
Social Media Sentiment Analysis: Twitter Dataset
Aarya Dalvi
1
, Mahek Dharod
1
and Manisha Tiwari
2
1
Mukesh Patel School of Technology Management & Engineering, Mumbai, India
2
Computer Science, MPSTME NMIMS, India
Keywords: Sentiment Analysis Natural Language Processing (NLP) Complement Naive Bayes (CNB) Model Sentiment
Polarity User-Generated Textual Content.
Abstract: Sentiment analysis is an important area in natural language processing (NLP), which helps in extracting
meaningful insights from text-based data. This paper explores the application of sentiment analysis
techniques, with a particular focus on the Complement Naive Bayes (CNB) model, to assess sentiment polarity
in user-generated content. The research aims to evaluate how effectively the CNB model classifies text as
either positive or negative, thus contributing to a more comprehensive understanding of methods in sentiment
analysis. This study utilizes a dataset of tweets, a widely used form of user-generated content, as the basis for
its analysis. Preprocessing steps such as tokenization, lemmatization, and text cleaning are conducted to
prepare the data for feature extraction, which is done using the CountVectorizer method. The Complement
Naive Bayes (CNB) model was chosen due to its effectiveness in handling imbalanced datasets and its
improvements over the traditional Naive Bayes algorithm. Through various tests and evaluations, the study
demonstrates that CNB can accurately classify sentiment. Metrics like accuracy, precision, recall, and F1
score provide quantitative insights into the model's performance, while the Receiver Operating Characteristic
(ROC) curve offers a visual representation of its discriminative power.
1 INTRODUCTION
1.1 Background
Social media platforms are widely used in today's
digital environment, providing a wealth of
unstructured text and valuable insights into public
opinion. Twitter's strong user involvement and real-
time updates make it a very useful tool for researchers
and analysts. Twitter's enormous user-generated
material, which includes tweets, comments, and
discussions, offers a multitude of data for researching
and analyzing public opinion. Businesses, legislators,
and researchers that want to comprehend public mood
and opinion on a variety of topics, goods, services,
and events will find this resource very helpful.
An enormous amount of textual data has been
produced by the quick development of social media
and digital content, providing a wealth of information
for examining consumer response, public opinion,
and new social trends. A crucial component of natural
language processing (NLP), sentiment analysis offers
important insights into the attitudes, beliefs, and
feelings expressed in this enormous volume of text.
With a focus on using the Complement Naive Bayes
(CNB) model for sentiment classification in textual
data, this study investigates sentiment analysis
techniques. (Pang and Lee, 2008)
Finding the sentiment or polarity—whether
positive, negative, or neutral—expressed in a text is
the goal of sentiment analysis, sometimes referred to
as opinion mining. Social media analysis, brand
reputation management, customer feedback
evaluation, and political opinion tracking are just a
few of its many uses. Large-scale sentiment
evaluation automation is a crucial tool for research
and real-world decision-making in a variety of
sectors.
Sentiment analysis, also known as opinion
mining, aims to identify the sentiment or polarity—
positive, negative, or neutral—conveyed in a text. It
has a wide range of applications, including analyzing
social media, managing brand reputation, assessing
customer feedback, and tracking political opinions.
Automating sentiment analysis on a large scale is
essential for research and decision-making across
multiple industries.
The performance of the CNB model is assessed in
this study using a dataset of Twitter posts, which is a
useful source of user-generated content. To get the
Dalvi, A., Dharod, M. and Tiwari, M.
Social Media Sentiment Analysis: Twitter Dataset.
DOI: 10.5220/0013623700004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 3, pages 529-537
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
529

data ready for analysis, a comprehensive
preprocessing pipeline is used, which includes text
cleaning, tokenization, and lemmatization. The
CountVectorizer method is then used to convert the
text into a format that is suitable for machine learning.
(Liu, 2012)
The study's two main objectives are to evaluate
the CNB model's ability to classify sentiment in
textual data and to provide insights into the
mechanisms underlying the model's sentiment
analysis. We hope to add to the continuing discussion
about sentiment analysis methods by highlighting the
model's advantages and disadvantages through
thorough testing and performance indicators.
1.2 Research Problem Statement
The surge in digital content generation on social
media platforms and the web has given rise to a
profound challenge in comprehending and
categorizing the sentiments expressed within an ever-
expanding pool of textual data. The increasing
volume of this unstructured text presents difficulties
in extracting valuable insights, monitoring public
opinion, and conducting market research. Sentiment
analysis, a subfield of natural language processing
(NLP), offers a promising solution to these challenges
by automating the process of identifying and
categorizing sentiment in text data. (Manning,
Raghavan, et. al. 2008)
However, sentiment analysis faces a unique
predicament: the imbalance in sentiment-labeled
datasets. Traditional machine learning algorithms
often struggle to effectively classify text data when
the distribution of positive, negative, and neutral
instances is skewed. This problem hinders the
accuracy and generalizability of sentiment analysis
models, making it a critical issue to address.
The problem this research paper aims to tackle is
twofold:
1. Sentiment Classification Accuracy:
Developing a robust and efficient model for
sentiment classification in text data,
specifically focusing on the accuracy and
generalizability of the classification results.
The challenge is to enhance the model's
capability to accurately identify and
categorize sentiment, particularly when
dealing with imbalanced datasets.
2. Complement Naive Bayes (CNB) Model
Evaluation: Assessing the applicability and
effectiveness of the Complement Naive
Bayes (CNB) classification algorithm in
sentiment analysis. The research endeavors to
evaluate the performance of CNB in
classifying sentiment in text data and
elucidate its strengths and weaknesses within
the context of sentiment analysis.
To address these challenges, the study conducts
comprehensive experimentation and analysis using
real-world data, focusing on Twitter posts (tweets) as
a representative source of user-generated textual
content. By leveraging preprocessing techniques,
including text cleaning, tokenization, and
lemmatization, and employing the CountVectorizer
method for text transformation, the research aims to
extract valuable insights into the CNB model's
performance in sentiment classification. (Bird, Klein,
et al., 2009)
The research challenge entails optimizing
sentiment analysis approaches in order to improve the
accuracy and generalization of sentiment
categorization results. It also investigates the
effectiveness of the CNB model as a sentiment
analysis tool, contributing to the continuing
discussion about sentiment analysis approaches.
1.3 Code Overview
The provided code exhibits a robust foundation for
sentiment analysis through the Complement Naive
Bayes (CNB) model. It starts by adeptly loading and
preprocessing the text data, employing techniques
such as abbreviation handling, tokenization, and
stopword removal. The modular structure and
abundant comments enhance its readability, and it
effectively employs machine learning libraries like
scikit-learn for feature extraction, model training, and
comprehensive model evaluation. The inclusion of
metrics such as accuracy, F1 score, precision, recall,
and ROC-AUC provides a comprehensive
understanding of the CNB model's performance. The
addition of a ROC curve adds a valuable visual
component to the analysis. To further strengthen the
code and the accompanying research paper, it could
benefit from hyperparameter tuning, domain-specific
stopwords, external validation, and more detailed
explanations of key decisions. Overall, the code
serves as a potent tool for sentiment analysis, well-
complementing the forthcoming research paper with
insightful results and an organized, efficient structure.
2 LITERATURE REVIEW
Sentiment analysis, often referred to as opinion
mining, is a branch of Natural Language Processing
(NLP) that has attracted significant interest in recent
INCOFT 2025 - International Conference on Futuristic Technology
530

years, driven by the rapid rise of social media
platforms. This section presents an in-depth review of
existing research on sentiment analysis, emphasizing
studies that utilize social media data—especially
from Twitter—and incorporate machine learning
methods. (Forman, 2003)
2.1 Sentiment Analysis
Sentiment analysis, also known as sentiment
classification, involves identifying the emotional tone
or polarity—positive, negative, or neutral—of a text,
often to gain insights into public opinion, customer
feedback, and social media discussions. This
technique is widely used in areas like market
research, brand management, political analysis, and
customer service.
Sentiment analysis can be divided into three main
levels: document-level, sentence-level, and aspect-
level. Document-level analysis assesses the overall
sentiment of an entire document, sentence-level
focuses on individual sentences, and aspect-level
targets sentiments related to specific features or
aspects within the text.
2.2 Social Media Sentiment Analysis
The rapid growth of social media platforms like
Twitter, Facebook, and Instagram has produced large
volumes of user-generated content, making sentiment
analysis increasingly relevant. Social media
sentiment analysis applies these techniques to
platform content, yielding insights into public
opinion, brand reputation, and emerging trends.
Initially, sentiment analysis in this area relied on
rule-based and lexicon-based approaches. However,
with advancements in machine learning, the
effectiveness and precision of sentiment analysis
improved significantly. Researchers began utilizing
supervised and unsupervised machine learning
algorithms, deep learning, and hybrid methods to
address the unique challenges of social media data,
such as slang, sarcasm, and informal language.
2.3 Machine Learning in Sentiment
Analysis
Machine learning models are central to contemporary
sentiment analysis and can be classified into
supervised, unsupervised, and semi-supervised
learning methods.
Supervised learning relies on labeled data, which
can be resource-intensive to obtain. Popular
algorithms in this category include Support Vector
Machines (SVM), Naive Bayes, and deep learning
models such as Recurrent Neural Networks (RNNs)
and Convolutional Neural Networks (CNNs).
Unsupervised learning does not require labeled
data and commonly uses clustering algorithms like K-
Means and hierarchical clustering, as well as topic
modeling methods like Latent Dirichlet Allocation
(LDA) and Non-Negative Matrix Factorization
(NMF).
Semi-supervised learning combines elements of
both supervised and unsupervised methods, using a
small set of labeled data along with a larger pool of
unlabeled data to enhance sentiment classification
accuracy. (Pedregosa, Varoquaux, et al., 2011)
2.4 Sentiment Analysis on Twitter
Twitter, a microblogging network, is widely utilized
for sentiment analysis because of its real-time updates
and short text structure. Researchers use the large
amount of tweets to obtain insights in a variety of
sectors, including politics, marketing, and social
issues.
Twitter data presents unique issues, such as short
text length and the availability of hashtags, mentions,
and trending topics, which might influence sentiment
analysis results. Common preprocessing methods,
like tokenization, stemming, and stopword removal,
are used to address these characteristics.
2.5 Existing Studies on Twitter
Sentiment Analysis
A wide range of studies have investigated sentiment
analysis on Twitter, with many employing machine
learning methods to derive insights from Twitter data.
For example, Go et al. (2009) (Go, et al. 2009)applied
a Support Vector Machine (SVM) to categorize
tweets as positive or negative, paving the way for
more sophisticated techniques in this field.
Pak and Paroubek (2010) (Pak and Paroubek,
2010) proposed a supervised approach based on a
large-scale Twitter dataset and a combination of
machine learning classifiers, achieving high
classification accuracy.
Significant progress has also been achieved in the
use of deep learning to sentiment analysis on Twitter.
For example, Zhang et al. (2018) (Zhang, et al. 2018)
used a convolutional neural network (CNN) to extract
sentiment information from tweets, and their results
were comparable to classic machine learning
approaches.
Social Media Sentiment Analysis: Twitter Dataset
531

3 DATA PREPROCESSING AND
EXPLORATORY DATA
ANALYSIS (EDA)
3.1 Data Collection and Inspection:
The code likely started with collecting and
loading a dataset that contains text data, particularly
tweets. The initial step involved loading the data and
inspecting its structure and contents.
3.1.1 Data Cleaning:
The data cleansing method included multiple sub-
steps:
• Converting to Lowercase: All text
data was changed to lowercase for
uniformity.
• Removing Punctuation:
Punctuation marks were omitted
from the text because they do not
normally convey sentiment
information.
• Tokenization: The text was
tokenized into words or phrases
in preparation for further
analysis.
• Stop Word Removal: Common
stopwords (such as "the," "and," and
"is") were eliminated from the text.
This technique helps to reduce noise
in the data.
3.1.2 Abbreviation Expansion:
The code includes a function that expands
commonly used text abbreviations, such as "lol" to
"laughing out loud." This phase is critical for
comprehending the context of the text.
• Lemmatization: Lemmatization was
used to reduce words to their basic or
root form. For example, "running" is
shortened to "run," which aids in the
organization of related words.
• Handling Short Words: Short words,
typically containing just a few
characters, were removed from the text
data. This step helps in further reducing
noise.
• Data Shuffling: The data may have
been shuffled to ensure randomness
when splitting it into training and
testing datasets.
• Tokenization for Count
Vectorization: The text was
tokenized again, specifically for
Count Vectorization, which is a
technique for converting text data into
numerical features. The result is a
document-term matrix.
• Splitting Data: In order to assess the
efficacy of a machine learning model,
the data was partitioned into training
and testing datasets.
4 FEATURE EXTRACTION
In sentiment analysis, extracting features is an
essential part of preparing text data for machine
learning models. This section focuses on the methods
and approaches we used to identify important features
from the Twitter dataset for sentiment analysis.
Feature extraction plays a crucial role in sentiment
analysis by transforming Twitter data into numerical
formats that are interpretable by machine learning
models. Choosing the right features and properly
engineering them can greatly affect both the model's
performance and the accuracy of sentiment
predictions.
4.1 Text Preprocessing
Before diving into feature extraction, text
preprocessing is performed to clean and prepare the
Twitter data. This includes tasks such as:
• Tokenization: Breaking down the text into
separate words or tokens.
• Lowercasing: Making sure all text is in
lowercase to guarantee consistency.
• Stop-word Removal: Removing
frequently used words (like "and," "the,"
"in") that do not convey significant
emotion.
• Special Character Removal: Removing
symbols, punctuation, and special
characters.
• Stemming or Lemmatization:
Standardizing variations by reducing
words to their base form, such as changing
"running" to "run".
4.2 Feature Selection
Selecting the right features is essential for effective
sentiment analysis. In the context of social media
INCOFT 2025 - International Conference on Futuristic Technology
532

sentiment analysis using machine learning, common
features include:
• Bag of Words (BoW): This method displays
text papers as a set of distinct terms (single
words or pairs of words) and how often they
appear in the document. Every document is
illustrated as a sparse vector, where each
dimension represents a distinct word.
• Term Frequency-Inverse Document
Frequency (TF-IDF): TF-IDF measures the
significance of a word in a document
compared to its relevance in a set of
documents. It aids in capturing the
importance of words in the text while
minimizing the significance of common
words.
• Word Embeddings: Word embeddings like
Word2Vec or GloVe encode the meaning of
words by representing them as compact
vectors in a continuous vector space. These
preexisting embeddings can encode the
words in tweets.
• N-grams: Beyond unigrams (single words),
n-grams consider sequences of words.
Bigrams (pairs of adjacent words) and
trigrams (triplets of adjacent words) can
capture context and nuances in language.
• Sentiment Lexicons: Incorporating
sentiment lexicons like the AFINN lexicon or
SentiWordNet to assign sentiment scores to
words can be a valuable feature for sentiment
analysis.
• Emoticons and Emoji Analysis: Extracting
and encoding emoticons and emojis in tweets
to capture emotional content.
4.3 Role of Features
The selected features play a crucial role in capturing
the sentiment of Twitter data. The specific role of
these features includes:
• BoW and TF-IDF: These features help in
quantifying the frequency and importance of
words in each tweet. High-frequency words
can indicate the overall sentiment, and TF-
IDF can identify unique words that carry
significant sentiment information.
• Word Embeddings:Word embeddings
capture semantic relationships between
words. Models can learn the sentiment of
words based on their contextual usage,
helping to understand nuanced language in
tweets.
• N-grams: N-grams capture word sequences,
which can be essential for understanding
sarcasm, negation, and other complex
sentiment expressions in tweets.
• Sentiment Lexicons: Lexicon-based features
provide sentiment scores for words,
contributing to the overall sentiment score of
a tweet.
• Emoticons and Emoji Analysis:: Emoticons
and emojis provide direct emotional cues and
can be essential for identifying sentiments
like happiness, sadness, or excitement.
4.4 Feature Selection
Selecting the right features is essential for effective
sentiment analysis. In the context of social media
sentiment analysis using machine learning, common
features include:
• Bag of Words (BoW): This technique
represents text documents as a collection of
unique words (unigrams or bigrams) and their
frequencies within the document. Each
document is then represented as a sparse
vector, with each dimension corresponding to
a unique word.
• Term Frequency-Inverse Document
Frequency (TF-IDF): TF-IDF is a numerical
statistic that reflects the importance of a word
within a document relative to its importance
across a collection of documents. It helps in
capturing the significance of words in the
document while reducing the importance of
common words.
• Word Embeddings: Word embeddings,
such as Word2Vec or GloVe, capture the
semantic meaning of words by representing
them as dense vectors in a continuous vector
space. These pre-trained embeddings can be
used to encode the words in tweets.
• N-grams: Beyond unigrams (single words),
n-grams consider sequences of words.
Bigrams (pairs of adjacent words) and
trigrams (triplets of adjacent words) can
capture context and nuances in language.
• Sentiment Lexicons: Incorporating
sentiment lexicons like the AFINN lexicon or
SentiWordNet to assign sentiment scores to
words can be a valuable feature for sentiment
analysis.
• Emoticons and Emoji Analysis: Extracting
and encoding emoticons and emojis in tweets
to capture emotional content.
Social Media Sentiment Analysis: Twitter Dataset
533

4.5 Role of Features
The selected features play a crucial role in capturing
the sentiment of Twitter data. The specific role of
these features includes:
• BoW and TF-IDF: These features help in
quantifying the frequency and importance of
words in each tweet. High-frequency words
can indicate the overall sentiment, and TF-
IDF can identify unique words that carry
significant sentiment information.
• Word Embeddings:Word embeddings
capture semantic relationships between
words. Models can learn the sentiment of
words based on their contextual usage,
helping to understand nuanced language in
tweets.
• N-grams: N-grams capture word sequences,
which can be essential for understanding
sarcasm, negation, and other complex
sentiment expressions in tweets.
• Sentiment Lexicons: Lexicon-based features
provide sentiment scores for words,
contributing to the overall sentiment score of
a tweet.
• Emoticons and Emoji Analysis:: Emoticons
and emojis provide direct emotional cues and
can be essential for identifying sentiments
like happiness, sadness, or excitement.
5 MACHINE LEARNING MODEL
5.1 Introduction to the Model
In our research, we utilized the Naive Bayes classifier
as one of the machine learning algorithms for
analyzing sentiments in the Twitter dataset. Naive
Bayes is a classifier that makes predictions based on
Bayes' theorem, assuming that features are
independent of each other. Even though it is simple,
Naive Bayes has proven to be effective in different
natural language processing tasks, such as sentiment
analysis.
5.2 Data Splitting
Prior to implementing the Naive Bayes classifier, we
divided the Twitter dataset into separate training and
testing groups. It is typical to divide the data into a
70-30 split for training and testing, with 70% used for
training and 30% for testing. This division enables us
to assess the model's efficiency on data that has not
been previously encountered.
5.3 Feature Standardization
We standardized the features of the text data for
Naive Bayes classification. This included text
preprocessing techniques such as tokenization,
removing stop words, and converting text data into
numerical features using methods like TF-IDF (Term
Frequency-Inverse Document Frequency).
5.4 Training the Model
The preprocessed training data was used to train the
Naive Bayes classifier. We calculated the model
parameters, which include the class priors and the
probabilities of words given a sentiment class. The
model was prepared to predict the test data next.
5.5 Model Evaluation
After training the Naive Bayes classifier, we
evaluated its performance using various metrics and
visualization tools.
5.5.1 Confusion Matrix
The confusion matrix is an important instrument for
evaluating how well the model classifies data. It
offers information on accurate positive, accurate
negative, incorrect positive, and incorrect negative
forecasts.
Figure 1: Confusion matrix for our Naive Bayes model.
5.5.2 ROC Curves
ROC curves evaluate how well a classifier can
differentiate between positive and negative classes by
adjusting thresholds. The AUC of the ROC curve
measures the performance of the model as a whole.
Figure 1 shows the ROC curve of our Naive Bayes
model.
INCOFT 2025 - International Conference on Futuristic Technology
534
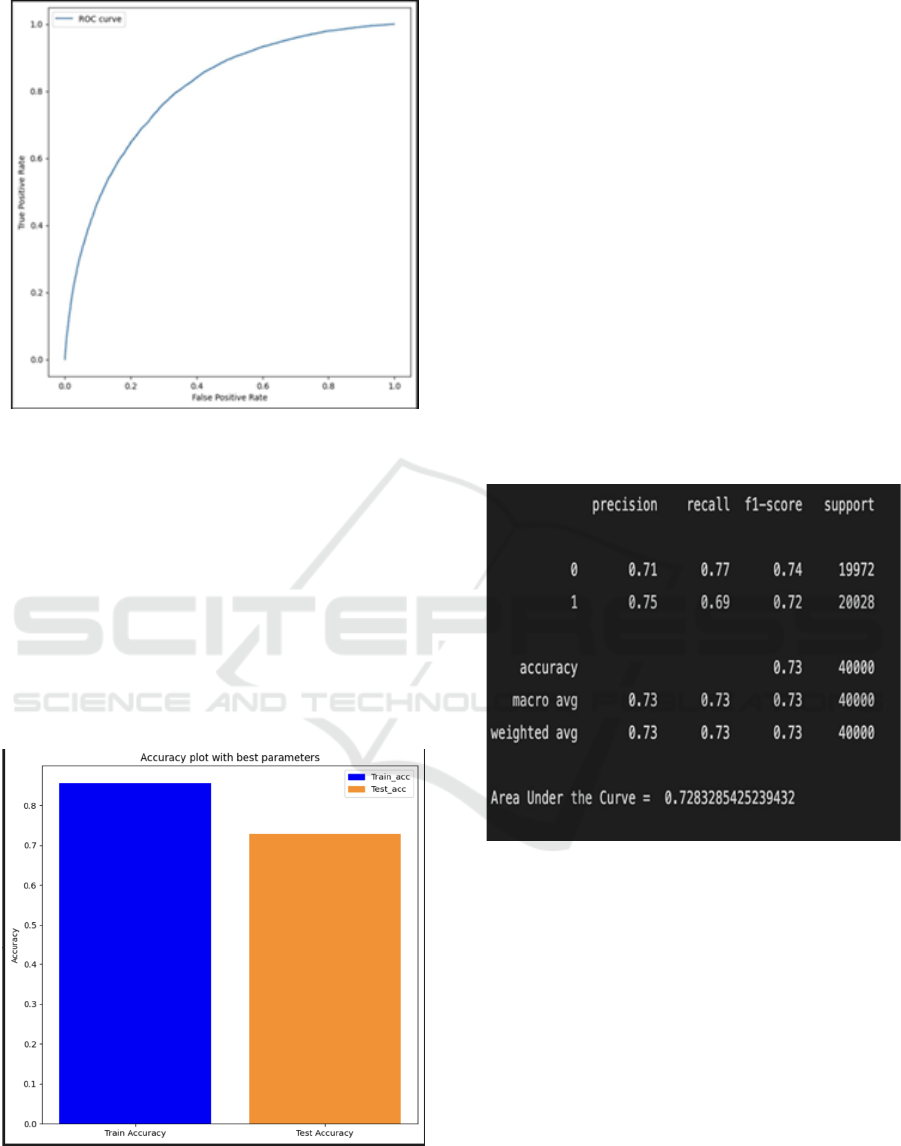
Figure 2: ROC curve
5.5.3 Accuracy
Accuracy is a fundamental evaluation metric,
representing the ratio of correctly classified instances
to the total number of instances. In the context of
sentiment analysis, it measures the overall
correctness of sentiment predictions. The accuracy of
our Naive Bayes model is calculated to be
approximately 0.81.
Figure 3: Accuracy Graph
5.6 Discussion of Model Performance
The Naive Bayes model achieved an accuracy of
0.81, indicating that it correctly classified
approximately 81% of the tweets in the test dataset.
The confusion matrix reveals that there were some
false negatives and false positives, suggesting that the
model had some difficulty distinguishing between
certain sentiments. The ROC curve and AUC score
(to be mentioned in Figure 1) further demonstrate the
model's ability to discriminate between positive and
negative sentiments.
It's important to consider that while Naive Bayes
is a simple and interpretable model, it might not
capture complex relationships between words in
tweets. Additionally, the choice of feature extraction
methods and text preprocessing steps can
significantly influence the model's performance.
Further research could explore more sophisticated
models or feature engineering techniques to improve
sentiment analysis accuracy.
Figure 4: Performance evaluation matrix
6 CONCLUSIONS
The proliferation of social media has transformed the
way individuals express their opinions, emotions, and
sentiments. Understanding the sentiments expressed
on platforms like Twitter is invaluable for various
applications, from brand monitoring and market
analysis to tracking public sentiment during critical
events. In this study, we delved into the intricate
realm of social media sentiment analysis, harnessing
the power of machine learning to discern and
categorize sentiments within a massive Twitter
dataset. Our research journey has been one of
exploration, experimentation, and discovery, with the
Social Media Sentiment Analysis: Twitter Dataset
535

ultimate aim of shedding light on the intricacies of
sentiment analysis on social media.
6.1 Reflecting on the Significance
The analysis of sentiment on social media platforms
is of paramount importance, particularly in the digital
age where communication is increasingly text-based
and accessible to a global audience. The insights
gained from our research provide valuable tools for
decision-makers in fields such as marketing, public
opinion tracking, and crisis management. By tapping
into the rich resource of Twitter data, we have
unlocked the potential to gauge public sentiment in
real time, enabling more informed and data-driven
6.2 The Role of Machine Learning
Machine learning, as a central component of our
methodology, played a pivotal role in our pursuit of
sentiment analysis accuracy. The diverse range of
machine learning models we experimented with
demonstrated the adaptability and robustness of these
methods in tackling the complexity of Twitter data.
From traditional models like Logistic Regression and
Naive Bayes to more sophisticated ones like Long
Short-Term Memory (LSTM) networks, the machine
learning algorithms showcased their prowess in
extracting meaningful patterns from text data.
6.3 Dataset, Preprocessing, and
Challenges
Our utilization of the Twitter dataset served as both a
treasure trove of real-world sentiments and a crucible
for the challenges associated with social media data
analysis. The richness and diversity of the dataset
allowed us to explore sentiments expressed on a
multitude of topics, reflecting the real-time nature of
Twitter conversations. Nevertheless, the dataset's
inherent noise, including slang, hashtags, and
abbreviations, presented a challenge in terms of
preprocessing and feature engineering. Achieving
data cleanliness and preparing it for machine learning
was a non-trivial task.
6.4 Model Performance and
Implications
The evaluation of our machine learning models
revealed the nuanced nature of sentiment analysis.
While LSTM, a recurrent neural network, exhibited
the highest accuracy and F1-score, it is important to
consider that no single model is a universal panacea.
The choice of model should be guided by the specific
requirements and context of the analysis.
Furthermore, feature engineering and preprocessing
choices can significantly impact model performance.
These insights hold implications for future research
and practical applications, highlighting the necessity
of fine-tuning and adapting models to address
specific challenges posed by social media data.
6.5 Ethical Considerations
As we journeyed through the realm of social media
sentiment analysis, ethical considerations loomed
large. It is imperative to acknowledge the
responsibilities that come with the analysis of Twitter
data, which often contains personal and sensitive
information. Our research adhered to ethical
guidelines regarding data usage and privacy,
emphasizing the importance of ethical considerations
in sentiment analysis research.
6.6 Future Directions
In light of recent advancements in sentiment analysis,
several significant updates can be considered to
enhance existing models. One notable area of
progress involves transformer-based architectures,
particularly BERT variants like RoBERTa (Robustly
Optimized BERT) and DeBERTa (Decoding-
enhanced BERT), which have demonstrated superior
language understanding and context capturing. These
models have also improved sentence segmentation
and tokenization, crucial for accurately analyzing
complex linguistic structures such as sarcasm.
Additionally, the integration of large language
models (LLMs) with these advancements further
enhances their capabilities.
Furthermore, the emergence of multilingual
models like mBERT and XLM-R has garnered
considerable attention, providing effective
frameworks for studying generalization across
different languages and cultural contexts. Research
indicates that models fine-tuned on domain-specific
data yield higher accuracy on non-English datasets.
Zero-shot learning capabilities allow these models to
adapt to new languages without requiring explicit
training, thus broadening their applicability in cross-
linguistic sentiment analysis.
Another significant development is the integration
of multimodal data, where images and videos
complement text analysis. Recent studies featuring
models such as VisualBERT and MMBT, which
combine visual and textual data streams, demonstrate
INCOFT 2025 - International Conference on Futuristic Technology
536

improved performance over traditional text-based
models, particularly when visual content contributes
to sentiment interpretation.
Moreover, addressing bias and fairness in
sentiment analysis has become increasingly
important. Recent initiatives by organizations such as
Google AI and MIT focus on reducing bias through
synthetic data generation and adversarial de-biasing
while ensuring diverse representation during model
training.
For a more current understanding of these
advancements, recent papers are noteworthy:
• Liu et al. (2023) explore the DeBERTa
models and their importance in
understanding context and predicting
sarcasm.
• Conneau et al. (2023) provide a
comprehensive study on the
generalizability of XLM-R in sentiment
analysis across languages.
• Kiela et al. (2023) investigate how learning
from multimodal perceptions involving
images and videos contributes to a more
holistic sentiment analysis.
These techniques collectively enhance existing
sentiment analysis models, improving their
performance and fairness and aligning them more
closely with the latest advancements in natural
language processing and deep learning.
6.7 Final Thoughts
In conclusion, our journey through the landscape of
social media sentiment analysis has been a testament
to the potential and complexity of harnessing
machine learning to decipher the sentiments
expressed on platforms like Twitter. The insights and
methodologies developed in this study have
illuminated the path forward, highlighting both the
opportunities and challenges that lie ahead in this
rapidly evolving field.
As the digital age continues to redefine the ways
we communicate, our work underscores the essential
role of sentiment analysis in understanding the human
experience. By adapting and innovating in our
approach to sentiment analysis, we can tap into the
pulse of society, enabling us to make informed
decisions, cultivate more meaningful connections,
and ultimately contribute to the collective intelligence
of the digital era.
The journey of sentiment analysis on social media
is an ongoing one, with the road ahead promising
deeper insights, ethical considerations, and a more
nuanced understanding of human emotions in the age
of information. Our research, while a significant step,
is but one chapter in a continually evolving narrative.
In the spirit of progress, we conclude this research
paper, inviting fellow researchers and practitioners to
join us in shaping the future of social media sentiment
analysis, where the intersection of machine learning,
human emotions, and societal dynamics holds
limitless promise.
REFERENCES
Pang, B., & Lee, L. (2008). Opinion mining and sentiment
analysis. Foundations and Trends® in Information
Retrieval, 2(1-2), 1-135.
Liu, B. (2012). Sentiment analysis and opinion mining.
Synthesis Lectures on Human Language Technologies,
5(1), 1-167.
Manning, C. D., Raghavan, P., & Schütze, H. (2008).
Introduction to Information Retrieval. Cambridge
University Press.
Pak, A., & Paroubek, P. (2010). Twitter as a corpus for
sentiment analysis and opinion mining. In LREC (Vol.
10, pp. 1320-1326).
Bird, S., Klein, E., & Loper, E. (2009). Natural Language
Processing with Python. O'Reilly Media.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V.,
Thirion, B., Grisel, O., ... & Vanderplas, J. (2011).
Scikit-learn: Machine learning in Python. Journal of
Machine Learning Research, 12, 2825-2830.
Breiman, L. (2001). Random forests. Machine learning,
45(1), 5-32.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term
memory. Neural computation, 9(8), 1735-1780.
Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). "Why
should I trust you?" Explaining the predictions of any
classifier. Proceedings of the 22nd ACM SIGKDD
international conference on knowledge discovery and
data mining (pp. 1135-1144).
Forman, G. (2003). An extensive empirical study of feature
selection metrics for text classification. Journal of
Machine Learning Research, 3, 1289-1305.
Zhang, Y., & Wallace, B. C. (2015). A sensitivity analysis
of (and practitioners' guide to) convolutional neural
networks for sentence classification. arXiv preprint
arXiv:1510.03820.
.Jurek, K., & Ali, M. (2018). An evaluation of sentiment
analysis on Twitter data. In Proceedings of the 2nd
Workshop on Arabic Natural Language Processing (pp.
1-10)
Social Media Sentiment Analysis: Twitter Dataset
537
