
Enhancing Customer Purchasing Behaviour Prediction in
E-Commerce: A Deep Learning Perspective
Rekulara Sharath, Anishetty Vineeth Kumar, Bokkena Sangameshwar and Bidyutlata Sahoo
Department of CSE(AI&ML), Institute of Aeronautical Engineering, Dundigal, Hyderabad, Telangana, India
Keywords: Deep Learning, Machine Learning, Data Preprocessing, Feature Engineering.
Abstract: Digital retailers are experiencing a growing volume of online transactions with consumers, which is driven
by consumers' ability to buy products through E commerce platforms. Such interactions tend to form complex
behavioural constructs that are extractable to assist companies in comprehending consumer requirements. One
of the most important applications is the correct determination of the behavior of consumers in the e commerce
domain. For selling any sort of product over the Internet or in the other words in order to achieve high profit
in an e-commerce business, the interplay between a customer and a merchandise is quite very critical.
Moreover, a lot of e commerce websites and services proliferate and competition has become just a mouse-
click away. Therefore the need to stay in the business, and enhance profitability measures purchases in a more
advanced way predicting desirability and allowing companies to customize services for customers based on
their indees. To help forecast behavioral patterns the research will incorporate foam Developing Learning
approaches. Also, narrative data from the dataset would be drawn through exploratory data analysis (EDA).
The dataset used in this research encompasses of different attributes, such as kind of visitors, that is whether
they made a purchase or not and many other variables. In this research, Deep Learning techniques aptly suited
for Multi-Level Data due to its robust capacity of modeling and accurate categorization are employed. In
addition to the insights gained from each particular set of data within EDA, the results from the behavioural
analysis prediction using any of the deep learning methods can add useful statistics to the e commerce
companies. Understanding user behaviour Smart usability design engagement, site design optimization,
personalisation and improvements in user experience..
1 INTRODUCTION
In the dynamic realm of digital commerce, the rapid
shift toward online platforms has significantly
reshaped consumer behavior, necessitating that e-
commerce businesses stay ahead by accurately
understanding and predicting purchasing patterns.
(Sarkar, Mia, et al. , 2023) This evolution has
emocratized shopping and created an environment
where every user interaction generates valuable data
that can reveal deep insights into consumer
preferences and trends. This paper presents a
comprehensive study that leverages advanced data
analytics, particularly focusing on Logistic
Regression, Neural Networks, and XGBoost, to
predict the accuracy of reorder behaviors in e
commerce. The foundation of this research is built on
meticulous Exploratory Data Analysis (EDA) of a
diverse dataset that includes customer demographics,
browsing history, purchase frequencies, and past
interactions with promotional offers. By uncovering
hidden patterns through EDA, we aim to enhance our
understanding of the factors influencing consumer
decisions in online shopping. Notably, we achieved
an accuracy of 90.13% using Artificial Neural
Networks, demonstrating the effectiveness of this
technique in predicting reorder behaviors.
Deep Learning and machine learning
techniques, such as Neural Networks and XGBoost,
are pivotal in this study, enabling us to process large
volumes of data and extract complex patterns that
traditional statistical methods might overlook. By
integrating these techniques, the study seeks to
develop robust predictive models capable of
forecasting key consumer behaviors, such as the
likelihood of reordering and product preferences. The
implications of these predictive models are profound,
offering e-commerce businesses a competitive edge
through data-driven decision-making. (Kumar,
Margala, et al. , 2023) Accurate behavioral
Sharath, R., Kumar, A. V., Sangameshwar, B. and Sahoo, B.
Enhancing Customer Purchasing Behaviour Prediction in E- Commerce: A Deep Learning Perspective.
DOI: 10.5220/0013599500004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 2, pages 649-655
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
649

predictions facilitate the creation of personalized
marketing campaigns, optimized user experiences,
and targeted strategies that resonate with specific
customer segments. The ultimate goal of this research
is to equip companies with the knowledge and skills
necessary to successfully negotiate the complex
terrain of consumer behavior, promote innovation in
customer service, and maintain development in the
fiercely competitive e-commerce sector. There are six
sections in this study. The arrangement is as follows:
Section 2 examines pertinent scholarly works. A
thorough explanation of the research technique is
given in Section 3. Section 4 discusses the results
analysis and accuracy validation using different
evaluation criteria. The paper's conclusion, found in
Section 5, reviews the goals in light of the data and
considers potential future approaches for the study of
consumer purchasing behavior. Lastly, Section 6
contains a list of references.
2 LITERATURE SURVEY
The literature review reveals a range of approaches
employed in predicting customer purchasing
behavior, each utilizing various supervised
classification techniques. These include Logistic
Regression, Decision Trees, K-Nearest Neighbors,
Naïve Bayes, Support Vector Machines (SVM),
Random Forests, and Stochastic Gradient Descent,
which, after thorough feature optimization, achieved
a remarkable accuracy rate of 88%. (Sarkar, Mia, et
al. , 2023) To reduce dataset complexity and boost
classifier performance, K-means clustering was
introduced, which enhanced data homogeneity. This,
combined with algorithms like C4.5, J48, CS-MC4,
and Multinomial Logistic Regression, delivered
superior prediction outcomes.
(Kumar, Margala, et al. , 2023) Moreover, a
dynamic pricing strategy was developed to categorize
customers based on behavioral patterns and optimize
pricing in real-time, guided by historical data. This
strategy aimed to maximize revenue while ensuring
customer satisfaction. (Chaubey, Gavhane, et al. ,
2014)SVM models also played a significant role in
analyzing inventory and sales data, uncovering a
critical insight that age is a major factor influencing
online purchasing decisions. This discovery is crucial
for developing more targeted e-commerce marketing
strategies. (Vankhede, Kumar, et al. ,
2024)Additionally, the Customer Behavior Mining
Framework integrated K-means clustering and
decision trees to anticipate customer actions,
demonstrating moderate accuracy. However, the
study suggests that the framework's performance
could be enhanced by leveraging more sophisticated
algorithms. Lastly, web usage mining was used to
gather valuable insights by analyzing client, server,
and agent logs. This approach offered a holistic view
of customer behavior, examining both technical and
interaction aspects within e-commerce platforms to
provide deeper understanding and actionable insights.
3 DESIGN AND PRINCIPLE OF
OPERATION
3.1 METHODOLOGY
The dataset utilized for this study is the Instacart
Market Basket Analysis dataset, sourced from the
public dataset repository, Kaggle. (Valecha, Varma,
et al. , 2018) This dataset contains a comprehensive
record of over 3 million grocery orders made by more
than 200,000 users across multiple retailers. It
includes detailed information on customer purchasing
behavior, such as the products ordered, the sequence
of orders, product categories, and reorder patterns.
The procedure is carried out to perform the analysis
effectively to gain the necessary insights for in E-
commerce. The whole methodology is divided into
the following steps as shown in Fig. 1:
• Data Collection
• Data Preprocessing
• Feature Engineering
• Model Selection
• Model Design
• Training
• Evaluation
• Hyper Parameter Tuning
• Re-Evaluation
Figure 1: Methodology.
INCOFT 2025 - International Conference on Futuristic Technology
650

3.1.1 Data Collection
The dataset utilized for this study is the Instacart
Market Basket Analysis dataset, sourced from the
public dataset repository, Kaggle. This dataset
contains a comprehensive record of over 3 million
grocery orders made by more than 200,000 users
across multiple retailers. It includes detailed
information on customer purchasing behavior, such as
the products ordered, the sequence of orders, product
categories, and reorder patterns. The procedure is
carried out to perform the analysis effectively to gain
the necessary insights for in E-commerce.
3.1.2 Data Preprocessing
Data preprocessing involved several critical steps to
prepare the data for predictive modeling. Initially,
missing values were identified and handled by either
removing incomplete entries or imputing values,
depending on the significance of the feature.
Categorical variables such as product names and
aisles were transformed using label encoding or one-
hot encoding to convert them into numerical formats.
3.1.3 Feature Engineering
A primary focus was on feature engineering, where
new variables were added to improve model accuracy,
including reorder frequency, duration between orders,
and product affinity ratings. These actions were
essential for enhancing the dataset's quality and
maximizing machine learning algorithms'
performance.
3.1.4 Model Selection
Complex patterns and temporal relationships are
captured by Deep Learning models like Artificial
Neural Networks (ANNs) and classic Machine
Learning methods like Logistic Regression, XGboost.
3.1.5 Model Design
The model design phase focuses on architecture,
using layers and activation functions suited to the
dataset. A specific model architecture, using a four-
layer structure with a ReLU activation function,
yielded superior accuracy.
3.1.6 Training
The dataset was separated into training and test sets in
order to evaluate the model's performance. Some of
the algorithms that were trained using features
generated from product data, client orders, and
reorder trends are XGboost, Artificial Neural
Networks, and logistic regression.
3.1.7 Evaluation
Performance is evaluated using criteria like as
accuracy, precision, recall, and F1-score. The efficacy
of the model is further validated by comparative
analysis. Businesses gain from the system by using it
to make better decisions, target customers more
effectively, and maximize marketing campaigns.
3.1.8 Hyper parameter Tuning
The act of adjusting a machine learning model's pre-
training parameters—which are not determined by the
data—is known as hyperparameter tuning. The
performance of the model is greatly influenced by
these variables, also known as hyperparameters.
(Baderiya, Chawan, et al. , 2018) Two common
tuning methods are Random Search and Grid Search.
While Random Search selects random combinations
of hyperparameters, Grid Search tests a preset set of
values for each hyperparameter in detail.
3.1.9 Evaluation
The results are then re-evaluated after tuning the
hyper parameters till the expected outcomes are
obtained.
4 RESULTS AND ANALYSIS
We used XGBoost, Logistic Regression, and
Artificial Neural Networks (ANN) to assess our
system's performance. To ensure data quality and
relevance to our analysis, these models were trained
on a carefully preprocessed dataset that underwent
intensive cleaning, normalization, and feature
engineering. To accomplish the goals, exploratory
data analysis is then carried out. The trained models
are assessed using metrics including recall, F1-score,
accuracy, precision, and ROC curves.
Accuracy: This is the proportion of accurately
predicted instances to all instances in a dataset. It is a
typical metric for assessing models of categorization.
The calculation of accuracy is as:
Accuracy =
Number of Correct Predictions
Total number of Predictions
∗100
Enhancing Customer Purchasing Behaviour Prediction in E- Commerce: A Deep Learning Perspective
651

A model is considered to have a high accuracy
score when its predictions closely match the actual
outcomes. (Sabbeh, 2018) However, it's important to
keep in mind that accuracy may not always be a
reliable indicator for unbalanced datasets; in these
Precision: This calculates the percentage of
accurate positive predictions among all the model’s
positive predictions
Precision =
𝑇𝑃
𝑇𝑃+𝐹𝑃
F1-Score: The F1-score, which is the harmonic
mean of recall and precision, is a single measure that
strikes a balance between the two.
𝐹1− score =2∗
Precision ∗ Recall
Precision + Recall
Recall: Recall, or sensitivity, is the proportion of
actual positive examples that the model correctly
predicted situations, other metrics like precision,
recall, or F1-score may provide greater insight into
the model's performance
Recall =
𝑇𝑃
𝑇𝑃 +𝐹𝑁
4.1 Logistic Regression Classifier
Logistic regression is a widely used statistical
technique for binary classification that predicts the
likelihood of an outcome based on one or more
predictor variables. (Saroja, Kannan, et al. , 2018) It
makes use of the logistic function, which converts a
linear feature combination into a likelihood score with
a range of 0 to 1.
Through the establishment of a threshold of 0.5,
the model divides the result into two categories. The
accuracy evaluation yielded a value of 78%. Class 0.0
is more accurately predicted by the model than class
1.0, as seen by its higher precision and recall. Since
class 1.0 has a lower recall, it is possible that there is
a problem with the model's performance for this class
or with class imbalance since the model is having a
trouble identifying instance of a class.
Table 1 Logistic Regression Classification report.
Class Precision Recall F1-score
0 0.80 0.96 0.87
1 0.66 0.26 0.37
Accurac
y
0.78
4.2 XGBoost Results
The gradient boosting framework for classification
and regression tasks is improved by the potent and
effective machine learning algorithm known as
XGBoost (Extreme Gradient Boosting). It works by
creating a group of decision trees, with each new tree
trying to fix the mistakes produced by the ones before
it. (Yunshengi, Qianqian, et al. , 2018). Two
important aspects of XGBoost are its parallel
processing capability, which speeds up model
training, and its regularization capabilities, which aid
in preventing overfitting.
To maximize performance, the method makes use
of sophisticated strategies like tree trimming,
handling missing values, and integrated cross-
validation. Large datasets and complicated issues are
particularly well suited for XGBoost, which is why it
is a popular choice for both real-world applications
and data science contests.
Because of its adaptability, practitioners can
achieve strong model performance and excellent
predicted accuracy by customizing it through
hyperparameter tuning. When evaluation the
accuracy, the obtained result is 74%. In comparison
to class 0.0, class 1.0 (the minority class) has a lower
F1 score of 0.37, indicating that the model performed
less well in class 1.0 prediction.
A lower score indicates difficulties with either
precision, recall, or both for class 1.0. Recall and
precision are combined into one measure, the F1
score. Based on its AUC score of 0.83, the model
seems to have a reasonable ability to differentiate
between the classes. While the general average F1
score of 0.60 indicates the overall performance across
both classes, the weighted average F1 score of 0.79
accounts for the distribution of course.
Table.2 XG Boost Classification report.
Class Precision Recall F1-score
0 0.97 0.74 0,84
1 0.24 0.77 0.37
Accuraca
y
0.74
The confusion matrix for the XGBoost model is as follows:
INCOFT 2025 - International Conference on Futuristic Technology
652
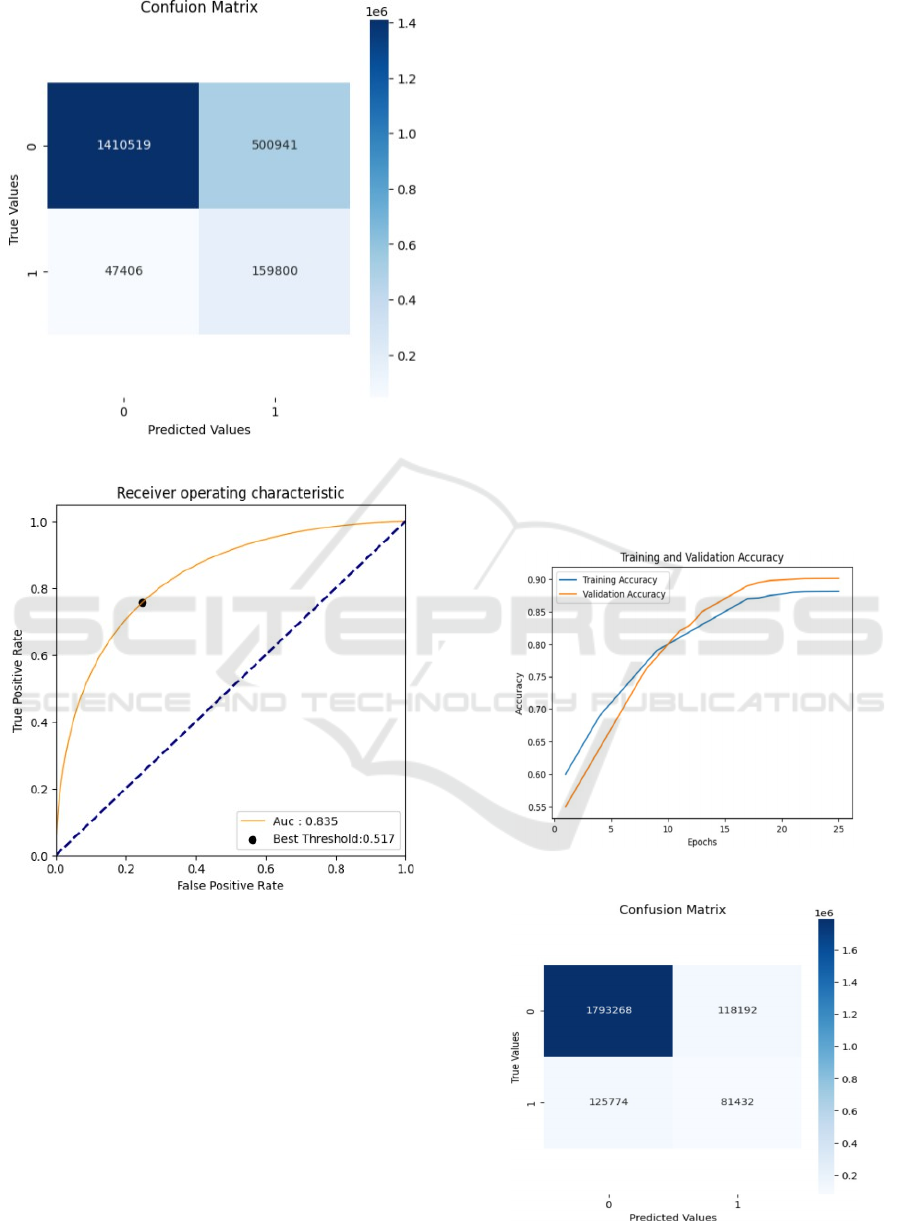
Figure 2: XGBoost Classification matrix.
Figure 3: XGBoost ROC Curve.
4.3 Artificial Neural Network ( ANN )
An Artificial neural network (ANN) classifier is a
computational model that resonates the human brain
and is designed to perform a range of classification
tasks. ANNs are highly helpful for classification
applications since they can learn complex and non-
linear correlations in data. (Sharma, Vidyalakshmi, et
al. , 2014) The network employs optimization
techniques like gradient descent during the learning
phase to minimize the discrepancy between the
expected and actual results.
This method, called backpropagation, is applied to
change wights. Backpropagation is the technique by
which artificial neural networks (ANNs) train by
modifying the weights of connections based on the
prediction error. This high level of accuracy reflects
the model’s strong overall performance. With an F1
Score of 0.89, the model appears to be able to handle
the majority class well, as evidenced by the balanced
precision and recall over the whole dataset.
The model performs well in class discrimination,
demonstrating a strong capacity to differentiate
between the two classes with an AUC-ROC score of
0.81. Macro Average F1 Score: At 0.66, this metric
provides an average performance measure across both
classes without considering class imbalance.
Weighted Average F1 Score: At 0.89, this metric
accounts for class distribution, reflecting better
performance when considering the number of
instances in each class. In our comparative analysis,
we benchmarked the performance of ANN model
against other machine learning techniques commonly
used in predictive analytics.
The following pictures shows the classification
matrix and the ROC curves for the ANN model:
Figure 4: Training and Validation Accuracy graph.
Figure 5: Classification matrix for ANN.
Enhancing Customer Purchasing Behaviour Prediction in E- Commerce: A Deep Learning Perspective
653
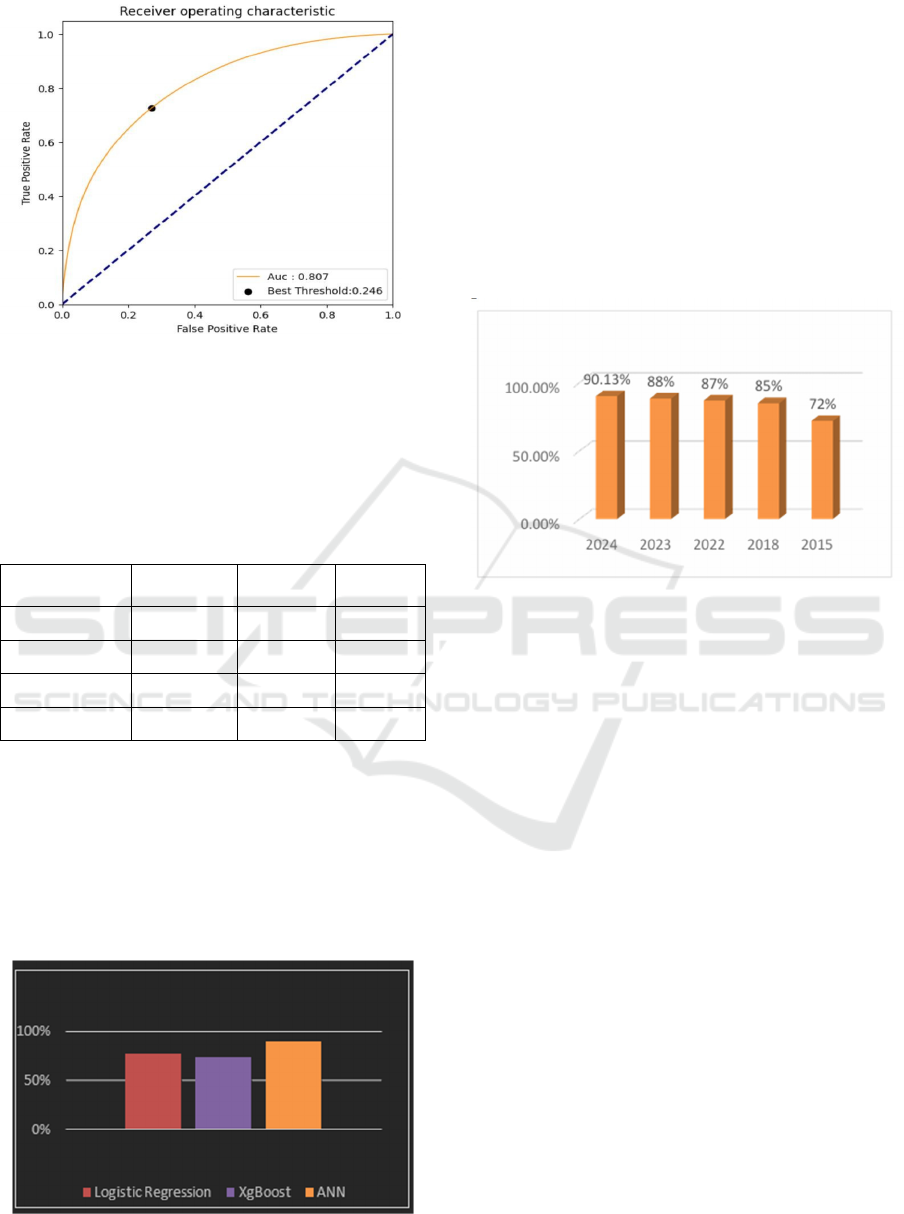
Figure 6 : ANN ROC Curve.
4.4 Comparison Table
The table below compares the F1-scores, recall,
accuracy, and precision of the models Logistic
Regression, XGBoost, and ANN
Table .3 Comparison Table.
Metrics/Model Logistic
Re
g
ression
XgBoost ANN
Accuracy 0.78 0.74 0.9013
Precision 0.70 0.61 0.89
Recall 0.55 0.70 0.78
F1-Score 0.47 0.47 0.76
The four main metrics—accuracy, precision,
recall, and F1- score—that are used to measure the
efficacy of Logistic Regression, XGBoost, and
Artificial Neural Networks (ANN) are compared in
the table. ANN outperforms both XGBoost (74%) and
Logistic Regression (78%) in terms of overall
performance, with the maximum accuracy of 90.13%.
Comparison graph between the accuracies of the
models Logistic Regression, XGBoost, ANN is
shown as below:
Figure 7 : Model comparison.
When comparing the models based on accuracy,
the Artificial Neural Network (ANN) classifier
demonstrates the highest performance, achieving an
accuracy of 90.13%, significantly outperforming both
Logistic Regression and XGBoost. Logistic
Regression, with an accuracy of 78%, performs better
than XGBoost, which scores 74%, but both fall short
of the ANN's capability. The substantial difference in
accuracy between ANN and the other models
suggests that ANN is more effective at capturing
complex patterns in the data, making it the most
suitable model for tasks requiring high predictive
performance.
Figure 8: Accuracy comparision with other researchers.
The Fig.8 shows the improvement in model
accuracy over time. In 2024, ANN achieved the
highest accuracy at 90.13%, followed by ensemble
stack algorithms in 2023 with 88%. In 2022, a
combination of classifiers like C4.5 and MLR reached
87%. Earlier models, such as MLPNN and Naive
Bayes in 2018, achieved 85%, while the Decision
Tree in 2015 had the lowest accuracy at 72%. The
trend highlights significant advancements in
predictive accuracy, with ANN and ensemble
methods at the forefront.
5 CONCLUSION
With an accuracy of 90.13%, our study shows how
powerful advanced deep learning techniques—
specifically, Artificial Neural Networks (ANNs) and
Recurrent Neural Networks (RNNs)—can be in
forecasting consumer purchase behavior in e-
commerce. This demonstrates how the models can
identify intricate patterns in data that traditional
approaches frequently fail to pick up on. Thorough
data pretreatment, hyperparameter tweaking, and
cross-validation were essential to this
accomplishment since they guaranteed clean, well
INCOFT 2025 - International Conference on Futuristic Technology
654

structured data and optimized model performance.
The models provide businesses with insightful
information that helps them make data-driven
decisions and customize marketing to increase sales
and improve consumer engagement. Subsequent
investigations could delve into sophisticated
structures such as Transformer models to enhance
performance, tackle scalability issues for real-time
implementation, and integrate ensemble learning
techniques. Predictive accuracy could be further
increased by incorporating additional data sources
and improving feature engineering.
REFERENCES
Sarkar M, Ayon E. H, Mia M.T, Ray R.K, Chowdhury M.S,
Ghosh B.P, Al Imran , M. Islam, M.T Tayaba and Puja
A.R, “Optimizing E-Commerce Profits: A
Comprehensive Machine Learning Framework for
Dynamic Pricing and Predicting Online Purchases,”
Journal of Computer Science and Technology Studies,
pp. 186-193, 2023.
Suresh Kumar S, Margala M and Siva Shankar S, “A Novel
Weight Optimized LSTM for dynamic pricing solutions
in e-commerce platforms based on customer buying
behaviour”.
Chaubey G , Gavhane P.R and Bisen D, “Customer
Purchasing Behavior prediction using machine learning
classification techniques,” J Ambient Intel Human
Comput , pp. 16133-16157, 2014.
P. Vankhede and S. Kumar, “Predictive Analytics for
Website User Behavior Analysis,” in IEEE
International Students Conference on Electrical,
Electronics and Computer Science (SCEECS), Bhopal,
India, 2024.
Harsh Valecha, Aparna Varma and Ishita Khare,
“Prediction of Consumer Behaviour Using Random
Forest Algorithm,” in 5th IEEE Uttar Pradesh Section
International Conference on Electrical, Electronics and
Computer Engineering (UPCON), 2018.
Mr. Shrey Harsh Baderiya and Prof. Pramila M. Chawan,
“Customer Buying Prediction Using Machine Learning
Techniques: A Survey,” International Research Journal
of Engineering and Technology (IRJET), vol. 05, no.
10, 2018.
Sahar F. Sabbeh, “Machine Learning Techniques for
Customer Retention: A Comparative Study,”
International Journal of Advanced Computer Science
and Applications, vol. 9, 2018.
M.N. Saroja, S. Kannan and K.R. Baskaran, “Analysing the
Purchase Behavior of a Customer for Improving the
Sales of a Product,” International Journal of Recent
Technology and Engineering (IJRTE), vol. 7, no. 4S,
pp. 2277-3878, 2018.
Ge Yunshengi, Zhang Qianqian and Kong Jie, “Research on
the Prediction of User behaviour based on neural
network,” in ICIIP, 2018.
Pooja Sharma, Vidyalakshmi Nair and Amalendu Jyotishi,
“Patterns of Online Grocery Shopping in India: An
Empirical Study,” in CONIAAC, Amritapuri India,
2014.
Enhancing Customer Purchasing Behaviour Prediction in E- Commerce: A Deep Learning Perspective
655
