
A Role of Machine Learning Algorithms for Demand Based Netflix
Recommendation System
Tejaswini Bhoye
1
, Aishwarya Mane
2
, Vandana Navale
3
, Sangeeta Mohapatra
3
,
Sandeep Chitalkar
4
, Vishal Borate
5 a
and Yogesh Mali
6 b
1
Department of Computer Engineering, Marathwada Mitramandal Institute of Technology, Lohegaon, Pune, India
2
Department of Computer Engineering, Marathwada Mitramandal College of Engineering, Pune, India
3
Department of Computer Engineering, Ajeenkya DY Patil School of Engineering, Lohegaon, Pune, India
4
Department of Artificial Intelligence and Data Science, Dr. D.Y Patil Institute of Technology, Pimpri, Pune, India
5
Department of Computer Engineering, Dr. D. Y. Patil College of Engineering and Innovation, Talegaon, Pune, India
6
School of Engineering, Ajeenkya DY Patil University Lohegaon, Pune, India
Keywords: Machine Learning, Collaborative Filtering, Content-based Filtering, SVD, Personalization, User Engagement,
Streaming Platforms.
Abstract: The rise of streaming services, personalized content recommendation is one of the critical features enhancing
user engagement and retention. This paper presents a comprehensive analysis of the Netflix recommendation
system, which bases its predictions on machine learning and collaborative filtering from behavioural data
about the viewers’ preferences. It combines the two techniques into a hybrid approach to create personalized
recommendations. It further honed the system using the technique of Singular Value Decomposition with
enhanced accuracy for recommendations relevant to the viewer. This is realized by dynamism whereby it is
possible to learn through the models that the viewers’ tastes change over time by feature engineering and
techniques based on deep learning. Hence, there is alignment with actual viewer preferences at the more
precise level. This research demonstrates and depicts how these methodologies efficiently work toward
improving viewer satisfaction, and therefore significantly contribute towards the competitive advantage of a
company such as Netflix, within the very competitive streaming market. The study provides prime ideas and
guidelines for progress into future advancement regarding the recommendation system in streaming platforms.
1 INTRODUCTION
In the streaming industry, one change in user
experience due to machine learning is the Netflix
recommendation system. This uses content-based
filtering, collaborative filtering, and hybrid models to
make recommendations tailored from large datasets
of viewing tastes and habits. Recent research through
deep learning algorithms helps in discovering
complex usage patterns, and hence adaptation
algorithms need to be continually updated based on
the analysis for enhancing users’ engagement and
reducing attrition. In paper (More, Jadhav, et al.,
2024) author proposed a hybrid model integrating the
improved CBF and CF using CNNs. They also
introduced Cascade Hybrid Filtering, which
outperformed all baselines with an RMSE of 0.6325.
a
https://orcid.org/0009-0009-7585-6667
b
https://orcid.org/0009-0004-0582-9595
Additional work in optimizing CNN feature
extraction would support nuanced recommendations.
In paper (Mali, Pawar, et al., 2023) authors combined
CF with K- means clustering to reduce the
computational cost of CF on large datasets, with
RMSEs of 0.6354. It is a good example of how
clustering may improve the precision of
recommendations.
In paper (Mali, Mohanpurkar, et al., 2015)
according to authors, the recommendation system of
Netflix shapes user preferences through “taste
communities” because it creates algorithmic taste-
making. The authors of this paper focus on the
cultural implications of tailoring content
recommendations (Nalawade, Pattnaik, et al., 2004),
for recommending content, Sharma et al. applied
feature extraction from metadata; they also noted the
212
Bhoye, T., Mane, A., Navale, V., Mohapatra, S., Chitalkar, S., Borate, V. and Mali, Y.
A Role of Machine Learning Algorithms for Demand Based Netflix Recommendation System.
DOI: 10.5220/0013589500004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 2, pages 212-220
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
importance of data visualization in raising user
engagement (Patil, Zurange, et al., 2024). To deal
with the data sparsity problem, in paper (Modi, Modi,
et al., 2024) authors devised a co-clustering algorithm
that proved to have accuracy gain of 7.91% as
compared to classical CF.
In handling the missing data modalities, Agrawal
et al. proposed a meta-learning approach which
utilizes a Graph Attention Network. This resulted in
greatly reducing the RMSE of multi-modal
recommendation systems. In paper (Mehta,
Chougule, et al., 2024) the methodology used
significantly improved Movie Lens datasets that
address the temporal aspect for dynamic user
preferences on the matrix factorization model
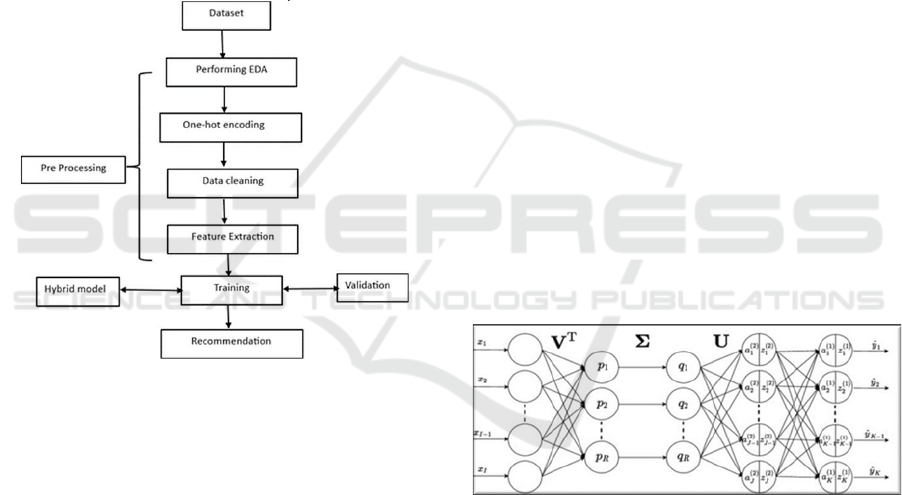
(Shimpi, Balinge, et al., 2024). The Figure 1. Shows
the Flowchart of recommendation system.
Figure 1: Flow Diagram for Recommendation System.
In paper (Ingale, Wankar, et al., 2024) authors
have combined data for Netflix and Amazon Prime
using the analytics of big data and the enhancement
in terms of cross-platform movie recommendations
are done on the grounds of providing platform-
specific suggestions. The flowchart illustrates how a
recommendation system is built by the process. A set
of dataset and exploratory data analysis determine the
trend and abnormality in data. Feature extraction
selects those important features to model the data.
Data cleaning manages missing values, and it uses
one-hot encoding on categorical data before
processing. Before training the model for trend,
validation is performed for the processed data. The
hybrid model uses a variety of recommendation
strategies
in
a
high
accuracy
level.
It
delivers
recommendations through the trained model to the
users.
1.1
Singular Value Decomposition
(SVD)
From Figure 2 SVD is one of the major benefits is the
simplification of some data that help in improving the
prediction accuracy, especially reducing the number
of features of the complex information that Netflix
collects. Of course, such information usually
includes, but is not restricted to, user interactions,
preferences, and content attributes. SVD makes it
possible to support personalized recommendations
that are more closely related to the interests of each
individual user by identifying latent factors that stand
in for the hidden user interests and content features.
SVD also addresses the sparse data problem faced
by Netflix, which basically means that most of the
viewers haven’t engaged with most of the content
items available. Even for less active users, SVD
guarantees strong recommendations by precisely
predicting missing elements of the user-content
matrix. This is possible because of the computational
efficiency of SVD, enabling it to process very large
volumes of data from Netflix’s at just about virtually
no computation cost, which also relates to an
important requirement for real-time dynamic
suggestions.
SVD Architecture is represented as in the Figure 2.
Figure 2: SVD Architecture.
2 RELATED WORK
In paper (More, Jadhav, et al., 2024) authors have
suggested a hybrid approach using CNN that
combines Collaborative Filtering (CF) with an
improvement in Content- Based Filtering (CBF) to
enhance the hybrid recommendations. In their
“Cascade Hybrid Filtering” approach, the user-item
interactions enable the first stage to continue through
CF that begins recommending some movies based on
those interactions, then continue the refinement by
A Role of Machine Learning Algorithms for Demand Based Netflix Recommendation System
213

assessing how much those movies resemble,
according to the contents in CBF. The performance of
the approach was tested on MAE and RMSE metrics
and it gave RMSE 0.6325 with an accuracy of 6 per
over the baseline models.
In paper (Mali, Pawar, et al., 2023) authors
proposed a Netflix recommendation system based on
the combination of Collaborative Filtering and K-
means clustering. Although CF is the most popular
technique, the high computational cost in case of
large datasets makes this algorithm inefficient.
Therefore, authors used K-means clustering for
grouping users with common interests before
applying CF. They used Twitter data mainly to obtain
user ratings; ratings were converted using Text Blob
polarity scores. This combined model achieved the
lower RMSE of 0.6354 in comparison to the
individual CF methods.
In paper (Mali, Mohanpurkar, et al., 2015) authors
have given recommendations on Netflix by
overcoming the cold- start problem in a hybrid
recommendation model based on the combination of
Collaborative Filtering and Content-Based Filtering.
Their system is making use of machine learning
algorithms to compute user behaviour and content
attributes, thereby bringing about a delicate balance
between item-based and user-based
recommendations.
In paper (Nalawade, Pattnaik, et al., 2004)
auuthors analyses NRS, one of its parts includes
critical questioning as to how it serves to central
purpose constructing preferences in the vast range of
users through “algorithmic taste-making”. In
application of a reverse engineering of NRS, Pajkovic
reveals how both methods of content-based filtering
along with collaborative filtering amalgamate by
putting users together to produce a form of ”taste
communities,” which, while spreading out beyond
national borders, stay coherent.
3 PROPOSED METHDOLOGY
3.1
Data Collection
The dataset utilized in this research was sourced from
kaggle Netflix Recommendation System. The
primary datasets include:
User Features
User ID: Every user is assigned a unique number, for
example, user001.Age: The age of the user can be
used while making the demographic analysis.
Gender: It can include the gender of the user
while making the suggestions.
Material: It depends on the subscription model.
3.1.1
Features of the Content
Movie/Show ID: A unique number assigned to every
title.
Title: The title of the film or the show. Genres are
classifications that apply to the plot of a movie or the
television show; among these are action, comedy,
drama, science fiction, and many more (Mulani,
Nandgaonkar, et al., 2024).
Description: It should be clear whether a user would
want to read the information based on a brief
overview or description of it (Sonawane, Mulani, et
al., 2024).
Release Year: It gives the year that this content was
released, which can therefore make one have a better
idea of how old or new the content is (Mandale, Modi,
et al., 2024).
Language: The main language used within the
content is this one, which is information that may be
a decision maker when determining what to watch
(Sengupta, Nalawade, et al., 2024), (More, Khane, et
al., 2024).
Cast: The females and actors who feature in the
movie or TV program. Information about the actors
in the movie help describe a user’s preferences
(Wanaskar, Dangore, et al., 2024).
Director: Information about who directed the movie
may affect whether or not to view it (More, Ramishte,
et al., 2024).
Production Company: Company that produced the
above stated film (Palkar, Jain, et al., 2024),
(Dangore, Modi, et al., 2024).
3.1.2
User-to-User Communication
User Evaluation Features Rating at specific instance
such as 1 to 5 stars and likes/dislike. This defines the
list of movies or a series a viewer has seen, and this
list for a viewer is termed the watch list (Dangore,
Bhaturkar, et al., 2024), (More, Shinde, et al., 2024).
Viewing time: The number of hours, say 90 minutes,
that a person spends viewing material (Vaidya,
Dangore, et al., 2024).
Watchlist: Titles that a user has added to their
watchlist but hasn’t watched (Sawardekar, Mulla, et
al., 2025).
3.2
Data Pre-Processing
3.2.1
Data Cleaning & Missing Values
Netflix deals with the missing data about the user
INCOFT 2025 - International Conference on Futuristic Technology
214

Such as missing ratings for any content by imputation
techniques or rejection of incomplete records (Modi,
Mali, et al., 2024), (Bhongade, Dargad, et al., 2024).
3.2.2
Similarity Computation
The system identifies users similar to the target user.
This is done by comparing their movie preferences or
other data points (Mali, Yogesh., et al., 2023).
3.2.3
Prediction
A machine learning model uses the similarity
information to make predictions about what movies
the target user would likely enjoy (Kale, Hrushikesh,
et al., 2024).
3.2.4
Recommendations
The model generates a list of recommended movies
for the target user, based on the predictions made
(Inamdar, Faizan, et al., 2024).
3.2.5
Normalization
The ratings obtained from the users may be
normalized, such that it will be consistency in
smoothness (Jagdale, Sudarshan, et al., 2020), (Modi,
Mali, et al., 2024).
3.2.6
Data Transformation
Encoding User and item features: Netflix assigns
numeric representations both to the users and content.
The information regarding both user and item is
encoded in a way so that all the categorical features
like user demographics, genres of movies, among
others convert into numerical vectors using
techniques such as one-hot encoding (Mali, Sharma,
et al., 2023).
Dimensionality Reduction: high dimensionality of
the data is reduced using for example a technique like
SVD or PCA(Modi, 2024). For instance, reducing
ratings over thousands of movies to identify key the
latent factor is the preference of users. The pre-
processing steps are shown in Figure 3.
Figure 3: Flow diagram of Pre-processing data.
3.3
Encoding Categorical Variables
For ease of modelling, categorical variables within
Netflix dataset have been label-encoded into numeric
formats. The process of label encoding assigns a
unique integer to each category so that machine
learning algorithms can handle it easily. The
categorical variables genre, content rating and
subscription tier were encoded to differentiate the
categories of different types of contents and levels of
subscription made by users (Mali, and, Chapte, 2014).
3.4
Train-Test Split
To test the efficiency of the recommendation systems,
the datasets were divided into training and testing
sets. An 80:20 split of the dataset into training and
testing was made to check the effectiveness of the
recommendation system of Netflix (Asreddy,
Shingade, et al., 2019).
3.5
Models Performed
3.5.1
Logistic Regression
The logistic regression can be used to predict the
likelihood that a user will engage with or enjoy a
particular show or movie. This approach involves
framing the recommendation problem as a binary
classification task: given a set of user, item, and
interaction features, the model predicts the
probability of a positive user response (like, watch, or
high rating) (Pathak, Sakore, et al., 2019).
3.5.2
SVM
The Support Vector Machines (SVM) can be used for
the task of categorization or to make a prediction [16]
about user engagement, view preferences, or churn
risks during the analysis of behaviour for users on
Netflix (Jagdale, Khandre, et al., 2021).
A Role of Machine Learning Algorithms for Demand Based Netflix Recommendation System
215

3.5.3
Random Forest
Random Forest is an ensemble learning technique,
which is efficient in analysing user behaviour and
forecasting what content a user might like in a Netflix
recommendation engine (Mali, Sawant, et al., 2023).
3.5.4
Singular Value Decomposition (SVD)
It is one of the most useful techniques for developing
dimensional reduction and latent factor discovery to
influence user choices in recommendation systems
like Netflix.
3.5.5
Decision Tree
A more-beloved, if perhaps more interpretable,
machine learning technique is called decision [16]
trees. They work by building a model that, given a
variety of input features-things like user
demographics and content qualities-will predict the
value of a target variable, say user ratings or
preferences, as Netflix and all sorts of
recommendation systems do.
3.5.6
Naive Bayes
Naıve Bayes can be applied in a Netflix
recommendation system by predicting user
preferences for movies or TV shows based on
demographic characteristics and viewing history.
3.5.7
Xg Boost
For supervised learning tasks, such as
recommendation systems like Netflix, XGBoost is the
most popular and effective gradient boosting method
implementation. Its sturdiness against overfitting and
capacity to handle huge datasets make it very
successful.
3.5.8
Cascade Hybrid Model
In complex systems especially, as in Netflix, this
hybrid approach may increase the user’s level of
satisfaction and engagement through multiple models
with their unique advantages but their unique
disadvantages limitations.
3.5.9
Neural Network
Neural networks make it possible to provide highly
customized recommendations by simulating
connections between users and content.
3.5.10
K-Nearest Neighbors
The KNN algorithm is a very simple yet powerful
collaborative filtering tool that Netflix and other
recommendation systems use to present content to
users based on their tastes.
4 RESULTS AND DISCUSSION
This resulted in an accuracy of 68.74% and a Root
Mean Square Error of 0.4560. User preference, to an
extent can be derived through this algorithm; however
the idea should further be augmented with its
application to get closer more accurate predictions.
KNN vs. Gradient Boosting Classifier. Gradually, the
Gradient Boosting Classifier outsmarted the KNN
with an absolute accuracy of 74.65% with the least
RMSE value of 0.4207 as compared to the overall
prediction. With an RMSE of 0.2826, and with the
highest accuracy of 90.66%, Cascade Hybrid was
amazing, showing its capabilities to be able to
produce relevant suggestions.
The clear winner on this one would be the
Singular Value Decomposition because it had the
highest accuracy at 94.34% and had the smallest
RMSE value at 0.2580. What this result reveals is that
SVD could really depict the user preference
accurately. SVM performed quite well with an
accuracy of 75.80% and an RMSE of 0.4108,
although it is still behind models like SVD and
Cascade Hybrid. Decision Tree seems to be less
useful in this situation with an accuracy of 64.70%
and comparatively high RMSE at 0.5942. With an
accuracy of 74.20% and an RMSE of 0.4229,
Random Forest established that recommendations
made were nearly accurate enough. With the neural
network, an accuracy of 73.81% with an RMSE of
0.5099 showed user preferences that can improve.
With the Naive Bayes approach, a moderate capacity
for prediction had an accuracy of 75.03% and an
RMSE of 0.4997.
On the contrary, SVD performed excellently,
yielding an unbelievable accuracy of 94.34% and a
reduced RMSE of 0.2580. Such high accuracy proves
that this is a very successful relevance-based
recommender system as well.
INCOFT 2025 - International Conference on Futuristic Technology
216
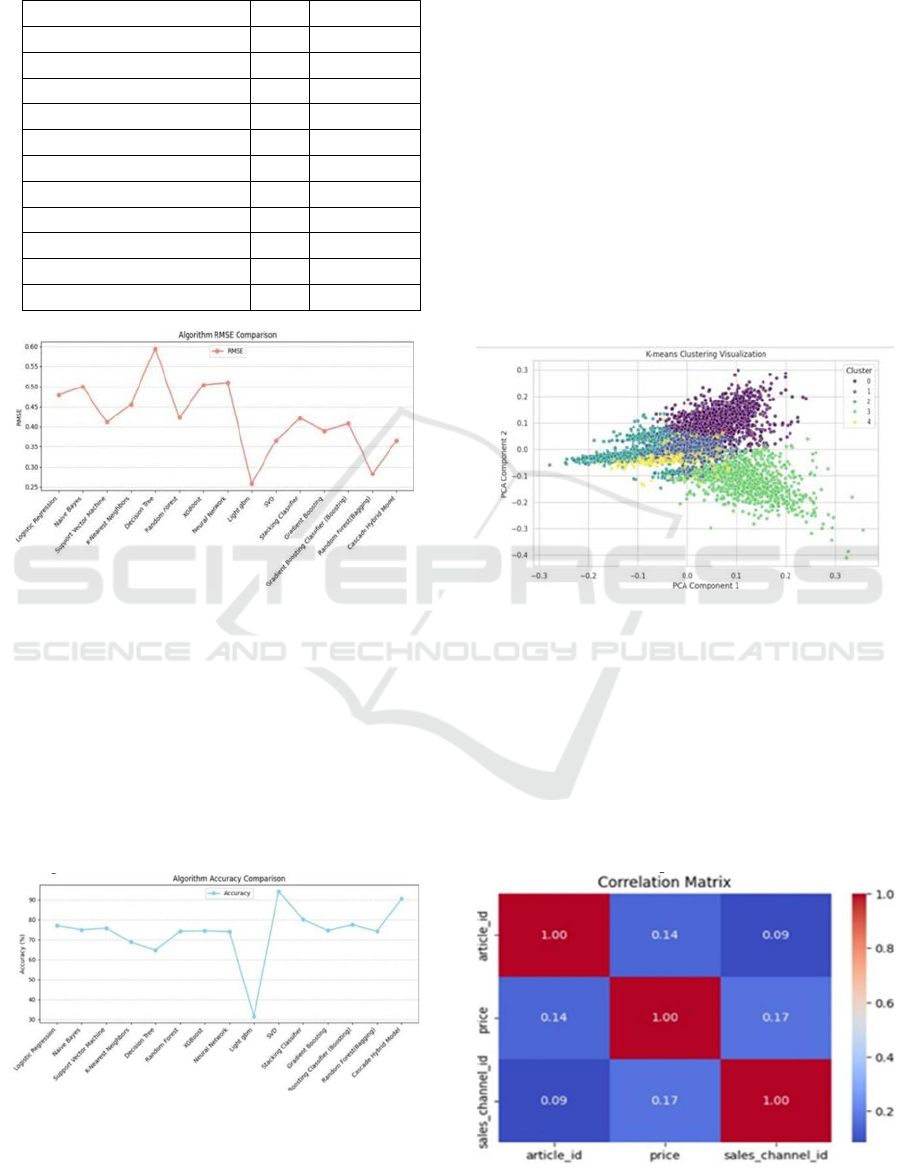
Table 1: Performance Comparison of Recommendation
Models.
Model
RMSE
Accuracy (%)
KNN
0.4560
68.74
Gradient Boosting Classifier
0.4207
74.65
Cascade Hybrid
0.2826
90.66
SVD
0.2580
94.34
SVM
0.4108
75.80
Decision Tree
0.5942
64.70
Random Forest
0.4229
74.20
Neural Network
0.5099
73.81
Naive Bayes
0.4997
75.03
Logistic Regression
0.4787
77.09
XG Boost
0.5048
74.52
Figure 4: RMSE for different models.
Improved error performance from lower values of
RMSE is represented by Figure 4, Algorithm RMSE
Comparison. Figure 5 represents Algorithm Accuracy
Comparison on how well each algorithm really
performs and higher values indicate a better predicted
result. In turn, they reflect trade-offs between
accuracy and RMSE in revealing those discrepancies
between algorithms that represent effectiveness Fig. 4
and Fig. 5.
Figure 5: Accuracy for different models.
The scatter diagram in Fig. 6, represents the data onto
two dimensions and showing the result of a K-means
clustering experiment on a data set. The x-axis is
“PCA Component 1,” and the y-axis is “PCA
Component 2,” which is the original multi-
dimensional data projected onto two principal
components to view it.
5 CONCLUSION
In this research, we developed a Netflix
recommendation system model using the Netflix
Recommendation System dataset. Different forms of
suggestion on Netflix had shown how well such
complex algorithms work to enhance user experience
as well as increase viewer engagement, which
ultimately boosts retention rates and revenue growth.
Figure 6: Scatter plot that visualizes the results of a K-means
clustering.
The SVD model alone is proven to be accurate and
efficient in its application on the dataset of Netflix so
well, as it may go in mitigating problems associated
with bespoke content recommendation. Results of
this research are consequential for trends of the
entertainment industry, as well as building more
advanced recommendation systems responding
dynamically to changes in the user’s preference.
Figure 7: Visual representation of Confusion Matrix.
A Role of Machine Learning Algorithms for Demand Based Netflix Recommendation System
217

Future research in this direction is expected to extend
beyond these conventional approaches and include
new machine learning techniques, such as deep
learning and reinforcement learning, in order to
increase recommendation prediction accuracy and
real-time adaptability further in diverse streaming
environments, such as that of Netflix. The following
advanced technologies include:
5.1
Context-Aware Suggestions
Through context-aware algorithms, depending upon
the present situations of the users, it can change
suggestions related to the location and time in
addition to considering the device type. It may
increase user engagement when proper suggestions
are brought up at a particular moment in time.
5.2
Multi-Modal Learning
Quality can be improved of recommendations by
researching multi-modal learning strategies that will
combine information from many sources, including
but not limited to text evaluation, photos, and videos.
5.3
Ethical AI
The future research is related to the moral concern of
the recommendation algorithm in Netflix, such as
bias detection and minimization, ensuring fairness,
and also promotion of transparency in the algorithmic
decision- making. XAI methodologies can very well
explain the recommendations. This will increase user
enjoyment and satisfaction.
REFERENCES
P. B. More, A. N. Jadhav, I. Khatik, S. Singh, V. K. Borate
and Y. K. Mali, “Sign Language Recognition Using
Hand Gestures”, 2024 3rd International Conference for
Advancement in Technology (ICONAT), GOA, India,
2024, pp. 1-5, doi:10.1109/ICONAT61936
.2024.10774685.
Y. Mali, M. E. Pawar, A. More, S. Shinde, V. Borate and
R. Shirbhate, “Improved Pin Entry Method to Prevent
Shoulder Surfing Attacks”, 2023 14th International
Conference on Computing Communication and
Networking Technologies (ICCCNT), Delhi, India,
2023, pp. 1-6, doi: 10.1109/ICCCNT569
98.2023.10306875.
Y. K. Mali and A. Mohanpurkar, “Advanced pin entry
method by resisting shoulder surfing attacks”, 2015
International Conference
on Information Processing
(ICIP), Pune, India, 2015, pp. 37-42, doi:
10.1109/INFOP.2015.7489347.
S. A. Nalawade, R. Pattnaik, S. Kadam, P. P. Lodha, Y. K.
Mali and V. K. Borate, “Smart Contract System with
Block-chain Capability for Improving Supply Chain
Management”, 2024 3rd International Conference for
Advancement in Technology (ICONAT), GOA, India,
2024, pp. 1-7, doi: 10.1109/ICONAT61936
.2024.10774955.
S. P. Patil, S. Y. Zurange, A. A. Shinde, M. M. Jadhav, Y.
K. Mali and V. Borate, “Upgrading Energy Productivity
in Urban City Through Neural Support Vector Machine
Learning for Smart Grids”, 2024 15th International
Confe. on Computing Communication and Networking
Technologies (ICCCNT), Kamand, India, 2024, pp. 1-
5, doi: 10.1109/ICCCNT61001.20 24.10724069.
S. Modi, M. Modi, V. Alone, A. Mohite, V. K. Borate and
Y. K. Mali, “Smart shopping trolley Using Arduino
UNO”,2024 15th International Conf. on Computing
Communication and Networking Technologies
(ICCCNT), Kamand, India, 2024, pp.1-6, doi:10.1109/
ICCCNT61001.2024.10725524.
U. Mehta, S. Chougule, R. Mulla, V. Alone, V. K. Borate
and Y. K. Mali, “Instant Messenger Forensic System”,
2024 15th International Conference on Computing
Communication and Networking Technologies
(ICCCNT), Kamand, India, 2024, pp. 1- 6, doi:
10.1109/ICCCNT61001.2024.10724367.
P. Shimpi, B. Balinge, T. Golait, S. Parthasarathi, C. J.
Arunima and Y. Mali, “Job Crafter - The One- Stop
Placement Portal”,2024 15th International Conference
on Computing Communication and Networking
Technologies (ICCCNT), Kamand, India, 2024, pp.1-8,
doi: 10.1109/ICCCNT61001.2024.10725010.
V. Ingale, B. Wankar, K. Jadhav, T. Adedoja, V. K. Borate
and Y. K. Mali, “Healthcare is being revolutionized by
AI-powered solutions and technological integration for
easily accessible and efficient medical care”, 2024 15th
International Confe. on Computing Communication
and Networking Technologies (ICCCNT), Kamand,
India, 2024, pp. 1-6, doi: 10.1109/ICCCNT61001.
2024.10725646.
U. Mulani, V. Nandgaonkar, R. Mulla, S. Sonavane, V. K.
Borate and Y. K. Mali, “Smart Contract System with
Blockchain Capability for Improved Supply Chain
Management Traceability and Transparency”, 2024
15th International Conference on Computing
Communication and Networking Technologies
(ICCCNT), Kamand, India, 2024, pp. 1-7, doi:
10.1109/ICCCNT61001.2024.10723871.
S. Sonawane, U. Mulani, D. S. Gaikwad, A. Gaur, V. K.
Borate and Y. K. Mali, “Blockchain and Web3.0 based
NFT Marketplace”, 2024 15th International Conference
on Computing Communication and Networking
Technologies (ICCCNT), Kamand, India, 2024, pp. 1-
6, doi: 10.1109/ICCCNT61001.2024.10724420.
P. Mandale, S. Modi, M. M. Jadhav, S. S. Khawate, V. K.
Borate and Y. K. Mali, Investigation of Different
Techniques on Digital Actual Frameworks Toward
Distributed Denial of Services Attack, 2024 15th
INCOFT 2025 - International Conference on Futuristic Technology
218

International Conference on Computing 14
Communication and Networking Technologies
(ICCCNT), Kamand, India, 2024, pp. 1-6, doi:
10.1109/ICCCNT61001.2024.10725776.
D. Sengupta, S. A. Nalawade, L. Sharma, M. S. J. Kakade,
V. K. Borate and Y. K. Mali, Enhancing File Security
Using Hybrid Cryptography, 2024 15th International
Conference on Computing Communication and
Networking Technologies (ICCCNT), Kamand, India,
2024, pp. 1-8, doi:
10.1109/ICCCNT61001.2024.10724120.
A. More, S. Khane, D. Jadhav, H. Sahoo and Y. K. Mali,
Auto-shield: Iot based OBD Application for Car Health
Monitoring, 2024 15th International Conference on
Computing Communication and Networking
Technologies (ICCCNT), Kamand, India, 2024, pp.1-
10,doi: 10.1109/ICCCNT61001.2024.10726186.
U. H. Wanaskar, M. Dangore, D. Raut, R. Shirbhate, V. K.
Borate and Y. K. Mali, A Method for Re- identifying
Subjects in Video Surveillance using Deep Neural
Network Fusion, & 2024 15th International Conference
on Computing Communication and Networking
Technologies (ICCCNT), Kamand, India, 2024, pp.1-
4,doi: 10.1109/ICCCNT61001.2024.10726255.
A. More, O. L. Ramishte, S. K. Shaikh, S. Shinde and Y. K.
Mali, Chain-Checkmate: Chess game using
blockchain,2024 15th International Conference on
Computing Communication and Networking
Technologies (ICCCNT), Kamand, India, 2024, pp. 1-
7, doi: 10.1109/ICCCNT61001.2024.10725572.
J. D. Palkar, C. H. Jain, K. P. Kashinath, A. O. Vaidya, V.
K. Borate and Y. K. Mali, Machine Learning Approach
for Human Brain Counselling, 2024 15th International
Conference on Computing Communication and
Networking Technologies (ICCCNT), Kamand, India,
2024, pp. 1-8, doi: 10.1109/ICCCNT61001.2024
.10723852.
M. Dangore, S. Modi, S. Nalawade, U. Mehta, V. K. Borate
and Y. K. Mali, Revolutionizing Sport Education With
AI, 2024 15th International Conf. on Computing
Communication and Networking Technologies
(ICCCNT), Kamand, India, 2024, pp.1-8, doi: 10.1109/
ICCCNT61001.2024.10724009.
M. Dangore, D. Bhaturkar, K. M. Bhale, H. M. Jadhav, V.
K. Borate and Y. K. Mali, &Applying Random Forest
for IoT Systems in Industrial Environments, 2024 15
th
International Conf. on Computing Communication and
Networking Technologies (ICCCNT), Kamand, India,
2024, pp.1-7, doi: 10.1109/ICCCNT61001.2024.10
725751.
A. More, S. R. Shinde, P. M. Patil, D. S. Kane, Y. K. Mali
and V. K. Borate, Advancements in Early Detection of
Lung Cancer using YOLOv7, 2024 5th International
Conference on Smart Electronics and Communication
(ICOSEC), Trichy, India, 2024, pp. 1739-1746,doi:
10.1109/ICOSEC61587.2024.10722534.
A. O. Vaidya, M. Dangore, V. K. Borate, N. Raut, Y. K.
Mali and A. Chaudhari, Deep Fake Detection for
Preventing Audio and Video Frauds Using Advanced
Deep Learning Techniques, 2024 IEEE Recent
Advances in Intelligent Computational Systems
(RAICS), Kothamangalam, Kerala, India, 2024, pp. 1-
6, doi: 10.1109/RAICS61201.2024.10689785.
Sawardekar, S., Mulla, R., Sonawane, S., Shinde, A.,
Borate, V., Mali, Y.K. (2025). Application of Modern
Tools in Web 3.0 and Blockchain to Innovate
Healthcare System. In: Rawat, S., Kumar, A., Raman,
A., Kumar, S., Pathak, P. (eds) Proceedings of Third
International Conference on Computational Electronics
for Wireless Communications. ICCWC 2023. Lecture
Notes in Networks and Systems, vol 962. Springer,
Singapore. https://doi.org/10.1007/978-981-97-1946-
4_2
Modi, S., Mali, Y., Kotwal, R., Kisan Borate, V., Khairnar,
P., Pathan, A. (2024). Hand Gesture Recognition and
Real-Time Voice Translation for the Deaf and Dumb.
In: Jain, S., Mihindukulasooriya, N., Janev, V.,
Shimizu, C.M. (eds) Semantic Intelligence. ISIC 2023.
Lecture Notes in Electrical Engineering, vol 1258.
Springer, Singapore.https://doi.org/10.1007/978-981-
97-7356-5_35.
Bhongade, A., Dargad, S., Dixit, A., Mali, Y.K., Kumari,
B., Shende, A. (2024). Cyber Threats in Social
Metaverse and Mitigation Techniques. In: Somani,
A.K., Mundra, A., Gupta, R.K., Bhattacharya, S.,
Mazumdar, A.P. (eds) Smart Systems: Innovations in
Computing. SSIC 2023. Smart Innovation, Systems and
Technologies, vol 392. Springer, Singapore. https://doi.
org/10.1007/978-981-97-3690-4_34.
Mali, Yogesh. &TejalUpadhyay, “Fraud Detection in
Online Content Mining Relies on the Random Forest
Algorithm”, SWB 1, no. 3 (2023): 13- 20.
Kale, Hrushikesh, Kartik Aswar, and Dr Yogesh Mali
Kisan Yadav. Attendance Marking using Face
Detection, International Journal of Advanced Research
in Science, Communication and Technology: 417-424.
Inamdar, Faizan, Dev Ojha, C. J. Ojha, and D. Y. Mali. Job
Title Predictor System, International Journal of
Advanced Research in Science, Communication and
Technology (2024): 457-463.
Jagdale, Sudarshan, Piyush Takale, Pranav Lonari,
Shraddha Khandre, and Yogesh Mali. “Crime
Awareness and Registration System, International
Journal of Scientific Research in Science and
Technology 5, no. 8 (2020).
Modi, S., Mali, Y., Sharma, L., Khairnar, P., Gaikwad,
D.S., Borate, V. (2024). A Protection Approach for
Coal Miners Safety Helmet Using IoT. In: Jain, S.,
Mihindukulasooriya, N., Janev, V., Shimizu, C.M. (eds)
Semantic Intelligence. ISIC 2023. Lecture Notes in
Electrical Engineering, vol 1258. Springer, Singapore.
https://doi.org/10.1007/978-981-97-7356- 5_30.
Y. K. Mali, L. Sharma, K. Mahajan, F. Kazi, P. Kar and A.
Bhogle, “Application of CNN Algorithm on X- Ray Images
in COVID-19 Disease Prediction”, 2023 IEEE
International Carnahan Conference on Security
Technology (ICCST), Pune, India, 2023, pp. 1-6, doi:
10.1109/ICCST59048.2023.10726852.
A Role of Machine Learning Algorithms for Demand Based Netflix Recommendation System
219

Shabina Modi, “Automated Attendance Monitoring System for
Cattle through CCTV.”, REDVET, vol. 25, no. 1, pp. 1025
-1034, Sep. 2024.
Y. Mali and V. Chapte, “Grid based authentication system”
International Journal of Advance Research in Computer
Science and Management Studies, vol. 2, no. 10, pp. 93- 99,
October 2014.
Rajat Asreddy, Avinash Shingade, Niraj Vyavhare, Arjun
Rokde and Yogesh Mali, “A Survey on Secured Data
Transmission Using RSA Algorithm and Steganography”,
International Journal of Scientific Research in Computer
Science Engineering and Information Technology
(IJSRCSEIT), vol. 4, no. 8, pp. 159-162, September-
October 2019, ISSN 2456–3307.
Jyoti Pathak, Neha Sakore, Rakesh Kapare, Amey Kulkarni and
Prof. Yogesh Mali, “Mobile Rescue Robot”, International
Journal of Scientific Research in Computer Science
Engineering and Information Technology (IJSRCSEIT),
vol. 4, no. 8, pp. 10-12, September- October 2019, ISSN
2456–3307.
Pranav Lonari, Sudarshan Jagdale, Shraddha Khandre, Piyush
Takale and Prof Yogesh Mali, “Crime Awareness and
Registration System”, International Journal of Scientific
Research in Computer Science Engineering and
Information Technology (IJSRCSEIT), vol. 8, no. 3, pp.
287-298, May-June 2021, ISSN 2456–3307.
Yogesh Mali and Nilay Sawant, “Smart Helmet for Coal
Mining”, International Journal of Advanced Research in
Science Communication and Technology (IJARSCT), vol.
3, no. 1, February 2023.
INCOFT 2025 - International Conference on Futuristic Technology
220
