
Process Chain for Artificial Intelligence-Based Demand Forecasting
and Procurement Scheduling
Maximilian Hohn
a
, and Philipp Maximilian Sieberg
b
Chair of Mechatronics, University of Duisburg-Essen, Lotharstr. 1, 47057 Duisburg, Germany
Keywords: Artificial Intelligence, Machine Learning, Supplay Chain Management, Risk Management, Predictive
Analytics, Probabilistic Modeling, Demand Forecasting, Procurement Scheduling, Procurement Planning,
Logistics, Inventory Management, Business Intelligence, Explainable AI.
Abstract: This position paper introduces a conceptual general process chain for leveraging artificial intelligence (AI) in
demand prediction and procurement scheduling for small and medium-sized enterprises (SME). While AI
offers significant advantages, such as reducing inventory costs, improving delivery reliability, and optimizing
logistics, its adoption in SME is hindered by limited expertise, restricted access to AI tools, and psychological
barriers like trust and acceptance. The proposed framework integrates probabilistic modeling, clustering
algorithms, feature extraction methods and temperature scaling to enhance prediction accuracy and efficiency.
By aggregating demand forecasts, the system enables risk-adjusted and cashflow-optimized scheduling. A
preliminary result is presented, demonstrating robust predictions within confidence intervals. While the
findings are preliminary, this paper highlights the transformative potential of AI in SME scheduling and
outlines future research directions, including model optimization and the integration of explainable AI
methods to further enhance traceability and user acceptance.
1 INTRODUCTION
The field of artificial intelligence (AI) has emerged as
a pivotal technology for numerous automated systems
and data-driven algorithms, offering significant
potential for enhancing business processes across
various sectors, including large corporations and
small- and medium-sized enterprises (SME).
According to an expert survey, the foremost
opportunities for AI in SME are projected to lie in the
domains of optimizing distribution and logistics and
enhancing process efficiency (Lundborg et al., 2023;
WIK GmbH, 2019). While the processing of goods
can vary significantly depending on the specific
industry, many procurements and scheduling
processes in the manufacturing industry maintain a
high degree of similarity. These processes are often
driven by factors such as market conditions, order
volume, and company-specific circumstances. The
overarching objective of procurement scheduling is to
optimize service quality, particularly delivery
reliability while minimizing capital expenditures,
a
https://orcid.org/0009-0002-9580-7650
b
https://orcid.org/0000-0002-4017-1352
resource utilization and inventory holding costs.
While the prioritization of these factors varies across
individuals, their overall relevance remains consistent
across all domains. The economic activity of the
manufacturing industry is defined as the treatment or
processing of products for the purpose of
manufacturing or refining products. Procurement
planning and organization is a prerequisite for the
value creation process. In the context of SME,
procurement planning often consists of a separate
department that regulates procurement depending on
demand. The central task is to define the order
quantity and the order time and to organize the
transport to some extent. In SME, this process is
predominantly executed manually, relying on
employees' experiential knowledge. However, this
experiential knowledge is vulnerable to fluctuation
when employees depart from the company.
Moreover, complex issues such as market
fluctuations or demand variations may not be fully
integrated into employees' experiential knowledge.
Large volumes of data accumulate in the planning and
724
Hohn, M., Sieberg and P. M.
Process Chain for Artificial Intelligence-Based Demand Forecasting and Procurement Scheduling.
DOI: 10.5220/0013647700003967
In Proceedings of the 14th International Conference on Data Science, Technology and Applications (DATA 2025), pages 724-731
ISBN: 978-989-758-758-0; ISSN: 2184-285X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

purchasing departments, which are often incomplete,
inaccessible, or underutilized. The advent of
technological progress, the proliferation of data, and
the emergence of sophisticated algorithms in the big
data domain have rendered extensive analyses and
models viable tools for process optimization in
procurement scheduling. Given the capacity of
planners to consider a limited amount of data during
the decision-making process, the development of
prediction models and efficient algorithms for data
preparation and feature extraction is imperative to
optimize processes (Allal-Chérif et al., 2021;
Baryannis et al., 2019).
The integration of AI into various sectors of industry
and research has been a subject of considerable
interest in recent years. According to a McKinsey
report from 2023, the global potential of AI is 17.1 to
25.6 trillion dollars (roughly 20% of global GDP),
making it a significant economic opportunity in
today's economic landscape (Chui et al., 2023). The
effectiveness of AI in the domain of supply chain
management has been a subject of notable attention
(McKinsey & Company, 2021). However, the
implementation of AI in SME is hindered by several
obstacles, primarily the lack of specialized expertise
and the challenges in accessing AI as a service (WIK
GmbH, 2019). While prominent companies
successfully develop and utilize AI services, such as
Forecast Pro (Business Forecast Systems, Inc.,
2025), and proprietary AI solutions to enhance their
own processes, there is a paucity of interest in
disseminating this knowledge to the public.
The primary benefit of the framework to be
developed lies in the reduction of stock levels and the
increase in delivery reliability through the use of AI,
especially for SME. While the economic benefit of
reducing stock can be quantified using a capital
replacement rate, the economic benefit of increasing
delivery reliability is difficult to quantify. An increase
in delivery reliability has a positive effect on the
expansion, stability, and interdependence of business
relationships. The successful implementation of AI in
supply chain management has been shown to result in
a 15% reduction in logistics costs, a 35% decrease in
stock levels, and a 65% improvement in service
quality (McKinsey & Company, 2021). A recent
study by Samuels confirms that the integration of AI
into supply chain management improves demand
forecasting, inventory optimization and decision-
making. This leads to lower inventory levels, cost
savings and higher delivery reliability, as AI enables
accurate forecasting, minimizes stock-outs and
reduces excess inventory (Samuels, 2024).
Global economic uncertainties and supply chain
disruptions in recent years have increased the need for
smart warehousing systems. Reports such as the
OECD SME and Entrepreneurship Outlook show that
SME worldwide are struggling with supply
bottlenecks and inefficient warehousing strategies,
resulting in high storage costs and limited flexibility
(OECD, 2023). The use of AI-supported scheduling
has the potential to meet these challenges. It
facilitates the early recognition of situations such as a
drop in demand and the implementation of suitable
measures. While the majority of German companies
perceive AI as a potential benefit, only a small
percentage of companies currently utilize existing
methods (Bitkom e. V., 2022). In addition to the
challenge of adapting existing solutions to the needs
and resources of SME, psychological constructs such
as acceptance and trust in AI solutions must
increasingly be considered. Studies show that
acceptance of AI drops when users see it as a control
tool or fear losing decision-making power and jobs.
This is especially true in small and medium-sized
enterprises, where long-standing routines often make
employees less open to change. To foster acceptance
of AI, these aspects must be addressed in technical
development.
The process chain presented here aims to address the
following research questions regarding its application
in SME:
• Which combination of data preprocessing, model
architecture, and model training maximizes
prediction quality?
• To what extent does the proposed process chain,
in terms of accuracy, outperform established
forecasting models such as ARIMA and Prophet?
• How does AI-supported procurement scheduling
impact costs, stock levels, inventory turnover
time, and delivery reliability?
2 STATE OF THE ART
Baryannis et al. (Baryannis et al., 2019) highlight the
potential of AI in supply chain risk management but
point out a lack of research on proactive and
predictive AI applications, especially regarding
decision-making, prediction methods, and the
integration of different AI technologies. Their
findings emphasize the need for further investigation
Process Chain for Artificial Intelligence-Based Demand Forecasting and Procurement Scheduling
725
in these areas. For instance, Venkatesan, and Goh
(Venkatesan & Goh, 2016) developed a multi-criteria
mixed integer linear program (MILP) model to
identify the optimal selection of suppliers and the
allocation of order quantities under the risk of
disruption. The findings indicate that the likelihood
of supplier default exerts a more substantial influence
on the anticipated aggregate expenditures compared
to the suppliers' adaptability and the ensuing loss
expenses. Pareto-optimal solutions facilitate the
assessment of a diverse array of decision alternatives.
Nevertheless, the authors highlight several
limitations, including those pertaining to
deterministic demand or unchanging purchase costs,
underscoring the necessity for further research to
elucidate these domains. A comparison of different
AI-based forecasting methods to improve the
accuracy of demand forecasting in supply chains
shows that the use of artificial neural networks
significantly improves the accuracy of demand
forecasting for intermittent demand (Amirkolaii et al.,
2017). In the context of SME Wong et al. (Wong et
al., 2024) demonstrated the benefits of AI-based risk
management in terms of improving business
continuity through improved response to changes
caused by disruptions.
This paper aims to address the existing research gaps
by developing a software process chain for combining
probabilistic AI predictors, thereby combining the
advantages of big data and machine learning with
individual prioritizations. This integration process
serves to reduce risk and enhance traceability for the
user. Despite the limited attention devoted to human
factors in the introduction and utilization of AI
applications in recent years, these factors have
gradually emerged as a focal point of research
interest. However, a more comprehensive
understanding of influencing factors such as trust,
acceptance, and other psychological factors, which
have proven to be key factors for success in the
interaction with other technologies and have already
been mapped in various models, is still lacking
(Choung et al., 2023; Davis, 1989; Manchon et al.,
2021). In addition to AI-specific aspects such as
representation and the degree of machine intelligence
(i.e., its capabilities), findings in the area of trust
highlight the relevance of antecedents that shape the
cognitive and emotional trust of users. These include
the tangibility, transparency, reliability, and
immediacy of AI applications, together with the role
of anthropomorphism. Explainability has been
identified as another pivotal factor influencing trust in
AI applications (Ferrario & Loi, 2022). However, the
extant empirical findings are subject to certain
limitations, including small samples, cross-sectional
observations, and experimental studies with
constraints on field environments. The samples
considered also differ considerably, impeding the
attainment of generalizability. Nevertheless,
enhancing our understanding of these phenomena
appears to be of paramount importance, particularly
in the context of SME with limited staffing and lower
levels of specialization.
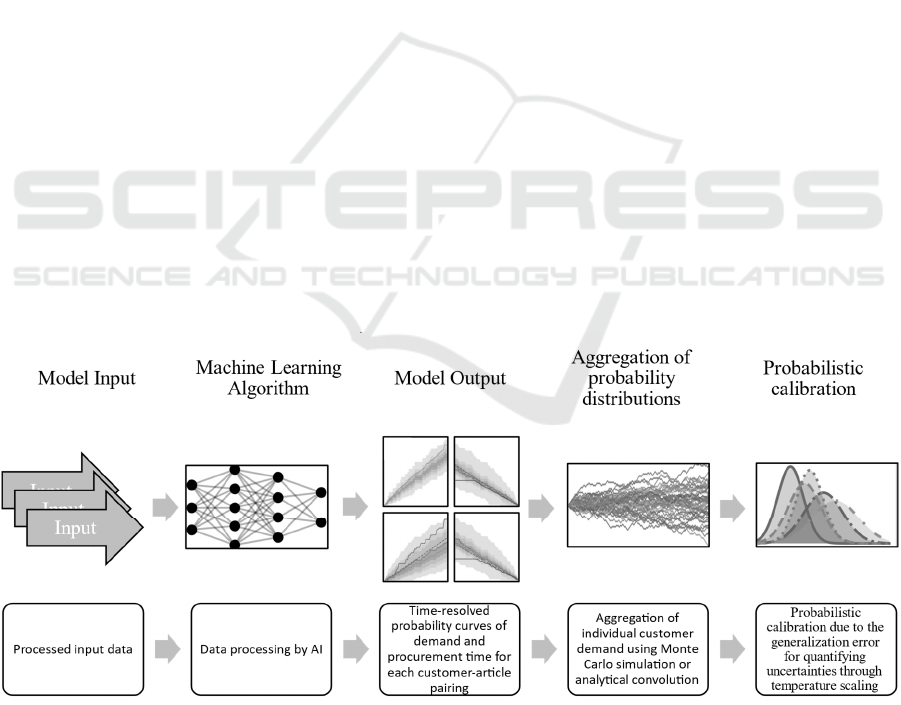
Figure 1: Process chain for predicting customer requirements and procurement times.
DATA 2025 - 14th International Conference on Data Science, Technology and Applications
726
3 METHODOLOGY
For developing the software framework, we focus on
an exemplarily SME, which is at the center of a
network of suppliers and customers. On the supplier
side, the procurement time as a function of the unit
quantity, and on the customer side, the quantity of
demand as a function of time are particularly relevant
for the scheduling tasks. There are often only a
limited number of data points available for individual
customers during the training period. Therefore, we
propose to train a machine learning algorithm not for
each individual customer, but to use a consolidated
model for all customers and all articles. Specific
customer and item parameters are then fed into the
machine learning algorithm as input. The prediction
for item demand can thus be made for each individual
customer and then aggregated at component level.
Figure 1 illustrates the process chain from data input,
through the machine learning algorithm, to the
processed model output. Each step of the process
chain will be presented in the following:
Model Inputs
All available and potentially relevant data should be
initially used as input variables. A post-analysis, for
example using SHapley Additive exPlanations
(SHAP) (Lundberg & Lee, 2017), makes it possible
to evaluate the influence of the input variables on the
target variables. By neglecting less relevant inputs,
model complexity can be reduced and efficiency
increased. The following model inputs, listed in Table
1, are initially and exemplarily used for prediction.
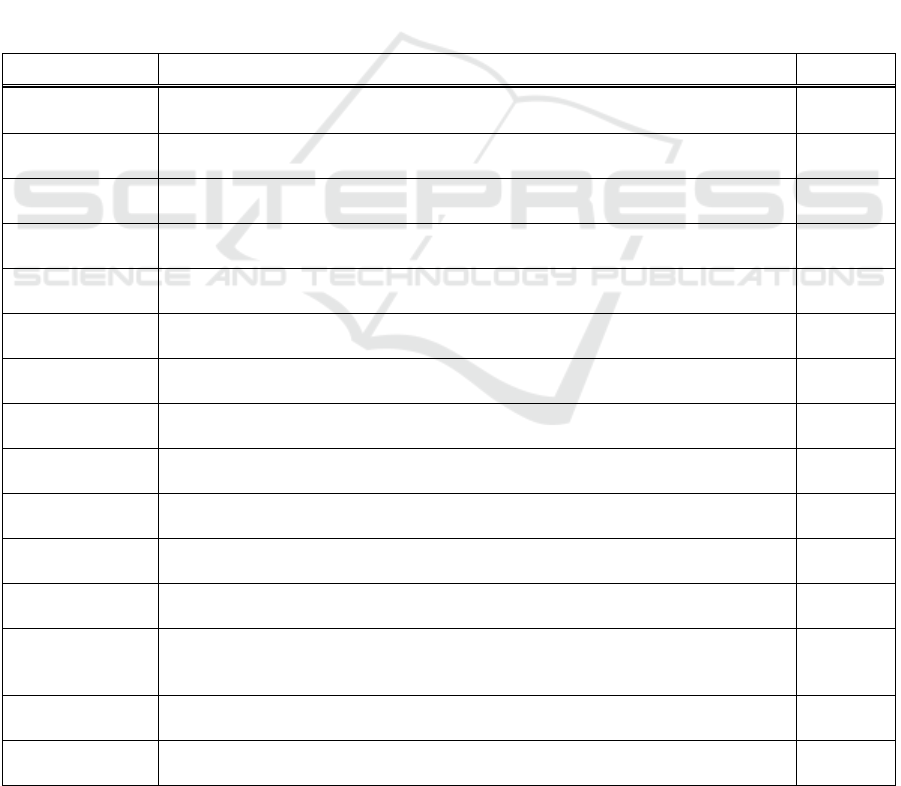
Table 1: Description of the input variables.
Input Description Format
Customer Since the model represents the demand of all customers within an organizational unit,
the customer identity is provided as a unique categorical variable.
One-hot
vector
Article Since the model represents the demand of all articles within an organizational unit, the
article identity is provided as a unique categorical variable.
One-hot
vector
Customer group Customers within an organizational unit are typically grouped. This grouping is
included in the model as a categorical variable.
One-hot
vector
Article group Articles within an organizational unit are typically grouped. This grouping is included
in the model as a categorical variable.
One-hot
vector
Historical demand
…
Historical demand contains information on patterns, trends, and seasonality. It can be
derived from actual deliveries and is provided to the model at three different levels:
… on customer
and article level
Historical demand for the specific customer and the specific article. Numerical
vector
… on customer
and article level
Historical demand of the specific customer for all other articles purchased. Numerical
vector
… on customer
level of the article
Historical demand of all other customers who purchase the specific article. Numerical
vector
Order frequency Number of times a customer has ordered an article within a defined period. Numerical
scalar
Average order
quantity
Mean order quantity of an article for a specific customer within a defined period. Numerical
scalar
Prediction
timestamp
Cyclic encoding of the time in the year. Numerical
vector
Start-of-
Production (SoP)
Difference between the SoP and the prediction timestamp. Numerical
scalar
Demand
announcements
In certain organizational units, demand is announced in advance. In this case, the
VDA4905 standard has been established. Both current and revised announcements are
included in the model.
Sparse
array
Customer
reliability
Based on historical demand announcements and actual demand, the reliability of the
announcements can be quantified numerically.
Sparse
array
External indices Publicly available indices provide information on global economic conditions,
industry trends, and logistics factors.
Numerical
vector
Process Chain for Artificial Intelligence-Based Demand Forecasting and Procurement Scheduling
727
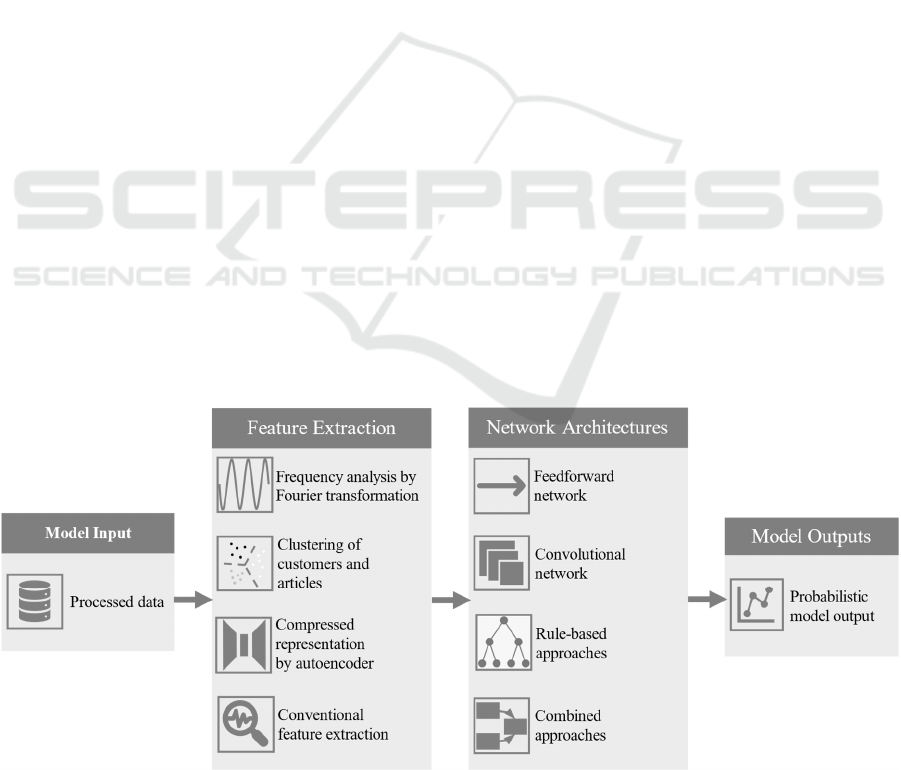
Machine Learning Algorithms – Design of
Experiment
At the center of the proposed process chain is an AI-
based model that aims to map the relationship
between input and output data as accurate as possible
and has the highest possible generalization capability.
Established methods for trend prediction such as the
“Autoregressive Integrated Moving Average”
(ARIMA) (Shumway & Stoffer, 2017) and the open
source library Prophet (Taylor & Letham, 2018) are
initially used as a baseline. A central aspect of the
research question is the comparative performance
analysis between conventional methods and machine
learning based models. In order to achieve a high
model quality, a systematic test matrix is applied to
the task and examined with regard to its suitability.
The overall structure is illustrated in
Figure
2.
Both customers and articles can exhibit similar or
contrasting patterns in terms of their input/output
behavior, which are systematically analyzed as part of
the feature extraction process by forming clusters.
Clustering algorithms such as k-Means (Lloyd, 1982)
or DBSCAN (Ester, M., Kriegel, H. P., Sander, J., &
Xu, X., 1996) are used to group customers and
articles. This improves the model's learning ability
and data structure. Since the demand announcements,
including past revised demand announcements, are in
a generalized format and in this case include a large
number of input dimensions, compression or
convolution can improve training and data structure.
This can be done on the feature extraction side by an
autoencoder that learns a dimension-reduced latent
representation of the input data (Hinton &
Salakhutdinov, 2006). This representation contains
almost the original information content and enables a
reduction in model size and more efficient
processing. Instead of dimension reduction at the data
pre-processing level, convolutional layers can also be
used at the network architecture level to enable
efficient data propagation. As a reference, the
convolutional networks are contrasted with pure
feedforward networks. Another decisive aspect is the
comprehensibility and explainability, which is crucial
for acceptance and trust in the AI application
(Afroogh et al., 2024). The probabilistic modeling of
the output contributes to the interpretability and
explainability of the model. In addition, architecture-
independent model-agnostic methods such as SHAP
can be used to increase transparency and
interpretability. Furthermore, rule-based machine
learning approaches with limited complexity can
provide additional insight into traceability and
explainability. Here, the advantages of traceability
have to be evaluated against any losses in model
quality. Although the processes of deliveries and
orders represent recurring events that could be
adequately modeled formally by recurrent neural
networks (RNNs), specific requirements speak
against the use of this architecture. A central aspect
of the problem is the need to generate not only point
predictions (quantities or points in time), but also
probability distributions for future events. This is
particularly crucial as decisions in procurement
scheduling are typically made under uncertainty. In
addition, the cumulative demand over a defined
period of time is more relevant than isolated
individual values, as this is directly linked to resource
planning and allocation. However, the feedback of
data within recurrent architectures poses considerable
challenges.
Figure 2: Design of experiment for machine learning algorithms.
DATA 2025 - 14th International Conference on Data Science, Technology and Applications
728

In particular, either a large number of possible
scenarios have to be modeled or probabilities cannot
be adequately taken into account. These limitations
would reduce the validity of the predictions and
impair the practical applicability of the model. For
this reason, approaches are preferred that can directly
predict probabilities for future periods on the basis of
historical data.
Model Output
Probabilistic modeling enables demand and
procurement time to be expressed as a function of
their probability of occurrence. This provides the
basis for risk- or cash flow-optimized procurement
scheduling and warehousing. A key advantage of this
approach lies in the subsequent adjustment of the
desired delivery reliability through user interaction.
Quantifying the risk increases transparency and
promotes acceptance and trust in the AI-based system
(Magnus Liebherr et al., 2025). Modeling multiple
output layers enables the simultaneous estimation of
multiple target values. Typically, the loss functions to
be minimized include the difference between the
target variable and the prediction. The output can be
calibrated to any quantile 𝑞 ∈ (0,1) by an
asymmetric
weighting of over- and underestimation:
𝐿
(
𝑦, 𝑦
)
=
𝑞 (𝑦−𝑦)
(
1 −𝑞
)(
𝑦−𝑦
)
,
𝑖𝑓 𝑦 > 𝑦
𝑒𝑙𝑠𝑒
(1
)
The choice of different weightings 𝑞 in several output
layers enables the simultaneous estimation of
different quantiles or confidence intervals. By
providing different confidence intervals and
interpolation methods, the user can interactively
explore risk-based scenarios and dynamically adapt
scheduling parameters to changing framework
conditions.
Aggregation of Probability Distributions
The AI-based model generates multivariate quantile
forecasts for each customer-article pairing. The
aggregated probability distributions of all customers
per article are primarily relevant for decision-making
in procurement scheduling. Depending on the number
of customers and the granularity of the quantiles,
these forecasts are calculated either analytically or
empirically: an analytical convolution combines the
individual distributions and calculates the resulting
overall distribution with mathematical precision:
𝑃
= 𝑃
∗𝑃
∗… ∗𝑃
(2
)
The convolution method is suitable due to the
computational complexity with a lower number of
customers and lower quantile granularity and
provides a mathematically exact calculation. The
Monte Carlo method approximates the resulting
distribution empirically by sampling. The calculation
effort can be reduced at the expense of accuracy.
These methods are based on the assumption of
stochastic independence between the probability
distributions generated by the AI. In a global market,
demand patterns can correlate due to common
economic factors. If these factors are not fully
integrated in the AI model, the premise of stochastic
independence does not apply. The resulting
systematic errors require an analysis that provides
information about the demand correlation of different
customers. Depending on the result of the analysis,
the systematic errors can be compensated by
integrating copula models, for example. If there is no
significant correlation between certain customers,
uncertainties can be compensated for by temperature
scaling.
Probabilistic Calibration
Despite the use of regularization methods, machine
learning algorithms have a tendency to overfitting,
especially in more complex architectures (Sun et al.,
2017). This overfitting leads to overconfident
predictions for test or validation data. Temperature
scaling offers an effective approach to improve
calibration by introducing a scalar parameter 𝑇 that
scales the output distribution of the logits.
Temperature scaling was originally developed for
classification models (Chuan Guo et al., 2017). In
2020, Utpala & Rai show that the concept can also be
applied to quantile calibrations in regression models
(Utpala & Rai, 2020). The temperature parameter 𝑇
is applied to the distribution function and can be
estimated based on past data.
4 INITIAL RESULTS AND
DISCUSSION
The process chain presented offers a generalized, AI-
based approach to forecasting demand and
procurement time. By integrating probabilistic
modelling, the aggregation of individual customer
demand at article level and temperature scaling, the
system enables a realistic quantification of
probabilities of occurrence and supports risk-adjusted
and cash flow-optimized scheduling. Both human
schedulers and downstream software agents can use
the AI-supported forecasts to optimize decisions,
increase delivery reliability and reduce storage costs.
Explicit risk quantification increases the transparency
of the system, thereby promoting user acceptance and
building trust.
Process Chain for Artificial Intelligence-Based Demand Forecasting and Procurement Scheduling
729
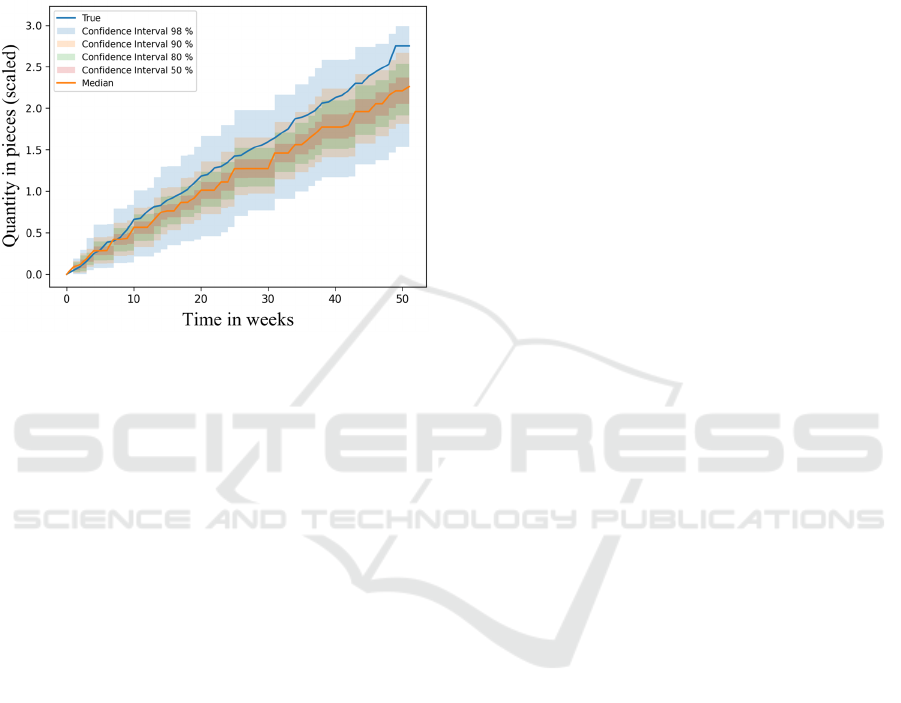
A first exemplary aggregated demand forecast over
52 weeks for a reference article (Figure 3) shows that
the spread of the confidence intervals increases with
increasing forecast horizon. In this case, the base
model slightly underestimates demand, but the actual
values are predominantly within the 90 % confidence
interval (without applying temperature scaling).
Figure 3: Exemplary aggregated demand forecast over 52
weeks.
The completion of the process chain includes a
systematic analysis and optimization of model
architectures and hyperparameters in order to further
increase the prediction quality. Future work will
address the adaptation of the process chain to the
prediction of procurement times, the integration of
explainable AI methods to increase traceability and
the extension to correlated demand patterns in global
supply chains using copula models. The presented
AI-based process chain makes the central advantages
of AI usable for SME in procurement scheduling by
enabling risk-conscious, efficient and transparent
scheduling, which both reduces storage costs and
sustainably increases delivery reliability.
REFERENCES
Afroogh, S., Akbari, A., Malone, E., Kargar, M., &
Alambeigi, H. (2024). Trust in AI: Progress, challenges,
and future directions. Humanities and Social Sciences
Communications, 11(1), 1–30. https://doi.org/10.1057/
s41599-024-04044-8
Allal-Chérif, O., Simón-Moya, V., & Ballester, A. C. C.
(2021). Intelligent purchasing: How artificial
intelligence can redefine the purchasing function.
Journal of Business Research, 124, 69–76.
https://doi.org/10.1016/j.jbusres.2020.11.050
Amirkolaii, K. N., Baboli, A., Shahzad, M. K., &
Tonadre, R. (2017). Demand Forecasting for Irregular
Demands in Business Aircraft Spare Parts Supply
Chains by using Artificial Intelligence (AI). IFAC-
PapersOnLine, 50(1), 15221–15226. https://doi.org/10.
1016/j.ifacol.2017.08.2371
Baryannis, G., Validi, S., Dani, S., & Antoniou, G. (2019).
Supply chain risk management and artificial
intelligence: state of the art and future research
directions. International Journal of Production
Research, 57(7), 2179–2202. https://doi.org/10.10
80/00207543.2018.1530476
Bitkom e. V. (2022). KI gilt in der deutschen Wirtschaft als
Zukunftstechnologie – wird aber selten genutzt
[Retrieved March 29, 2025].
Business Forecast Systems, Inc. (2025). forecast pro
[Retrieved April 26, 2025]. https://www.forecas
tpro.com/
Choung, H., David, P., & Ross, A. (2023). Trust in AI and
Its Role in the Acceptance of AI Technologies.
International Journal of Human–Computer Interaction,
39(9), 1727–1739. https://doi.org/10.1080/104473
18.2022.2050543
Chuan Guo, Geoff Pleiss, Yu Sun, & Kilian Q. Weinberger
(2017). On Calibration of Modern Neural Networks.
International Conference on Machine Learning, 1321–
1330. http://proceedings.mlr.press/v70/guo17a.html
Chui, M., Hazan, E., Roberts, R., Singla, A., Kate, S.,
Sukharevsky, A., Yee, L., & Zemmel, R. (2023). The
economic potential of generative A [Retrieved March
28, 2025]. https://www.mckinsey.com/~/media
/mckinsey/business functions/mckinsey digital/our
insights/the economic potential of generative ai the next
productivity frontier/the-economic-potential-of-
generative-ai-the-next-productivity-frontier
Davis, F. D. (1989). Perceived Usefulness, Perceived Ease
of Use, and User Acceptance of Information
Technology. MIS Quarterly, 13(3), 319. https://doi.
org/10.2307/249008
Ester, M., Kriegel, H. P., Sander, J., & Xu, X. (1996). A
density-based algorithm for discovering clusters in
large spatial databases with noise. Proceedings of the
Second International Conference on Knowledge
Discovery and Data Mining (KDD-96) (pp. 226-231).
https://cdn.aaai.org/kdd/1996/kdd96-
037.pdf?source=post_page--------------
Ferrario, A., & Loi, M. (2022). How Explainability
Contributes to Trust in AI. In 2022 ACM Conference on
Fairness, Accountability, and Transparency (pp. 1457–
1466). ACM. https://doi.org/10.1145/3531146.
3533202
Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing
the dimensionality of data with neural networks.
Science, 313(5786), 504–507. https://doi.org/10.1126/
science.1127647
Lloyd, S. (1982). Least squares quantization in PCM. IEEE
Transactions on Information Theory, 28(2), 129–137.
https://doi.org/10.1109/TIT.1982.1056489
DATA 2025 - 14th International Conference on Data Science, Technology and Applications
730

Lundberg, S., & Lee, S.‑I. (2017, May 22). A Unified
Approach to Interpreting Model Predictions.
http://arxiv.org/pdf/1705.07874
Lundborg, M., Papen, M.‑C. Dr., Roloff, M., Simons, M. J.,
& Stamm, P. (2023). Künstliche Intelligenz im
Mittelstand [Retrieved March 29, 2025]. https://
www.mittelstand-
digital.de/MD/Redaktion/DE/Publikationen/ki-Studie-
2023.pdf?__blob=publicationFile&v=4
Magnus Liebherr, Ellen Enkel, Effie Law, Mohammadreza
Mousavi, Matteo Sammartino, & Philipp Sieberg
(2025). Dynamic Calibration of Trust and
Trustworthiness in AI-Enabled Systems. International
Journal on Software Tools for Technology Transfer.
https://kclpure.kcl.ac.uk/portal/en/publications/dynami
c-calibration-of-trust-and-trustworthiness-in-ai-
enabled-sy
Manchon, J. B., Bueno, M., & Navarro, J. (2021). From
manual to automated driving: How does trust evolve?
Theoretical Issues in Ergonomics Science, 22(5), 528–
554. https://doi.org/10.1080/1463922X.2020.1830450
McKinsey & Company. (2021). Succeeding in the AI
supply-chain revolution [Retrieved March 28, 2025].
https://www.mckinsey.com/industries/metals-and-
mining/our-insights/succeeding-in-the-ai-supply-
chain-revolution#/
OECD. (2023). OECD SME and Entrepreneurship Outlook
2023. Retrieved March 29, 2025. https://www.
oecd.org/en/publications/oecd-sme-and-entrepreneur
ship-outlook-2023_342b8564-en.html, https://doi.org
/10.1787/342b8564-en
Samuels, A. (2024). Examining the integration of artificial
intelligence in supply chain management from Industry
4.0 to 6.0: A systematic literature review. Frontiers in
Artificial Intelligence, 7, 1477044. https://doi.org/10.33
89/frai.2024.1477044
Shumway, R. H., & Stoffer, D. S. (2017). Arima Models.
Time Series Analysis and Its Applications, 75–163.
https://doi.org/10.1007/978-3-319-52452-8_3
Sun, X., Sun, W., Ma, S., Ren, X., Zhang, Y., Li, W., &
Wang, H. (2017, November 25). Complex Structure
Leads to Overfitting: A Structure Regularization
Decoding Method for Natural Language Processing.
http://arxiv.org/pdf/1711.10331
Taylor, S. J., & Letham, B. (2018). Forecasting at Scale.
The American Statistician, 72(1), 37–45.
https://doi.org/10.1080/00031305.2017.1380080
Utpala, S., & Rai, P. (2020). Quantile Regularization:
Towards Implicit Calibration of Regression Models.
Venkatesan, S. P., & Goh, M. (2016). Multi-objective
supplier selection and order allocation under disruption
risk. Transportation Research Part E: Logistics and
Transportation Review, 95, 124–142.
https://doi.org/10.1016/j.tre.2016.09.005
WIK GmbH (Ed.). (2019). https://www.mittelstand-
digital.de/MD/Redaktion/DE/Publikationen/kuenstlich
e-intelligenz-im-mittelstand.pdf?__blob=publication
File&v=5 [retrieved March 28, 2025].
Begleitforschung Mittelstand-Digital.
Wong, L.‑W., Tan, G. W.‑H., Ooi, K.‑B., Lin, B., &
Dwivedi, Y. K. (2024). Artificial intelligence-driven
risk management for enhancing supply chain agility: A
deep-learning-based dual-stage PLS-SEM-ANN
analysis. International Journal of Production Research,
62(15), 5535–5555. https://doi.org/10.1080/00
207543.2022.2063089
Process Chain for Artificial Intelligence-Based Demand Forecasting and Procurement Scheduling
731
