
Detection of Historical Building Crack Using CDNet Model
Priya Mittal
1
, Bhisham Sharma
2
, Komuravelly Sudheer Kumar
3
and Haeedir Mohameed
4,5
1
Chitkara University Institute of Engineering and Technology, Rajpura, Punjab, India
2
Centre for Research Impact and Outcome, Chitkara University Institute of Engineering and Technology, Rajpura, Punjab,
India
3
School of Computer Science and Artificial Intelligence, SR University, Warangal, Telangana, India
4
Department of Computer Techniques Engineering, College of Technical Engineering, The Islamic University, Najaf, Iraq
5
Department of Computer Techniques Engineering, College of Technical Engineering, The Islamic University of Al
Diwaniyah, Al Diwaniyah, Iraq
Keywords: Cracks, Building Crack, Deep Learning, CDNet, Detection SDG.
Abstract: It is crucial to address the cracks in ancient monuments to preserve and safeguard them in alignment with the
sustainable development goals (SDG). Thus, a new deep learning-based innovative CNN model, CDNet, is
proposed for crack detection, which overcomes the challenges of manual detection. Our model was trained
and evaluated using the Historical Crack Dataset. It achieved outstanding results, with 99% accuracy, 98.99%
precision, and 99.01% recall. These results beat the performance of both the VGG16 and ResNet-50 models.
The CDNet model can be subsequently deployed to the cloud for real-time applications.
1 INTRODUCTION
The protection and preservation of the cultural
heritage of ancient monuments is one of the issues
that must be addressed by the upcoming generations.
Cracks that result in the loss of historical heritage and
grandeur and the risk to the lives of living beings are
a consequence of the numerous threats that these
ancient structures face from environmental changes
and human practices. Cracks are significant defects in
building infrastructure that can have a significant
economic impact and pose a safety risk if left
unattended. Consequently, it is essential to evaluate
the crack's profundity to ascertain the most suitable
restoration method and forestall significant damage
(Laxman, Tabassum, et al. , 2023). Crack detection
has been conducted manually in the past, a process
that is labor-intensive, time-consuming, and less
precise (Xu, Tang, et al. , 2023).
Due to these constraints, there is a need for the
development of more effective and precise techniques
to identify and evaluate cracks in building structures.
In past years, there has been substantial growth in
the utilization of deep learning methods for the
identification of cracks in civil structures, including
buildings, bridges, dams, and roads. These
advancements have prompted the development of a
novel deep-learning model that can be used to detect
cracks or potential damage to buildings. This model
is capable of analyzing images of structures,
identifying existing cracks, and predicting potential
future damage.
We introduce a novel model, CDNet, that is
specifically designed for the verification of cracks in
building structures. The CDNet model extracts spatial
features from a dataset that comprises images of
cracks in buildings. 80% of the dataset is utilized to
train the model, while the rest 20% is reserved for
evaluating its performance. The F1 score, precision,
accuracy, and recall of the model are assessed while
testing it on unseen data.
In this paper, the working of the CDNet model is
discussed. In Section II, various works done by
researchers are examined. Further, the proposed
model CDNet is discussed in section III. The
subsequent section IV of the paper focuses on the
results of the method's implementation. Finally, the
paper concluded with a summary, which was
followed by references to the numerous works.
2 RELATED WORK
In this part, a detailed review is presented of the crack
detection methods. Tran et al. (Tran, Nguyen, et al. ,
2023) created a deep-learning model called U-Net to
438
Mittal, P., Sharma, B., Kumar, K. S. and Mohameed, H.
Detection of Historical Building Crack Using CDNet Model.
DOI: 10.5220/0013621200004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 3, pages 438-443
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
detect cracks on the bridge deck. The model
demonstrates exceptional performance, with an
accuracy rate of 92.38 percent. Popli et al. (Popli,
Kansal, et al. , 2023) Suggested the use of a robotic
model called Xception to detect cracks in roads. The
newly proposed model achieves an accuracy of 90%.
Tabernik et al. (Tabernik, Šuc, et al. , 2023)
proposed a novel paradigm, SegDecNet++, to
streamline quality control during building and
maintenance processes. The proposed model obtained
a dice score of 81%. Pham et al. (Pham, Ha, et al. ,
2023) concluded the research using Ostu Method to
detect ground cracks along with their length and
width and the accuracy recorded was 86.7% to 99.9%.
Yadav et al. (Yadav, Sharma, et al. , 2024) suggested
a new Convolutional Neural Network based model,
HCTNet to identify cracks in roads ensuring
sustainable road safety. The model achieved the F1
score of 97.20%.
Sun et al. (Sun, Yang, et al. , 2021) suggested
conducting research utilizing the DeepLabV3+ model
to accurately identify cracks and bugholes on the
surface of the concrete. The model attained an
impressive outcome, with a mean average precision
of 95.58%.
Lin et al. (Lin, Li, et al. , 2023) suggested a model,
DeepCrackAt based on the encoder-decoder network
for crack segmentation and recorded an accuracy of
97.41%. Karimi et al. (Karimi, Mishra, et al. , 2024)
proposed the implementation of a YOLO (You Only
Look Only) deep learning model to diagnose damage
in tiles. The CDNet model attained an accuracy rate
of 72%.
Katsigiannis et al. (Katsigiannis, Seyedzadeh, et
al. , 2023) suggested a deep learning-based model,
MobileNetV2 to diagnose the cracks in brickwork
masonry and achieved the F1 score of 100%. Yadav
et al. (Yadav, Prasad, et al. , 2024) proposed the
CCTNet to improve the precision of crack detection
in structures. The model recorded a precision of
99.33% for the proposed dataset. Tasci et al. (Tasci,
Acharya, et al. , 2023) developed a new architecture
inception and concatenation residual (InCR) to
identify damaged buildings. The model outperforms
other models by showing an accuracy of 99.82%.
Reis et al. (Reis, Turk, et al. , 2024) created a
combination model of ResNet152 +SVM to
recognize the cracks in roads after the earthquake.
The hybrid model had the highest level of success,
with accuracy values of 98.68%. Zheng et al. (Zheng,
Lei, et al. , 2020) suggested three deep learning
models out of which RFCN (Richer Fully
Convolutional Network) showed the best results for
identifying the fractures in buildings with a recorded
accuracy as 91%. Akgul et al. (Akgül, 2023)
introduced a novel fusion model called Mobile-
DenseNet for accurately recognizing cracks that
appear on the surface of the concrete. The fusion
model achieved a success percentage of 99.87%.
Roy et al. (Roy, Kukreja, et al. , 2023) developed a
hybrid model of a deep CNN to detect the intensity of
defects in painting in heritage buildings. The hybrid
model resulted in an accuracy of 84.23%. Joshi et al.
(Joshi, Singh, et al. , 2022) created a deep-learning
model to identify surface cracks or defects in various
structures. The model achieved an average precision
of 93.445% in its predictions. ABDELLAOUI et al.
(ABDELLAOUI, Errousso, et al. , 2024) concluded
the study by considering the VGG-based learning
model as the most superior for detecting cracks in the
pavement as the model records an accuracy of 86.5%.
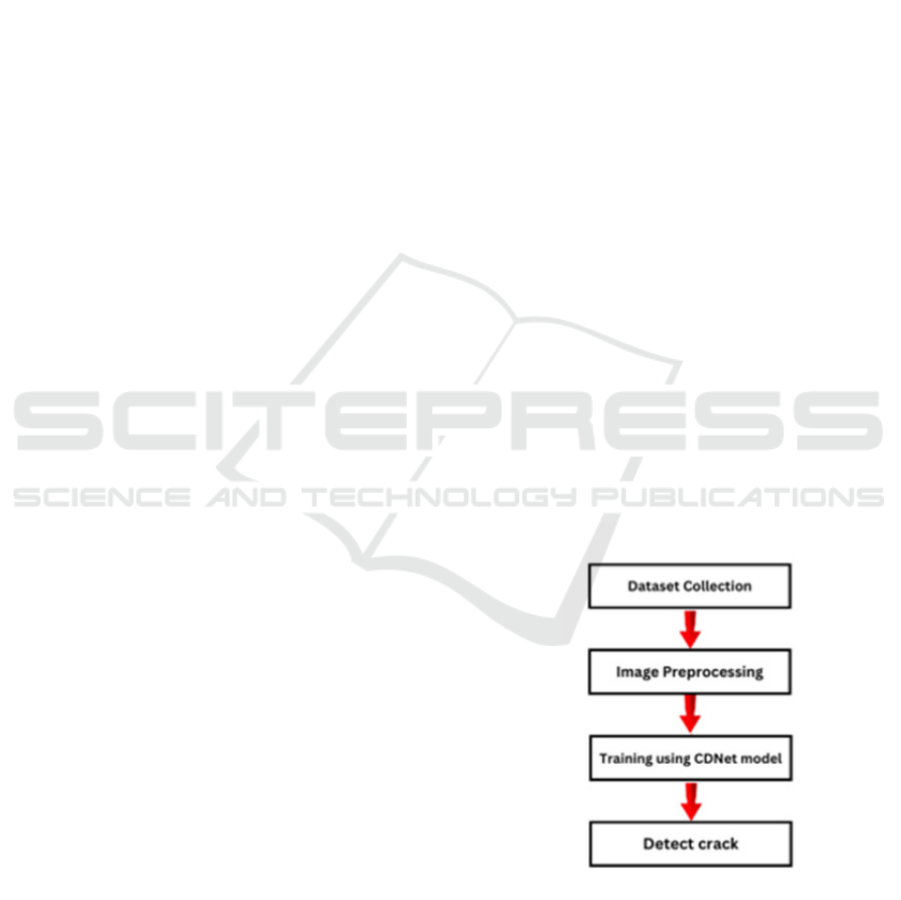
3 ARCHITECTURE OF THE
MODEL
There are several issues with the earlier models that
used deep learning methods that need to be fixed.
Based on the previously employed ResNext and
VGG16 models, a new model is built in order to
optimize the performance of the crack detecting
model through deep learning. This study developed a
CDNet (Crack Detection network) sequential model
for diagnosing building cracks. In this model, 5
convolution blocks.
The sizes of the convolutional
layers, conv1, conv2, conv3, conv4, and conv5, are
16, 32, 64, 128, and 256, respectively. The model
consists of four different stages as shown in Figure 1.
Figure 1: Stages During Crack Detection
3.1 Working of the CDNet model
A 2D convolutional layer processes an input image or
feature map by applying several filters, extracting
Detection of Historical Building Crack Using CDNet Model
439

local features that are useful for tasks including image
recognition, classification, and segmentation. The
CDNet contain 5 convolution layer. The convolution
layers have 16, 32,64,128, and 256 filter.
Furthermore, each convolution layer is followed by
ReLU activation and a maxpooling layer.
In the CDNet each filter detects specific features
such as edges, corners, or textures. Each convolution
layer is followed by ReLu activation functions and a
max-pooling layer. To decrease computational load
and the risk of overfitting, the max-pooling layer
shrinks the feature maps in spatial dimensions while
keeping the most crucial information. The network
can learn more complicated functions because of the
Relu layer's non-linearity. The Relu Layer applies the
Relu function to every input element. Equation 1 is
the mathematical formula for Relu Function.
f(x) = max(0,x) (1)
After every convolutional block, a channel
attention block (CAB) is also included as shown in
Figure 2. Structure of CDNet model to detect cracks
Channel Attention is a mechanism that allows a
neural network to dynamically focus on the most
informative channels of feature maps. It helps the
model to weigh the importance of each channel and
suppress less useful ones. It operates by first
compressing spatial dimensions into channel-wise
summaries using global pooling. These summaries
are processed via thick layers to create channel-
specific attention weights, which are then used to
scale the relevance of each channel. Channels with
higher weights are emphasized, while less relevant
ones are suppressed. This mechanism improves
feature learning and computational efficiency by
ensuring that the network focuses on the most
informative channels, leading to better model
performance.
The experimental setting of the CDNet method is
shown in Table I.
Table 1: Observations
Crack Images 3896
Batch size 8
E
p
ochs 50
Channels 5
Trainin
g
80%
Validation and Testing 20%
4 RESULTS
This section discussed the proposed model CDNet’s
dataset description and quantitative results.
4.1 Dataset
The Historical Building Crack2019 collection
comprises approximately 3886 meticulously curated
images of cracked areas of antiquated structures. The
dataset contains approximately 45 photographs of a
medieval mosque (Masjid) of Egypt. There are 758
photographs of fractured surfaces and 3,138
photographs of non-cracked surfaces in the
collection. The digital camera was used to capture the
images, which had a resolution of 5184 × 3456 pixels.
Some of the sample crack images are displayed in
Figure 3. Also, by utilizing the rotational invariance,
the size of the dataset has been expanded, and
additional data was added through the use of the
ImageGenerator method found in the Keras package.
The crack image was subjected to augmentation
techniques such as rotating clockwise, rotating
anticlockwise, horizontal flip, and vertical flip.
(a) (b)
Figure 3. Sample crack images
4.2 Experimental Setting
Before testing with the CDNet model, the photos
were scaled to 300 by 300 pixels. The model was then
trained with batch size of 8. The initial learning rate
INCOFT 2025 - International Conference on Futuristic Technology
440
was set at 0.001 to improve the performance. We let
the model train and alter its values for 50 epochs.
Parameters that are evaluated to check the
performance are F1 score, Accuracy, Recall,
Precision, and Sensitivity from the confusion matrix.
These parameters are computed by indicators like TP,
TN, FP, and FN. With these data, the necessary
metrics can be computed as follows:
𝐴𝑐𝑐𝑢𝑟𝑎𝑐𝑦 𝑇𝑁 𝑇𝑃/𝑇𝑁 𝑇𝑃 𝐹𝑁
𝐹𝑃 (2)
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑇𝑃/𝑇𝑃 𝐹𝑃 (3)
𝑅𝑒𝑐𝑎𝑙𝑙 𝑇𝑃/𝐹𝑃 𝑇𝑁 (4)
𝐹1 𝑠𝑐𝑜𝑟𝑒 2 ∗ 𝑅𝑒𝑐𝑎𝑙𝑙 ∗ 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛/
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 𝑅𝑒𝑐𝑎𝑙𝑙 (5)
Kappa is utilized to verify the performance of a
classification model, such as a CNN, by comparing
the predicted labels to the actual labels. Kappa = 1
indicates a perfect match and a negative value
indicates no match or worst agreement.
4.3 Performance evaluation on the
Building Crack dataset
The Building Crack collection consists of 758
pictures illustrating surfaces with cracks and 3138
images exhibiting surfaces without cracks. First input
image is resized to 300x300x3 pixels. After that,
images are fed to the ResNet-50, VGG16, and CDNet
models for training. We utilized batch sizes of 64 over
50 epochs for training of models. In addition, training
process was expedited by using the Adam optimizer,
with a starting learning rate of 0.001. After training,
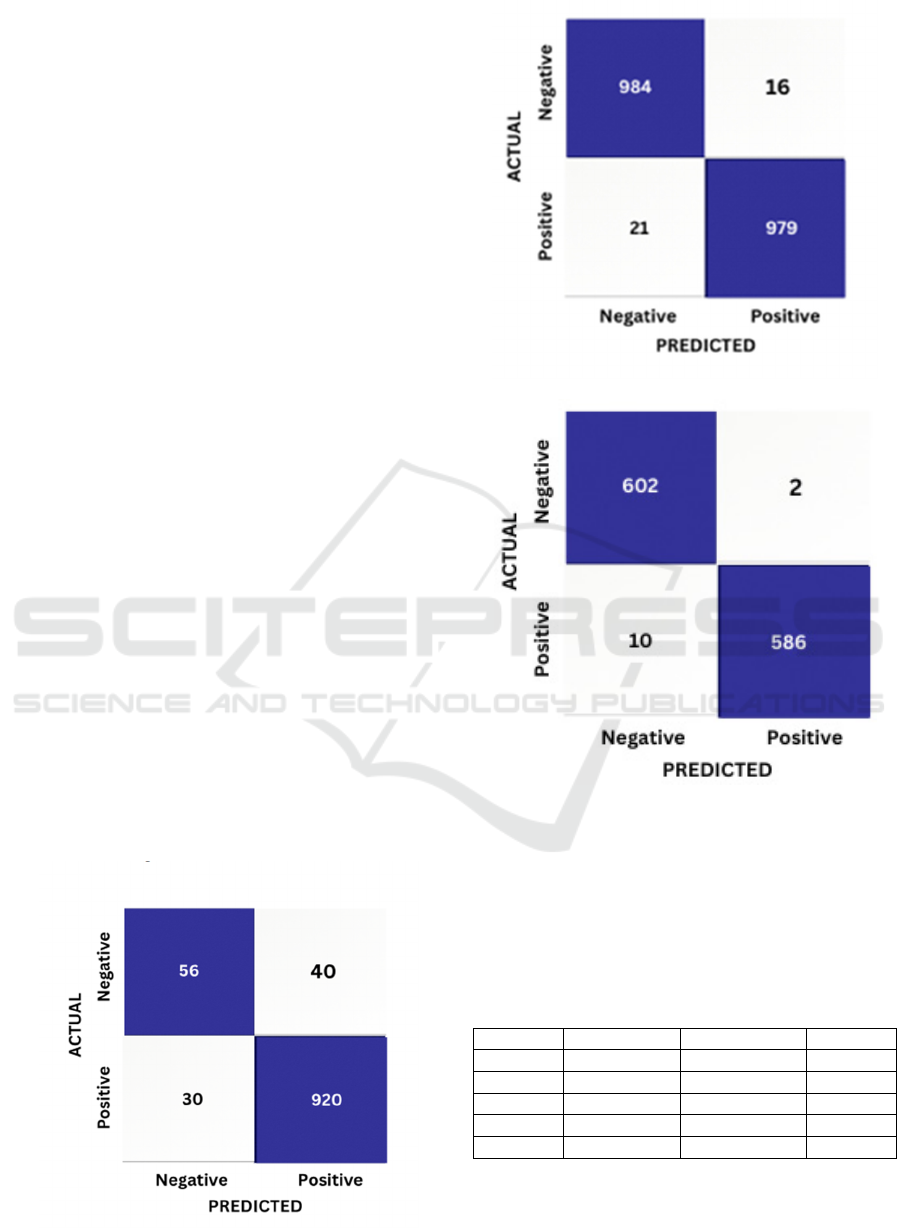
confusion matrices were created for each model and
may be seen in Figure 4.
(a)
(b)
(c)
Figure 4: Confusion matrix (a) VGG16 (b) ResNet-50 and
(c) proposed CDNet model
From the confusion matrices, Kappa, accuracy,
F1 score, recall, and precision can be calculated using
the formulas described in section B and shown in
Table 2.
Table 2: Performance metric on Building Crack dataset
VGG16 ResNet-50 CDNet
Precision 95.24% 96.15% 98.99%
F1 score 94.53% 95.70% 98.99%
Recall 93.85% 95.27% 99.01%
Accurac
y
93.52% 95.43% 99%
Kappa 0.90 0.93 0.98
Detection of Historical Building Crack Using CDNet Model
441
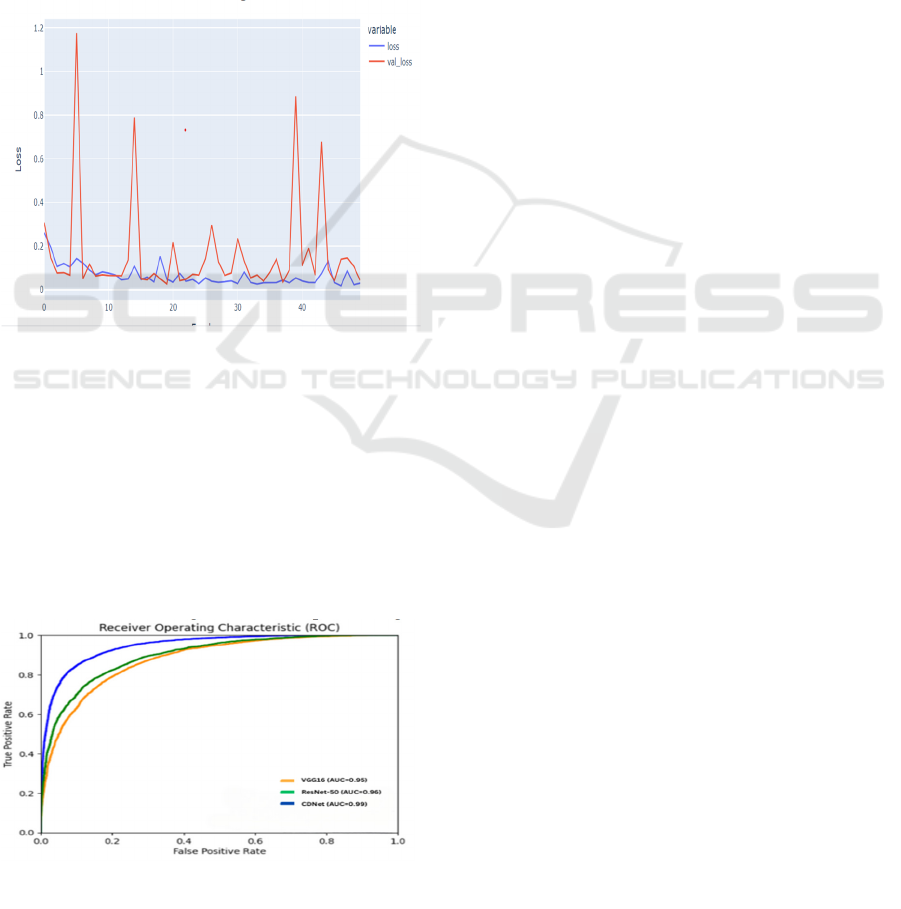
4.4 Training and Validation Loss
Valuable insights into the model's learning progress
are provided by training and validation losses. The
model is enhancing its ability to learn from the
training data is indicated by a decrease in loss over
time. Overfitting can be detected by comparing these
losses: it is characterized by a decrease in the training
loss and an increase in the validation loss, which
suggests that the model is memorizing the training
data rather than learning to generalize from it. The
training (TR) and validation (VL) contours for the
proposed technique are depicted in Figure 5, which
utilizes the Historical Building Crack2019 dataset.
Figure 5: Training and Validation Loss over time
4.5 ROC plot
One often used statistic to evaluate building crack
performance is the receiver operating characteristic
(ROC). Taking the true positive rate (TPR) on the y-
axis and the false positive rate (FPR) at the x-axis at
several threshold values generates the ROC curve.
The area under the curve (AUC) measure shows the
likelihood that a positive value selected would rank
better than a random negative instance picked. Figure
Figure 6. Roc-based comparisons of the VGG16, ResNet-
50 and CDNet model
6 shows the comparison of ResNet-50, VGG16, and
the CDNet model in which VGG16 has an AUC of
0.95, ResNet-50 has 0.96 AUC and CDNet boasts the
highest AUC of 0.99.
5 CONCLUSIONS
By leveraging deep learning techniques, the CDNet
model offers a powerful tool for the preservation and
maintenance of historical buildings. Its application
can significantly enhance our ability to identify and
repair cracks, ultimately collaborating with the
preservation of cultural heritage. The proposed
CDNet model shows an accuracy of 99% and a
precision value of 98.99% which is higher than the
previously used VGG16 and ResNet-50 models for
which accuracy of 93.52% and 95.43% were recorded
respectively. Also, the area under the curve for the
CDNet model i.e. 0.99 is greater than the VGG16 and
ResNet-50 models. Despite showing high accuracy,
the model has a high computational cost. So, the
CDNet model needs to be further modified to achieve
low computational cost. Future work will emphasized
on further modifying the model and enlarging the
dataset to include a broader range of structures and
crack types, ensuring even greater accuracy and
reliability in real-world applications.
REFERENCES
Laxman, K.C., Tabassum, N., Ai, L., Cole, C. and Ziehl, P.,
2023. Automated crack detection and crack depth
prediction for reinforced concrete structures using deep
learning. Construction and Building Materials, 370,
p.130709.
Xu, S., Tang, H., Wang, X. and Wang, D., 2023, November.
Assessment of geometric parameters of segmented
crack on concrete building facade using deep learning.
In Structures (Vol. 57, p. 105188). Elsevier.
Tran, T.S., Nguyen, S.D., Lee, H.J. and Tran, V.P., 2023.
Advanced crack detection and segmentation on bridge
decks using deep learning. Construction and Building
Materials, 400, p.132839.
Popli R, Kansal I, Verma J, Khullar V, Kumar R, Sharma
A. ROAD: Robotics-Assisted Onsite Data Collection
and Deep Learning Enabled Robotic Vision System for
Identification of Cracks on Diverse
Surfaces. Sustainability. 2023; 15(12):9314.
Tabernik, D., Šuc, M. and Skočaj, D., 2023. Automated
detection and segmentation of cracks in concrete
surfaces using joined segmentation and classification
deep neural network. Construction and Building
Materials, 408, p.133582.
INCOFT 2025 - International Conference on Futuristic Technology
442

Pham, M.V., Ha, Y.S. and Kim, Y.T., 2023. Automatic
detection and measurement of ground crack
propagation using deep learning networks and an image
processing technique. Measurement, 215, p.112832.
Yadav, D.P., Sharma, B., Chauhan, S., Amin, F. and
Abbasi, R., 2024. Enhancing Road Crack Localization
for Sustainable Road Safety Using
HCTNet. Sustainability, 16(11), p.4409.
Sun, Y., Yang, Y., Yao, G., Wei, F. and Wong, M., 2021.
Autonomous crack and bughole detection for concrete
surface image based on deep learning. IEEE access, 9,
pp.85709-85720.
Lin, Q., Li, W., Zheng, X., Fan, H. and Li, Z., 2023.
DeepCrackAT: An effective crack segmentation
framework based on learning multi-scale crack
features. Engineering Applications of Artificial
Intelligence, 126, p.106876.
Karimi, N., Mishra, M. and Lourenço, P.B., 2024. Deep
learning-based automated tile defect detection system
for Portuguese cultural heritage buildings. Journal of
Cultural Heritage, 68, pp.86-98.
Katsigiannis, S., Seyedzadeh, S., Agapiou, A. and Ramzan,
N., 2023. Deep learning for crack detection on masonry
façades using limited data and transfer
learning. Journal of Building Engineering, 76,
p.107105.
Yadav, Dhirendra Prasad, Bhisham Sharma, Shivank
Chauhan, and Imed Ben Dhaou. 2024. "Bridging
Convolutional Neural Networks and Transformers for
Efficient Crack Detection in Concrete Building
Structures" Sensors 24, no. 13: 4257.
Tasci, B., Acharya, M.R., Baygin, M., Dogan, S., Tuncer,
T. and Belhaouari, S.B., 2023. InCR: Inception and
concatenation residual block-based deep learning
network for damaged building detection using remote
sensing images. International Journal of Applied Earth
Observation and Geoinformation, 123, p.103483.
Reis, H.C., Turk, V., Karacur, S. and Kurt, A.M., 2024,
April. Integration of a CNN-based model and ensemble
learning for detecting post-earthquake road cracks with
deep features. In Structures (Vol. 62, p. 106179).
Elsevier.
Zheng, M., Lei, Z. and Zhang, K., 2020. Intelligent
detection of building cracks based on deep learning.
Image and Vision Computing, 103, p.103987.
Akgül, İ., 2023. Mobile-DenseNet: Detection of building
concrete surface cracks using a new fusion technique
based on deep learning. Heliyon, 9(10).
Roy, P.S., Kukreja, V., Jain, V. and Vats, S., Classification
of Defective Intensity Levels of Paint in Heritage
Buildings using the CNN-SVM.
Joshi, D., Singh, T.P. and Sharma, G., 2022. Automatic
surface crack detection using segmentation-based deep-
learning approach. Engineering Fracture Mechanics,
268, p.108467.
El Arbi ABDELLAOUI, A.L.A.O.U.I., Errousso, H., Filali,
Y., Chekira, C. and Agoujil, S., 2024. Harnessing Deep
Learning Techniques for Enhanced Detection and
Classification of Cracks in Pavement Imagery. Procedia
Computer Science, 236, pp.386-393.
Detection of Historical Building Crack Using CDNet Model
443
