
Robust Peer-to-Peer Machine Learning Against Poisoning Attacks
Myria Bouhaddi and Kamel Adi
Computer Security Research Laboratory, University of Quebec in Outaouais, Gatineau, Quebec, Canada
Keywords:
Peer-to-Peer Machine Learning, Poisoning Attacks, Adversarial Machine Learning, Robust Aggregation,
Decentralized AI.
Abstract:
Peer-to-Peer Machine Learning (P2P ML) offers a decentralized alternative to Federated Learning (FL), re-
moving the need for a central server and enhancing scalability and privacy. However, the lack of centralized
oversight exposes P2P ML to model poisoning attacks, where malicious peers inject corrupted updates. A
major threat comes from adversarial coalitions, groups of peers that collaborate to reinforce poisoned updates
and bypass local trust mechanisms. In this work, we investigate the impact of such coalitions and propose
a defense framework that combines variance-based trust evaluation, Byzantine-inspired thresholding, and a
feedback-driven self-healing mechanism. Extensive simulations in various attack scenarios demonstrate that
our approach significantly improves robustness, ensuring high accuracy, detection by attackers, and model
stability under adversarial conditions.
1 INTRODUCTION
Machine learning (ML) has transformed domains
such as autonomous systems, medical diagnostics,
financial fraud detection, and cybersecurity. These
advances have mainly relied on centralized architec-
tures, where large volumes of data are aggregated on a
central server for model training. Although this facil-
itates optimization, it raises concerns about data pri-
vacy, security vulnerabilities, and scalability, particu-
larly with sensitive or geographically distributed data.
Decentralized learning paradigms have emerged
to address these issues. Federated Learning (FL) en-
ables clients to collaboratively train a model without
sharing raw data, but it still relies on a central server
for aggregation, creating a single point of failure and
a potential adversarial target.
To eliminate central coordination, Peer-to-Peer
Machine Learning (P2P ML) offers a fully decen-
tralized alternative. Each node maintains and trains
its local model, periodically exchanging parameters
with neighbors. This structure promotes scalability,
preserves data locality, and suits privacy-sensitive or
infrastructure-constrained environments.
In scenarios where centralized coordination is
infeasible due to connectivity constraints, dynamic
topologies, or lack of infrastructure, P2P ML be-
comes a natural fit. Unlike Federated Learning, which
still depends on a central server for aggregation, P2P
A
D
B
C
E A
B C D
E
Server
(a) Peer-to-Peer Learning
(a) Federated Learning
Figure 1: Comparison between Federated Learning and
Peer-to-Peer Machine Learning. In FL, a central server ag-
gregates updates from clients, while in P2P ML, peers ex-
change updates directly.
ML enables nodes to exchange and integrate updates
locally through a fully decentralized protocol. This
architecture is particularly suited for environments
such as the Internet of Things (IoT), Mobile Ad Hoc
Networks (MANETs), Vehicular Ad Hoc Networks
(VANETs), and decentralized blockchain ecosystems.
In these domains, devices must operate au-
tonomously under energy constraints, intermittent
connectivity, or rapid topology changes. For exam-
ple, IoT nodes often lack continuous communica-
tion; VANETs require model updates on the move;
MANETs form spontaneously without fixed infras-
tructure; and blockchain applications align naturally
with decentralized learning models, especially for
collaborative fraud or anomaly detection.
By adapting to these conditions, P2P ML broad-
ens the scope of collaborative learning. However,
Bouhaddi, M., Adi and K.
Robust Peer-to-Peer Machine Learning Against Poisoning Attacks.
DOI: 10.5220/0013640600003979
In Proceedings of the 22nd International Conference on Security and Cryptography (SECRYPT 2025), pages 539-546
ISBN: 978-989-758-760-3; ISSN: 2184-7711
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
539

the absence of central authority introduces vulnera-
bilities, notably model poisoning attacks, where mali-
cious peers inject corrupted updates to degrade per-
formance or implant stealthy backdoors (Bouhaddi
and Adi, 2024). Unlike FL, which allows for cen-
tralized filtering, ML P2P’s localized, asynchronous
exchanges make detecting poisoning attacks signifi-
cantly harder. Without a global reference, the nodes
must rely solely on limited neighborhood views, com-
plicating the distinction between benign and mali-
cious behavior. The decentralized and dynamic nature
of P2P networks further exacerbates this risk, allow-
ing adversaries to exploit topology weaknesses, coor-
dinate across multiple nodes, and propagate poisoned
updates across several hops before detection.
In this work, we investigate critical vulnerabilities
in peer-to-peer machine learning under poisoning at-
tacks, focusing particularly on adversarial coalitions.
Without centralized coordination, each node must in-
dependently assess the trustworthiness of its neigh-
bors based solely on local information, creating an
asymmetry that coordinated adversaries can exploit to
subvert learning outcomes while avoiding detection.
To address this challenge, we propose a defense
framework tailored for fully decentralized environ-
ments. It combines three complementary mecha-
nisms: (1) a local variance-based reputation update
to detect anomalies, (2) a coalition-based detection
method that integrates structural, reputational and
performance-based signals, and (3) a self-healing pro-
tocol that enables compromised nodes to gradually re-
cover by adjusting their dependence on local updates.
Together, these layers allow nodes to adapt dynam-
ically, suppress poisoned information, and maintain
robust model performance.
The remainder of this paper is organized as fol-
lows. Section 2 reviews related work on adversar-
ial threats in decentralized learning; Section 3 intro-
duces the threat model and attack strategies; Section 4
presents our defense mechanism; Section 5 provides
experimental validation and analysis; and Section 6
concludes with insights and future directions.
2 STATE OF THE ART
Numerous studies have highlighted the impact of
poisoning attacks in Federated Learning, where ad-
versaries exploit collaborative updates by corrupting
training data or directly manipulating model updates.
Since peer-to-peer machine learning shares architec-
tural similarities with FL but lacks a central aggrega-
tor, understanding poisoning attacks in FL provides
a strong basis for analyzing threats in decentralized
settings.
Poisoning attacks can be categorized by method-
ology and attacker intent. The two main types are data
poisoning and model poisoning. In data poisoning,
adversaries manipulate training data, either through
clean label attacks, where adversarial samples resem-
ble legitimate data, or dirty label attacks, where la-
bels are flipped to mislead learning (Shejwalkar et al.,
2022; Sun et al., 2022; Shafahi et al., 2018; Rong
et al., 2022). Model poisoning involves directly alter-
ing updates, optimizing them to avoid detection while
significantly influencing the global model (Bhagoji
et al., 2019; Sun et al., 2019; Bagdasaryan et al.,
2020). Attackers may also inject backdoors, hidden
triggers causing targeted misclassifications (Xie et al.,
2019; Zhou et al., 2021).
Another key dimension is the target of the at-
tacker. Targeted poisoning alters predictions for spe-
cific inputs while maintaining overall accuracy, often
through backdoors (Sun et al., 2022; Tolpegin et al.,
2020). Semi-target attacks degrade the performance
of certain classes, and untargeted attacks disrupt the
overall convergence of the model (Cao and Gong,
2022). Centralized aggregation in FL can mitigate
some effects, but in P2P ML, adversarial coalitions re-
inforce malicious updates, making semi-targeted and
untargeted attacks especially dangerous.
Despite extensive research, many defenses re-
main insufficient, particularly in decentralized envi-
ronments. Byzantine-resilient aggregation (BRA) fil-
ters extreme gradients but often assumes a major-
ity of honest clients, an assumption invalidated un-
der collusion (Sun et al., 2019; Panda et al., 2022).
Privacy-preserving techniques such as Secure Aggre-
gation (SA) and differential privacy protect confiden-
tiality but do not prevent adversarial updates, and can
even be exploited via structured noise injection (Sun
et al., 2019; Hossain et al., 2021; Naseri et al., 2020).
Moreover, most defenses assume static attack strate-
gies, whereas adaptive adversaries that use reinforce-
ment learning can continuously evade detection (Li
et al., 2022).
The transition from FL to P2P ML introduces
new challenges. In FL, centralized servers enforce
trust, but in P2P ML, trust must be decentralized,
exposing the system to Sybil attacks and collusion.
Blockchain-based trust models, leveraging crypto-
graphic proofs, offer a promising solution. In addi-
tion, topology-aware aggregation can detect poisoned
updates by detecting anomalies in local neighbor-
hoods. Given that adversarial influence spreads faster
in P2P ML, defenses must integrate metalearning and
autoencoder-based anomaly detection to identify sub-
tle deviations without accessing raw data.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
540

In sum, poisoning attacks represent a critical chal-
lenge for both FL and P2P ML. Although FL defenses
are well studied, their effectiveness in fully decentral-
ized settings remains uncertain. P2P ML demands
trust-based, distributed, and topology-aware defenses
capable of mitigating adversarial influence while pre-
serving collaborative learning efficiency. Future re-
search should focus on distributed anomaly detection,
adaptive poisoning mitigation, and resilient peer-to-
peer aggregation to secure decentralized learning sys-
tems.
3 THREAT MODEL
3.1 System Model
We consider a decentralized peer-to-peer machine
learning framework where nodes collaboratively train
a model without a central server. The system is rep-
resented as a graph G = (V, E), with V denoting the
set of nodes and E ⊆ V × V the bidirectional com-
munication links. Each node i ∈ V maintains a local
model w
i
and periodically exchanges parameters with
its neighbors N
i
, aggregating updates based on trust,
similarity, or statistical heuristics.
Without a global coordinator, the attack surface
increases significantly. Unlike federated learning,
where a central server can apply robust aggregation
or anomaly detection, P2P ML systems rely entirely
on peer interactions, making them more vulnerable to
adversarial interference, especially under coordinated
attacks.
3.2 Adversarial Capabilities
We assume a coalition of malicious nodes V
A
⊂ V that
aims to disrupt the learning process by injecting cor-
rupted updates during aggregation. These nodes op-
erate independently and have full control over their
local training data and model updates. Before broad-
casting, they can arbitrarily alter gradients or model
weights, producing noisy, biased, or adversarial up-
dates.
The proportion of adversarial nodes is denoted by
α =
|V
A
|
|V |
, where 0 < α < 1. Malicious nodes partici-
pate in each training round, exchange messages with
honest neighbors, and use various poisoning strate-
gies, ranging from simple label flipping to sophisti-
cated gradient manipulations designed to evade naive
detection mechanisms.
3.3 Attack Objectives and Strategies
The objectives of adversarial nodes can be broadly
classified into three categories. The first is global
model degradation, where inconsistent or high-
variance updates disrupt convergence, slowing train-
ing, or leading to unstable, poorly generalized mod-
els. The second is targeted model manipulation,
where adversaries embed specific misclassifications
or backdoors, subtly altering decision boundaries
while maintaining overall accuracy to evade detec-
tion.
The third and more sophisticated strategy is
coalition-based trust subversion. Here, malicious
nodes coordinate to reinforce each other’s poisoned
updates, exploiting trust mechanisms based on simi-
larity or consistency. This coordination gradually in-
creases their influence, steering the learning process
toward adversarial objectives while avoiding detec-
tion through mutual support.
3.4 Formalization of the Threat
Formally, each node i ∈ V aggregates neighbor mod-
els using a local aggregation rule A
i
. An adversarial
node j ∈ V
A
aims to produce an update w
A
j
such that
the aggregated model A
i
({w
k
}
k∈N
i
) deviates maxi-
mally from the expected global update w
∗
, while re-
maining stealthy to evade local detection. This de-
fines a dual objective: to maximize impact while min-
imizing detectability.
The effectiveness of such attacks depends on fac-
tors such as the number and distribution of malicious
nodes, the topology and dynamics of the communi-
cation graph, and the aggregation strategies used by
the honest nodes. In highly connected graphs, ma-
licious influence may be diluted, whereas in sparse
or structured networks, even small coalitions can ex-
ert significant impact, especially by exploiting trust
mechanisms or statistical shortcuts.
3.5 Adversarial Scenarios
To capture the range of adversarial behaviors and
evaluate the robustness of our defense mechanisms,
we define three representative attack scenarios.
Scenario 1 – Single Adversarial Neighbor. The
node is surrounded by mostly honest neighbors, with
only one adversarial peer injecting poisoned updates.
This scenario evaluates local statistical techniques,
such as variance-based reputation mechanisms, to
identify and isolate outliers.
Scenario 2 – Critical Mass of Malicious Neigh-
bors. As the number of adversarial neighbors in-
Robust Peer-to-Peer Machine Learning Against Poisoning Attacks
541

creases, their influence on aggregation increases. This
scenario explores the threshold beyond which local
defenses like statistical filtering or reputation adjust-
ments fail, analogous to the Byzantine fault tolerance
threshold.
Scenario 3 – Fully Poisoned Neighborhood. In
this extreme case, all neighbors are malicious. The
node, deprived of any honest reference, must rely on
a feedback-based mechanism, using future or alter-
native neighbors to retroactively detect poisoning and
engage in self-healing behavior.
These scenarios cover the spectrum of adversar-
ial influence in decentralized learning environments,
from isolated attacks to complete compromise. The
next section introduces our defense mechanisms and
shows how they address these scenarios under varying
conditions.
4 DEFENSE MODEL AGAINST
POISONING ATTACKS IN P2P
MACHINE LEARNING
We introduce a defense model to counter poison-
ing attacks in peer-to-peer machine learning systems.
Our approach combines a dynamically evolving trust
mechanism based on update consistency, a reputation-
aware aggregation strategy, and a feedback-driven
self-correction mechanism. These components ad-
dress adversarial configurations that range from iso-
lated attackers to fully compromised neighborhoods.
4.1 System and Trust Graph
Formalization
We consider a decentralized peer-to-peer learning
system composed of n nodes. Each node maintains
and updates a local model through iterative training
and exchanges with its direct neighbors. The struc-
ture of communication and trust is represented by a
directed graph G = (V, E, R), where V = {1, . .. , n}
denotes the set of nodes, E ⊆ V ×V the directed com-
munication links and R = {r
(t)
i j
∈ [0, 1]} the dynamic
reputation scores at each round t. A directed edge
( j, i) ∈ E indicates that node i receives an update from
node j, with r
(t)
i j
reflecting the trust placed by i in j in
round t.
Each round t, node i aggregates the model param-
eters received from neighbors N (i) together with its
own model w
(t)
i
using:
w
(t+1)
i
= a
(t)
ii
· w
(t)
i
+
∑
j∈N (i)
a
(t)
i j
· ˜w
(t)
j
,
where ˜w
(t)
j
is the update of node j, and the weights
satisfy:
a
(t)
ii
+
∑
j∈N (i)
a
(t)
i j
= 1.
The aggregation weights are computed as:
a
(t)
i j
=
r
(t)
i j
r
(t)
ii
+
∑
k∈N (i)
r
(t)
ik
, for j ∈ N (i)∪ {i}.
This mechanism ensures that the most trusted nodes
have greater influence, while the nodes with lower
reputation scores are reduced, allowing each node to
adaptively balance external inputs against its own up-
dates in adversarial settings.
4.2 Variance-Based Reputation Update
Mechanism
The trust-based aggregation framework uses reputa-
tion scores r
(t)
i j
to weigh the influence of neighbor j on
node i. These scores are updated at each round based
on the consistency of received updates, with the aim
of down-weighting neighbors whose updates deviate
significantly from expected behavior.
In each round t, node i receives updates
{ ˜w
(t)
j
}
j∈N (i)
and computes a local consensus model
¯w
(t)
i
, for example, using the coordinate median. The
deviation of each neighbor j is quantified by:
d
(t)
i j
=
˜w
(t)
j
− ¯w
(t)
i
2
.
The node i then calculates the empirical variance
Var
(t)
i
in all deviations. A soft trust score s
(t)
i j
∈ (0, 1]
is assigned by:
s
(t)
i j
= exp
−
d
(t)
i j
q
Var
(t)
i
+ ε
,
where ε > 0 prevents division by zero.
The reputation score is updated using exponential
smoothing:
r
(t+1)
i j
= λ · r
(t)
i j
+ (1 − λ) · s
(t)
i j
,
where λ ∈ [0, 1] controls the stability-speed trade-off:
small λ adapts quickly, large λ emphasizes long-term
behavior.
By reinforcing consistent behavior and penalizing
outliers, this mechanism dynamically adjusts trust to
maintain robustness against adversarial updates.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
542

4.3 Detection of Coalition Attacks via
Local Byzantine-Aware
Thresholding
The variance-based reputation mechanism effectively
detects isolated adversarial behaviors, where a sin-
gle poisoned update deviates significantly from oth-
ers. However, it fails when multiple malicious neigh-
bors collude by sending similarly crafted updates. In
such cases, the statistical deviation becomes artifi-
cially low, making malicious nodes appear trustwor-
thy and allowing them to gain influence while evading
local anomaly detection.
To address this, each node i monitors not only the
variance of incoming updates but also the wider con-
sistency of its own learning dynamics. We propose a
local detection strategy based on three jointly satisfied
conditions.
First, node i tracks the variance Var
(t)
i
among the
received updates. A very low variance may indicate
either stability or artificial agreement among adver-
saries. Second, node i evaluates the proportion of
trusted neighbors:
H
(t)
i
=
n
j ∈ N (i) | r
(t)
i j
≥ δ
o
,
with high reputation ratio:
η
(t)
i
=
|H
(t)
i
|
|N (i)|
.
A large η
(t)
i
usually reflects neighborhood trust, but,
when combined with low variance, can suggest collu-
sion.
Third, node i monitors its own local loss L
(t)
i
. If
trusted neighbors provide consistent updates but L
(t)
i
remains high, this indicates adversarial influence.
Node i indicates a possible coalition poisoning at-
tack if:
Var
(t)
i
< ε
v
, η
(t)
i
> θ, L
(t)
i
> L
max
,
where ε
v
, θ, and L
max
are system-defined thresholds.
This tri-criteria mechanism provides a robust lo-
cal indicator of coalition-based poisoning by integrat-
ing structural, reputational, and learning-performance
signals. Upon detection, node i initiates a protective
strategy described in the next section.
Upon diagnosing a possible coalition poisoning
attack: low variance, high neighbor trust, and de-
graded local performance, node i initiates a self-
healing protocol to mitigate malicious influence.
The strategy temporarily isolates the node from
poisoned updates by prioritizing its own model. Let
γ ∈ (0, 1) denote the self-reliance factor; the updated
aggregation rule is:
w
(t+1)
i
= γ · w
(t)
i
+ (1 − γ) ·
∑
j∈N (i)
a
(t)
i j
· ˜w
(t)
j
,
with γ close to 1 during healing. This reduces external
influence while preserving the learning structure.
The self-healing phase lasts a fixed number of
rounds ∆, during which node i monitors its local loss
L
(t)
i
. If L
(t)
i
< L
max
, the node gradually reintroduces
external updates by decreasing γ; otherwise, it pro-
longs the healing phase, relying primarily on local
data.
This mechanism provides a local, reactive defense
without requiring global coordination, thus maintain-
ing full decentralization.
4.4 Algorithmic Overview and
Temporal Adaptation Strategy
We summarize our defense strategy as a dynamic al-
gorithm operating on a finite learning horizon of T
communication rounds. In each round, every node
i receives updates from neighboring nodes and per-
forms local computations: reputation updates, ag-
gregation, anomaly detection, and, if needed, self-
healing.
The model adapts over time through three in-
terconnected phases: (1) trust-based aggregation in-
formed by variance-aware reputation updates, (2)
coalition attack detection based on structural, repu-
tational, and performance signals, and (3) a feedback-
driven self-healing mechanism that rebalances aggre-
gation toward local updates during compromise.
This layered strategy enables each node to refine
neighbor trustworthiness, detect coordinated poison-
ing without central oversight, and react autonomously
to adversarial conditions.
The algorithm 1 details the entire procedure at
each node, highlighting the modularity and adaptabil-
ity of the defense process to various levels of threat
and network configurations.
5 EXPERIMENTAL EVALUATION
We evaluate the effectiveness of the proposed defense
model in protecting a target node against poisoning at-
tacks in a decentralized peer-to-peer machine learning
environment. The experiments are carried out under
four adversarial scenarios, each representing a spe-
cific neighborhood configuration. We evaluate perfor-
mance in terms of local learning accuracy, loss, and
attacker detection rate.
Robust Peer-to-Peer Machine Learning Against Poisoning Attacks
543
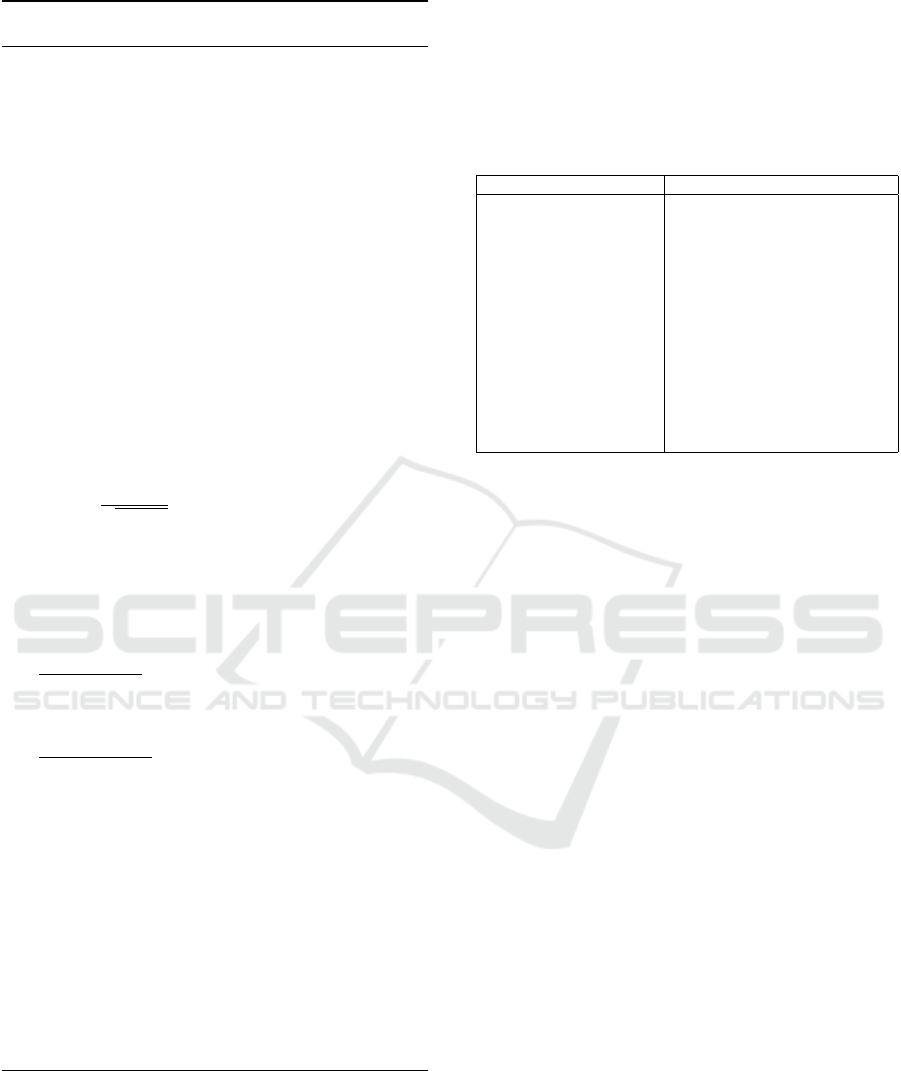
Algorithm 1: Defense Against Poisoning Attacks in P2P
Machine Learning.
Require: Trust graph G = (V, E, R), training rounds
T , smoothing factor λ, variance threshold ε
v
,
reputation threshold δ, trust density threshold θ,
loss threshold L
max
, self-healing duration ∆, self-
reliance factor γ
1: Initialize local model w
(0)
i
and reputations r
(0)
i j
=
1 for all j ∈ N (i)
2: for each round t = 1 to T do
3: for each node i ∈ V do
4: Receive updates { ˜w
(t)
j
}
j∈N (i)
5: Compute local consensus ¯w
(t)
i
←
median({ ˜w
(t)
j
})
6: for each neighbor j ∈ N (i) do
7: Compute deviation d
(t)
i j
= ∥ ˜w
(t)
j
−
¯w
(t)
i
∥
2
8: Compute trust score: s
(t)
i j
=
exp
−
d
(t)
i j
q
Var
(t)
i
+ε
!
9: Update reputation: r
(t+1)
i j
= λ · r
(t)
i j
+
(1 − λ) · s
(t)
i j
10: end for
11: Compute normalized weights: a
(t)
i j
=
r
(t)
i j
r
(t)
ii
+
∑
k∈N (i)
r
(t)
ik
12: Compute trust density ratio: η
(t)
i
=
|{ j∈N (i)|r
(t)
i j
≥δ}|
|N (i)|
13: if Var
(t)
i
< ε
v
and η
(t)
i
> θ and L
(t)
i
> L
max
then
14: for each healing step τ = 1 to ∆ do
15: Self-healing aggregation:
w
(t+1)
i
= γ · w
(t)
i
+ (1 − γ) ·
∑
j∈N (i)
a
(t)
i j
· ˜w
(t)
j
16: end for
17: else
18: Normal aggregation: w
(t+1)
i
= a
(t)
ii
·
w
(t)
i
+
∑
j∈N (i)
a
(t)
i j
· ˜w
(t)
j
19: end if
20: end for
21: end for
5.1 Simulation Setup
The simulation involves 50 nodes structured as a ran-
dom directed graph. Each node trains a local model
on a private, non-i.i.d. subset of the MNIST dataset
and exchanges updates with its direct neighbors. In
each experiment, we focus on a specific target node
and vary the nature of its neighbors to simulate differ-
ent adversarial settings. The target learning dynamics
is monitored over 200 communication rounds.
The parameters used in the simulations are summa-
rized in Table 1.
Table 1: Simulation Parameters.
Parameter Value
Number of nodes (n) 50
Graph topology Random directed graph (avg. degree = 4)
Learning rounds (T ) 200
Local model 2-layer MLP (ReLU, softmax)
Local data per node 1,200 MNIST samples
Optimizer SGD (learning rate = 0.01)
Batch size 32
Reputation smoothing factor (λ) 0.7
Variance threshold (ε
v
) 10
−3
Reputation threshold (δ) 0.8
Trust density threshold (θ) 0.6
Loss threshold (L
max
) 0.5
Self-reliance factor (γ) 0.95
Self-healing duration (∆) 10 rounds
5.2 Defense Strategies Compared
We compare four approaches:
• No Defense: neighbor updates are aggregated
without filtering or weighting.
• Static Weighting: aggregation with fixed trust
weights.
• Variance Only: reputation scores updated based
on deviation from consensus.
• Full Defense: complete model including vari-
ance scoring, Byzantine-aware filtering, and self-
healing.
5.3 Scenario-Based Evaluation
Each scenario simulates a different adversarial con-
figuration around the target node:
• Scenario A (Isolated Attack): one neighbor
sends poisoned updates.
• Scenario B (Coalition - 40%): 40% of neighbors
coordinate poisoned updates.
• Scenario C (Full Compromise): all neighbors
are malicious and colluding.
• Scenario D (Dynamic Adversaries): attackers
appear and disappear during training.
5.4 Accuracy of the Target Node
Figure 2 shows the average classification accuracy
of the target node in all scenarios. In Scenario A,
even the Variance Only defense performs well, as
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
544
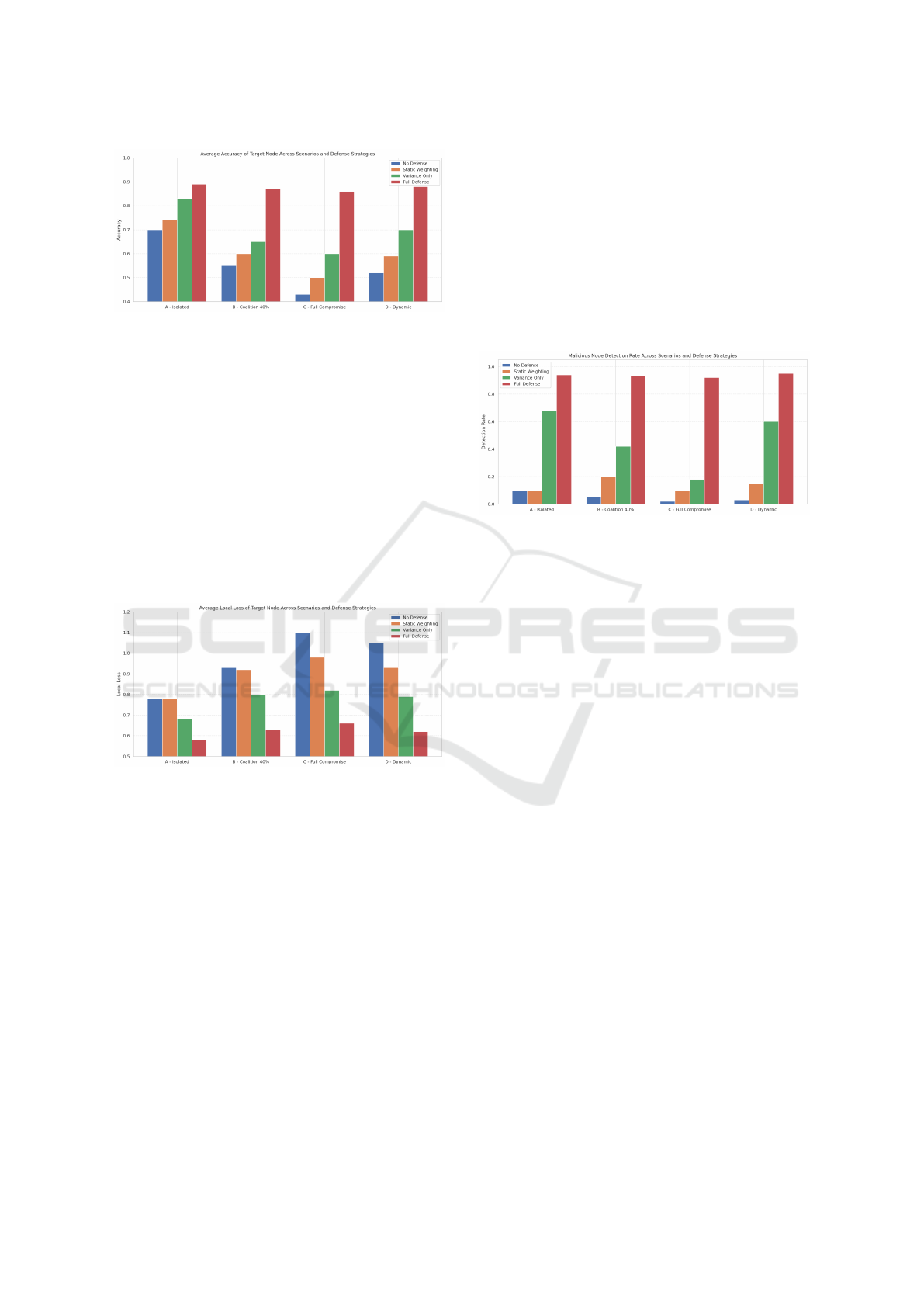
Figure 2: Target node accuracy across scenarios and defense
strategies.
the isolated attack is easily detectable. However, in
Scenarios B and C, involving coordinated poisoning,
variance-based defense becomes less effective, failing
to detect consistent malicious updates. In contrast,
the Full Defense mechanism—combining statistical
filtering, trust thresholding, and self-healing - main-
tains high precision and effectively mitigates coalition
attacks. In Scenario D, with dynamic adversaries, the
full strategy again proves adaptive, supporting robust
learning under evolving attack patterns.
5.5 Local Loss of the Target Node
Figure 3: Local loss observed by the target node across sce-
narios.
Figure 3 reports the average local loss observed by the
target node in different attack scenarios and defense
strategies. The loss reflects the model’s ability to fit
its local data despite adversarial interference.
In Scenario A, all strategies limit the loss, and
variance-based defense already provides noticeable
improvement over baseline, confirming that isolated
attackers can be effectively down-weighted by devia-
tion detection.
In Scenarios B and C, adversarial coordination be-
comes more evident: coherent poisoned updates re-
duce variance, weakening the variance-only defense.
Consequently, local loss remains elevated even with
statistical filtering, and static weighting also fails to
mitigate the poisoning effect.
In contrast, the full defense consistently achieves
the lowest loss in all scenarios, highlighting the bene-
fits of combining reputation filtering, threshold-based
rejection, and self-healing to preserve model integrity.
Scenario D further emphasizes the need for adap-
tivity: as attack patterns evolve, the full defense dy-
namically adjusts, maintaining bounded local loss.
Overall, these results confirm that our model not only
prevents convergence failures but also maintains ro-
bust learning under realistic adversarial conditions.
5.6 Malicious Node Detection Rate
Figure 4: Detection rate of malicious neighbors by the tar-
get node.
Figure 4 presents the detection rate of malicious
neighbors by the target node across scenarios. This
metric measures the ability to correctly identify poi-
soned updates.
In Scenario A (isolated attacker), the Variance
Only defense achieves a detection rate above 65%, ef-
fectively capturing outlier updates. However, in Sce-
nario B (coalition of 40%), the detection rate drops to
42% as colluding attackers reduce the variance, mak-
ing malicious behavior statistically indistinguishable
from honest peers.
The situation worsens in Scenario C (full compro-
mise), where variance-based detection almost fails,
with rates as low as 18%. This highlights the limits
of relying solely on variance signals.
In contrast, the full defense mechanism consis-
tently exceeds 90% detection in all scenarios, includ-
ing dynamic attacks (Scenario D). This robustness
results from combining variance monitoring, reputa-
tion filtering, and self-healing, enabling the system to
identify poisoning sources even under subtle adver-
sarial conditions.
Overall, these results confirm that single-layer
anomaly detection is insufficient in adversarial peer-
to-peer environments. A layered and adaptive ap-
proach, which integrates multiple signals over time,
is essential for robust defense.
Robust Peer-to-Peer Machine Learning Against Poisoning Attacks
545

6 CONCLUSION
We addressed poisoning attacks in peer-to-peer ma-
chine learning, where nodes aggregate updates with-
out central authority. Although scalable and privacy-
friendly, this architecture complicates the detection of
malicious behaviors, especially in the presence of col-
luding adversaries.
We proposed a defense framework that combines
variance-based reputation scoring, Byzantine-aware
thresholding, and feedback-driven self-healing, en-
abling nodes to detect and mitigate both isolated and
coordinated attacks.
Experiments show that variance alone is insuffi-
cient against collusions, whereas our full defense pre-
serves model accuracy, reduces loss, and maintains
high detection rates under dynamic adversarial condi-
tions.
Future work will explore context-sensitive dy-
namic trust thresholds to further enhance the adapt-
ability and resilience of decentralized learning sys-
tems.
REFERENCES
Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., and
Shmatikov, V. (2020). How to backdoor federated
learning. In International conference on artificial in-
telligence and statistics, pages 2938–2948. PMLR.
Bhagoji, A. N., Chakraborty, S., Mittal, P., and Calo, S.
(2019). Analyzing federated learning through an ad-
versarial lens. In International conference on machine
learning, pages 634–643. PMLR.
Bouhaddi, M. and Adi, K. (2024). When rewards deceive:
Counteracting reward poisoning on online deep re-
inforcement learning. In 2024 IEEE International
Conference on Cyber Security and Resilience (CSR),
pages 38–44. IEEE.
Cao, X. and Gong, N. Z. (2022). Mpaf: Model poison-
ing attacks to federated learning based on fake clients.
In Proceedings of the IEEE/CVF conference on com-
puter vision and pattern recognition, pages 3396–
3404.
Hossain, M. T., Islam, S., Badsha, S., and Shen, H. (2021).
Desmp: Differential privacy-exploited stealthy model
poisoning attacks in federated learning. In 2021 17th
International Conference on Mobility, Sensing and
Networking (MSN), pages 167–174. IEEE.
Li, H., Sun, X., and Zheng, Z. (2022). Learning to at-
tack federated learning: A model-based reinforcement
learning attack framework. Advances in Neural Infor-
mation Processing Systems, 35:35007–35020.
Naseri, M., Hayes, J., and De Cristofaro, E. (2020). Lo-
cal and central differential privacy for robustness
and privacy in federated learning. arXiv preprint
arXiv:2009.03561.
Panda, A., Mahloujifar, S., Bhagoji, A. N., Chakraborty, S.,
and Mittal, P. (2022). Sparsefed: Mitigating model
poisoning attacks in federated learning with sparsifi-
cation. In International Conference on Artificial In-
telligence and Statistics, pages 7587–7624. PMLR.
Rong, D., Ye, S., Zhao, R., Yuen, H. N., Chen, J., and He,
Q. (2022). Fedrecattack: Model poisoning attack to
federated recommendation. In 2022 IEEE 38th In-
ternational Conference on Data Engineering (ICDE),
pages 2643–2655. IEEE.
Shafahi, A., Huang, W. R., Najibi, M., Suciu, O., Studer,
C., Dumitras, T., and Goldstein, T. (2018). Poison
frogs! targeted clean-label poisoning attacks on neural
networks. Advances in neural information processing
systems, 31.
Shejwalkar, V., Houmansadr, A., Kairouz, P., and Ramage,
D. (2022). Back to the drawing board: A critical eval-
uation of poisoning attacks on production federated
learning. In 2022 IEEE Symposium on Security and
Privacy (SP), pages 1354–1371. IEEE.
Sun, Y., Ochiai, H., and Sakuma, J. (2022). Semi-targeted
model poisoning attack on federated learning via
backward error analysis. In 2022 International Joint
Conference on Neural Networks (IJCNN), pages 1–8.
IEEE.
Sun, Z., Kairouz, P., Suresh, A. T., and McMahan, H. B.
(2019). Can you really backdoor federated learning?
arXiv preprint arXiv:1911.07963.
Tolpegin, V., Truex, S., Gursoy, M. E., and Liu, L. (2020).
Data poisoning attacks against federated learning sys-
tems. In Computer security–ESORICs 2020: 25th
European symposium on research in computer secu-
rity, ESORICs 2020, guildford, UK, September 14–
18, 2020, proceedings, part i 25, pages 480–501.
Springer.
Xie, C., Huang, K., Chen, P.-Y., and Li, B. (2019). Dba:
Distributed backdoor attacks against federated learn-
ing. In International conference on learning repre-
sentations.
Zhou, X., Xu, M., Wu, Y., and Zheng, N. (2021). Deep
model poisoning attack on federated learning. Future
Internet, 13(3):73.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
546
