
Sentiment Analysis of Indian Political Tweets: A Comparative Study
with LSTM and RNN Model
Swati V. Bhat, Vidhi R. Patel, Om R. Muddapur, Chandanagouda H., Uday Kulkarni
and Sunil Gurlahosur
School of Computer Science and Engineering, KLE Technological University, Hubli, India
Keywords:
Sentiment Analysis, Machine Learning, Deep Learning Models, LSTM, RNN, Indian Political Tweets,
Word2Vec, TF-IDF, Political Discourse.
Abstract:
Sentiment analysis has emerged as one of the prime focuses in machine learning, particularly with the rise
of social media platforms such as X (formerly Twitter), Reddit, Instagram, and Facebook. These platforms
are now central to public conversations, including discussions on politics, generating massive amounts of
data through tweets and comments. The study focuses on applying existing deep learning models to the
underexplored domain of sentiment analysis of Indian political tweets. The objective is to determine whether
models such as LSTM and RNN are applicable to the analysis of Indian political sentiment. The study uses
advanced natural language processing techniques, such as Term Frequency-Inverse Document Frequency (TF-
IDF) and Word2Vec, for feature extraction to represent tweet text. The research is testing these models on
a new and unique dataset of Indian political tweets to find out which model and feature combination best
suits this specific context. Experimental results show that TF-IDF embeddings, along with LSTM and RNN
models, significantly outperform Word2Vec in sentiment classification with accuracy rates of 83.02% and
81.06%, respectively. These findings demonstrate the potential of LSTM with TF-IDF to effectively analyze
political discourse on social media and suggest insights into the suitability of existing models for Indian
political sentiment analysis.
1 INTRODUCTION
The explosive growth of social media platforms
such as Twitter, Reddit, Instagram and Facebook
has fundamentally changed how people commu-
nicate, exchange information, and express their
views(Duncombe, 2019). These platforms have be-
come integral to global conversations, enabling users
to engage in real-time discussions on a wide range of
topics (Madakam and Tripathi, 2021). Among them,
Twitter stands out as a platform of choice for dynamic
public discourse. Its simplicity, and accessibility al-
low users to express thoughts and opinions on var-
ious matters, including politics, a subject that con-
sistently evokes strong reactions and vibrant debates
(Park, 2013).
Politics has always been a major topic in society.
On X (formerly Twitter), people regularly discuss cur-
rent affairs, express their opinions about policies, and
assess the deeds and choices of political figures. This
enormous number of conversations is a gold mine of
public opinion, providing priceless insights into the
opinions, worries, and goals of the population (Re-
search, 2021). These insights can be used by ana-
lysts, researchers, and policymakers to better under-
stand public sentiment, guide choices, develop gover-
nance plans, and even promote cross-border coopera-
tion.
The problem lies in the current limitations of sen-
timent analysis research on social media platforms
like Twitter. Most studies focus on specific events
or use basic methods that classify opinions simply as
positive or negative, missing the finer emotional de-
tails, layered trends, and complexities of public dis-
cussions. Additionally, many existing approaches fail
to use advanced computational techniques to capture
the context and subtleties of text data. This creates a
gap in understanding the full spectrum of public sen-
timent, especially in the diverse and fast-evolving po-
litical landscape of India, where refined insights are
crucial for informed decision-making and meaningful
participation.
The paper addresses the challenge of analyzing
Indian political sentiment by evaluating the suitabil-
Bhat, S. V., Patel, V. R., Muddapur, O. R., H., C., Kulkarni, U. and Gurlahosur, S.
Sentiment Analysis of Indian Political Tweets: A Comparative Study with LSTM and RNN Model.
DOI: 10.5220/0013584000004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 1, pages 701-706
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
701
ity of existing deep learning models such as LSTM
and RNN. It aims to test whether these models can
effectively capture the complexity of public senti-
ment in India’s rapidly evolving political landscape.
This study extracts meaningful features from tex-
tual data by using advanced text representation tech-
niques such as Term Frequency-Inverse Document
Frequency (TF-IDF) (Qaiser and Ali, 2018b) , (Liu
et al., 2018) and Word2Vec (Jatnika et al., 2019).
These models are then applied to analyze contextual
aspects of political tweets.Providing valuable insights
for future research in Indian political sentiment anal-
ysis.
The paper is structured to comprehensively ad-
dress the objectives of the study, with Section 2 pro-
viding a detailed background study that reviews ex-
isting sentiment analysis techniques such as TF-IDF,
Word2Vec (Lei, 2020), LSTM and RNN. This sec-
tion also explores their applications in social me-
dia analysis, with a focus on prior research in po-
litical sentiment analysis, emphasizing the strengths
and limitations of current approaches,highlighting
the description of existing models.Then in section 3
the proposed methodology is outlined, detailing the
use of advanced text representation and deep learn-
ing techniques, such as TF-IDF for feature extrac-
tion, Word2Vec for contextual word embedding, and
LSTM and RNN models for sequential data analysis.
It also describes the process of data cleaning, prepro-
cessing, and model training, ensuring accuracy and
efficiency. And in section 4 the experimental results
are discussed in-depth, including a comparative anal-
ysis of the proposed methods using metrics like ac-
curacy, recall, precision, and F1-score, accompanied
by visualizations that provide insights into sentiment
distribution and polarity trends. Then in the final sec-
tion 5 the paper concludes with a summary of the key
findings and their implications for understanding pub-
lic sentiment in Indian politics,along with a discus-
sion on potential future research directions, such as
expanding the methods to other domains or exploring
advanced sentiment analysis.
2 BACKGROUND STUDY
Several techniques have been developed for sentiment
analysis, particularly machine learning approaches,
which are useful for improving the accuracy of senti-
ment classification across various domains, including
politics, finance, and social media.
Machine learning approaches have been exten-
sively explored. (Gangwar and Mehta, 2022) inves-
tigates Israeli political tweets, addressing challenges
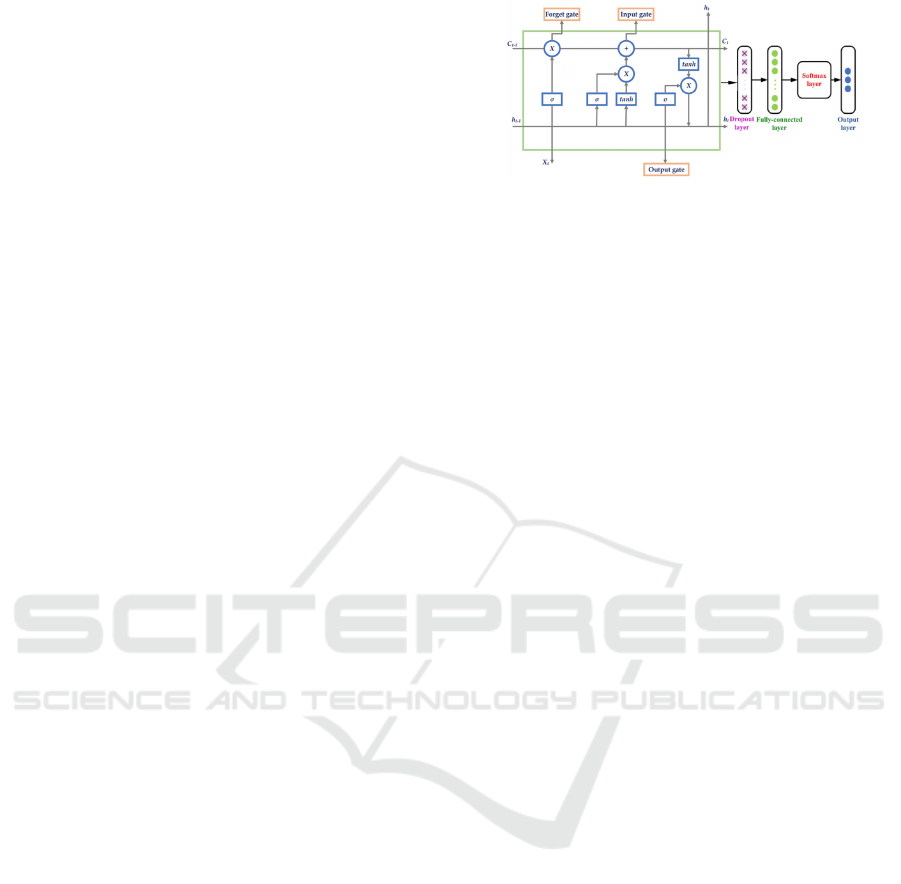
Figure 1: The internal structure of a single hidden unit in
an LSTM, visualizing the computation of h
t
and C
t
using
an input x
t
, the hidden state value of the previous unit h
t−1
,
and the cell state unit value of the preceding unit C
t−1
.
such as regional dialects and linguistic biases. Sim-
ilarly, (Hicham et al., 2023) emphasizes the effec-
tiveness of TF-IDF for sparse data, as elaborated in
(Qaiser and Ali, 2018a). Word2Vec, another fea-
ture representation, captures semantic relationships
between words, enhancing deep learning models like
LSTM networks and RNNs, as demonstrated in (Jat-
nika and Setiawan, 2020).
Advanced neural network models, such as LSTM
and RNN, have proven to be very effective for the
analysis of sequential data. LSTMs have an excel-
lent capability of capturing long-term dependencies
and are very effective for tasks like sentiment anal-
ysis on long-form text. For instance, (Paduri et al.,
2022) illustrates how LSTM can model temporal pat-
terns, while (Murthy et al., 2020) has demonstrated its
ability in analyzing the sentiment within complex text
structures. The architecture of an LSTM network, as
described in (Darji, 2021), is presented in Figure 1. It
depicts the internal structure of a single LSTM cell,
including its gating mechanisms, namely the input,
forget, and output gates, which control the flow of in-
structions.
RNNs, on the other hand, are well-suited for tasks
involving shorter or fragmented text, such as tweets
or reviews, due to their ability to model sequential
dependencies. Studies like (Kurniasari and Setyanto,
2020) and (Thomas and C A, 2018) emphasize the
utility of RNNs in sentiment classification. The archi-
tecture of RNNs, as visualized in (Stier et al., 2021),
is depicted in Figure 2. It highlights their sequential
processing structure, where hidden states are passed
from one time step to the next, enabling RNNs to cap-
ture temporal patterns effectively.
Despite the advancement in sentiment analysis,
the Indian political tweets are still not well explored.
Models like LSTM and RNN have been promising,
but their performance on Indian political tweets has
not been fully tested. Techniques like TF-IDF and
Word2Vec work well for feature extraction, but it is
unknown how effective they are when combined with
these deep learning models. This gap can be filled by
INCOFT 2025 - International Conference on Futuristic Technology
702

Figure 2: A simple Recurrent Neural Network unfolded
over t time steps, where U represents input-to-hidden
weights, W represents hidden-to-hidden weights, and V rep-
resents hidden-to-output weights.
using LSTM and RNN models with these text repre-
sentation techniques to analyze the unique sentiment
in Indian political tweets.
3 PROPOSED WORK
To understand the sentiment behind political tweets
in the Indian context, we need a thoughtful and struc-
tured approach. This section highlights the strategies
and methods used to analyze and make sense of these
sentiments effectively.Figure 3 illustrates the end-to-
end workflow applied for sentiment analysis of Indian
political tweets.
Figure 3: Workflow: Step-by-step process for sentiment
analysis of political tweets.
3.1 Methodology and Implementation
This section provides a detailed overview of the mod-
els, methodologies, and their implementation strate-
gies employed for analyzing sentiment in Indian po-
litical tweets. By delving into the computational tech-
niques and tools used it aims to offer a comprehensive
understanding of how sentiment analysis was con-
ducted. The focus is on outlining the approaches
used to process and interpret the vast amount of tex-
tual data, providing information about how these tech-
niques were applied to extract meaningful insights
from the public discourse on Indian politics.
3.1.1 Data Preprocessing
The dataset has been refined to enhance its suitabil-
ity for analysis. This involved preparing plain text
versions of the tweets by removing stopwords, extra
whitespaces, usernames, and punctuation. Addition-
ally, case folding was applied, duplicate entries were
eliminated, and rows without tweets were removed.
Irrelevant columns such as date and user details have
been dropped to come up with a cleaner version of
the dataset. The Natural Language Toolkit (NLTK)
pre-trained ’punkt’ English tokenizer was used to split
longer tweets into individual words.
3.1.2 Lexicon Based Sentiment Analysis
The dataset was unlabeled, which consisted only of
tweets without classification into positive, negative, or
neutral categories. Sentiment analysis was performed
to compute the sentiment in terms of the semantic ori-
entation of words or phrases in the tweets.This was
achieved using the python package TextBlob, which
returns the polarity of the text. The polarity values
range from -1 to 1, with negative sentiment at -1, neu-
tral at 0, and positive at +1.
3.1.3 Text representation methods
In this subsection, we take a closer look at the tech-
niques used to create word embeddings and evaluate
the importance of words in a tweet.The methods in-
clude:
a) Word2Vec : In analyzing Indian political tweets,
Word2Vec helps to represent a text in a way that cap-
tures the context and meaning of words, making it
easier to identify subtle sentiments and topics in po-
litical discussions. Its ability to preserve the relation-
ships between words allows machine learning models
to perform better by utilizing the created word em-
beddings.
Figure 4 shows the Word2Vec architecture(Zhang,
2019) applied to political tweets on the sample tweet
”should we laugh or cry who is calling whom corrupt
jokers of Indian politics.” The tweet is tokenized and
the Skip-gram approach is used to learn word embed-
dings by predicting the context of a target word. Each
word is represented as a vector, capturing semantic
relationships to reflect the meaning and context in po-
litical discourse.
b) TF-IDF : It is use to measure the importance of
words in each tweet relative to the entire dataset. TF
calculates how often a word appears in a tweet, us-
ing methods like raw frequency or logarithmic nor-
Sentiment Analysis of Indian Political Tweets: A Comparative Study with LSTM and RNN Model
703

Figure 4: Word2Vec Neural Network Architecture: Illustra-
tion of the model used to convert words into vector repre-
sentations for semantic analysis.
malization. IDF identifies significant terms by reduc-
ing the weight of commonly used words (stop words)
and emphasizing unique or less frequent words across
tweets. This helps highlight key terms like political
names and topics, enabling effective feature extrac-
tion for sentiment classification.
The TF-IDF weight of a term x in tweet y is:
w
x,y
= t f
x,y
× log
N
d f
x
(1)
where, t f
x,y
is the frequency of term x in tweet y, d f
x
is the number of tweets containing term x, N is the
total number of tweets.
3.1.4 Model Building
The dataset is divided into two sets training set (80%)
and testing set (20%). The training set is used to train
the LSTM and RNN models, thus enabling them to
learn from the data.
Both models take word embeddings as in-
put. These word embeddings are generated using
Word2Vec or TF-IDF. Each word in a tweet is rep-
resented as a vector, and the sequence of these word
embeddings is passed through the RNN and LSTM
models for sentiment analysis.
Data: Input sequence {x
t
}
T
t=1
Result: Predicted output sequence { ˆy
t
}
T
t=1
Initialize hidden state h
0
;
for t ← 1 to T do
Compute hidden state:
z
t
← U x
t
+W h
t−1
+ b
h
;
Apply activation function: h
t
← tanh(z
t
);
Compute output: o
t
← V h
t
+ b
o
;
Predict output: ˆy
t
← softmax(o
t
);
end
return { ˆy
1
, ˆy
2
, . . . , ˆy
T
};
Algorithm 1: RNN Model for Sequential Data Predic-
tion.
Algorithm 1 describes the working of the RNN
model, where each word is processed sequentially
over time steps t = 1 to T . At each step, the hidden
state h
t
is updated using the current word embedding
x
t
, the previous hidden state h
t−1
, and a bias term with
an activation function (tanh). The output o
t
is com-
puted from h
t
using a weight matrix and bias, and
the sentiment prediction ˆy
t
is obtained by applying the
softmax function.
Data: Input sequence {x
t
}
T
t=1
Result: Predicted output y
pred
Initialize parameters
W
i
, W
f
, W
o
, W
g
, b
i
, b
f
, b
o
, b
g
, W
f c
, b
f c
;
Initialize cell state c
0
and hidden state h
0
;
for t ← 1 to T do
Compute input gate:
i
t
← σ(W
i
[h
t−1
, x
t
] + b
i
);
Compute forget gate:
f
t
← σ(W
f
[h
t−1
, x
t
] + b
f
);
Compute output gate:
o
t
← σ(W
o
[h
t−1
, x
t
] + b
o
);
Compute candidate values:
˜c
t
← tanh(W
g
[h
t−1
, x
t
] + b
g
);
Update cell state: c
t
← f
t
⊙ c
t−1
+ i
t
⊙ ˜c
t
;
Update hidden state: h
t
← o
t
⊙ tanh(c
t
);
end
Compute final output: y ← W
f c
· h
drop
T
+ b
f c
;
Predict with softmax: y
pred
← softmax(y);
return y
pred
;
Algorithm 2: LSTM Model for Sequence-to-Output
Prediction.
Algorithm 2 describes the working of LSTM
model, where at each time step t, the input tweet is
processed by updating the input gate i
t
, forget gate f
t
and output gate o
t
. The candidate values ˜c
t
are used
to update the cell state c
t
, while the hidden state h
t
is
updated to capture relevant context. The final predic-
tion y
pred
is made by feeding the hidden state through
a fully connected layer followed by the softmax func-
tion.
After training the models for 10 epochs, predic-
tions are made using the unseen testing data based on
the patterns learned. Both models use the same hyper-
parameters with an embedding dimension of 1000, a
hidden dimension of 128, and a learning rate of 0.001.
INCOFT 2025 - International Conference on Futuristic Technology
704
4 EXPERIMENTAL RESULTS
AND ANALYSIS
The dataset for the analysis of Indian political tweets
in the study was obtained from Kaggle (Adritpal08,
2024). It contains 50,000 tweets along with informa-
tion like posting date, user details, and engagement
metrics such as likes and retweets. Figure 5 illustrates
the distribution of polarity across the dataset after pre-
processing, showcasing the sentiment breakdown of
the tweets.
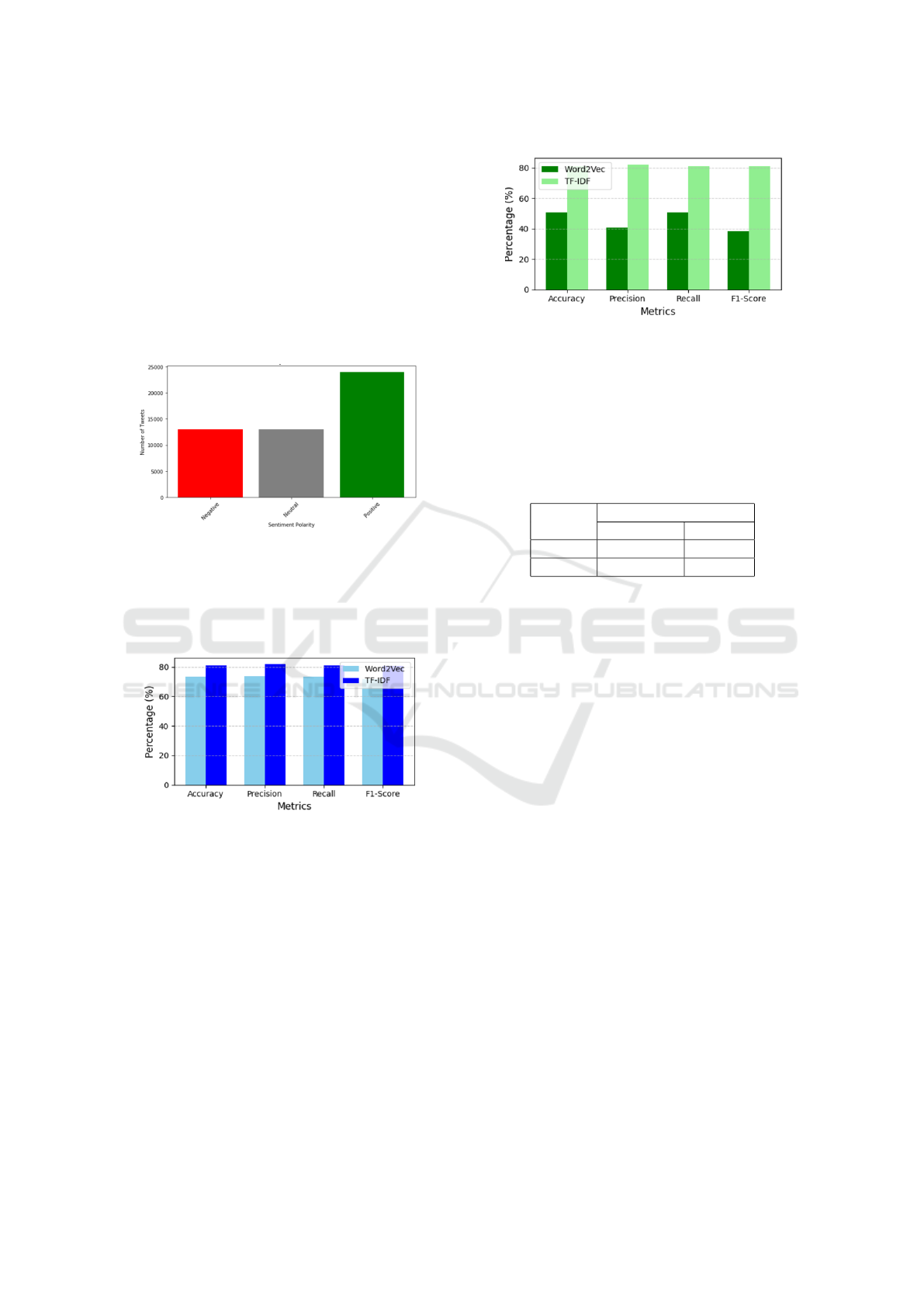
Figure 5: Sentiment polarity vs Number of Tweets.
The final training dataset includes about 24,000
positive tweets, 15,000 neutral tweets, and 13,000
negative tweets, which indicates most of the tweets
are positive, followed by neutral and then negative.
Figure 6: Performance matrics of LSTM in %.
Figure 6 shows how the LSTM model performs
using TF-IDF and Word2Vec representations across
different metrics. It is clear that the LSTM with TF-
IDF performs much better. This suggests that TF-
IDF captures the important features of the Indian po-
litical dataset more effectively. On the other hand,
Word2Vec which creates distributed word representa-
tions, may not fully capture the specific details and
context of this dataset.
In Figure 7, the performance metrics indicate that
the RNN model achieves better results with TF-IDF
compared to Word2Vec across all evaluated metrics.
This observation implies that, for the Indian politi-
cal tweets dataset, TF-IDF serves as a more effective
feature representation for sentiment analysis. The su-
Figure 7: Performance matrics of RNN in %.
perior performance with TF-IDF can be attributed to
its ability to highlight important terms, enabling the
RNN model to focus on relevant features, a benefit
that may not be as pronounced when using Word2Vec.
Consequently, TF-IDF emerges as the more suitable
choice for this task.
Table 1: Testing Accuracy of models with different tech-
niques.
Models Accuracy (%)
Word2Vec TF-IDF
LSTM 73.08 83.02
RNN 50.7 81.06
As observed in Table 1, the LSTM model with
TF-IDF outperforms the same model with Word2Vec,
achieving better performance across various metrics.
This indicates that TF-IDF offers more effective fea-
ture representations for the Indian political tweets
dataset when used with LSTM, highlighting its supe-
riority over Word2Vec embeddings for this task. The
enhanced performance of LSTM can be attributed to
its ability to capture long-range dependencies in the
text, which is essential for understanding the contex-
tual and nuanced nature of political sentiments. Un-
like RNNs, LSTMs are better equipped to retain im-
portant information across long sequences, making
them more suitable for task like sentiment analysis of
political tweets.
5 CONCLUSION AND FUTURE
WORK
This study compares the performance of LSTM and
RNN models for sentiment analysis of Indian politi-
cal tweets, filling the gap in the underexplored area of
Indian political sentiment analysis. The results show
that LSTM combined with TF-IDF delivers the high-
est accuracy of 83.02%, outperforming other combi-
nations such as Word2Vec (73.08%) and RNN with
either TF-IDF (81.06%) or Word2Vec (50.7%).These
Sentiment Analysis of Indian Political Tweets: A Comparative Study with LSTM and RNN Model
705

results show that the combination of LSTM with TF-
IDF is particularly effective in identifying key con-
textual features in political discourse, which shows
the strength of LSTM in capturing sequential patterns.
The study emphasizes the suitability of integrating ex-
isting deep learning models with text representation
techniques for sentiment analysis, providing valuable
insights into how these methods can be applied to the
domain of Indian political tweets.
In the future, the results of this study can be
further improved by refining feature extraction tech-
niques and exploring more advanced model archi-
tectures. Additionally, scaling the analysis to larger
and more diverse datasets could enhance the robust-
ness and generalizability of the findings. These ad-
vancements would provide deeper and more reliable
insights into public sentiment, making this research
even more impactful for understanding political dis-
course.
REFERENCES
Adritpal08 (2024). Dataset of indian politics tweets and
reactions. Accessed: 2024-12-24.
Darji, H. (2021). Investigating sparsity in recurrent neural
networks. Unpublished.
Duncombe, C. (2019). The politics of twitter: Emotions
and the power of social media. International Political
Sociology, 13(4):409–429.
Gangwar, A. and Mehta, T. (2022). Sentiment analysis
of political tweets for israel using machine learning.
arXiv preprint arXiv:2204.06515.
Hicham, N., Karim, S., and Habbat, N. (2023). Customer
sentiment analysis for arabic social media using a
novel ensemble machine learning approach. Int. J.
Electr. Comput. Eng, 13(4):4504.
Jatnika, D., Bijaksana, M., and Ardiyanti, A. (2019).
Word2vec model analysis for semantic similarities in
english words. Procedia Computer Science, 157:160–
167.
Jatnika, D. and Setiawan, A. A. A. (2020). Word2vec model
analysis for semantic word similarities. Indonesian
Journal of Computer Science, 12(3):45–57.
Kurniasari, L. and Setyanto, A. (2020). Sentiment analysis
using recurrent neural network. In Journal of Physics:
Conference Series, volume 1471, page 012018. IOP
Publishing.
Lei, S. (2020). Research on the improved word2vec opti-
mization strategy based on statistical language model.
In 2020 International Conference on Information Sci-
ence, Parallel and Distributed Systems (ISPDS), pages
356–359.
Liu, C.-z., Sheng, Y.-x., Wei, Z.-q., and Yang, Y.-Q. (2018).
Research of text classification based on improved tf-
idf algorithm. pages 218–222.
Madakam, S. and Tripathi, S. (2021). Social me-
dia/networking: Applications, technologies, theories.
Journal of Information Systems and Technology Man-
agement, 18.
Murthy, D., Allu, S., Andhavarapu, B., and Bagadi, M.
(2020). Text based sentiment analysis using lstm. In-
ternational Journal of Engineering Research and, V9.
Paduri, A. R. et al. (2022). Stock price prediction using sen-
timent analysis and deep learning for indian markets.
arXiv preprint arXiv:2204.05783.
Park, C. (2013). Does twitter motivate involvement in
politics? tweeting, opinion leadership, and politi-
cal engagement. Computers in Human Behavior,
29:1641–1648.
Qaiser, S. and Ali, M. (2018a). Text mining: Use of tf-idf to
examine the relevance of words. International Journal
of Computer Applications, 181(1):25–29.
Qaiser, S. and Ali, R. (2018b). Text mining: Use of tf-
idf to examine the relevance of words to documents.
International Journal of Computer Applications, 181.
Research, P. (2021). Political content on social
media. https://www.pewresearch.org/
political-content-social-media-2021/.
[Online; accessed 30-Nov-2024].
Stier, J., Darji, H., and Granitzer, M. (2021). Experiments
on properties of hidden structures of sparse neural net-
works.
Thomas, M. and C A, D. (2018). Sentimental analysis us-
ing recurrent neural network. International Journal of
Engineering and Technology(UAE), 7:88–92.
Zhang, J. (2019). Skip-gram neural network from scratch.
Accessed: Nov. 30, 2024.
INCOFT 2025 - International Conference on Futuristic Technology
706
