
Containerization in Web Development: Docker and Kubernetes
Bhakti Sanket Puranik, Arti Sonawane, Rahul Rasal, Parth Renakale and Darshan Kakad
Department of Computer Engineering, Dr. D. Y. Patil Institute of Technology Pimpri, Maharashtra, India
Keywords: Containerization, Docker, Kubernetes, Web Development, Orchestration, DevOps, Microservices.
Abstract: Containerization has changed how we manage web apps today. With tools like Docker Kubernetes, it helps
create containers that keep environments consistent. Docker makes easy to build and run these containers.
Kubernetes takes it a step further by managing them automatically—this includes scaling, orchestration, and
management. This paper dives into the key ideas & benefits of containerization, especially through Docker &
Kubernetes. We look at how they've impacted web development and scalability. Finally, we offer practical
insights on deploying containers and managing them securely.
1 INTRODUCTION
The web development field has significantly evolved
from traditional models into microservices
architecture that has thrived due to increased
demands for agility and scalability. Indeed, while it is
easier to develop monolithic applications, they often
struggle to adapt changes in very quick cycles and
scale well. On the other hand, microservices break
applications down into very manageable and small
components that can be developed and deployed
independently. This flexibility, however, brings much
complexity, especially when one is managing
services at many developmental stages and in pro-
duction.
Containerization is a solution to these issues,
which provides isolated environments called
containers encapsulating the ap- plication along with
its necessary dependencies for desired performance
across different environments. Docker happens to be
one of the widely used tools to build and manage
those containers, whereas Kubernetes improves this
by autom- atization of its deployment, scaling, and
orchestration. This paper reviews the core principles
of Docker and Kubernetes, their applications in
modern web development, and the critical importance
of securing these containerized environments.
The demand to manage web applications in an
appropriate manner has made developers shift their
paradigms of deploy- ing and then managing
applications. Traditional deployments had many
inherent problems, where ”it works on my machine”
problems more frequently made the rounds: code that
worked fine in one configuration failed in another.
That risk can be partially mitigated by a process
called containerization, where an application with all
its dependencies is bundled together in such a way
that there is little inconsistency. This bundling makes
it easier to develop and deploy applications from the
local machine to cloud servers.
Containerization has brought application adoption
for mi- croservices architecture quite fast. Taking the
applications into small, self-contained services gives
a chance to the developers to optimize each service
individually. So with a service without any
dependency, developing cycle will become faster and
scal- ability eases also, then teams can adapt agile
methodologies with more iterative development and
quicker response in front of market demands.
Innovation that happens quickly, on the other hand,
needs organizations responding more powerfully to
changes in business needs.
2 OVERVIEW OF DOCKER AND
KUBERNETES
2.1 Docker
Deploying applications into containers turns to be
much easier and has a very light configuration with
the help of Docker. This process ensures constant
performance through all the development stages. This
has made container technology used by Docker
Puranik, B. S., Sonawane, A., Rasal, R., Renakale, P. and Kakad, D.
Containerization in Web Development: Docker and Kubernetes.
DOI: 10.5220/0013588700004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 2, pages 163-173
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
163

enable development in such ways that it is more
efficient compared to the traditional virtual machines
for the creation, deployment, and management of
applications. It has made each container operate in
isolation and share the kernel of its host operating
system, reducing overhead and increasing resource
utilization.
A few major components of Docker are involved.
Docker images consist of read-only templates that
include all the necessary assets to run a container.
Images can be developed from a Dockerfile, a script
that outlines the process to build an image. Running
instances of images are known as containers and can
operate with light and isolated environments for better
management. This architecture makes deployment
fast and has consistent application behavior across
development, testing, and production environments
(Merkel, 2014).
Besides that, Docker supports a thriving
ecosystem of tools and integrations - Docker
Compose and Docker Swarm. It defines and runs
multi-container applications with Docker Compose.
And it gives native clustering and orchestration with
Docker Swarm. Together, these tools make easy
management of complex applications for teams
(Goldstein, 2017).The main advantages of Docker
include not only efficiency but also the ability to run
with modern development practices, such as CI/CD.
Integrating Docker in CI/CD pipelines is intended to
automate test and deploy applications so that any new
code should be very solid before reaching production.
These steps substantially reduce the possibility of
human errors and improve the general reliability of
the applications (Burns et al., 2016).
Another important feature of Docker is security.
The Docker containers are built with a default of
running in an isolated environment, making it
unlikely to have system-wide failures when
applications have bugs or vulnerabilities. However,
de- velopers must practice the good way of securing
their con- tainers. They must, for instance, use images
that are trusted. The minimal privileges shall be
maintained by the containers, which minimize the
attacking opportunities. Scanning for vulnerability in
Docker images at regular intervals is also necessary
for maintaining a secured environment (Turnbull,
2014).
Simply put, Docker is the new best method to
deploy or manage applications. It allows developers
to write their code, ship it, and run it uniformly across
different environments. Powerful tools and
integrations combined with a lightweight architecture
make Docker an essential component in modern
software development.
2.2 Kubernetes
Kubernetes is pretty much an orchestration system for
containers that automatically manages the
deployment and scaling of containerized applications,
abstracting away from the underlying infrastructure
so developers can focus on writ- ing code rather than
managing deployment details. Some of the key
features include auto-scaling, self-healing, and
service discovery which makes the management of
containers across clusters of machines efficient
(Hightower et al., 2017).
Kubernetes works on the concept of pods, that are
the small- est deployable units and may contain one
or more containers sharing their resources like
storage. In Kubernetes, nodes are the worker
machines running these applications, each having a
Kubelet agent to ensure appropriate containers are
running. It introduces services as a layer of
networking that ensures load balancing and
communication between different pods. Deployments
portray the intended state of an application, which
manages updates and scaling with ease (Daemon,
2018).
The architecture of Kubernetes is designed to be
flexible and resilient. It comprises of a master worker
model, where the master node controls the cluster, and
the worker node executes applications. This
separation of concerns leads to scaling up and
resource management as well as allowing
organizations to host large applications in a high
avenue (Farley, 2019a).
The Kubernetes system also gives a robust API
that can extend integration with multiple tools and
platforms. This extensibility makes it so teams can
adopt additional functional- ities such as monitoring,
logging, and security improvements without having
to undertake significant restructuring efforts on their
already existing infrastructure. The richness of the
Kubernetes ecosystem, including instruments such as
Helm for package management and Istio for service
mesh capacities, provides further explanations for the
attractiveness of this system for organizations that are
in pursuit of moving towards microservices
architectures (Bhargava, 2019).
In terms of community support, Kubernetes really
gained great mileage from the major cloud providers
and the open- source community. It ensured ongoing
collaboration keeping Kubernetes at the top of
container orchestration technologies based on recent
developments in modern application develop- ment
(Brown, 2020).
Conclusion: Kubernetes is far beyond being the
orchestrator of containers in itself, but the future trend
INCOFT 2025 - International Conference on Futuristic Technology
164

of deployment and management of applications
within a cloud-native landscape. Its powerful
features, scalability, and flexibility are what make it
an important component in the transition embracing
containerization and microservices architectures by
the organizations.
3 COMPONENTS OF DOCKER
AND KUBERNETES
3.1 Components of Docker
The three primary components of Docker are Docker
im- ages, containers, and Dockerfiles. The Docker
images con- stitute the fundamental building blocks
of any program and
its dependencies, which would
result in consistent execution across environments.
Such images are created based on a Dockerfile, which
contains all the instructions necessary for assembling
the image. Running versions of these images are
referred to as Docker containers and therefore offer
isolated environments that are lighter in weight than
traditional virtual machines. It supports a shared
kernel architecture that causes the resource utilization
efficient and has rapid application deployment
(Narayan, 2020).
A Docker image is a layered filesystem that gets
built layer by layer. All these layers represent an
instruction in the Docker file, optimizing both the
storage and also building processes more speedily.
That implies that when changes are made to
an
image, only the layers that are affected have to be
rebuilt again to save time and computational
resources. This layer- based architecture supports
image caching, and that reduces the time taken to
deploy, hence making them faster for iteration in
development (Smith, 2020).
Docker Hub also provides a central repository
to share Docker images. It provides official and
community-maintained images - the number is vast,
and many were published openly, so users can find
and make use of the available pre-built images for
common applications. This fact accelerates the
development time as teams can reuse and include
ready-built images instead of having to build
everything from scratch (Dyer, 2021). The Docker
package also includes a CLI through which
developers can communicate with containers and
images at the most basic level. With simple
commands, users can create, start, stop, and manage
their containers without complications, making it
easier to use. This simplicity also happens with
regard to the management of container networks,
through which containers can easily communicate
with each other, thereby encouraging the use of
microservices architecture (Finkelstein, 2020).
For example, the architecture of Docker is
conveniently built to be easily integrated with cloud
services. Most of the cloud providers give managed
Docker services, and this would enable teams to
deploy their applications on a scalable infrastructure
without having to control the underlying hardware.
This simply means that organizations are able to
concentrate on their business functions while using
the cloud resources efficiently (Farley, 2019).
Figure 1: Docker Architecture
3.2 Components of Kubernetes
It consists of several components working together to
manage containerized applications. Pods are the
smallest de- ployable units in Kubernetes, which
contain one or more containers that share the same
network and storage resources. Application execution
happens on nodes, and each node is managed by a
Kubelet, which ensures that the appropriate
containers are always running. Services are
networking layers that allow multiple pods to
communicate and share load, while deployments are
used to specify desired states for applications- like
scaling and updating procedures (Ang, 2021).
The control plane is the back end of Kubernetes,
dealing with cluster management and scheduling
decisions for pods. Its most prominent components
include the API server, etcd- the state of a cluster,
scheduler, and controller manager.
END. The API server is the main interface one
may use to access the Kubernetes cluster, thus it
enables all users and applications communicating
with the control plane. Etcd is the distributed key-
value store that holds the configuration data and state
of the cluster (Green, 2019).
The ability of schedulers, one of the
fundamental parts of the functionality of
Kubernetes, is to make a decision about where to
run pods based on factors such as available
resources, constraints, and policies defined by users.
With dy- namic scheduling capability, resources are
Containerization in Web Development: Docker and Kubernetes
165

efficiently utilized, meaning applications are
responsive with varying loads (McCarthy, 2022).
Kubernetes supports several strategies for
deployment, in- cluding rolling updates as well as
blue-green deployment, allowing users to update
applications online with no downtime. These
strategies ensure that teams can deploy new
features and fixes while not ever going out of
service; this is highly essential in most modern web
application forms, in terms of uptime (Li, 2020).
In Kubernetes, security is multi-dimensional and
goes from role-based access control, which enforces
restrictions based on role, through network policies
that determine how pods interact with each other and
external services to security contexts, allowing
developers to encode security settings for individual
pods. Thus, security contexts are taken to a very
granular level of what might be needed as an
application runs inside the cluster (Chen, 2020).
Altogether, Kubernetes has several components
that work together in ensuring that containerized
applications have a robust and scalable platform in
which to run. Generally, its architecture is scalable,
secure, and reliable regarding application
deployment.
Figure 2: Kubernetes Architecture
4 APPLICATION OF DOCKER
AND KUBERNETES IN WEB
DEVELOPMENT
4.1 Docker in Web Development
Docker has changed the whole process of
development in web development because it
introduces a paradigm of containerization in the
lifecycle of development. One of the advantages
Docker offers is environment consistency. Applica-
tions usually pose problems related to inconsistencies
between the development, testing environments, and
the production environment in traditional workflows
of development. Such inconsistencies lead to errors
that sometimes cannot be readily identified. All the
above challenges are mitigated by Docker because
Docker encapsulates the applications and their de-
pendencies inside containers. Everything that the
application needs to run-from libraries and
configurations down to the code-is held in one
container. This approach ensures that, in all stages of
the development cycle, the application behaves
exactly, so developers feel much more confident and
make fewer mistakes at deployment time (Merkel,
2014).
Docker also lets developers create a microservices
archi- tecture, which has become a backbone of
modern web ap- plications. This would be a
microservices framework; in this type of structure,
applications are divided into smaller, inde- pendent
services that can be developed, tested, and deployed
separately. A structure like this is made easier by
Docker, which allows developers to wrap each of
these microservices into an individual container. This
kind of modularity is actually
very essential for scaling up applications as well
as keeping them together. Each microservice can be
developed using a different technology or even a
different programming language according to its
requirement. It also allows teams to choose the best
tool for the job without the limitation of having a
monolithic application structure (Goldstein, 2017).
Another important strength of Docker is its
seamless in- tegration with Continuous Integration
and Continuous De- ployment (CI/CD) pipelines.
Organizations today must be able to roll out updates
fast and consistently in today’s fast- changing
development environment. What Docker improves in
CI/CD processes is that it makes the testing and
deployment automated in consistent environments.
This facilitates the developers to push code changes
with less time between coding and delivering it to
the users. The automated tests run in Docker
containers that are an exact replica of the production
environment; this ensures that problems flagged, if
any, are detected early in the cycle of development.
The result is having updates and features delivered
with greater frequency and confidence, thus
improving quality in the software being delivered to
the users (Turnbull, 2014).
Moreover, Docker offers versions and isolation of
appli- cations, thus enhancing management over
dependencies and libraries. Applications can run
multiple versions on the system at one time; thus, new
features can be tested without interfering with the
production environment. This is quite useful espe-
INCOFT 2025 - International Conference on Futuristic Technology
166

cially for large teams where collaboration proves
important. Each can work on his or her version of
the application, and it gets merged only after the
changes are validated; they can push them into the
original codebase. That is a reduction of risk in cases
of potential conflicts between people because it
makes straightforward the collaboration processes of
working together with other team members.
In short, Docker is integral to web development in
pro- viding tools that ensure consistency of
environments, that foster microservices architecture,
and naturally fit into CI/CD workflows. Its
containerization technology really simplifies the
complexities of the headache around deploying, that
actually prevent developers from going beyond other
forms of build- ing features. So while more and more
organizations take to Docker, productivity increases
and innovations are fueled by fast and reliable
software delivery. In continuation with this aspect of
importance in the web development landscape, the
Docker ecosystem continues to grow with a rich
repository of pre-built images and an all
encompassing community base for support.
4.3 Kubernetes for Scaling Web
Applications
Today, Kubernetes is an important orchestration
platform through which organizations manage their
containerized ap- plications, especially at times when
they want to scale up their activities effectively. With
growing complexity in web applications and their
diverse user demands, robust orches- tration
strategies surface as requirements. Among the most
significant features in Kubernetes is its ability to auto-
scale applications. This enables dynamic scaling in
terms of the number of running pods in direct
proportion to the demand currently occurring,
ensuring that applications stay responsive even in the
traffic peak. Besides performance, auto-scaling
capabilities also optimize resource usage for
operations and help organizations balance the cost of
operations (Hightower et al., 2017). Ku- bernetes
scales applications up during peak usage and down
when things are quieter, so resources are being
allocated and contributing to a much more sustainable
infrastructure.
Another significant benefit of Kubernetes is that
it can do load balancing. Since applications receive
different levels of traffic, it would be unwise to let all
that traffic pour in on one particular pod, where
containers can become over-represented. In return,
the release manages this through routing incoming
requests to the appropriate pods, thereby ensuring
high avail- ability and reliability. This is a vital load
balancing feature for maintaining service levels,
particularly in production environ- ments where
uptime is indispensable. Kubernetes has a variety of
algorithms that determine the kind of distribution of
traffic, thus allowing organizations to fine-tune their
configurations to specific needs (Farley, 2019a). It
preserves a uniform experience for the users,
regardless of heavy traffic.
Kubernetes also offers self-healing capabilities
that make applications resilient. It keeps track of the
health of the containers and takes corrective measures
automatically upon discovering any problems. For
example, if there is a failure or the container is
hanging, Kubernetes might restart the container or
replace with a new one without human interven- tion
(Bhargava, 2019). The self healing capability is
crucial for support in maintaining high availability
and reliability, especially in large scale applications
where a downtime would be costly.
Besides these features, Kubernetes also offers full
resource management. It makes the organization
define resource re- quests and limits to every
container; it therefore ensures that the applications
run well enough without a single applica- tion
monopolizing the infrastructure. This kind of
resource management is important in offering a
balanced environment, especially when the
infrastructure is cloud-based because resources can
be dynamically allocated (Daemon, 2018).
Another area where Kubernetes is helpful are
service dis- covery and load balancing that are
integral elements ensuring the smooth operation of
the microservices architecture. This will simplify the
intra-service communication among services by
using the predefined names instead of the IP
addresses. This abstraction would increase not only
the reliability of interactions among the services but
also make easier the introduction of new services and
updates.
In brief, Kubernetes is the need in the scaling of
current web applications as it covers self scaling, load
balancing, auto-healing features, and managing
resources. This allows organizations to have high
performance coupled with cost op- timization based
on availability. With increasingly scalable and
complex web applications, the need for such an
enabler like Kubernetes for developers and operations
teams is becoming ever more crucial in terms of
delivering reliable and resilient applications in the
cloud.
Containerization in Web Development: Docker and Kubernetes
167

Table 1: Comparison Between Key Features Of Docker
And Kubernetes
Feature Docke
r
Kubernetes
Primary
Purpose
Containerization and
image
management
Container
orchestration and
management
Deployment Single host
de
p
lo
y
ment
Multi-host
de
p
lo
y
ment
Scaling Manual scaling Automatic scaling
Load
Balancin
g
Basic load balancing Advanced load
b
alancin
g
Networking Simple networking
model
Complex
networking with
services
Storage Local storage
solutions
Persistent storage
and dynamic
p
rovisioning
Management Docker CLI and
Docke
r
Com
p
ose
kubectl, Helm
charts
Health
Monitoring
Basic health checks Advanced health
monitoring
an
d
self-healing
Resource
Management
Limited resource
management
Comprehensive
resource
management
Service
Discover
y
Basic service
discover
y
Built-in service
discover
y
State
Mana
g
ement
Stateless containers Stateful sets and
mana
g
ement
Community
Support
Large community
with many resources
Strong community
and
ecos
y
ste
m
5 CASE STUDY: MONOLITHIC
VS. CONTAINERIZED
DEPLOYMENT IN A FINTECH
STARTUP
5.1 Background
Besides the fact that the online payment company
has got a system that was not designed to make it easy
for them to customize or expand their system
according to their needs. This means that if they want
something to be brought into their system, they have
to run the entire process through the same that they
run. It required a large amount of money in addition
to taking a significant amount of time.
They handled this issue by changing the system
architecture. They switched to a microservices
architecture with containers. Docker was building
these containers, and Kubernetes was controlling the
performance of these containers. It will hence- forth
help in making them versatile as well as proficient.
5.2 Objectives
The key objectives of the transition were:
• Reduced deployment time: Reduced
time to deploy new features.
• Increased uptime and scalability:
Increased availability to meet traffic
bursts.
• Optimal resource usage: Reduced
cost of infrastructure through
dynamic allocation of resources
5.3 Approach
The monolithic application was broken into smaller
ser- vices, each one deployed as a Docker container.
Kubernetes orchestrated these containers, managing
auto-scaling and re- source allocation during peak
traffic periods.
5.4 Metrics and Quantitative Results
Table 2: Comparison Of Monolithic Vs. Containerized
Deployment Metrics
Metric
Monolithic
Deployment
Containerized
Deployment
(Docker +
Kubernetes)
Deployment
Time
3–5 hours per
release
45 minutes per
release (60%
reduction)
U
p
time 98.5% avera
g
e
99.9% avera
g
e
Feature
Rollout Rate
1
feature/month
3–4 features/month
(300–400%
increase
)
Resource
Utilization
Underutilized
during low
traffic
30% lower CPU
usage with
Kubernetes
o
p
timization
Cost
Savings
High fixed
costs
25% reduction via
dynamic scaling
Peak
Response
Time
2.5 seconds
1.2 seconds (52%
reduction)
Scalability
Manual
scaling
Auto-scaling
handle
d
3x traffic
5.5 Outcomes
• Deployment Speed: 60% faster
deployments speeded up development
cycles. Uptime: Kubernetes maintained
99.9% uptime during high traffic.
• Cost Savings: Infrastructure costs
lowered by 25% by dynamic scaling..
INCOFT 2025 - International Conference on Futuristic Technology
168
• Scalability: The system handled 3x traffic
without manual intervention.
• Response Time: Reduced peak latency
by 52%, improv- ing user experience.
5.6 Analysis of Results and Graphical
Representation
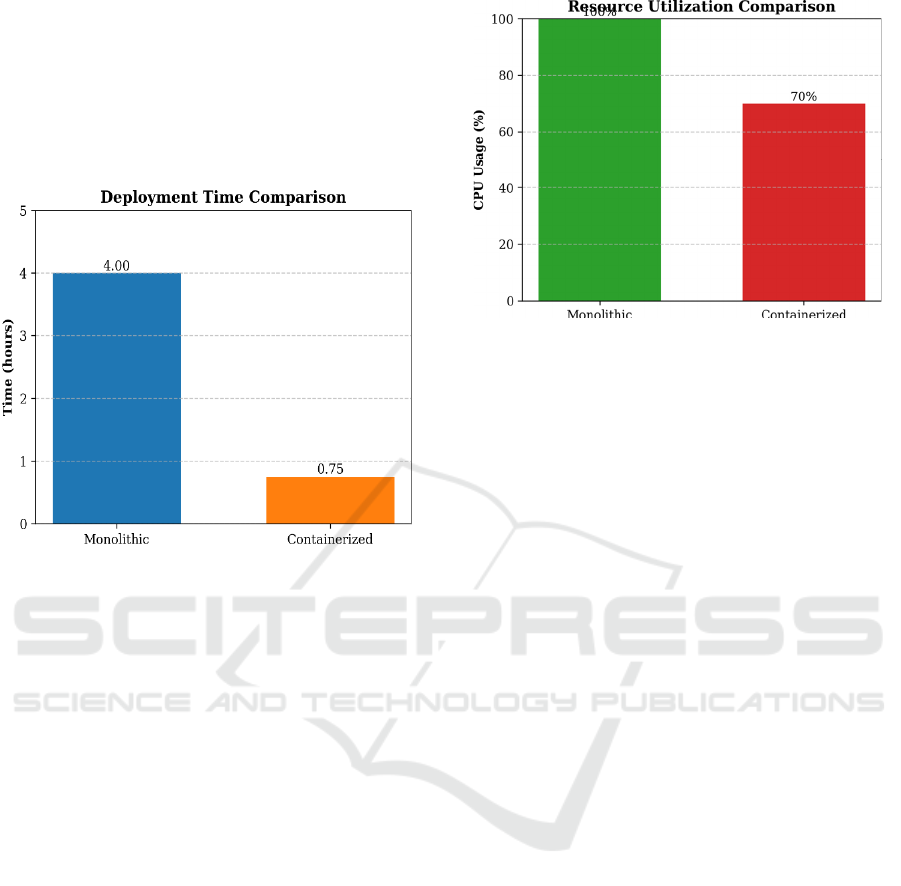
Figure 3: Deployment Time Comparison
The graphical comparisons in Fig. 3 and Fig. 4
demonstrate the transformative impact of
containerization on the fintech startup’s operations.
Fig. 3 highlights a 60% reduction in deployment time,
directly attributable to Docker’s lightweight
containers and Kubernetes’ declarative orchestration.
By elim- inating manual configuration and enabling
parallelized work- flows, the startup accelerated
feature delivery while maintain- ing consistency
across environments.
Fig. 4 highlights Kubernetes’ dynamic resource
manage- ment, which saved 30% of CPU usage
during off-peak hours. This is a result of Kubernetes’
Horizontal Pod Autoscaler (HPA), which
dynamically scales pod replicas according to current
demand. For example, during peak hours, HPA scaled
pods from 5 to 20 to ensure sub-second latency, and
scaling down during off-hours saved on idle resource
expenditures.
Collectively, these findings confirm the synergy
between Docker’s environment consistency and
Kubernetes’ auto- scaling features to attain the twin
goals of agility and cost- effectiveness delineated in
Section V.B
Figure 4: Resource Utilization Comparison
5.7 Conclusion
By adopting Docker and Kubernetes, the startup
achieved faster deployments, reduced costs, and
improved scalability, demonstrating the
transformative potential of containerization in high-
traffic environments.
6 SECURITY IN DOCKER AND
KUBERNETES
As container usage goes up so do security threats—
it’s crucial to secure while using tools like Docker and
Kubernetes that offer built-in security features.
6.1 Common Security Threats in
Containerized Environments
Some usual risks include:
• Privilege Escalation: If configured
poorly attackers might exploit this for
advantage against host systems (Brown,
2020).
• Insecure Images: Using outdated or
unverified images from public sources
can expose vulnerabilities (Narayan,
2020).
• Network Exposures: Allowing open
access without con- trols increases risks
for unauthorized breaches.
6.2 Best Practices for Securing Docker
and Kubernetes
To minimize such risks organizations must
follow:
Containerization in Web Development: Docker and Kubernetes
169

• Use Trusted Images: Always use official
or verified images after scanning them
before any deployment.
• Minimize Privileges: Avoid using root
access; instead apply user namespaces
limiting access effectively.
• Enable Network Policies: Set policies
controlling com- munication between
pods improving overall security
structures within clusters (Smith, 2020).
Ongoing auditing is crucial; keeping up to
date can help address new vulnerabilities as they
appear.
7 DEPLOYING AND
MANAGING CONTAINERS
WITH KUBERNETES
7.1 Kubernetes Deployment Process
Kubernetes brings a lot of revolutionary changes into
how applications are deployed and managed within
containerized environments. It is fundamentally
based on a declarative model of application
management, whereby developers state what
exactly they want their application to be, but not
how the current state can be achieved through listing
out detailed commands and actions to achieve that
state. This enables developers to configure key
components of the applications. For example, how
many replicas or pods are required, what container
image to be applied, and all of the requirements in
terms of resources for a given application component.
Through this, it enables Kubernetes to allow
organizations to have as much automation as well as
consistency in the different processes of deployment
as possible (Daemon, 2018).
This makes the deployment within Kubernetes
always begin with the creation of a Deployments
resource, which is akin to the blueprints for an
application. It has been noticed that by default, it
happens that a configuration file for Deployment
happens to be a YAML file, so it is easy for a
developer to accurately specify what he wants out of
the application in the most concrete terms. The
YAML file will have a good number of the basic
components, including the name assigned to the
application; the number of replicas to be created; the
container image to use; and any additional
configurations required for the application to behave
as it should (Daemon, 2018). For instance, a simple
Deployment YAML file could be defined to ensure
three replicas of a web application are active and
running, through the use of a particular image from a
container registry. Now that the Deployment YAML
has been defined, we can apply the configuration to
the Kubernetes cluster using its command-line
interface, kubectl. The kubectl apply command takes
the YAML file and commands the provision of corre-
sponding resources on the cluster. At this point,
Kubernetes takes over responsibility for managing
the application so that the actual state of the system
matches that specified in the YAML file. Any
anomaly that may occur due to pod deployment, for
example, when a pod fails or is unresponsive will be
self corrected by Kubernetes to re-achieve the desired
state (Farley, 2019a).
One more compelling advantage of applying
Kubernetes to deploy an application is that the
intrinsic scaling of ap- plications occurs. Developers
are able to scale quickly as more replicas, that is, pods
needed in real-time. This can either be done
automatically or manually. For instance, the number
of replicas can be scaled up using the command
kubectl scale if, for example, traffic in the application
has increased. Conversely, they can scale down the
number of replicas when the demand becomes low.
Kubernetes also offers a feature called Horizontal
Pod Autoscaler (HPA) that can adjust the number of
replicas automatically based on the observed metrics
of CPU utilization and other parameters. This is
critical to the performance and resource efficiency in
dynamic environments (Bhargava, 2019).
In addition, Kubernetes enables rolling updates so
that developers can deploy a new version of their
application without downtime. Kubernetes replaces
old versions with new ones in such a manner that
users suffer minimal disruption. Developers can
specify update strategies in the configuration of a
Deployment, which also includes controlling how
updates are rolled out and monitored. This flexibility
would especially
be highly useful in production environments
where uptime must be maintained (Brown, 2020).
Furthermore, Kubernetes boosts the management
of appli- cation resources by supporting resource
requests and limits. Developers can declare the
minimum and maximum amount of resources
assigned to each pod, thus allowing an application to
have enough resources to run efficaciously while
preventing resource contention between applications
running within a cluster. It happens to be one of the
significant factors for optimizing resource usage and
health of the overall Kubernetes cluster (Narayan,
2020).
INCOFT 2025 - International Conference on Futuristic Technology
170

The integration with service discovery is another
critical part of the deployment process into
Kubernetes. While deploying an application to
Kubernetes, it automatically assigns a stable IP
address and a DNS name to every service, so other
compo- nents can communicate easily. It simplifies
inter-service com- munication, especially for
microservices architectures, which generally need
multiple services to interact properly for the delivery
of an application’s complete functionality.
Abstracting away service discovery and load
balancing, Kubernetes frees developers to focus on
building and scaling applications with- out worrying
about network configurations in the dark (Smith,
2020).
In summary the deployment process by
Kubernetes em- powers developers to define and
manage their applications in an organized manner. It
does so by providing them with key parameters
regarding replicas, images, and resource needs to
ensure consistency and automated deployments
across their en- vironments. Other than the
simplification of scaling and updat- ing of
applications, Kubernetes further enhances resource
man- agement as well as service discovery. Since
more organizations have begun using Kubernetes for
container orchestration, the process of deployment
becomes an important element in their application
development and operational strategies, leading to
innovation and agility within today’s rapidly
changing digital environment (Dyer, 2021).
7.2 Methods and Materials
Deployment on Kubernetes, in general, begins
systemat- ically by composing a well-structured
YAML configuration file. Then the structure it
provides is used to make the actual deployment of the
application feasible because developers can
encompass all the critical constituent parts, including
container images, the number of replicas, or pods, and
many configura- tions necessary for proper operation
of the application. YAML is another way to say
’defining the deployment specifications, and its usage
represents a clear, human-readable format that
developers and operators may refer to in developing
and understanding the deployment configurations
with much ease (Daemon, 2018).
The most initial step of the deployment process is
creating the YAML configuration file, which
contains several key sections. The top of the file is
represented by apiVersion field, which states what
version of the Kubernetes API to use, and the kind
field represents that it is a Deployment of which type
of resource is being defined. In the metadata section,
there are meta-data about the deployment, such as
name for the
deployments and labels that can be used for
organization and identification (Farley, 2019a). This
structured approach ensures that the Kubernetes API
interprets and can administer the deployment
correctly.
In spec, developers define the desired state of the
appli- cation. In this case, how many replicas to
create, defining the number of instances of the
application running at any given time. Specifying
multiple replicas is essential to achieve high
availability and load-balancing so that the application
can manage different levels of user traffic without
undergoing any deterioration in performance. Every
replica runs in its own pod, which the basic unit of
deployment in Kubernetes (Bhargava, 2019).
The selector field in the spec section holds a prime
position in linking the deployment to the
corresponding pods. This helps Kubernetes identify
which pods belong to the deploy- ment through
defining matching labels for the pods. Labeling is the
most fundamental mechanism in rolling updates,
scaling, and other operational tasks since it helps
Kubernetes recognize pods and thus manage them
accordingly. For example, during a rolling update,
Kubernetes detects the pods to update with the new
release over time through the labels defined in the
selector (Brown, 2020).
Another important part of the YAML file that
describes the pod specification is the template
section. Developers define the image to be used in the
containers, which comes with configurations like
environment variables, ports, and resource requests
and limits inside this section. The name provided for
an image defines the specific image of a container to
use that must originate from either a public or private
container registry. For example, a basic deployment
will be using an image like Node.js straight from
Docker Hub, whereas a complex application will use
several images running for different services
(Narayan, 2020).
The ports field explains which ports the container
exposes to let traffic in and out of the application.
Developers can also specify resource requests and
limits to ensure that the application needs to access a
certain amount of CPU and memory resources. This
makes it possible to maintain the level of performance
of the application and prevent resource competition
in a multi-tenant mode (Smith, 2020). With these
specs defined in the YAML file, developers can enjoy
an increased level of control over their applications
and, hence increased reliability and scalability.
Containerization in Web Development: Docker and Kubernetes
171

After the YAML configuration file has been
created, devel- opers will apply it to the cluster using
the CLI, specifically the kubectl command. For
instance, the command kubectl apply -f
deployment.yaml reads the YAML file and gives
instructions to Kubernetes to deploy the deployment
according to the configurations depicted in the
YAML file. From then on, the control plane of
Kubernetes takes over to make sure that the real world
state of the application finds its meeting in the one
described in the YAML file (Dyer, 2021). If, for any
reason, something is not right, like a pod doesn’t start
or does not provision with the defined resource
requirements, Kubernetes feeds back in events and
logs that make it very easy for developers to identify
and resolve problems accordingly.
Here’s an example YAML Deployment file:
Conclusion: Techniques and resources used in
deploying applications in Kubernetes revolve around
the process of creating a detailed YAML
configuration file. This file holds critical features
such as the information about images, counts of
replicas, and pod specifications enabling developers
to describe and manage applications in an efficient
manner. Empowered by YAML and Kubernetes CLI,
organisations will now automate all the deployment
processes to ensure consistency and reliability
throughout the environments built for the
applications. As organizations embrace Kubernetes
more and more for container orchestration, learning
nuances about a deployment process is one of the
most crucial steps in order to be able to negotiate the
complexities of modern application development and
deployments (Finkelstein, 2020)
8 CONCLUSION
Containerization has brought major improvements to
web development—affording developers tools
tailored for smoothly running scalable applications
everywhere consistently via Docker while
automating management processes through fea- tures
provided by Kubernetes.
Together they support the foundation under
modern prac- tices seen throughout DevOps fields
today! With growing trends towards microservices
plus increasing adoption rates comes an urgent need
surrounding effective security measures too! So by
streamlining deployments this allows teams focus
squarely back onto building great applications while
maintain- ing reliability overall!
Future studies will investigate AI-powered
autoscaling in Kubernetes with predictive analytics
and blockchain-based auditing for container security.
Integration with serverless architectures (e.g.,
Knative) may further improve resource allocation in
dynamic environments.
REFERENCES
Ang, C. J. (2021). Kubernetes for developers: A step-by-
step guide. Software Development Lifecycle Journal,
7(5), 16–25.
Bhargava, A. (2019). Kubernetes and high availability:
Strategies for modern applications. IEEE Spectrum,
56(11), 31–35.
Brown, J. (2020). Securing containers: A guide to best
practices. Cybersecurity Trends, 22(7), 20–25.
Burns, B., Grant, B., Oppenheimer, D., Brewer, E., &
Wilkes, J. (2016). Borg, Omega, and
Kubernetes. Communications of the ACM, 59(5), 50–
57. https://doi.org/10.1145/2907881
Chen, H. R. (2020). Scaling microservices: Techniques and
challenges. ACM Transactions on Internet Technology,
20(4), 22–42.
Daemon, D. (2018). Managing Kubernetes
deployments. Container Orchestration Monthly, 9(4),
12–16.
Dyer, A. T. (2021). A practical guide to Kubernetes
security. Cloud Security
Alliance. https://cloudsecurityalliance.org
Farley, G. (2019). Scalable web apps with
Kubernetes. IEEE Cloud Computing Magazine, 6(2),
14–18.
Farley, K. (2019). DevOps and the future of
containerization. Software Development Trends, 12(4),
50–57.
Finkelstein, N. P. (2020). Microservices in action: How
Docker and Kubernetes transform software
development. Journal of Software Engineering, 11(2),
78–95.
Goldstein, R. P. (2017). The rise of containerization in web
development. Journal of Web DevOps, 15(3), 22–33.
INCOFT 2025 - International Conference on Futuristic Technology
172

Green, P. (2019). The role of containers in microservices
architecture. International Journal of Cloud Computing
and Services Science, 8(1), 27–35.
Hightower, K., Burns, B., & Beda, J. (2017). Kubernetes:
Up and running. O’Reilly Media.
Li, T. H. (2020). Best practices for securing Kubernetes
clusters. Journal of Cybersecurity, 10(3), 33–41.
McCarthy, L. (2022). Performance optimization strategies
for Kubernetes. Journal of Cloud Computing Research,
5(2), 22–30.
Merkel, D. (2014). Docker: Lightweight Linux containers
for consistent development and deployment. Linux
Journal, 2014(239), 2–9.
Narayan, S. (2020). Container image security: Risks and
mitigation. Cloud Security Journal, 10(1), 45–52.
Patil, S. K. (2022). A survey of container orchestration
systems. International Journal of Computer
Applications, 182(17), 11–17.
Smith, M. (2020). Network policies in Kubernetes:
Enhancing security. Journal of Cloud Computing, 8(3),
19–27.
Turnbull, J. (2014). The Docker book: Containerization is
the new virtualization. Lopp Publishing.
Containerization in Web Development: Docker and Kubernetes
173
