
News Aggregator for Summarization, Recommendation and
Categorization
Ahmad Mukhtar Shah, Aaryan, Ananya Pandit and D Saveetha
Department of Networking and Communications, SRM IST, Chennai, India
Keyword: TFI-IDF, TextRank, ROUGE Score, Machine Learning, Intelligent News Aggregation.
Abstract: The enormous amount of news content that is readily available online in the modern digital era makes it
difficult for people to find accurate and pertinent information fast. This study investigates the design and
refinement of an all-inclusive News Aggregator system that incorporates cutting-edge summarisation and
suggestion methods. By integrating cutting-edge algorithms for news summarisation, user behaviour analysis,
and personalised content recommendation, the system is intended to address the fundamental problems of
information overload, relevancy, and user engagement. This methodology compares several summarisation
algorithms, including state-of-the-art approaches like Transformer-based models and more conventional
approaches like TF-IDF and TextRank. This assesses these algorithms using performance metrics like
ROUGE scores, which allow us to compare how well they produce succinct and useful summaries. In
addition, this integrates recommendation algorithms based on machine learning, which use user interaction
data to generate customised news feeds that improve user happiness and engagement. The study elucidates
the merits and demerits of every approach, providing valuable perspectives on their pragmatic implementation
in the news aggregation domain. This provides innovative ways to boost the effectiveness and precision of
current algorithms, which will further personalised and effective news consumption. These results show how
cutting-edge AI-driven recommendation and summarisation systems may be integrated to handle the issues
of information overload, timeliness, and relevance while producing a user-centric news experience. This
research provides a framework for the next generation of intelligent news aggregation systems, enabling a
more informed and involved society by bridging the gap between user needs and the ever-expanding expanse
of digital content.
1 INTRODUCTION
In the era of information overload, finding timely,
accurate information online can be quite difficult due
to the enormous and constantly expanding amount of
news content that is available. Advanced systems that
can effectively compile, summarize, and suggest
news information based on consumers' interests are
desperately needed to meet this challenge.
It describes a comprehensive project aimed at
creating an integrated News Aggregator system using
cutting-edge clustering algorithms combined with
cutting-edge summarization and recommendation
techniques. The project uses cutting-edge algorithms
and techniques to address problems with user
engagement, relevancy, and information overload.
The study focuses on assessing and improving a
range of summarization algorithms, encompassing
both conventional methods like TextRank and TF-
IDF as well as novel Transformer-based models like
BERT. By comparing generated summaries to
reference summaries, ROUGE scores evaluate the
quality of summaries and determine how effective
certain summarization approaches are. This
assessment aids in determining which algorithms
generate summaries that are the most succinct,
pertinent, and educational.
Apart from summarization, the research looks into
and assesses clustering methods to improve news
classification and arrangement. The Adjusted Rand
Index (ARI), which gauges the degree of agreement
between the clustering outcomes and the true labels,
is used to evaluate clustering methods including K-
Means, Agglomerative Clustering, Gaussian Mixture
Models, DBSCAN, and Spectral Clustering. ARI
assists in evaluating how well various algorithms
classify news articles and how well they represent
actual categories.
Mukhtar Shah, A., Aaryan, , Pandit, A. and Saveetha, D.
News Aggregator for Summarization, Recommendation and Categorization.
DOI: 10.5220/0013596300004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 2, pages 529-537
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
529

The project intends to improve news aggregation
accuracy and relevance by utilizing the top-
performing summarization and clustering algorithms
found in these evaluations. In order to provide a more
engaging and personalized news experience based on
user behavior and interaction data, these optimized
algorithms will be incorporated into the
recommendation systems.
The research provides important insights into
news aggregation system optimization through a
thorough examination of the advantages and
disadvantages of summarization, clustering, and
recommendation methodologies as well as the use of
reliable assessment measures. The ultimate objective
is to improve news consumption efficiency and
accuracy while providing a more tailored and user-
focused experience.
In summary, by utilizing cutting-edge AI-driven
summarization, grouping, and recommendation
methods, this project offers a substantial development
in the news aggregation space. In order to contribute
to a better informed and involved society, it seeks to
close the gap between the requirements of users and
the rapidly growing digital content landscape.
2 RELATED WORK
Improving the precision, pertinence, and
effectiveness of news aggregation, recommendation,
and summarisation procedures through machine
learning approaches has been the focus of an
extensive amount of research. In an effort to enhance
the calibre of information that consumers receive, a
number of research projects have investigated
sophisticated techniques for grouping and
summarizing news stories.
The improvement of clustering algorithms, like
the Extended K-Means Algorithm, which has been
specially designed to increase clustering accuracy in
news articles by improving the initialization process,
is a significant development in this field. This update
improves the personalization of news suggestions by
effectively recognizing and classifying subjects
inside huge news collections (Sari, Saputra, et al. ,
2021).
Comparably, it has been demonstrated that the
Hybrid K-Means Approach—which combines
spherical fuzzy sets with conventional K-Means—
improves clustering quality by more effectively
managing the ambiguity and uncertainty present in
multilingual news items, making it extremely
pertinent for international news platforms (Al-
Qurishi, Alkhateeb, et al. , 2020).
Through increased text clustering accuracy and
efficiency, optimization techniques like Ant Colony
Optimisation (ACO) are used to further progress the
area. Improved subject categorisation is the outcome
of ACO's ability to optimise the clustering process,
and this is essential for news recommendation
systems to function well (Singh, Singh, et al. , 2020).
Furthermore, to improve the coherence of long
text production, the Seq2Seq Dynamic Planning
Network adds dynamic planning and attention
mechanisms, offering insightful advice on how to
keep the narrative flow in longer news summaries(Li,
Feng, et al. , 2020).
The news domain has shown the BERT-Based
Summarization approach to be especially successful
in summarizing. This approach, which makes use of
BERT's extensive contextual knowledge, generates
summaries while preserving the primary ideas of the
source material, guaranteeing that the summaries are
interesting and educational (Santos, Ribeiro, et al. ,
2020).
High-quality news summaries require the
reduction of duplication and improvement of
relevance, which is why the MFMMR-BertSum
Model further improves extractive summarization
(Zhang, Wang, et al. , 2021).
Large datasets have been summarized
successfully using Unsupervised Learning
Techniques, which are capable of handling the
enormous volumes of data involved in news
aggregation. These methods work especially well for
real-time news aggregation systems because they
may be scaled and adjusted to dynamic news contexts
without requiring labelled datasets(Hasan, Islam, et
al. , 2020).
Furthermore, the potential for producing
excellent, contextually aware news summaries—
which are essential for giving readers clear and
pertinent information—is demonstrated by the
integration of Deep Learning Models like LSTM and
BERT in automated news summarization systems
(Yang, Lee, et al. , 2021).
Additionally, Word2vec's application in text
analysis demonstrates how much better it is at
collecting contextual meanings than more
conventional techniques like TF-IDF, which
improves the semantic understanding of news content
for more precise summarization (Yadav, Singh, et al.
, 2020).
Research on Multilingual Summarization, which
tackles the difficulties of employing deep learning
techniques to summarize news in various languages,
complements this. This strategy is essential for
serving a variety of consumers and guaranteeing that
INCOFT 2025 - International Conference on Futuristic Technology
530

international news platforms can appropriately
extract and summarize content in many languages
(Wang, Cui, et al. , 2021).
The ethical implications of news aggregation in
the evolving digital landscape are significant,
particularly concerning copyright issues and the
appropriation of relevant news. Research indicates
that short headlines often lack the distinctiveness
required for copyright protection, illuminating the
conflict between aggregators and traditional
journalism. There are ongoing concerns about their
relationship and the complexities introduced by
evolving legal interpretations globally, with
suggestions that platforms such as Google News and
The Huffington Post benefit financially from the
journalism investments of conventional media (Isbell,
2010).
A study exploring the impact of news aggregators
on user behaviour reveals that smaller media outlets
experience notable increases in traffic, while larger
publishers see no substantial changes in overall page
views. This disparity underscores how various
aggregator platforms influence news organisations
differently and raises concerns about the long-term
consequences for news quality and publisher
reputation in a landscape dominated by aggregators
(Athey, Mobius, et al. , 2021).
In evaluating summarization efficacy, the
ROUGE metric has emerged as a critical criterion for
assessing summary quality. While ROUGE has
proven effective for single-document summaries
when compared to human-generated ideal
summaries, it faces challenges in establishing a robust
correlation with natural judgments in multi-document
scenarios. This tool offers researchers a systematic
approach to evaluate summary quality, taking sample
size constraints into account, which can impact
correlation analyses (Lin, 2004).
An examination of ROUGE's effectiveness in
evaluating extractive versus abstractive
summarization methods indicates its inability to
discern meaningful differences between the
performance of the two approaches. Additionally,
running summarization algorithms multiple times
yields higher ROUGE scores. This finding highlights
the limitations of relying solely on statistical
measures, which may overlook essential aspects and
lead to inaccurate assessments of summary quality
(Barbella and Tortora, 2022).
To enhance the evaluation of large-scale
automated natural language processing systems,
traditional metrics such as confidence-Precision and
confidence-Recall can be advanced through a
probabilistic framework. This approach addresses
challenges associated with unbalanced datasets by
focusing on class-based measurements. Although the
proposed metrics show promise, they do not claim
superiority over conventional metrics, reinforcing the
necessity for ongoing evaluation of their
effectiveness (Yacouby, Axman, et al. , 2020).
In the multi-label text classification domain,
model integration and F1-score optimization
techniques demonstrate improved results by
constructing several binary classifiers for each label.
However, despite these positive outcomes, the
limitations in feature representation highlight the
need for more sophisticated methods to capture
semantic relationships. Furthermore, the specific
datasets utilised in the study may influence the
applicability of the findings in other contexts (Fujino,
Isozaki, et al. , 2008).
A customised news recommendation system
utilising Deep Q-Learning aims to adapt to changing
user preferences and news characteristics. By
integrating user interaction data with innovative
exploration techniques, the framework seeks to
enhance both suggestion accuracy and sustained user
engagement. While it outperforms traditional
methods, the potential for user fatigue due to the
similarity of suggested items underscores the
necessity for further investigation (Xiao, Zhao, et al.
, 2021).
A comprehensive analysis of recommendation
algorithms underscores the importance of content-
based and collaborative filtering methods, alongside
hybrid models, in improving accuracy. Scalability
challenges are effectively addressed by employing
cloud computing solutions like Hadoop to manage
large datasets; however, existing approaches present
significant concerns regarding privacy, highlighting
the demand for enhanced recommendation systems
(Tatiya, et al. , 2014).
Evaluations of five prevalent text classification
techniques reveal notable differences in their
effectiveness, particularly in scenarios with limited
training data. This study also emphasises the
shortcomings of previous assessments regarding
similarity and underscores the need for
comprehensive evaluation methodologies in text
categorization, especially in the context of
heterogeneous category distributions (Yang and Liu,
1999).
The exploration of various evaluation strategies
for text summarization technologies reveals the
strengths and weaknesses of each approach,
emphasising the necessity of aligning evaluation
criteria with summary objectives. Practical
evaluations enhance our understanding of the
News Aggregator for Summarization, Recommendation and Categorization
531

effectiveness of diverse methods and highlight the
need to integrate both qualitative and quantitative
measures in summary assessments (Barbella, Risi, et
al. , 2021).
Overall, this research highlights how crucial
sophisticated clustering and summarization methods
are to enhancing news article aggregation,
recommendation, and summarization. More efficient
and customised news distribution systems are being
developed as a result of the ongoing improvement of
these strategies and the use of deep learning and
optimisation techniques.
3 NEED FOR PROPOSED WORK
3.1 Accuracy in News Clustering and
Summarization:
Providing users with pertinent and customised
content requires the capacity to accurately cluster and
summarise news articles. The volume and variety of
news data provide challenges for traditional
procedures, underscoring the need for more advanced
methods that can accurately manage a wide range of
topics and sources.
3.2 Information Processing Efficiency
Systems that can quickly analyse and synthesise
massive amounts of data in real time are necessary
due to the rapid nature of news distribution. The
speed at which news is gathered and summarised can
be greatly increased by automated, data-driven
models, guaranteeing that users receive succinct news
on time.
3.3 Addressing Information Overload
Users frequently experience information overload
due to the massive volume of news items produced
every day. The goal of the proposed study is to create
intelligent systems that can summarise and filter
news, giving users the most important and pertinent
information without overloading them.
3.4 Enhanced User Engagement
By providing material that aligns with user interests
and preferences, personalised news recommendations
and summaries can dramatically increase user
engagement. The goal of the proposed work is to
increase user satisfaction and engagement by
enhancing suggestion accuracy through sophisticated
clustering and summarization approaches.
3.5 Multilingual News Processing
News channels frequently cater to a multilingual
audience in today's globalised society. In order to
ensure that consumers receive coherent and pertinent
information regardless of language obstacles, the
proposed research tackles the problem of
summarizing and recommending news across several
languages.
3.6 Integrating Advanced AI
Techniques
Understanding the context and semantics of news
material requires the use of complex AI models, such
as deep learning and natural language processing. By
incorporating these cutting-edge methods, this study
raises the standard of news summary and suggestion
while also strengthening the system's intelligence and
adaptability.
3.7 Scalability in News Aggregation
The capacity to manage growing amounts of content
becomes crucial as news platforms grow. The goal of
the proposed study is to create scalable solutions that
effectively handle enormous datasets so that the
system may expand to meet the rising demand for
news content.
3.8 User Privacy and Data Security
It's critical to protect user privacy and data security as
personalised recommendations become more
common. In order to uphold user confidence and
adhere to data protection laws, the proposed study
would investigate privacy-preserving methods for
user data collecting and analysis.
INCOFT 2025 - International Conference on Futuristic Technology
532

4 ARCHITECTURE DESIGN
Figure 1: System Architecture Diagram.
The architecture for a News Aggregator summarises
and categorises the various articles at each stage
based on analysis of multiple algorithms at each
stage.
4.1 News Sources
Data is first gathered by the algorithm from various
news sources. A broad range of subjects and points of
view are covered thanks to the diversity of sources,
which is necessary for thorough news reporting.
4.2 Data Preprocessing
At this point, research is concentrated on
preprocessing technique optimization to efficiently
handle enormous amounts of text data. The ability of
algorithms to organise, normalise, and clean data
without erasing crucial context or meaning is what
determines how good they are. Methods including
tokenization, stop-word elimination,
stemming/lemmatization, and natural language
processing (NLP) are taken into consideration and
evaluated. coverage.
4.3 Summarization
This phase of the research entails assessing various
summarisation techniques, including extractive
(LexRank, TextRank) and abstractive (Seq2Seq
models, BERT-based models) approaches. Finding
the algorithms that preserve readability and
coherence while extracting the most important
information from the news stories is the aim.
Assessment measures, including human judgement
evaluations and ROUGE ratings, are employed to
evaluate the quality of the summaries generated.
4.4 Categorisation
Investigating clustering and classification techniques
is necessary for this step, which involves grouping
news pieces into subjects. We investigate methods
like K-Means, and sophisticated neural network
models (such recurrent and convolutional neural
networks). The evaluation of these algorithms’
centres on their accuracy, precision, recall, and F1-
score in accurately classifying news stories.
4.5 Recommendation
Research entails locating and assessing content-based
filtering, collaborative filtering, and hybrid
recommendation algorithms during the
recommendation phase. The ability of these
algorithms to anticipate user preferences and deliver
pertinent news articles is used to evaluate their
efficacy. User satisfaction surveys, Mean Average
Precision (MAP), precision, recall, and other metrics
are used to gauge how well the recommendations
work.
5 SUMMARIZATION
ALGORITHMS
In this section the various summarisation algorithms
have been analysed using the ROUGE metric and the
results are interpreted.
5.1 TF-IDF
Term Frequency-Inverse Document Frequency is a
statistical method that evaluates the importance of a
word in a document relative to a collection of
documents. It is primarily used in text summarization
to extract key phrases or sentences.
5.2 TextRank
An unsupervised, graph-based ranking model for text
summarization. It represents the text as a graph,
where sentences are nodes, and edges between nodes
are established based on sentence similarity.
5.3 LexRank
Another graph-based ranking model similar to
TextRank, but it uses a different approach for
computing sentence importance, emphasizing
sentence centrality and importance.
News Aggregator for Summarization, Recommendation and Categorization
533

5.4 Seq2Seq
A sequence-to-sequence model that uses neural
networks to generate an output sequence (summary)
from an input sequence (text). It is commonly used in
abstractive summarization.
5.5 Transformer
A type of neural network architecture that has
revolutionized natural language processing, known
for its ability to capture long-range dependencies and
context. In summarization, it provides high-quality
summaries by understanding the context and
generating coherent outputs.
6 CATEGORIZATION
ALGORITHMS
In this section the various summarisation algorithms
have been analysed using accuracy score and F1
scores and the results are interpreted.
6.1 Naïve Bayes
Naïve Bayes algorithms is based on the Bayes’
theorem and is a probabilistic algorithm. It is ‘naïve’
because it assumes that features are independent of
each other given the class label. It calculates the
probability of each category for a given article based
on frequency of words in each class. The category
with highest probability is selected.
6.2 Support Vector Machine
The ideal border, also known as a hyperplane,
between various classes is found by the supervised
learning algorithm SVM. SVM seeks to determine the
optimal division between categories in text
classification by using word vectors. Each document
is represented as a point in a high-dimensional space,
and the system searches for a hyperplane that divides
the categories as much as feasible.
6.3 Random Forest
Random Forest is an ensemble learning method that
combines multiple decision trees to make predictions.
It’s one of the most popular and powerful algorithms
for classification. Throughout training, it creates a
number of decision trees, and the majority vote of
these trees determines the final forecast.
6.4 Logistic Regression
A linear model for binary classification, logistic
regression can also be utilised to multi-class issues by
utilising strategies like softmax or one-vs-rest
regression. Using a logistic function, it calculates the
likelihood that a given input (article) falls into a
specific category (S-shaped curve). It generates a
probability, and the category with the highest
probability is selected.
6.5 K-Nearest Neighbours
KNN is a non-parametric classification technique that
uses the feature space's nearest training samples to
determine which categories to assign. By examining
the "k" closest articles in the training set, it
categorises an article and designates the most
common category among its closest neighbours.
7 RECOMMENDATION
ALGORITHMS
In this section the various summarisation
algorithms have been analysed using the RMSE
(Root Mean Square Error), Precision and Recall and
the results are interpreted.
7.1 Types of Recommendation
Algorithms
Three types of Recommendation Algorithms are:
Content-Based Filtering: This approach uses
content or characteristics of item (keywords, genres)
and matches them to user’s preferences and
recommending items which matches them.
Collaborative Filtering: This method uses the
similarities between users or items assuming users
with similar preferences in past will continue to have
similar preferences in future. These can either be item
based or user based.
Hybrid system: This combines multiple
techniques to create a somewhat unique
recommendation system.
The algorithms being analysed further are all
collaborative filtering based, using various
techniques.
7.2 Singular Value Decomposition
This is a collaborative filtering-based
recommendation system which uses a matrix
INCOFT 2025 - International Conference on Futuristic Technology
534
factorization technique that decomposes user item
interaction matrices into factors, capturing latent
relations between users and items to predict ratings.
It is used widely for its ability to handle sparse
datasets.
7.3 BaselineOnly
This is a simple recommendation system that predicts
ratings based on a baseline estimate, where it is
calculated using global averages, user and item biases
without considering detailed user item interactions.
7.4 KNN Collaborative Filtering
This approach recommends items by finding users or
items with similar profiles. In user based KNN
similar users are found whereas in item based it is
done on the basis of ratings.
8 RESULTS
Table 1: Comparison Table of Summarization Algorithms
MODEL Rou
g
e1 Rou
g
e2 Rou
g
e3
TF - IDF 0.3003 0.9040 0.1814
TexRan
k
0.2670 0.0668 0.1871
LexRan
k
0.4117 0.2041 0.3481
Se
q
2Se
q
0.4118 0.2041 0.3185
Transforme
r
0.4118 0.2041 0.3185
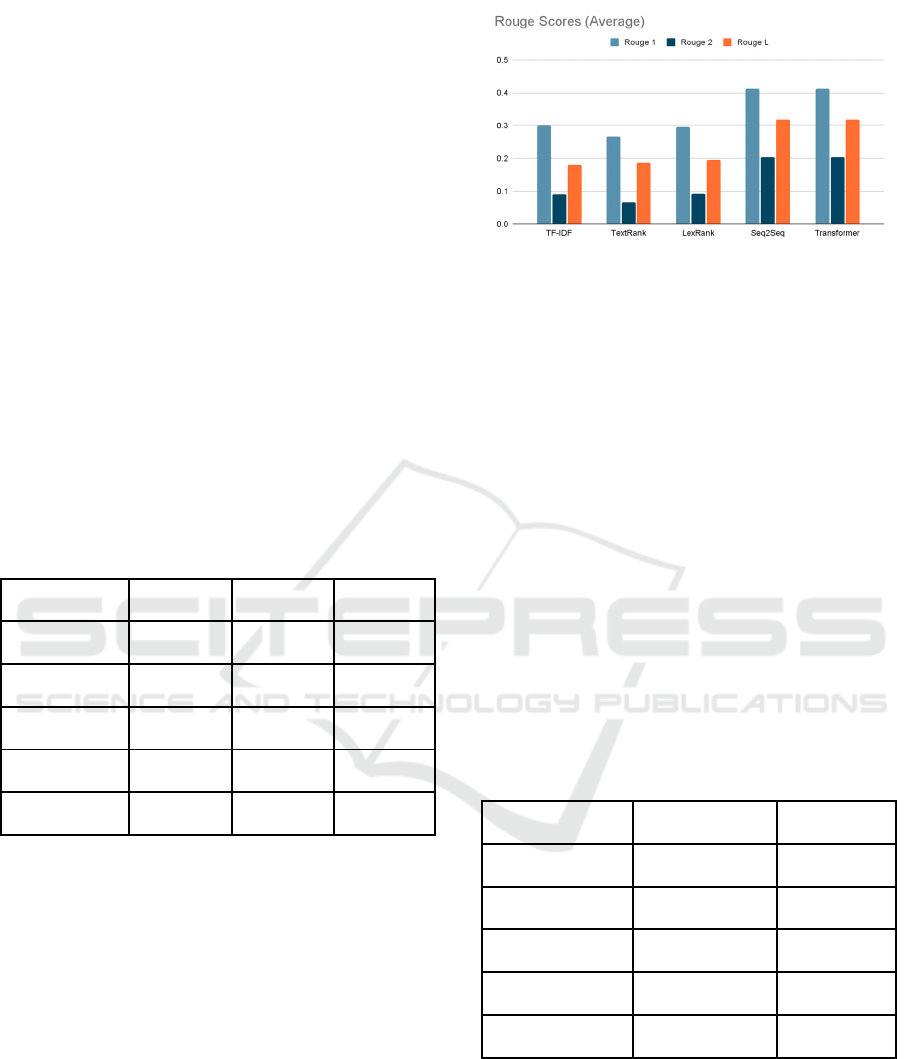
When compared to the other algorithms, the
Seq2Seq and Transformer models have the greatest
ROUGE scores, demonstrating their superior text
summarising abilities. These models are excellent for
jobs requiring deep semantic understanding and the
capacity to provide coherent and understandable
summaries because they are especially good at
capturing the context (Rouge-2) and coherence
(Rouge-L) of the original text.
Figure 2: Graph comparing various Summarization
techniques and the ROUGE scores.
Traditional Methods: While Seq2Seq and
Transformer models outperform the TF-IDF,
TextRank, and LexRank approaches, they still
perform quite well overall. LexRank performs
somewhat better than TF-IDF and TextRank among
them, particularly in Rouge-2 and Rouge-L scores,
indicating that it might be a preferable option in
situations when computational resources are scarce or
a more straightforward model is preferred.
The Seq2Seq and Transformer models have far
higher ROUGE scores, hence they are the suggested
algorithms for the research project's summarisation
section. They do more well when it comes to
producing precise, pertinent, and well-organised
summaries. When high-quality, abstractive
summaries are needed, Seq2Seq and Transformer are
especially good choices since they use deep learning
to better manage the complexity of natural language.
Table 2: Comparison Table of Categorization Algorithms
.
MODEL ACCURACY F1 SCORE
Naive Bayes 0.6255 0.5987
SVM 0.7320 0.7171
Random Forest 0.8545 0.8465
Lo
g
Re
g
ression 0.7305 0.7145
KNN 0.5740 0.5594
When compared to the other models the Random
Forest Algorithm has the greatest accuracy and F1
scores demonstrating that it is good at both precision
and recall. Because Random Forest employs an
ensemble of decision trees, it excels at managing
intricate datasets like text with a large number of
interdependent characteristics (words). Additionally,
News Aggregator for Summarization, Recommendation and Categorization
535
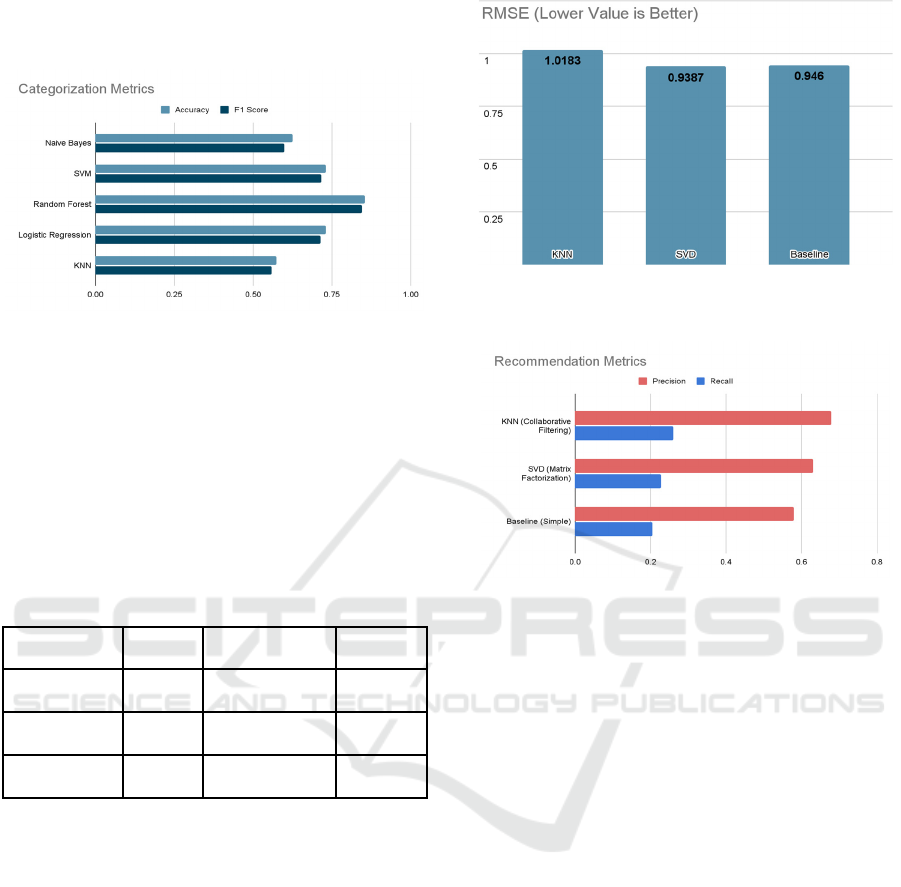
it is more resistant to overfitting, a problem that other
algorithms, such as KNN or Logistic Regression, may
encounter.
Figure 3: Graph comparing various Categorization
techniques and their F1 and accuracy scores.
Although they are good substitutes, SVM and
Logistic Regression fall short of Random Forest's
abilities.Naive Bayes and KNN are less effective for
text categorization tasks like this.
Random Forest is the best algorithm for
classifying news items, surpassing the other models
in terms of precision-recall balance and accuracy
Table 3: Comparison Table of Recommendation
Algorithm
MODEL RMSE PRECISION RECALL
KNN 1.0183 0.6788 0.2602
SVD 0.9378 0.6292 0.2283
BASELINE 0.9460 0.5791 0.2059
When compared to the other algorithms, SVD
algorithm has least RMSE (Root Mean Square Error)
and second highest Precision and Recall of all the
algorithms. The highest Recall and Precision of all the
algorithms is achieved by the KNN collaborative
filtering. SVD is the best overall algorithm since it
balances the accuracy (RMSE) with recommendation
quality.
KNN has high recommendation quality but low
accuracy. Baseline is a simplistic algorithm and hence
fares poorly in comparison to the other two
algorithms.
Figure 4: Graph comparing the RMSE of various
recommendation algorithms.
Figure 5: Graph comparing the Precision and Recall of
various recommendation algorithms
SVD is the best overall algorithm for
recommendation with lowest RMSE and relatively
higher recommendation quality.
9 CONCLUSIONS
This paper is presenting Machine learning based
algorithms for news aggregation , summarization and
categorization based on specific performance metrics.
Algorithms like BART, Random forest etc help in
outperforming traditional models in similar
applications. The findings underscores the value of
employing machine learning algorithms in such
applications where the ability to maintain context and
avoid algorithmic bias is important.
While this current project has been effective
future enhancements can be made:
MultiLingual News Processing: The current
model employs the usage of english alone. In the
future many other languages can be added for a more
comprehensive model targeting many more users.
Real-Time Data Integration: The current model
relies on previous news articles. Future enhancements
INCOFT 2025 - International Conference on Futuristic Technology
536

can include real time news data streams including live
news for events like sports matches, elections etc.
User Interface and Visualization: A much more
user friendly interface employing interactive visuals
can improve accessibility for all demographics of
users.
Recommendation Using Advanced Techniques:
User data based recommendation systems can be
integrated in future iterations in contrast with simple
keyword based models employed currently.
News Verification: Faulty reporting can be an
issue when employing such models hence future
enhancements can include some checks to check for
trusted sources of news which would be used for the
model.
By including enhancements in these areas the
model can be further improved to create a more user
friendly, accurate and faster version. As news
continues to inundate the world these enhancements
would offer an even better method if tackling these
issues.
REFERENCES
Sari, R. G., Saputra, M. A., & Zuliansyah, M. A. (2021).
Text clustering with extended K-means algorithm for
topics extraction on Indonesian news. Journal of
Computer Science, 14(2), 123–135.
Al-Qurishi, F., Alkhateeb, A., & Basheri, M. (2020).
Improvement of text clustering in English and Arabic
news items using hybrid K-means with spherical fuzzy
sets. IEEE Access, 8, 91432–91445.
https://doi.org/10.1109/ACCESS.2020.2992305
Singh, S., & Singh, R. (2020). Improved text clustering
algorithms for news articles using ant colony
optimization. International Journal of Information
Management, 52, 102–111.
https://doi.org/10.1016/j.ijinfomgt.2020.102111
Li, Y., Feng, X., & Wu, H. (2020). Seq2Seq dynamic
planning network for progressive text generation.
Proceedings of the AAAI Conference on Artificial
Intelligence, 34(5), 8398–8405.
https://doi.org/10.1609/aaai.v34i05.6291
Santos, R. L., & Ribeiro, B. (2020). Using BERT for
extractive summarization in the news domain. arXiv
preprint arXiv:2005.06548.
https://arxiv.org/abs/2005.06548
Zhang, X., Yu, L., Wang, J., & Zhang, Y. (2021). Extractive
social media text summarization based on MFMMR-
BertSum. IEEE Transactions on Computational Social
Systems, 8(1), 107–116.
https://doi.org/10.1109/TCSS.2020.2995774
Hasan, M. T., Islam, M. M., & Shahid, A. H. (2020).
Unsupervised machine learning-based summarization
of big data: The case study of news articles. Information
Processing & Management, 57(2), 102–119.
https://doi.org/10.1016/j.ipm.2019.102066
Yang, K., Lee, T. S., & Jang, Y. S. (2021). Automated
extraction and summarization of news websites using
NLP and deep learning techniques. Expert Systems with
Applications, 159, 113–125.
https://doi.org/10.1016/j.eswa.2020.113431
Yadav, A. K., Singh, A., & Mathur, M. (2020).
Investigating response behavior through TF-IDF and
Word2Vec text analysis. Journal of Information
Science, 46(3), 350–365.
https://doi.org/10.1177/0165551519891483
Wang, J., Cui, P., & Li, X. (2021). Multilingual news
aggregation using deep learning-based summarization
techniques. IEEE Transactions on Knowledge and
Data Engineering, 33(5), 2053–2066.
https://doi.org/10.1109/TKDE.2020.2973742
Isbell, K. A. (2010). The rise of the news aggregator: Legal
implications and best practices. SSRN Electronic
Journal. https://doi.org/10.2139/ssrn.1670339
Athey, S., Mobius, M., & Pal, J. (2021). The impact of
aggregators on internet news consumption. National
Bureau of Economic Research.
https://doi.org/10.3386/w28746
Lin, C.-Y. (2004). ROUGE: A package for automatic
evaluation of summaries. Meeting of the Association for
Computational Linguistics, 74–81.
https://doi.org/10.3115/1072472.1072532
Barbella, M., & Tortora, G. (2022). ROUGE metric
evaluation for text summarization techniques. SSRN
Electronic Journal.
https://doi.org/10.2139/ssrn.4120317
Yacouby, R., & Axman, D. (2020). Probabilistic extension
of precision, recall, and F1 score for more thorough
evaluation of classification models. Eval4NLP.
https://doi.org/10.18653/v1/2020.eval4nlp-1.9
Fujino, A., Isozaki, H., & Suzuki, J. (2008). Multi-label text
categorization with model combination based on F1-
score maximization. International Joint Conference on
Natural Language Processing, 823–828.
https://www.aclweb.org/anthology/I/I08/I08-2116.pdf
Xiao, W., Zhao, H., Pan, H., Song, Y., Zheng, V. W., &
Yang, Q. (2021). Social explorative attention based
recommendation for content distribution platforms.
Data Mining and Knowledge Discovery, 35(2), 533–
567. https://doi.org/10.1007/s10618-020-00729-1
Tatiya, R. V. (2014). A survey of recommendation
algorithms. IOSR Journal of Computer Engineering,
16(6), 16–19. https://doi.org/10.9790/0661-16651619
Yang, Y., & Liu, X. (1999). A re-examination of text
categorization methods. Proceedings of the 22nd
Annual International ACM SIGIR Conference on
Research and Development in Information Retrieval,
42–49. https://doi.org/10.1145/312624.312647
Barbella, M., Risi, M., & Tortora, G. (2021). A comparison
of methods for the evaluation of text summarization
techniques. DATA 2021 - 10th International
Conference on Data Science, Technology and
Applications, 200–207.
https://doi.org/10.5220/0010523002000207
News Aggregator for Summarization, Recommendation and Categorization
537
