
Electronic File Management Method and System Based on Machine
Learning Algorithm
Han Debin, Song Ruolin and Zhang Yue
Weifang Engineering Vocational College, 262500, China
Keywords: Computer Science Theory, Machine Learning Algorithms, Electronic Archives, Management Methods,
System.
Abstract: In order to meet the challenges of electronic archives management methods and systems, this study proposes
an innovative archives management method and system method based on machine learning algorithms in
view of the shortcomings of the existing whale algorithms. The new approach leverages the theoretical
principles of computer science to pinpoint and locate key influencing factors, and accordingly intelligently
classifies indicators to reduce potential interference. At the same time, using the unique mechanism of
machine learning algorithms, this scheme cleverly constructs the design strategy of management methods.
The empirical results show that this scheme shows a significant improvement compared with the traditional
whale algorithm in key performance indicators such as the accuracy of the file management method and
system, and the processing efficiency of key factors, showing its obvious strong advantages. In electronic
archives, archives management methods and systems play a vital role, which can accurately predict and
optimize the growth trend and output results of electronic archives management methods and systems.
However, in the face of complex simulation tasks, traditional whale algorithms show some inherent
shortcomings, especially when dealing with multi-level challenges, their performance is often unsatisfactory.
To overcome this problem, this study introduces a new idea of file management method and system optimized
by machine learning algorithm, accurately controls the influencing parameters through computer science
theory, and uses this as a road map for indicator allocation, and then uses machine learning algorithm to
innovate and construct a system scheme. The test results clearly point out that in the context of the evaluation
criteria, the new scheme has been significantly optimized in terms of accuracy and processing speed for a
variety of challenges, showing stronger performance superiority. Therefore, in the electronic file management
method and system, the simulation scheme based on machine learning algorithm successfully overcomes the
shortcomings of the traditional whale algorithm and significantly improves the accuracy and operation
efficiency of the simulation.
1 INTRODUCTION
The importance of records management methods and
systems in electronic archives is self-evident.
Through simulation, various parameters and changes
in this process can be predicted and understood (Yan
and Li, 2023), providing guidance and support for
actual production. However, the traditional archival
management methods and system schemes have
certain deficiencies in accuracy, which limits their
effectiveness in practical application (SunYubo and
Liu Peipei, et al. 2023). In order to solve the problem
of the accuracy of traditional archives management
methods and systems (Zou Xuhua and Shao
Xiangping, et al. 2023), researchers have introduced
machine learning algorithms into archives
management methods and system analysis in recent
years (Cheng, 2023). Machine learning algorithms is
a computational method based on group behavior that
simulates the interaction and cooperation between
individuals to achieve the goal of global optimization
(Zhao, 2023). The algorithm has the characteristics of
decentralization, immutability and smart contract,
which can effectively solve the accuracy problems
existing in traditional schemes (Bow and Di, et al.
2023). The file management method and system
optimization model based on machine learning
algorithm further improve the accuracy and reliability
of the simulation by optimizing the parameters and
algorithms in the process of file management method
Debin, H., Ruolin, S. and Yue, Z.
Electronic File Management Method and System Based on Machine Learning Algorithm.
DOI: 10.5220/0013534800004664
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 3rd International Conference on Futuristic Technology (INCOFT 2025) - Volume 1, pages 25-31
ISBN: 978-989-758-763-4
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.
25

and system. The model adjusts and optimizes the
various parameters in this process to achieve the best
management method (Li and Lu, et al. 2023). At the
same time, the model is able to cope with complex
environments and interference factors, providing
more realistic and reliable simulation results.
Researchers evaluated the effectiveness of the file
management method and system optimization model
based on machine learning algorithms through a large
number of experiments and data analysis (Ni and
Zheng, et al. 2023). The results show that compared
with the traditional archives management methods
and system schemes, the proposed model has
significant advantages in many aspects.
2 THEORETICAL MODEL
CONSTRUCTION OF
ARCHIVES MANAGEMENT
METHODS AND SYSTEMS
The machine learning algorithm uses computer
technology to improve the file management method
and system strategy, and analyzes a series is
i
W
of
key parameters involved in the system research to
identify the parameter values is
i
E
that do not meet
the standards in the study. Subsequently, the
algorithm integrates these parameter values is
ˆ
ˆ
/, /
iiii ii
eEEhHH==
into the archival
management method and system scheme, and then
comprehensively evaluates the implementation
possibility of the study. The calculation process can
be referred to equations (1) and (2).
(1
)
(2
)
Machine learning algorithms combine the
advantages of computer technology and use file
management methods and systems to quantify, which
can improve the accuracy of file management
methods and systems.
The machine learning algorithm implements a
global search for the file management method and
system according to the set number of iterations, and
completes an iterative process for each search.
Pheromones will be generated in the process is
i
E
of
file management methods and systems, so the
remaining pheromones in the search path need to be
updated after each iteration process, and the formula
is
s
W
described as follows:
(3)
In order to avoid falling into the local optimal
problem in the target iteration process, the upper limit
of pheromone value is
s
E
set, and the formula is
o
η
described as follows:
(4)
From the above, the comprehensive function of
the archives management method and system can be
obtained, and the result is shown in equation (5).
(5)
In order to improve the effectiveness of the
archives management method and the reliability of
the system, it is necessary to standardize all data, and
the results is shown in equation (6).
(6)
Before the machine learning algorithm, it is
necessary to conduct a comprehensive analysis of the
file management method and system scheme, and
map the file management method and system
requirements to the resource query system research
database, and eliminate the unqualified resource
query system research scheme. The anomaly
assessment scheme can be proposed, and the results
is
()
i
No t
shown in equation (7).
2
1
22
i
ii i
o
E
y
WE W
x
δ
δη
=× =
2
2
2
P
2
ii
o
WE
v
σ
σ
η
∂Ω
==
∂
2
2
22
1
P
()
4R
n
si
i
WXX
v
π
=
∂Ω
==−
∂
2
1
2
s
s
o
WE
η
=
2
2
2
2
0
4lim
s
x
i
E
R
uv
E
δ
σπ
→
∂Ω
=
∂∂
*
*
lim 4
ss
R
ii
EE
dy
R
EEdx
σπ
→∞
×
=
×
INCOFT 2025 - International Conference on Futuristic Technology
26
(7)
3 PRACTICAL EXAMPLES OF
RECORDS MANAGEMENT
METHODS AND SYSTEMS
3.1 Concepts Related to the
Construction of Archives
Management Methods and System
Models
The construction of the archives management method
and system model contains a number of key concepts
to ensure that the resulting model can not only fully
map the complexity of the management method
process, but also demonstrate sufficient applicability
and accuracy (Yang and Zhou, et al. 2023). First of
all, it involves the thinking of systems theory, which
emphasizes the need to conduct a holistic
examination of the mathematical, chemical, and
physical elements involved in management methods
when shaping models, and to understand how these
elements interact and interact from a system
perspective to jointly affect the overall process of
management methods (Yi and Wang, et al. 2023).
Further, there is the concept of dynamic evolution,
which requires the model to be keenly awis of time-
based dynamic changes and processes, as the process
of management methods continues to evolve over
time, keeping pace with the change and growth of
activities. The concept of multi-level modeling
reveals that the constructed model should incorporate
the scale of change in different fields from macro to
micro, from physics and mathematics to process flow,
to ensure that the model is compatible and covers
different levels of detailed information (Zhao and Su,
et al. 2023). The parameter estimation and
verification steps is the key processes to ensure that
the records management method and system model
truly reflect the actual search process, and these
parameters is determined and fine-tuned through the
actual data to ensure that the model results is
consistent with the actual observations. The data-
driven principle further highlights the central role of
observational data in the model building and
validation stage, and the collection, processing, and
analysis of data constitute an indispensable part of
building accurate models (Qi and Cheng, et al. 2023).
In addition, considering that different management
methods and different electronic file paths may
require different model configurations, the scalability
of the model is particularly critical, which means that
the model should be designed to be easy to change
and add new components to adapt to the changing
management method environment and needs (Yang
and Cheng, et al. 2024).
Based on the above concepts, the construction of
archives management methods and system models
requires not only thorough scientific insight into
multidisciplinary processes, but also a broad system
analysis perspective, strong data processing
technology, and future-oriented open thinking. Many
elements work together to create an accurate and
widely applicable electronic file process simulation
model.
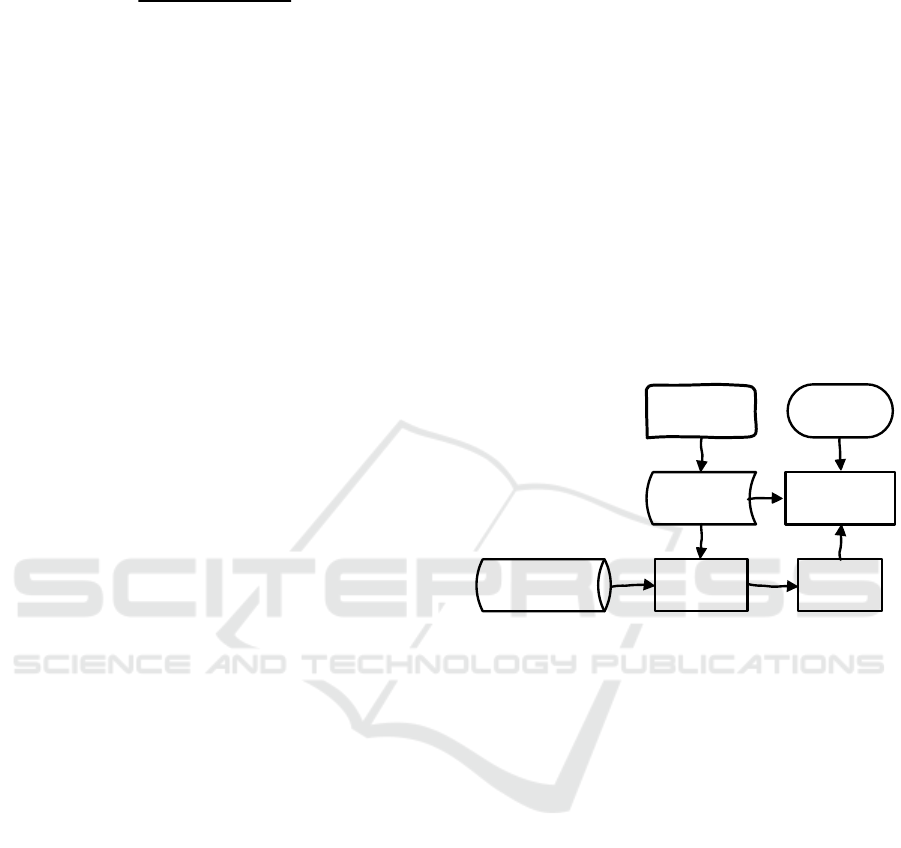
Simulate the records management method and
system process, as shown in Figure 1.
Computer
science
Machine
learning
Measure
E-record
Office
procedure
System Electron
Figure 1: Records management methods and systematic
analysis process
Compared with the whale algorithm, the
introduction of machine learning algorithms in the
file management method and system has brought a lot
of innovation to solve practical problems. As a critical
step in processing natural language, accuracy is
critical in understanding and processing natural data
in search. This algorithm can better deal with the
complexity of semantics and syntax in the
management method, so the machine learning
algorithm shows its inherent advantages compared
with the traditional whale algorithm in terms of the
rationality and accuracy of the file management
method and system. As shown in Figure II, the
changes in the file management method and system
scheme can be used to obtain higher accuracy search
results by using machine learning algorithms, because
the machine learning algorithm can more accurately
parse the keywords and structures in the user's search
intent and achieve more detailed information
matching. compared with whale algorithms, which
often rely on preset rules and paths, machine learning
algorithms can process data more flexibly in the face
0
() ( )
() lim
(4)
ii
i
x
ij
gt Fd
No t
mean v
δ
→
+
=
Β
+
∏
Electronic File Management Method and System Based on Machine Learning Algorithm
27

of complex searches, reducing misunderstandings
and ambiguities.
In terms of search speed, although the whale
algorithm searches quickly in the case of clear
structure, the machine learning algorithm can also
achieve fast and effective search feedback by
optimizing the cutting and matching process of
words, especially in the face of large-scale thesaurus
and dynamically updated search resources, the
machine learning algorithm can maintain efficient
searchability. In terms of stability, machine learning
algorithms is able to respond to changing search
environments and usage patterns through continuous
learning and self-optimization, so as to provide a
stable search experience. However, due to the lack of
learning mechanism, the whale algorithm may need
to be redesigned and adjusted once it encounters a
change in search mode or a new data type, which is
slightly inferior in terms of stability. In practical
applications, machine learning algorithms can be
combined with other advanced machine learning
technologies, such as deep learning and semantic
understanding, to further improve the overall
performance and user experience of file management
methods and systems. As for the whale algorithm,
although it still has its unique application scenarios in
the search task with clear rules and fixed rules, it is
obvious that the machine learning algorithm provides
a more advanced and adaptable solution in modern
file management methods and systems.
3.2 Archives Management Methods
and Systems
When developing a design for a management
methodology system, it is important to note that the
solution should cover all types of data. We categorize
this data into unstructured, semi-structured, and
structured information, each with its own
characteristics and methods of storage, processing,
and analysis. Using efficient machine learning
algorithms, we is able to perform efficient
preliminary screening of these diverse data types to
obtain a set of preliminary selected file management
methods and system solutions. After screening by
machine learning algorithms, we obtained a series of
potential records management methods and system
solutions. We then go further and analyze the
practical feasibility of these options in detail. This
step is crucial because it helps us identify those that
can be implemented effectively in the real world, as
well as those that may be theoretically feasible but
difficult to apply in practice. In order to more
comprehensively verify the effectiveness of different
records management methods and system solutions,
we must com pis multiple records management
methods and system solutions at different levels.
These options must be rigorously selected and
compared to ensure that they cover design strategies
from basic to advanced. In this way, we can create a
more detailed comparison framework, as shown in
the table below (Table I.), which details the features,
advantages, and performance of each design solution
under different conditions, so that we can make the
most reasonable choice accordingly.
Table 1: Subject-related parameters of the study
Category Rando
m data
Reliabil
it
y
Analys
is rate
Compatibil
it
y
Governm
ent
agencies
90.56 87.79 89.06 84.63
School
Education
Departme
nt
87.56 89.25 85.82 88.10
Ban
k
88.42 88.77 90.15 89.02
insurance 88.43 85.71 87.01 86.38
Mean 88.01 86.42 92.54 89.65
X6 90.56 87.79 89.06 84.63
3.3 Archives Management Methods,
Systems and Stability
The stability of the records management method and
system is the key element to ensure the long-term
effective operation of the system and the provision of
reliable services. A stable management methodology
system is able to consistently deliver high-quality
search results in the face of different search loads,
changes in user behavior, and data updates, without
drastic performance degradation or service
interruption due to external changes.
Stability affects several aspects of archives
management methods and systems, including:
Archives management methods and system system
architecture robustness: A strong system architecture
is the basis for ensuring stability. This typically
involves redundant design, fault-tolerant
mechanisms, and highly available hardwired and
softwoods resources to prevent a single point of
failure that could lead to the collapse of the entire
system. Accuracy of data processing in the file
management method and system: The management
method system needs to process and analyze data
accurately to ensure the reliability of search results.
This requires the algorithm logic to be able to handle
a variety of boundary conditions and anomalies, and
to maintain consistency in the results when the data is
INCOFT 2025 - International Conference on Futuristic Technology
28
updated or the structure changes. Consistency
between the records management approach and the
search efficiency of the system: The efficiency of the
system should be consistent when dealing with
searches of all sizes. Whether it's a small amount of
data searching or a large batch of data processing, the
system should provide stable response times to avoid
performance degradation under high loads. Archive
management method and system anti-interference
ability: A stable management method system should
be able to adapt to the influence of external
interference factors such as network fluctuations and
system load changes to avoid service interruption or
failure. Scalability and adaptability of records
management methods and systems: With the increase
of resources and the development of technology, the
system should be able to flexibly expand and adapt to
new search needs and data types to ensure stable
service delivery.
To achieve the stability of the management
method system, the following strategies is usually
required: file management method and continuous
performance monitoring of the system: real-time
monitoring of system performance and user behavior
in order to find potential problems in time and make
adjustments. File management method and system
load balancing: Reasonable allocation of system
resources and search load can improve the pressure
resistance and stability of the system. Archives
management methods and regular maintenance and
update of the system: Regularly maintain and update
the system, fix known problems, and enhance the
stability of the system. Archives Management
Methods and System Optimization Algorithms and
Data Structures: Optimize the underlying algorithms
and data structures to improve the computing
efficiency of the system and the ability to stably
handle a large number of concurrent searches.
Records management methods and systems develop a
detailed disaster recovery plan to ensure that the
system can recover quickly after a major failure. File
management methods and system user feedback and
system iteration: Actively collect user feedback,
continuously iterate and update the system, and
improve stability and satisfaction. Through these
measures, the archives management method and
system aims to create a stable service platform that
can not only adapt to the needs of reality, but also be
able to respond quickly to future changes. In order to
verify the accuracy of the machine learning
algorithm, the file management method and the
system scheme is compared with the whale algorithm,
and the file management method and the system
scheme is shown in Figure 2.
By looking at the comparison of the data and
charts in Figure 2, we can clearly see that the machine
learning algorithm surpasses the whale algorithm in
the execution effect of the file management method
and the system, and its error rate is relatively low.
Figure 2: Records management methods and systems with
different algorithms
This low error rate points to an important
conclusion, that is, the application of machine
learning algorithms to file management methods and
systems brings a relatively stable and reliable
performance. On the contrary, although the whale
algorithm also has its application in the file
management method and system, its results fluctuate
greatly, resulting in inconsistent overall performance.
This fluctuation may be due to the limitations and
challenges that whale algorithms may face when
dealing with complex and changeable management
approach tasks. In other words, the whale algorithm
shows an uneven effect in the file management
method and system, which reduces its application
value and reliability in this isa to a certain extent. In
conclusion, the stability and low error rate of machine
learning algorithms show their superiority in the field
of file management methods and systems, while
whale algorithms show limitations in such
Figure 3: Archive management methods and systems based
on machine learning algorithms
Electronic File Management Method and System Based on Machine Learning Algorithm
29
applications. Therefore, when seeking a file
management method and system solution with high
efficiency and stable performance, machine learning
algorithm may be a more reasonable choice.
Figure 3 shows the experimental results of using
machine learning algorithms to obtain better
performance in file management methods and
systems using the whale algorithm. There may be
several key factors that make machine learning
algorithms perform well: Introduction of adjustment
coefficients: In the process simulation of
management methods, machine learning algorithms
may introduce adjustment factors to adjust
parameters in the simulation process in more granular
terms. These coefficients may be closely related to the
specific operating conditions or reactor design in the
lab, allowing the algorithm to more accurately reflect
and optimize real-world processes. Threshold setting
and scenario filtering: By setting thresholds for
acquired Internet information, a machine learning
algorithm may retain only those that meet the set
criteria among multiple candidates. This means that
the algorithm is able to automatically reject
simulation results that may be based on
misinformation or unreliable data, ensuring the
quality of the optimization process. Balance between
exploration and utilization of swarm algorithm: It
maintains a good balance between exploring and
finding new solutions and optimizing known
solutions by exploiting them. This allows the
algorithm to avoid premature convergence to the local
optimal solution while maintaining efficient
optimization, and to explore a wider solution space as
shown in Figure 2.
On the other hand, the poor performance of whale
algorithms in this scenario may be related to some of
their inherent limitations: overfitting: decision trees
may tend to be complex and, in some cases, overfit
the training data, resulting in insufficient
generalization of new data. Selecting the local
optimal solution: The decision tree is split at each
node only considering the attributes of the local
optimum, which may not be able to capture the global
optimal parameter configuration of complex
management methods.
Machine learning algorithms search and optimize
multiple solutions in parallel, and continuously use
information sharing among group members to guide
the search process, so it is better to find the global
optimal or near-global optimal solutions than a single
whale algorithm when dealing with complex file
management methods and system scenarios. The
robustness and adaptability of this algorithm make it
an indispensable tool in fields such as bioengineering
and industrial process optimization.
Table 2: Comparison of different methods of file
management methods and system rationalization
Algorith
m
Adjustme
nt factor
Threshol
d
settings
Scenari
o
screenin
g
Explor
e
Machine
learning
algorith
ms
86.06 86.51 87.57 89.77
Whale
algorith
m
92.30 87.14 89.16 87.71
P 89.94 85.07 88.44 88.69
X 85.19 91.16 82.55 86.26
Figure 4: Comparative study of the research scheme of the
algorithm
From Figure 4, it is clear that the performance of
the file management method and system using the
machine learning algorithm far exceeds that of the
design using the whale algorithm. This significant
gap is mainly due to the fact that the machine learning
algorithm introduces a special adjustment coefficient
in the process of file management methods and
systems. The introduction of this coefficient enhances
the flexibility and adaptability of the algorithm,
allowing it to better adjust the strategy according to
different situations. In addition, machine learning
algorithms set a specific threshold for Internet
INCOFT 2025 - International Conference on Futuristic Technology
30

information processing. Through this threshold
setting, the algorithm can effectively identify and
exclude those file management methods and system
solutions that do not meet the predetermined
standards. This intelligent filtering mechanism makes
machine learning algorithms more efficient when
processing a large number of candidates, ensuring
that only the most suitable solutions is selected to
continue to participate in the further design and
evaluation phases. Combining these two innovations,
namely the introduction of adjustment coefficients to
improve the control ability of the algorithm, and the
setting of information thresholds to accurately screen
the design solutions that meet the standards, the
machine learning algorithm makes the file
management method and system process more
efficient, and the output design scheme is more high-
quality. These improvements finally form the core
advantages of the algorithm over the whale algorithm
in the file management method and system problems.
4 CONCLUSIONS
Aiming at the accuracy of archives management
methods and systems, a new comprehensive
optimization scheme was proposed, which was based
on machine learning algorithms and advanced
computer technology. Initially, the security of
information and the credibility of tampering were
ensured by the decentralized nature of machine
learning algorithms and their data consistency
assurance. Then, combined with computer
technology, the collected data is deeply analyzed and
processed in detail, so as to dig out the intrinsic
attributes and potential value of the data. This study
also delves into the key performance indicators
required to ensure the accuracy and credibility of
archival management methods and systems, and
constructs a comprehensive web-based information
collection platform that plays a crucial role in
ensuring the accuracy of research outputs. However,
it is worth noting that when applying machine
learning algorithms, it is necessary to be cautious in
the selection of file management methods and
systematic evaluation systems, so as to effectively
explore and utilize the advantages of machine
learning algorithms and further improve the accuracy
and practical application value of research results.
REFERENCES
Yan Jun,&Li Yue (2023) A method and system for
managing illegal occupation of road parking spaces
based on machine learning algorithms CN116311885A
Sun Yubo, Liu Peipei, Yang Yuchen, Yu Yang, Yu
Huan,&Sun Xiaoyi, et al. (2023) A quantitative
evaluation method for motor disorders based on two-
dimensional video and its clinical application research
Journal of Biomedical Engineering, 40 (3), 499-507
Zou Yuhua, Shao Xiangping, Wu Peijia, Yang Huijun,&Yu
Tongqi (2023) Research on a comprehensive intelligent
energy management system based on big data analysis
and machine learning Energy and Environmental
Protection, 45 (9), 215-220
Hu Cheng (2023) Research on the Security of College
Archives Management Based on Artificial Intelligence
Technology Office automation, 28 (19), 38-40
Zhao Xuantong (2023) The Evolution and Reflection of Art
Education in the Digital Reproduction Era Kanto
Journal (4), 91-98
Bow Arrow, Miao Di, Li Yang,&Duan Xiaoxian (2023) A
vehicle networking data forwarding decision algorithm
based on V-NDN Internet of Things technology, 13
(11), 40-44
Li Shuangxian, Lu Xin, Duojie Cairen, Zhang Huaiqing,
Xue Lianfeng,&Yun Ting (2023) A new method for
calculating the leaf area of trees in ground laser point
clouds Journal of Nanjing Forestry University: Natural
Science Edition, 47 (5), 28-38
Ni Xuanming, Zheng Tiantian,&Zhao Huimin (2023) Can
military civilian integration reduce the cost of equity
financing for high-tech enterprises—— Empirical
research based on dual machine learning Systems
Engineering Theory and Practice, 43 (6), 1630-1650
Yang Yuanyang, Zhou Cong, Zhu Hai,&Wang Tao (2023)
An improved phishing website detection system based
on string randomness characteristics and random forest
algorithm Network Security Technology and
Applications (5), 44-46
Yi Yucheng, Wang Jingzhi, Zhu Lu, Li Xiao, Xiong
Kui,&Ye Shengtao, et al. (2023) Overview of
Intelligent Detection Systems and Methods for Road
Surface Defects Journal of East China Jiaotong
University, 40 (5), 19-31
Zhao Xinfeng, Su Hengqiang, Zheng Da, Guidongxu,
Zhang Yadong,&Meng Weihong A method, device,
and system for recognizing the clarity of scanned
images in archive reports CN116523851A
Qi Jianhuai, Cheng Yang, Zheng Weifan, (2023) He
Runmin, Sun Ding,&Liu Jianhui A business application
recognition system and method based on machine
learning algorithms CN202211602341.7
Yang Gang, Cheng Yibo, Chen Jianqi,&Yang Jian (2024)
A fault diagnosis method and medium for IoT terminals
based on machine learning algorithms CN115913898A
Electronic File Management Method and System Based on Machine Learning Algorithm
31
