
Design and Implementation of a Phonological Analyzer for the Irula
Language: A Computational Approach to Endangered Language
Preservation
Vaishakh S. Kamath
1
, Safa Salim
1
, Jyothi Ratnam
2
, Arun Kumar K. P
2
and G. Veena
1
1
Department of Computer Science and Applications, Amrita School of Computing, Amritapuri, India
2
Amrita-CREATE, Amrita Vishwa Vidyapeetham, Amritapuri, India
Keywords:
Phonological Analyzer, Irula Language, Low-Resource Languages, Computational Linguistics, MFCC,
Machine Learning.
Abstract:
Irula is a South Dravidian language spoken by a small tribal community in India and is critically endangered
due to a decreasing number of speakers and the assimilation of its speakers into dominant regional languages
such as Tamil and Malayalam. This research focuses on creating a phonological analyzer that utilizes Mel-
Frequency Cepstral Coefficients (MFCC) for feature extraction, aiming to tackle the computational limitations
faced by the Irula language. The study evaluates the performance of two machine learning models, Bi-LSTM
and SVM, in classifying audio data from Irula, Tamil, and Malayalam. Additionally, it explores the phonologi-
cal systems of these closely related languages, emphasizing articulatory features, variations in consonants, and
retroflex articulations. The findings indicate that the SVM model surpasses the Bi-LSTM model, achieving
a classification accuracy of 90%. This project contributes to the preservation of endangered languages and
enhances the field of low-resource language processing by creating a computational framework for analyzing
the phonological features of Irula. The results also open avenues for additional research in computational
linguistics and phonetics, particularly for languages that are underrepresented.
1 INTRODUCTION
The legacy and culture of a region is carried in its
languages which provides a sense of social identity.
However, many of the original Dravidian languages
that are native to India are in danger of becoming
extinct because of a lack of preservation and a drop
in speakers.The Irula community is an indigenous
tribal group belonging to the South Dravidian lan-
guage family, primarily residing in four southern In-
dian states: Andhra Pradesh, Karnataka, Kerala, and
Tamil Nadu. Their estimated population is around
200,000 individuals(The Criterion: An International
Journal in English, 2024). According to the 2011 cen-
sus, Irula, a South Dravidian tribal language, is an
endangered language, with 12,000 speakers in Kerala
currently (Kerala Institute for Research Training and
Development Studies of Scheduled Castes and Sched-
uled Tribes (KIRTADS), 2017). The speakers from a
small hamlet in Kerala’s Attapadi region are the sub-
ject of our attention. In the domains of computational
linguistics and natural language processing, Irula is
considered a zero-resource language. This study aims
to solve this problem by creating the first phonolog-
ical analyzer specifically designed for the Irula lan-
guage. The goal is to determine whether the provided
audio data is from the sister Dravidian languages of
Tamil, Malayalam, or Irula.
Code mixing or code-switching refers to the jux-
taposition of linguistic units from two or more lan-
guages in a single conversation or sometimes even
a single utterance. It is the transfer of linguistic el-
ements or words from one language to another or
mixed together. Native speakers, mostly tribal peo-
ple, are attempting to switch to the main-stream lan-
guages of their area, resulting in code mixing. The
main external factors causing language endangerment
among the Irula people are cultural, educational, and
economic subjugation. Internal factors, such as the
community’s rejection of its own language and the
general decline of group identity, also contribute to
this issue. The Irula tribal communities link their tra-
ditional language and culture to their precarious so-
cial and economic status. They now feel that their
languages are useless and should not be preserved. In
S. Kamath, V., Salim, S., Ratnam, J., Kumar K. P, A. and Veena, G.
Design and Implementation of a Phonological Analyzer for the Irula Language: A Computational Approach to Endangered Language Preservation.
DOI: 10.5220/0013606300004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 2, pages 871-877
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
871

their pursuit to combat discrimination, achieve finan-
cial stability, and enhance social mobility for them-
selves and their children, they have relinquished their
languages and traditions. However, they are unaware
that they risk losing their identity if they are unable
to communicate in their native tongue. In such a sit-
uation, it became crucial to preserve and strengthen
the root language, or Irula, from both a cultural and a
computational standpoint. Irula presents a significant
obstacle due to the absence of any digital corpus or
documentation. The objective of this project is to cre-
ate computational tools for Irula that will significantly
influence the field of low-resource language process-
ing and help preserve the language.
Proto-Dravidian refers to the linguistic recon-
struction of the common ancestor of the Dravidian
languages indigenous to the Indian subcontinent. This
language set has descendants in Irula, Tamil, and
Malayalam. Analyzing these three languages reveals
clear commonalities in syntax, semantics, and lexi-
con. The phonological system is where the degree of
divergence appears. These parallels and discrepancies
are examined in this study. It also emphasizes how the
phoneme inventory and sound patterns of these lan-
guages have changed over time.
Malayalam has a more significant phonetic dis-
tinction for every consonant. Irula, which is more
like Tamil, has distinct phonological characteristics,
as evidenced by the change in where some consonants
are articulated. These changes emphasize how each
language’s phonetics—particularly its fricatives and
retroflexes—make these sister languages distinct. The
aim of this study is to assess and analyze the phono-
logical distinctions that exist. Irula shares phonetic
similarities with Tamil and Malayalam, but it also has
distinctive phonetic characteristics, such as consonan-
tal shift and phoneme simplification. For instance, the
word ”singam” in Tamil means ”lion,” whereas the
word ”simham” in Malayalam indicates both phono-
logical and lexical diversity. Irula is closely con-
nected to languages like Malayalam, as seen by the
term ”shivaya,” which is pronounced similarly. This
word is pronounced ”sivaya” in Tamil, and ”chivaya,”
”shivaya,” or ”sivaya” in Irula. This research fo-
cuses on phonetic differences, as well as syntactic and
grammatical similarities.
This effort also aims to analyze the similarities
and differences between these languages. Despite
having a similar lexicon and grammatical organiza-
tion, their phonetic components differ greatly. Frica-
tives and retroflexes aid in the development of a thor-
ough phonological model that precisely differentiates
between these languages. Vowel articulation and pho-
netic markers offer a strong foundation for examining
these languages’ development. The necessity for in-
struments that can precisely record the phonetic vari-
ety among the proto-Dravidian languages and aid in
their preservation is discussed in this work.
Section II provides an overview of related re-
search in phonological analysis, emphasizing stud-
ies that focus on language preservation and linguis-
tic diversity, especially concerning low-resource lan-
guages. This section reviews prior work on acous-
tic feature extraction, phoneme segmentation, and
the creation of language models specifically designed
for endangered languages. Section III describes the
methodology of this study, including the dataset uti-
lized for phonological analysis, feature extraction
methods like MFCC, and the models used for pho-
netic comparison. Section IV presents the results
from the acoustic analysis, highlighting both the sim-
ilarities and differences in phonetic characteristics
among Malayalam, Tamil, and Irula while assessing
the effectiveness of various feature extraction tech-
niques. Section V assesses the phonological mod-
els based on their ability to identify language-specific
features, particularly regarding their role in preserv-
ing Irula. Finally, Section VI concludes with a discus-
sion on the implications of these findings for linguis-
tic research and outlines potential directions for future
work, such as incorporating machine learning tech-
niques for automatic phoneme segmentation and de-
veloping speech-to-text systems for low-resource lan-
guages.
2 RELATED WORKS
The majority of the existing computational linguis-
tics literature on voice analysis concentrates on lan-
guages with abundant resources or extensive docu-
mentation. However, research on resource-centered
and endangered languages has brought attention to the
need for computational tools designed specifically for
these languages. Speech segmentation and pronunci-
ation modeling are the subjects of two studies that are
particularly relevant to this endeavor.
The first study segmented voice samples using
a hybrid segmentation system that integrated signal
processing and machine learning methods(Prakash
et al., 2016). particularly Speech data is divided into
syllable-level segments using a hidden Markov model
(HMM), which is initialized using the global aver-
age variance. Along with examining the distribution
of acoustic qualities among the languages, the study
also examined the acoustic characteristics of sylla-
bles in six Indian languages. and determine the par-
allels and discrepancies The study’s findings demon-
INCOFT 2025 - International Conference on Futuristic Technology
872

strate how these models could enhance TTS systems
and speech technologies for low-resource and poly-
glot languages. However, the lack of variation in lan-
guage, dialect, and speakers makes research difficult.
Having trouble understanding natural or loud speech
also adds to it.
For compatibility with Indian languages, a sec-
ond study created a pronunciation model that in-
cludes spelling and pronunciation techniques trans-
ferred from UTF-8 to ISCII(Singh, 2006). The model
employs Dynamic Time Warping (DTW) for string
alignment and incorporates telemetry to gauge pho-
netic similarity. Spell checking is one of the many
applications that the model supports. Normalization
of text and identification of related terms. The re-
sults demonstrate how standardizing a phonemic or-
thographic framework for the Brahmi script has im-
proved natural language processing for Indian lan-
guages. However, issues like resource efficiency were
identified. limited pronunciation format presentation
and language generalization.
Hegarty et.al. (2019) phonetic comparison of-
fers crucial tools for comprehending the phonetic
diversity of languages. An online database and
tools for analyzing phonetic similarities and con-
trasts between languages are made available by this
project(Nallanthighal et al., 2021). It is a useful tool
in the field of comparative linguistics. Dialectics and
sociolinguistics ”Phonetics Comparison” emphasizes
the difficulty of developing phonetics resources for
those with low proficiency despite its wide breadth.
This project’s technique, which includes the capac-
ity to search, filter, and examine phonetic data, es-
tablishes a standard for recording and examining the
phonological characteristics of underrepresented lan-
guages.
Tohru et al. represent the overview of evolution
of speech recognition, speech synthesis, and machine
translation.Key approaches include a minimum mean
square error (MMSE) estimator with a Gaussian mix-
ture model (GMM) and a particle filter to reduce noise
and interference(Shimizu et al., 2008). An MDLSSS
algorithm determines the number of parameters based
on training data size using the maximum description
length criterion. Despite well-trained models, fac-
tors like speaker variability and background noise can
still cause errors, which are mitigated by applying
generalized word posterior probability (GWPP) for
post-processing. The translation process uses TATR
and EM modules, with TATR leveraging translation
examples and employing probabilities and penalties
when necessary.The XIMERA speech synthesis en-
gine, trained on large corpora from Japanese, English,
and Chinese speakers, uses an HMM-based statisti-
cal prosody model to produce natural pitch patterns
without heavy signal processing. Evaluation across
the BTEC, MAD, and FED corpora ensures the sys-
tem’s robustness in various speaking styles. Results
indicate high accuracy (82-94 percentage for Chinese)
and BLEU scores (0.55-0.74) for Chinese-Japanese
and Chinese-English translations. The paper con-
cludes that integrating these advanced techniques sig-
nificantly enhances the performance and consistency
of speech recognition, synthesis, and machine trans-
lation systems
Nallanthighal et al. investigates the connection
between speech’s respiratory effort and phoneme for-
mation. The results of the study on the respiratory pat-
terns linked to particular phonetic classes provide in-
sights into the physical components of speech produc-
tion, despite the controlled setting and small sample
size(Heggarty et al., 2019). These observations could
help with the phonological analysis of Irula by exam-
ining the differences in respiratory effort between the
language’s phonetic components. However, the ac-
curacy of lung volume changes—which is crucial for
practical applications—is limited by the absence of
calibration in respiratory data measurement.
While previous studies have examined various
methods for phonological analysis and language
preservation, there has been limited research compar-
ing machine learning models for phonetic analysis in
low-resource languages such as Irula. Furthermore,
the automation of phonological feature extraction us-
ing models like BiLSTM and SVM has not been ex-
tensively studied, particularly in the context of Indian
languages. This research seeks to fill this gap by as-
sessing BiLSTM and SVM models for phoneme seg-
mentation and comparing the acoustic properties of
Malayalam, Tamil, and Irula. The aim is to enhance
the accuracy of phonological analysis tools for endan-
gered languages and evaluate the feasibility of these
models for automating phonetic feature extraction in
less-explored languages.
3 METHODOLOGY
MFCCs are used (Han et al., 2006)(Paulraj et al.,
2009)in this study’s methodology to extract phonetic
features from audio recordings of considered lan-
guages Malayalam, Tamil and Irula.Both deep learn-
ing model and a machine learning model were im-
plemented to classify the phoneme analysis for Irula,
Malayalam, and Tamil. The procedure can be divided
into several key steps, including dataset preparation
,feature extraction, train the model, and evaluation.
Design and Implementation of a Phonological Analyzer for the Irula Language: A Computational Approach to Endangered Language
Preservation
873
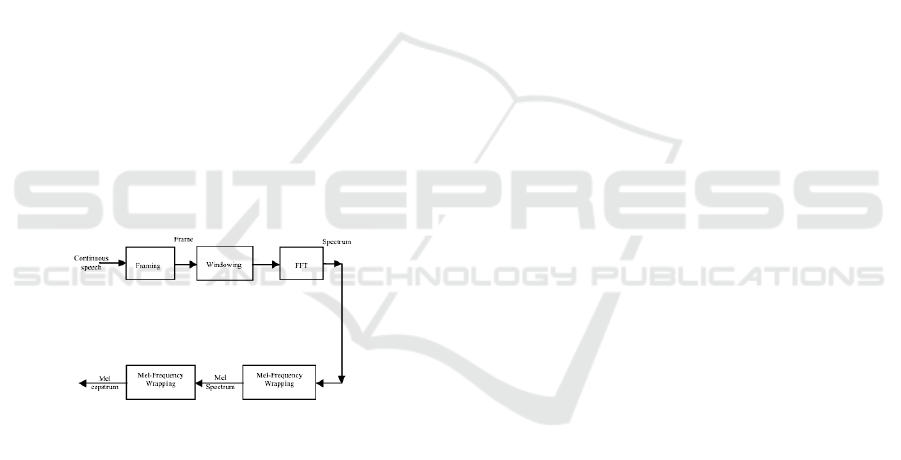
3.1 Dataset Preparation
We gathered voice samples from one male and one
female speaker of each language for our study, result-
ing in a total of six participants. For dataset devel-
opment, we collected one hundred comparable words
from Irula, Malayalam, and Tamil. These words share
similarities in phonology, morphology, and seman-
tics. The recordings are made by native speakers of
the respective languages and saved in WAV format.
3.2 Feature Extraction
The participants’ voice signals were(Paulraj et al.,
2009) captured. at a sample rate of 16 kHz. The
audio samples were processed using MFCC, a pop-
ular method for extracting phonetic characteristics in
audio sources . The audio samples were examined
using MFCC(Han et al., 2006), a commonly em-
ployed method for extracting phonetic features from
(Paulraj et al., 2009) audio sources. The primary ob-
jective of MFCC is to mimic human auditory per-
ception. For each audio file, thirteen MFCC coeffi-
cients—an established standard in speech processing
research—were extracted. Consequently, each audio
frame generated a total of thirteen MFCC features, ef-
fectively capturing essential phonetic traits.
Figure 1: An illustration of the MFCC block
The components of MFCC(Roul and Rath, 2023)
feature extraction algorithm:
3.2.1 Frameblocking
The continuous voice stream is segmented into frames
of N samples, with neighboring frames overlap-
ping by M samples (where M is less than N). The
first frame contains the original N samples. (mfc,
2023)(Paulraj et al., 2009). This pattern continues as
the second frame overlaps the first by M samples and
begins M samples after it. This process continues un-
til each spoken phrase is captured in either a single
frame or multiple frames(mfc, 2023)(Paulraj et al.,
2009) . Typically, N and M are set to 256 and 100,
respectively(mfc, 2023)(Paulraj et al., 2009) .
3.2.2 Windowing
Windowing reduces spectral distortion and signal dis-
continuities at the start and end of each frame by
smoothly tapering the signal to zero(Paulraj et al.,
2009). When N denotes the number of samples in
each frame(Paulraj et al., 2009), the resulting signal
is obtained through this windowing technique(mfc,
2023)(Paulraj et al., 2009). The Hamming window,is
usually utilized.
3.2.3 Fast Fourier Transform
After applying a Hamming window to reduce spectral
leakage, the Fast Fourier Transform (FFT) is used to
convert the signal from the time domain to the fre-
quency domain. The FFT is an efficient algorithm
designed to compute the Discrete Fourier Transform
(DFT) for a set of N samples, {x
n
}. In contrast
to the DFT, which has a computational complexity
of O(N
2
), the FFT optimizes this to O(N logN) by
taking advantage of the symmetry and periodicity of
complex exponentials.
3.2.4 Mel-Frequency Wrapping
The frequency characteristics of spoken sounds do not
conform to a conventional linear scale(Paulraj et al.,
2009). As a result, a specialized scale known as the
”Mel” scale is utilized to relate perceived pitch to
an actual frequency f measured in Hertz (Hz)(Paulraj
et al., 2009). On this scale, frequencies below 1000
Hz are spaced linearly, while those above 1000 Hz
shift to a logarithmic spacing. Typically, the number
of coefficients obtained from the Mel-frequency spec-
trum, represented as K, is commonly set at 20(Paulraj
et al., 2009).
3.2.5 Cepstrum
The logarithmic time is again transformed from the
Mel spectrum, resulting in the MFCCs(Han et al.,
2006). For the specified frame analysis, the cepstral
representation of the speech spectrum provides an ef-
fective depiction of the signal’s local spectral char-
acteristics(Paulraj et al., 2009). The Discrete Cosine
Transform (DCT) can be applied to convert the real-
number Mel spectrum coefficients into the(Paulraj
et al., 2009) temporal domain.
Using the previously described method, a set
of MFCCs is computed for each 30 ms speech
frame(Paulraj et al., 2009), incorporating overlap.
The DCT coefficients for each speech input are ex-
tracted and used as the feature set for the neural net-
work(Paulraj et al., 2009) model.
INCOFT 2025 - International Conference on Futuristic Technology
874
3.3 Model Architecture and Training
3.3.1 Bi-LSTM
A specific type of recurrent neural network (RNN),
known as bi-LSTM (bidirectional long short-term
memory)(Subramanian et al., 2023) , is capable of
processing sequential data in both frontward and
backward directions(Nama, 2018). By combining
bidirectional processing with the strengths of LSTM,
this model can effectively integrate both the previous
and next context of the input sequence(Madamanchi
et al., 2024). This bidirectional approach significantly
reduces the risk of losing important information that
may be influenced by factors present in the opposite
direction.
To evaluate the performance of a simplified BiL-
STM model, the Keras framework was employed for
building and training the architecture. The input data
was enhanced with Gaussian noise by adding random
values with a mean of 0 and a standard deviation of
0.1 to the training dataset. This augmentation aimed
to introduce variability and improve the model’s ro-
bustness.
The model architecture was constructed using a
sequential layout. The initial layer featured a Bi-
LSTM with 128 units, configured to avoid returning
intermediate sequences, thus ensuring a compact rep-
resentation of the input data. To avoid overfitting, a
Dropout layer with a probability of 0.5 was added to
deactivate nodes during training.
Subsequently, a dense layer with 32 units and a
hyperbolic tangent activation function was incorpo-
rated. This choice differed from the commonly used
ReLU activation function, allowing for an assessment
of how an alternative activation mechanism influences
the model’s learning process. The output layer con-
sisted of a dense layer with a softmax activation func-
tion, generating probabilities for each class corre-
sponding to the number of target categories in the one-
hot encoded labels. The model was compiled using
the Adam optimizer, with categorical cross-entropy
as the loss function and accuracy as the evaluation
metric. To minimize computational demands, training
was performed on a smaller subset of data, consisting
of only 100 samples. The model underwent training
for 10 epochs with a batch size of 32. These adjust-
ments, including the reduced dataset size and training
duration, were implemented to investigate the model’s
performance under resource-constrained conditions.
3.3.2 Support Vector Machine
Support Vector Machine (SVM) is a powerful super-
vised learning method that is mainly used for classi-
fication purposes.(Nair et al., 2019). It works by fig-
uring out the best hyperplane—or decision boundary
in higher dimensions—to divide various data point
classes(Nair et al., 2019)(Ratnam et al., 2021). The
primary goal of Support Vector Machines (SVM) is
to maximize the distance between the nearest data
points from different classes, known as support vec-
tors. (Nair et al., 2019). This strategy improves
the model’s resilience and its ability to generalize to
new data. (Nair et al., 2019)(Ratnam et al., 2021).
MFCCs are frequently used to capture audio char-
acteristics, leading to a feature space that is typi-
cally high-dimensional, with 13 coefficients for each
time frame. Given that SVMs perform well in high-
dimensional settings, they are particularly suitable for
tasks such as sound or vowel classification. We im-
plemented SVM using the Scikit-learn library , apply-
ing a linear kernel function that is effective for high-
dimensional feature spaces like the MFCCs utilized in
this study. SVM is recognized for its efficacy in sound
and vowel categorization tasks(Nair et al., 2019)(Rat-
nam et al., 2021).
4 EVALUATION AND RESULT
4.1 Comparison between Irula,
Malayalam and Tamil
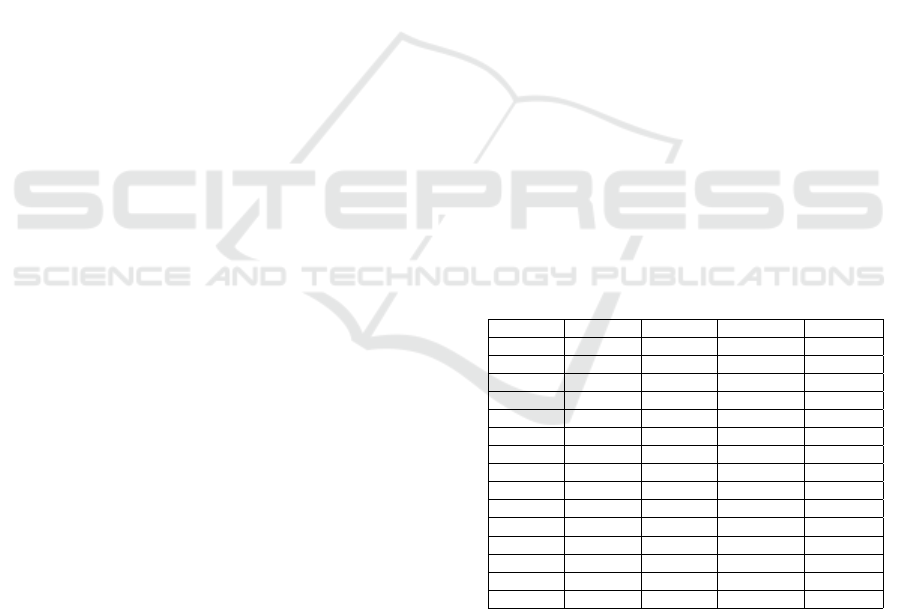
Table 1: Comparison between Irula and its Sister Lan-
guages.
Weight 1 Weight 2 Weight 3 Language Phoneme
-576.296 42.311 -4.741 Malayalam [a]
-442.539 51.198 7.521 Irula [a]
-463.308 73.609 -2.683 Tamil [a]
-563.650 24.217 17.235 Malayalam [i]
-384.451 49.462 -1.058 Irula [i]
-429.236 60.565 21.706 Tamil [i]
-609.626 68.138 30.401 Malayalam [u]
-431.740 46.375 2.256 Irula [u]
-458.865 85.762 20.168 Tamil [u]
-573.000 30.000 7.720 Malayalam [e]
-367.637 53.044 -8.653 Irula [e]
-4.732 57.919 13.994 Tamil [e]
-538.000 62.500 25.600 Malayalam [o]
-386.394 63.102 3.869 Irula [o]
-418.050 89.870 18.211 Tamil [o]
4.2 Evaluation
In this task, we assess both models using evaluation
metrics such as precision, recall, and F1-score(Tang
et al., 2020). Specifically, in this multi-class classi-
fication task, these metrics help us in evaluating the
model’s performance(Tang et al., 2020). Precision is
a statistical metric employed to assess the effective-
Design and Implementation of a Phonological Analyzer for the Irula Language: A Computational Approach to Endangered Language
Preservation
875

ness of a classification model, especially in identify-
ing true positive predictions(Tang et al., 2020). Recall
is a performance metric that measures a model’s ca-
pability to accurately identify all pertinent instances
within a dataset(Tang et al., 2020). The F1 Score is
a statistical metric that integrates two essential evalu-
ation measures: precision and recall. It reflects their
harmonic mean, offering a single value that balances
both the accuracy (precision) and comprehensiveness
(recall) of a model’s predictions(Tang et al., 2020).
4.3 Result
The performance of the phonological analyzer was
evaluated using two machine learning models: Bi-
LSTM and SVM. The models were assessed based
on their classification reports and confusion matrices,
which provide insights into the predictive accuracy
and error patterns.
The classification performance of the models is
summarized in Tables 2 and 3, which provide de-
tailed metrics, including precision, recall, F1-score,
and support for each class.
Table 2: Classification report for Bi-LSTM.
Class Precision Recall F1-Score Support
Irula 0.85 0.92 0.89 38
Malayalam 0.86 0.86 0.86 37
Tamil 0.90 0.69 0.78 13
Table 3: Classification report for SVM.
Class Precision Recall F1-Score Support
Irula 0.95 0.97 0.96 38
Malayalam 0.89 0.86 0.88 37
Tamil 0.77 0.77 0.77 13
To further evaluate the performance of both mod-
els, a Confusion Matrix was employed. These matri-
ces are presented in Figures 2 and 3 for the Bi-LSTM
and SVM models, respectively.
Figure 2: Confusion Matrix for Bi-LSTM
Figure 3: Confusion Matrix for SVM
5 CONCLUSION
This study presents an innovative approach to analyz-
ing and classifying speech data from five individuals
into three distinct classes based on articulatory fea-
tures such as tongue position, tension, and lip place-
ment (front, middle, and rear). MFCCs for feature
extraction, the research assessed the performance of
Bi-LSTM and SVM. The empirical analysis reveals
that the SVM model outperformed the Bi-LSTM in
classification accuracy, highlighting its potential as a
robust method for phonological analysis.
This research not only showcases computational
advancements but also has significant implications
for the preservation of Irula, an endangered language
with a rich linguistic heritage. By combining compu-
tational methodologies with linguistic analysis, it es-
tablishes a foundational framework for studying Irula
and offers a scalable approach for other low-resource
languages. By emphasizing the phonological differ-
ences and common features among Irula, Tamil, and
Malayalam, this work contributes to the advancement
of computational phonology and linguistics.
Furthermore, it highlights the urgent need to
develop tools for preserving and analyzing endan-
gered languages in the digital age. The framework
presented here is anticipated to support future re-
search in phonological modeling, language preserva-
tion, and computational applications for low-resource
languages, ensuring that their cultural and academic
legacies endure.
REFERENCES
(2023). Speaker recognition using mfcc. Slideshare. Avail-
able at: https://www.slideshare.net/slideshow/speaker
-recognition-using-mffc/29354934\#9.
Han, W., Chan, C.-F., Choy, C.-S., and Pun, K.-P. (2006).
An efficient mfcc extraction method in speech recog-
INCOFT 2025 - International Conference on Futuristic Technology
876

nition. In 2006 IEEE International Symposium on Cir-
cuits and Systems (ISCAS), pages 4 pp.–.
Heggarty, P., Shimelman, A., Abete, G., Anderson, C.,
Sadowsky, S., Paschen, L., Maguire, W., Jocz, L.,
Aninao, M., W
¨
agerle, L., Appelganz, D., Silva, A.,
Lawyer, L., Camara Cabral, A. S., Walworth, M.,
Michalsky, J., Koile, E., Runge, J., and Bibiko, H.-J.
(2019). Sound comparisons: A new resource for ex-
ploring phonetic diversity across language families of
the world. INTERNATIONAL CONGRESS OF PHO-
NETIC SCIENCES 2019.
Kerala Institute for Research Training and Development
Studies of Scheduled Castes and Scheduled Tribes
(KIRTADS) (2017). Irular — KIRTADS. Accessed:
2024-12-18.
Madamanchi, S., Nedungadi, P., Sai, M., Reddy, R., and
Ratnam, J. (2024). Automated speech correction as-
sistive technology for malayalam articulation errors.
Nair, A. J., Rasheed, R., Maheeshma, K., Aiswarya, L., and
Kavitha, K. R. (2019). An ensemble-based feature
selection and classification of gene expression using
support vector machine, k-nearest neighbor, decision
tree. In 2019 International Conference on Communi-
cation and Electronics Systems (ICCES), pages 1618–
1623.
Nallanthighal, V. S., H
¨
arm
¨
a, A., Strik, H., and Doss, M. M.
(2021). Phoneme based respiratory analysis of read
speech. In 2021 29th European Signal Processing
Conference (EUSIPCO), pages 191–195.
Nama, A. (2018). Understanding bidirectional lstm for se-
quential data processing. https://medium.com/@anis
hnama20/understanding-bidirectional-lstm-for-seque
ntial-data-processing. Accessed: 2024-11-25.
Paulraj, M. P., Yaacob, S. B., Nazri, A., and Kumar, S.
(2009). Classification of vowel sounds using mfcc
and feed forward neural network. In 2009 5th Inter-
national Colloquium on Signal Processing & Its Ap-
plications, pages 59–62.
Prakash, A., Prakash, J. J., and Murthy, H. A. (2016).
Acoustic analysis of syllables across indian lan-
guages. In Interspeech 2016, pages 327–331.
Ratnam, J., Kp, S., T.K, B., Priya, M., and B., P. (2021).
Hybrid Machine Translation System for the Transla-
tion of Simple English Prepositions and Periphrastic
Causative Constructions from English to Hindi, pages
247–263.
Roul, A. K. and Rath, B. N. (2023). Text independent
speaker recognition using fuzzy based neural net-
work. In 2023 1st International Conference on Cir-
cuits, Power and Intelligent Systems (CCPIS), pages
1–5.
Shimizu, T., Ashikari, Y., Sumita, E., Zhang, J., and Naka-
mura, S. (2008). Nict/atr chinese-japanese-english
speech-to-speech translation system. Tsinghua Sci-
ence and Technology, 13(4):540–544.
Singh, A. K. (2006). A computational phonetic model for
indian language scripts. In Semanticscholar.
Subramanian, M., S, L. S., and V R, R. (2023). Deep learn-
ing approaches for melody generation: An evaluation
using lstm, bilstm and gru models. In 2023 14th Inter-
national Conference on Computing Communication
and Networking Technologies (ICCCNT), pages 1–6.
Tang, T., Tang, X., and Yuan, T. (2020). Fine-tuning bert
for multi-label sentiment analysis in unbalanced code-
switching text. IEEE Access, 8:193248–193256.
The Criterion: An International Journal in English (2024).
The Irula Language and Literature. Accessed: 2024-
12-18.
Design and Implementation of a Phonological Analyzer for the Irula Language: A Computational Approach to Endangered Language
Preservation
877
