
Enhancing AI-Generated Code Accuracy: Leveraging Model-Based
Reverse Engineering for Prompt Context Enrichment
Boubou Thiam Niang
a
, Ilyes Alili, Benoit Verhaeghe
b
, Nicolas Hlad
c
and Anas Shatnawi
d
Berger-Levrault, Limonest, France
fi
Keywords:
Model-Based Reverse Engineering, Code Generation, Large Language Models, Prompt Engineering, Context
Enrichment.
Abstract:
Large Language Models (LLMs) have shown considerable promise in automating software development tasks
such as code completion, understanding, and generation. However, producing high-quality, contextually rele-
vant code remains a challenge, particularly for complex or domain-specific applications. This paper presents
an approach to enhance LLM-based code generation by integrating model-driven reverse engineering to pro-
vide richer contextual information. Our findings indicate that incorporating unit tests and method dependencies
significantly improves the accuracy and reliability of generated code in industrial projects. In contrast, simpler
strategies based on method signatures perform similarly in open-source projects, suggesting that additional
context is less critical in such environments. These results underscore the importance of structured input in
improving LLM-generated code, particularly for industrial applications.
1 INTRODUCTION
Large Language Models (LLMs) have emerged as
powerful tools in software engineering, enabling tasks
such as code completion (Husein et al., 2024), trans-
lation (Chen et al., 2018), repair (Olausson et al.,
2023), understanding (Nam et al., 2024), and gener-
ation (Fakhoury et al., 2024). These models can ac-
celerate software development and enhance developer
productivity (Noy and Zhang, 2023). However, LLM-
generated code often lacks contextual precision, lim-
iting its reliability in complex or domain-specific ap-
plications. The quality of generated code heavily
depends on structured inputs, like Prompt Engineer-
ing (Heston and Khun, 2023), to ensure relevance and
accuracy.
One challenge in LLM-driven code generation
is the limited domain knowledge of general-purpose
models (Saha, 2024), which can struggle with spe-
cialized terminology and domain-specific require-
ments (Gu et al., 2024). This highlights the im-
portance of incorporating structured input, such
as Model-Driven Engineering (MDE) (Claris
´
o and
a
https://orcid.org/0000-0002-8618-1740
b
https://orcid.org/0000-0002-4588-2698
c
https://orcid.org/0000-0003-4989-2508
d
https://orcid.org/0000-0002-5561-4232
Cabot, 2023), to align generated code with complex
and evolving specifications.
Various strategies have been explored to improve
the contextual accuracy of LLM-generated code, such
as structured prompt engineering (White et al., 2023),
iterative refinement (Madaan et al., 2024), grammar-
based augmentations (Ugare et al., 2024), and do-
main adaptation techniques, such as fine-tuning on
specialized datasets (Soliman et al., 2024) or inte-
grating external knowledge sources (Welz and Lan-
quillon, 2024). However, these methods still struggle
to fully capture contextual dependencies and evolv-
ing software specifications. This paper proposes en-
hancing LLM-based code generation through Model-
Based Reverse Engineering (MBRE) (Rugaber and
Stirewalt, 2004), which extracts structured input from
existing software artifacts to provide richer context.
Our study investigates the use of reverse-
engineered data in industrial and open-source
projects. We find that strategies leveraging unit tests
and method dependencies significantly improve code
accuracy in industrial settings, while simpler meth-
ods relying on method signatures perform similarly
in open-source projects. These results demonstrate
the impact of structured input, particularly in indus-
trial applications where richer context enhances code
maintainability and accuracy.
The key contributions of this paper are:
346
Niang, B. T., Alili, I., Verhaeghe, B., Hlad, N., Shatnawi and A.
Enhancing AI-Generated Code Accuracy: Leveraging Model-Based Reverse Engineering for Prompt Context Enrichment.
DOI: 10.5220/0013570300003964
In Proceedings of the 20th International Conference on Software Technologies (ICSOFT 2025), pages 346-354
ISBN: 978-989-758-757-3; ISSN: 2184-2833
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

1. MBRE-LLM Integration: We introduce a novel
approach that integrates Model-Based Reverse
Engineering (MBRE) with LLM-based code gen-
eration to improve code quality.
2. Context Augmentation Evaluation: We eval-
uate the impact of augmented context, such as
name, signature, unit tests and method depen-
dencies, on generated code across industrial and
open-source projects.
The remainder of this paper is structured as fol-
lows: Section 2 surveys the related literature. Sec-
tion 3 outlines the proposed approach. Section 4 de-
scribes the experimental setup and evaluation proce-
dures. Section 5 presents the results. Section 6 dis-
cusses the limitations of the study and directions for
future work. Finally, Section 7 concludes the paper.
2 RELATED WORK
Advances in code generation have leveraged tech-
niques such as abstract modeling, (LLMs, and Test-
Driven Development (TDD) (Mathews and Nagap-
pan, 2024). Recent research increasingly integrates
these approaches to improve both the correctness and
efficiency of generated code.
Model-Driven Prompt Engineering adapts princi-
ples from MDE to enhance prompt construction for
LLMs (Sadik et al., 2024). Clariso et al. (Claris
´
o
and Cabot, 2023) introduced Impromptu, a domain-
specific language (DSL) designed for platform-
independent prompt specification, addressing the
challenges of ad hoc prompt creation.
TDD, traditionally used in software engineer-
ing, has been extended to formal methods and sys-
tem modeling, including applications in timed au-
tomata (Zhang, 2004), formal verification (Munck
and Madsen, 2015), and constraint-based test-
ing (Zolotas et al., 2017). However, these studies pri-
marily focus on abstract modeling and do not directly
address unit test-driven code generation.
LLMs have gained significant traction in the con-
text of code generation. Research highlights the im-
pact of prompt quality on code correctness (Fagadau
et al., 2024) and the benefits of combining LLMs
with testing frameworks to enhance code reliabil-
ity (Gu, 2023). Mathews et al.(Mathews and Nagap-
pan, 2024) and Fakhoury et al.(Fakhoury et al., 2024)
further demonstrate how integrating TDD and test-
based guidance with LLMs can improve generation
outcomes.
While individual efforts have explored LLMs,
TDD, and MDE separately, limited work has exam-
ined their integration with reverse-engineered mod-
els. In particular, the use of MBRE to guide LLMs
in domain-specific code generation remains an open
area of research.
This work addresses that gap by integrating
MBRE artifacts, such as unit tests and method depen-
dency models, with LLMs to enhance the quality of
code generation in complex, domain-specific scenar-
ios.
3 APPROACH
This section presents our methodology that com-
bines Model-Based Reverse Engineering(Rugaber
and Stirewalt, 2004) and Prompt Engineering(Gao,
2023) to improve the accuracy of code generation us-
ing large language models (LLMs). This approach
ensures that generated code aligns with the project’s
architecture and requirements by leveraging reverse
engineering techniques and well-structured prompts.
The process comprises three main steps:
1. Automated Reverse Engineering: Analyzes the
existing codebase to produce an abstract model
capturing key components and dependencies.
2. Model Query and Information Extraction: Ex-
tracts relevant details (e.g., method signatures and
dependencies) from the model and formats them
into structured queries (e.g., JSON) to guide the
LLM.
3. Prompt Construction and Code Generation:
IUses the extracted data to build a detailed
prompt, ensuring the LLM-generated code aligns
with the project structure and requirements.
Figure 1 illustrates the overall process of our ap-
proach.
Figure 1: Overview of the Prompt Engineering Approach
for Accurate Code Generation via Reverse Engineering in
LLMs.
3.1 Automated Reverse Engineering
The first step involves analyzing the existing code
repository to generate an abstract model that rep-
resents key components such as classes, methods,
Enhancing AI-Generated Code Accuracy: Leveraging Model-Based Reverse Engineering for Prompt Context Enrichment
347
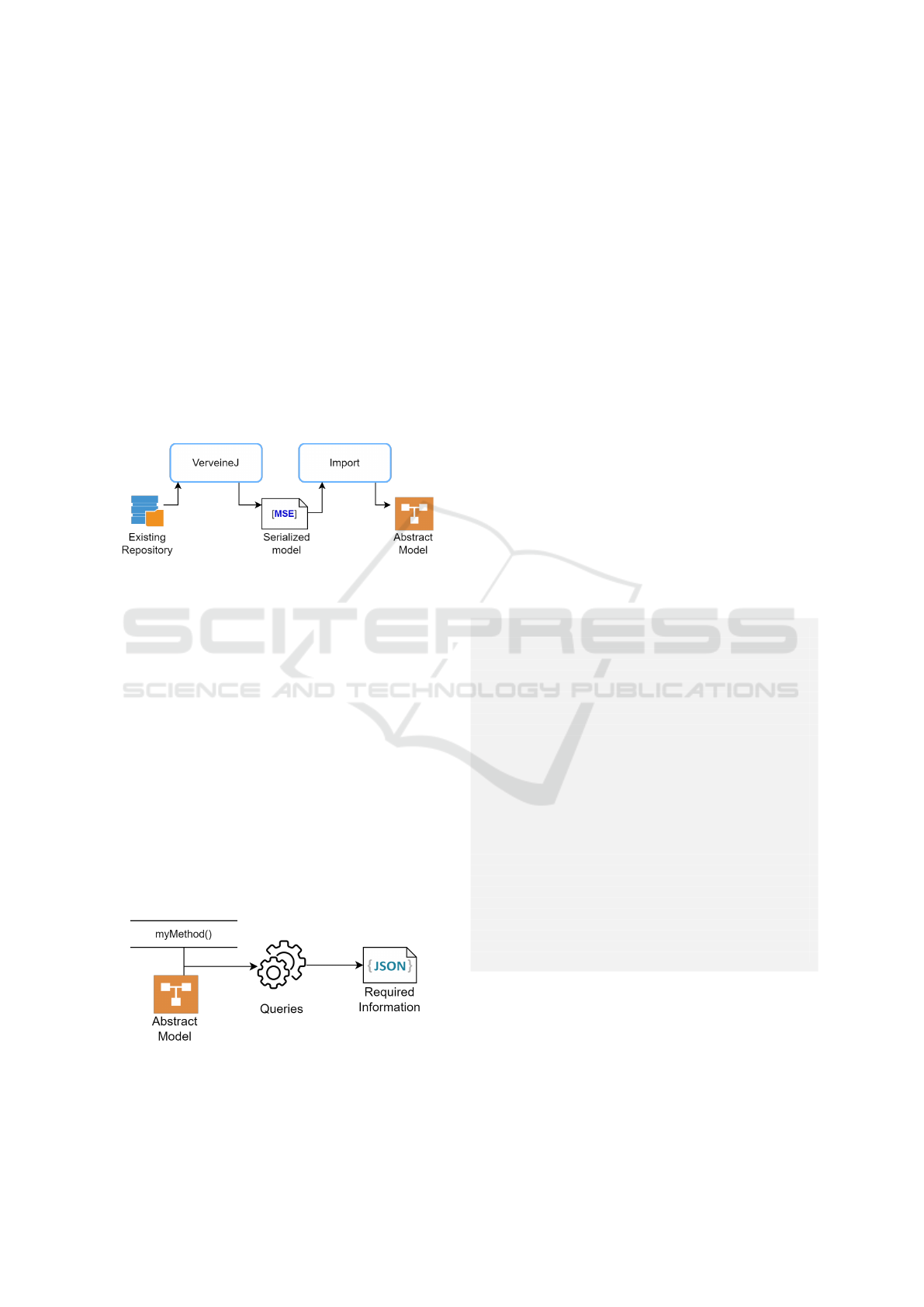
and dependencies. This model provides a founda-
tion for the next stages of the process. Tools such as
VerveineJ (VerveineJ., 2022) produce this model in a
language-independent format (e.g., JSON or Moose
Serialization Format, MSE), enabling flexible analy-
sis across different languages. MSE is designed for
easy import into the Moose a software analysis plat-
form (Moosetechnology, 2020), which offers tools for
interactive model exploration.
This step is essential as it provides the abstract
model with structured context needed for subsequent
analysis. Without this model, extracting meaningful
data from the codebase would be significantly more
challenging.
Figure 2 shows how the initial code base is trans-
formed into a model that can be queried.
Figure 2: Automated Reverse Engineering Process using
VerveineJ and Moose platform.
3.2 Model Query and Information
Extraction
In the second step, the abstract model is queried to ex-
tract relevant information, such as method names, sig-
natures, and dependencies. This information is struc-
tured into a query (typically in JSON format) to guide
the LLM in generating accurate code.
This structured data is essential for ensuring that
the LLM has the context it needs to generate code that
fits the code structure. We also incorporate unit test
cases that provide insights into the expected behavior
of the methods, further refining the prompt for accu-
racy.
Figure 3 illustrates the querying process and the
resulting structured output.
Figure 3: Model Query Process for Information Retrieval.
3.3 Prompt Construction and Code
Generation
The final step constructs a detailed prompt based
on the information extracted from the model. This
prompt ensures that the LLM generates code that ad-
heres to the project’s structure and meets the speci-
fied requirements. The prompt includes essential con-
text such as method signatures, relevant unit tests, and
coding guidelines.
The quality and clarity of the prompt are critical to
the effectiveness of the generated code. By providing
structured, method-specific details, we help the LLM
produce code that is both syntactically correct and
functionally consistent with the original codebase.
The prompt follows a structured template divided
into four sections: Instructions, Details, Guidelines,
and Test Code. These sections ensure that the LLM
receives only the most relevant information, minimiz-
ing the inclusion of unnecessary or distracting data.
The template is populated with data obtained during
the previous model query phase.
A sample template for Java code generation is pre-
sented in Listing 1.
Listing 1: Java Code Generation Template.
You a r e a J ava pr o g r am mi n g e x pe rt t as ke d wi th g en er a t i ng
me a n i n g fu l Ja va co de . P l ea se i m pl em en t th e re qu ir e d
me th od b as ed on the p ro vi d e d O ri gi na l m et h o d .
** In st r u c ti o n s :* *
- Res po nd o nly w it h co nc is e Ja va c o de .
- Imp le me n t on ly th e or ig in a l me th od c o rr e s p on di n g t o the
pr ov id ed s i g na tu re .
- Imp le me n t the f ull l og ic of th e m et ho d ba se d on the
si gna tu re , fo l l o w in g be s t p ra ct ic es f or Ja va
pr o g r am mi n g .
** D e t a i l s : **
- * * O ri gi na l M e t h od Si g n a t u re ** :
{ r e f e re n ce _s i gn a t u re }
{ r e f e re n ce _v a ri a b l es }
{ m et h od s _ o ut g o i ng }
** Gu id e l i n e s : **
- U se on ly th e pa ra m e t er s s p e ci fi ed in th e me th o d s ig na t u r e
.
- As s u me a ll n ec es sa ry d at a is a v a i la bl e t h r o u g h th e
pr ov id ed p a r am et er s .
- Av oi d g e n er at in g or a s s u m in g any a d d i t i on al d at a not
in cl ud ed i n t h e me th od s i g n a t ur e .
- Fo l l ow b es t pr ac t i c e s f o r Jav a p r o gr am m i n g and e ns ur e the
co d e is co mp le te a nd t es ta bl e w i th in t he gi ve n
co nt ex t .
** T es t C od e : * *
{ t es t_ co d e }
Figure 4 illustrates the code generation process
based on the extracted data and the prompt building.
The proposed structured approach ensures the
LLM generates code that integrates seamlessly into
the project.
ICSOFT 2025 - 20th International Conference on Software Technologies
348

Figure 4: Prompt construction and code generation for dif-
ferent strategies.
4 EXPERIMENTAL SETUP AND
EVALUATION
We evaluate our approach through a case study, vari-
ous code generation strategies, and defined metrics to
measure the effect of various type of contextual infor-
mation on LLM-generated code accuracy.
To evaluate our approach, we address the follow-
ing research questions:
RQ1: How does additional context, such as
method signatures, unit tests, and method calls, affect
code generation accuracy? Does the impact differ be-
tween industrial and open-source code bases?
The hypothesis is that enriched context will im-
prove accuracy, especially in industrial code, while
open-source projects may show more stable perfor-
mance due to prior exposure.
RQ2: How does code complexity, as measured by
cyclomatic complexity, method length, and assertion
count, influence the effectiveness of different code
generation strategies?
The hypothesis is that longer and more compre-
hensive test methods will improve the functional cor-
rectness of generated code, particularly in industrial
code bases with more complex code.
4.1 Case Study
We evaluated our approach on two Java-based
projects to ensure diversity:
1. IndusApp, A proprietary industrial application for
client subscription management, developed by
Berger-Levrualt (Berger-Levrault, 2025).
2. RxJava (Davis and Davis, 2019): A popular open-
source JVM implementation of Reactive Exten-
sions, with over 47K stars and 7.6K forks on
GitHub
1
.
These projects provide a balanced experimental
setting, allowing us to compare performance across
both open-source and industrial codebases. Key
project metrics are shown in Table 1:
1
https://github.com/ReactiveX/RxJava
Table 1: Overview of Key Metrics for Selected Use Cases.
Project Type Classes Package Methods LoC Tests
IndusApp Industrial 536 136 6873 67330 390
RxJava Open-Source 16570 75 47970 415391 9495
4.2 Evaluation Setup
We implemented four code generation strategies with
varying levels of contextual information:
The evaluation involves four code generation
strategies with increasing levels of contextual infor-
mation. The Trivial strategy uses only the method
name, providing minimal context. The Naive strategy
expands this to the full method signature, including
the method name, parameter types, and return type.
The Test-Based strategy incorporates unit tests, as-
suming they are written before implementation, al-
lowing the model to leverage expected behaviors as
guidance. Finally, the Augmented strategy includes
method call details within the target method, offering
deeper insights into dependencies and execution flow.
This increasing complexity allows us to system-
atically assess how varying levels of context af-
fect code generation quality. We use the Code-
BLEU (Ren et al., 2020) metric to evaluate accuracy
by comparing generated and reference code. Code-
BLEU integrates four components—N-gram match,
weighted N-gram match, AST match, and data flow
match—each weighted equally (0.25) to capture lexi-
cal, syntactic, and semantic correctness.
Code generations are performed using the
LLama3 (Touvron et al., 2023) model. The evaluation
aims to identify which strategy yields the most accu-
rate and maintainable code across both open-source
and industrial case studies.
5 RESULTS
We evaluated the effectiveness of four code gen-
eration strategies—Trivial, Naive, Test-Based, and
Augmented—using the CodeBLEU metric. This
section compares results across both industrial (In-
dusApp) and open-source (RxJava) projects, focusing
on how contextual information impacts code quality.
5.1 Industrial Project: IndusApp
Overall Strategy Comparison. Figure 5 presents
CodeBLEU scores and sub-metrics for all four strate-
gies. While overall scores are below 50%, syntax
and dataflow scores are notably higher, particularly
for Test-Based and Augmented strategies.
Enhancing AI-Generated Code Accuracy: Leveraging Model-Based Reverse Engineering for Prompt Context Enrichment
349
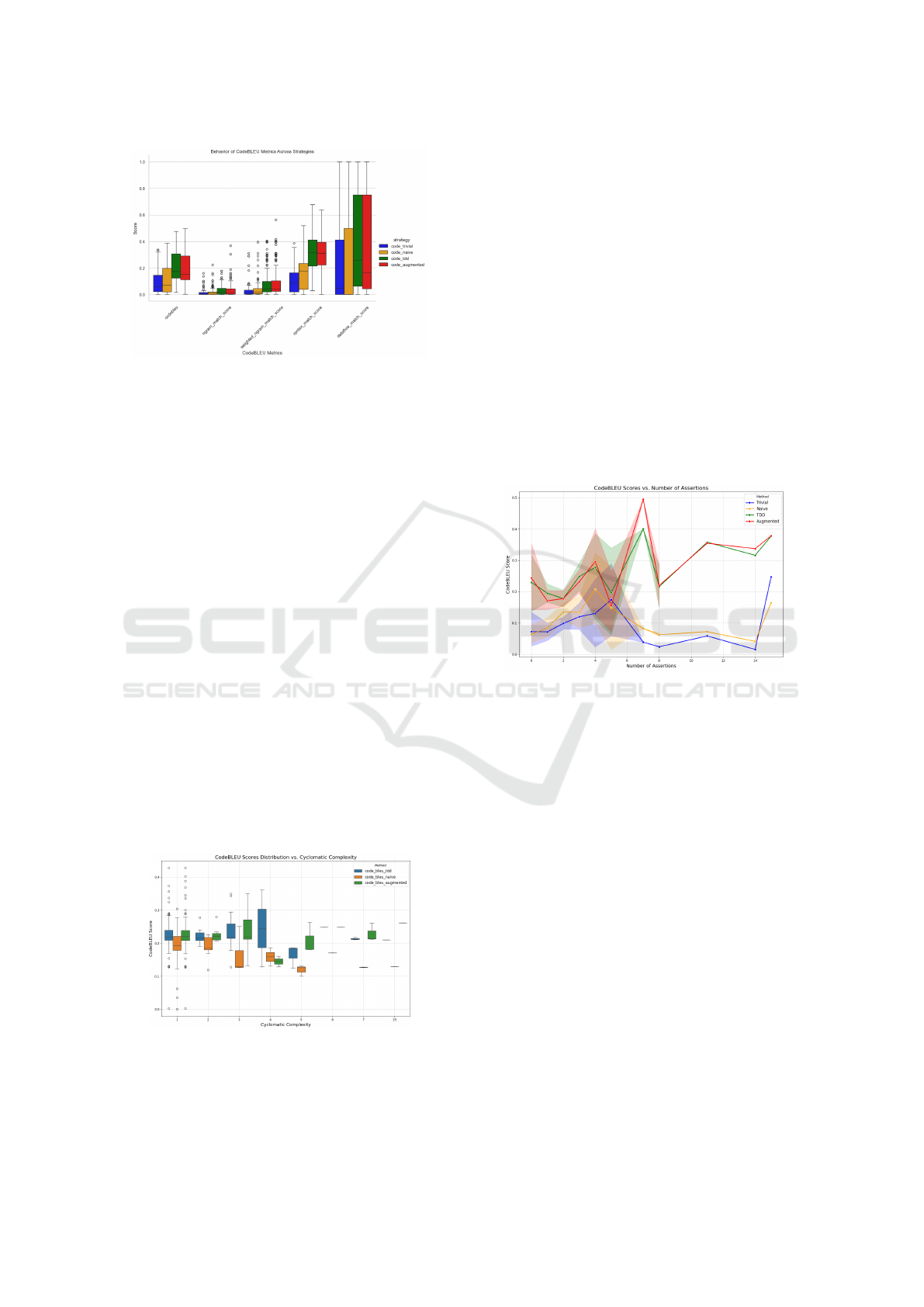
Figure 5: Distribution of CodeBLEU Scores and Sub-
Metrics Across Code Generation Strategies.
The Test-Based and Augmented approaches
achieve approximately 75% on dataflow match and
40% on syntax match, outperforming Trivial and
Naive strategies. Ngram-based metrics remain below
20% across all strategies, the overall scores still com-
pare favorably to the reference mean value of 24% for
Text-to-Code generation provided on the CodeBLEU
GitHub page (Microsoft, 2023).
These results support the hypothesis (RQ1) that
adding contextual information, such as unit tests or
method calls, significantly improves code accuracy,
especially in syntax correctness and semantic accu-
racy. This indicates that Test-Based and Augmented
approaches generate code that better preserves pro-
gram structure and execution flow, even if the tex-
tual representation varies from reference implemen-
tations.
Effect of Test Method Cyclomatic Complexity.
Figure 6 shows a heatmap of average CodeBLEU
scores across four code generation strategies, based
on the cyclomatic complexity (1-19) of the reference
test methods. Higher complexity indicates more intri-
cate control flow.
Figure 6: Average CodeBLEU Scores by Cyclomatic Com-
plexity of Test Methods for IndusApp.
Test-Based and Augmented strategies consistently
outperform Trivial and Naive ones, especially at mod-
erate complexity levels (4–6), achieving scores be-
tween 0.33 and 0.36 compared to just 0.04 to 0.06.
Although performance declines across all strategies
beyond level 6, Test-Based and Augmented meth-
ods still retain a notable advantage (0.13–0.15 vs.
0.00–0.06).
These results support RQ1, suggesting that con-
textual information—such as unit tests—significantly
improves performance for simple to moderately com-
plex methods. However, the reduced effectiveness at
higher complexity levels poses a challenge to RQ2,
highlighting the need for alternative strategies in those
scenarios.
Effect of Number of Assertions in Test Method.
Figure 7 shows the relationship between CodeBLEU
scores and the number of assertions in test methods
for an industrial project.
Figure 7: Relationship Between CodeBLEU Scores and
Number of Assertions.
Test-Based and Augmented strategies outperform
Trivial and Naive across nearly all assertion counts,
peaking at around 7 assertions (0.5 for Augmented,
0.4 for Test-Based). After a brief drop at 8 assertions,
their performance stabilizes between 0.3–0.4 through
assertion counts 10–14. In contrast, Trivial and Naive
remain below 0.2, often under 0.1, with only slight
improvement at 14.
These results support RQ2: more assertions gen-
erally improve code generation, with Test-Based
methods benefiting most up to a complexity thresh-
old. While the specific contribution of added method
call context in the Augmented strategy is unclear, it
does not diminish the benefits of unit tests.
Effect of Test Method Lines of Code (LoC). Fig-
ure 8 shows the relationship between CodeBLEU
scores and the number of lines of code in test meth-
ods.
All strategies exhibit a slight negative correla-
tion between CodeBLEU scores and test method LoC
(–0.05 to –0.10), suggesting that longer test methods
ICSOFT 2025 - 20th International Conference on Software Technologies
350
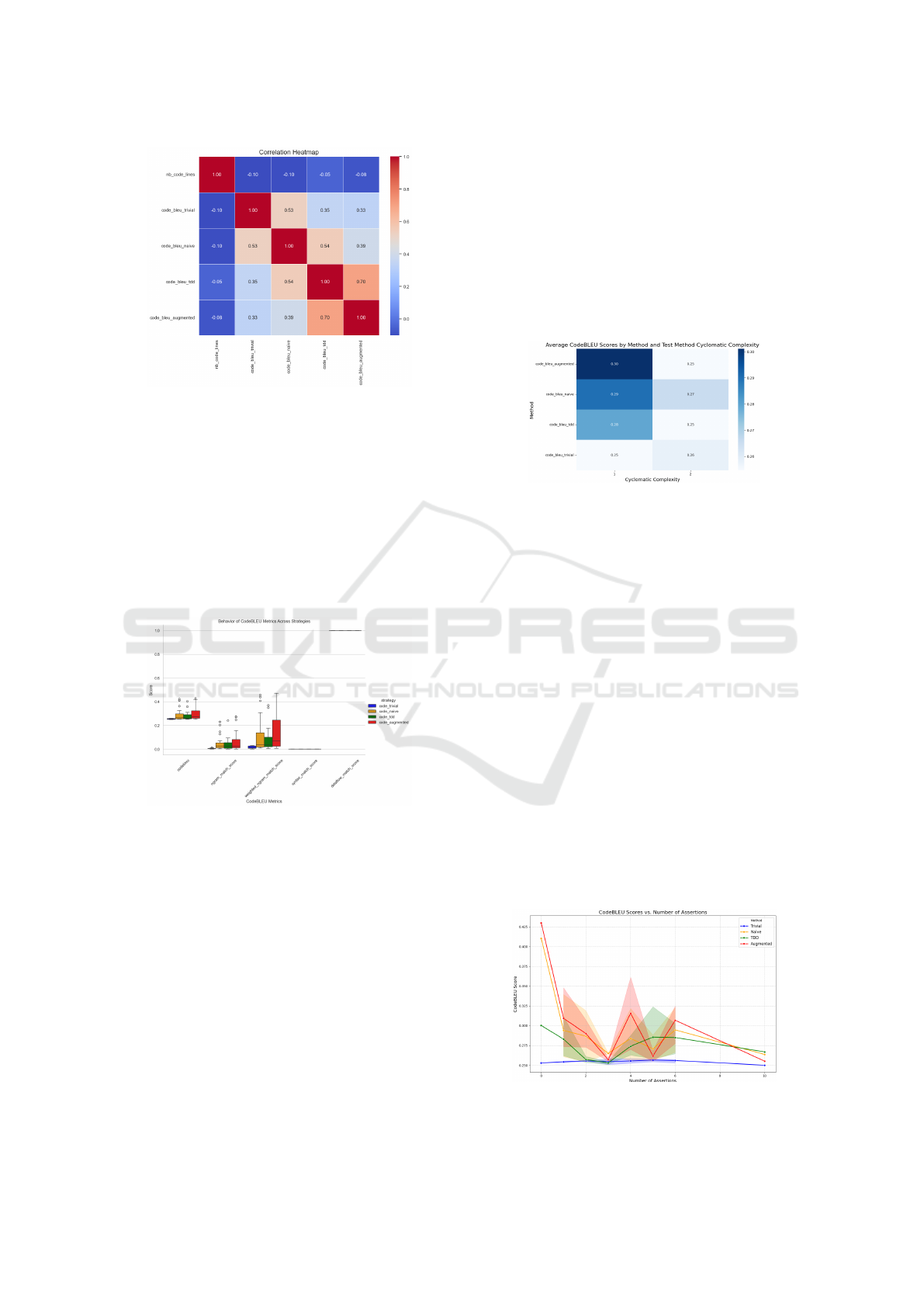
Figure 8: Relationship Between CodeBLEU Scores and
Test Method Lines of Code for IndusApp.
do not significantly impact code generation quality.
These results do not support RQ2 in the context of
test LoC.
5.2 Open-Source Project: RxJava
Overall Strategy Comparison. Figure 9 shows
CodeBLEU scores across code generation strategies
for an open-source project.
Figure 9: Distribution of CodeBLEU Scores and Code-
BLEU Sub-Metrics Across Code Generation Strategies.
The CodeBLEU scores range from 20–40%, close
to the 24% baseline for Text-to-Code tasks. No sin-
gle strategy emerges as superior. The low N-gram and
Weighted N-gram scores indicate limited precision in
matching code patterns. Additionally, the near-zero
syntax and data flow scores reveal that the generated
code often lacks correct syntax and data flow accu-
racy. This suggests that while open-source projects
offer extensive documentation, they do not guaran-
tee functionally or semantically accurate code gen-
eration, partly due to the absence of enforced code
structures.
These results address RQ1, showing that the in-
clusion of additional contextual information does not
meaningfully improve CodeBLEU scores for open-
source data. Instead, the model’s prior familiarity
with recurring patterns in open-source code appears
to drive more consistent performance, regardless of
the amount of context provided.
Effect of Test Method Cyclomatic Complexity.
Figure 10 illustrates the average CodeBLEU scores
for different code generation strategies, categorized
by the cyclomatic complexity of the test methods.
Figure 10: Average CodeBLEU Scores by Cyclomatic
Complexity of Test Methods.
In this study, the cyclomatic complexity of the test
methods varies from 1 to 2. This low complexity is
likely due to the concise and focused nature of the
methods under test. Given the limited range of com-
plexity values, it is challenging to definitively con-
clude whether increased complexity results in a no-
ticeable decrease in CodeBLEU scores. However, the
data hints that even within this narrow range, higher
complexity might pose difficulties for accurate code
generation.
These observations suggest that the cyclomatic
complexity of test methods affects the scores, ad-
dressing RQ2. Nonetheless, additional research with
a wider range of complexity values is required to fully
comprehend this impact.
Effect of Number of Assertions in Test Method.
Figure 11 illustrates the relationship between Code-
BLEU scores and the number of assertions in test
methods for the RxJava open-source project.
Figure 11: Relationship Between CodeBLEU Scores and
Number of Assertions.
Enhancing AI-Generated Code Accuracy: Leveraging Model-Based Reverse Engineering for Prompt Context Enrichment
351

The results indicate that the Trivial strategy con-
sistently yields low and stable CodeBLEU scores.
However, across all strategies, the CodeBLEU scores
remain above the reference value of 24% for the
Text-to-Code use case. This suggests that additional
contextual information does not significantly impact
CodeBLEU scores for open-source projects, address-
ing RQ1.
Effect of Test Method Lines of Code (LoC). Fig-
ure 12 presents the relationship between CodeBLEU
scores and the number of lines of code (LoC) in test
methods across different code generation strategies
for the RxJava open-source project.
Figure 12: Relationship Between CodeBLEU Scores and
Test Method LoC for RxJava Open Source Project.
The heatmap shows that CodeBLEU scores have
a negative correlation with LoC, ranging from -0.15
to -0.34. This indicates that code quality is not depen-
dent on the test code LoC for any strategy. Among
the strategies, the Augmented and Naive approaches
show the strongest correlation (0.85), suggesting sim-
ilar quality outcomes. This implies that the addi-
tional information in the Augmented strategy, such
as unit tests and method call details, does not signifi-
cantly impact open-source projects. The Naive strat-
egy, which considers only method signatures, appears
sufficient for open-source projects, addressing RQ2
from the LoC perspective.
6 LIMITATIONS AND FUTURE
WORK
This study focused exclusively on Java applications
and utilized Llama 3 as the code generation model.
As a result, the findings may not be directly appli-
cable to other programming languages with different
syntactic structures or paradigms. Additionally, the
performance insights may be model-specific. Future
research should compare multiple language models
and extend evaluations to other languages, such as
Python or JavaScript, to assess cross-language con-
sistency and generalization.
The evaluation was conducted on just two
projects—one industrial and one open-source. While
this setup enabled a comparative analysis, it may
not reflect the full diversity of real-world software
systems. Expanding the dataset to include more
projects from various domains, architectures, and
scales would improve the generalization and robust-
ness of the findings.
Although automated metrics like CodeBLEU pro-
vide a standardized way to assess code generation
quality, they do not fully capture important aspects
such as readability, maintainability, or correctness in
practical development contexts. To provide a more
comprehensive evaluation, future studies should in-
corporate human-in-the-loop methods, such as man-
ual code reviews or usability testing.
This study primarily focused on unit tests and
method call dependencies as sources of context for
code generation. While these proved valuable, other
contextual elements, such as inline comments, code
history, developer intent, or issue trackers, could fur-
ther enhance the quality of generated code. Future
work could investigate these additional types of con-
text and their influence on different facets of code
generation.
Finally, this research offers a static snapshot of
code generation effectiveness. To understand how
these strategies evolve over time and how maintain-
ability is affected in long-term development, future
work should include longitudinal studies that assess
code generation strategies across multiple software
versions or updates.
7 CONCLUSION
This study demonstrates that incorporating reverse-
engineered contextual data, such as unit tests and
method dependencies, significantly enhances code
quality in industrial software projects. In contrast,
simpler strategies based solely on method signa-
tures perform comparably to test-based approaches in
open-source projects, suggesting that extensive con-
textual information may be less essential in those set-
tings.
We also find that test methods with more asser-
tions or verifications tend to yield higher-quality gen-
erated code. However, increasing the complexity of
ICSOFT 2025 - 20th International Conference on Software Technologies
352

these tests can diminish their effectiveness, particu-
larly in industrial environments, while having a lesser
impact on open-source code bases.
Overall, these results highlight the value of test-
driven development and context-rich prompts in re-
generating accurate and maintainable code, especially
within industrial software evolution workflows.
REFERENCES
Berger-Levrault (2025). Official website of berger-levrault.
https://www.berger-levrault.com/. Accessed: 2025-
03-10.
Chen, X., Liu, C., and Song, D. (2018). Tree-to-tree neural
networks for program translation. Advances in neural
information processing systems, 31.
Claris
´
o, R. and Cabot, J. (2023). Model-driven prompt engi-
neering. In 2023 ACM/IEEE 26th International Con-
ference on Model Driven Engineering Languages and
Systems (MODELS), pages 47–54. IEEE.
Davis, A. L. and Davis, A. L. (2019). Rxjava. Reactive
Streams in Java: Concurrency with RxJava, Reactor,
and Akka Streams, pages 25–39.
Fagadau, I. D., Mariani, L., Micucci, D., and Riganelli,
O. (2024). Analyzing prompt influence on automated
method generation: An empirical study with copilot.
In Proceedings of the 32nd IEEE/ACM International
Conference on Program Comprehension, pages 24–
34.
Fakhoury, S., Naik, A., Sakkas, G., Chakraborty, S., and
Lahiri, S. K. (2024). Llm-based test-driven interactive
code generation: User study and empirical evaluation.
arXiv preprint arXiv:2404.10100.
Gao, A. (2023). Prompt engineering for large language
models. Available at SSRN 4504303.
Gu, Q. (2023). Llm-based code generation method for
golang compiler testing. In Proceedings of the 31st
ACM Joint European Software Engineering Confer-
ence and Symposium on the Foundations of Software
Engineering, pages 2201–2203.
Gu, X., Chen, M., Lin, Y., Hu, Y., Zhang, H., Wan, C., Wei,
Z., Xu, Y., and Wang, J. (2024). On the effectiveness
of large language models in domain-specific code gen-
eration. ACM Transactions on Software Engineering
and Methodology.
Heston, T. F. and Khun, C. (2023). Prompt engineering in
medical education. International Medical Education,
2(3):198–205.
Husein, R. A., Aburajouh, H., and Catal, C. (2024). Large
language models for code completion: A systematic
literature review. Computer Standards & Interfaces,
page 103917.
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L.,
Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S.,
Yang, Y., et al. (2024). Self-refine: Iterative refine-
ment with self-feedback. Advances in Neural Infor-
mation Processing Systems, 36.
Mathews, N. S. and Nagappan, M. (2024). Test-driven
development for code generation. arXiv preprint
arXiv:2402.13521.
Microsoft (2023). Codebleu – a weighted syntactic and
semantic bleu for code synthesis evaluation. https:
//github.com/microsoft/CodeXGLUE/blob/main/
Code-Code/code-to-code-trans/CodeBLEU.MD.
Accessed: 2025-03-10.
Moosetechnology (2020). Official website of modular
moose. https://modularmoose.org/. Accessed: 2025-
04-18.
Munck, A. and Madsen, J. (2015). Test-driven modeling
of embedded systems. In 2015 Nordic Circuits and
Systems Conference (NORCAS): NORCHIP & Inter-
national Symposium on System-on-Chip (SoC), pages
1–4. IEEE.
Nam, D., Macvean, A., Hellendoorn, V., Vasilescu, B., and
Myers, B. (2024). Using an llm to help with code un-
derstanding. In Proceedings of the IEEE/ACM 46th
International Conference on Software Engineering,
pages 1–13.
Noy, S. and Zhang, W. (2023). Experimental evidence on
the productivity effects of generative artificial intelli-
gence. Science, 381(6654):187–192.
Olausson, T. X., Inala, J. P., Wang, C., Gao, J., and Solar-
Lezama, A. (2023). Is self-repair a silver bullet for
code generation? In The Twelfth International Con-
ference on Learning Representations.
Ren, S., Guo, D., Lu, S., Zhou, L., Liu, S., Tang, D., Sun-
daresan, N., Zhou, M., Blanco, A., and Ma, S. (2020).
Codebleu: a method for automatic evaluation of code
synthesis. arXiv preprint arXiv:2009.10297.
Rugaber, S. and Stirewalt, K. (2004). Model-driven reverse
engineering. IEEE software, 21(4):45–53.
Sadik, A. R., Brulin, S., Olhofer, M., Ceravola, A., and
Joublin, F. (2024). Llm as a code generator in
agile model driven development. arXiv preprint
arXiv:2410.18489.
Saha, B. K. (2024). Generative artificial intelligence for
industry: Opportunities, challenges, and impact. In
2024 International Conference on Artificial Intelli-
gence in Information and Communication (ICAIIC),
pages 081–086. IEEE.
Soliman, A., Shaheen, S., and Hadhoud, M. (2024). Lever-
aging pre-trained language models for code genera-
tion. Complex & Intelligent Systems, pages 1–26.
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux,
M.-A., Lacroix, T., Rozi
`
ere, B., Goyal, N., Hambro,
E., Azhar, F., et al. (2023). Llama: Open and ef-
ficient foundation language models. arXiv preprint
arXiv:2302.13971.
Ugare, S., Suresh, T., Kang, H., Misailovic, S., and Singh,
G. (2024). Improving llm code generation with gram-
mar augmentation. arXiv preprint arXiv:2403.01632.
VerveineJ., M. (2022). Verveinej. Accessed: 2025-03-07.
Welz, L. and Lanquillon, C. (2024). Enhancing large lan-
guage models through external domain knowledge. In
International Conference on Human-Computer Inter-
action, pages 135–146. Springer.
Enhancing AI-Generated Code Accuracy: Leveraging Model-Based Reverse Engineering for Prompt Context Enrichment
353

White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert,
H., Elnashar, A., Spencer-Smith, J., and Schmidt,
D. C. (2023). A prompt pattern catalog to enhance
prompt engineering with chatgpt. arXiv preprint
arXiv:2302.11382.
Zhang, Y. (2004). Test-driven modeling for model-driven
development. Ieee Software, 21(5):80–86.
Zolotas, A., Claris
´
o, R., Matragkas, N., Kolovos, D. S., and
Paige, R. F. (2017). Constraint programming for type
inference in flexible model-driven engineering. Com-
puter Languages, Systems & Structures, 49:216–230.
ICSOFT 2025 - 20th International Conference on Software Technologies
354
