
Analysis of Three-Dimensional Human Movements and Its Research
in Sports Dance Teaching
Ruili Zheng
1,*
and Jingqi Zhang
2
1
Physical Education Research Department, Xinjiang University, Urumqi, Xinjiang, China
2
Office of the president of the Party Committee, Xinjiang Institute of Engineering, Urumqi, Xinjiang, China
Keywords: VR Technology, Three-Dimensional Analysis
, Human Movement, Movement Analysis, Dance Teaching
Abstract: Since human beings are the most important element in the natural and social environment, various human
activities are accompanied by a wealth of important information about the interaction between humans and
nature, and between humans and society. The automatic learning and recognition of human action behavior
is of great significance in the fields of advanced human-computer interaction, automatic monitoring of human
behavior, and intelligent analysis of sports, and has a wide range of application prospects. This article mainly
studies the three-dimensional human movement analysis and its application in sports dance teaching. This
article summarizes three methods for obtaining 3D human action skeleton data, and uses depth map sequence
as the method for obtaining action skeleton data in this article. Then, the 3D human skeleton model and action
pose feature description method in this paper are proposed. This article describes the key frame extraction
method of 3D human motion data, summarizes the characteristics of 3D human motion data, and analyzes the
current main key frame extraction methods. This paper studies the 3D human action recognition methods and
analyzes the advantages and disadvantages of various recognition methods. This article studies the current
state of sports dance teaching, and based on this, proposes a teaching method that combines sports dance with
three-dimensional human movement analysis. Through experiments, it is found that when analyzing the
movements in the dance process, the estimation errors of the human head, pelvis, upper and lower arms and
upper and lower legs in the first 300 frames are all under 70mm, which can accurately analyze the current
dance movements. The standardization can help students learn dance better.
1 INTRODUCTION
With the vigorous development of our country's
economy and the continuous acceleration of the pace
of people's lives. Faced with the ever-increasing
pressure of life, people devote more time to work and
study, while the time allocated to physical exercise
and dance art is getting less and less, which invisibly
leads to a general decline in the physical fitness of the
public (Purvis and Denise, 2016). With the rapid
development of the electronic information industry,
more and more electronic products are applied to all
areas of life (Wei, 2017). In this article, a sports dance
teaching method using a three-dimensional human
movement analysis instrument is proposed to help
students learn dance.
Many scholars have conducted research and
analysis on three-dimensional human movement
analysis and its application in sports dance teaching.
For example, Ayame Yamazaki, Takuo Ikeda and
Takeshi Tsutsumi applied video fundus photography
technology to three-dimensional recording and
analysis of eye movements, which required
quantification of the main sequence (Borgogno,
2017). They used infrared images to obtain the
characteristics of the torsion fundus and analyzed its
main sequence (Hooshang and Eric, et al. 2016). Guo
Yusun, Chen Wenjuan and others proposed a new
dance self-learning framework based on Laban's
motion analysis principles (Yamazaki and Ikeda, et
al. 2019), so that students can automatically analyze
dance movements and correct dance skills without an
expert (Sun and Chen , et al. 2017). They proposed a
"shape-effort" feature description model to reflect the
subtleties of dance movement.
This article introduces the related technologies of
3D human motion analysis in detail, including 3D
human motion skeleton data acquisition method,
motion key posture frame extraction method and
human motion recognition (Wang and Huang, et al.
Zheng, R. and Zhang, J.
Analysis of Three-Dimensional Human Movements and Its Research in Sports Dance Teaching.
DOI: 10.5220/0013538700004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 1, pages 227-232
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
227

2016). This article introduces the current situation of
sports dance teaching, and puts forward a sports
dance teaching method based on three-dimensional
human movement analysis technology (Jiang and
Zhang , et al. 2017). This article analyzes the error of
each limb joint when the three-dimensional human
body movement analysis instrument analyzes sports
dance movements through experiments (Migliorati
and Cevidanes , et al. 2021). This article analyzes the
effect of three-dimensional human movement
analysis on sports dance teaching through
experiments.
2 RESEARCH ON THE ANALYSIS
OF 3D HUMAN MOVEMENT
CHARACTERISTICS BASED
ON VR TECHNOLOGY AND
ITS APPLICATION IN THE
DESIGN OF SPORTS DANCE
TEACHING SYSTEM
2.1 3D Human Motion Analysis
Related Technology
2.1.1 Three-dimensional Human Body
Motion Skeleton Data Acquisition
Method
In computer vision, there are three main methods to
obtain 3D human action skeleton sequence: based on
multi-view 2D video image sequence reconstruction,
based on 3D motion capture system acquisition and
based on depth map sequence mapping (Shogo and
Yasuhiro, et al. 2018). Due to differences in human
body shape, lack of depth information in 2D images,
and partial self-occlusion, it is difficult to accurately
estimate 3D human bones (Fan and Zheng, et al.
2018). At present, the 3D skeletal joint data of the
human body is mainly obtained by two methods
based on the 3D motion capture system and the depth
map sequence. The 3D skeletal joint data obtained
based on the motion capture system has higher
accuracy and fewer noise points, but the motion
capture equipment is expensive, cumbersome to use
and generally not applicable (Peng C and Pan B Z, et
al. 2020). Based on the depth information collection
and mapping methods of the depth sensor, the
prediction of 3D bone joints usually has errors, and
the depth map will also contain noise, but the depth
sensor is small in size and has universal applicability.
2.1.2 Action Key Pose Frame
Extraction
Method
The key posture framework of the three-dimensional
human body action refers to the posture that can best
reflect the action changes in the action and
represented by the 3D bone joint coordinate data. The
current 3D motion data key frame extraction methods
are mainly divided into two types: uniform sampling
extraction and adaptive sampling extraction. Uniform
sampling extraction refers to re-sampling the motion
sequence at equal time intervals. Due to the problems
of undersampling and oversampling (leading to
missing and redundant key frames), this method has
not been widely used. The method of adaptive
sampling to extract key frames usually uses the
original motion data to be converted into motion
feature description, and automatically extracts the
posture of the key frame by analyzing the motion
posture feature of the action posture sequence, which
solves the uniformity problem well. At present, the
adaptive sampling and extraction of key frames are
mainly divided into three categories: frame
subtraction, curve simplification and clustering.
2.1.3 Human
Action Recognition
Human action recognition research belongs to the
category of pattern recognition. After describing the
mathematical model of action posture features, it
mainly includes two basic tasks: standard action
classifier design and action classification recognition.
According to the characteristics of the algorithm,
action recognition algorithms are mainly divided into
three categories: methods based on template
matching, methods based on state space, and methods
based on syntax analysis. The template-based method
is easy to implement, does not require a large number
of training action samples, has a small amount of
calculation, and has a higher recognition rate when
the quality and parameters of the reference template
are both optimized. However, this method is sensitive
to the length of the action gesture sequence and noise
points, and its robustness is not good enough. It is
usually suitable for the classification and recognition
of simple actions. The method based on state space
can effectively overcome the problem that template
matching is sensitive to noise. The algorithm has high
robustness and can recognize simple and continuous
actions. It is the current mainstream action
recognition method and is widely used. However, this
method also has disadvantages. In order to obtain an
ideal classifier model, a large number of action
samples are required for training. For a classifier
INCOFT 2025 - International Conference on Futuristic Technology
228

model with more parameters, the amount of
calculation is relatively large. The method based on
grammatical analysis is helpful to understand the
complex action structure and effectively use the prior
knowledge, but the current research is still in its
infancy, usually combined with the first two methods.
2.2 B.VR Technology
Virtual reality technology is developed by integrating
multiple technologies, including real-time 3D
computer graphics technology, wide-angle stereo
display technology and head tracking technology. In
the VR system, the image that the user sees through
the VR device depends on the position and direction
of the eyes, but the human visual system and the
motion system are separated, which is determined by
the structure of the human brain. Using head tracking
technology can link the vision system with the motion
system, so that the virtual objects in the VR system
look more realistic.
2.3 Sports Dance Teaching
In the past, when people wanted to learn sports dance,
they usually had two choices: go to a sports dance
club to learn from a teacher or learn by themselves by
watching animations and videos.
2.3.1 Sports Dance Club
At present, the most commonly used method for
dance teaching is the demonstration-practice method.
Demonstration-exercise is a simple and reasonable
teaching method that can help people learn movement
and mental skills. In this method, the teacher must
first demonstrate the dance for the students, and then
the students imitate the teacher's movements under
the teacher's on-site supervision. Afterwards, the
teacher will give feedback to inform the students of
their performance, thereby helping the students to
further improve their dance moves. Traditionally,
dance demonstrations and information feedback must
be completed by a teacher. This learning model has
proven to be effective, but the dependence on the
teacher makes this learning model lack of
convenience and flexibility.
2.3.2 Sports Dance Teaching System
With the development of technology, students can
now take sports dance courses without the teacher
present. Some sports dance teaching systems have
been developed and put into use one after another.
However, these systems can only provide simple
demonstration functions, and they cannot provide any
feedback information to help students improve their
sports dance moves.
2.3.3 Sports Dance Class Using Three-
Dimensional Human Movement
Analysis
According to the current situation of sports dance
teaching, the idea of combining three-dimensional
human movement analysis technology with sports
dance teaching system and applying it in the sports
dance classroom was put forward, and a comparative
experiment was done. Three-dimensional human
movement analysis can more accurately analyze the
current standardization of dance movements, which
can help students learn dance better. The application
of three-dimensional human movement analysis in
sports dance classrooms helps to increase students'
interest in sports dance, helps improve students'
learning efficiency, and enables students' subjectivity
to be brought into full play, thereby improving
teaching efficiency and quality.
3 ANALYSIS OF 3D HUMAN
MOVEMENT
CHARACTERISTICS BASED
ON VR TECHNOLOGY AND
ITS APPLICATION
EXPERIMENT IN THE DESIGN
OF SPORTS DANCE
TEACHING SYSTEM
3.1 Three-Dimensional Human
Movement Analysis-Error Analysis
3.1.1 Test subject
This article collects 10 dance talents as volunteers to
conduct experiments. The three-dimensional human
motion analysis instrument records the physical state
of the 10 volunteers when they dance the same dance,
analyzes the difference between the data recorded by
the three-dimensional human motion analysis
instrument and the actual data, and understands the
accuracy of the three-dimensional human motion
analysis instrument in analyzing dance movements.
Analysis of Three-Dimensional Human Movements and Its Research in Sports Dance Teaching
229

3.2 Evaluation Experiment of Dance
Class Using Three-Dimensional
Human Movement Analysis
3.2.1 Experimental Setup
A total of 46 students, including 29 girls and 17 boys,
participated in the evaluation experiment. None of
these students have any experience in dance learning.
Let them learn folk dance and modern dance
successively. These students were divided into an
experimental group and a control group with 23
people in each group. The experimental group entered
a dance class using three-dimensional human
movement analysis to learn dance, while the control
group entered a traditional dance class to learn. In
order to ensure the quality of the experiment, three
judges who have received dance training were invited
to evaluate the dance movements of the students. Only
when at least two people approve a student’s dance
move, is it considered that the student has mastered the
dance move. Finally, the students who mastered the
dance were invited to participate in a questionnaire
survey. Among them, in the study of ethnic dance,
there are 22 people in the experimental group and 19
people in the control group; in the study of modern
dance, there are 23 people in the experimental group
and 22 people in the control group.
3.2.2 Data Sources
This article uses questionnaires to obtain student data,
and analyzes and processes these data to verify the
effect of three-dimensional human movement
analysis on sports dance teaching.
3.2.3 Ways of Identifying
3.2.3.1 Cross-Validation
When learning folk dance and modern dance
successively, a cross-validation method will be used,
that is, the experimental group learning folk dance
will become the control group when learning modern
dance; and the control group learning folk dance will
become the experiment when learning modern dance
group. In this way, all 46 students have the
opportunity to learn dance in two different ways.
3.2.3.2 T-test
When verifying the learning efficiency, because the
learning time is a continuous variable, this article uses
the paired sample test method in the t-test to verify
the efficiency of the three-dimensional human
movement analysis for students’ dance learning. The
paired sample test statistics are:(1),(2),and (3).
𝑡=
𝑑
̅
−μ
0
𝑠
√
𝑛
⁄
(1
)
𝑑
̅
=
∑
𝑑
1
𝑛
(2
)
𝑠
=
∑
2
1
1
(3
)
Among them, d
is the average of the paired
sample difference, s
is the standard deviation of the
paired sample difference, and n is the number of
paired samples. This statistic t obeys the t distribution
with n−1 degrees of freedom under the condition that
μ=μ0 is true.
3.2.3.3 Chi-Square Test
In the questionnaire survey, because the study is a
non-continuous variable, this paper uses the chi-
square test method to test the help of three-
dimensional human movement analysis to students'
dance learning and the cognitive burden it provides
and the degree of student satisfaction.
4 THREE-DIMENSIONAL
HUMAN MOVEMENT
ANALYSIS AND ITS
EXPERIMENTAL RESEARCH
ANALYSIS IN SPORTS DANCE
TEACHING
4.1 Three-Dimensional Human
Movement Analysis-Error Analysis
The average value of all limb joint coordinate errors
is used as the error of each frame. Table 1 shows the
estimation errors of the human head, pelvis, upper
and lower arms, and upper and lower legs in the first
300 frames.
It can be seen from Figure 1 that when the 3D
human movement analysis analyzes the movements
in the dance process, the estimation errors of the
human head, pelvis, upper and lower arms, and upper
and lower legs in the first 300 frames are all below
70mm. All the above results show that the 3D human
motion analysis performs well in human body posture
tracking, can more accurately analyze the current
INCOFT 2025 - International Conference on Futuristic Technology
230
standardization of dance movements, and can help
students learn dance better.
Table 1: Estimation Error of Part of Human Body Joints
During Dance
Hea
d
Pelvi
s
Lowe
r Arm
Uppe
r
Arm
Calve
s
Thig
h
50 22.5 16.4 54.7 37.4 31.4 25.8
10
0
25.7 20.1 26.8 26.4 27.3 26.7
15
0
22.6 22.4 62.1 32.7 43.6 27.1
20
0
36.7 31.6 54.3 34.1 32.2 31.2
25
0
34.5 32.4 52.1 33.4 34.6 32.3
30
0
39.8 32.7 52.9 55.2 31.7 32.8
Figure 1: Estimation Error of Part of Human Body Joints
During Dance
4.2 An Evaluation Experiment in A
Dance Classroom Using Three-
Dimensional Human Movement
Analysis
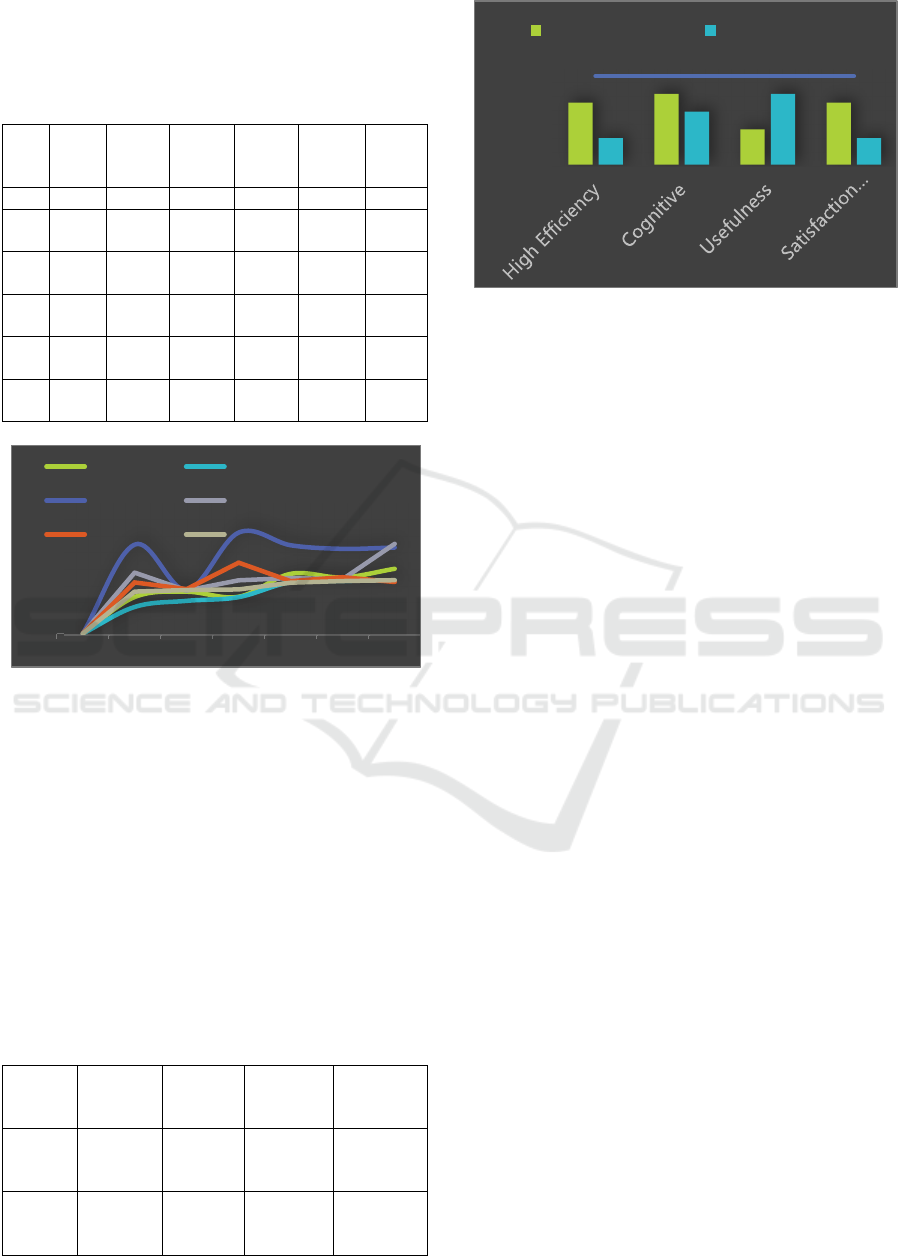
Table 2 shows the results of T test and Chi-square test
on the efficiency of the system, the cognitive burden
of the students, the usefulness of the system, and the
degree of satisfaction of the students when the
experimental group and the control group are learning
two types of dance.
Table 2: Test Result
High
Efficien
cy
Cogniti
ve
Burden
Usefulne
ss
Satisfacti
on Level
Nation
al
Dance
0.0007 0.0008 0.0004 0.0007
Moder
n
Dance
0.0003 0.0006 0.0008 0.0003
Figure 2: Test Result
From Figure 2, it can be seen that the two groups
of middle school students have significant differences
in the efficiency of the system, the cognitive burden
of the students, the usefulness of the system, and the
average evaluation of satisfaction. The P values of the
test results are all below 0.001. It can be concluded
that dance teaching classrooms using 3D human
movement analysis are more efficient, more helpful,
and more satisfying than traditional teaching
classrooms. The 3D human movement analysis
learning environment can provide a more suitable
cognitive burden.
5 CONCLUSIONS
Nowadays, as the pace of life accelerates, people have
fewer and fewer opportunities to exercise. The
popularization of sports and dance art has become
very difficult, and there are many reasons why people
suffer because of the lack of correct guidance
methods to help them exercise effectively. This
article is dedicated to the development of a sports
dance teaching system based on 3D human movement
analysis. Our goal is to record the coach’s movements
and provide a three-dimensional display effect to help
later students learn the movements better. At the same
time, the system should have the ability to analyze the
quality of sports learning, can point out and correct
the errors of students' local joint points in the process
of sports learning, and can also perform an overall
assessment of the overall sports learning quality of
students.
0
100
0 50 100 150 200 250 300
Error(mm)
Frame
Head Pelvis
LowerArm Upper Arm
Calves Thigh
0
0.0005
0.001
0.0015
Test Result(P)
Evaluation Index
National Dance Modern Dance
Analysis of Three-Dimensional Human Movements and Its Research in Sports Dance Teaching
231

ACKNOWLEDGMENTS
Xinjiang University Doctoral Research Funding
Project.(NO:BS190128)
REFERENCES
Purvis, Denise. Dance Science: Anatomy, Movement
Analysis, Conditioning[J]. Journal of Dance Education,
2016, 16(4):157-157.
Wei Z . Application and implementation of motion capture
and motion analysis technology in dance teaching[J].
Revista de la Facultad de Ingenieria, 2017, 32(16):474-
480.
D, Borgogno, A, et al. Test-electron analysis of the
magnetic reconnection topology[J]. Physics of Plasmas,
2017, 24(12):122303-122303.
Hooshang H , Eric T , Li B , et al. Towards a Cybernetic
Model of Human Movement[J]. Mechanical
Engineering Research, 2016, 6(1):29
Yamazaki A , Ikeda T , Tsutsumi T . Main sequence of
torsional saccadic eye movement – analysis by three-
dimensional video-oculography[J]. Acta Oto-
Laryngologica, 2019, 139(1):1-3.
Sun G , Chen W , Li H , et al. A Virtual Reality Dance
Self-learning Framework using Laban Movement
Analysis[J]. JOURNAL OF ENGINEERING
SCIENCE AND TECHNOLOGY REVIEW, 2017,
10(5):25-32.
Wang X , Huang T , Wang W . Human Skeleton Three-
Dimensional Reconstruction-Based Sports Features
Analysis[J]. Journal of Computational & Theoretical
Nanoscience, 2016, 13(12):9988-9992.
Jiang X , Zhang Y , Bai S , et al. Three-dimensional
analysis of craniofacial asymmetry and integrated,
modular organization of human head[J]. International
Journal of Clinical and Experimental Medicine, 2017,
10(8):11424-11431.
Migliorati M , Cevidanes L , Sinfonico G , et al. Three
dimensional movement analysis of maxillary impacted
canine using TADs: a pilot study[J]. Head & Face
Medicine, 2021, 17(1):1-10.
Shogo O , Yasuhiro E , Ryuta S , et al. Three-dimensional
kinematic analysis of glenohumeral, scapular, and
thoracic angles at maximum shoulder external rotation
associated with baseball shadow pitching: comparison
with normal pitching[J]. Journal of Physical Therapy
Science, 2018, 30(7):938-942.
Fan H , Zheng H , Zhao J . Three-dimensional
discontinuous deformation analysis based on strain-
rotation decomposition[J]. Computers and
Geotechnics, 2018, 95(mar.):191-210.
Peng C , Pan B Z , Xue L F , et al. Three-dimensional
structural modeling and deformation analysis of
Archean magnetite quartzite from the Anshan–Benxi
area, northeastern China[J]. Geomechanics and
Geophysics for Geo-Energy and Geo-Resources, 2020,
6(4):62.
INCOFT 2025 - International Conference on Futuristic Technology
232
