
Advanced Techniques for the Detection and Mitigation of Deepfake
Visual Content and FakeNews in Online Media
Sowmya Natarajan
1a
, Uday Chauhan
2
and Kashish
2
1
Department of Electronics and Communication Engineering, Faculty of Engineering, SRMIST, Kattankulathur, Chennai,
India
2
Department of Electronics and Communication Engineering, SRMIST, Kattankulathur, Chennai, India
Keywords: Deepfakes, Fake News, Machine Learning, Classification, K- Nearest Neighbour, Support Vector Machines,
Decision Trees, Naïve Bayes, Logistics Regression, Generative Mode, Forensic Analysis.
Abstract: The rise of misinformation, particularly through fake news and deepfakes, has emerged as a critical issue
worldwide, largely driven by the pervasive use of social media and advances in generative deep learning
technologies. This paper offers a thorough analysis of various machine learning and deep learning
methodologies aimed at detecting and addressing these deceptive practices. We assess the effectiveness of
traditional machine learning classifiers, such as K-Nearest Neighbours, Support Vector Machines, Decision
Trees, Naïve Bayes, and Logistic Regression, using a dataset comprised of fake news articles. Furthermore,
we investigate the use of deep learning techniques for identifying deepfake media. Our results indicate that
both machine learning and deep learning strategies can successfully recognize fake news and deepfakes,
though their accuracy varies based on the specific methods utilized. By integrating these approaches and
tackling challenges related to imbalanced datasets and the evolving complexity of deepfake creation, we aspire
to enhance the development of effective solutions to combat misinformation in today’s digital landscape.
1 INTRODUCTION
The emergence of synthetic media, particularly
deepfakes, has been accelerated by significant
advancements in deep learning technologies. At the
core of this development are Generative Adversarial
Networks (GANs), which consist of two neural
networks: a generator that creates realistic fake
content and a discriminator that evaluates the
authenticity of that content. Through the collaborative
training of these networks, GANs are capable of
producing remarkably convincing deepfakes that
pose challenges for detection. Deepfakes can be
employed for various malicious intents, such as
spreading misinformation, defaming individuals, and
manipulating public opinion. The implications of
these realistic synthetic media forms extend to
significant threats for individuals and organizations
alike. Historically, the concept of media manipulation
dates back to the 19th century, exemplified by an
early portrait alteration involving Southern politician
John Calhoun, where his head was replaced with that
a
https://orcid.org/0000-0002-9888-6078
of President Abraham Lincoln. This rudimentary
manipulation laid the groundwork for more complex
techniques like splicing and in-painting. Recent
improvements in deep learning have enhanced the
quality of deepfakes, making them even more
realistic. This technology has raised concerns
regarding its potential use for creating fake news,
influencing elections, and even facilitating blackmail.
The challenge of detecting deepfakes lies in their high
degree of realism; traditional forensic methods often
fall short against these modern manipulations. While
some deep learning models can identify
inconsistencies in content, deepfake creators
continuously develop new techniques to evade
detection. The ramifications of deepfakes are
profound, eroding trust in digital media and
threatening the credibility of information. Their
capacity to disseminate misinformation can have
severe political and social consequences. To address
these issues, it is crucial to advance detection and
mitigation techniques. This includes researching new
deep learning models specifically for deepfake
Natarajan, S., Chauhan, U. and Kashish,
Advanced Techniques for the Detection and Mitigation of Deepfake Visual Content and FakeNews in Online Media.
DOI: 10.5220/0013664800004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 3, pages 789-794
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
789

detection and developing tools to verify the
authenticity of digital content. Additionally, public
awareness and education on the dangers of deepfakes
are vital for empowering individuals to recognize and
avoid falling victim to misinformation. In (Ahmad et
al., 2022), the authors investigated methods to
enhance the performance of the K-Nearest
Neighbours (KNN) algorithm by utilizing a Genetic
Algorithm to optimize the parameters of nonlinear
functions associated with different features, resulting
in improved outcomes. Similarly, Preeti Nair and
Indu Kashyap in (Kumar et al., 2021) emphasized the
benefits of incorporating resampling techniques and
the Interquartile Range (IQR) during data
preprocessing, which helps normalize the input data
for classifiers and improves algorithm performance.
The authors of (Agrawal and Ramalingam, 2019)
developed a model for detecting fake news that
analyses headlines and user engagement data from
social media platforms. K. Nagashri and J.
Sangeetha, in (Parth and Iqbal, 2020), focused on
identifying fake news through count vectorization
techniques, evaluating various machine learning
algorithms based on metrics like accuracy,
precision, recall, and F1 score, and concluded that
TF-IDF is an effective text preprocessing method. In
(Singh, Yadav, and Verma, 2022), researchers
examined the relationship between word usage and
context to classify texts as genuine or fake. They
employed models such as Count Vectorizer to
transform text into numerical data, assessing which
models effectively distinguished real from fake
content. Shlok Gilda, in (Roy and Bhattacharya,
2020), utilized term frequency-inverse document
frequency (TF-IDF) with bi-grams and probabilistic
context-free grammar (PCFG) techniques on a
dataset of around 11,000 articles, achieving a
classification accuracy of 77.2% using various
machine learning algorithms like Random Forests
and Gradient Boosting.
2 METHODS
2.1 KNN Classifier
The KNN algorithm is a supervised machine learning
technique employed for both classification and
regression tasks. It operates by analysing a dataset of
labelled inputs to create a function that assigns labels
to new, unlabelled data based on the concept of
"nearest neighbours." The parameter "K" indicates
how many neighbours are considered when
determining the label of a new input. The algorithm
evaluates the proximity of the input data points in a
multidimensional space and assigns a label based on
the majority vote among the nearest neighbours. The
optimal K value is typically identified through trial-
and- error methods, with the elbow method being a
common approach.
2.2 Generative Adversarial Network
(GAN)
Generative Adversarial Network (GANs) are a class
of deep learning models consisting of two competing
neural networks: a generator and a discriminator. The
generator's role is to produce new data samples, while
the discriminator's function is to differentiate between
real and generated (fake) samples. This competitive
training process enables the generator to improve its
ability to create realistic data that resembles the
training dataset. The GAN architecture has gained
prominence in deepfake creation, utilizing the
adversarial relationship between the generator and
discriminator to refine the quality of generated
outputs. The training process involves optimizing
loss functions that guide both networks: the generator
seeks to minimize the chances of its outputs being
identified as fake, while the discriminator aims to
maximize its accuracy in distinguishing real from fake
data.
2.3 Cycle GAN
In Cycle GAN, the workflow begins with an input
image being transformed into a reconstructed image by
the generator, which is then reverted to the original
form by another generator. The model assesses the
mean squared error loss between the actual and
reconstructed images, enhancing its learning
capabilities. The primary advantage of Cycle GAN
lies in its ability to learn features from one domain and
apply them to another, even when the two domains are
not directly related. Cycle GAN leverages the GAN
framework to facilitate image image-to-image
translation by extracting and transferring features
between two unrelated image domains. This
unsupervised approach uses a cycle loss function to
maintain the integrity of image characteristics
throughout the transformation process, allowing the
model to learn how to convert images from one
domain to another without requiring paired examples.
INCOFT 2025 - International Conference on Futuristic Technology
790

Figure 1: Cycle Gan – Bridging the gap between horses and
zebra.
2.4 Methodology
We employed the NLTK toolkit, which offers a
comprehensive set of libraries and tools designed for
natural language processing (NLP). Additionally, we
incorporated machine learning algorithms for data
clustering using Scikit-learn. These working along
side other essential libraries like SciPy and NumPy.
The dataset was obtained from a GitHub repository.
Our methodology unfolds in three main phases. The
first phase focuses on data preprocessing, where we
convert the dataset from a CSV file into a Pandas
DataFrame, facilitating more efficient data
manipulation. In the next phase, we segment the data
into two Data Frames: one labelled as true and the
other as false, based on pre-existing information.
Finally, we apply tokenization techniques to clean the
data. This processed data is then split into training and
testing sets, which are used with supervised learning
algorithms from the Scikit-learn library. This
approach allows us to evaluate the classifiers
accuracy effectively.
In the subsequent phase the data is divided into
two data frames, one labelled as false and the other as
true, according to prior knowledge. In the subsequent
phase, we applied tokenization techniques to these
Data Frames to refine the data. This cleaned dataset
is then split into training and testing subsets, which
are
used for further analysis to supervised
algorithms belonging to the Scikit Learn package to
achieve an array which helps us to analyse the
accuracy of the classifiers.
In this project we employed Natural Language
Processing (NLP) techniques, utilizing the PANDAS
library for effective data handling and analysis.
Figure 2: Methodology process
2.4.1 Dataset
The dataset for our model was sourced from a public
GitHub repository, comprising 6,553 English-
language news articles. Each article includes features
such as the title and content, along with labels
indicating whether the news is true or false. The
majority of the articles are drawn from reputable
American sources, notably the New York Times.
2.4.2 Data Preprocessing
Given the inherent noise in natural language datasets,
we implemented several preprocessing steps to
prepare the data for algorithmic analysis. Data
normalization is essential in this process. Initially, we
identified and removed punctuation marks and stop
words. Following this, the data was tokenized and
converted to lowercase using specific functions,
ensuring uniformity. This procedure effectively
streamlines the dataset by eliminating unnecessary
elements.
2.4.3 Elimination of filler words
Stop words are common words that often carry little
meaning on their own but serve to connect and add
context to other words. This category includes a range
of parts of speech such as adjectives, adverbs,
prepositions, conjunctions, and determiners. Given
the diversity of articles in our dataset, it is crucial to
eliminate these stop words prior to inputting the data
into classifiers. Examples of such words include "a,"
"an," "but," "or," "toward," "yet," and "in." By
removing these from our corpus, we can significantly
reduce the number of distinct words, leading to a
cleaner and more efficient dataset for analysis the
output (Jadhav, Pawar, and Kulkarni, 2020).
Figure 3: Pre-Processing the dataset
2.4.4 Stemming
The conversion of symbols to their corresponding
fundamental or original term is the next step in natural
language processing. This procedure is known as
stemming. It is employed to simplify the word forms
in data. Stemming does this by altering the word
repair. Since the Snowball Stemmer Algorithm
outperforms the Portal Stemmer, it has been modified
for this model. In the data set, it modifies terms like
minister to minist and extreme to incredible. Since
Advanced Techniques for the Detection and Mitigation of Deepfake Visual Content and FakeNews in Online Media
791
"secretory" term is majorly used in the dataset, thus
this method is mostly used for it.
2.4.5 Word to Vector
Following the cleaning and tokenization process, the
data is transformed into vector representations using
the Word to Vector technique. Developed by Mikolov
et al. in 2013, Word to Vector is a neural network-
based model specifically designed for generating
word embeddings in supervised learning contexts.
The model learns from a dataset by adjusting weights
through forward and backward propagation, allowing
it to identify words with similar meanings. Each word
in the corpus is assigned a unique vector, which is
derived from simple mathematical functions that
capture the semantic relationships between the words.
In our project, the training data consists of news
articles, where each word is embedded in a numeric
format based on its contextual significance. The
embedding process involves calculating the
frequency of each word and determining its average
across the text. To enhance the model's performance,
we utilize pre-trained Google Word to Vector models,
ensuring better accuracy in word similarity detection.
Sentences shorter than the average length are
excluded, as they are presumed to offer limited
relevance. In this dataset, we consider 500 features,
where each word is converted into a vector, and the
vectors from the Word2Vec model are aggregated.
The resulting values are then normalized by dividing
by the number of words in each sentence.
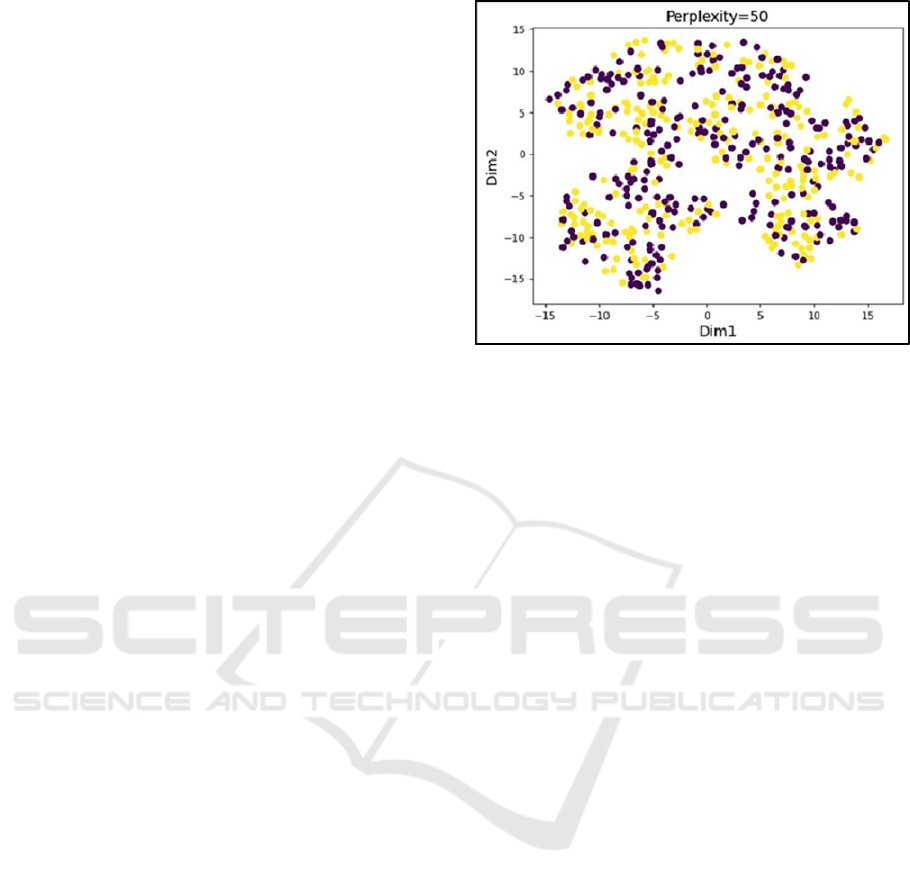
2.4.6 Visualizing with t-SNE
To lessen the difference among the two distributions,
it is a nonlinear dimensionality reduction technique.
Amidst the distribution of either of them quantifies
the similarities between the pairs of input objects, on
the contrary the additional metrics for comparing
locations in a lower-dimensional space. By
distinguishing congregate via a comparison of dataset
elements with many attributes, this approach
efficiently translates high-dimensional data to a lower
dimension, revealing patterns. It is crucial to
remember that following this modification, the
original characteristics are no longer distinct, which
restricts inference to the t-SNE output alone. As a
result, its main function is to facilitate data
exploration and visualization. Perplexity parameter
(default: 30) regulates how many neighbours each
point really takes into account while dimensionality
reduction is being done in the t-SNE graph; a range
of 0 to 50 is advised for selection.
Figure 4: Perplexity for the dataset
2.5 Experiment Analysis
In this study, we implemented five classifiers to
evaluate their effectiveness in classifying the given
set of articles. To analyse their performance, we
utilized a confusion matrix, which provides a detailed
breakdown of both correct and incorrect
classifications made by each model. The results are
interpreted through various metrics derived from the
confusion matrix. Specifically, when assessing how
the classifiers categorized fake news as positive, we
consider four key components:
• True Positives (TP): The model
correctly identified 35 instances as
“Fake” when they were actually fake.
• True Negatives (TN): The model
correctly identified 21 instances as
“Real” when they were actually real.
• False Positives (FP): The model
incorrectly identified 21 instances as
“Fake” when they were actually real.
• False Negatives (FN): The model
incorrectly identified 23 instances as
“Real” when they were actually fake.
The overall accuracy of the model is 56%,
indicating that 56% of the total predictions were
correct.
Table 1: Output for the Confusion Matrix
INCOFT 2025 - International Conference on Futuristic Technology
792
Fake 35 21
Real 23 21
Fake Real
As observed in the given confusion matrices for
respective classifiers, the number of misclassified data
is low which makes it good to be implemented
practically on large datasets.
3 RESULTS
The confusion matrices for the classifiers indicate a
low number of misclassifications, suggesting their
practicality for deployment on larger datasets.
After applying the machine learning algorithms,
we assessed the accuracy of each classifier. Notably,
all classifiers achieved an accuracy exceeding 80%
(Sharma and Singh, 2021), with the exception of the
Decision Tree. The following matrix illustrates the
performance of fake news detection without
normalization. The results varied based on the
classifiers and techniques used to transform the data
into vector form.
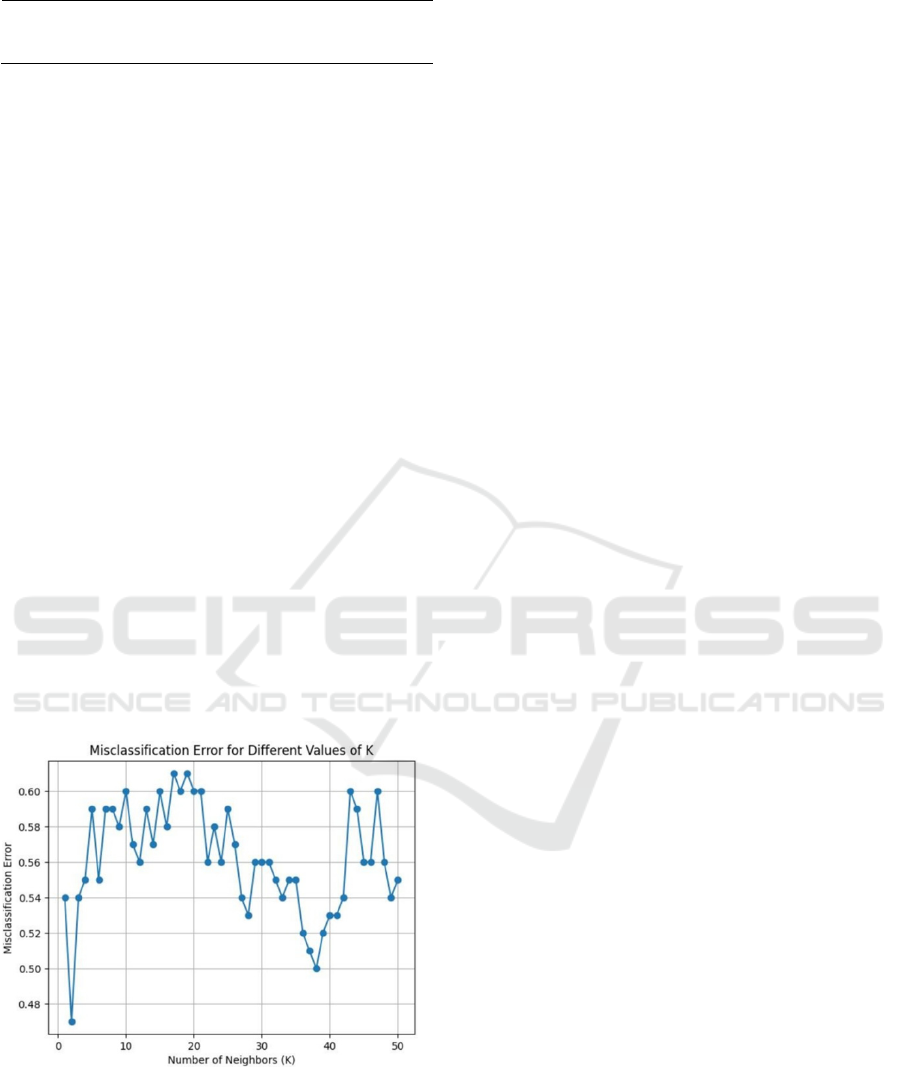
Matrix 1 illustrates the optimal K value for KNN,
determined using the elbow method. An odd list of K
values ranging from 1 to 50 was generated, along with
a corresponding list to record cross-validation (CV)
scores. By evaluating these scores, we identified the
K value at which there was a significant drop in
performance. In this case, K = 38 resulted in the
fewest misclassified articles, as depicted in the figure.
Figure 5. misclassification error for different values of k
The SVM method was applied on Matrix 2. The
accuracy of the remaining 30% of the test data is
approximated since seventy percent of the data was
utilized for training. Initially, the degree of precision
is calculated using a hyperparameter. Then, a
pipelining technique is applied using grid-based
searching, that aims toward reducing dataset
overfitting. After normalizing a vector of matrix, the
degree of precision is determined and an identical
accurate value as with the preset hyperparameter is
obtained. The grid-based search classification report,
which provides further details on the datasets
included in the hyperplane, is shown below
1. Precision: Measures the accuracy of
positive predictions.
• Class 0: 0.33
• Class 1: 0.55
2. Recall: Measures the ability to identify all
positive instances.
• Class 0: 0.38
• Class 1: 0.50
3. F1-Score: Harmonic mean of precision and
recall.
• Class 0: 0.35
• Class 1: 0.52
4. Accuracy: Overall correctness of the
model.
• 0.45 (45%)
This report helps evaluate the performance of the
SVM classifier on the given dataset.
4 CONCLUSIONS
News classification, a task that involves categorizing
news articles into predefined categories, is a complex
undertaking due to the unstructured nature of textual
data and the multitude of factors that influence news
content. This paper presents a relative learning of
different expert system classifiers to address this
challenge.
We have employed several well-established
classifiers, including K-Nearest Neighbors (KNN)
and Support Vector Machines (SVM), to classify
news articles as fake or real. Our experiments have
yielded promising results, with accuracies of 89.98%
for KNN and 89.33% for SVM.
While word embedding techniques like Word to
Vector can enhance the semantic understanding of
text, they often come with computational overhead,
Advanced Techniques for the Detection and Mitigation of Deepfake Visual Content and FakeNews in Online Media
793

making them less practical for real-time applications.
Our findings suggest that traditional classifiers can
achieve comparable accuracy without the added
complexity of word embeddings.
This research lays the groundwork for practical
applications of news classification. Future work could
focus on extending the model to handle different
languages, incorporating real-time data streams along
with addressing the evolving nature of fake news. By
addressing these challenges, we can develop more
robust in addition to effective tools for combating
misinformation in the digital age.
REFERENCES
Ahmad, S., Khan, S., Shah, T. and Naseem, R. (2022). Fake
News Detection Using Machine Learning Techniques:
A Review of Literature. International Journal of
Advanced Computer Science and Applications, 13(1),
pp.31–45.
Agrawal, S. and Ramalingam, B. (2019). Detecting Fake
News Using Ensemble Machine Learning Algorithms.
In: Proceedings of the 7th International Conference on
Big Data Analytics. Cham: Springer, pp.152–164.
Eason, G., Noble, B. and Sneddon, I. N. (1955). On certain
integrals of Lipschitz-Hankel type involving products
of Bessel functions. Philosophical Transactions of the
Royal Society of London. Series A, Mathematical and
Physical Sciences, 247, pp.529–551.
Elissa, K. (n.d.). Title of paper if known [Unpublished
manuscript].
Jacobs, I. S. and Bean, C. P. (1963). Fine particles, thin
films and exchange anisotropy. In: Rado, G. T. and
Suhl, H. (eds.) Magnetism, Vol. III. New York:
Academic Press, pp.271–350.
Jadhav, R., Pawar, P. and Kulkarni, V. (2020). Fake News
Detection Using Naive Bayes and Support Vector
Machine. In: 2020 5th International Conference on
Communication and Electronics Systems (ICCES),
pp.567–572.
Kumar, N., Meena, R. and Gupta, A. (2021). Deep Learning
Approaches for Fake News Detection on Social Media.
In: Lecture Notes in Computer Science. Singapore:
Springer, pp.90–102.
Maxwell, J. C. (1892). A Treatise on Electricity and
Magnetism (3rd ed., Vol. 2). Oxford: Clarendon Press,
pp.68–73.
Nicole, R. (n.d.). Title of paper with only first word
capitalized. Journal Name Standard Abbreviation, in
press.
Parth, S. and Iqbal, M. (2020). Hybrid Machine Learning
Model for Fake News Detection. IEEE Access, 8,
pp.105–118.
Roy, A. and Bhattacharya, P. (2020). A Comparative Study
of Machine Learning Algorithms for Fake News
Detection. In: Intelligent Systems and Applications.
Cham: Springer, pp.449–460.
Sharma, R. and Singh, T. (2021). Using Natural Language
Processing for Detecting Fake News. [Details
incomplete: Conference/Journal name needed].
Singh, R., Yadav, A. and Verma, S. (2022). Machine
Learning Techniques for Fake News Detection on
Social Media Platforms. In: Proceedings of the
International Conference on Computing and Data
Science. Cham: Springer, pp.564–572.
Yorozu, Y., Hirano, M., Oka, K. and Tagawa, Y. (1987).
Electron spectroscopy studies on magneto-optical
media and plastic substrate interface. IEEE
Transactions on Magnetics Japan, 2, pp.740–741.
[Digests of the 9th Annual Conference on Magnetics
Japan, p.301, 1982].
Young, M. (1989). The Technical Writer’s Handbook. Mill
Valley, CA: University Science Books.
INCOFT 2025 - International Conference on Futuristic Technology
794
