
Customer Support Ticket Categorization and Prioritization Using
Natural Language Processing
C. S Kanimozhi Selvi, S. Jyothi Shri, R. Prasshanthini, Neelamegan and R. Sanjay
Department of Artificial Intelligence, Kongu Engineering College, Erode, Tamilnadu, India
Keywords: Customer Support, NLP Automation, Ticket Categorization, Prioritization Models, Supervised Learning,
Deep Learning.
Abstract: Efficient and effective customer service relies heavily on the systematic management of customer support
tickets. This paper presents an Natural Language Processing (NLP) - driven system designed to automate the
categorization and prioritization of customer support tickets, significantly enhancing service efficiency. The
system analyzes ticket content using machine learning models and deep learning models for both
categorization and prioritization tasks. Categorization is achieved using Topic Modeling (NMF) to identify
department-specific categories, while ticket priority levels are determined by extracting urgency and impact
keywords. By leveraging these techniques, the system streamlines ticket handling, reduces manual
intervention, and optimizes resource allocation. Experimental results demonstrate high accuracy, scalability,
and improved operational efficiency, ultimately enhancing customer satisfaction.
1 INTRODUCTION
In today’s highly competitive market, customer
support is the order of the day for customer
satisfaction and loyalty. Support teams face the
ongoing challenge of managing a high volume of
diverse queries, such as payment issues, general
inquiries, technical problems, and product requests.
Accurate categorization and prioritization are crucial
to ensure swift, personalized resolutions that meet
customer expectations. Traditional ticket handling
processes rely heavily on manual efforts, which are
time-consuming, labor-intensive, and prone to human
error. As customer bases expand, the need for
intelligent, automated solutions to streamline these
operations becomes increasingly evident. Efficient
categorization and prioritization are, therefore,
critical components of modern customer support
systems.
This study introduces an advanced framework
leveraging machine learning and deep learning
techniques to address these challenges effectively.
The framework classifies support tickets into
appropriate departmental categories and assigns
priority levels based on factors like urgency and
impact. Using a comprehensive dataset of 78,313
customer complaints, the work rigorously builds and
evaluates various ML and DL models for these tasks.
To handle unlabeled data, Topic Modeling techniques
such as Non-negative Matrix Factorization (NMF)
are applied to categorize queries into five distinct
departmental groups. By automating support ticket
management, this framework aims to significantly
enhance operational efficiency, reduce manual effort,
and improve overall customer satisfaction. This
automation ultimately strengthens customer
relationships and fosters long-term loyalty by
providing timely, accurate support.
2 LITERATURE SURVEY
In 2024, Carla Vairetti et al. (Vairetti, Aránguiz, et al.
, 2024) introduced a framework that combines
multicriteria decision-making (MCDM) and deep
learning to prioritize complaints. The framework
automates complaint classification and prioritization
using text analytics and operational research
techniques. It bridges deep learning with traditional
machine learning by incorporating pretrained models.
MCDM is applied to combine multiple criteria into a
single prioritization score, enhancing decision-
690
Selvi, C. S. K., Shri, S. J., Prasshanthini, R., Neelamegan, and Sanjay, R.
Customer Support Ticket Categorization and Prioritization Using Natural Language Processing.
DOI: 10.5220/0013640400004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 3, pages 690-698
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

making. The framework's effectiveness is
demonstrated by its application to real-world data
from a Chilean agency. This approach improves
efficiency in managing complaints across various
service sectors.
In 2022, Alvaro Aldunate et al. (Aldunate,
Maldonado, Declerck, 2022)presented a
methodology which utilizes BERT and transfer
learning to uncover customer satisfaction factors
across various sectors. It highlights the superiority of
deep learning models over traditional text mining
methods in classification accuracy. The research
emphasizes the importance of automated evaluation
of consumer feedback for decision-making in the
service sector. A four-step methodology is used to
extract relevant insights from open-ended survey
responses. The study demonstrates how NLP and
deep learning can enhance customer experience
analysis.
In 2023, Peter Adebowale Olujimi et al. (Olujimi,
and, Ibijola, 2023)] reviewed 73 studies on the use of
NLP to automate customer queries across various
industries. The research highlights benefits like faster
response times, improved accuracy, and higher
customer satisfaction, indicating the increasing
demand for automated customer care systems. It
suggests that future research could explore advanced
NLP models and AI integration to further enhance
consumer interactions. The study emphasizes the
importance of thorough literature reviews for
credibility and adds to the growing body of
knowledge on NLP’s role in transforming customer
service and boosting corporate performance.
In 2021, H. A. Ahmed et al. (Ahmed, Bawany, et
al. , 2021) introduced CaPBug, a system for
automating software bug prioritization and learning
models, including CNNs, BiLSTMs, and BERT. It
demonstrated that BERT combined with TF-IDF and
Logistic Regression achieved the best macro-
averaged F1-score, highlighting the effectiveness of
pre-trained models in automating complaint
prioritization and improving resource allocation in
customer service.
The system analyzes bug reports from Eclipse
and Mozilla using supervised machine learning and
natural language processing (NLP). Bug reports were
manually classified into six categories and five
priority levels from 2016 to 2019. The system
predicts bug categories and priorities using textual
and categorical data, with feature extraction using
TF-IDF and NLP algorithms. Popular classification
methods are employed. The system improves
software maintenance by accurately predicting issues
and addressing class imbalance in priority levels.
In 2020, Nikhil Patel et al. (Patel, and, Trivedi,
2020) explored the use of predictive modeling,
machine learning, NLP, and AI chatbots to enhance
customer support and loyalty. The study examines
NLP applications across industries like marketing, e-
commerce, healthcare, telecommunications, and
finance, based on 26 articles from 2015 to 2022.
Common techniques like TF-IDF and SVM are
highlighted. The research discusses the need for
larger datasets to improve NLP applications in
customer service. Various models like TextCNN,
AdaBoost, and LDA were also applied in the study,
focusing on response quality, helpfulness, and
appropriateness.
In 2018, Sridhar Ramaswamy et al. (Ramaswamy,
and, DeClerck, 2020)explored using NLP and deep
learning for customer perception analysis. The study
integrates various technologies to extract insights
from consumer feedback, emphasizing the
importance of understanding consumer attitudes and
preferences. It discusses methods like named entity
recognition, rule-based semantics, and semantic
annotation to improve perception analysis. The
authors suggest using industry-specific survey
questions for more detailed insights.
In 2018, Ruanda Qamili et al. (Qamili, Shabani, et
al. , 2018) aimed to enhance customer service
productivity by incorporating machine learning into
ticketing systems. The study covers sentiment
analysis, ticket assignment, and spam detection in
customer support. It proposes an automated solution
to improve ticket management and reduce false
positives in spam filtering using a conservative
unanimity method. The authors emphasize the
importance of addressing delayed issue resolutions in
customer service.
In 2021, Nokudaiyaval G et al. (Kirthiga, and,
Ghayathri, 2021)developed a system using NLP and
the BERT algorithm to reduce labor and save
customers' time in customer support. NLP is used for
speech recognition, while BERT handles text
classification and prediction. Unlike existing systems
using IVR to route calls, the proposed solution
generates automated responses without human
intervention. The system is pre-trained using a closed
dataset, with tokenization applied to customer input.
BERT’s bidirectional search locates key interaction
information, providing a response between start and
finish parameters. This approach improves customer
support services by reducing reliance on human
interactions.
In 2022, Blümel and Zaki (Blümel, and, Zaki,
2022) conducted a comparative analysis of classical
and deep learning-based natural language processing
Customer Support Ticket Categorization and Prioritization Using Natural Language Processing
691

methods to prioritize customer complaints. The study
combined feature engineering techniques like TF-
IDF and Word2Vec with machine learning classifiers
and deep learning models, including CNNs,
BiLSTMs, and BERT. It demonstrated that BERT
combined with TF-IDF and Logistic Regression
achieved the best macro-averaged F1-score,
highlighting the effectiveness of pre-trained models
in automating complaint prioritization and improving
resource allocation in customer service.
In 2018, Silva et al. (Silva, Pereira, et al. , 2018)
introduced a machine learning-based module to
automate the categorization of IT incident tickets.
The proposed system uses a support vector machine
(SVM) to classify tickets, achieving an accuracy of
approximately 89% on real-world data. The module
enhances incident management productivity by
reducing routing errors and minimizing delays in
ticket assignment, contributing to improved IT
service delivery and customer satisfaction.
In 2023, Reddy and Prabhu (Reddy, and, Prabhu,
2023) conducted a comprehensive review on the role
of artificial intelligence in request management
processes. The study highlights AI's transformative
potential in automating request capture, logging,
categorization, and prioritization using techniques
like NLP, machine learning, and chatbots. It discusses
the challenges in manual request management and the
benefits of AI in enhancing workflow optimization,
resource allocation, and scheduling. The paper
underscores the impact of AI in improving efficiency,
accuracy, and customer satisfaction in request
management systems.
In 2019, Lucini et al. (Lucini, Tonetto, et al. ,
2019) proposed a text mining framework to analyze
airline customer satisfaction using Online Customer
Reviews (OCRs). They examined 55,775 reviews
across 419 airlines, identifying 27 satisfaction
dimensions and 882 adjectives through Latent
Dirichlet Allocation (LDA). The framework achieved
a prediction accuracy of 79.95% for customer airline
recommendations. Key satisfaction factors included
cabin staff, onboard service, and value for money.
The study provides actionable insights, highlighting
the need for tailored strategies in customer service
and comfort based on cabin class preferences to
enhance competitiveness in the airline industry.
In 2022, Ishizuka et al. (Ishizuka, Washizaki, et
al. , 2022) proposed a novel method to improve
feature comprehension in software development
projects using issue tickets. The method categorizes
tickets through clustering and visualizes them using
heatmapping and principal component analysis
(PCA). It also includes ticket lifetime visualization
for time-series analysis and keyword relationships
among ticket categories. A case study on an industrial
project demonstrated its effectiveness in helping
project members and newcomers understand
implemented features. The study emphasizes the
value of structured, visualized tickets in enhancing
onboarding and comprehension of multi-dimensional
requirements in evolving projects.
In 2019, Al-Hawari and Barham (Hawari, and,
Barham, 2019) introduced a machine learning-based
help desk system aimed at improving IT service
management. The system utilizes a ticket
classification model to streamline ticket resolution by
automatically associating help desk tickets with the
correct service. The methodology involves training
ticket data, preprocessing, stemming, feature
vectorization, and algorithm tuning. Experimental
results revealed that incorporating ticket comments
and descriptions significantly improved model
accuracy from 53.8% to 81.4%. The system also
features administrator and user views, supports
automatic email notifications, and enables
performance measurement through key performance
indicators (KPIs) for IT staff and processes.
In 2023, Benitez Pereira et al. (Pereira, Pizzio, et
al. , 2023) presented a machine learning model for
classifying IT support tickets to enhance help desk
operations. The model categorizes incoming support
tickets into seven topics with an average precision of
75%. To support daily operations, a web prototype
was developed, offering both frontend and backend
functionalities for IT analysts. The code, model, and
anonymized data were made publicly available for
replication of the study. This approach helps
minimize ticket resolution time and improves user
satisfaction by automating ticket topic identification.
3 PROPOSED METHODOLOGY
3.1 Data Collection
The dataset comprises complaint texts submitted by
customers to a financial institution. This dataset,
sourced from Kaggle, is specifically designed to
facilitate the classification and prioritization of
customer support tickets. It contains a total of 78,313
individual complaints, each in JSON format,
capturing various issues and grievances reported by
users. The data aims to support the development of
models or systems that can categorize these
complaints effectively and determine their priority
levels, enhancing customer service workflows.
INCOFT 2025 - International Conference on Futuristic Technology
692
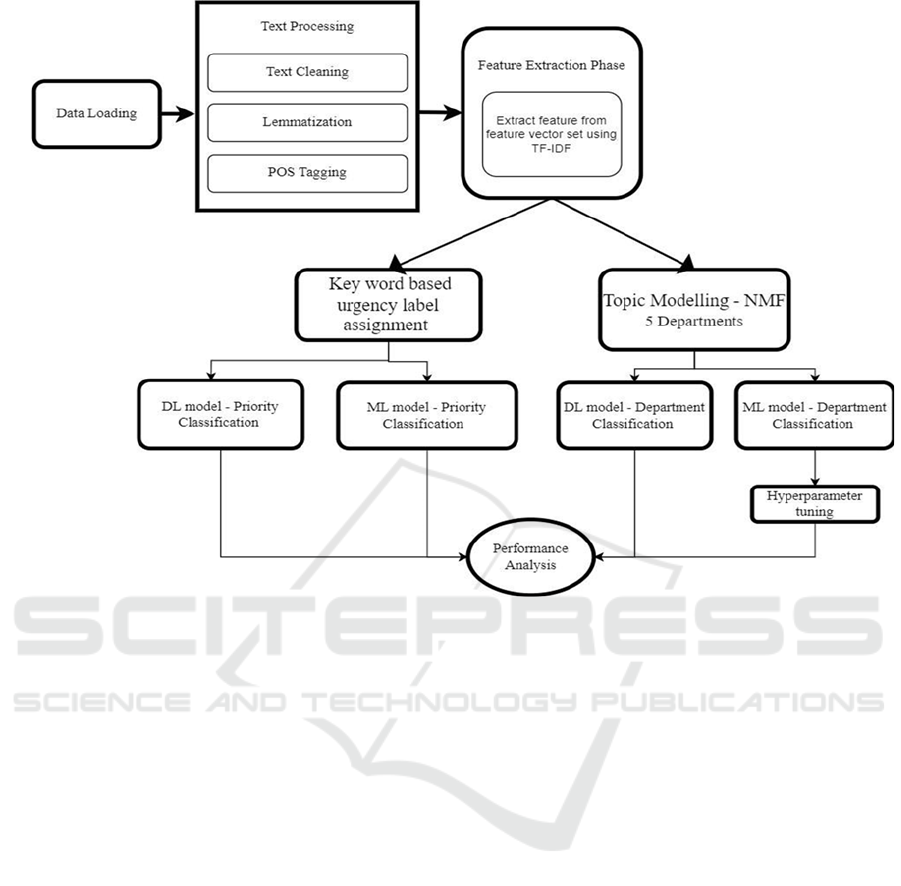
Figure 1: Department classification ML model’s accuracies.
3.2 Data Preprocessing
The initial phase of classifying customer complaints
into departments involves comprehensive text
preprocessing to ensure data quality and relevance.
This process begins by removing unnecessary or
duplicate fields from the dataset, retaining only
essential information for analysis. Blank or
incomplete entries are identified and eliminated to
maintain data integrity. Text data is standardized
through methods like converting all text to lowercase
and removing punctuation using regular expressions,
which simplifies further analysis. Lemmatization is
applied to reduce words to their root forms, enhancing
consistency and aiding tasks such as information
retrieval and sentiment analysis. Masked personal
data is removed to eliminate personal details of the
user.
Feature extraction is initially performed using
TF-IDF (Term Frequency-Inverse Document
Frequency), a technique that highlights the most
important and relevant terms within the complaints.
By analyzing the frequency of terms across multiple
documents, it helps identify key words that are
significant in the context of the dataset. These
extracted features are then used for topic modeling,
where the most common terms present across the
complaints are analyzed to uncover underlying, latent
themes within the text data. Topic modeling is carried
out using NMF (Non-negative Matrix Factorization).
For each topic, the top 10 words are extracted, and
these words are manually mapped to predefined
categories such as Retail Banking Operations, Credit
Card Management, Payment and Billing, Dispute
Reporting, and Mortgages/Loans. This mapping
process ensures that each customer complaint is
accurately classified into the appropriate department,
which facilitates better message forwarding and
streamlined management of the complaints. For
prioritization of complaints, urgency is determined by
matching text tokens against a predefined list of
urgent words that signify a time-sensitive issue.
Advanced NLP tools, such as spaCy and negspacy,
are used to detect negation within the text, ensuring
that phrases like "not urgent" are correctly
interpreted. This method guarantees that complaints
are accurately classified as urgent or non-urgent, even
when negation modifies the meaning of key words.
This approach enhances the ability to prioritize
critical issues effectively, ensuring that the most time-
sensitive complaints are addressed promptly.
Customer Support Ticket Categorization and Prioritization Using Natural Language Processing
693

3.3 Machine Learning Models
3.3.1 Logistic Regression
This algorithm establishes a relationship between the
input features and the probability of a binary outcome
by applying a logistic function, making it highly
effective for predicting outcomes in two categories.
This algorithm is ideal for classifying customer
complaints into predefined categories and prioritizing
them. In this case, it helps to extract the most relevant
terms from the complaints using TF-IDF, which
boosts the model’s ability to accurately categorize
and prioritize complaints. The model achieved a
classification accuracy of 91.99%, efficiently sorting
complaints into their respective categories. For
prioritization, the model achieved an accuracy of
90.11%, demonstrating its ability to accurately
determine the urgency of complaints.
3.3.2 Decision Tree
The Decision Tree is a algorithm which divides the
dataset into smaller subsets by selecting decision
nodes based on the most relevant features, forming a
tree structure where each leaf represents a
classification label or a continuous value. This
method is effective for handling complex datasets
with multiple features, and it is highly interpretable.
By creating decision boundaries based on feature
values, it excels at categorizing complaints and
prioritizing them according to urgency. The model
achieved a classification accuracy of 78.44%,
accurately sorting complaints into predefined
categories. For prioritization, it achieved an
exceptional accuracy of 99.96%, effectively
differentiating between urgent and non-urgent
complaints with high precision.
3.3.3 Random Forest Classifier
This generates a collection of decision trees, each
built from various subsets of the data, and then
averages their outputs to mitigate overfitting and
improve accuracy. This method is particularly
effective for handling complex datasets, managing
large volumes of data, and providing feature
importance metrics. By using an ensemble approach,
Random Forest reduces both bias and variance
compared to a single decision tree, making it a
reliable choice for classifying and prioritizing
complaints. The model achieved a classification
accuracy of 81.13%, successfully organizing
complaints into predefined categories. For
prioritization, it reached an accuracy of 90.03%,
effectively distinguishing between urgent and non-
urgent complaints.
3.3.4 Support Vector Machine
Support Vector Machine (SVM) identifies the
optimal hyperplane that separates data points into
distinct classes, maximizing the margin between the
nearest points of different categories. This makes
SVM particularly effective for handling high-
dimensional datasets and complex classification
problems. Additionally, it excels in scenarios where
the data is not linearly separable, a common
characteristic of real-world datasets. In this study,
SVM achieved an impressive classification accuracy
of 91.51%, effectively sorting customer complaints
into predefined categories. For prioritization, the
model demonstrated a strong performance with an
accuracy of 94.68%, efficiently distinguishing
between urgent and non-urgent complaints.
3.3.5 Multinomial Naïve Bayes
Multinomial Naive Bayes is a algorithm tailored for
text classification tasks. It leverages Bayes' Theorem
and operates under the assumption that features, such
as words in a text dataset, are conditionally
independent of each other when conditioned on the
class label. This algorithm is ideal for classifying
customer complaints into predefined categories and
prioritizing them, as it can handle large vocabularies
and text-based features efficiently. Its probabilistic
nature helps in assigning the most likely category
based on the frequency of words in the complaints.
The model achieved an accuracy of 71.87% for
classification, accurately categorizing customer
complaints into predefined categories. For
prioritization, the model achieved an accuracy of
89.39%, although it performed poorly on the "urgent"
category, as reflected in its recall of 0%.
3.3.6 Gradient Boosting Machines
Gradient Boosting Machines (GBM) is an ensemble
algorithm that integrates multiple weak models to
form a robust predictive system, making it well-suited
for complex tasks such as text classification. It has
proven effective in categorizing customer complaints
and ranking them by urgency. GBM excels at
processing large datasets and modeling intricate
patterns, making it a strong candidate for prioritizing
and classifying customer issues. The model
demonstrated high performance, achieving a
classification accuracy of 90.45% and a prioritization
INCOFT 2025 - International Conference on Futuristic Technology
694

accuracy of 98.84%, particularly excelling in
identifying "urgent" and "not urgent" complaints.
3.3.7 XG Boosting
XG Boost is an advanced gradient boosting algorithm
known for its speed and performance in classification
tasks, making it well-suited for customer complaint
classification and prioritization. By leveraging
decision trees in an ensemble framework, XG Boost
efficiently handles large datasets with missing values
and complex relationships. In the classification task,
the model achieved an accuracy of 91.17% in
categorizing complaints, while for prioritization, it
achieved an outstanding 99.73% accuracy, excelling
at distinguishing between "urgent" and "not urgent"
complaints. Its high precision and recall reflect its
strong predictive performance.
3.4 Deep Learning Models
3.4.1 BERT
BERT (Bidirectional Encoder Representations from
Transformers), is an advanced transformer leveraged
deep learning model developed for natural language
understanding. By employing a bidirectional
attention mechanism, it analyzes a word's context by
considering the words on both sides within a
sentence, making it exceptionally efficient for tasks
like text classification. This makes BERT particularly
suitable for tasks like department categorization and
urgency prioritization, where understanding the
nuanced meaning of words in context is crucial. For
department categorization, BERT achieved an
accuracy of 81%, while for urgency prioritization, it
performed even better with an accuracy of 92%,
showcasing its strong capability in both tasks.
3.4.2 RNN
A Recurrent Neural Network (RNN) is a model
tailored for sequential data processing, using a hidden
state to retain information from prior inputs and
capture dependencies over time. This makes RNNs
especially suitable for tasks involving sequences,
such as text classification in department
categorization and urgency prioritization, where the
order of words or phrases can influence the meaning.
In the department categorization task, RNN achieved
an accuracy of 80%, while for urgency prioritization,
it also achieved an accuracy of 92%, showing that it
can handle both tasks effectively.
3.4.3 CNN
A Convolutional Neural Network (CNN) is typically
used for image processing but has proven effective
for text classification tasks by applying convolutional
layers to extract local patterns from sequences of text.
This ability to detect local features makes CNNs
suitable for department categorization and urgency
prioritization, where the focus is on identifying
important keywords or phrases within text. CNNs are
particularly effective when the task benefits from
recognizing local patterns and structures in data, such
as words or phrases with specific relevance. In
department categorization, CNN achieved an
accuracy of 80%, while for urgency prioritization, the
model achieved an accuracy of 91%, showing its
ability to handle both tasks with competitive
performance.
4 PERFORMANCE ANALYSIS
This study evaluates model performance using
Precision, Recall, F1-Score, and Accuracy. Precision
indicates the ratio of correctly predicted positive
cases to the total positive predictions, showcasing the
model's reliability in positive classifications. Recall,
assesses the model's effectiveness in detecting all
actual positive instances, calculated as the proportion
of true positives among all actual positives. The F1-
Score, offers a balanced evaluation by accounting for
both false positives and false negatives, making it
particularly valuable for imbalanced datasets. Lastly,
Accuracy measures the percentage of all correct
predictions, encompassing both true positives and
true negatives, providing a comprehensive
performance overview.
Table 1: Comparison of ml models for department
categorization
Model Precision Recall F1
Score
Accuracy
(%)
Logistic
Regression
0.93 0.91 0.92 0.92
SVM 0.92 0.91 0.91 0.92
XG Boost 0.91 0.91 0.91 0.91
Gradient
Boosting
Machines
0.90 0.90 0.90 0.90
Random Forest 0.83 0.77 0.78 0.81
Decision Tree 0.78 0.78 0.78 0.78
Multinomial
Naïve Bayes
0.79 0.64 0.61 0.72
Customer Support Ticket Categorization and Prioritization Using Natural Language Processing
695
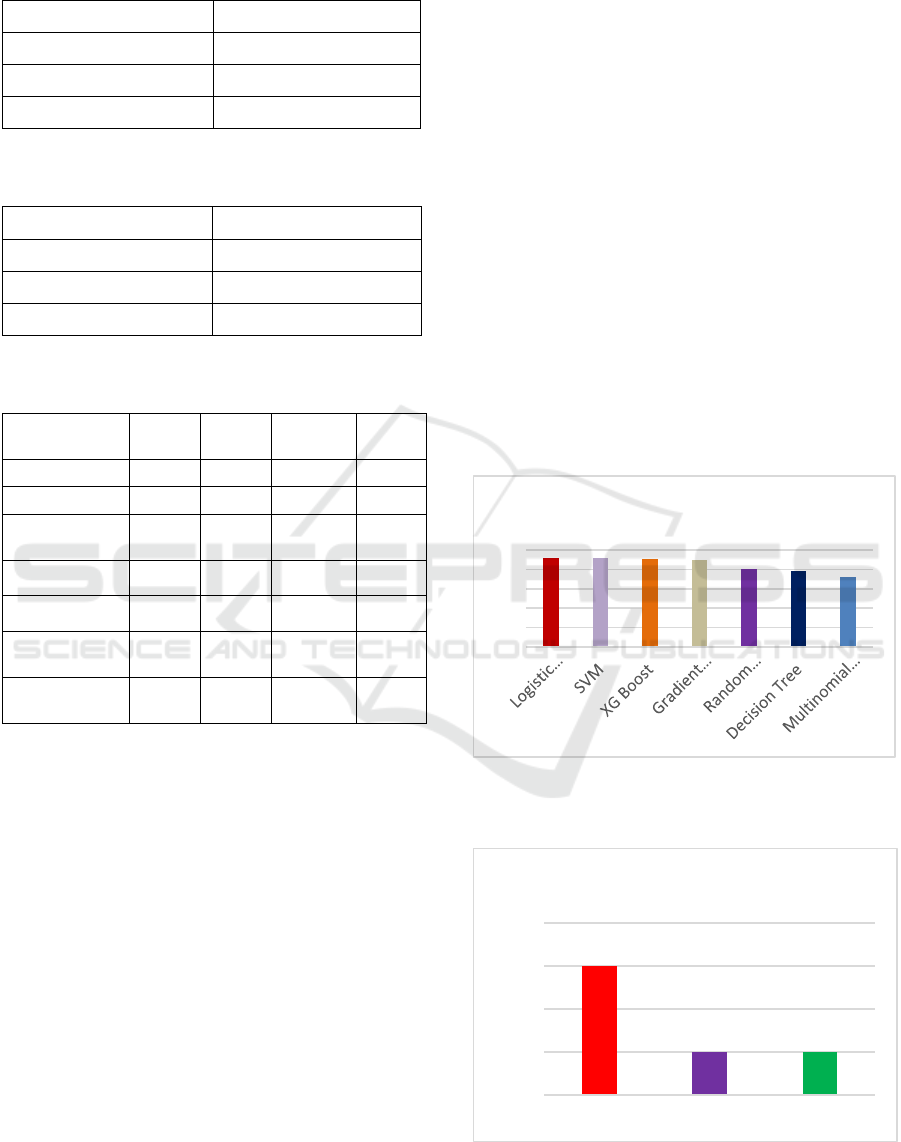
Table 2: Comparison of dl models for department
categorization
Model Accuracy(%)
BERT 0.81
RNN 0.80
CNN 0.80
Table 3: Comparison of dl models for urgency
prioritization
Model Accuracy(%)
BERT 0.92
RNN 0.92
CNN 0.91
Table 4: Comparison of ml models for urgency
prioritization
Model Precision Recall F1 Score Accuracy
(%)
Decision Tree 1.00 1.00 1.00 1.00
XG Boost 1.00 1.00 1.00 1.00
Gradient Boosting
Machines
0.99 0.95 0.97 0.99
SVM 0.97 0.75 0.82 0.95
Random Forest 0.94 0.53 0.53 0.90
Logistic
Regression
0.93 0.53 0.54 0.90
Multinomial Naïve
Bayes
0.45 0.50 0.47 0.89
5 RESULTS AND DISCUSSION
To find best model for both the categorization of
departmental affiliations and the prioritization of
tickets, the study conducted a thorough evaluation of
the performance of various machine learning and
deep learning architectures. In the department
classification task, logistic regression emerged as the
best-performing machine learning model, achieving
the highest accuracy of 91.99%, closely followed by
SVM (91.51%) and XG Boost (91.17%). Gradient
Boosting Machines demonstrated solid results with
an accuracy of 90.45%, while Random Forest and
Decision Tree performed moderately, achieving
81.13% and 78.44%, respectively. Multinomial
Naive Bayes, however, recorded the lowest accuracy
at 71.87%, indicating its limited suitability for this
task. Among the deep learning models, BERT stood
out with the highest accuracy of 81.00%, showcasing
its ability to leverage pre-trained contextual
embeddings effectively. CNN and RNN followed
closely with accuracies of 80.83% and 80.45%,
respectively, indicating competitive but slightly
lower performance compared to transformer-based
architectures. In the priority classification task,
Decision Tree outperformed all other models,
achieving a remarkable accuracy of 99.96%. Gradient
Boosting Machines (98.84%) and XG Boost
(99.73%) also demonstrated exceptional
performance. Logistic Regression (90.11%), Random
Forest (90.03%), and SVM (94.68%) showed
consistent and reliable results, while Multinomial
Naive Bayes lagged slightly with an accuracy of
89.39%. Among deep learning models, BERT again
proved to be the most effective, achieving an
accuracy of 92.64%, followed closely by CNN
(92.50%) and RNN (91.79%). These results reaffirm
the effectiveness of BERT's pre-trained embeddings
in handling natural language tasks with contextual
complexity.
Figure 2: Department classification ML model’s accuracies
Figure 3: Department classification DL model’s accuracies
0.92 0.92
0.91
0.9
0.81
0.78
0.72
0
0.2
0.4
0.6
0.8
1
Accuracy
0.81
0.8 0.8
0.795
0.8
0.805
0.81
0.815
BERT RNN CNN
Accuracy
INCOFT 2025 - International Conference on Futuristic Technology
696
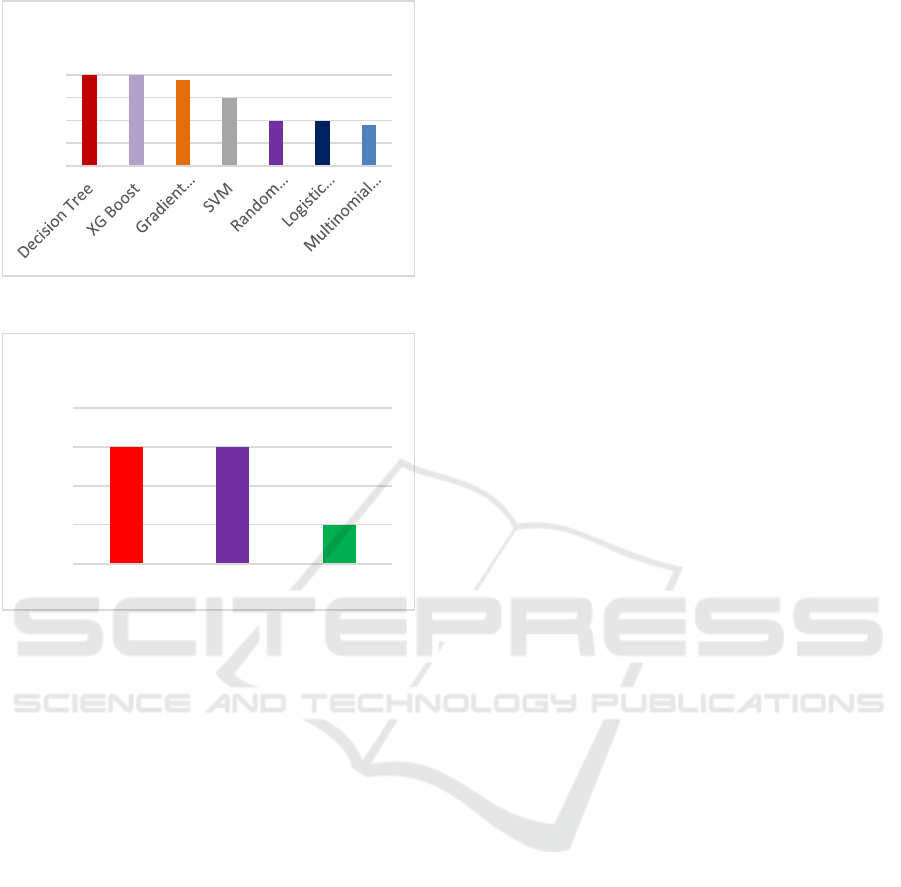
Figure 4: Priority classification ML model’s accuracies
Figure 5: Priority classification DL model’s accuracies
6 CONCLUSIONS
This project represents a significant stride in
automating customer support ticket management,
offering a comprehensive solution for both
department categorization and priority classification.
Logistic regression emerged as a standout performer
in department classification, achieving an impressive
accuracy of 91.99%, closely trailed by SVM and XG
Boost. Conversely, decision tree excelled in priority
classification, boasting an exceptional accuracy of
99.96%. The inclusion of deep learning models,
notably BERT, showcased competitive performance,
particularly in priority classification, achieving an
accuracy of 92.64%. These findings highlight the
efficacy of machine learning (ML) and deep learning
(DL) techniques in enhancing ticket management
processes and elevating customer satisfaction levels.
Deep learning models, like BERT, will exhibit
superior performance when confronted with larger
datasets and complex, unstructured data, as they can
discern intricate patterns and dependencies.
Furthermore, DL models may outperform ML models
when trained over numerous epochs, leveraging their
ability to learn hierarchical representations of data.
Our study extends beyond conventional approaches
by incorporating innovative topic modelling
techniques to label unlabelled data effectively. This
approach not only improves model accuracy but also
demonstrates versatility and practicality in real-world
support environments, addressing the challenge of
limited availability of labelled data when coming to a
real world problem. By integrating both department
categorization and priority classification into a
unified framework, our research achieves remarkable
accuracy levels, surpassing previous studies that
focused solely on one aspect. Moving forward, future
research endeavours may explore additional
optimization strategies and investigate the
deployment of these models in diverse support
environments to validate scalability, effectiveness,
and real-world applicability
REFERENCES
Vairetti, C., Aránguiz, I., Maldonado, S., Karmya, J. P., &
Leal, A. (2024). Analytics-driven complaint
prioritisation via deep literacy and multicriteria
decision-timber. European Journal of Functional
Exploration, 312, 1108–1118.
Aldunate, Á., Maldonado, S., Vairetti, C., & Armelini, G.
(2022). Understanding client satisfaction via deep
literacy and natural language processing. Expert
Systems with Applications, 209, 118309.
Olujimi, P. A., & Ade-Ibijola, A. (2023). NLP ways for
automating responses to client queries: A methodical
review. Published online.
https://doi.org/10.1007/s44163-023-00065-5
Ahmed, H. A., Bawany, N. Z., & Shamsi, J. A. (2021).
CaPBug: A framework for automatic bug
categorization and prioritization using NLP and
machine learning algorithms. IEEE Access,
https://doi.org/10.1109/ACCESS.2021.3069248
Patel, N., & Trivedi, S. (2020). Using predictive modeling,
machine learning personalization, NLP client support,
and AI chatbots to increase client fidelity. EQM
ResearchBerg, 3(3), 1-10.
Ramaswamy, S., & DeClerck, N. (2020). Client perception
analysis using deep learning and NLP. Caterpillar Inc.,
Montgomery, IL 60538.
Qamili, R., Shabani, S., & Schneider, J. (2018). An
intelligent framework for issue ticketing system
grounded on machine literacy. Proceedings of the IEEE
EDOCW 2018, DOI: 10.1109/EDOCW.2018.00022
G, N., Kirthiga, R. V., & Ghayathri, J. (2021). Automatic
trailing of client support tickets using BERT algorithm.
Suhel SF, Shukla VK, Vyas S, Mishra VP, discussion
to robotization in banking through chatbot using
artificial machine intelligence language. In 2020 8th
International Conference on Trustability, Infocom
11
0.99
0.95
0.9 0.9
0.89
0.8
0.85
0.9
0.95
1
Accuracy
0.92 0.92
0.91
0.905
0.91
0.915
0.92
0.925
BERT RNN CNN
Accuracy
Customer Support Ticket Categorization and Prioritization Using Natural Language Processing
697

Technologies, and Optimization Trends and Unborn
Directions (ICRITO), IEEE, 611-618.
Blümel, J., & Zaki, M. (2022). Comparative analysis of
classical and deep learning-based natural language
processing for prioritizing customer complaints.
Proceedings of the 55th Hawaii International
Conference on System Sciences, 10 pages.
Silva, S., Pereira, R., & Ribeiro, R. (2018). Machine
learning in incident categorization automation. In 13th
Iberian Conference on Information Systems and
Technologies (CISTI), Caceres, Spain, 13-16 June
2018. IEEE.
Reddy, S. R. S., & Prabhu, V. (2023). Role of Artificial
Intelligence in Request Management: A
Comprehensive Review. In 2023 IEEE 11th Region 10
Humanitarian Technology Conference (R10-HTC).
IEEE.
Lucini, F. R., Tonetto, L. M., Fogliatto, F. S., & Anzanello,
M. J. (2019). Text mining approach to explore
dimensions of airline customer satisfaction using online
customer reviews. Journal of Air Transport
Management, 78, 101760.
Ishizuka, R., Washizaki, H., Tsuda, N., Fukazawa, Y., Ouji,
S., Saito, S., & Iimura, Y. (2022). Categorization and
visualization of issue tickets to support understanding
of implemented features in software development
projects. Applied Sciences, 12(7), 3222.
Al-Hawari, F., & Barham, H. (2019). A machine learning-
based help desk system for IT service management.
Journal of King Saud University-Computer and
Information Sciences.
Benitez Pereira, L. S., Pizzio, R., Bonho, S., Ferraz De
Souza, L. M., & Arnoni Junior, A. C. (2023). Machine
Learning for Classification of IT Support Tickets. In
2023 International Conference on Cyber Management
and Engineering (CyMaEn), Bangkok, Thailand. IEEE.
INCOFT 2025 - International Conference on Futuristic Technology
698
