
Research on Self Adjustment Technology of Data Mining Algorithm
in Control Engineering
Chunxiang Huang, Nenjun Ben
*
and Guojun Yan
Institute of Intelligent Manufacturing, Yancheng Polytechnic College, Yancheng, Jiangsu,224005, China
Keyword: Data Mining Algorithm, Control Engineering, Automatic Adjustment.
Abstract: The research direction is the self-tuning technology of data mining algorithm in control engineering. The main
purpose of this research is to develop a new technology of automatic fault identification and diagnosis in
various industrial systems based on nonlinear models. The proposed method will be used to optimize such
systems through neural networks. The results obtained in the implementation stage show that the neural
network with a large number of hidden units (up to 500) can be used as an effective tool to solve nonlinear
model problems. The research on self-tuning technology of data mining algorithm in control engineering is
to find the best method of using data mining algorithm to control the process. It is also called intelligent
system or artificial intelligence (AI). The main goal of this research is to develop an intelligent system that
can perform better than human operators in the control process. Self tuning technology refers to the ability of
computer systems to learn from past experience and improve performance by using these experiences without
any human intervention.
1 INTRODUCTION
Now the numerical solution of the computer is so
simple and fast. From the aspect of solution alone (or
from the aspect of publishing papers), the frequency
domain method seems to have no need to exist (Wang
and Shen, et al. 2019). Just like the Routh criterion, it
has completed the historical task and can quit the
historical dance stage with honor (unfortunately, it is
still teaching the Routh criterion now). Moreover, the
frequency domain method will eventually be
transformed into the time domain algorithm (Xu and
Miao, 2018). However, the real engineering of
control system, LTI system, still depends on Bode
diagram (signal or system) most of the time (Bi and
Meng, et al. 2021). Many of the top international
companies and engineers I have learned will look at
Bode diagram when designing control system, at least
before the actual operation of the system (Hong,
2021). And it is not only the control system, but also
in the field of signal processing (digital signal
processing), even more obvious (Sun and Zhijian, et
al. 2019).
Personally, I think the more important reason is
physical intuition. This word is actually not rigorous.
In fact, the frequency domain method is often not
rigorous, but it is useful (Luo and Zheng, et al. 2019).
For example, the cut-off frequency / bandwidth, if
spectrum peak, low-frequency gain, high-frequency
gain, these key points can be seen by experience,
roughly (pay attention to roughly) the response curve,
robustness, high and low if interference suppression,
stability, accuracy, etc., and really can be seen by
simple calculation in your mind. More importantly, if
you want to change a certain characteristic (response
curve, robustness, high and low if interference
suppression, stability, accuracy, etc.), you can also
directly know which parameters to adjust and what
impact this characteristic will have on other
characteristics (Chen and Xu, et al. 2021).
In contrast, given a differential equation, even if
you can calculate some performance indicators
through the computer, if you want to change this
indicator to meet a specific requirement, you can
almost only try (Tung-and WU, et al. 2019); And
most of the time, one performance is good, and the
other performance is not good, because there are
interactions (Bai and Xiong, et al. 2019). Based on
this, this paper studies the self-tuning technology of
data mining algorithm in control engineering.
Huang, C., Ben, N. and Yan, G.
Research on Self Adjustment Technology of Data Mining Algorithm in Control Engineering.
DOI: 10.5220/0013545400004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 1, pages 453-456
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
453

2 RELATED WORKS
2.1 Data Mining Algorithm
Data mining is the process of discovering useful
patterns in data. The purpose of data mining session
is to determine the trend and pattern of data. Data
mining emphasizes the processing of a large number
of observed databases. It is a frontier discipline
involving database management, artificial
intelligence, machine learning, pattern recognition,
and data visualization. From a statistical point of
view, it can be seen as the automatic exploratory
analysis of a large number of complex data sets
through computers. Data source: it is the foundation
of data warehouse system and the data source of the
whole system. It usually includes internal and
external information of the enterprise. Internal
information includes various business processing
data and various document data stored in RDBMS.
External information includes various laws and
regulations, market information and competitor
information, etc (Liang, 2018).
Data storage and management: it is the core of the
whole data warehouse system. The real key of data
warehouse is data storage and management. The
organization and management mode of data
warehouse determines that it is different from
traditional database, and also determines its
manifestation of external data. To decide what
products and technologies to adopt to establish the
core of data warehouse, we need to analyze the
technical characteristics of data warehouse. The data
of existing business systems are extracted, cleaned
up, effectively integrated, and organized according to
the theme. Data warehouse can be divided into
enterprise level data warehouse and department level
data warehouse (usually called data mart) according
to the coverage of data. Figure 1 below shows the data
mining process.
Figure 1: Data mining process
OLAP server: effectively integrate the data
required for analysis and organize it according to the
multidimensional model, so as to conduct multi angle
and multi-level analysis and find trends. Its specific
implementation can be divided into ROLAP,
MOLAP and HoLap. ROLAP basic data and
aggregate data are stored in RDBMS; MOLAP basic
data and aggregate data are stored in
multidimensional database; HoLap basic data is
stored in RDBMS, and aggregated data is stored in
multidimensional database.
Front end tools: mainly including various report
tools, query tools, data analysis tools, data mining
tools and various application development tools
based on data warehouse or data mart. Among them,
data analysis tools are mainly for OLAP servers,
while report tools and data mining tools are mainly
for data warehouses.
2.2 Control Engineering Technology
As for master control engineering, first of all, we need
to mention the basic theory of control engineering
system control process, that is, control engineering
cybernetics. Its main research contents are
information, state and control engineering topology.
Usually, this theory is the reference basis for building
master control engineering. The main function of the
master control project is to input control commands
and parameters, and display the operation and
feedback information of the controlled equipment. In
addition, from the perspective of the basic framework
of the master control of control engineering, it is
divided into three control structures: centralized,
decentralized and hierarchical. Each control structure
has the advantages and disadvantages of dichotomy.
Second, the centralized control structure is relatively
simple in structure and control, which makes the
management and network construction easier, and the
delay time is small, reducing the error in the
transmission process. However, the installation
workload is large and the cost is high, which is not
conducive to resource sharing. The advantage of
decentralized control structure is its high reliability.
Even if the controller fails, the control engineering
system will not be completely paralyzed. Therefore,
when the system scale meta method is centralized
control, the communication is more convenient, or the
user requires the use of decentralized control
structure, the decentralized control structure can be
used. However, the decentralized control structure
also has some defects. If the state of the control
engineering system cannot be controlled and
observed, the hierarchical control structure combines
INCOFT 2025 - International Conference on Futuristic Technology
454
the centralized and decentralized control structure,
which can realize both local control and global
coordinated control.
𝑃
1
1𝑝
𝑝
𝑝
𝑝1
𝑝
𝑃
(1
)
𝑆𝑖𝑚
𝑑
,𝑑
∑
𝑊
𝑊
∑
𝑊
∙
∑
𝑊
(2)
The controlled control engineering system is
mainly based on the cybernetics of control
engineering. The control mechanism can be
implemented through software or hardware to
provide certain control services. Generally, the
controlled control engineering system can be
understood as a data resource, or it can be a control
system centered on computer, which combines field
control with management and data acquisition. In
terms of structure, it mainly includes control
engineering control center, acquisition node user
interface and intermediate control node. During the
design process, certain principles should be followed,
that is, the planning of safety detection, safety
protection and emergency recovery reflects the
principle of integrity, and the classification of safety
levels and levels of controlled control projects reflects
the principle of hierarchy. The introduction of
variable factors in controlled control engineering
reflects the principle of dynamic, and the restriction
of authority reflects the principle of minimization.
Only by ensuring the application of design principles
can the safety and controllability of control
engineering system be guaranteed.
3 RESEARCH ON SELF-TUNING
TECHNOLOGY OF DATA
MINING ALGORITHM IN
CONTROL ENGINEERING
System analysis refers to the analysis of system
performance with known system structure and
parameters System design refers to the performance
indicators that the control object and the control
system are known to achieve. It is required to design
a system to achieve these indicators.
If the parameters of the control system cannot
fully meet the performance index of the design
requirements by adjusting its own parameters, it is
necessary to add some devices in the system whose
parameters and characteristics can be changed as
needed to make the system performance fully meet
the design requirements, which is system correction
(correction), and the corresponding correction device
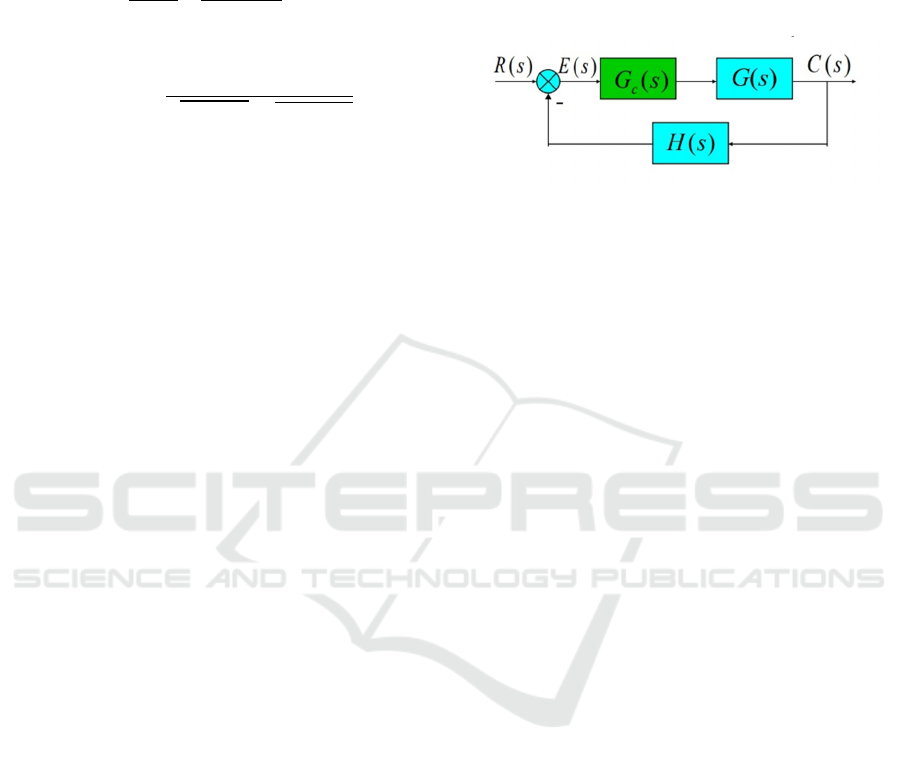
is also called compensator As shown in Figure 2
below, series correction in automatic adjustment.
Figure 2: Series correction in automatic adjustment
It infers future data from historical and current
data according to time series data, and it can also be
considered as related knowledge with time as the key
attribute. At present, time series prediction methods
include classical statistical methods, neural networks
and machine learning. In 1968, box and Jenkins put
forward a set of relatively perfect time series
modeling theory and analysis methods. These
classical mathematical methods predict time series by
establishing random models, such as autoregressive
model, autoregressive moving average model,
summation autoregressive moving average model
and seasonal adjustment model. Because a large
number of time series are non-stationary, their
characteristic parameters and data distribution change
with the passage of time. Therefore, only through the
training of some historical data, the establishment of
a single neural network prediction model can not
complete the accurate prediction task. Therefore,
people put forward retraining methods based on
statistics and accuracy. When it is found that the
existing prediction model is no longer suitable for the
current data, retrain the model to obtain new weight
parameters and establish a new model. Many systems
also use the computational advantages of parallel
algorithms to predict time series.
In addition, other types of knowledge can be
found, such as deviation, which is a description of
differences and extreme special cases, and reveals the
abnormal phenomena of things that deviate from the
Convention, such as special cases outside the
standard category, outliers outside the data clustering,
etc. All these knowledge can be found at different
conceptual levels, and with the improvement of
conceptual levels, from micro to meso to macro, to
meet the needs of different users at different levels of
decision-making.
Research on Self Adjustment Technology of Data Mining Algorithm in Control Engineering
455

It reflects the characteristic knowledge of the
common nature of similar things and the different
characteristic knowledge between different things.
The most typical classification method is based on
decision tree. It constructs a decision tree from the set
of examples, which is a guided learning method. This
method first forms a decision tree according to the
training subset (also known as window). If the tree
cannot give the correct classification of all objects,
select some exceptions to add to the window, and
repeat the process until the correct decision set is
formed. The final result is a tree, whose leaf node is
the class name, and the intermediate node is an
attribute with branches, which corresponds to a
possible value of the attribute Data classification also
includes statistics, rough set and other methods.
Linear regression and linear discriminant analysis are
typical statistical models. In order to reduce the cost
of decision tree generation, an interval classifier is
also proposed. Recently, some people have also
studied the use of neural network methods for
classification and rule extraction in databases.
4 CONCLUSIONS
The self-tuning technology of data mining algorithm
is the most important part of control engineering. Self
adjustment technology is to adjust the feedback
signal, which is generated by data mining algorithm
to achieve a stable and reliable control system. This
paper studies the self-tuning technology of data
mining algorithm in control engineering. First, there
are two types of algorithms used to adjust the
feedback signal: independent algorithm and
dependent algorithm. Secondly, there are three
methods to adjust the feedback signal: direct method,
indirect method and mixed method. In general, it can
be said that the focus of these studies is to develop
intelligent systems based on the use of AI technology.
ACKNOWLEDGEMENT
2021 Jiangsu Province Policy Guidance Plan (Special
for Introducing Foreign Talents) Fund Project:Key
technology research and development of wall-
climbing robots for large ferromagnetic surfaces such
as ships(BX2021051)
REFERENCES
Wang X , Shen Y , Yang H . Exploration of Data Mining
Technology in Data of Food Control[J]. Chinese
Pharmaceutical Affairs, 2019.
Xu Y , Miao Z . Application of data mining technology in
quality control of building material equipment
manufacturing process[J]. China Building Materials
Science & Technology, 2018.
Bi B , Meng J , Cheng B . A Study on the Dynamic
Adjustment of Pressure Relief Gas Drainage Drilling in
Mined-Out Areas[J]. 2021, 9(2):9.
Hong X . Application of Data Mining Technology in
Software Engineering[J]. Journal of Physics:
Conference Series, 2021, 2066(1):012013-.
Sun W , Zhijian W U , Zhang F , et al. Self-Adjustment
Algorithm of Self-Regulating Grounding Fault in
Distributed Microgrid[J]. Computer & Digital
Engineering, 2019.
Luo Q F , Zheng H J , Zhang S C . Preliminary Study on
Analysis Technology of Normal Water Storage Level
Adjustment for Constructed Reservoir-Taking
Hangzhou City Qingshan Reservoir as an Example[J].
Zhejiang Hydrotechnics, 2019.
Chen Z , Xu P , Feng F , et al. Data mining algorithm and
framework for identifying HVAC control strategies in
large commercial buildings[J]. 2021.
Tung-sheng, WU, Ying-sing, et al. The Control Technology
of Medical Expenses: A Combination of Data Mining
and Quality Control Chart[C]// 2019.
Bai Y , Xiong Y , Jiang L . Application of Data Mining
Technology in College Student Management[J].
Journal of Hubei Open Vocational College, 2019.
Liang J . Microblog community data mining algorithm
based on chaotic stability sub-control mechanism[J].
Foreign Electronic Measurement Technology, 2018.
INCOFT 2025 - International Conference on Futuristic Technology
456
