
Leveraging Distributional Reinforcement Learning for Performance
Optimization of Spark Job Scheduling in Cloud Environment
Sumit Kumar
1 a
, Vishnu Prasad Verma
2 b
and Santosh Kumar
2 c
1
Deptt. of CSE, UIET, Maharshi Dayanand University, Rohtak, Haryana, 124001, India
2
Deptt. of CSE, IIIT Naya Raipur, Raipur, Chhattisgarh, 493661, India
Keywords:
Apache Spark, Distributed Computing, Job Scheduling, Distributional Deep Reinforcement Learning, Big
Data, Performance Optimization, Cloud Computing.
Abstract:
Apache Spark is extensively utilized for processing massive data sets in fields like big data analytics and
machine learning. However, its performance is closely tied to how jobs are scheduled, and resources are
allocated, especially in dynamic cloud settings. The default Spark scheduler can sometimes struggle to effi-
ciently manage resources in diverse clusters, leading to delays, higher costs, and slower job completion. This
research introduces a new approach for optimizing Spark job scheduling using Distributional Deep Reinforce-
ment Learning (DDRL). Unlike other methods focusing on average performance, DDRL employs a Rainbow
Deep Q-Network to model the entire range of possible outcomes. This allows the system to better understand
the risks and uncertainties associated with scheduling decisions. Key features of our approach include multi-
step learning for long-term planning, techniques to encourage exploration and exploitation, and strategies for
adapting to rapidly changing workloads. Our experiments show that the proposed framework significantly
improves Spark’s performance. It achieves faster job scheduling, better resource utilization, and lower overall
costs than existing methods. These results demonstrate the potential of DDRL as a robust and scalable solution
for enhancing Spark scheduling in dynamic cloud environments
1 INTRODUCTION
Big data processing professionals rely heavily on dis-
tributed computing frameworks like Apache Spark.
Efficient job scheduling is crucial to harnessing
Spark’s full potential in cloud environments. Al-
though foundational, traditional algorithms like First-
In-First-Out (FIFO) and Fair Scheduling struggle
with dynamic workloads and heterogeneous clusters,
leading to suboptimal resource utilization and longer
job completion times (Gandomi et al., 2019).
Key factors influencing Spark job scheduling in-
clude data affinity, resource heterogeneity, Service
Level Agreement (SLA) objectives, data skew, inter-
job dependencies, and workload nature. Data affin-
ity affects execution and transmission times, requir-
ing sophisticated algorithms to minimize completion
time (Zhang et al., 2022). Resource heterogeneity, in-
cluding hardware capabilities and specific task needs,
a
https://orcid.org/0009-0000-8676-4017
b
https://orcid.org/0009-0009-5831-7258
c
https://orcid.org/0000-0003-2264-9014
must be considered for optimization, as seen in sys-
tems like RUPAM (Islam et al., 2021a). SLA ob-
jectives, such as cost minimization and performance
improvement, are critical, with RL models helping
to meet these in cloud-deployed Spark clusters (Is-
lam et al., 2021b). Data skew and deadline con-
straints complicate scheduling, necessitating algo-
rithms to manage rental costs and meet deadlines (Gu
et al., 2020). If unmanaged, inter-job dependencies
can lead to job failures, highlighting tools like the
Wing dependency profiler (Cheng et al., 2018). The
workload nature, including streaming data, demands
adaptive scheduling approaches like A-scheduler (Li
et al., 2020) (Xu et al., 2018). Hybrid cloud en-
vironments add complexity, requiring algorithms to
optimize costs and meet deadlines through various
VM Average pricing (Cheng et al., 2017). Effi-
cient scheduling must also minimize communication
costs associated with cross-node data transfers, as
seen in locality-aware task scheduling algorithms (Fu
et al., 2020). These factors underscore the need for
advanced and adaptive algorithms to optimize job
scheduling in Spark.
Kumar, S., Verma, V. P. and Kumar, S.
Leveraging Distributional Reinforcement Learning for Performance Optimization of Spark Job Scheduling in Cloud Environment.
DOI: 10.5220/0013582600004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 1, pages 615-623
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
615

However, to resolve the issues mentioned above,
the rise of Deep learning-based solutions is prolifer-
ating due to emerging applications for futuristic big
data processing and leveraging new possibilities for
intelligent job scheduling in cloud computing (Cao
et al., 2024). Among these, distributional deep rein-
forcement learning (DDRL) stands out by learning the
entire distribution of possible computed rewards, pro-
viding a deeper understanding for agents to make cor-
rect decisions to optimize job scheduling as compared
to traditional Deep Reinforcement Learning (DRL),
which emphasizes maximizing predicted maximum
return (Li, 2023) for completion of jobs in cloud com-
puting which leverages to solve severe issues influ-
encing Spark job scheduling. DDRL is beneficial in
cloud environments where dynamically increasing the
size of jobs, execution times, and requirement of dis-
tributional resource availability in dynamic changes.
In this work, a novel framework is proposed to
utilize the potential of using a DDRL technique to
optimize Spark job scheduling efficiently. By inte-
grating the DDRL technique with Spark’s schedul-
ing mechanisms, the primary objective of this work
is to create a strategy with superior adaptability and
robustness, dynamically adjusting to evolving work-
loads and resource conditions to achieve high perfor-
mance. Moreover, the primary goal extends to mini-
mizing overall execution time on jobs and maximiz-
ing resource utilization to ensure job deadlines are
met.
The remainder of the paper is structured as fol-
lows: Section 2 provides a related work, Section 3
outlines the proposed methodology, Section 4 offers
a detailed analysis of experimental setup, Section 5
analyzes the result and performance comparisons. Fi-
nally, Section 6 provides concluding remarks with fu-
ture scopes.
2 RELATED WORKS
Efficiently scheduling jobs in Apache Spark is crucial
for maximizing resource utilization and performance,
especially in cloud environments. Researchers have
explored various approaches to tackle challenges like
ensuring data is processed where it’s stored, handling
fluctuating workloads, and dealing with diverse com-
puting resources. This section examines Spark’s dif-
ferent job scheduling techniques, including traditional
and more recent methods. By reviewing these ap-
proaches, we can identify areas for improvement and
understand the motivations behind the research pre-
sented in this work.
The study in (Cheng et al., 2017) integrates a dy-
namic batching technique with an A-scheduler, which
uses an expert fuzzy control mechanism to adjust the
length of each batch interval according to the time-
varying streaming workload and system processing
rate. The research in (Fu et al., 2020) introduces a
new task scheduling algorithm for Spark applications
that focuses on reducing data transfer between nodes
and racks, which can slow down performance and
cause network congestion. Using a bipartite graph
model, the algorithm aims to find the best way to
schedule both map and reduce tasks, ensuring that
data locality is optimized for better performance.
The study in (Venkataraman et al., 2016) proposes
a performance prediction framework named Ernest
that accurately predicts the running time of analytics
jobs on specified hardware configurations, focusing
on minimizing the training data required for accurate
predictions. The paper (Alipourfard et al., 2017) in-
troduces CherryPick, a system that employs Bayesian
Optimization to construct performance models for di-
verse applications. These models are sufficiently pre-
cise to identify the best or nearly optimal configura-
tion with minimal test runs. CherryPick characterizes
each cloud configuration using parameters such as the
number of VMs, the number of CPUs, the speed per
CPU core, RAM per core, disk quantity, disk speed,
and the VM’s network capacity. It utilizes the Gaus-
sian Process as a prior in Bayesian Optimization, rec-
ognized for its effectiveness as a surrogate model and
computational feasibility for large-scale problems.
The paper (Yadwadkar et al., 2017) presents
PARIS, a data-driven system designed to accurately
estimate workload performance and associated costs
for various user-specified metrics across multiple
cloud services operators. PARIS employs a mixed
framework that combines offline and online data gath-
ering and processing. It surpasses advanced base-
lines, such as collaborative filtering and linear inter-
polation models, by reducing forecast at execution
time errors by a factor of 4 for specific workloads
on AWS and Azure. This results in a 45% reduction
in user costs while maintaining performance. Spark
on YARN lacks energy efficiency and deadline con-
trol, to overcome this problem the study (Shabestari
and Navimipour, 2023) introduces a system designed
to reduce energy usage in Spark running on YARN
within diverse clusters, while also ensuring deadlines
are met. It achieves this with a deadline-aware model,
locality-aware executor assignment, and a heuristic
task scheduler.
Existing research has made progress in address-
ing challenges like dynamic resource allocation and
data skew in Spark scheduling. However, effectively
managing resources in diverse cloud environments re-
INCOFT 2025 - International Conference on Futuristic Technology
616

mains an ongoing challenge. Distributional Deep Re-
inforcement Learning (DDRL) offers a potential so-
lution by considering the full range of possible out-
comes, not just average rewards. This study extends
previous work by developing a framework integrat-
ing DDRL with Spark’s scheduling mechanisms. The
goal is to create a more robust and adaptive system
that overcomes limitations identified in prior research.
3 METHODOLOGY
3.1 Problem Formulation
Let M stand for the overall number of virtual ma-
chines (VMs) in the cluster, and L signify the overall
number of jobs. The scheduler allocates executors on
VMs based on resource capacities and job demands.
Each Job’s resource demand in CPU and memory is
modeled as a multi-dimensional box. The resource
constraints are:
∑
a∈E
(p
cpu,a
× y
a j
) ≤ r
cpu, j
∀ j ∈ S (1)
∑
a∈E
(p
mem,a
× y
a j
) ≤ r
mem, j
∀ j ∈ S (2)
An executor is placed for task P in VM j if the
binary decision variable y
a j
is 1; otherwise, it is 0.
Executors cannot use combined resources from mul-
tiple VMs:
∑
j∈S
y
a j
= 1 ∀a ∈ E (3)
The scheduler’s total cost is:
Cost
aggregate
=
∑
j∈S
(r
price, j
× r
T, j
) (4)
The average job completion time is:
AvgT =
∑
b∈J
T
job,b
L
(5)
The optimization goal is to minimize:
γ × Cost + (1 − γ) × AvgT (6)
where γ ∈ [0, 1] is a user-defined parameter.
This NP-hard, mixed-integer linear programming
(MILP) problem becomes infeasible to solve opti-
mally as the number of jobs, executors, and cluster
size increases. While capable of handling large data,
heuristic algorithms often lack generalizability and
fail to capture workload and cluster architecture nu-
ances.
Our solution involves a cloud-based scheduling
system for batch workload balancing. It dynamically
assigns incoming batch jobs to clusters with changing
resources. Batch jobs { job1, job2, . . . , jobN} arrive
sequentially, each consisting of multiple parallel tasks
{task j, 1, task j, 2, . . . , task j, O}. The Task instances
to be executed can be spread across multiple VMs,
starting with matching CPU and memory needs.
The scheduling agent plans based on current re-
source needs and cluster usage. The instance creation
process verifies if a VM meets SLA constraints:
InsSuccess =
(
ins
cpu
≤ r
Avl
cpu
ins
mem
≤ r
Avl
mem
(7)
Table 1: Symbolic Annotations and Their Meaning
Notation Meaning
M Total virtual machines in a cluster
L Total user-requested jobs
O Overall tasks in ongoing job
P Quantity of instances required for
the task at the moment
α VM indices, α = {1, 2, . . . , M}
β Job indices, β = {1, 2, . . . , L}
γ Task indices in the job, γ =
{1, 2, . . . , O}
δ The task’s instantiation identifiers,
δ = {1, 2, . . . , P}
r
cpu
Max CPU capacity available in VM
r
i
, i ∈ α
r
mem
Max memory capacity available in
VM r
i
, i ∈ α
r
cpuAvl
Available CPU of VM r
i
, i ∈ α
r
memAvl
Available memory of VM r
i
, i ∈ α
j
obj
j-th job within group of jobs, j ∈ β
task
j,o
o-th task in within j-th job, o ∈ γ
insNum
j,o
The quantity of instance in task
j,o
insSucc
j,o
Instances created in task
j,o
ins
cpu, p
Demand for CPU resources in an
instance, p ∈ δ
ins
mem, p
Demand for memory resources in
an instance, p ∈ δ
3.2 Optimizing Spark Scheduling with
Distributional Reinforcement
Learning
Let S denote the state space of an Apache Spark job
in a cloud environment, where each state s ∈ S repre-
sents a configuration of allocated resources, includ-
ing CPU cores, memory units, and potentially net-
work bandwidth or disk space. The objective is to
Leveraging Distributional Reinforcement Learning for Performance Optimization of Spark Job Scheduling in Cloud Environment
617
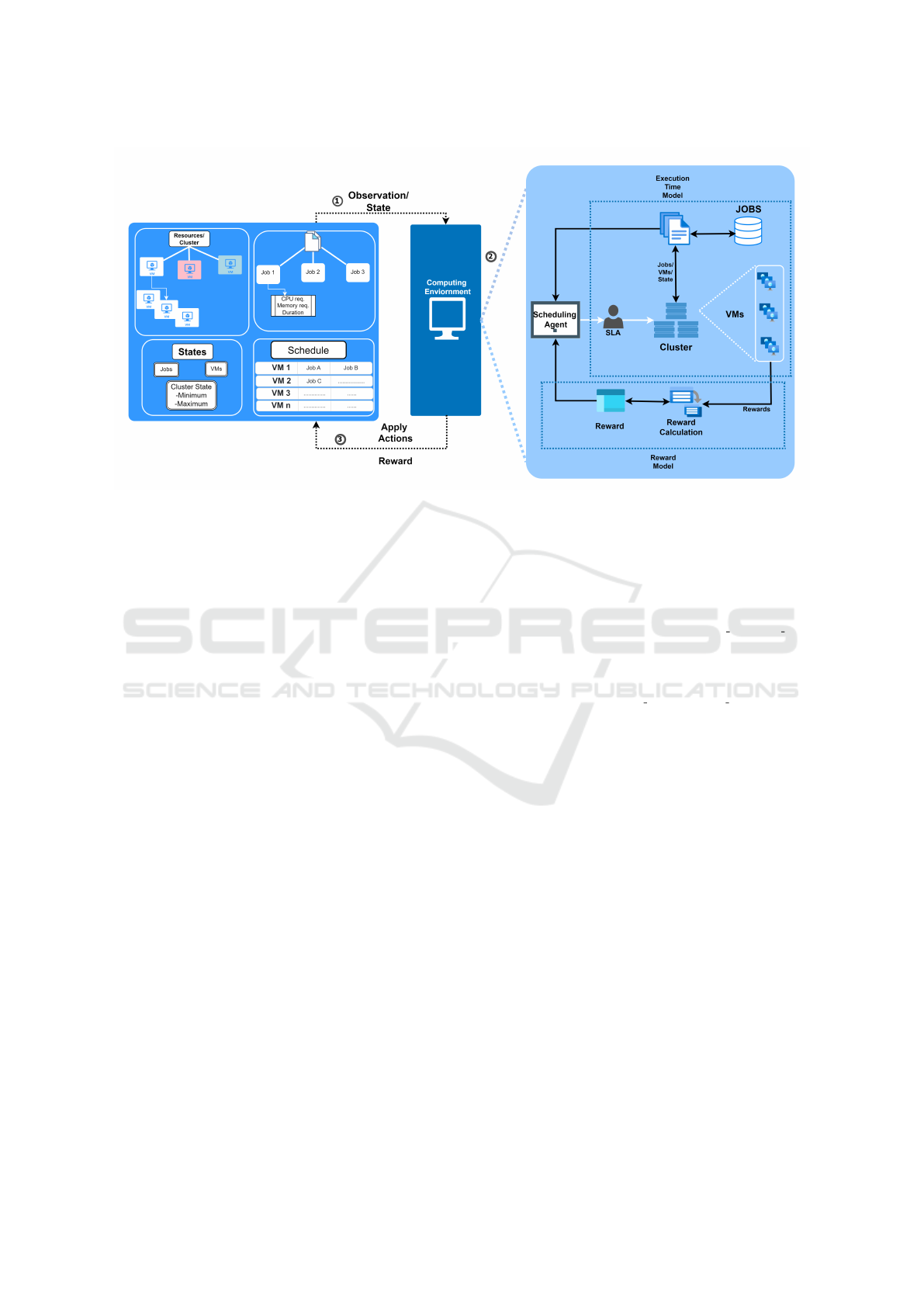
Figure 1: Proposed DRL Framework
determine an optimal policy, π
∗
, that specifies the re-
source allocation strategy to minimize the expected
cost while accounting for the inherent uncertainty in
job execution times. These times are influenced by
data size and distribution, resource availability, clus-
ter heterogeneity, and shuffle operations. Traditional
scheduling algorithms often rely on average resource
utilization metrics, which may not effectively capture
this variability.
3.2.1 Policy Optimization
The objective to find the policy π
∗
that minimizes the
expected cost is determined by:
π
∗
= argmin
π
E
s∼S
E
a∼π(s)
E
T ∼P(T |s,a)
[C(s, a, T )]
,
(8)
The policy π
∗
is optimized using DDRL. Instead of
predicting average rewards, DDRL models the en-
tire reward distribution, accounting for variability and
risks in resource allocation decisions. DDRL opti-
mizes CPU, memory, and network bandwidth alloca-
tion in Spark, considering average execution time and
outliers. This results in robust resource management
that adapts to workload fluctuations and cloud envi-
ronment uncertainties.
3.2.2 Model Formulation
The success of DDRL for multi-objective optimiza-
tion depends on the state space, action space, and
reward function. These components for batch task
load balancing scheduling are shown in Fig: 1 and
are specified as follows:
Temporal State: The current scheduling environ-
ment is a two-part, one-dimensional vector. The first
component of this vector represents cluster resource
load:
s1 = [l
Cpu1
, l
Mem1
, . . . , l
CpuN
, l
MemN
, l
Cpu avg
, l
Mem avg
]
(9)
Where l
Cpu1
, . . . , l
CpuN
are the CPU loads and
l
Mem1
, . . . , l
MemN
are the memory loads of all VMs
Cloud infrastructure. l
Cpu avg
and l
Mem avg
the mean
workloads. The machine load is normalized between
0 and 1 for better precision and efficacy.
The second component of the vector represents a
task instance’s resource needs:
s
2
= [taskType, insCpu, insMem, insNum] (10)
where insCpu and insMem are the CPU and memory
needs, taskType is the task index, and insNum is the
overall number of instances. The overall state of the
scheduling environment is:
s = s
1
+ s
2
(11)
Action Space: A virtual machine is chosen by the
scheduling agent for instance creation. Each of the M
distinct actions corresponds to one of the M machines
in the cluster:
A = {a | a ∈ {1, 2, . . . , M}} (12)
Reinforcement Signal: The RL model’s training
relies on the Reinforcement Signal, also known as re-
ward function r, with signals indicating the quality of
the agent’s actions. Positive signals/rewards signify
beneficial actions, while negative signals/rewards de-
note detrimental ones. SLA limitations are analyzed
INCOFT 2025 - International Conference on Futuristic Technology
618
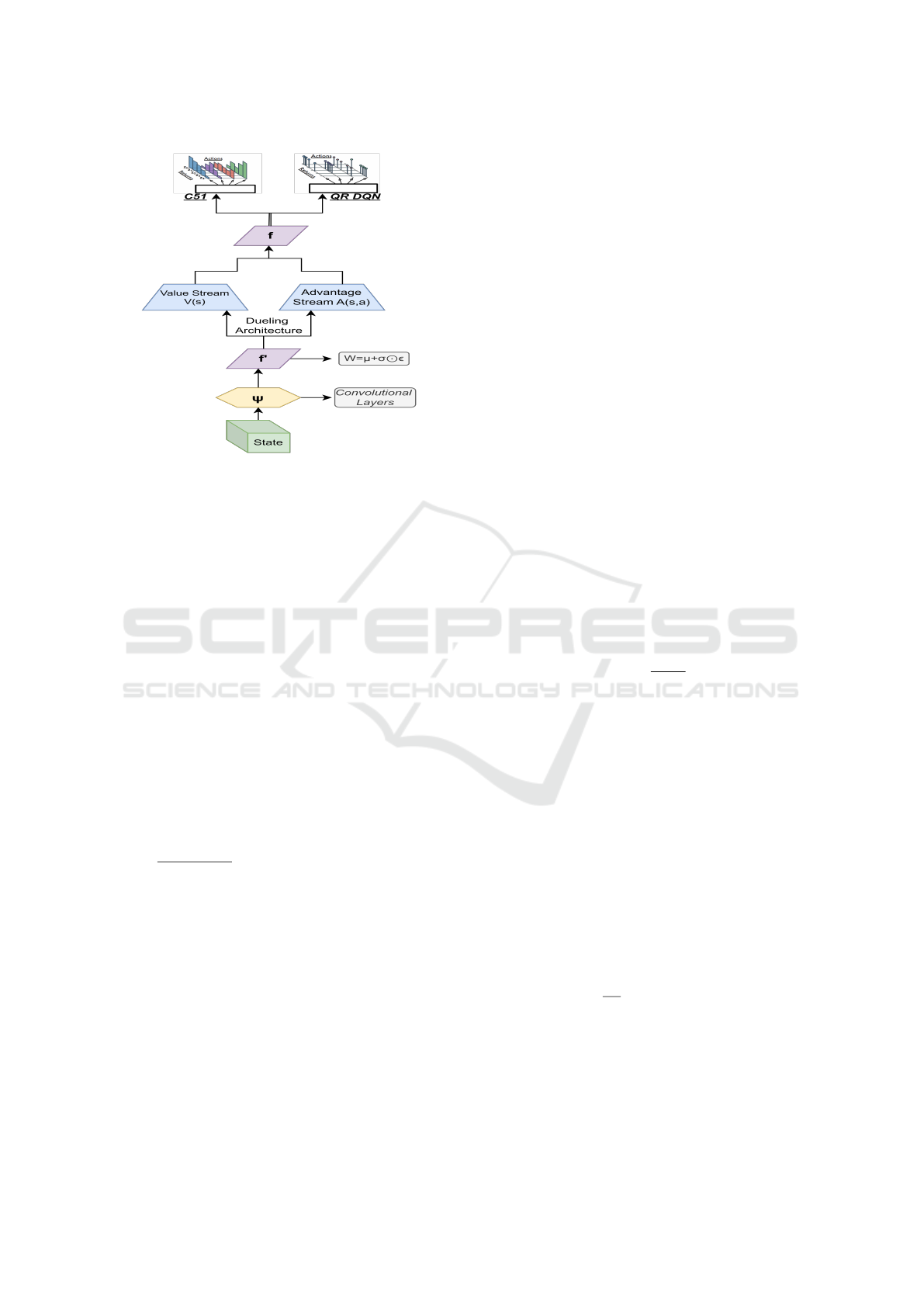
Figure 2: Network architectures for Rainbow-DQN distri-
butional RL algorithms
first; if criteria are breached, the VM fails to meet in-
stance creation requirements, resulting in r = −1. The
reward is then adjusted based on the cluster’s load bal-
ancing variances, calculated to distinguish between
average cluster load and individual cluster load VM
scheduling for the current instance. Load differences
in CPU and memory are represented by dvCpu and
dvMem.
dvCpu = lC pu
avg
− lCpu
i
(13)
dvMem = lMem
avg
− lMem
i
(14)
Load balancing aims to keep all VM load as close
to the cluster’s average load as possible. A posi-
tive divergence value indicates that the chosen virtual
machine’s load surpasses the cluster’s average load,
hence such a machine should not be picked. When
SLA restrictions are satisfied, the reward mechanism
is defined as follows:
r =
(
1, if dvCpu ≥ 0 and dvMem ≥ 0
dvCpu+dvMem
2
, otherwise
(15)
3.3 Rainbow DQN: An Integrated
Approach to Deep Reinforcement
Learning
In Spark job scheduling, the RL environment sim-
ulates real workloads and includes cluster resource
constraints in the state space. A DRL agent’s ac-
tions, such as placing an executor, yield immediate
rewards and update the state based on VM and task
changes, as illustrated in figure 1. Agents aim to
complete all executors and collect episodic rewards
by managing resource availability and demand con-
straints. Rainbow DQN enhances deep reinforcement
learning by combining Double Q-learning, Prioritized
Experience Replay, Dueling Network Architectures,
Multi-step Learning, DRL, and Noisy Nets into one
framework, addressing DQN limitations and improv-
ing performance and stability, as shown in figure 2.
Double Q-learning
Double Q-learning reduces overestimation bias by
separating action selection and assessment. Rainbow
DQN maintains two networks: the online network
(θ
1
) for action selection and the target network (θ
2
)
for assessment. The update rule is:
Z(y, a;θ
1
) ← Z(y, a; θ
1
) + α
r + γZ(y
′
, argmax
a
′
Z(y
′
, a
′
;θ
1
);θ
2
) − Z(y, a; θ
1
)
(16)
Prioritized Experience Replay
Prioritized Experience Replay (PER) assigns a pri-
ority to each experience based on the temporal-
difference (TD) error. Experiences with larger TD
errors are more likely to be sampled. The sampling
probability for an experience j is:
P( j) =
p
β
j
∑
k
p
β
k
(17)
where p
j
is the priority of experience j and β con-
trols the prioritization level. Priority p
j
is adjusted by
the absolute TD error and a constant ε:
p
j
= |δ
j
| + ε (18)
Dueling Network Architectures
The Dueling Network Architecture separates the rep-
resentation of state values from action advantages.
The Q-value is divided into two parts: the state value
function U(x) and the advantage function A(x, b). The
Q-values are computed as:
Q(x, b;θ
1
, β, G) = U (x; θ
1
, G) + (A(x, b; θ
1
, β)
−
1
|B|
∑
b
′
A(x, b
′
;θ
1
, β)
!
(19)
Multi-step Learning
Multi-step learning improves the learning process by
considering cumulative rewards over multiple steps.
The k-step return R
(k)
t
is:
Leveraging Distributional Reinforcement Learning for Performance Optimization of Spark Job Scheduling in Cloud Environment
619

R
(k)
t
=
k−1
∑
m=0
G
m
r
t+m
+ G
k
U(x
t+k
) (20)
The Q-value update rule is:
Z(y
t
, b
t
) ← Z(y
t
, b
t
) + α
h
R
(k)
t
− Z(y
t
, b
t
)
i
(21)
Distributional Reinforcement Learning
DRL models the distribution of returns. Rainbow
DQN uses Categorical DQN (C51) to approximate the
return distribution:
Z(x, b) =
N
∑
i=1
p
i
δ
z
i
(22)
where z
i
are support points and p
i
are probabilities.
Noisy Nets
Noisy Nets introduce noise into network parameters
to facilitate exploration and are defined as:
W = µ + σ ⊙ ε (23)
Where W are noisy weights, µ and σ are learnable
parameters, and ε is a noise vector sampled from a
standard Gaussian distribution.
3.4 Designing the Agent by Integrating
the Enhancements
Rainbow DQN combines six enhancements for supe-
rior performance: Double Q-learning reduces over-
estimation bias by using two network weights (cur-
rent and target). Prioritized Experience Replay accel-
erates learning by sampling critical transitions more
frequently. The Dueling Network Architecture splits
the output into value and advantage streams for more
accurate value estimates. Multi-step Learning incor-
porates multi-step returns, capturing longer-term de-
pendencies by considering cumulative rewards over
multiple steps. Distributional Q-Learning predicts
a distribution over returns rather than a single Q-
value, providing a richer value function representa-
tion. Noisy Networks replace standard layers with
noisy layers, enhancing exploration through stochas-
ticity in network parameters.
These enhancements produce a robust, efficient,
consistent learning process, improving performance
in various RL tasks. Rainbow DQN also includes
functions ψ and f . The feature extractor ψ, typi-
cally convolutional layers, processes the input state
into a lower-dimensional feature representation. The
Q-value function f , the final fully connected layers,
takes ψ(x) and produces Q-values for each action, in-
corporating the enhancements of Rainbow DQN.
Table 2: Hyperparameters for Agent and Environment
Specifications Value
Rfixed 10000
Batch Size 128
Eval. Episodes 10
Policy Opt. Priority (γ) [0.0, 0.25, 0.50,
0.75, 1.0]
Q-Network Layers 200
Policy Eval. Interval 1000
Epsilon 0.001 or 0.1-1
Iterations 10000
Learning Rate 0.001/0.0009
Optimizer Adam
Discount Factor 0.9
Job Dur. Inc. for Bad
Placement
30%
Collect Steps/Iter. (DQN) 10
Collect Episodes/Iter. (RE) 10
Replay Buffer Size 10000
AvgTmin, AvgTmax
Profiled from
Actual Runs of Task
Valid Action Reward -1 or +1
AvgT, Costmax Dyn. Calculated
Invalid Action Reward -200
Target Update Period 100
N-Step Update 3
Alpha, Beta (Prioritized
Buf.)
0.6, 0.4
4 EXPERIMENTAL SETUP
DRL was integrated using TensorFlow, employing a
deep neural network policy architecture with multi-
ple layers and feature inputs. The training proce-
dure involved iterative episodes with an exploration-
exploitation strategy to minimize job execution times
and optimize resource usage. Various VM instance
types and price models were chosen to train and as-
sess an agent for cost minimization, analogous to an
actual cloud setting. The study employed three dis-
tinct VM types, differentiated by CPU specifications
and memory capacities. The DRL agents were re-
quired to have CPU cores and 128 GB of RAM. Ten-
sorFlow 2.11.0, TF-Agent 0.16.0, and Python 3.7.8
were installed on the machines. We developed a TF-
agent compatible environment to train multiple DRL
agents with various objectives; the hyperparameter
for agent and environment is shown in table 2. Re-
ward signals were designed to maximize cost effi-
ciency while reducing average job length. This envi-
ronment, named RB DDRL uses TensorFlow agents
and can be expanded for new rewards, continuous
states, and additional DRL agents. For the work-
load, we utilized the BigDataBench (Wang et al.,
2014) benchmark suite, selecting three distinct ap-
plications as jobs for the cluster: WordCount (CPU-
INCOFT 2025 - International Conference on Futuristic Technology
620
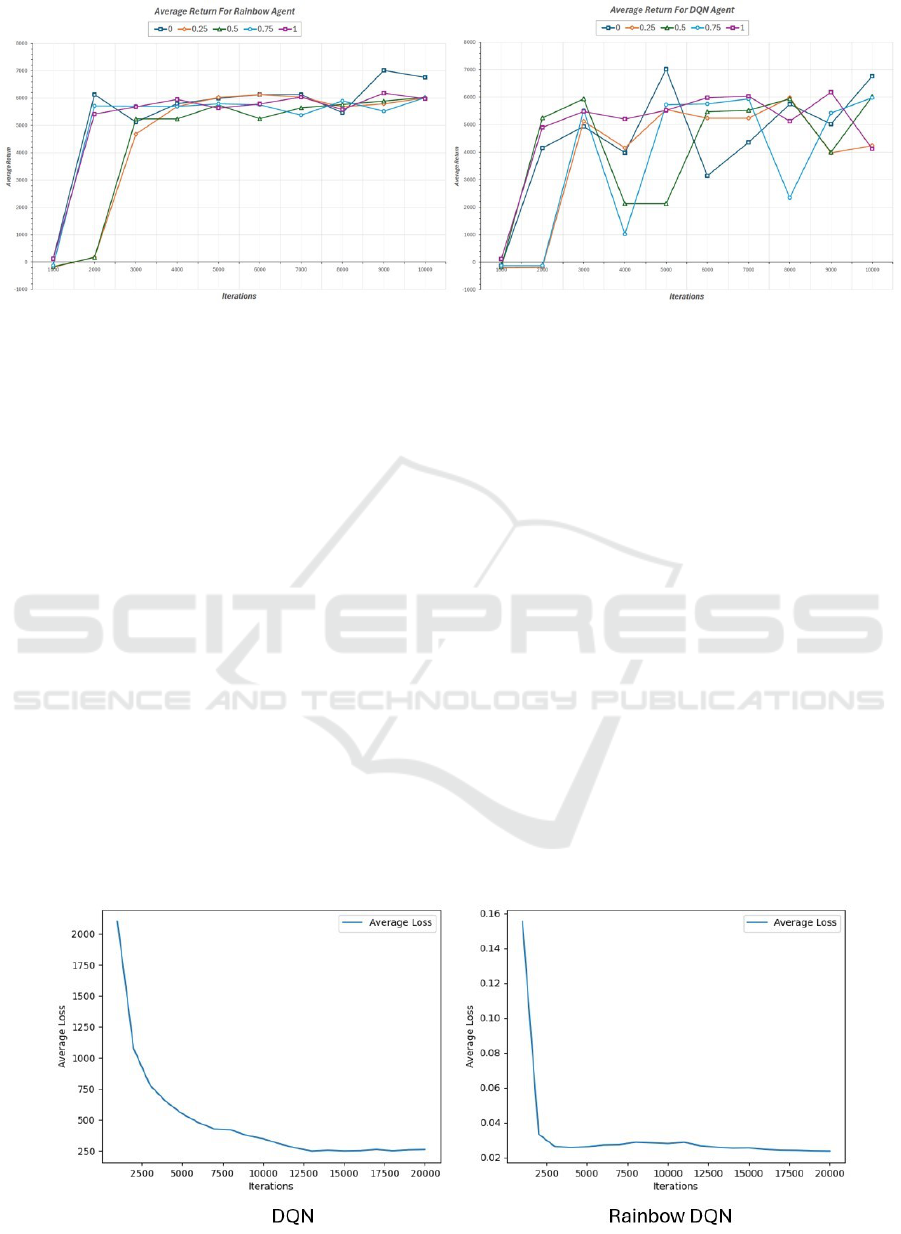
Figure 3: Average return for different γ values of Rainbow DQN and DQN agent
intensive), PageRank (network or I/O-intensive), and
Sort (memory-intensive). Job requirements were gen-
erated using a uniform distribution, with CPU cores
ranging from 1 to 6, memory ranging from 1 to 10
GB, and the total number of executors ranging from 1
to 8.
5 RESULT ANALYSIS
5.1 Convergence and Effectiveness of
DRL
Figure 3 shows Rainbow DQN’s convergence under
normal task arrival patterns in comparison to DQN
agent’s, which depicts the efficiency of the agent as
it very quickly adapted and balanced between ex-
ploration and exploitation and achieved convergence,
whereas DQN could not converge as efficiently as
Rainbow and showed numerous and many devia-
tions and fluctuations. We trained agents with dif-
ferent gamma values over 10,000 iterations to study
their impact on Average return and average rewards.
Episodic rewards vary based on cluster conditions
and task criteria. Figure 5 shows every agent ac-
tion’s step-by-step reward gained for it. The reward
pattern demonstrates Rainbow DQN’s effectiveness
in optimizing immediate and long-term rewards de-
spite occasional drops due to the epsilon-greedy pol-
icy, which helped find the most optimal one. Rain-
bow DQN balances resource allocation and task exe-
cution times in Spark scheduling. The policy π
∗
out-
performed traditional heuristics, exceeding theoreti-
cal expectations in real-world efficiency. The ease and
quickness of convergence and the multiple layers en-
sure more optimal usage of resources and execution
of jobs. The quicker the convergence is acquired, the
more efficiently the jobs will be executed, increasing
deadline adherence and promoting resource utiliza-
tion.
Figure 4: Comparison of Loss in DQN vs Rainbow DQN
Leveraging Distributional Reinforcement Learning for Performance Optimization of Spark Job Scheduling in Cloud Environment
621

5.2 Comparison of Loss in DQN and
Rainbow DQN
The optimized policy π
∗
using Rainbow DQN sig-
nificantly outperforms traditional scheduling meth-
ods DQN, reducing loss as shown in figure 4. This
enhances efficiency in execution time, CPU/memory
utilization, and job completion times. Rainbow
DQN effectively manages execution time uncertain-
ties (P(T | s, a)) and adapts dynamically to real-world
variability, surpassing deterministic approaches. It
also shows promising reward results, indicating op-
timal performance and effective learning from initial
negative rewards (Fig: 5).
Figure 5: Reward for each step for γ= 1.0
6 CONCLUSION AND FUTURE
DIRECTION
This study demonstrates the effectiveness of DRL in
enhancing Apache Spark scheduling within cloud en-
vironments. By modeling uncertainties in job exe-
cution times and dynamically adapting resource allo-
cations, DDRL-based policies significantly improved
cost efficiency and performance metrics. The reward
pattern highlights Rainbow DQN’s ability to optimize
both immediate and long-term rewards despite occa-
sional drops due to the epsilon-greedy policy. Ex-
periments showed that DDRL outperformed DQN
in minimizing loss and improving resource utiliza-
tion. The practical implications include cost savings
through efficient resource allocation, operational ef-
ficiencies via automated management, and scalability
to meet evolving computational demands. Leverag-
ing DRL for Spark scheduling offers a promising path
toward advancing distributed computing efficiency in
cloud environments. Future work will improve al-
gorithm convergence, refine reward functions, han-
dle dynamic workloads, and integrate factors such as
network bandwidth and disk I/O. Automated hyper-
parameter optimization will reduce complexity and
enhance DRL performance. Additionally, further ex-
ploration of DRL algorithms, deeper integration with
cloud-native features, and broader applicability across
diverse Spark workloads and infrastructures will be
prioritized.
REFERENCES
Alipourfard, O., Liu, H. H., Chen, J., Venkataraman, S., Yu,
M., and Zhang, M. (2017). Cherrypick: Adaptively
unearthing the best cloud configurations for big data
analytics. In 14th USENIX Symposium on Networked
Systems Design and Implementation (NSDI 17), pages
469–482.
Cao, Z., Deng, X., Yue, S., Jiang, P., Ren, J., and Gui, J.
(2024). Dependent task offloading in edge comput-
ing using gnn and deep reinforcement learning. IEEE
Internet of Things Journal.
Cheng, D., Chen, Y., Zhou, X., Gmach, D., and Miloji-
cic, D. (2017). Adaptive scheduling of parallel jobs
in spark streaming. In IEEE INFOCOM 2017-IEEE
Conference on Computer Communications, pages 1–
9. IEEE.
Cheng, D., Zhou, X., Wang, Y., and Jiang, C. (2018). Adap-
tive scheduling parallel jobs with dynamic batching in
spark streaming. IEEE Transactions on Parallel and
Distributed Systems, 29(12):2672–2685.
Fu, Z., Tang, Z., Yang, L., and Liu, C. (2020). An op-
timal locality-aware task scheduling algorithm based
on bipartite graph modelling for spark applications.
IEEE Transactions on Parallel and Distributed Sys-
tems, 31(10):2406–2420.
Gandomi, A., Reshadi, M., Movaghar, A., and
Khademzadeh, A. (2019). Hybsmrp: a hybrid
scheduling algorithm in hadoop mapreduce frame-
work. Journal of Big Data, 6(1):1–16.
Gu, H., Li, X., and Lu, Z. (2020). Scheduling spark tasks
with data skew and deadline constraints. IEEE Access,
9:2793–2804.
Islam, M. T., Karunasekera, S., and Buyya, R. (2021a).
Performance and cost-efficient spark job scheduling
based on deep reinforcement learning in cloud com-
puting environments. IEEE Transactions on Parallel
and Distributed Systems, 33(7):1695–1710.
Islam, M. T., Wu, H., Karunasekera, S., and Buyya, R.
(2021b). Sla-based scheduling of spark jobs in hybrid
cloud computing environments. IEEE Transactions on
Computers, 71(5):1117–1132.
Li, D., Hu, Z., Lai, Z., Zhang, Y., and Lu, K. (2020). Co-
ordinative scheduling of computation and communi-
cation in data-parallel systems. IEEE Transactions on
Computers, 70(12):2182–2197.
Li, S. E. (2023). Deep reinforcement learning. In Rein-
forcement learning for sequential decision and opti-
mal control, pages 365–402. Springer.
Shabestari, F. and Navimipour, N. J. (2023). An energy-
aware resource management strategy based on spark
and yarn in heterogeneous environments. IEEE Trans-
actions on Green Communications and Networking.
INCOFT 2025 - International Conference on Futuristic Technology
622

Venkataraman, S., Yang, Z., Franklin, M., Recht, B., and
Stoica, I. (2016). Ernest: Efficient performance pre-
diction for {Large-Scale} advanced analytics. In 13th
USENIX Symposium on Networked Systems Design
and Implementation (NSDI 16), pages 363–378.
Wang, L., Zhan, J., Luo, C., Zhu, Y., He, Y., Gao, W., Jia,
Z., Shi, Y., Zhang, S., Zheng, C., Lu, G., Zhan, K.,
Li, X., and Qiu, B. (2014). Bigdatabench: a big data
benchmark suite from internet services. Proceedings -
International Symposium on High-Performance Com-
puter Architecture.
Xu, L., Butt, A. R., Lim, S.-H., and Kannan, R. (2018). A
heterogeneity-aware task scheduler for spark. In 2018
IEEE International Conference on Cluster Computing
(CLUSTER), pages 245–256. IEEE.
Yadwadkar, N. J., Hariharan, B., Gonzalez, J. E., Smith,
B., and Katz, R. H. (2017). Selecting the best vm
across multiple public clouds: A data-driven perfor-
mance modeling approach. In Proceedings of the 2017
symposium on cloud computing, pages 452–465.
Zhang, X., Li, X., Du, H., and Ruiz, R. (2022). Task
scheduling for spark applications with data affinity on
heterogeneous clusters. IEEE Internet of Things Jour-
nal, 9(21):21792–21801.
Leveraging Distributional Reinforcement Learning for Performance Optimization of Spark Job Scheduling in Cloud Environment
623
