
Human Detection in Disaster Scenarios for Enhanced Emergency
Response Using YOLO11
Md Sadiq Z Pattankudi, Samarth Uppin, Abdul Rafay Attar, Kunal Bhoomaraddi, Rohan Kolhar
and Sneha Varur
Department of SOCSE, KLE Technological University Hubballi, Karnataka, India
Keywords:
Yolo11, Convolution Neural Network, Disaster Events, UAV and Drones.
Abstract:
In disaster scenarios, the ability to rapidly and accurately detect key elements such as rescuers, victims, ve-
hicles, and dangerous objects is crucial for effective and timely rescue operations. This research proposes
applying You Only Look Once(YOLO11), a real time object detection model to detect aerial images captured
by drone. To train the model, a custom dataset was created, containing four classes—rescuer, victim, vehicles,
and dangerous objects—representing critical components in disaster environments. This dataset provided a
comprehensive and controlled environment to evaluate the system’s performance. The results demonstrated
that the proposed system significantly enhances decision making processes, particularly in locating and rescu-
ing human survivors during emergency situations. The model achieved an overall precision of 82.4%, recall of
30.5%, a mean Average Precision at IoU 50 (mAP50) of 36.1%, and a mean Average Precision (mAP) at IoU
50-95 (mAP50- 95) of 16.4%. These performance metrics highlight the reliability of the model in identifying
critical objects in real time, with opportunities for further refinement to improve recall and precision balance,
making it a valuable tool for disaster response teams.
1 INTRODUCTION
Natural disasters(Li et al., 2023) have a severe im-
pact on human life(Baez et al., 2010), and with the
rise in global warming, the frequency of events such
as floods has significantly increased(Banholzer et al.,
2014). Recent extreme weather events in Kerala have
highlighted the ongoing challenges posed by climate
change and vulnerabilities in infrastructure (Chaud-
hary and Piracha, 2021). Rapid response and effi-
cient resource allocation are critical to minimizing ca-
sualties and reducing damage. However, the scale
and unpredictability of such events make traditional
methods of disaster management challenging. In re-
cent years, Unmanned Aerial Vehicles (UAVs)(Das
and Roy, 2023) have emerged as a significant technol-
ogy in disaster management. Their ability to navigate
through inaccessible terrains, capture high-resolution
imagery, and deliver real-time data has revolution-
ized emergency response strategies(He et al., 2016;
Sandino et al., 2021). UAVs have been successfully
deployed to assess disaster-hit regions, monitor the
extent of damage(Rahman et al., 2024b), and identify
people in need of assistance. Research demonstrates
that UAVs significantly reduce emergency response
times and enhance situational awareness(van Tilburg
and Kaizer, 2021), making them invaluable assets
in the aftermath of natural disasters (Goodchild and
Glennon, 2019). Parallel to advancements in UAV
technology, object detection models have seen rapid
evolution, with You Only Look Once (YOLO)(Terven
et al., 2023) becoming a cornerstone in real-time im-
age processing, It is a state-of-the-art object detec-
tion model that has shown remarkable performance
in terms of both speed and accuracy(Sharma and Ya-
dav, 2023). The recent development of these mod-
els has further enhanced its capabilities, making it
highly suitable for real-time applications where both
detection speed and precision are paramount. In
drone-based disaster response and ability to detect ob-
jects accurately in aerial images becomes essential for
identifying survivors, vehicles in complex and clut-
tered environments. Our work contributes to enhanc-
ing UAV-based disaster response by training a cus-
tom YOLO 11 model on a disaster-specific dataset
containing classes such as rescuer, victim, vehicles,
and dangerous objects(Patel and Sharma, 2023). The
model is trained to identify critical elements in aerial
Pattankudi, M. S. Z., Uppin, S., Attar, A. R., Bhoomaraddi, K., Kolhar, R. and Varur, S.
Human Detection in Disaster Scenarios for Enhanced Emergency Response Using YOLO11.
DOI: 10.5220/0013601000004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 2, pages 739-746
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
739

images captured during emergencies, enabling rapid
assessment and resource allocation in complex envi-
ronments.
The primary objectives of our study are:
• To create a diverse dataset that captures com-
mon disaster scenarios, including flood zones and
post-earthquake environments, with an emphasis
on detecting humans, vehicles, and hazardous ob-
jects.
• Develop a YOLO 11-based object detection
framework specifically optimized for drone im-
agery in disaster scenarios, building on this
dataset.
• Evaluate the framework comprehensively based
on critical metrics such as detection accuracy, in-
ference speed, and real-time processing capabili-
ties to ensure its reliability.
The paper contains the sections as follows:
Section II reviews literature survey, highlighting re-
cent advancements in disaster response and object de-
tection models. Section III of the paper provides a
background study, offering an overview of key con-
cepts used in UAV-based disaster management. Sec-
tion IV outlines the proposed methodology, detail-
ing data collection, model training, and deployment
strategies. Section V represents the results and dis-
cussions, analyzing the performance of the system in
various disaster scenarios. Finally, Section VI con-
cludes with a summary of findings and explores po-
tential directions for future research and implementa-
tion.
2 LITERATURE SURVEY
The integration of AI and drones for disaster man-
agement, particularly in search-rescue operations, has
garnered attention in recent years. Drones equipped
with AI algorithms are used for multiple tasks that in-
clude damage assessment, victim localization, and re-
source allocation. AI enables drones to autonomously
detect critical objects, such as humans, vehicles, and
infrastructure damage, which is crucial in situations
where human intervention is limited or unsafe (Pa-
pyan et al., 2024). Object detection models, particu-
larly those using deep learning techniques,(Deng and
Yu, 2014; Alom et al., 2018) have shown promise
in improving the efficiency of disaster response by
enabling real-time identification and classification
of objects in complex environments (Nehete et al.,
2024).
Existing AI-based solutions for disaster manage-
ment often rely on signal-based detection, such as
mobile phone triangulation, which can be unreliable
in areas where infrastructure is damaged or where sur-
vivors do not have access to mobile phones (Pan et al.,
2023). This has led to an increasing interest in in-
tegrating visual-based detection systems, which can
operate independently of infrastructure, providing a
more robust and versatile approach to search and res-
cue missions (Lygouras et al., 2019).
While significant progress has been made in de-
veloping AI-driven drone systems for disaster man-
agement, several gaps remain in the current research.
Many models still struggle with accurate detection in
obstructed environments and often lack the real-time
processing capabilities required for effective deploy-
ment in time-critical scenarios.
Our work involves building a YOLO 11-based ob-
ject detection model on a custom dataset, which di-
rectly addresses the limitations found in existing sys-
tems. YOLO 11 is known for its fast inference time
and high accuracy in detecting objects, even in clut-
tered and partially obstructed environments. By train-
ing the model on a custom dataset that simulates dis-
aster scenarios, we can improve detection accuracy
in environments typical of natural disasters. Addi-
tionally, YOLO 11’s ability to process images in real-
time ensures that the system can be deployed in search
and rescue missions, where every second counts. In
summary, our work builds on existing research by
overcoming key limitations such as detection accu-
racy in complex environments and the need for real-
time, visual-based object detection. By addressing
these gaps, the YOLO 11-based model has the po-
tential to significantly enhance the effectiveness of
drone-assisted disaster response systems, ultimately
improving the efficiency of search and rescue opera-
tions in natural disasters.
3 BACKGROUND STUDY
3.1 Unmanned Aerial Vehicles
UAV’s(Kumar et al., 2023), usually known as drones,
have proven to be invaluable tools for disaster man-
agement(Xie and Zhao, 2023), providing aerial per-
spectives that allow responders to assess and moni-
tor large areas quickly and efficiently(Madnur et al.,
2024). Drones can reach places that are inaccessi-
ble due to hazardous conditions(Wang and Lee, 2024;
Rahman et al., 2024a), making them essential for
locating survivors after natural disasters. These AI
systems often rely on models such as CNNs(O’Shea
and Nash, 2015) and more specialized architecture
like YOLO, which can detect objects in real time.
INCOFT 2025 - International Conference on Futuristic Technology
740
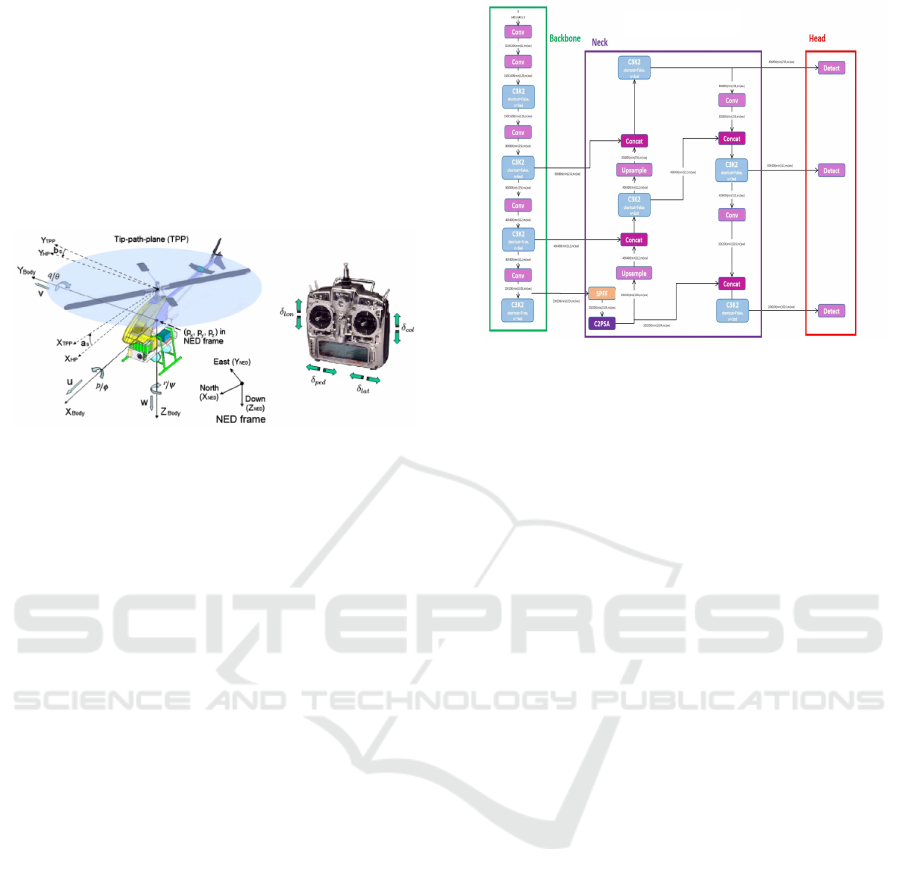
Several notable studies have been pivotal in laying
the foundation for human detection in disaster sce-
narios. These studies have focused on improving
the accuracy and speed of AI-based detection mod-
els in dynamic and complex environments(Norvig,
2022; Chowdhury and Bose, 2024). Through these
advances, our goal is to deploy an edge device capa-
ble of saving lives by helping to carry out effective
search-and-rescue operations.
Figure 1: Schematic diagram of uav (Kontogiannis and
Ekaterinaris, 2013).
3.2 You Only Look Once (YOLO 11)
YOLO 11, an advanced version of the You Only Look
Once (YOLO) series, enhances aerial human detec-
tion in emergency response scenarios. By leveraging
a single deep learning pass over an image, YOLO 11
can quickly detect and classify human figures in real-
time from aerial footage, such as drones, even in en-
vironments like natural disasters. The network oper-
ates by applying convolutional layers to extract visual
features such as shapes, movements, and patterns at
varying levels of abstraction. This allows it to ac-
curately recognize human figures, even in cluttered
or obstructed areas. YOLO 11 has been trained in
datasets with various aerial images, allowing it to gen-
eralize across hazardous conditions, providing first re-
sponders with immediate information on human loca-
tion during emergencies. It’s high speed and accuracy
make it an invaluable tool in enhancing emergency re-
sponse efforts by enabling faster, more effective res-
cue operations(Khanam and Hussain, 2024).
4 PROPOSED METHOD
4.1 Dataset Collection and Preparation
During the dataset creation process, we encountered
a significant challenge: the lack of human presence
in many publicly available disaster scenario image
datasets. This absence of representation for victims
Figure 2: Architecture of YOLO 11 (Rao, 2024).
and rescuers created obstacles in effectively training
the model for real-world applications. To overcome
this, we developed a comprehensive dataset that sim-
ulates various disaster scenarios, such as floods, wild-
fires, and post-earthquake environments. Drone im-
ages of disaster-stricken areas were initially sourced
from publicly available platforms like Google and dis-
aster management resources.
Using Roboflow’s advance annotation tool,
bounding boxes were manually drawn around each
object of interest within the images(Aqeel et al.,
2024). This step was crucial for accurately identify-
ing and localizing objects in disaster scenarios. Each
object within the bounding boxes was classified into
one of the predefined categories: victim, rescuer,
vehicle, or obstacle. This classification ensured that
the dataset was comprehensive and well-structured,
reflecting the specific objects essential for search-
and-rescue missions. By annotating each image in
detail, the process maintained high consistency and
precision, allowing the model to learn the necessary
features for detecting these objects in real-world
disaster situations.
4.2 Model Configuration and Training
Upon completing the annotation process, the dataset
consisted of 150 images, carefully designed to repre-
sent a variety of disaster environments. This ensured
that the model could generalize across different dis-
aster conditions. The annotated dataset was then ex-
ported and prepared for training the YOLOv11 model.
The model was trained on this dataset for 175 epochs,
with a learning rate of 0.01, a value selected based
on previous research, which strikes a balance between
fast convergence and model stability for object detec-
tion tasks.
The model architecture utilizes a standard loss
Human Detection in Disaster Scenarios for Enhanced Emergency Response Using YOLO11
741

Figure 3: Methodology used to train the model.
function for object detection, which combines both
classification and localization losses. The total loss
(L) used in the YOLO model is the sum of the classi-
fication loss (L
cls
), localization loss (L
loc
), and confi-
dence loss (L
con f
):
L = L
cls
+ L
loc
+ L
con f
(1)
The classification loss is typically calculated using the
cross-entropy loss:
L
cls
= −
N
∑
i=1
y
i
log( ˆy
i
) (2)
where y
i
represents the ground truth label, ˆy
i
is the
predicted class probability, and N is the number of
object classes.
The localization loss is calculated using the mean
squared error between the predicted and true bound-
ing box coordinates:
L
loc
=
N
∑
i=1
(x
i
− ˆx
i
)
2
+ (y
i
− ˆy
i
)
2
+ (w
i
− ˆw
i
)
2
+ (h
i
−
ˆ
h
i
)
2
where x
i
, y
i
are the center coordinates, and w
i
, h
i
are the width and height of the bounding box for the
i-th object.
The confidence loss quantifies how well the model
predicts the presence of an object in a particular cell
of the grid:
L
con f
=
N
∑
i=1
C
i
1 −
ˆ
C
i
where C
i
is the confidence score (whether an ob-
ject is present in the cell), and
ˆ
C
i
is the predicted con-
fidence score.
The learning rate was set at 0.01, following a
learning rate decay scheme to gradually reduce the
rate as training progresses to improve model stability
and performance. The model architecture, compris-
ing 238 layers and 2,582,932 parameters, was specif-
ically designed to handle the complexities of aerial
imagery in disaster scenarios, ensuring that it could
effectively detect and classify objects, even in clut-
tered and obstructed environments typically found in
disaster zones.
The model was trained with a validation set to
monitor performance and prevent overfitting. In or-
der to study the generalization capability and practical
performance of the model, the testing was performed
on the test set.
4.3 Area Calculation
Victim detection and positioning depend on the pose
of the UAV camera and its projection of its environ-
mental footprint. A victim is detected if their 2D local
position s
0
pv
(x, y) lies within the projected footprint of
the camera, determined by summing the angles be-
tween s
0
pv
and the corners of the boundaries of the
footprint.
Geometrically, based on the design shown in Fig-
ure 6, the expected extent l of a vision-based sensor
2D projected footprint can then be computed using
the following Equations (14) and (15):
l
top, bottom
= s
0
pu
(z) · tan
α ± tan
−1
h
2 f
(3)
l
left, right
= s
0
pu
(z) · tan
± tan
−1
w
2 f
(4)
where s
0
pu
is the UAV altitude, α and β are the
camera’s pointing angles from the vertical z-axis and
the horizontal x-axis of the world coordinate frame,
w is the lens width, h is the lens height, and f is the
focal length(Nandan Date, 2024).
Figure 4: UAV camera coverage(Sandino, 2022).
INCOFT 2025 - International Conference on Futuristic Technology
742
As illustrated in 4, in Field Of View (FOV) Pro-
jection and Footprint Extent of a Vision-Based Sensor
you have the setup of a camera mounted on the frame
of a UAV defining the variable α as the angle going
up/down from the vertical (or pitch), laying down the
coordinates of the footprint corners c Using the fol-
lowing transformation, the footprint corners c in the
camera center local coordinate frame I are translated
to the world’s coordinate frame W :
c
0
(X)
c
0
(Y )
=
s
0
pu
(X)
s
0
pu
(Y )
+
cos(ϕ
u
) − sin(ϕ
u
)
sin(ϕ
u
) cos(ϕ
u
)
c(X)
c(Y )
, (5)
where s
0
pu
represents the next position of the UAV,
and ϕ
u
is Euler yaw angle of the UAV, Since no ac-
tions change the heading of the UAV mid-flight, and
yaw estimation errors are negligible, we can rewrite
Equation(4) in the following form:
c
0
(X)
c
0
(Y )
=
s
0
pu
(X) + c(X)
s
0
pu
(Y ) + c(Y )
, (6)
The detection confidence o
ζ
that comes as part of
the output data from the CNN object detector is mod-
eled using the following equation:
o
ζ
=
(1 − ζ
min
)(d
uv
− z
min
+ ζ
min
)
z
max
− z
min
, (7)
where ζ
min
is the minimally accepted confidence
threshold, z
max
and z
min
are the maximum and mini-
mum UAV flying altitudes, respectively, and d
uv
is the
Manhattan distance between the UAV and the victim.
5 RESULTS AND DISCUSSION
The model has been optimized during training to
alleviate the output of the loss function, and its output
was evaluated based on: precision(P), where P is the
proportion of accurately anticipated positive exam-
ples were among all positive predictions. recall(R),
where R is the proportion of the genuinely antici-
pated positive instances among all positive examples.
mAP50 is a mean Average Precision at a threshold of
50% IoU, which reveals the model’s precision in ob-
jects’ prediction. mAP50-95 – a mean Average Preci-
sion on IoU thresholds.
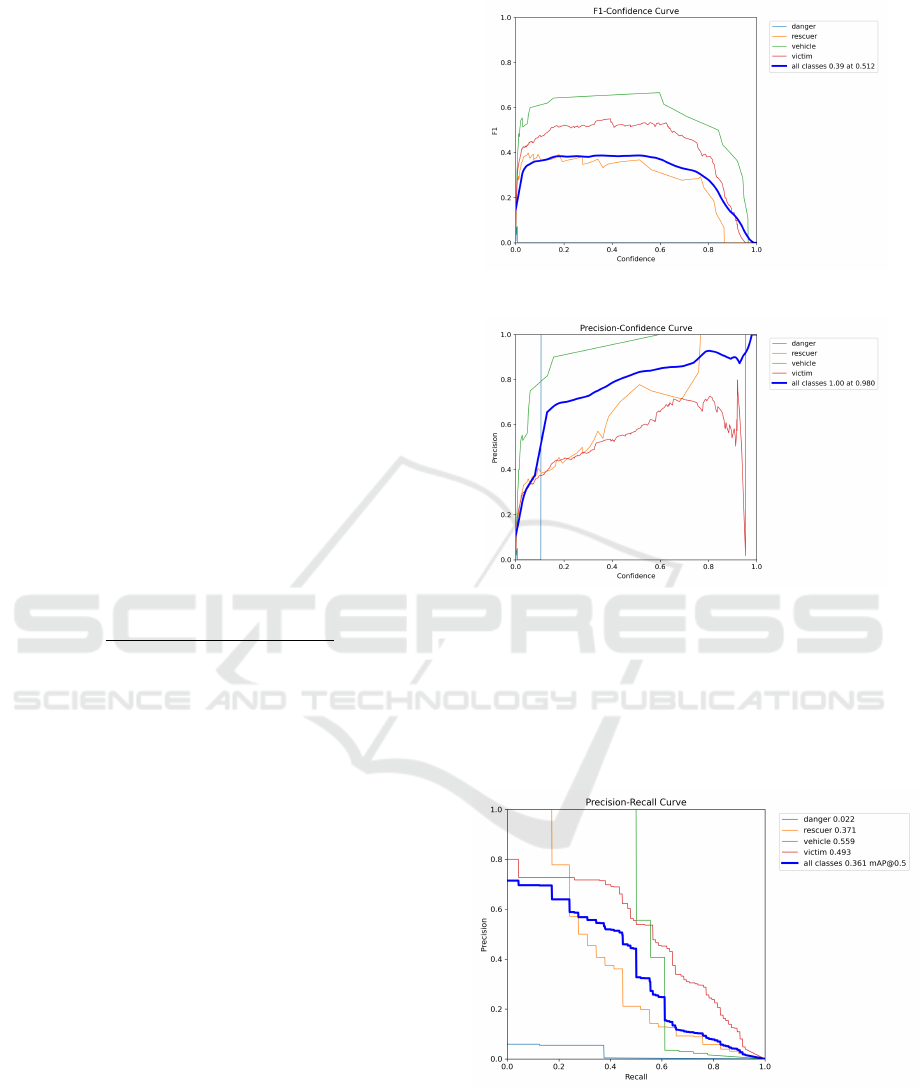
Fig. 5 shows the F1-score versus confidence of
39% with confidence of 0.51. Basically, the confi-
dence value gives an idea about how confident the
model is with the defect detection; values close to 1
are completely confident in the positive detection of
the correct defect.
Figure 5: Plotting of F1-score vs. confidence
Figure 6: Plotting of precision vs. confidence
Fig. 6 illustrates the precision versus confidence
for all classes. The model achieves a precision of
100% at a confidence threshold of 0.98. Higher confi-
dence values indicate more reliable predictions, with
vehicle performing consistently well, while rescuer
and victim exhibit variability.
Figure 7: Plotting of precision vs. recall
Fig. 7 illustrates the precision-recall relationship
of the proposed system, providing an overview of its
detection performance across various classes.
Fig. 8 depicts the relationship between recall and
confidence, illustrating how the model’s ability to
Human Detection in Disaster Scenarios for Enhanced Emergency Response Using YOLO11
743
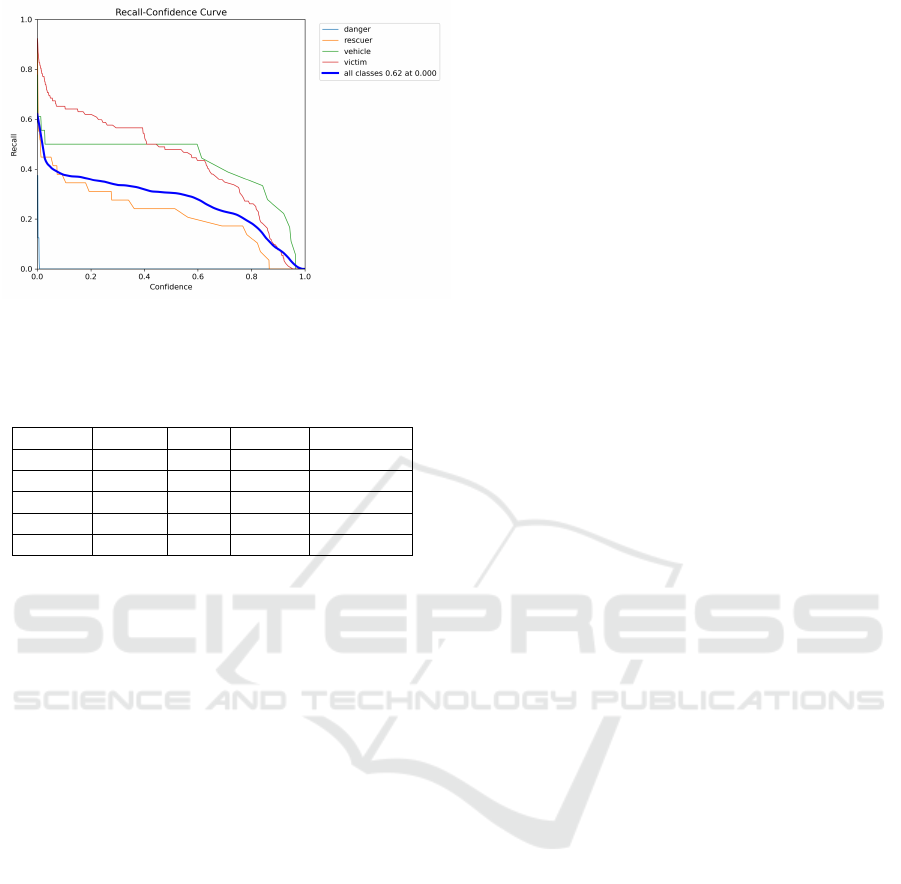
Figure 8: Plotting of recall vs. confidence.
identify relevant objects varies across different con-
fidence thresholds.
Table 1: Detection performance for different classes.
Class Box(P) R mAP50 mAP50-95
All 0.824 0.305 0.361 0.164
Danger 1.000 0.000 0.0222 0.00731
Rescuer 0.753 0.241 0.371 0.192
Vehicle 0.975 0.500 0.559 0.259
Victim 0.567 0.478 0.493 0.199
From table1, the class-wise performance of the
model is as follows:
• Danger Class: Precision was 1.0, but recall was
0.0, indicating no detections. The mAP50 was
0.0222, and mAP50-95 was 0.00731, showing
poor performance.
• Rescuer Class: Precision was 0.753, and recall
was 0.241. The mAP50 was 0.371, and mAP50-
95 was 0.192, highlighting the need to improve
recall.
• Victim Class: Precision was 0.567, and recall was
0.478. The mAP50 was 0.493, and mAP50-95
was 0.199, indicating moderate performance with
room for improvement.
In terms of inference speed, the model demon-
strated significant efficiency, which is crucial for real-
time applications in disaster response. The prepro-
cessing time was 0.2 ms, meaning that the data was
prepared quickly for analysis. The inference time,
or the time taken by the model to process each im-
age, was 2.2 ms, which is sufficiently fast for rapid
decision-making. Overall, the model’s efficiency in
processing and analyzing images makes it suitable for
deployment in emergency response situations, where
every millisecond counts.
As shown in the figure9, we developed an appli-
cation on the Roboflow platform, designed and tested
on an edge device (a mobile phone) within a con-
trolled experimental setting to assess its performance.
Extending this approach, the edge device can be em-
bedded in drones for real-time deployment, enabling
implementation in critical scenarios, such as emer-
gency rescue operations during natural disasters, such
as floods. This deployment can facilitate rapid re-
sponse by delivering automated insights, enhancing
the efficiency and accuracy of search-and-rescue mis-
sions in challenging environments.
The findings demonstrate YOLO11’s effective-
ness in detecting crucial objects during disaster sce-
narios, significantly aiding rescue operations. The
model’s high speed allows it to perform well on
drones with limited processing power, meeting the
real-time constraints necessary for urgent decision-
making. While YOLO11 provides substantial im-
provements over earlier models, challenges such as
detection accuracy in low-light or highly obstructed
conditions remain. Future work could focus on in-
tegrating additional sensors, such as infrared or Li
DAR, to enhance detection capabilities in complex
environments.
6 CONCLUSION
The training results highlight the strengths and ar-
eas for improvement of the model in detecting objects
within disaster scenarios. The model demonstrates
strong performance in detecting victims, as evidenced
by the higher mAP scores (mAP50 = 0.56), suggest-
ing that it is effective at identifying survivors in dis-
tress.However, performance in detecting other criti-
cal objects,such as dangerous objects and rescuer,
showed relatively lower mAP scores, indicating areas
that need further development. This performance gap
can likely be attributed to the relatively small size of
the dataset, especially the limited instances of certain
categories, such as dangerous objects and rescuers.
The model also exhibited strong detection capabili-
ties for vehicles, suggesting that it performs reason-
ably well in identifying vehicles during disaster re-
sponse operations. In disaster response scenarios, the
model’s precision and recall values reflect that it is
relatively good at identifying objects of interest, but
there is notable room for improvement, particularly in
detecting distant objects, which are often encountered
in real-world disaster scenarios.
The model’s effectiveness could be enhanced
through techniques such as data augmentation and
expanding the dataset to include a broader range of
disaster environments, helping to improve its gener-
alization capabilities. These findings are consistent
with similar studies in the field, where object detec-
INCOFT 2025 - International Conference on Futuristic Technology
744

Figure 9: Testing in Real Time
tion models, particularly those based on the YOLO
architecture, have been successfully deployed in real-
time disaster monitoring systems, achieving effective
results in terms of both speed and accuracy, to fur-
ther optimize the model’s performance, future work
should include experimenting with different learning
rates and exploring more diverse and comprehensive
datasets. These advancements will be critical for im-
proving the model’s ability to detect various objects
in dynamic and challenging disaster scenarios, ulti-
mately enhancing its deployment in real-time search-
and-rescue operations.
REFERENCES
Alom, J., Taha, T. M., and Asari, V. K. (2018). Deep learn-
ing for computer vision: A brief review. IEEE Access.
Aqeel, M., Norouzzadeh, P., Maazallahi, A., Tutun, S.,
Miab, G., Al Dehailan, L., Stoeckel, D., Snir, E., and
Rahmani, B. (2024). Dental cavity analysis, predic-
tion, localization, and quantification using computer
vision. Artificial Intelligence in Health, 1:80.
Baez, J., Fuente, A., and Santos, I. (2010). Do natural dis-
asters affect human capital? an assessment based on
existing empirical evidence. Institute for the Study of
Labor (IZA), IZA Discussion Papers.
Banholzer, S., Kossin, J., and Donner, S. (2014). The Im-
pact of Climate Change on Natural Disasters, pages
21–49.
Chaudhary, M. T. and Piracha, A. (2021). Natural disas-
ters—origins, impacts, management. Encyclopedia,
1(4):1101–1131.
Chowdhury, N. and Bose, S. (2024). Future perspectives on
ai-assisted disaster management. IEEE Transactions
on Intelligent Systems.
Das, M. and Roy, K. (2023). Enhancing uav accuracy in
search missions with yolov11. IEEE Access.
Deng, L. and Yu, D. (2014). Overview of deep learning.
In Proceedings of the 2014 IEEE International Con-
ference on Acoustics, Speech and Signal Processing
(ICASSP).
Goodchild, M. and Glennon, J. A. (2019). Applications of
unmanned aerial vehicles (uavs) in disaster manage-
ment. Geography Compass.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition (CVPR).
Khanam, R. and Hussain, M. (2024). Yolov11: An
overview of the key architectural enhancements.
arXiv:2410.17725v1 [cs.CV] 23 Oct 2024.
Kontogiannis, S. G. and Ekaterinaris, J. A. (2013). De-
sign, performance evaluation and optimization of a
uav. Aerospace science and technology, 29(1):339–
350.
Kumar, R., Singh, A., and Patel, V. (2023). Human detec-
tion from unmanned aerial vehicles’ images for search
and rescue missions: A state-of-the-art review. IEEE
Access.
Li, J., Wang, X., and Zhang, H. (2023). Uav-enhanced
Human Detection in Disaster Scenarios for Enhanced Emergency Response Using YOLO11
745

dataset for human detection in disaster scenarios.
arXiv Preprint.
Lygouras, E., Santavas, N., Taitzoglou, A., Tarchanidis, K.,
Mitropoulos, A., and Gasteratos, A. (2019). Unsuper-
vised human detection with an embedded vision sys-
tem on a fully autonomous uav for search and rescue
operations. Sensors, 19(16):3542.
Madnur, P., Shetty, P., Parashetti, G., Varur, S., and M,
M. S. (2024). Advancing in cricket analytics: Novel
approaches for pitch and ball detection employing
opencv and yolov8. In 2024 IEEE 9th International
Conference for Convergence in Technology (I2CT),
pages 1–8.
Nandan Date, Rohan Kolhar, N. B. S. K. S. V. (2024). Au-
tonomous grid-driven unmanned aerial vehicle tech-
nology for precise quantification in multi-cropped
fields. International Journal of Advances in Electron-
ics and Computer Science (IJAEC).
Nehete, P., Dharrao, D., Pise, P., and Bongale, A. (2024).
Object detection and classification in human rescue
operations: Deep learning strategies for flooded en-
vironments. International Journal of Safety and Secu-
rity Engineering, 14(2):599–611.
Norvig, P. (2022). Algorithms for artificial intelligence.
IEEE Signal Processing Magazine.
O’Shea, K. and Nash, R. (2015). An introduction to convo-
lutional neural networks. ArXiv e-prints.
Pan, M., Li, Y., Tan, W., and Gao, W. (2023). Drone-
assisted fingerprint localization based on kernel global
locally preserving projection. Drones, 7(7):480. Sub-
mission received: 16 June 2023 / Revised: 15 July
2023 / Accepted: 18 July 2023 / Published: 20 July
2023.
Papyan, N., Kulhandjian, M., Kulhandjian, H., and
Aslanyan, L. (2024). Ai-based drone assisted human
rescue in disaster environments: Challenges and op-
portunities. Pattern Recognition and Image Analysis,
34(1):169–186.
Patel, V. and Sharma, R. (2023). Improved vehicle detection
using yolov11 in disaster zones. IEEE Transactions on
Transportation Systems.
Rahman, M. A., Islam, M. S., and Hossain, M. S. (2024a).
Human detection in drone images using yolo for
search-and-rescue operations. ACM Digital Library.
Rahman, M. A., Islam, M. S., and Hossain, M. S. (2024b).
A search operation unmanned aerial vehicle using
yolo v5 with real-time human detection and counting.
IEEE Xplore.
Rao, S. N. (2024). Yolov11 architecture explained: Next-
level object detection with enhanced speed and accu-
racy.
Sandino, J. (2022). Autonomous decision-making for UAVs
operating under environmental and object detection
uncertainty. PhD thesis.
Sandino, J., Maire, F., Caccetta, P., Sanderson, C., and Gon-
zalez, L. (2021). Drone-based autonomous motion
planning system for outdoor environments under ob-
ject detection uncertainty. Remote Sensing, 13:4481.
Published on November 8, 2021.
Sharma, K. and Yadav, R. (2023). Advanced ai techniques
in uav rescue missions: A yolov11 case study. IEEE
Transactions on Rescue AI.
Terven, J., C
´
ordova-Esparza, D.-M., and Romero-
Gonz
´
alez, J.-A. (2023). A comprehensive review of
yolo architectures in computer vision: From yolov1 to
yolov8 and yolo-nas. Machine Learning and Knowl-
edge Extraction, 5(4):1680–1716.
van Tilburg, C. and Kaizer, M. (2021). Reducing emergency
response times using uavs: A case study. Journal of
Emergency Management.
Wang, J. and Lee, C. (2024). Optimizing yolov11 for uav
disaster response. IEEE Robotics and Automation
Magazine.
Xie, H. and Zhao, Y. (2023). Yolov11 in disaster monitor-
ing: Insights and innovations. IEEE Computational
Intelligence Magazine.
INCOFT 2025 - International Conference on Futuristic Technology
746
