
A Fragile Watermarking Technique for Integrity Authentication of
CSV-Files Using Invisible Line-Ending Control Characters
Florian Zimmer
1 a
, Malte Hellmeier
1 b
, Motoki Nakamura
2 c
and Tobias Urbanek
1 d
1
Fraunhofer Institute for Software and Systems Engineering ISST, Speicherstr. 6, 44147 Dortmund, Germany
2
Data & Security Research Laboratory, Fujitsu Limited, Kanagawa, Japan
fl
Keywords:
Digital Watermarking, Fragile, CSV, Integrity, Authentication, Line-Ending, Unicode, CRLF, LF.
Abstract:
Every day, a growing amount of data, including audio, video, images, and plain text, is published and shared
online. Facilitating its interoperable exchange, a range of standards and formats has emerged, establishing
common ground. Among plain text formats, CSV prevails as one of the most used text formats. However,
being a simplistic, plain text format, it lacks built-in security measures. Consequently, data users cannot
authenticate the integrity of CSV texts they receive. A recognised method in research for ensuring text integrity
is fragile watermarking. Accordingly, numerous watermarking techniques are available for tamper detection.
However, many of these methods are either incompatible with the CSV format or visible to the human eye.
To address these shortcomings, we propose a novel fragile watermarking technique for CSV files. Using
invisible line-ending control characters, we are able to embed any byte-encodable information into a CSV
cover text, making it truly imperceptible. We evaluated our technique by conducting three experiments to
benchmark robustness, capacity and imperceptibility and comparing it with existing solutions. We found that
our technique successfully achieves complete imperceptibility in all cases. However, a limited capacity and
line-ending normalisation sensitivity must be considered when applying it.
1 INTRODUCTION
The proliferation of an increasingly interconnected
world has led to an ever-growing amount of data, with
a projected growth to more than 394 zettabytes within
the next five years (Taylor, 2024). Driven by the
digital transformation, more and more digital assets
are created, published, and shared over the internet
every day, such as audio, video, images, or simply
plain text (Rizzo et al., 2019). Moreover, active
research in inter-organisational data sharing suggests
that to fully utilise the value of data, it needs to be
shared (Otto, 2022).
One of the most used plain text data formats
besides HTML and PDF is the Comma-Separated
Values (CSV) format. According to Vitagliano et
al., CSV makes up to 31% of available formats
on governmental portals (Vitagliano et al., 2023).
Being simple in nature, the CSV format provides
a
https://orcid.org/0009-0002-8060-7162
b
https://orcid.org/0000-0002-2095-662X
c
https://orcid.org/0009-0004-3894-5023
d
https://orcid.org/0009-0007-3121-0245
an easy way of storing, processing, and transferring
data (Abba and Hassan, 2018). Especially
for information exchange between heterogeneous
systems and processing of raw data, CSV prevails to
be a common choice due to its broad compatibility
and lightweight processing capabilities (Ito, 2024).
However, as CSV is a plain text format focused
on simplicity, it was not designed with security in
mind and thus fails to provide any security features
out of the box (Ito, 2024). This leaves data users of
third-party CSV files exposed to various risks when
using them. Following recent work, data integrity
attacks are considered one of the most fundamental
ones (Tian and Nogales, 2023), potentially resulting
in financial losses up to human harm (Jaigirdar et al.,
2019; Hisham et al., 2013). Therefore, as CSV
does not provide any protection schemes itself, other
solutions are needed.
Besides well-known security approaches and
cryptography techniques, watermarking – especially
fragile watermarking – has been identified as a
potential solution aiming at mitigating data integrity
risks. Therefore, various watermarking schemes
have been proposed that aim to enable integrity
Zimmer, F., Hellmeier, M., Nakamura, M., Urbanek and T.
A Fragile Watermarking Technique for Integrity Authentication of CSV-Files Using Invisible Line-Ending Control Characters.
DOI: 10.5220/0013559600003979
In Proceedings of the 22nd International Conference on Security and Cryptography (SECRYPT 2025), pages 455-466
ISBN: 978-989-758-760-3; ISSN: 2184-7711
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
455
authentication by making the watermark susceptible
to any changes made to the cover medium. For
example, (He et al., 2020) proposed a novel
watermarking technique for semi-structured text data
such as JSON, XML, or CSV by embedding error-
correction codes into the least significant bit (LSB) of
numeric values. Other text watermarking schemes,
on the other hand, often focus on homoglyph
substitutions, as demonstrated in (Rizzo et al., 2016).
However, most of the existing watermarking
approaches for integrity authentication are either not
applicable for the CSV format or alter the values
themselves. Consequently, recent work proposed a
novel data hiding scheme which embeds a digital
signature into a CSV cover text using alternating
double quotation marks (Ito, 2024). The proposed
scheme does not change the values themselves but
exploits the syntactical definition of the CSV format.
Yet, a significant drawback of this approach is that it
is visible to its user, affecting the text’s fidelity.
In this study, we aim to address the shortcomings
of existing work by proposing a novel CSV fragile
watermarking technique. Using invisible, non-
printable line-ending control characters to embed a
digital signature in a CSV cover text, our approach
is imperceptible in nature. We demonstrate how our
technique manages to incorporate any byte-encodable
information into plain CSV text and how it can be
utilised alongside digital signatures to authenticate
the text’s integrity. Furthermore, we evaluate our
approach in an experimental setup and compare it
with related work. Our main contributions include:
(i) A novel fragile watermarking technique
for CSV text, outlining the embedding and
extraction procedure.
(ii) An experimental setup used to evaluate and
compare our approach with relevant related
work.
The remainder is structured as follows: In
Section 2, we present relevant background
information and related work. Section 3 introduces
our CSV watermarking approach. Section 4 describes
the experimental setup and results. In Section 5, we
discuss results and limitations. Section 6 concludes
the study with a summary.
2 BACKGROUND
2.1 Watermarking
The idea of hiding data inside multimedia content
goes back to the 20th century, with a substantial
increase in academic publications since the
90s (Petitcolas et al., 1999). Since then, data
hiding has mainly focused on proofing copyright and
assuring the content integrity of digital media (Bender
et al., 1996). Existing methods aim to hide a secret
message (like a watermark or signature) inside
a cover medium. Those cover mediums can
range from images, text, audio, and video (Rizzo
et al., 2019) to more specialised types like Word
documents (Liu and Tsai, 2007), CSV files (Ito,
2024), or databases (Rani and Halder, 2022). An
alternative delimitation is a classification into the
categories of cryptography, steganography, and
watermarking (Taleby Ahvanooey et al., 2018;
Podilchuk and Delp, 2001; Rizzo et al., 2019).
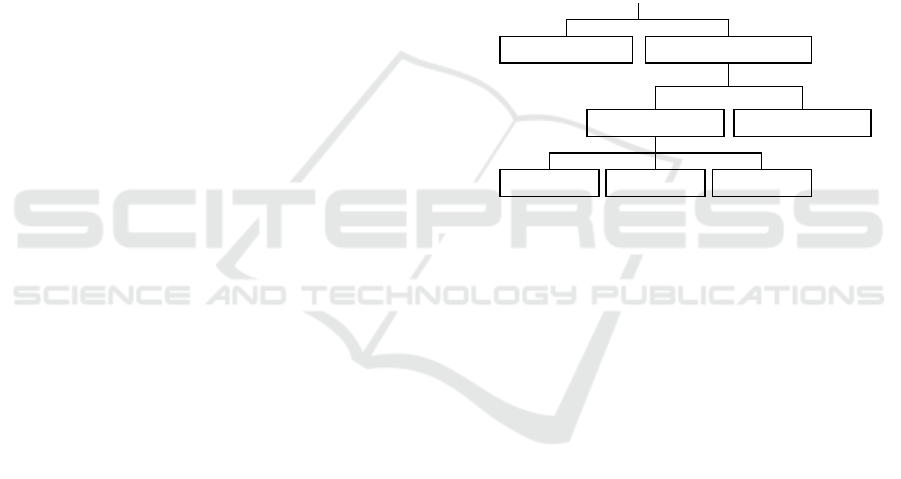
An overview of the interrelationship between the
categories is shown in Figure 1.
Cryptography Information Hiding
SteganographyWatermarking
Semifragile RobustFragile
Figure 1: Information Hiding Classification (Podilchuk and
Delp, 2001; Taleby Ahvanooey et al., 2018; Rizzo et al.,
2019; Hellmeier et al., 2025).
Cryptography uses encryption and decryption
techniques by working with cipher to focus on
data hiding and data protection (Alkawaz et al.,
2016). In contrast, steganography focuses on
secure communication by hiding data invisibly to
prevent third parties from detecting it (Hartung
and Kutter, 1999). Watermarking aims to embed
copyright information visibly or invisibly inside the
cover (Jalil and Mirza, 2009; Kamaruddin et al.,
2018). The latter can further be divided into
robust techniques aiming for security and copyright
protection, fragile techniques aiming for tamper
detection, and semi-fragile techniques for something
in between (Podilchuk and Delp, 2001; Alkawaz
et al., 2016).
This work presents a fragile watermarking
technique for CSV cover files, introduced in the
following.
2.2 CSV Text Format
The CSV format is a plain text format for sharing,
processing and storing tabular data (Abba and Hassan,
2018). CSV has been used for decades, especially
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
456

in the domain of databases. As CSV was developed
out of need for an exchange format for heterogeneous
systems, CSV was long lacking a sound definition or
standard (Mitl
¨
ohner et al., 2016). This has led to
various dialects and formats that persist to this day,
resisting standardisation efforts.
In 2005, the IEFT published the RFC4180
specification, aiming at defining a common CSV
format based on how CSV was predominantly used at
the time. According to this, the most basic structure
of CSV text is records of the form aaa,bbb,ccc
delimited by a CRLF line-break. On top of that,
they define a more sophisticated grammar on how
to format different contents. Nevertheless, the
resulting specification still acknowledges the variety
of different dialects that exist by recommending
that “Implementors should be conservative in what
(they) do (and) be liberal in what (they) accept from
others” (Shafranovich, 2005, p. 5) when adhering to
this specification.
Roughly ten years later, in 2016, the W3C
formalised a non-normative document, aiming
at increasing the interoperability of CSV on the
web by defining a data model for CSV, as well
as by enhancing it with an additional metadata
model. This was to enrich the overall capabilities
of CSV, increasing the interoperability and overall
accessibility of CSV documents by formally
describing them (Brickely et al., 2016).
Nevertheless, the interoperability challenge
associated with utilising the CSV format has persisted
to this day. Therefore, recent work emphasised the
need for either a more consistent usage of the CSV
format or more robust processing and parsing tools
(Mitl
¨
ohner et al., 2016; van den Burg et al., 2019;
Vitagliano et al., 2023).
As the proposed watermarking scheme in this
work makes use of the fact that different dialects
exist, we investigate how major CSV tools handle our
watermarked content more closely in Section 4.
2.3 Line-Ending Control Characters
Line-Ending control characters are non-printable
control characters often found in text encoding
standards such as Unicode
1
or ASCII
2
. Often referred
to as newline, their function is to indicate the end of
a line or the beginning of a new line, respectively
(Allen, 2007). Being utilised for text formatting
purposes only, they are invisible to regular users as
they are non-printable.
1
https://www.ietf.org/rfc/rfc3629.txt [25.02.25]
2
https://www.ietf.org/rfc/rfc20.txt [25.02.25]
There is a variety of different line-ending control
characters for different text encoding standards.
Unicode, e.g., defines eight different ones, with the
most prominent ones being carriage return (CR), line
feed (LF), and the combination of both carriage return
and line feed (CRLF) (Allen, 2007). Moreover,
different operating systems use different line-ending
control characters by default. An overview can
be seen in Table 1. The variety of different line-
ending control characters originated from a time when
typewriters required a combination of carriage return
to move the cursor back to the beginning of the
page and line feed to move the page up in order to
continue writing in a new line. With the shift to
the digital world, some operating systems, such as
Windows, kept the combination of CRLF and others,
such as UNIX-based operating systems, chose LF
only (Saltzer and Ossanna, 1970; IEEE, 1986).
Table 1: Newline per Operating System (Allen, 2007).
Operating System Newline
MacOS 9.x and earlier CR
MacOS X LF
Unix LF
Windows CRLF
Nowadays, many operating systems and tools
are capable of handling both line-endings. This
becomes evident, as many messaging protocols such
as HTTP
3
, MTP
4
or FTP
5
stipulate the usage of
CRLF. Yet, most server operating systems which use
those messaging formats for information exchange
are UNIX-based (Fortune Business Insights, 2024).
As a result, platform users are usually free to use
both types of line-endings. However, most operating
systems or tools usually normalise line-endings to the
default platform-specific line-ending. E.g., Git
6
, a
major version control tool, provides an option which
automatically converts CRLF into LF on any push.
In this work, we take advantage of the variety
of accepted line-ending control characters and
intentionally use a mixture of both CRLF and LF. We
analyse any implications this might have in Section 4.
2.4 Related Work
According to (Liu et al., 2025), text watermarking
approaches can roughly be divided into four
categories: format-, lexical-, syntactic- or generation-
3
https://www.ietf.org/rfc/rfc2616.txt [25.02.25]
4
https://www.ietf.org/rfc/rfc780.txt [25.02.25]
5
https://www.ietf.org/rfc/rfc354.txt [25.02.25]
6
https://www.git-scm.com/book/ms/v2/Customizing-
Git-Git-Configuration.html [25.02.25]
A Fragile Watermarking Technique for Integrity Authentication of CSV-Files Using Invisible Line-Ending Control Characters
457

based approaches. Our line-ending-based approach
mainly falls into the category of format-based
watermarking or, more specifically, into the
subcategory of Unicode-based substitution.
Among the Unicode-based substitution
techniques, one of the most notable approaches
to mention is UniSpaCh (Por et al., 2012) and the
proposed watermarking technique in (Rizzo et al.,
2019). Both of them are representative of many
more techniques which embed a watermark into
a cover text by either replacing whitespaces or
other confusables with similar-looking whitespaces
or characters or by adding additional zero-width
characters. Although this class of techniques could
be adapted for use with CSV text, the applicability
might be limited as these kinds of approaches
strongly depend on text values. On top of that, these
approaches would alter the text values themselves
and are, therefore, not suitable for use cases where
accuracy is an important requirement.
Therefore, in (He et al., 2020), a data protection
scheme for semi-structured text is proposed, which
allows not only for content integrity authentication
but also for data recovery if the data has been
tampered with. They achieve this by embedding
error correction codes into the least-significant bits
of whitelisted numeric values. In their work, they
mainly focus on JSON text, yet they highlight the
applicability to other semi-structured text data like
CSV. However, even if it is negligible for some
use cases, altering the least significant bit of numeric
values might not be appropriate in others.
Consequently, in recent work, (Ito, 2024)
proposed a novel embedding scheme in order to
integrate digital signatures in CSV text, allowing for
integrity authentication. They do this by exploiting
the vague definition of the CSV format, which makes
double quotes for values optional in most cases.
Therefore, using alternating double quotes, they are
able to embed a byte-encoded digital signature into
CSV text.
A similar approach is followed in (Wen and Wang,
2013), which uses alternating double quotes and
single apostrophes to enclose text values. Although
their approach is demonstrated for XML text, it could
also be adapted to CSV as well, given the variation of
different dialects.
In contrast to other approaches, both of the latter
succeed at leaving the values untouched. This
way, they enable users to authenticate the content’s
integrity by verifying the digital signature included
in the watermark. However, a major shortcoming of
both approaches is that the changes introduced to the
text are visible to the human eye, affecting its fidelity.
3 PROPOSED SOLUTION
In the following, we present our novel fragile CSV
watermarking technique and describe the embedding
and extraction procedures in detail. Our approach
addresses the shortcomings of existing approaches, as
it is imperceptible by using invisible, non-printable
line-ending control characters. More specifically,
using a combination of alternating CRLF and LF
control characters, we are able to embed any byte-
encodable information in a CSV cover text. We do
this by mapping 0 or 1 to either control characters,
respectively. As discussed in Section 2, most major
platforms, as well as text encoding standards, are
capable of handling both representations. Thus, most
CSV editors and tools are able to display and parse
a mixed set of line-endings, as we demonstrate in
Section 4.
Furthermore, the following properties,
acknowledged in literature, characterise our
watermarking technique (Rizzo et al., 2016):
• Fragile - the fragility of a watermark is given if
it is susceptible to any changes made to the cover
text. In our case, the fragility is grounded on
two facts: First, as mentioned in Section 2, mixed
line-endings are prone to normalisation. Therefore,
different tools tend to wipe the watermark if any
changes are made, as we discuss in Section 4.
Second, we integrate a digital signature into
the watermark’s content to make sure that the
remaining modifications, which might not be
detected by line-ending normalisation, are covered
as well. This way, the recipient is able to securely
authenticate the text’s integrity. According to (Cox
et al., 2000), doing this is a feasible approach to
enable integrity authentication capabilities.
• Invisible - a watermark is invisible if it is hidden
in the carrier text and does not appear to the user.
As line-ending control characters are non-printable,
this holds true for our approach.
• Distortion-free - a distortion-based watermarking
technique introduces slight modifications to the
data itself, whereas a distortion-free technique
leaves the data itself untouched (He et al., 2020).
As our approach keeps the values intact and rather
alters the syntax within acceptable boundaries, our
approach is considered distortion-free.
• Blind - a watermark is blind if the extraction
procedure does not require the original cover text.
As our approach is able to extract the content
given solely the watermarked CSV text, it can be
considered blind.
• Secure - a watermark technique is secure if it
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
458

adheres to Kerckhoffs’ Law (Kerckhoffs, 1883).
Specifically, if a malicious actor is aware of the
embedding and extraction procedures, they still
cannot read or alter the watermark’s content without
access to a private shared secret (Petitcolas et al.,
1999). Since we aim to employ digital signatures in
practice, this principle applies to our case.
In the following, both the embedding and
extraction procedures are detailed. To establish them
by general means, we consider a random bitstring as
watermark content in our notions. However, the same
can be applied to digital signatures or any other kind
of information that can be encoded as bitstring.
3.1 Embedding Procedure
Using alternating CRLF and LF line-endings, our
approach is capable of embedding any byte-encodable
information into a CSV text. More precisely, we are
able to embed a bitstring B of length m into a CSV
cover text, where B := {b
0
,b
1
,...,b
m
} and b ∈ {0, 1}.
The CSV text can be represented by a set of n rows
R, where R := {r
0
,r
1
,...,r
n
}. Furthermore, each row
r
i
has a trailing line-ending ℓ
j
with i = 1, . . . , n and
j = 1, . . . , ˜n. Since a line-ending for the last row, r
n
is often times optional, the following applies: ˜n ≤ n.
Accordingly, the total watermark capacity C
max
can
be described with C
max
= ˜n, limiting the size of B
with m ≤ C
max
, meaning only as many bits fit in the
CSV text as there are line-endings. However, for the
following notions, we assume ˜n = n for the sake of
simplicity.
In order to embed B into a set of rows R, resulting
in a watermarked CSV text denoted as CSV
wm
, we
define the following watermark embedding function
W : (R, B) → CSV
wm
as follows:
W (R, B) =
n
M
i=0
(
r
i
f (b
i
), if i ≤ m,
r
i
ℓ
i
, if i > m
(1)
where ⊕ denotes a concatenation operator, putting
all rows back together, each with a trailing line-
ending. However, when choosing what line-ending
to place, we distinguish between the following two
cases: In cases where i ≤ m the bitstring B is not fully
embedded into the CSV text yet. Thus, we apply
a mapping function f , which determines what line-
ending to append to each r
i
in order to embed bit
b
i
. In all other cases where i > m the bitstring is
fully embedded within the cover text. Accordingly,
all remaining rows r
i
simply keep their original line-
ending ℓ
i
. As a result, we receive the watermarked
CSV text CSV
wm
for which W (R,B) = CSV
wm
applies.
Mapping function f : {0, 1} → {CRLF,LF},
determining what line-ending to append in order to
embed a single bit b of bitstring B, is defined in the
following way:
f (b) =
(
CRLF, if b = 0,
LF, if b = 1
(2)
It is worth noting that the mapping function was
arbitrarily chosen and may also be switched.
The embedding procedure can be implemented as
described in Algorithm 1. Accordingly, all rows need
to be iterated, and for each row r
i
either a new line-
ending is appended according to the mapping function
or the original line-ending ℓ
i
is maintained as soon as
all bits b
i
are embedded.
Data: R ← CSV rows, with
R := {r
0
,r
1
,...,r
n
}, with line-ending
ℓ
i
for each r
i
Data: B ← Watermark bitstring, with
B := {b
0
,b
1
,...,b
m
} and
b
i
∈ {0, 1} and m ≤ n
Result: CSV
wm
← watermarked CSV
Initialise CSV
wm
,lineEnding ← as empty
for i = 1 to n do
if i > m then
lineEnding ← ℓ
i
else if b
i
= 0 then
lineEnding ← CRLF
else
lineEnding ← LF
end
CSV
wm
← CSV
wm
+ r
i
+ lineEnding
end
return CSV
wm
Algorithm 1: CSV Watermark Embedding.
3.2 Extraction Procedure
In order to extract the watermark’s content, i.e.
bitstring B, each row of the watermarked CSV
text CSV
wm
needs to be iterated by applying an
inverse mapping function until all m bits are
extracted. Accordingly, the extraction function
W
−1
: CSV
wm
→ {0,1}
m
is denoted as:
W
−1
(CSW
wm
) =
m
M
i=0
f
−1
(ℓ
i
)
(3)
Thus B = W
−1
(CSW
wm
). Moreover, the inverse
mapping function f
−1
: {CRLF, LF} → {0, 1} is
defined as follows:
f
−1
(ℓ) =
(
0, if ℓ = CRLF,
1, if ℓ = LF
(4)
A Fragile Watermarking Technique for Integrity Authentication of CSV-Files Using Invisible Line-Ending Control Characters
459

Consequently, if there is no tampering with
the watermarked CSV text CSV
wm
, we expect the
following equation to hold true:
W
−1
(W (R,B)) = B (5)
Based on the prior, the extraction procedure
can algorithmically be described as detailed in
Algorithm 2. Therefore, each line-ending ℓ
i
must be
checked to extract each bit b
i
respectively. The entire
procedure is carried out until all m bits are extracted,
resulting in B.
Data: R ← CSV rows of CSV
wm
, with
R := {r
0
,r
1
,...,r
n
}, with line-ending
ℓ
i
for each r
i
Result: B ← bitstring
Initialise B ← as empty
for i = 1 to m do
if ℓ
i
= CRLF then
B ← B + 0
else if ℓ
i
= LF then
B ← B + 1
end
end
return B
Algorithm 2: CSV Watermark Extraction.
It is worth noting that determining the size m
of bitstring B, i.e., the number of line-endings
required to read in order to extract the embedded
information, might not be straightforward. In our
case of embedding digital signatures, the resulting
bitstring sizes are fixed length, dependent on the
signature used. Therefore, extracting the watermark
is no issue as long as the recipient knows when to stop
reading. As knowing what signature is embedded is
a precondition to be able to validate the signature at
all, we assume this as given. However, in other cases
with dynamic content size, the extraction procedure
may require adjustments to be able to identify the last
bit included. This could be done, e.g., by embedding
special delimiter bits or bytes that clearly signal the
end of contents.
4 EXPERIMENTAL EVALUATION
In order to evaluate the proposed fragile CSV
watermarking technique, we conducted three
experiments described in detail in the upcoming
section. We base our evaluation criteria on related
work by analysing the robustness, capacity, and
imperceptibility (Kn
¨
ochel and Karius, 2024; Li
et al., 2021). It is essential to note that despite
“the differences between watermarking techniques
[...], the requirements that any watermarking system
must satisfy can be summarised by the so-called
watermarking tradeoff triangle” (Li et al., 2021,
p. 172). This visual representation of the criteria as a
triangle illustrates their interdependence and conflicts
with one another (Li et al., 2021).
4.1 Experimental Setup
Several experiments were carried out to assess
our CSV watermarking technique, focusing on its
robustness, capacity, and imperceptibility. Each
experiment used a set of RFC4180 conform CSV
files. More specifically, two distinct datasets were
compiled for the experiments. The datasets are based
on prior work of (Vitagliano et al., 2023). In their
work, the authors aimed to compile a representative
real-world set of CSV files by scraping various data
sources to evaluate their CSV dialects. In total,
they collected 3712 files, which are accessible on
GitHub
7
, along with accompanying annotation JSON
files denoting the dialect characteristics of each CSV.
Furthermore, they designed an additional CSV file,
that is intended to represent an average CSV file, both
in dialect and content.
Consequently, we assembled two datasets: DS1
and DS2. A full overview of both datasets’
characteristics can be seen in Table 2. DS1 is a
subset of (Vitagliano et al., 2023) initial sample
set, excluding all files that were not RFC4180-
conforming, not Unicode-encoded or Unicode-
compatible, and exceeded a total file size of 1 Mb.
This was to ensure a consistent and manageable set
of files. Doing this resulted in 380 distinct CSV files.
The median amount of rows and columns are 64 and
8, respectively. The median file size is 7.33 KB.
Table 2: Dataset Overview as Median Values.
Dataset Files Rows Columns Size (KB)
DS1 380 64 8 7.33
DS2 1 84 9 21.4
DS2, on the other hand, comprises solely the
presented average CSV file. However, as this file used
LF line-endings instead of the RFC4180 stipulated
CRLF line-endings, we converted them accordingly.
DS2 has 84 rows, 9 columns and a file size of
21.4 KB. The content is a broad mixture of numeric
values of different formats, as well as various text
7
https://github.com/HPI-Information-Systems/Pollock
[24.02.25]
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
460

values encompassing dates, short text, long multi-line
descriptions, and special characters.
Using the datasets mentioned above, the
following experiments were conducted to analyse our
watermarking technique:
Experiment A: This experiment aimed to analyse
both the capacity and imperceptibility of the
technique. Therefore, we implemented a testbed
in Python, which allowed us to embed a random
bitstring of maximum length C
max
into all CSV files
of DS1. In a second step, we computed the following
metrics: Char and file size difference of original
and watermarked CSV, embedded bits per character,
and the Structural Similarity Index Measure (SSIM).
According to (Setiadi, 2021), SSIM is particularly
well suited to measure visual similarity as it closely
matches human perception. To apply SSIM, we
used the Python package Pillow to render a visual
representation of CSV files, to be then able to
calculate the SSIM between original and watermarked
files using scikit-image’s SSIM implementation. This
and all following experiments were run on a Desktop
Computer, running Windows 11 Pro 64-Bit 24H2,
equipped with an AMD Ryzen 7 3800XT 8-Core
processor, running with a base clock speed of 3.9
GHz, as well as 32GB of DDR4 3200MHz C16
memory. Moreover, Python 3.10 was used as an
interpreter.
Experiment B: As changing the line-endings of
CSV text modifies its syntax, this experiment
investigated whether the alterations fall within
acceptable boundaries. This is in line with (Vitagliano
et al., 2023) as they found that both CRLF and
LF are used widely for CSV files. Therefore, it’s
important to validate whether CSV tools can handle a
mixture of them. Otherwise, CSV tools would prompt
any syntax errors directly to its users, affecting the
watermark’s imperceptibility. Therefore, we chose
different CSV linters to check whether they are able
to validate a watermarked CSV file successfully. To
do this, we first watermarked the average CSV file of
DS2 to then manually conduct the experiment on five
online available CSV linters. The CSV linters used
are listed in Table 6. The linters were chosen based
on the fact that they offer direct file uploads. This
was an important consideration, as most other linters
would otherwise normalise line-endings if printed to
a text field before validating it.
Experiment C: This experiment aimed at analysing
the robustness of the watermarking technique by
investigating how different CSV tools and text editors
affect the embedded watermark. More specifically,
this experiment examined the normalisation of line-
endings. To do so, we first watermarked the average
CSV file of DS2. Next, we used a set of candidate
tools and manually opened and saved the file without
making any changes. This was to trigger a potential
normalisation or reformatting of the CSV file. The
candidate tools used are displayed in Table 3. The
set comprises major CSV tools and text editors
commonly used by regular users to edit and view CSV
text or files.
Lastly, in our effort to address the shortcomings of
related work, we decided to carry out all of the three
experiments for the Double Quote approach (DQ)
mentioned in (Ito, 2024) and for the Double Single
Quotes Code approach (DSQC) described in (Wen
and Wang, 2013) as well. A brief description of
their embedding technique is outlined in Section 2.4.
Doing this allowed for a comprehensive comparison
of our approach and existing work. Hence,
we implemented both approaches in our testbed,
adhering to the explanations provided by the authors
in their work. A comparison of all three methods
based on a lorem ipsum CSV text is displayed in
Figure 2. It is important to highlight that we needed
to make the usually invisible line-endings visible
to observe the difference in our line-ending-based
approach (LE).
(a) Source (b) LE ⟨010⟩
(c) DQ ⟨00111010⟩ (d) DSQC ⟨111010⟩
Figure 2: Rendered CSV Texts With Watermark Contents.
4.2 Robustness
The robustness of a watermark is connected to its
persistence, which refers to the ability to withstand
both intentional and unintentional modifications or
attacks (Swanson et al., 1998). Therefore, it
is typically assessed by simulating various attack
scenarios such as insertion, deletion, or replacement
attacks, thereby demonstrating its persistence across
different cases (Rizzo et al., 2019). However, in the
case of fragile watermarking, the opposite is true. A
fragile watermark should be capable of detecting any
changes made to the cover medium and enable the
A Fragile Watermarking Technique for Integrity Authentication of CSV-Files Using Invisible Line-Ending Control Characters
461
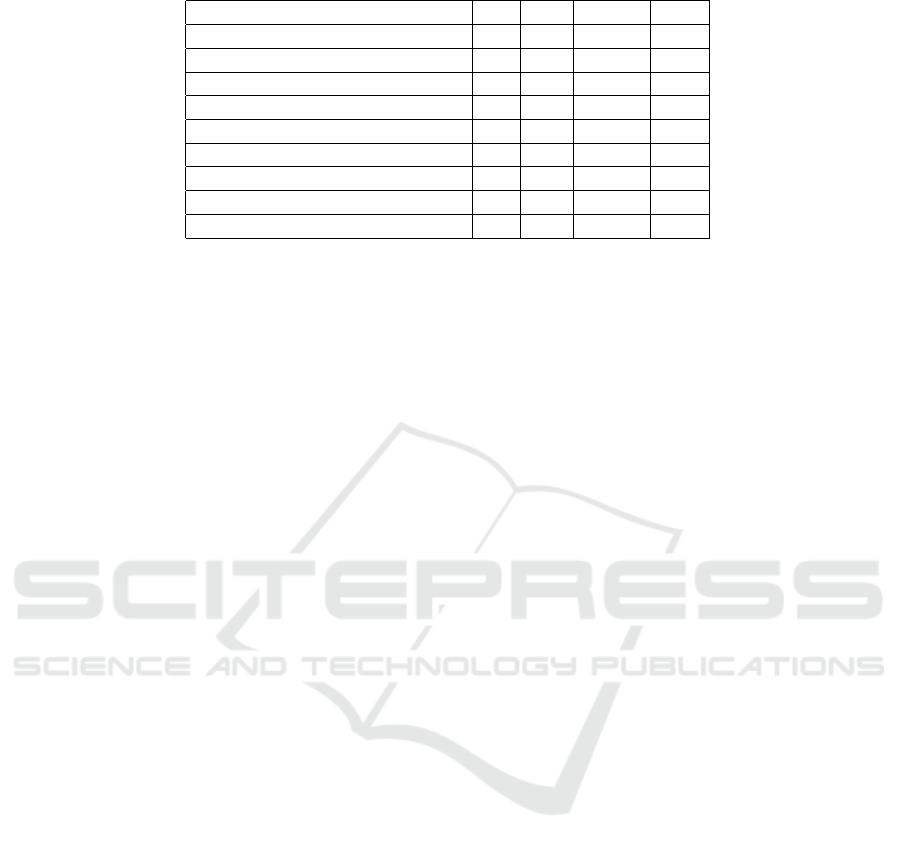
Table 3: Experiment C: Normalisation Test.
Tool LE DQ DSQC DS2
Excel (LTSC Pro+ 2021 v2108) ✓ ✓ (✓) ✓
LibreOffice Calc (v25.2.0) ✓ ✓ (✓) ✓
Google Sheets ✓ ✓ (✓) ✓
Windows Editor (v11.2410.21.0) ✓ ✗ ✗ ✗
VSCode (v1.97.2) ✓ ✗ ✗ ✗
Sublime Text (v4192) ✓ ✗ ✗ ✗
Notepad++ (v8.6.9) ✗ ✗ ✗ ✗
Atom (v1.60.0) ✗ ✗ ✗ ✗
Vim (v9.1.0) ✗ ✗ ✗ ✗
user to authenticate its integrity.
In our case, two factors must be considered when
analysing its fragility: line-ending normalisation
and digital signatures. As digital signatures are a
proven method of data integrity authentication (NIST,
2023), we mainly focused on the implications of
line-ending normalisation, investigating whether the
embedded digital signature would easily be wiped or
not. Therefore, we conducted Experiment C, opening
and saving a sample watermarked CSV file in various
commonly used CSV and text editors. The results are
presented in Table 3. A check mark ’✓’ indicates that
a normalisation occurred, whereas a ’✗’ indicates that
the file remained unchanged. On the other hand, a
’(✓)’ indicates that although the file was normalised,
its structure was compromised during the process and,
as a result, not accurately parsed.
Interestingly, normalisation occurred for all three
types of watermarked files as well as the original
unwatermarked source file. This is based on the
fact that two styles of using quotation exist: a
minimal one, enclosing only cells which require to
be escaped due to special characters like commas
or line-endings within the cell itself, or the holistic
one, which encloses all cells regardless of their
content (Vitagliano et al., 2023). Therefore,
especially CSV tools like Excel, LibreOffice Calc
or Google Sheets normalised both line-endings and
quotations, resulting in a consistent minimal CSV
text. Moreover, no CSV tool was able to parse the
DSQC watermarked CSV file, as they did not manage
to handle a mixed use of single and double quotation
marks. As a result, they broke the structure of the
CSV format when trying to normalise it.
Furthermore, it becomes evident that solely
CSV tools performed CSV specific normalisation.
All other general text editors did not normalise
quotations. However, some of them do normalise
line-endings. Considering the variety of text editors
available, it appears that more sophisticated text
editors such as Notepad++, Atom, or Vim do not
perform any modifications, like normalisation. In
contrast, more user-friendly tools like Windows
Editor tend to normalise line-endings.
Based on this, the robustness of all three
approaches is prone to normalisation to some degree.
Yet, our approach seems to be affected by it in
more cases, as line-ending normalisation is format-
agnostic. However, in all three cases, a normalisation
can technically be seen as a modification to the
original cover text, as it is indeed a modification of
the CSV text as a whole. Even if the watermark
would stay persistent, verifying the extracted digital
signature would fail regardless.
4.3 Capacity
A watermark’s capacity is often defined as the number
of bits the watermark achieves to embed into the
cover medium (Li et al., 2021). Besides robustness
and imperceptibility, it is also an important evaluation
criterion for watermarks, as watermarking techniques
usually attempt to achieve a high embedding capacity.
However, according to (Liu et al., 2025), the greater
the watermark’s size, the more it negatively impacts
the cover text’s fidelity. As a result, one typically has
to choose between the two.
We conducted Experiment A to assess the capacity
of our approach alongside the two other methods.
Using 380 representative RFC4180 conform CSV
files of varying length and contents, we embedded
a random bitstring of maximum length into each
file. The results can be seen in Table 4. The
embedding capacity, that is, the embedded bits per
character, was the highest for the DQ approach with
0.07 bits/char and a median of 475 embedded bits,
followed by DSQC with 0.05 bits/char and a median
of 312 embedded bits. Our approach accomplished
0.01 bits/char with a median of 64 embedded bits.
The significant capacity difference among
the three approaches arises from the embedding
technique. Whereas the DQ and DSQC approaches
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
462

Table 4: Experiment A: Results as Median Values.
LE DQ DSQC
Total Embedded Bits 64 475 312
Emb. Bits/Char 0.01 0.07 0.05
Char Count Difference -32 407 485
SSIM Score 1.0 0.62 0.56
both embed their bits per cell, our line-ending-based
approach is row-based. Thus, it can only include
as many bits as there are rows. As the sample set’s
median of rows was 64, so was the embedding
capacity of our approach. The slight difference
in DQ and DSQC is based on the fact that DQ
considers numeric values as well, whereas DSQC
solely enquotes text values.
Since all three methods depend on embedding a
digital signature into the CSV text, we must also
consider the size of common signatures. A brief
overview is pictured in Table 5. It becomes evident
that given our sample set, DQ is the only approach
which can reliably fit a digital signature in most
cases. DSQC, on the other hand, would be able to
utilise smaller signatures such as DSA. In contrast,
our approach can only embed a digital signature into
CSV files, with a minimum amount of 320 rows.
Therefore, all three approaches depend highly on the
size and content of a CSV text and are thus only
applicable for larger files. Yet, the size affects our
line-ending-based approach to a higher degree.
Table 5: Common Digital Signature Sizes Based On (NIST,
2013; NIST, 2023).
Digital Signature Signature Size
DSA 320 - 512 Bits
RSA 1024 - 4096 Bits
ECDSA 512 - 1024 Bits
EdDSA 512 - 896 Bits
4.4 Imperceptibility
The imperceptibility of watermarks is highly
connected to human perception. According to
(Swanson et al., 1998), a truly imperceptible
embedding procedure is given in case humans cannot
differentiate between original and watermarked
content. However, as capacity and imperceptibility
are conflicting goals, watermarking approaches
usually aim for either one of them.
Accordingly, our goal in conducting
Experiment A was, besides analysing the capacity, to
evaluate the visual similarity of the three approaches.
To do so, for each CSV file, we created a rendered
image of the plain CSV text both for the original and
watermarked contents. Based on this, we calculated
the SSIM score. The median values for each approach
are displayed in Table 4.
Following this, our approach has a median SSIM
score of 1.0, denoting full similarity between all
original and watermarked CSV texts and is therefore
indistinguishable. DQ on the other hand has a
median similarity of 0.62, slightly better than DSQC
with a similarity score of 0.56. The difference
arises because, in certain cases, DQ does not add
any additional double quotes to the row’s first or
proceeding cells. Doing this shifts the entire line to
the right, resulting in greater dissimilarity.
Additionally, we examined the char size
difference between the source and the watermarked
file. As an increase in char and, thus, in file size
affects both practicality and imperceptibility, we
chose to include this metric in our experiment. The
resulting differences are also displayed in Table 4.
Therefore, our approach managed to decrease the
char size with a median of −32 chars, whereas
both DQ and DSQC increased the char size by 407
and 485, respectively. The decrease in char size is
because our approach replaces some of the CRLF
line-ending control characters with a single LF
character. It is worth noting that a file having LF
line-endings per default would lead to an increase in
char size. However, as we used RFC4180 conform
samples, the default line-ending was CRLF.
Furthermore, by conducting Experiment B, we
evaluated whether the modifications lay within
acceptable boundaries. A CSV tool or linter
prompting any warnings or format errors to a potential
user would significantly decrease the imperceptibility.
We, therefore, manually used five online CSV linters.
The results can be seen in Table 6.
Table 6: Experiment B: CSV Linter Validity.
Linter LE DQ DSQC DS2
CSVLint.io ✗ ✓ (✗) ✓
ToolkitBay.com ✓ ✓ (✗) ✓
CSVLint.com ✓ ✓ ✓ ✓
Zazuko.com ✓ ✓ (✗) ✓
ExtendsClass.com ✗ ✗ (✗) ✗
The DQ approach was successfully validated by
four out of five linters. In contrast, two out of
five linters could not validate our approach. One
mentioned inconsistent line-endings, whereas the
other had problems parsing the file. Similarly, only
one linter successfully validated the DSQC approach.
All others were unable to parse it correctly and,
consequently, could not validate it at all. It is worth
noting that the ExtendsClass CSV validator could
A Fragile Watermarking Technique for Integrity Authentication of CSV-Files Using Invisible Line-Ending Control Characters
463

not validate any of the files, including the original
unwatermarked source file. The reason for this
was the presence of an empty last row in the file.
However, according to RFC4180, an empty last row
is permissible.
Following the previous results, our method
exhibits superior imperceptibility compared to the
other two approaches. This advantage arises as our
approach utilises invisible control characters, which
are not detectable by the human eye. In contrast, both
DQ and DSQC utilise visible quotations, degrading
the visual appearance.
5 DISCUSSION
In this study, we present a novel CSV fragile
watermarking technique. Our aim is to overcome the
shortcomings of existing approaches by addressing
the imperceptibility. Consequently, we investigated
the application of invisible line-ending control
characters and compared our technique with relevant
existing approaches by conducting three experiments
using two distinct representative datasets.
Our experiments show that robustness,
characterised by fragility in our case, is affected
by normalisation across all three methods. However,
normalisation is notably more influential on our
technique because of the usage of line-endings.
Nevertheless, a wiped watermark presents no issue
in most cases, as modifying a file would lead to an
invalid digital signature anyway. Therefore, a failed
validation might be as good as having no signature
at all for many users, as they would not be able to
estimate what changes have been made and whether
they affect the accuracy of the data or the format only
after all.
Furthermore, the experiments highlight the
difference in the overall watermarks’ capacities. Our
findings show that our approach is inferior to the other
approaches, as it embeds bits row-based rather than
cell-based. Considering the size of commonly used
digital signatures, it is evident that our approach is
applicable to files that are at least 320 rows in size
only. However, as we excluded all files greater than
1 Mb from our dataset, the median value might be
higher in reality. For example, in relevant related
work, researchers analysed 104.826 CSV files from
various sources (Mitl
¨
ohner et al., 2016). They found
that their sample set had a mean value of 379 rows,
with a min and max value of 1 and 8684, respectively.
This emphasises the great variation in row sizes.
Lastly, we demonstrate the complete
imperceptibility of our approach and its superiority
over the two other candidates. Consequently, a
watermarked CSV is indistinguishable by the human
eye using our technique. Only by comparing the
difference in file size, a user is able to detect the
modification. In contrast, when using DQ and DSQC,
a user can clearly identify the changes made both
visually and by size. However, it is worth noting that
a typical user who solely views the watermarked CSV
text without a side-by-side comparison might not
anticipate a watermark embedding scheme behind it.
Our findings validate the already known trade-off
watermark techniques must make regarding the three
criteria. We suggest that our contribution introduces
a novel fragile watermarking technique for CSV text.
To the best of our knowledge, this is the first fragile
watermarking technique for CSV, which is genuinely
imperceptible. It is, therefore, particularly well-
suited for use cases where imperceptibility is the most
important goal. However, if a use case requires higher
capacity, then either DQ or DSQC may be more
appropriate. In terms of robustness, the difference
between the approaches is, in reality, negligible.
Therefore, the choice between the approaches largely
depends on the use case and the objectives one aims
to achieve.
5.1 Limitations & Future Work
In this section, we explore the limitations of our
work and outline future touch points. Firstly,
although we utilised the wide range of dialects
available and relied on the robustness of popular
parsers and tools to handle such inconsistencies,
mixing line-endings adds to the already challenging
landscape of inconsistent CSV files. Our results
support the conclusions drawn by (Vitagliano et al.,
2023), indicating that the issue of inconsistent CSV
dialects remains a significant challenge for various
tools and parsers. Consequently, the effectiveness
of our method is highly dependent on the context.
Future research could improve this by exploring
which environments might benefit from our approach
specifically, where normalisation and inconsistencies
are not an issue.
Second, commonly used normalisation wipes our
watermark. While this may not undermine the goal of
solely utilising text whose integrity has been verified,
some users may prefer standard formatting and
normalisation optimisations, given that the contents
remain unchanged. Consequently, future work could
address this by developing a semi-fragile approach for
CSV text, which permits simple formatting-related
modifications. To do this, error correction codes
might be suitable for localising any changes.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
464

Third, our method uses a row-based embedding
scheme, which limits its capacity. Since a digital
signature is necessary to verify the text’s integrity,
our solution is impractical for small CSV files.
Hence, future research could investigate other more
compact tamper-detection methods, balancing size
and security. For example, in (Rizzo et al., 2016)
SipHash, a key-based hash is used, which is 64 bits in
size only. Additionally, the feasibility of expanding
the set of line-ending control characters could be
explored to increase overall capacity.
6 CONCLUSION
In this study, we proposed a novel fragile
watermarking technique for CSV text. We aimed
to address the shortcomings of existing techniques,
focusing on imperceptibility specifically. Using a
combination of different invisible line-ending control
characters, we are able to embed any byte-encodable
information into a CSV cover text. Moreover, we
conducted three experiments with representative
datasets in order to evaluate and compare our
approach with relevant existing work.
We found that while our approach has limited
capacity compared to existing techniques, it excels
in imperceptibility. Therefore, our approach is most
suitable in situations where imperceptibility is the
primary goal. However, due to the line-ending-
based embedding scheme, our approach is more
vulnerable to normalisation, making the watermark
sensitive to formatting procedures. Consequently,
careful consideration is required when choosing to
implement our embedding scheme. Future work
should address this issue by developing a semi-fragile
watermarking technique which allows for format
optimisations.
ACKNOWLEDGEMENTS
CRediT Author Statement
Florian Zimmer: Conceptualisation, Methodology,
Software, Data Curation, Investigation, Writing -
Original Draft, Visualisation. Malte Hellmeier:
Conceptualisation, Methodology, Investigation,
Writing - Original Draft, Visualisation. Motoki
Nakamura: Conceptualisation, Investigation.
Tobias Urbanek: Software.
REFERENCES
Abba, A. H. and Hassan, M. (2018). Design and
implementation of a csv validation system. In Bogach,
N., Pyshkin, E., and Klyuev, V., editors, Proceedings
of the 3rd International Conference on Applications in
Information Technology, pages 111–116, New York,
NY, USA. ACM.
Alkawaz, M. H., Sulong, G., Saba, T., Almazyad, A. S., and
Rehman, A. (2016). Concise analysis of current text
automation and watermarking approaches. Security
and Communication Networks, 9(18):6365–6378.
Allen, J. D. (2007). The Unicode standard 5.0. Addison-
Wesley, Upper Saddle River NJ, new ed. edition.
Bender, W., Gruhl, D., Morimoto, N., and Lu, A. (1996).
Techniques for data hiding. IBM Systems Journal,
35(3.4):313–336.
Brickely, D., Tennison, J., and Herman, I. (2016). Csv
on the web working group. Accessed February 2025
at: https://www.w3.org/2013/csvw/wiki/Main
Page.
html.
Cox, I. J., Miller, M. L., and Bloom, J. A. (2000).
Watermarking applications and their properties.
In Proceedings International Conference on
Information Technology: Coding and Computing
(Cat. No.PR00540), pages 6–10. IEEE Comput. Soc.
Fortune Business Insights (2024). Server operating
system market volume. Accessed February
2025 at: https://www.fortunebusinessinsights.
com/server-operating-system-market-106601.
Hartung, F. and Kutter, M. (1999). Multimedia
watermarking techniques. Proceedings of the IEEE,
87(7):1079–1107.
He, J., Ying, Q., Qian, Z., Feng, G., and Zhang, X.
(2020). Semi-structured data protection scheme based
on robust watermarking. EURASIP Journal on Image
and Video Processing, 2020(1).
Hellmeier, M., Qarawlus, H., Norkowski, H., and Howar,
F. (2025). A hidden digital text watermarking method
using unicode whitespace replacement. In Bui, T. X.,
editor, Proceedings of the 58th Hawaii International
Conference on System Sciences, pages 7411–7420.
Hawaii International Conference on System Sciences.
Hisham, S. I., Muhammad, A. N., Zain, J. M., Badshah, G.,
and Arshad, N. W. (2013). Digital watermarking for
recovering attack areas of medical images using spiral
numbering. In 2013 International Conference on
Electronics, Computer and Computation (ICECCO),
pages 285–288. IEEE.
IEEE (1986). Portable operating system interface for
computer environments (POSIX).
Ito, A. (2024). Embedding digital signature into csv files
using data hiding.
Jaigirdar, F. T., Rudolph, C., and Bain, C. (2019). Can i
trust the data i see? In Proceedings of the Australasian
Computer Science Week Multiconference, pages 1–10,
New York, NY, USA. ACM.
Jalil, Z. and Mirza, A. M. (2009). A review of digital
watermarking techniques for text documents. In
A Fragile Watermarking Technique for Integrity Authentication of CSV-Files Using Invisible Line-Ending Control Characters
465

2009 International Conference on Information and
Multimedia Technology, pages 230–234. IEEE.
Kamaruddin, N. S., Kamsin, A., Por, L. Y., and Rahman,
H. (2018). A review of text watermarking: Theory,
methods, and applications. IEEE Access, 6:8011–
8028.
Kerckhoffs, A. (1883). La cryptographie militaire: pp. 5-38.
J. Sciences Militaires.
Kn
¨
ochel, M. and Karius, S. (2024). Text steganography
methods and their influence in malware: A
comprehensive overview and evaluation. In P
´
erez-
Gonz
´
alez, F., Comesa
˜
na-Alfaro, P., Kr
¨
atzer, C., and
Vicky Zhao, H., editors, Proceedings of the 2024 ACM
Workshop on Information Hiding and Multimedia
Security, pages 113–124, New York, NY, USA. ACM.
Li, Y., Wang, H., and Barni, M. (2021). A survey
of deep neural network watermarking techniques.
Neurocomputing, 461:171–193.
Liu, A., Pan, L., Lu, Y., Li, J., Hu, X., Zhang, X., Wen,
L., King, I., Xiong, H., and Yu, P. (2025). A survey of
text watermarking in the era of large language models.
ACM Computing Surveys, 57(2):1–36.
Liu, T.-Y. and Tsai, W.-H. (2007). A new steganographic
method for data hiding in microsoft word documents
by a change tracking technique. IEEE Transactions
on Information Forensics and Security, 2(1):24–30.
Mitl
¨
ohner, J., Neumaier, S., Umbrich, J., and Polleres, A.
(2016). Characteristics of open data csv files. In 2016
2nd International Conference on Open and Big Data
(OBD), pages 72–79. IEEE.
NIST (2013). Digital signature standard (DSS) - FIPS 186-
4.
NIST (2023). Digital signature standard (DSS) - FIPS 186-
5.
Otto, B. (2022). The evolution of data spaces. In Otto, B.,
ten Hompel, M., and Wrobel, S., editors, Designing
Data Spaces, pages 3–15. Springer International
Publishing, Cham.
Petitcolas, F., Anderson, R. J., and Kuhn, M. G. (1999).
Information hiding-a survey. Proceedings of the IEEE,
87(7):1062–1078.
Podilchuk, C. I. and Delp, E. J. (2001). Digital
watermarking: algorithms and applications. IEEE
Signal Processing Magazine, 18(4):33–46.
Por, L. Y., Wong, K., and Chee, K. O. (2012). Unispach:
A text-based data hiding method using unicode
space characters. Journal of Systems and Software,
85(5):1075–1082.
Rani, S. and Halder, R. (2022). Comparative analysis
of relational database watermarking techniques: An
empirical study. IEEE Access, 10:27970–27989.
Rizzo, S. G., Bertini, F., and Montesi, D. (2016). Content-
preserving text watermarking through unicode
homoglyph substitution. In Desai, B. C., Toyama, M.,
Bernardino, J., and Desai, E., editors, Proceedings
of the 20th International Database Engineering &
Applications Symposium on - IDEAS ’16, pages
97–104, New York, New York, USA. ACM Press.
Rizzo, S. G., Bertini, F., and Montesi, D. (2019). Fine-grain
watermarking for intellectual property protection.
EURASIP Journal on Information Security, 2019(1).
Saltzer, J. H. and Ossanna, J. F. (1970). Remote terminal
character stream processing in multics. In Cooke,
H. L., editor, Proceedings of the May 5-7, 1970,
spring joint computer conference on - AFIPS ’70
(Spring), page 621, New York, New York, USA. ACM
Press.
Setiadi, D. R. I. M. (2021). Psnr vs ssim: imperceptibility
quality assessment for image steganography.
Multimedia Tools and Applications, 80(6):8423–
8444.
Shafranovich, Y. (2005). Rfc 4180. Accessed February
2025 at: https://www.rfc-editor.org/rfc/rfc4180.html.
Swanson, M. D., Kobayashi, M., and Tewfik, A. H. (1998).
Multimedia data-embedding and watermarking
technologies. Proceedings of the IEEE, 86(6):1064–
1087.
Taleby Ahvanooey, M., Li, Q., Hou, J., Dana Mazraeh, H.,
and Zhang, J. (2018). Aitsteg: An innovative text
steganography technique for hidden transmission of
text message via social media. IEEE Access, 6:65981–
65995.
Taylor, P. (2024). Volume of data/information created,
captured, copied, and consumed worldwide from 2010
to 2023, with forecasts from 2024 to 2028. Accessed
February 2025 at: https://www.statista.com/statistics/
871513/worldwide-data-created/.
Tian, Y. and Nogales, A. F. R. (2023). A survey
on data integrity attacks and ddos attacks in cloud
computing. In 2023 IEEE 13th Annual Computing
and Communication Workshop and Conference
(CCWC), pages 0788–0794. IEEE.
van den Burg, G. J. J., Naz
´
abal, A., and Sutton, C. (2019).
Wrangling messy csv files by detecting row and type
patterns. Data Mining and Knowledge Discovery,
33(6):1799–1820.
Vitagliano, G., Hameed, M., Jiang, L., Reisener, L., Wu,
E., and Naumann, F. (2023). Pollock: A data loading
benchmark. Proceedings of the VLDB Endowment,
16(8):1870–1882.
Wen, Q. and Wang, Y. (2013). An efficient fragile
web pages watermarking for integrity protection of
xml documents. In Hutchison, D., Kanade, T.,
Kittler, J., Kleinberg, J. M., Mattern, F., Mitchell,
J. C., Naor, M., Nierstrasz, O., Pandu Rangan, C.,
Steffen, B., Sudan, M., Terzopoulos, D., Tygar, D.,
Vardi, M. Y., Weikum, G., Shi, Y. Q., Kim, H.-
J., and P
´
erez-Gonz
´
alez, F., editors, Digital Forensics
and Watermaking, volume 7809 of Lecture Notes in
Computer Science, pages 135–144. Springer Berlin
Heidelberg, Berlin, Heidelberg.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
466
