
Impact of Resource Heterogeneity on MLOps Stages: A Computational
Efficiency Study
Julio Corona
1 a
, Pedro Rodrigues
1 b
, M
´
ario Antunes
1,2 c
and Rui L. Aguiar
1,2 d
1
Instituto de Telecomunicac¸
˜
oes, Universidade de Aveiro, Aveiro, Portugal
2
DETI, Universidade de Aveiro, Aveiro, Portugal
Keywords:
Machine Learning, Heterogeneous Computing, MLOps, DevOps.
Abstract:
The rapid evolution of hardware and the growing demand for Machine Learning (ML) workloads have driven
the adoption of diverse accelerators, resulting in increasingly heterogeneous computing infrastructures. Ef-
ficient execution in such environments requires optimized scheduling and resource allocation strategies to
mitigate inefficiencies such as resource underutilization, increased costs, and prolonged execution times. This
study examines the computational demands of different stages in the Machine Learning Operations (MLOps)
pipeline, focusing on the impact of varying hardware configurations characterized by differing numbers of
Central Processing Unit (CPU) cores and Random Access Memory (RAM) capacities on the execution time of
these stages. Our results show that the stage involving resource-intensive model tuning significantly influences
overall pipeline execution time. In contrast, other stages can benefit from less resource-intensive hardware.
The analysis highlights the importance of smart scheduling and placement, prioritizing resource allocation for
model training and tuning stages, in order to minimize bottlenecks and enhance overall pipeline efficiency.
1 INTRODUCTION
Machine Learning Operations (MLOps) has emerged
as a critical paradigm for a streamlined develop-
ment, deployment, and management of Machine
Learning (ML) workflows in real-world applica-
tions (Kreuzberger et al., 2023). By integrating De-
vOps principles with the unique requirements of ML
systems, MLOps aims to address the complexities of
end-to-end ML lifecycle management (Smith, 2024).
This includes tasks such as data collection, prepro-
cessing, model training, evaluation, and deployment.
While MLOps provides a structured framework to
improve collaboration, scalability, and reliability, its
practical implementation requires addressing several
technical and computational challenges.
One of the fundamental aspects of MLOps is the
orchestration of ML pipelines, which involve sequen-
tial stages designed to transform raw data into ac-
tionable insights. Each pipeline stage has differ-
ent computational requirements influenced by fac-
a
https://orcid.org/0009-0001-7898-7883
b
https://orcid.org/0009-0009-5916-4062
c
https://orcid.org/0000-0002-6504-9441
d
https://orcid.org/0000-0003-0107-6253
tors such as algorithm complexity, data size, and re-
source availability. In practice, these pipelines are
executed in heterogeneous computing environments
consisting of various hardware types, including Cen-
tral Processing Units (CPUs), Graphics Processing
Units (GPUs), Field-Programmable Gate Arrays (FP-
GAs), and Tensor Processing Units (TPUs) (Faubel
et al., 2023). These environments offer the poten-
tial for performance optimization by leveraging the
unique strengths of different hardware components.
However, achieving efficient execution in such set-
tings requires intelligent scheduling and resource al-
location strategies to avoid inefficiencies such as un-
derutilized resources, increased costs, and prolonged
execution times.
This study investigates the execution times of var-
ious ML pipeline stages within heterogeneous com-
puting environments. It focuses on how variations
in Virtual Machines (VMs) configurations, character-
ized by different numbers of Virtual Central Process-
ing Units (vCPUs) cores and Random Access Mem-
ory (RAM) capacities, affect the performance of in-
dividual stages and the overall efficiency of pipeline
execution in ML workflows.
The main contributions of this study are as fol-
lows: i) provides a detailed analysis of the computa-
246
Corona, J., Rodrigues, P., Antunes, M., Aguiar and R. L.
Impact of Resource Heterogeneity on MLOps Stages: A Computational Efficiency Study.
DOI: 10.5220/0013520600003964
In Proceedings of the 20th International Conference on Software Technologies (ICSOFT 2025), pages 246-253
ISBN: 978-989-758-757-3; ISSN: 2184-2833
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

tional requirements of ML pipeline stages, shedding
light on how these requirements vary across tasks
such as data preprocessing, feature engineering, and
model training, and ii) offers insights into the impact
of resource configurations, including vCPU cores and
RAM, on the execution efficiency of the MLOps
pipeline, emphasizing the importance of aligning
hardware resources with the specific demands of dif-
ferent pipeline components.
The remainder of this paper is organized as fol-
lows. Section 2 provides background on MLOps
and heterogeneous computing. Section 3 reviews
key studies that address the challenges of deploying
ML pipelines in heterogeneous environments. Sec-
tion 4 outlines the research methodology, including
datasets, ML pipeline stages, and computational in-
frastructure. Section 5 analyzes the performance of
MLs pipeline stages in various VM configurations,
highlighting how resource allocation affects execu-
tion times. Finally, Section 6 concludes the paper
with a summary of the insights and outlines the fu-
ture research directions.
2 BACKGROUND
To understand the context of this work and highlight
the relevance of understanding the computational de-
mands of different stages of the MLOps pipeline, in
this section, we provide an overview of MLOps (sub-
section 2.1) and the challenges of running ML work-
loads on heterogeneous computing (subsection 2.2).
2.1 MLOps
As already mentioned, MLOps stands for Machine
Learning Operations, consisting of a set of practices
that automate and simplify the ML workflow and de-
ployment. In other words, it can be seen as a cul-
ture and practice that unifies ML application devel-
opment (Dev) with ML system deployment and op-
erations (Ops). The concept of MLOps is an exten-
sion of DevOps applied to data and ML applications.
Essentially, it applies the DevOps concepts relevant
to the ML field and creates new practices that effec-
tively automate the entire workflow of ML systems.
By adopting MLOps practices, several benefits can
be achieved, such as improved efficiency, increased
scalability, reliability, enhanced collaboration, and re-
duced costs.
A key concept in MLOps is the ML pipeline,
which consists of sequential steps covering a
model’s lifecycle, including data collection, data
pre-processing, feature engineering, model training,
model evaluation, and model deployment. Each step
can be complex and time-consuming, requiring spe-
cialized tools and expertise. The use of ML pipelines
helps automate and streamline these processes, en-
hancing reproducibility and scalability.
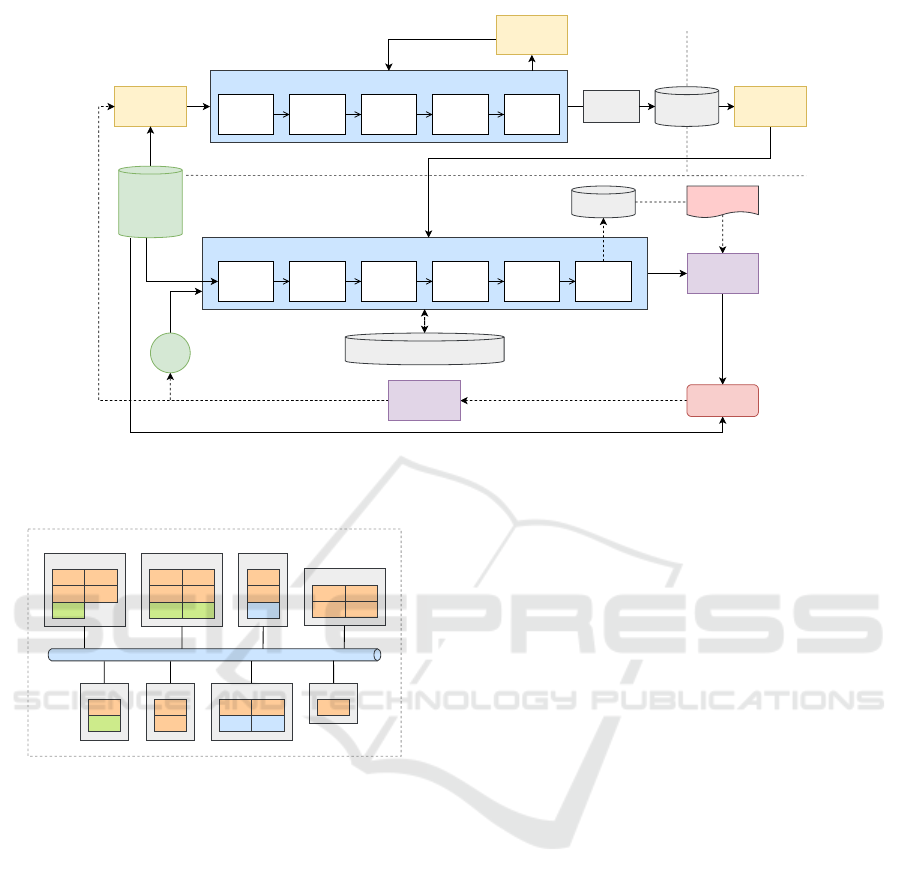
While somewhat abstract, Figure 1 illustrates a
typical organization and flow of an MLOps workflow.
As can be seen, the core component of the workflow
is the ML pipeline, highlighting the importance of op-
timizing its execution.
MLOps has the potential to enhance ML work-
flows but faces several challenges, including resis-
tance to change, lack of expertise, and organiza-
tional silos (Faubel et al., 2023). A key issue
is the efficient orchestration and scheduling of ML
pipelines in heterogeneous computing environments.
Improper scheduling can lead to resource underuti-
lization, wasted computational time, and higher costs.
In order to develop strategies that can address these
challenges, it is first essential to understand the com-
putational requirements of different stages of the ML
pipeline, which is the main focus of this work.
2.2 Heterogeneous Computing
The rapid evolution of hardware and the rise of ML
workloads, which have motivated the adoption of dif-
ferent types of accelerators (e.g. GPUs and TPUs),
have made the existing computing infrastructure het-
erogeneous. In this context, heterogeneous comput-
ing refers to using multiple types of hardware in a sin-
gle system, such as CPUs, GPUs, FPGAs, and TPUs.
Each type of hardware has its strengths and weak-
nesses, and by combining them in a single system, it
is possible to take advantage of each other’s unique
capabilities to improve performance and efficiency.
For example, GPUs are good at parallel processing
tasks, while CPUs are better at sequential tasks. Us-
ing both types of hardware together makes it possible
to achieve better performance than using either type
of hardware alone. For illustration Figure 2 shows an
example of a heterogeneous computing environment
with CPUs, GPUs, and FPGAs.
However, as mentioned above, the benefits of het-
erogeneous computing may not be fully realized with-
out proper orchestration and task placement strate-
gies. To take full advantage of the resources available
in these environments, it is crucial to develop intel-
ligent scheduling techniques that determine the best
placement of tasks that make up a workload. This
is particularly important in the context of ML work-
loads, as different stages of a pipeline use various al-
gorithms and techniques and, therefore, take advan-
tage of different types of hardware. By understanding
Impact of Resource Heterogeneity on MLOps Stages: A Computational Efficiency Study
247
Data
analysis
Data
validation
Data
preparation
Model
evaluation
Model
training
Model
validation
Orchestrated experiment
Model
analysis
Source
code
Pipeline
deployment
Feature
store
Data
validation
Data
preparation
Model
evaluation
Model
training
Model
validation
Automated Pipeline
Data
extraction
Model
registry
Trained model
CD: Model
serving
Prediction
service
Performance
monitoring
ML metadata store
Offline
extraction
Batch
fetching
Trigger
experimentation/development/test
preproduction/production
Source
repository
ML Ops
Figure 1: General overview of a common MLOps workflow. Adapted from (Google, 2024).
CPU CPU
CPU CPU
GPU
CPU CPU
CPU CPU
GPU GPU
CPU CPU
CPU CPU
CPU
CPU
FPGA
CPU
CPU
CPUCPU
GPU
CPU
FPGA
CPU
FPGA
Node 1 Node 2
Node 4
Node 3
Node 5 Node 6 Node 8Node 7
Connection network
Heterogeneous cluster
Figure 2: Simple representation of a heterogeneous cluster.
Adapted from (Zhang and Wu, 2012).
the computational requirements of different pipeline
stages and how they can be optimized for heteroge-
neous computing environments, it is possible to de-
velop strategies to improve the efficiency and effec-
tiveness of ML workflows.
3 RELATED WORK
Despite the novelty of the problem at hand, some au-
thors have taken the first steps to propose solutions
that mitigate the challenge of deploying ML pipelines
in heterogeneous environments. One of these pioneer-
ing works is the study by N. Le et al. (Le et al., 2020),
which investigates how to schedule ML jobs on in-
terchangeable resources with different computation
rates to optimize performance while ensuring fairness
among users in a shared cluster. In this study, the au-
thors propose AlloX. This framework transforms the
scheduling problem into a min-cost bipartite match-
ing problem and determines optimal CPU and GPU
configurations for ML jobs, outperforming existing
methods in heterogeneous setups.
Another study that attempts to approach this prob-
lem is the work of Chen et al. (Chen et al., 2023),
which proposes an improved task scheduling system
for Kubernetes-based MLOps frameworks using a
Genetic Algorithm (GA). By modeling scheduling as
a multi-objective knapsack placement problem, which
is NP-hard, the authors demonstrate that their ap-
proach significantly reduces execution time compared
to the default Kubernetes scheduler. Although not
explicitly designed for heterogeneous environments,
the fitness function considered in the GA allows the
solution to be extended to this type of environment,
demonstrating the potential of the proposed approach.
Motivated by hardware heterogeneity and hetero-
geneous performance of ML workloads, Narayanan et
al. proposed Gavel (Narayanan et al., 2020), a cluster
scheduler for DNN training in on-premises and cloud
environments. Using a round-based scheduling mech-
anism, Gavel adapts existing scheduling policies to
account for heterogeneity and colocation. While rele-
vant, the work focuses only on training jobs and con-
siders heterogeneity solely in terms of GPUs, neglect-
ing other ML pipeline stages.
In addition, focusing only on heterogeneous GPU
clusters, in (Jayaram Subramanya et al., 2023), the
authors present Sia. This scheduler efficiently allo-
cates resources to elastic resource-adaptive jobs from
ICSOFT 2025 - 20th International Conference on Software Technologies
248

heterogeneous Deep Learning (DL) clusters. The so-
lution profiles job throughput across batch sizes on
different GPU types and uses a policy optimizer for
informed scheduling decisions. The authors evalu-
ated Sia on a 64-GPU cluster with three GPU types
using traces from production DL clusters, demon-
strating significant reductions in average job time and
makespan compared to state-of-the-art schedulers.
To achieve fair and efficient scheduling of DL
workloads in heterogeneous GPU environments, Xiao
Zhang proposed Mixtran (Zhang, 2024). MixTran ab-
stracts GPU resources as virtual tickets and converts
uniform requests into a global optimization model
that considers resource demands, heterogeneous node
constraints, and user fairness. It then applies second-
price trading rules to reallocate resources, enhanc-
ing system utilization while ensuring fairness dynam-
ically. Evaluated on a 16-GPU cluster running diverse
DL jobs, MixTran reduced execution time by 30-50%
compared to the default Kubernetes scheduler.
In summary, although recent work has proposed
possible solutions to the problem of scheduling ML
pipelines in heterogeneous environments, they have
several limitations. First, most of them focus only
on the training phase of ML pipelines, but a com-
plete ML pipeline consists of several other phases,
ranging from data collection to model deployment.
Second, most solutions only consider heterogeneous
GPU clusters, whereas, in practice, heterogeneous en-
vironments may include other types of hardware.
Although this study does not introduce novel
methodologies for task allocation in diverse environ-
ments, it thoroughly explores the effects of hardware
variations, specifically concerning CPU and RAM,
on the execution time of ML pipelines. Examining
computational demands and optimal resource config-
urations aims to identify key factors that can inform
future research. In this context, we plan to inves-
tigate strategies for dynamic task allocation that ac-
count for hardware heterogeneity, with the goal of re-
fining MLOps workflows and enhancing performance
across diverse computing infrastructures.
4 RESEARCH METHODOLOGY
This section presents a detailed overview of the ex-
perimental framework employed in this study. It be-
gins with an introduction to the datasets utilized, fol-
lowed by a description of the computational processes
involved in each stage of the ML pipeline. Exper-
iments are conducted on diverse computational re-
sources with varying vCPU cores and RAM config-
urations, allowing an analysis of how resource con-
straints impact the ML stages’ runtime. For model
tuning and evaluation, the datasets are partitioned into
training and testing sets, reserving 20% of the data for
testing.
4.1 Datasets
The datasets analyzed in this work span diverse do-
mains, each possessing unique characteristics and
challenges. They are sourced from publicly available
repositories, with specific attributes selected for clas-
sification tasks. They include:
• KPI-KQI (Preciado-Velasco et al., 2021): This
synthetic dataset contains 165 samples with 14
features, including Key Performance Indicators
(KPIs) and Key Quality Indicators (KQIs) at-
tributes for nine distinct services. The labels rep-
resent 5G service types.
• User Network Activities Classification (UNAC)
(Sandeepa et al., 2023): This dataset consists of
389 samples with 23 features describing network
traffic parameters such as protocols, packet sizes,
and timestamps. The labels classify network ac-
tivities.
• IoT-APD (MKhubaiib, 2024): This dataset
comprises 10,485 samples with 17 features
extracted from IoT simulations, including
source/destination ratios and durations. The
labels indicate the type of attack.
• Network Slicing Recognition (NSR) (Dutta, ):
With 31,583 samples and 17 features, this dataset
includes attributes such as packet delay and equip-
ment categories. It is designed for network slice
selection, including failure scenarios.
• DeepSlice (Thantharate et al., 2019): This dataset
includes 63,167 samples with 10 features focus-
ing on 5G network slice parameters. The output
categorizes different types of network services.
• NSL-KDD (Tavallaee et al., 2009): Comprising
42 attributes for 41 data characteristics and one
attack label, this dataset has improved balance and
diversity over the KDD-CUP dataset.
• IoT-DNL (Speedwall10, ): This dataset contains
477,426 samples and 13 features derived from
wireless IoT environments, including frame de-
tails and attack labels. Supports anomaly-based
IDS evaluation.
4.2 Machine Learning Pipeline
ML pipelines are structured workflows that streamline
the development, training, and evaluation of ML mod-
Impact of Resource Heterogeneity on MLOps Stages: A Computational Efficiency Study
249

els. Typical ML pipelines consist of several stages,
each designed to ensure effective and efficient data
and model handling. These stages are essential for
transforming raw data into actionable insights or pre-
dictions. Execution times at each stage were mea-
sured using Python’s exectimeit library, which pro-
vides a wrapper specifically designed to accurately
measure short execution times, as detailed in (Moreno
and Fischmeister, 2017).
The methodology used in this study incorporates
the following stages for developing and evaluating
ML models:
Stage 1 (Data Cleaning): In this initial stage the
datasets are cleaned to ensure data quality by remov-
ing rows with missing values, duplicates, and irrele-
vant columns.
Stage 2 (Data Preprocessing): The data prepro-
cessing pipeline consists of multiple steps to enhance
data quality and improve model performance. First,
categorical variables are encoded using label encod-
ing to convert them into numerical representations.
Next, low-variance features are removed to eliminate
irrelevant information. Outlier detection is performed
using Isolation Forest to filter anomalous data points.
The remaining features are then normalized to stan-
dardize input scales, ensuring consistency across vari-
ables. Finally, Principal Component Analysis is ap-
plied to reduce dimensionality while retaining 90% of
the dataset’s variance, improving computational effi-
ciency and mitigating the risk of overfitting.
Stage 3 (Model Tuning): The stage evaluates
three representatives ML models: Logistic Regres-
sion (LR), Random Forest (RF), and Multi-Layer
Perceptron (MLP). Hyperparameter tuning was per-
formed using the genetic algorithm provided by the
sklearn-genetic-opt library. Each combination of
hyperparameters was validated using 4-fold cross-
validation.
Stage 4 (Model Evaluation): To evaluate the per-
formance of the models, the Matthews Correlation
Coefficient (MCC) metric (Chicco and Jurman, 2020)
was selected. MCC offers a reliable and balanced as-
sessment of classification models, particularly in sce-
narios involving imbalanced datasets or when evalu-
ating performance across multiple classes is critical.
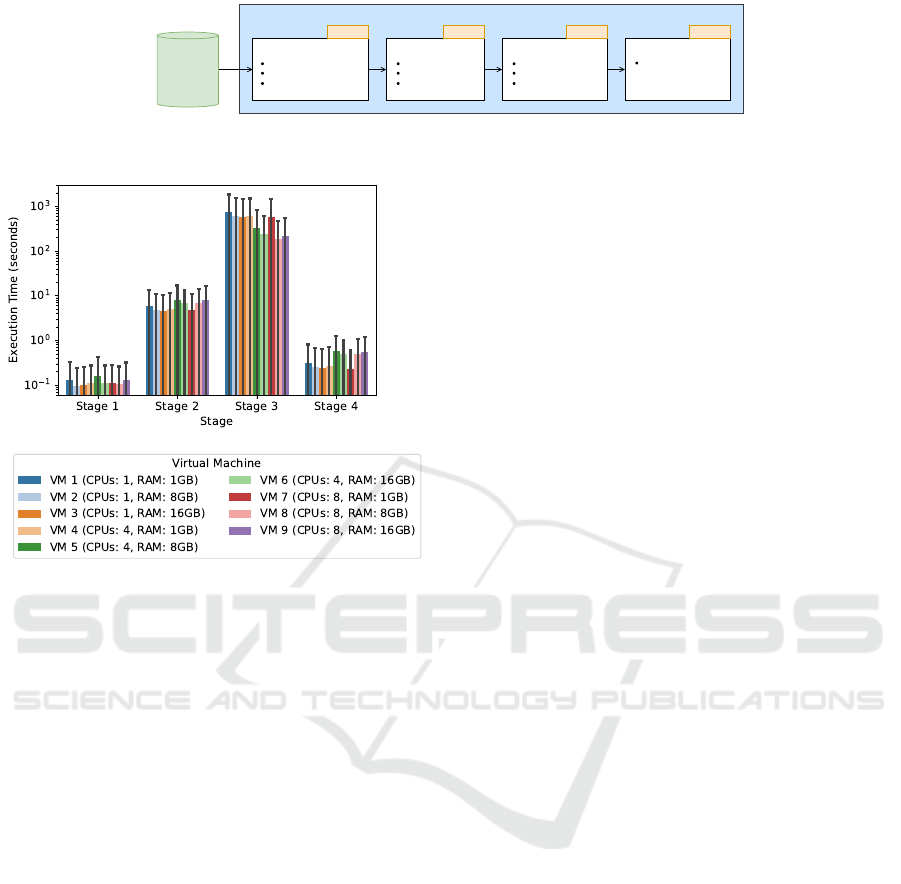
A visual representation of the ML pipeline under
consideration is shown in Figure 3.
4.3 Computational Infrastructure
This experiment used nine identical computing nodes,
each hosting a single VM to constrain hardware avail-
ability. The VMs were defined by their respective
vCPU cores and RAM capacities, as outlined in Ta-
ble 1. This setup was intentionally conservative, as
many real-world frameworks exhibit greater hardware
variability, including the use of dedicated accelerators
such as GPUs, TPUs, and FPGAs.
Table 1: Virtual Machines Configuration.
VM vCPU Cores RAM (GB)
VM 1 1 1
VM 2 1 8
VM 3 1 16
VM 4 4 1
VM 5 4 8
VM 6 4 16
VM 7 8 1
VM 8 8 8
VM 9 8 16
The heterogeneous VM configuration allowed the
evaluation of the feasibility and performance of the
ML stages under varying resource constraints. This
approach provided valuable insight into optimizing
the use of computational resources to meet diverse
task requirements. The heterogeneity of the exper-
iment is simplistic (we only vary two components)
for two main reasons. First, although simplistic, it
allows us greater control over the possible combina-
tions to have a better view of the impact of such small
changes. Second, at the time of publication, we do
not have other computational resources to allocate.
5 ANALYSIS & DISCUSSION
The following analysis examines how the pipeline
stages perform in different VMs configurations and
evaluates the impact of varying VMs allocations on
overall ML pipeline performance.
Given the significant difference in execution times
for Stage 3 compared to the other stages, Figure 4
illustrates the execution times using a logarithmic
scale.
Stage 1, focused on data cleaning, demonstrated
relatively consistent execution times across all config-
urations, with an average of approximately 0.117 sec-
onds and a low standard deviation of 0.178 seconds.
This suggests that data cleaning tasks were largely
unaffected by variations in computational resources,
likely due to their inherently low computational de-
mands. Notably, VM 2 (1 vCPU and 8 GB RAM)
achieved the fastest mean execution time of 0.096 sec-
onds, outperforming VM 1 (1 vCPU and 1 GB RAM),
which recorded a mean of 0.129 seconds. This indi-
cates that increased RAM can provide a slight perfor-
ICSOFT 2025 - 20th International Conference on Software Technologies
250
Datasets
ML Pipeline
Data cleaning
remove duplicates
remove missing values
remove irrelevant columns
Data preprocessing
label encoding
feature normalization
PCA
Model tuning
Logistic Regression
Random Forest
Multi-Layer Perceptron
Model evaluation
MCC
Stage 1 Stage 2 Stage 3 Stage 4
Figure 3: ML pipeline considered in this work.
Figure 4: Execution times grouped by VM (log scale).
mance advantage even for lightweight tasks. How-
ever, the trend becomes less straightforward when
considering configurations with higher vCPU counts.
For instance, VM 4 (4 vCPUs and 1 GB RAM) and
VM 6 (4 vCPUs and 16 GB RAM) showed compara-
ble performance, with mean execution times of 0.111
and 0.110 seconds, respectively, suggesting that addi-
tional RAM beyond 1 GB had minimal impact. In-
terestingly, VM 5 (4 vCPUs and 8 GB RAM) exhib-
ited the slowest mean execution time of 0.162 sec-
onds, potentially indicating inefficiencies in resource
allocation or overhead. Similarly, VMs with 8 vC-
PUs, such as VM 7 (8 vCPUs and 1 GB RAM) and
VM 8 (8 vCPUs and 8 GB RAM), showed no signif-
icant performance improvement over configurations
with fewer vCPUs, reinforcing the idea that excessive
computational resources can lead to diminishing re-
turns for lightweight tasks.
Stage 2, which includes data preprocessing, ex-
hibited greater execution time variability across con-
figurations, with mean times ranging from 4.618 sec-
onds in VM 3 (1 vCPU, 16 GB RAM) to 8.128 sec-
onds in VM 5 (4 vCPUs, 8 GB RAM). Notably,
among single-vCPU configurations, increasing RAM
consistently improved performance, as seen in VM 3
achieving the lowest mean execution time. However,
for multi-vCPU configurations, performance trends
were less predictable, with VM 5 (4 vCPUs, 8 GB
RAM) and VM 9 (8 vCPUs, 16 GB RAM) experienc-
ing the highest mean execution times. Interestingly,
VM 7 (8 vCPUs, 1 GB RAM) outperformed several
higher-resource configurations, suggesting inefficien-
cies in resource management at higher core and mem-
ory levels. The results highlight that for this stage,
while additional RAM can enhance performance in
single-core environments, increased CPU and mem-
ory allocations do not always yield proportional ben-
efits for this stage.
Stage 3, focused on model tuning, showed a sig-
nificant reduction in execution time as computational
resources increased, with VM 8 (8 vCPUs, 8 GB
RAM) achieving the lowest mean time of 184.36 sec-
onds. Single-vCPU configurations exhibited the high-
est execution times, with VM 1 (1 vCPU, 1 GB RAM)
reaching 734.25 seconds, highlighting the limitations
of minimal resources for this stage. Among multi-
vCPU configurations, VM 6 (4 vCPUs, 16 GB RAM)
and VM 8 demonstrated the best performance, sug-
gesting that both increased CPU cores and sufficient
RAM contribute to efficiency. However, VM 7 (8 vC-
PUs, 1 GB RAM) showed worse performance than
VM 5 (4 vCPUs, 8 GB RAM), indicating that memory
constraints can bottleneck execution even with higher
CPU counts. The results suggest a balanced combina-
tion of CPU and RAM is necessary to achieve optimal
performance at this stage.
Stage 4, which involved model evaluation and se-
lection, was less resource-intensive than model tun-
ing but showed varying performance across different
configurations, with VM 7 (8 vCPUs, 1 GB RAM)
achieving the fastest mean execution time of 0.231
seconds, followed closely by VM 3 (1 vCPU, 16 GB
RAM) with 0.238 seconds. Single-vCPU configu-
rations like VM 1 (1 vCPU, 1 GB RAM) showed
slightly higher mean times of 0.306 seconds, while
those with additional RAM, such as VM 2 (1 vCPU, 8
GB RAM), demonstrated improved performance with
0.255 seconds. The performance of multi-vCPU con-
figurations was less consistent; for example, VM 4
(4 vCPUs, 1 GB RAM) performed at 0.262 seconds,
while VM 6 (4 vCPUs, 16 GB RAM) took 0.490 sec-
onds, showing that adding CPUs and RAM may not
always lead to better results.
When analyzing how VMs allocations influence
the total pipeline execution, all possible combinations
Impact of Resource Heterogeneity on MLOps Stages: A Computational Efficiency Study
251
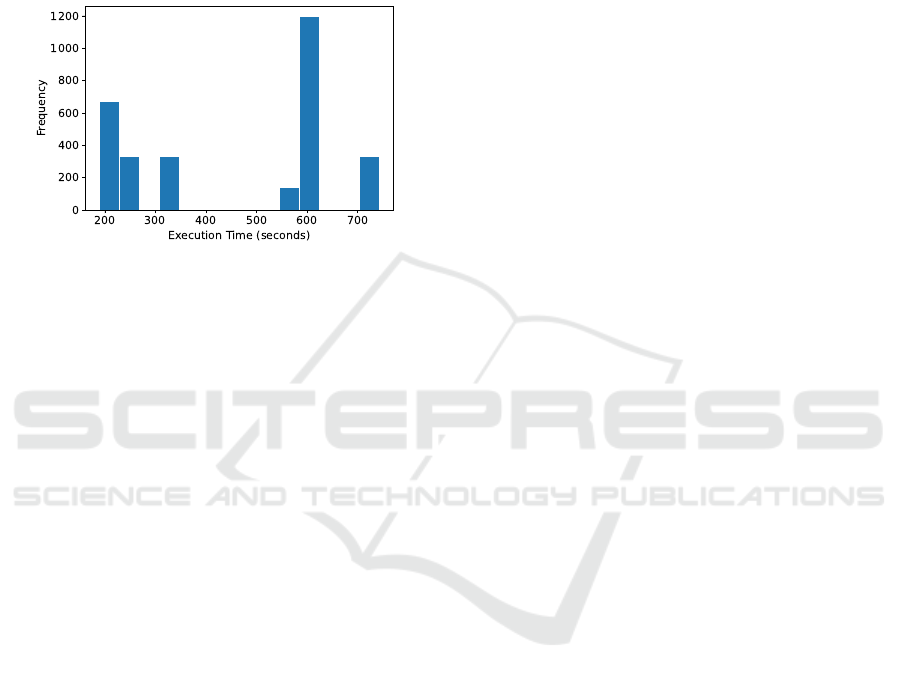
were evaluated. The distribution of these times is
shown in Figure 5. Each combination is denoted as
[S
1
, S
2
, S
3
, S
4
], where S
i
represents the VM assigned
to Stage i. Although our pipeline follows a typical
structure, it does not include all possible operations
for each stage. As a result, the distribution could ex-
hibit different properties, but the minimum and maxi-
mum execution times would remain the same.
Figure 5: Pipeline execution time histogram.
A notable observation is the pronounced cluster-
ing of execution times at both ends of the histogram.
The interval from 184.363 to 218.755 seconds shows
a frequency count of 672, while the interval between
578.427 and 602.224 seconds peaks at 1008 occur-
rences. This indicates that numerous VMs combi-
nations result in highly efficient execution times or
are grouped towards the upper limit of the execu-
tion times. The mean and standard deviation of the
total execution times, 458.960 seconds and 196.416
seconds, respectively, reveal that most VM alloca-
tions are suboptimal compared to the best total time
of 184.363 seconds, while the worst total time of
734.250 seconds is approximately 1.4 standard devi-
ations above the mean. These metrics underscore the
expected performance of simpler allocation strategies,
such as Round Robin or First In, First Out (FIFO),
which are likely to produce results near the average
due to their lack of workload-specific optimization.
The first group represents the best-performing
configurations, yielding the shortest total execution
times and highlighting their efficiency in pipeline ex-
ecution. In particular, the combinations [VM 2, VM
3, VM 8, VM 7], [VM 6, VM 3, VM 8, VM 7], and
[VM 4, VM 3, VM 8, VM 7] produced the shortest to-
tal times, all approximately 189.317 seconds. These
configurations used a mixture of VMs with seemingly
optimized resource allocations for the pipeline stages,
particularly stage 3, which dominates the total exe-
cution time. The consistently low execution times
in these configurations suggest that VM 8 is highly
suited for the resource-intensive Stage 3, while VMs
2, 3, 4, or 7 effectively handle the less demanding ear-
lier stages.
In contrast, other groups of combinations exhib-
ited total times ranging from 228.860 seconds to
347.516 seconds. These configurations often involved
using VMs 5 or 6 for Stage 3, which proved to be less
efficient than VM 8 for handling this resource-heavy
stage. Furthermore, slight variations in total times
within this range indicate the interaction of VMs as-
signments for earlier stages, where minor inefficien-
cies can compound when paired with a suboptimal
Stage 3 configuration.
The worst-performing combinations had total
times ranging from 545.275 to 624.379 seconds and
from 703.483 to 743.035 seconds. The first group, be-
tween 545.275 and 624.379 seconds, included combi-
nations such as [VM 8, VM 2, VM 3, VM 7], [VM 4,
VM 2, VM 3, VM 7], [VM6, VM5, VM4, VM9],
and [VM3, VM5, VM7, VM8]. These configura-
tions assigned Stage 3 to VMs 2, 3, 4, or 7, which
lacked sufficient resources to process efficiently, caus-
ing significant bottlenecks. The second group, be-
tween 703.483 and 743.035 seconds, contained com-
binations like [VM 7, VM 5, VM 1, VM 9], which
not only assigned Stage 3 to an inefficient VM (VM
1) but also compounded inefficiencies by suboptimal
assignments in earlier stages. This highlights the im-
portance of ensuring that the most resource-intensive
stages are handled by VMs with sufficient capacity to
avoid cascading inefficiencies.
6 CONCLUSION AND FUTURE
DIRECTIONS
This study highlights the critical role of appropriate
VM configurations in optimizing ML pipeline perfor-
mance, particularly for stages with longer process-
ing times. Our analysis demonstrates that the per-
formance of Stage 3, which involves model tuning,
has the most substantial impact on the total pipeline
execution time. Configurations utilizing VM 8 con-
sistently achieved better performance for Stage 3. In
contrast, combinations involving VMs with limited
resources (for example, VM 1 or VM 4 with 1 GB
of RAM) caused significant delays.
Furthermore, selecting less resource-intensive
VMs for earlier stages proved beneficial in optimiz-
ing performance. For example, configurations such
as [VM 2, VM 3, VM 8, VM 7], [VM 6, VM 3, VM
8, VM 7], and [VM 4, VM 3, VM 8, VM 7] deliv-
ered the shortest total execution times by balancing
resource allocation across all stages. In contrast, con-
figurations that paired suboptimal VMs for Stage 3
with other stages caused inefficiencies, contributing
ICSOFT 2025 - 20th International Conference on Software Technologies
252

to longer execution times.
This study underscores the importance of prior-
itizing resource allocation, particularly for the most
resource-intensive stages, to minimize bottlenecks
and ensure efficient ML pipeline execution. However,
since many real-world frameworks exhibit greater
hardware variability, including the use of dedicated
accelerators such as GPUs, TPUs, and FPGAs, future
research should investigate whether these findings can
be generalized to such environments. Additionally,
future work should explore dynamic VM provision-
ing and adaptive resource management strategies to
enhance performance in heterogeneous and evolving
computing scenarios.
ACKNOWLEDGEMENTS
This study was funded by the PRR – Plano de
Recuperac¸
˜
ao e Resili
ˆ
encia and by the NextGen-
erationEU funds at University of Aveiro, through
the scope of the Agenda for Business Innovation
“NEXUS: Pacto de Inovac¸
˜
ao – Transic¸
˜
ao Verde e
Digital para Transportes, Log
´
ıstica e Mobilidade”
(Project nº 53 with the application C645112083-
00000059).
REFERENCES
Chen, H.-M., Chen, S.-Y., Hsueh, S.-H., and Wang, S.-
K. (2023). Designing an improved ml task schedul-
ing mechanism on kubernetes. In 2023 Sixth Interna-
tional Symposium on Computer, Consumer and Con-
trol (IS3C), pages 60–63.
Chicco, D. and Jurman, G. (2020). The advantages of the
matthews correlation coefficient (mcc) over f1 score
and accuracy in binary classification evaluation. BMC
genomics, 21(1):1–13.
Dutta, G. Network slicing recognition. https:
//www.kaggle.com/datasets/gauravduttakiit/network-
slicing-recognition.
Faubel, L., Schmid, K., and Eichelberger, H. (2023). Mlops
challenges in industry 4.0. SN Computer Science,
4(6):828.
Google (2024). Mlops: Continuous delivery and
automation pipelines in machine learning.
https://cloud.google.com/architecture/mlops-
continuous-delivery-and-automation-pipelines-
in-machine-learning.
Jayaram Subramanya, S., Arfeen, D., Lin, S., Qiao, A., Jia,
Z., and Ganger, G. R. (2023). Sia: Heterogeneity-
aware, goodput-optimized ml-cluster scheduling. In
Proceedings of the 29th Symposium on Operating Sys-
tems Principles, SOSP ’23, page 642–657, New York,
NY, USA. Association for Computing Machinery.
Kreuzberger, D., K
¨
uhl, N., and Hirschl, S. (2023). Ma-
chine learning operations (mlops): Overview, defini-
tion, and architecture. IEEE access, 11:31866–31879.
Le, T. N., Sun, X., Chowdhury, M., and Liu, Z. (2020).
Allox: compute allocation in hybrid clusters. In
Proceedings of the Fifteenth European Conference
on Computer Systems, EuroSys ’20, New York, NY,
USA. Association for Computing Machinery.
MKhubaiib. IoT attack prediction dataset. https:
//www.kaggle.com/datasets/mkhubaiib/iot-attack-
prediction-dataset.
Moreno, C. and Fischmeister, S. (2017). Accurate measure-
ment of small execution times—getting around mea-
surement errors. IEEE Embedded Systems Letters,
9(1):17–20.
Narayanan, D., Santhanam, K., Kazhamiaka, F., Phan-
ishayee, A., and Zaharia, M.(2020). Heterogeneity-
Aware cluster scheduling policies for deep learning
workloads. In 14th USENIX Symposium on Operat-
ing Systems Design and Implementation (OSDI 20),
pages 481–498. USENIX Association.
Preciado-Velasco, J. E., Gonzalez-Franco, J. D., Anias-
Calderon, C. E., Nieto-Hipolito, J. I., and Rivera-
Rodriguez, R. (2021). 5g/b5g service classifica-
tion using supervised learning. Applied Sciences,
11(11):4942.
Sandeepa, C., Senevirathna, T., Siniarski, B., Nguyen, M.-
D., La, V.-H., Wang, S., and Liyanage, M. (2023).
From opacity to clarity: Leveraging xai for robust net-
work traffic classification. In International Confer-
ence on Asia Pacific Advanced Network, pages 125–
138. Springer.
Smith, J. (2024). Devops and mlops convergence: Improv-
ing collaboration between data science and engineer-
ing teams. Australian Journal of Machine Learning
Research & Applications, 4(2):82–86.
Speedwall10. Iot device network logs. https:
//www.kaggle.com/datasets/speedwall10/iot-device-
network-logs.
Tavallaee, M., Bagheri, E., Lu, W., and Ghorbani, A. A.
(2009). A detailed analysis of the kdd cup 99 data
set. In 2009 IEEE symposium on computational intel-
ligence for security and defense applications, pages
1–6. Ieee.
Thantharate, A., Paropkari, R., Walunj, V., and Beard, C.
(2019). Deepslice: A deep learning approach towards
an efficient and reliable network slicing in 5g net-
works. In 2019 IEEE 10th Annual Ubiquitous Com-
puting, Electronics & Mobile Communication Confer-
ence (UEMCON), pages 0762–0767. IEEE.
Zhang, K. and Wu, B. (2012). Task scheduling for gpu het-
erogeneous cluster. In 2012 IEEE International Con-
ference on Cluster Computing Workshops, pages 161–
169.
Zhang, X. (2024). Mixtran: an efficient and fair scheduler
for mixed deep learning workloads in heterogeneous
gpu environments. Cluster Computing, 27(3):2775–
2784.
Impact of Resource Heterogeneity on MLOps Stages: A Computational Efficiency Study
253
