual
and biomechanical information streams, over-
coming the inherent limitations of single-modality
approaches through structured fusion of contex-
tual and skeletal data.
• Biomechanical Criteria-Based Model Compar-
ison: Systematic analysis of how vision-based,
pose-based, and multi-modal approaches perform
across specific biomechanical assessment criteria.
• Edge Deployment Performance Evaluation:
Implementation and testing of the proposed mod-
els on edge computing hardware to determine in-
ference latency, enabling informed deployment
decisions for real-time exercise assessment appli-
cations.
This system advances real-time exercise assess-
ment, providing objective and detailed feedback cru-
cial for injury prevention and performance optimiza-
tion.
The paper is organized as follows. Section 1 is
an introduction. Section 2 reviews related literature,
Section 3 details our methodology, Section 4 presents
results and analysis, and Section 5 concludes with key
findings and future directions.
2 RELATED WORK
2.1 Human Activity Recognition and
Exercise Assessment
Human Activity Recognition (HAR) has evolved
through two primary approaches: wearable sensor-
based and vision-based modalities (Kaseris et al.,
2024). Vision-based methods predominantly rely on
visible-light and depth cameras, with much of the re-
search focusing on either raw image inputs or skele-
tal pose representations (Baradel et al., 2018; Khan
et al., 2022). Building on this foundation, recent re-
search has increasingly focused on exercise evalua-
tion using vision-based inputs, particularly skeletal
pose data and RGB frames extracted from video. This
trend is driven by the need for automated fitness and
rehabilitation systems that not only recognize activity
type but also assess execution quality.
Ganesh et al. (Ganesh et al., 2020) developed a
virtual coaching system using RGB video and Open-
Pose (Cao et al., 2019) for 2D keypoint extraction,
achieving 98.98% accuracy in exercise recognition
with a Random Forest classifier. Their assessment
method compared user and trainer skeletons by aver-
aging point-wise distances, but this approach failed to
distinguish genuine mistakes from variations in body
proportions, offering limited and inaccurate feedback.
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for Automated Exercise Evaluation
25

In VCOACH (Youssef et al., 2023), the authors
proposed an efficient architecture for simultaneous
exercise recognition and detailed performance evalu-
ation, leveraging 1D convolutional layers with resid-
ual blocks applied to skeletal pose keypoint sequences
extracted via MediaPipe pose estimation. The sys-
tem was designed to handle multi-label classification
in addition to identifying the type of exercise. Evalu-
ated on the MMDOS dataset (Sharshar et al., 2022),
the model achieved an average accuracy of 75.34% ±
6.71% and a Jaccard score of 0.71 ± 0.03 across ten
runs under the Full Assessment Configuration, which
targets the detection of specific execution mistakes
alongside activity recognition.
2.2 Vision-Based Models for Video
Analysis
Recent advances in vision models have demonstrated
strong capabilities in processing RGB image se-
quences for video-based understanding tasks. Pre-
trained architectures such as Vision Transformers
(ViT) (Dosovitskiy et al., 2020) and 3D ResNet (Du
et al., 2023) have shown significant success across a
range of applications due to their ability to capture
spatial and temporal dependencies. In our work, we
adopt a set of vision-based architectures to process
RGB video data for exercise recognition and assess-
ment. These include 3D ResNet (Du et al., 2023), 1D
CNN-GRU combined with ViT (Chen et al., 2023),
and a 2D CNN + ViT hybrid (Arnab et al., 2021). The
detailed architecture and implementation of each ap-
proach are discussed in later sections.
2.3 Datasets for Exercise Analysis
Most existing datasets focus on activity recognition
rather than detailed correctness assessment. Table
1 compares key exercise analysis datasets, revealing
significant gaps in multi-view recording, detailed cor-
rectness criteria, and exercise-specific biomechanical
feature extraction.
General-purpose datasets like UTD-
MHAD (Chen et al., 2015) (8 subjects, 27 actions)
and MoVi (Ghorbani et al., 2021) (90 participants,
20 actions) offer technical comprehensiveness but
lack correctness annotations. More specialized
datasets include HSiPu2 (Zhang et al., 2021) with
3 exercises (push-up, pull-up, and sit-up) using
dual-view recording but lacking participant count
documentation, and KIMORE (Capecci et al., 2019)
containing 78 participants (44 healthy, 34 with motor
dysfunctions) performing 5 rehabilitation exercises
with clinical scoring. The MEx dataset (Wijekoon
et al., 2019) captures 7 physiotherapy exercises
performed by 30 subjects using multiple sensors
(accelerometers, pressure mat, depth camera) but
lacks exercise correctness annotations.
ALEX-GYM-1 addresses these limitations by
uniquely combining:
• Synchronized multi-camera view recording:
Frontal and lateral camera views capture comple-
mentary information - bilateral symmetry and bal-
ance from front, joint angles and postural align-
ment from side - enabling comprehensive assess-
ment impossible with single perspectives.
• Fine-grained biomechanical criteria: Rather
than binary correct/incorrect labels, 5-7 specific
criteria per exercise enable targeted feedback on
distinct movement components, identified by pro-
fessional trainers as critical for performance and
safety.
• Invariant biomechanical features: Skeletal
landmarks are transformed into distance and an-
gular relationships that remain consistent regard-
less of body proportions, camera position, or ex-
ecution speed, creating robust representations of
movement quality.
The novelty of the ALEX-GYM-1 dataset can be
observed in its comprehensive integration of multi-
view recordings with criterion-specific biomechan-
ical annotations. Whereas existing datasets have
been limited to either general activity recognition
or simplified binary correctness labels, this dataset
was purposefully designed to bridge the gap be-
tween mere exercise identification and detailed move-
ment quality assessment. The dataset’s synchronized
dual-perspective recordings, combined with expert-
validated biomechanical criteria and standardized fea-
ture representations, establish a new benchmark for
exercise assessment resources. This structured ap-
proach enables more nuanced exercise evaluation than
previously possible, allowing for the development of
automated systems capable of providing specific, ac-
tionable feedback comparable to that of human train-
ers.
3 METHODOLOGY
3.1 Dataset
The ALEX-GYM-1 dataset was constructed to cap-
ture fundamental gym exercises performed by indi-
viduals of varying demographics. Videos of squats,
lunges, and single-leg Romanian deadlifts were
recorded from both frontal and lateral camera views,
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
26
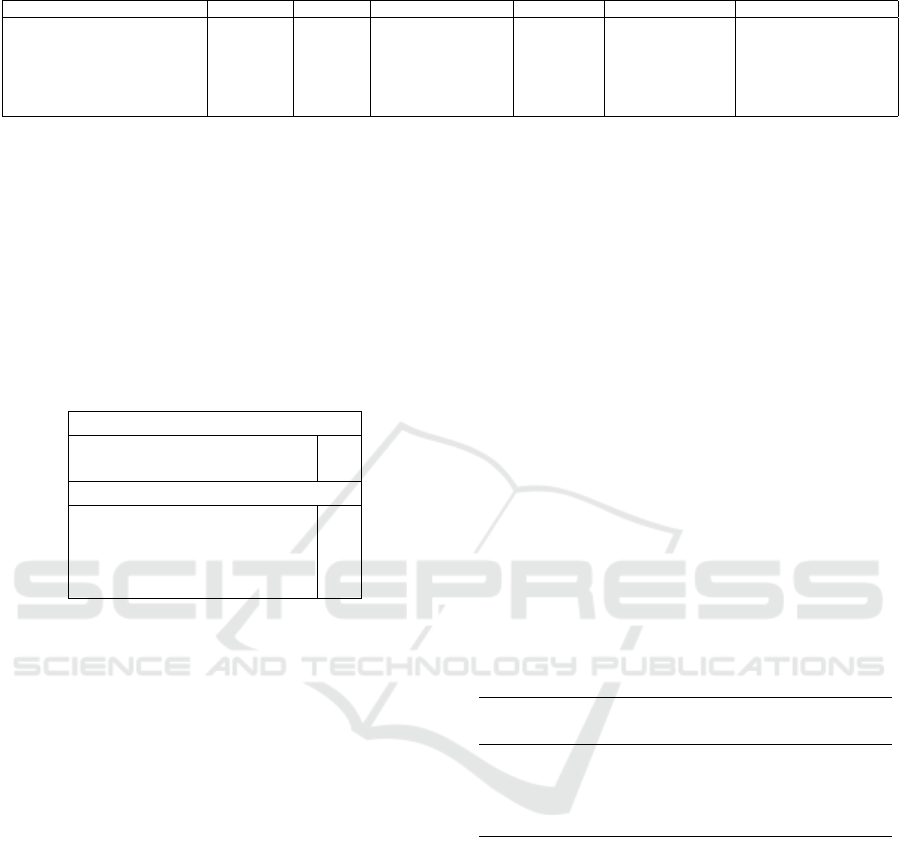
Table 1: Comprehensive comparison of workout exercise analysis datasets.
Dataset Multi-View Pose Data Correctness Criteria Participants Expert Annotation Biomechanical Features
ALEX-GYM-1 Yes (2) 3D Multi-label 45 Yes Yes
HSiPu2 (Zhang et al., 2021) Yes (2) 2D Binary Not reported Yes No
KIMORE (Capecci et al., 2019) No 3D Multi-score 78 Yes Partial
UTD-MHAD (Chen et al., 2015) No 3D No 8 No No
MEx (Wijekoon et al., 2019) No No No 30 No No
MoVi (Ghorbani et al., 2021) Yes (multi) MoCap No 90 No No
with professional trainers annotating specific biome-
chanical criteria—each represented as a boolean fea-
ture—to assess movement correctness.
3.1.1 Demographic Composition
The dataset comprises 45 participants distributed
across demographic categories as presented in Ta-
ble 2.
Table 2: Demographic distribution of participants in ALEX-
GYM-1.
Gender
Female 12
Male 33
Age Groups
Children (8–12 years) 4
Teenagers (13–19 years) 7
Young Adults (20–35 years) 31
Adults (36–54 years) 3
3.1.2 Exercise Composition
The dataset contains 670 videos distributed across
three exercise types:
• Squat (295 videos): Six boolean features were
annotated: feet flat, simultaneous hip/knee bend,
backward hip movement, neutral lower back, hips
below knees, feet angled 30°.
• Lunges (106 videos): Seven boolean features were
annotated: shoulder-width heels, forward gaze,
90° knee bend, natural arm movement, aligned
feet, straight back, back knee positioning.
• Single-Leg Romanian Deadlifts (269 videos):
Five boolean features were annotated: balance
maintenance, back alignment, full leg extension,
controlled reversal, support knee angle.
All data collection was conducted with partici-
pants’ informed consent for research purposes.
3.2 Data Preprocessing
A two-stage preprocessing pipeline was implemented
to standardize inputs and extract biomechanically-
relevant features.
General preprocessing: Original videos were
recorded at 30 FPS with durations ranging from 3 to
8 seconds, depending on exercise execution and par-
ticipant speed. To normalize temporal variation, each
video was temporally resampled by extracting 16 uni-
formly spaced frames per camera view (Frontal and
Lateral) at intervals of video-duration/16, creating a
standardized representation regardless of original per-
formance speed. MediaPipe’s 3D pose estimation was
applied to extract 33 skeletal landmarks per frame.
The selection of 16 frames was determined
through quantitative analysis of the trade-off between
computational efficiency and motion fidelity. A frame
stacking methodology was employed, wherein binary
silhouettes were extracted from frames and aggre-
gated through pixel-wise summation to generate com-
posite motion heatmaps. These temporal aggregations
were evaluated at varying frame counts (4, 8, 16, 32)
against a 64-frame reference standard using Structural
Similarity Index (SSIM) and Intersection over Union
(IoU) metrics.
Table 3: Comparative Analysis of Motion Representation
Fidelity Across Frame Sampling Rates.
Frame Count Frontal View
(SSIM / IoU)
Lateral View
(SSIM / IoU)
4 0.924 / 0.982 0.946 / 0.990
8 0.946 / 0.995 0.948 / 0.993
16 0.967 / 0.997 0.963 / 0.998
32 0.985 / 0.999 0.982 / 0.999
While utilizing higher frame counts approached
perfect representation, computational overhead in-
creased proportionally. The 16-frame configuration
preserved over 96% SSIM and exceeded 99.7% IoU
across both camera views, offering an optimal balance
between computational efficiency and motion repre-
sentation fidelity.
Pose feature engineering: While the extracted skele-
tal landmarks provide positional information, raw co-
ordinates are highly sensitive to variations in sub-
ject positioning, camera angle, and body propor-
tions. To create robust, invariant representations suit-
able for exercise assessment, these landmarks were
transformed into biomechanically meaningful rela-
tionships through two complementary feature sets:
Euclidean distances. Euclidean distances between
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for Automated Exercise Evaluation
27

landmark pairs were calculated:
d
i j
=
q
(x
i
− x
j
)
2
+ (y
i
− y
j
)
2
+ (z
i
− z
j
)
2
(1)
where p
i
= (x
i
, y
i
, z
i
) and p
j
= (x
j
, y
j
, z
j
) represent
keypoint coordinates. Due to symmetry (d
i j
= d
ji
),
the total unique distances was determined as
Total Pairwise Distances =
33 × 32
2
= 528
Angular Relationships. Angular relationships be-
tween landmark triplets were derived, with cosine val-
ues used for numerical stability:
θ
i jk
= cos
−1
(p
i
− p
j
) · (p
k
− p
j
)
∥p
i
− p
j
∥∥p
k
− p
j
∥
(2)
⇒ cos(θ
i jk
) =
(p
i
− p
j
) · (p
k
− p
j
)
∥p
i
− p
j
∥∥p
k
− p
j
∥
where p
i
, p
j
, and p
k
represent three distinct land-
marks with p
j
serving as the vertex point. The vectors
(p
i
− p
j
) and (p
k
− p
j
) form the two sides of the angle
being measured. The total unique angle combinations
was determined as
Total Pose Angles =
33
3
=
33 × 32 × 31
3 × 2 × 1
= 5456
creating a final feature vector of 5984 dimensions
(528 distances + 5456 angles) that provide a position-
invariant representation of biomechanical relation-
ships.
3.3 Data Organization
The dataset was structured to facilitate efficient access
and processing:
• Demographic metadata: Excel file contain-
ing participant attributes including age, gender,
height, and weight.
• Technical data: Excel file with video iden-
tifiers for each camera view (odd/even for
frontal/lateral), repetition indices, exercise classi-
fications, and binary correctness criteria for each
biomechanical criteria.
• Naming convention: Files follow
(num video) idx (repetition idx) (frame number).jpg
as shown in Figure 1.
• Directory structure: Three primary directories
(Squats, Lunges, Deadlifts) with hierarchical or-
ganization by camera view and repetition.
Figure 1: Image naming convention demonstrating corre-
sponding frontal (1 idx 0 1.jpg) and lateral (2 idx 0 1.jpg)
camera views.
3.4 Model Architecture
To effectively classify these diverse biomechanical
criteria, which range from precise joint angles to com-
plex movement patterns, a multi-modal architecture
capable of capturing both explicit skeletal relation-
ships and visual contextual information was devel-
oped. This dual perspective design enables the extrac-
tion of complementary information from each modal-
ity, resulting in a more accurate assessment than using
any single modality alone.
3.4.1 System Overview
In this study, exercise evaluation is formulated as a
multi-label binary classification task. The proposed
system does not classify the exercise type itself, as
this is predetermined through dataset organization
prior to assessment. Instead, for each known exercise,
the system evaluates a set of specific biomechanical
criteria (6 for squats, 5 for deadlifts, and 7 for lunges),
where each criterion is represented as a binary value
indicating whether it is satisfied (1) or not satisfied
(0) in the exercise execution. This approach enables
detailed, criterion-wise feedback on exercise form.
As illustrated in Figure 2, the proposed processing
framework employs a dual-stream architecture that
integrates both visual and skeletal modalities. The
system processes 16 frames from each camera view,
with all three RGB color channels preserved to main-
tain visual details. The system features two paral-
lel pathways: a pose-based stream, where 33 land-
marks extracted via MediaPipe are transformed into a
5984-dimensional vector for position-invariant repre-
sentation, and a vision-based stream, where raw video
frames are processed using specialized 3D convolu-
tional networks to capture spatio-temporal dynam-
ics. A key innovation of this architecture is its oper-
ational flexibility—each modality is capable of func-
tioning independently as a standalone assessment sys-
tem or collaboratively within a multi-modal fusion
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
28
Frontal Lateral
Vision Pose
Fusion
Frontal Video
16 frames
Lateral Video
16 frames
MediaPipe
Pose Estimation
MediaPipe
Pose Estimation
Pose Data
16×33×3
Pose Data
16×33×3
Distance
& Angle
Computation
Distance
& Angle
Computation
Pose Features
16×5984
Pose Features
16×5984
Vision-Based
Model
Pose-Based
Model
Standalone
Path
Exercise
Criteria
Predictions
Standalone
Path
Exercise
Criteria
Predictions
Vision Features
Pose Features
+
Multi-Stage
Fusion Network
Exercise
Criteria
Predictions
Figure 2: Multi-Modal Exercise Evaluation System workflow: Vision (red) and Pose (blue) pathways operate independently
or through fusion.
framework. This modular design supports deploy-
ment under varying computational constraints, en-
abling a lightweight option in resource-limited set-
tings while preserving the option for full multi-modal
analysis when higher accuracy is required. The in-
formation flow is driven by synchronized frontal and
lateral video inputs, offering multi-view perspectives
that mitigate occlusion and ambiguity common in
single-view setups. Each pathway is carefully opti-
mized to leverage the strengths of its respective data
modality.
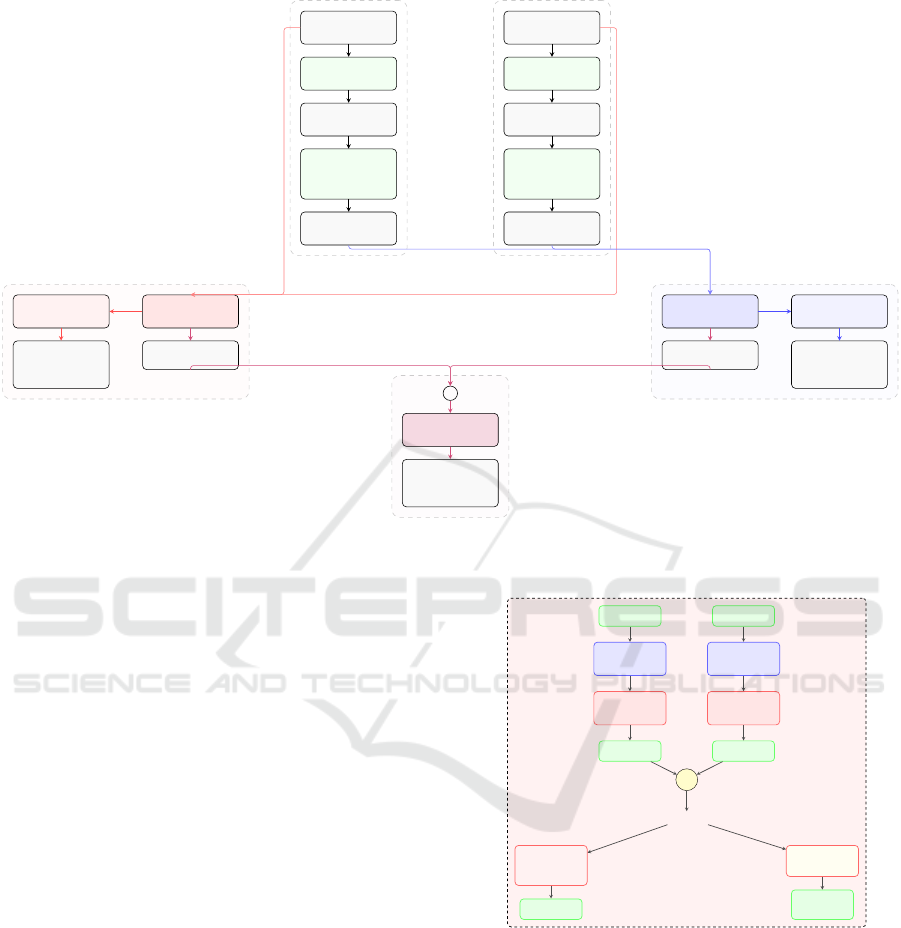
3.4.2 Vision-Based Model
The Vision-Based Model, illustrated in Figure 3, em-
ploys a dual-stream 3D convolutional architecture de-
signed to process frontal and lateral camera views
separately before integrating their outputs for com-
prehensive analysis. Each camera view (Frontal and
Lateral) is handled by a dedicated ResNet3D-18 net-
work pre-trained on the Kinetics-400 action recog-
nition dataset. A selective transfer learning strategy
was adopted, where early layers (labeled as ”Frozen”)
were kept static to preserve their ability to extract low-
level visual features such as edges, textures, and basic
motion cues, while deeper layers (labeled as ”Fine-
tuned”) were adapted to specialize in exercise-specific
movement patterns. This approach reduces training
Vision-Based Model
Frontal Frames
16×3×224×224
Lateral Frames
16×3×224×224
ResNet3D
Layers 1-2
(Frozen)
ResNet3D
Layers 1-2
(Frozen)
ResNet3D
Layers 3-4
(Fine-tuned)
ResNet3D
Layers 3-4
(Fine-tuned)
Feature Vector
512
Feature Vector
512
+
Dual Output Paths
FC
1024→512→256
BatchNorm, ReLU
Dropout
Standalone
Predictions
FC 1024→512
BatchNorm, ReLU
Dropout
Features for
Multi-Modal
Fusion
Figure 3: Vision-Based Model architecture with dual
ResNet3D streams. Frontal and lateral frames are processed
through transfer-learned 3D CNN pathways with selectively
frozen and fine-tuned layers.
complexity, accelerates convergence, and improves
generalization by balancing pre-learned visual repre-
sentations with task-specific adaptation. The result-
ing feature vectors from each stream, capturing essen-
tial spatio-temporal characteristics, are concatenated
into a unified representation. This fused representa-
tion is then directed either into a standalone model
path or into a feature extraction path for integration
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for Automated Exercise Evaluation
29
Pose-Based Model
Frontal Pose
16×5984
Lateral Pose
16×5984
Conv2D 256
stride (2,1)
BatchNorm, ReLU
Conv2D 256
stride (2,1)
BatchNorm, ReLU
Enhanced
Residual Block 1
(256→512)
Enhanced
Residual Block 1
(256→512)
Enhanced
Residual Block 2
(512→512)
Enhanced
Residual Block 2
(512→512)
Adaptive
Average Pooling
Adaptive
Average Pooling
Feature Vector
512
Feature Vector
512
+
Dual Output Paths
FC
1024→512→256
BatchNorm, ReLU
Dropout
Standalone
Predictions
FC 1024→512
BatchNorm, ReLU
Dropout
Features for
Multi-Modal
Fusion
Figure 4: Enhanced Pose-Based Model architecture. High-
dimensional pose features from both camera views are pro-
cessed through specialized convolutional pathways with
multi-stage residual blocks and global pooling.
with pose-based information in the multi-modal fu-
sion framework. Throughout the architecture, batch
normalization, ReLU activations, and dropout layers
are applied to ensure stable training and robust per-
formance.
3.4.3 Pose-Based Model
The Pose-Based Model, illustrated in Figure 4, was
designed to capture the biomechanical relationships
between body joints. Unlike the Vision-Based Model,
this component focuses exclusively on a structured
representation of body configuration. The input to the
model consists of high-dimensional vectors encoding
pairwise distances and angular relationships between
joints crafted to be invariant to position, scale, and
partial rotation. to effectively process these high-
dimensional features, the model first applies a 2D
convolutional layer that reduces dimensionality while
preserving the temporal structure of the sequence.
The network uses residual blocks (shown in Figure
5) that include three main operations: channel re-
duction, feature processing, and channel expansion.
These blocks incorporate shortcut connections that
help information flow through deep layers, improving
training stability. Following this processing, adaptive
average pooling creates compact feature vectors for
each camera view by consolidating temporal informa-
tion. These representations are then concatenated and
routed through either a standalone prediction pathway
or a feature extraction pathway designed for integra-
tion with the visual stream in the multi-modal fusion
framework, mirroring the architecture of the Vision-
Based Model.
Enhanced Residual Block with Bottleneck Design
Input Features
Main Path
1×1 Conv
Reduce Channels
in → in/2
3×1 Conv
Extract Features
in/2 → in/2
1×1 Conv
Expand Channels
in/2 → out
+
Shortcut Path
Identity
When dimensions
match
1×1 Conv
When dimensions
change
ReLU
Activation
Enhanced
Output Features
Figure 5: Residual Block with Bottleneck Design.
This architecture implements a computationally efficient
main path with three specialized convolutions (reduc-
tion→extraction→expansion), complemented by an adap-
tive shortcut for maintaining feature integrity, optimizing
both gradient flow and inference efficiency.
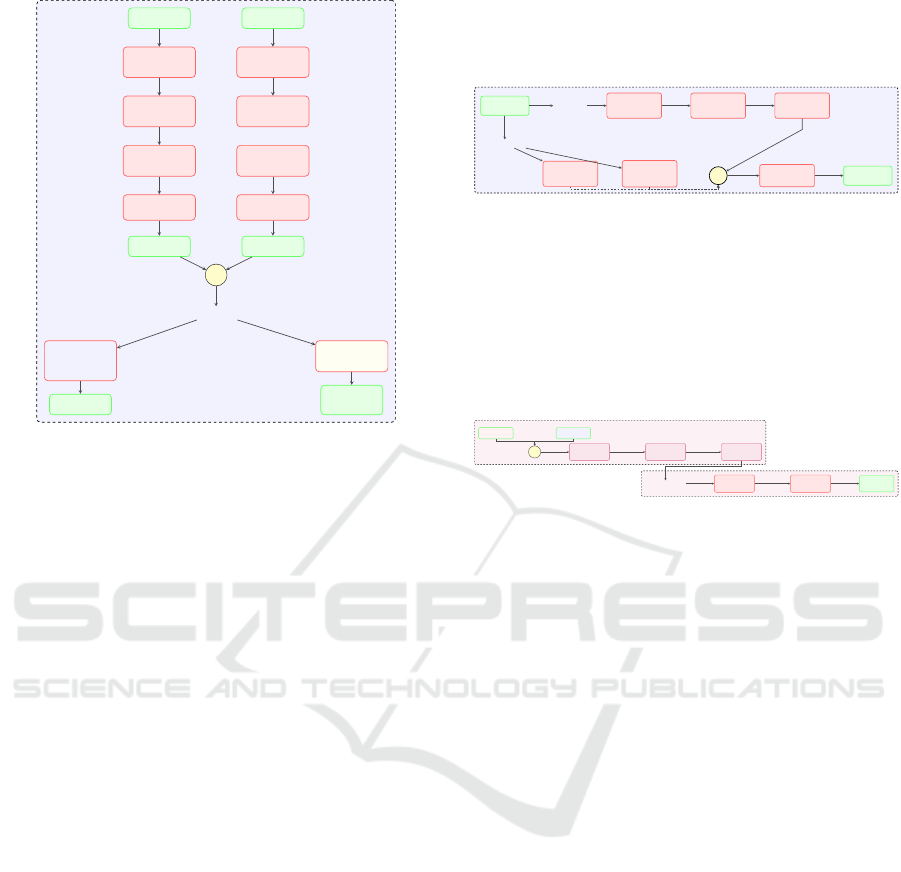
3.4.4 Multi-Modal Feature Fusion
Multi-Stage Feature Fusion
Classification Network
Vision Features
512
Pose Features
512
Feature Integration Path
+
FC Layer 1
1024→768
BatchNorm, ReLU
FC Layer 2
768→384
BatchNorm, ReLU
FC Layer 3
384→192
BatchNorm, ReLU
Classification Head
FC Layer 4
192→96
ReLU, Dropout
FC Layer 5
96→output
Sigmoid
Exercise Criteria
Binary Pre-
dictions
Figure 6: Multi-Modal Feature Fusion Architecture. Com-
plementary feature sets are progressively combined and re-
fined through fully connected layers with normalization and
dimension reduction, culminating in a specialized classifi-
cation head that produces criterion-specific predictions.
The Multi-Modal Feature Fusion architecture, shown
in Figure 6, presents the integration of the comple-
mentary capabilities of visual and skeletal modalities.
This design leverages the broader contextual under-
standing provided by visual input alongside the fine-
grained joint-level insights derived from pose fea-
tures. Instead of relying solely on raw concatenation,
the architecture adopts a staged transformation pro-
cess, where each successive layer serves to refine and
compress the joint feature space, selectively retain-
ing the most informative cross-modal patterns. The
classification head produces independent probability
estimates for each assessment criterion, enabling de-
tailed feedback by accounting for the fact that differ-
ent aspects of movement correctness can occur inde-
pendently.
3.5 Training Strategy and
Implementation
A participant-based data splitting strategy was im-
plemented to ensure robust evaluation and prevent
data leakage. This approach segregated partici-
pants (rather than individual exercise repetitions) into
train/validation/test sets with ratios of 70/15/15. This
methodology is crucial for realistic performance as-
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
30

sessment as it prevents the model from recognizing
specific individuals’ movement patterns across data
splits, ensuring generalization to unseen participants.
Implementation utilized PyTorch with CUDA accel-
eration on NVIDIA P100 GPUs. Models were trained
with a batch size of 16, optimized using Adam with
an initial learning rate of 1e-4 and weight decay of
1e-5. Dynamic learning rate adjustment was imple-
mented through ReduceLROnPlateau scheduling, re-
ducing the learning rate by a factor of 0.5 when val-
idation loss plateaued for 5 consecutive epochs. Bi-
nary cross-entropy with logits loss served as the pri-
mary objective, complemented by gradient clipping
(max norm 1.0) and early stopping with a patience of
10 epochs to prevent overfitting.
4 RESULTS AND ANALYSIS
4.1 Evaluation Metrics
In this study, two primary metrics were utilized for
evaluating model performance: Hamming Loss and
F1-score. Hamming Loss quantifies classification er-
rors in multi-label tasks by measuring the fraction of
incorrectly predicted labels, where the labels repre-
sent the biomechanical criteria specific to each exer-
cise type:
HL =
1
N · L
N
∑
i=1
L
∑
j=1
I(y
i j
̸= ˆy
i j
) (3)
where N represents the number of samples, L denotes
the number of labels, y
i j
and ˆy
i j
are true and predicted
labels, and I(·) is the indicator function. Lower val-
ues indicate superior performance. F1-score was em-
ployed to assess precision-recall balance:
F1-score = 2 ·
Precision · Recall
Precision + Recall
(4)
4.2 Comparative Analysis of Model
Architectures
Table 4 presents a comprehensive cross-architecture
performance comparison, including both our pro-
posed multi-modal approach and several strong base-
line models implemented specifically for controlled
benchmarking. The results demonstrate multiple sig-
nificant findings across model architectures. First,
our proposed Multi-Modal architecture consistently
outperforms all alternatives across all three exercise
types, achieving average Hamming Loss reductions of
1.5%, 24.2%, and 12.3% compared to the best com-
peting approach (1D CNN-GRU + 3D ResNet (Chen
et al., 2023; Du et al., 2023)).
Among single-stream approaches, our biome-
chanical feature engineering strategy substantially
improved pose-based assessment, with combined an-
gle and distance features reducing Hamming Loss
by 32.6% for squats compared to raw landmarks.
The Vision-based model achieved a 65.5% lower
Hamming Loss than the optimized Pose-based model
for squats (0.0370 vs. 0.1074), demonstrating the
strength of 3D convolutional networks (Du et al.,
2023) in capturing visual cues, which skeletal data
miss. The superior performance of the Multi-Modal
model reflects its ability to fuse detailed biomechan-
ical features with broader visual context, offering a
more complete view of exercise quality.
4.3 Biomechanical Criteria Analysis
The tables (5, 6, 7) analyze model performance across
specific exercise criteria, revealing distinct modality
capabilities.
Biomechanical criteria analysis reveals distinct,
complementary strengths across modalities. In squat
assessment (Table 5), the Pose-based backbone ex-
cels at precise joint relationships, achieving perfect
classification for ”hip/knee simultaneous bend” (HL:
0.0000), while the Vision-based backbone demon-
strates superior capability for contextual understand-
ing, perfectly classifying “hips moving backward,”
“neutral lower back,” and “hips below knee level.”
This dichotomy illustrates how skeletal representa-
tions effectively encode explicit biomechanical re-
lationships, while 3D convolutions capture holistic
movement qualities that transcend landmark data.
In the deadlift assessment (Table 6), each
biomechanical criterion highlights modality-specific
strengths. The Pose-based model excels in ”Balance”
(HL: 0.1220 vs. 0.1463 for Vision), suggesting skele-
tal landmarks better capture stability. Conversely,
”Control reverse” sees an 83% error reduction from
Pose to Vision (HL: 0.2927 to 0.0488), emphasiz-
ing Vision’s advantage in modeling temporal dynam-
ics. Vision also achieves perfect classification (HL:
0.0000) for ”Straight back” and ”Knee bent,” key for
injury prevention. For ”Leg extension,” the Multi-
Modal model improves on Vision (25% error reduc-
tion), showing the benefit of integrating both modali-
ties for complex joint and motion assessments.
The lunge exercise (Table 7) highlights this com-
plementarity most dramatically, with the Vision-
based approach achieving 90% error reduction for
“back knee position” compared to the Pose-based ap-
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for Automated Exercise Evaluation
31
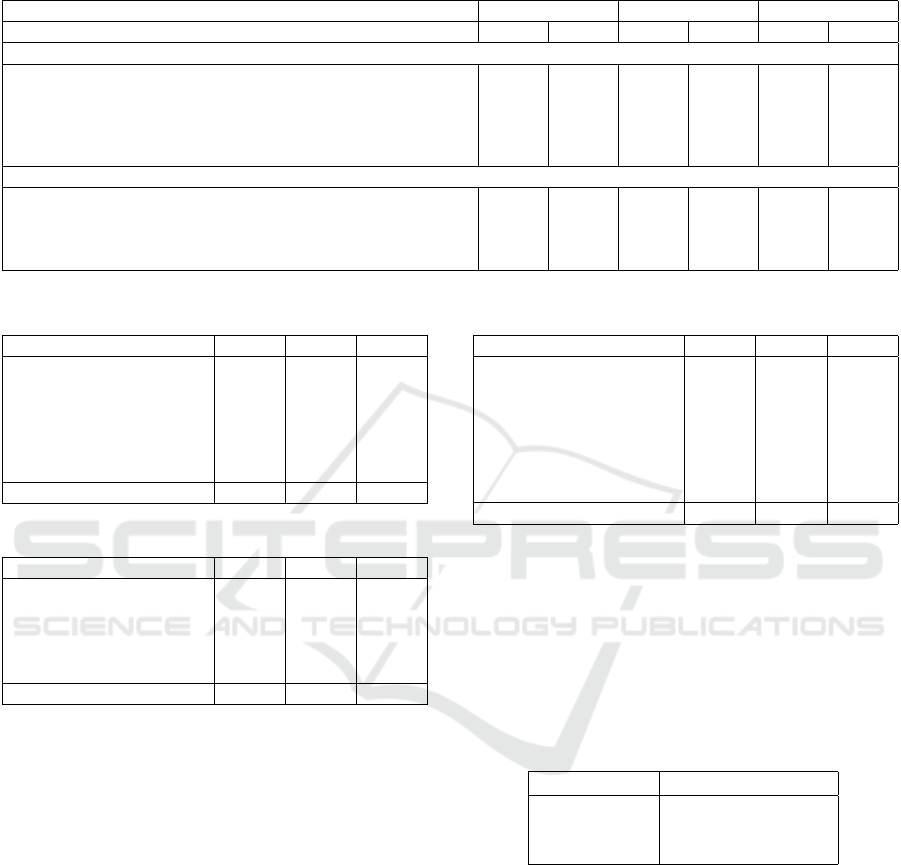
Table 4: Cross-architecture performance comparison. The single-stream models and multi-modal approaches shown here
represent custom baseline implementations developed specifically for this study to enable controlled comparison against our
proposed architecture.
Model Squat Deadlift Lunges
HL F1 HL F1 HL F1
Single-Stream Models
Pose (Raw) 0.1593 0.8232 0.2000 0.7232 0.2689 0.6814
Pose (Distances) 0.1519 0.8211 0.1902 0.7054 0.2689 0.6949
Pose (Angles) 0.1296 0.8502 0.1805 0.7099 0.2521 0.6794
Pose (Angles+Distances) 0.1074 0.8795 0.1463 0.7865 0.2521 0.7139
Vision-Based (3D ResNet) (Du et al., 2023) 0.0370 0.9583 0.0585 0.9217 0.1008 0.8805
Competing Multi-Modal Approaches
1D CNN-GRU + ViT (Chen et al., 2023) 0.0481 0.9502 0.1073 0.9276 0.1681 0.8837
2D CNN + ViT (Arnab et al., 2021) 0.0444 0.9665 0.0927 0.9377 0.1597 0.8862
1D CNN-GRU + 3D ResNet (Chen et al., 2023; Du et al., 2023) 0.0263 0.9694 0.0644 0.9303 0.0862 0.8947
Multi-Modal (Proposed) 0.0259 0.9706 0.0488 0.9347 0.0756 0.9097
Table 5: Squat biomechanical criteria Hamming loss.
Biomechanical Criterion Pose Vision Multi
Feet flat 0.2000 0.0444 0.0667
Hip/knee bend 0.0000 0.0444 0.0000
Hips backward 0.1111 0.0000 0.0000
Neutral back 0.1111 0.0000 0.0000
Hips below knee 0.0222 0.0000 0.0000
Feet angled 0.2000 0.1333 0.0889
Overall 0.1074 0.0370 0.0259
Table 6: Deadlift biomechanical criteria Hamming loss.
Biomechanical Criterion Pose Vision Multi
Balance 0.1220 0.1463 0.1220
Straight back 0.0244 0.0000 0.0000
Leg extension 0.1951 0.0976 0.0732
Control reverse 0.2927 0.0488 0.0488
Knee bent 0.0976 0.0000 0.0000
Overall 0.1463 0.0585 0.0488
proach (HL: 0.0588 vs. 0.5294)—demonstrating vi-
sion’s advantage where landmark detection proves
challenging. Similarly, for “head looking forward,”
the vision approach reduces error by 80% (HL:
0.0588 vs. 0.2941) by capturing orientation cues
poorly represented in skeletal models.
The Multi-Modal architecture effectively lever-
ages these complementary strengths, consistently out-
performing individual modalities across biomechani-
cal criteria. For complex criteria like “feet angled out-
ward” in squats, it delivers 33.3% improvement over
the Vision-based model and 55.6% over the Pose-
based model (HL: 0.0889 vs. 0.1333 and 0.2000),
while achieving perfect classification for “head look-
ing forward” in lunges where both individual modali-
ties exhibit errors.
Table 7: Lunge biomechanical criteria Hamming loss.
Biomechanical Criterion Pose Vision Multi
Heels width 0.2941 0.2353 0.2353
Head forward 0.2941 0.0588 0.0000
90° knee bend 0.2353 0.1176 0.0588
Arms swing 0.1765 0.0588 0.0588
Feet aligned 0.0588 0.0588 0.0588
Back straight 0.1765 0.1176 0.0588
Back knee pos. 0.5294 0.0588 0.0588
Overall 0.2521 0.1008 0.0756
4.4 Computational Efficiency Analysis
Edge deployment feasibility was evaluated on a Rasp-
berry Pi 4 (Quad-core Cortex-A72 @ 1.8GHz, 4GB
RAM) to simulate real-world portable applications
like mobile fitness apps and smart gym equipment.
Results are shown in Table 8.
Table 8: Inference Performance Metrics.
Model Inference Time (s)
Pose-Based 0.0192
Vision-Based 5.2748
Multi-Modal 5.6324
The Pose-based backbone demonstrates remark-
able computational efficiency (0.0192s per inference),
enabling real-time feedback on edge devices like
smartphone. In contrast, Vision-based and Multi-
Modal models exhibit significantly higher latencies
(5.27s and 5.63s), making them more suitable for
cloud-based processing or offline analysis. This
presents a practical deployment spectrum where the
Pose-based model could provide immediate feedback
during exercise sessions on resource-constrained de-
vices, while the more accurate Multi-Modal approach
could be employed for detailed post-workout analysis
or in scenarios where higher computational resources
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
32

are available. This accuracy-efficiency trade-off of-
fers flexibility in designing exercise assessment sys-
tems based on specific user requirements and hard-
ware constraints.
4.5 Key Findings
The comprehensive evaluation yields several impor-
tant conclusions:
• Multi-modal integration consistently outper-
forms single-modality and competing hybrid
approaches, with average Hamming Loss reduc-
tions of 30.0% compared to the Vision-based
backbone and 79.5% compared to the Pose-based
backbone.
• Feature engineering significantly enhances pose-
based assessment, with combined angle and dis-
tance features reducing Hamming Loss by 32.6%
for squats compared to raw landmark coordinates.
• The component backbones exhibit complemen-
tary strengths: the Vision-based component ex-
cels at capturing motion context and spatial
relationships, while the Pose-based component
demonstrates advantages in precise joint angle as-
sessment.
• Computational requirements vary dramatically
between components, with the Pose-based back-
bone offering 293× faster inference than the inte-
grated Multi-Modal system on edge devices.
5 CONCLUSION
This study presents ALEX-GYM-1, a novel multi-
camera view dataset with synchronized lateral and
frontal camera perspectives and criterion-specific an-
notations for exercise assessment, alongside a hy-
brid architecture that integrates vision-based and
pose-based modalities for comprehensive evaluation.
Experimental results demonstrate the Multi-Modal
approach’s superior performance, achieving 30.0%
and 79.5% Hamming Loss reductions compared to
Vision-based and Pose-based models respectively.
Biomechanical criteria analysis revealed complemen-
tary strengths across modalities: Vision-based com-
ponents excel at contextual elements (90% error re-
duction for back knee positioning), while Pose-based
components demonstrate precision in joint relation-
ships (perfect classification for hip/knee simultane-
ous bend). The computational efficiency evaluation
established a deployment spectrum from lightweight
Pose-based systems (0.0192s inference) suitable for
real-time applications to high-accuracy Multi-Modal
architectures (5.6324s) for detailed analysis. These
findings validate the hypothesis that multi-modal in-
tegration transcends single-modality limitations, es-
tablishing a new benchmark in automated exercise
assessment. Future work will focus on optimiz-
ing the architecture for reduced latency ,and expand-
ing the dataset with diverse biomechanical scenar-
ios to further enhance assessment capabilities across
fitness monitoring, rehabilitation, and personalized
training applications. Future work will focus on fur-
ther optimizing the architecture for reduced latency
and expanding the dataset to improve generalizability
and performance. While the current dataset is suf-
ficient for validating and benchmarking different ar-
chitectures across three specific exercises, deploying
production-ready models will require a significantly
larger and more diverse dataset. This includes incor-
porating a wider range of exercise types and biome-
chanical scenarios to ensure robust performance in
real-world applications.
Regarding latency optimization, while the pose-
based modality already shows strong efficiency on
resource-constrained hardware, further improvements
will focus on the vision-based modality. With proper
architectural tuning, the vision-based branch can be
optimized for lower latency, enabling the use of more
accurate, real-time systems even on limited hardware.
This broadens the potential for deployment on edge
and mobile devices
AVAILABILITY
The proposed method and the ALEX-GYM-1 dataset
are publicly available. Please refer to the dataset via
the citation (Hassan et al., 2025).
ACKNOWLEDGMENTS
This work is Funded by the Science and Technology
Development Fund STDF (Egypt); Project id: 51399
- “VERAS: Virtual Exercise Recognition and Assess-
ment System”.
REFERENCES
Arnab, A. et al. (2021). Vivit: A video vision transformer.
In Proceedings of the IEEE/CVF International Con-
ference on Computer Vision, pages 6836–6846.
Baradel, F., Wolf, C., and Mille, J. (2018). Human activity
recognition with pose-driven attention to rgb. In Proc.
BMVC 2018-29th Brit. Mach. Vision Conf.
ALEX-GYM-1: A Novel Dataset and Hybrid 3D Pose Vision Model for Automated Exercise Evaluation
33

Cao, Z., Hidalgo, G., Simon, T., Wei, S.-E., and Sheikh,
Y. (2019). Openpose: Realtime multi-person 2d pose
estimation using part affinity fields.
Capecci, M., Ceravolo, M. G., Ferracuti, F., Iarlori, S.,
Monteri
`
u, A., Romeo, L., and Verdini, F. (2019). The
kimore dataset: Kinematic assessment of movement
and clinical scores for remote monitoring of physi-
cal rehabilitation. IEEE Trans. Neural Syst. Rehabil.
Eng., 27(7):1436–1448.
Chen, C., Jafari, R., and Kehtarnavaz, N. (2015). Utd-mhad:
A multimodal dataset for human action recognition
utilizing a depth camera and a wearable inertial sen-
sor. In Proc. IEEE Int. Conf. Image Process. (ICIP),
pages 168–172.
Chen, J. et al. (2023). Vision transformer with gru for action
recognition in skeleton sequences. Neurocomputing.
Clark, R. A. et al. (2021). The use of wearable technology
and computer vision for movement analysis and injury
prevention in sport. J. Sports Sci., 39(5):533–544.
Dosovitskiy, A. et al. (2020). An image is worth 16x16
words: Transformers for image recognition at scale.
arXiv preprint arXiv:2010.11929.
Du, X., Li, Y., Cui, Y., Qian, R., Li, J., and Bello, I. (2023).
Revisiting 3d resnets for video recognition. In Pro-
ceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition, pages 2889–2899.
Duong-Trung, N., Kotte, H., and Kravcik, M. (2023). Aug-
mented intelligence in tutoring systems: A case study
in real-time pose tracking to enhance the self-learning
of fitness exercises. In Responsive and Sustainable
Educational Futures, pages 705–710. Springer.
Ganesh, P., Idgahi, R., Venkatesh, C., Babu, A., and
Kyrarini, M. (2020). Personalized system for human
gym activity recognition using an rgb camera. In Pro-
ceedings of the 13th ACM International Conference
on PErvasive Technologies Related to Assistive Envi-
ronments, pages 1–7.
Ghorbani, S., Mahdaviani, K., Thaler, A., Kording, K.,
Cook, D. J., Blohm, G., and Troje, N. F. (2021).
Movi: A large multi-purpose human motion and video
dataset. PLOS ONE, 16(6):e0253157.
Hassan, A., Serour, A., Gamea, A., and Gomaa, W. (2025).
Alex-gym-1: A multi-camera dataset for automated
evaluation of exercise form. GitHub. Accessed: 2025-
07-21.
Kaseris, M., Kostavelis, I., and Malassiotis, S. (2024). A
comprehensive survey on deep learning methods in
human activity recognition. Machine Learning and
Knowledge Extraction, 6(2):842–876.
Keogh, J. W. and Winwood, P. W. (2017). The epidemi-
ology of injuries across the weight-training sports.
Sports Med., 47(3):479–501.
Khan, I. U., Afzal, S., and Lee, J. W. (2022). Human activ-
ity recognition via hybrid deep learning-based model.
Sensors, 22(1):323.
Kotte, H., Kravcik, M., and Duong-Trung, N. (2023). Real-
time posture correction in gym exercises: A computer
vision-based approach for performance analysis, error
classification and feedback. International Journal of
Artificial Intelligence in Education.
Neha, D. and Manju, D. (2023). Virtual fitness trainer us-
ing artificial intelligence. International Journal for
Research in Applied Science and Engineering Tech-
nology, 11(3):1499–1507.
Sharshar, A., Fayez, A., Eitta, A. A., and Gomaa, W. (2022).
Mm-dos: A novel dataset of workout activities. In
2022 International Joint Conference on Neural Net-
works (IJCNN), pages 1–8. IEEE.
Wijekoon, A., Wiratunga, N., and Cooper, K. (2019). MEx
[dataset]. https://doi.org/10.24432/C59K6T. UCI Ma-
chine Learning Repository.
Winwood, P. W., Hume, P. A., Cronin, J. B., and Keogh, J.
W. L. (2014). Retrospective injury epidemiology of
strongman athletes. Journal of Strength and Condi-
tioning Research, 28(1):28–42.
Wushao, W., Hefu, S., and Hanxiang, Z. (2000). An epi-
demiological survey and comparative study of the in-
juries in weightlifting. Sports Science, 20(4):44–46.
Youssef, F., Parque, V., and Gomaa, W. (2023). Vcoach:
A virtual coaching system based on visual streaming.
Procedia Computer Science, 222:207–216.
Zhang, C., Liu, L., Yao, M., Chen, W., Chen, D., and Wu, Y.
(2021). Hsipu2: A new human physical fitness action
dataset for recognition and 3d reconstruction evalua-
tion. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern
Recognit. Workshops (CVPRW), pages 481–489.
ICINCO 2025 - 22nd International Conference on Informatics in Control, Automation and Robotics
34
