
A Hybrid-Based Transfer Learning Approach for IoT Device
Identification
Stephanie M. Opoku
1
, Habib Louafi
2 a
and Malek Mouhoub
1 b
1
Department of Computer Science, University of Regina, Regina, Canada
2
Department of Science of Technology, TELUQ University, Montreal, Canada
fi
Keywords:
IoT, Device Identification, Fingerprinting, Network Traffic, Feature Extraction, Maximum Mean Discrepancy,
Transfer Learning, Machine Learning.
Abstract:
The rapid growth and diversity of Internet of Things (IoT) devices pose significant challenges in device iden-
tification and network security. Traditional techniques for fingerprinting IoT devices frequently encounter
challenges due to the complexity and scale of today’s IoT networks. This paper presents an innovative model
applying transfer learning (TL) methodologies to analyze network data and precisely identify IoT devices.
Our solution effectively classifies devices by integrating instance-based, feature-based, and hybrid-based TL
methodologies for extracting essential features from traffic data. The proposed model undergoes a thorough
evaluation on three benchmark IoT datasets, exhibiting improved prediction accuracy, precision, recall, and
F1-Score relative to traditional methods. The hybrid technique significantly improves performance by han-
dling computational and scalability issues. This paper highlights the effectiveness of TL in improving IoT
device identification, providing an efficient and effective solution for various and dynamic network environ-
ments.
1 INTRODUCTION
In the modern technological landscape, accurately
identifying and managing network assets has become
vital for maintaining operational security. This ne-
cessity is heightened by the rapid increase in net-
worked devices, including the Internet of Things
(IoT) (Aidoo et al., 2022), which introduces new
challenges due to its diversity and constantly chang-
ing nature. Traditional methods, such as manual in-
ventories and standard network scanning, are proving
inadequate in handling the complexity and volume of
these devices, as they are time consuming and prone
to errors, thus exposing networks to unauthorized ac-
cess and poor asset management (Falola et al., 2023).
The rise of IoT devices, each with distinct operational
characteristics and inherent security weaknesses, fur-
ther complicates this scenario. Existing solutions of-
ten fail to address these challenges effectively, high-
lighting the need for more advanced and reliable iden-
tification methods.
As IoT networks expand, so does the frequency
of security threats and vulnerabilities, requiring en-
a
https://orcid.org/0000-0002-3247-3115
b
https://orcid.org/0000-0001-7381-1064
hanced protective measures (Dwivedi et al., 2022).
Traditional machine learning (ML) models face chal-
lenges with zero-day attacks and the limited avail-
ability of labeled data for new attacks. TL offers
a solution by training reliable models in abandoned
datasets, referred to as source domain, and then trans-
fer these models to domains where data is scarce,
which is referred to as target domain (Sivanathan
et al., 2019).
This paper introduces an innovative solution for
the identification of IoT devices, utilizing advanced
data analysis and TL techniques to address the short-
comings of traditional approaches. Our solution fo-
cuses on analyzing the network traffic generated by
IoT devices and extracting features from network
packet headers over a specified time frame. This ap-
proach captures both protocol-based and flow-based
statistical features, enabling accurate and rapid cat-
egorization and recognition of various types of IoT
devices.
To identify fingerprints of IoT devices, we pro-
pose an IoT device identification framework using
TL techniques, incorporating instance-based, feature-
based, and hybrid-based approaches. The proposed
framework aims to take advantage of the unique char-
Opoku, S. M., Louafi, H., Mouhoub and M.
A Hybrid-Based Transfer Learning Approach for IoT Device Identification.
DOI: 10.5220/0013449000003979
In Proceedings of the 22nd International Conference on Security and Cryptography (SECRYPT 2025), pages 309-320
ISBN: 978-989-758-760-3; ISSN: 2184-7711
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
309

acteristics of network traffic and device behavior to
accurately identify and differentiate IoT device fin-
gerprints. For more reliable training results, the
three approaches considered are trained on three com-
mon datasets and evaluated using well-known met-
rics, such as Accuracy, Precision, Recall, and F1-
Score. This approach represents a significant ad-
vancement in network asset identification, providing a
reliable solution to the challenges posed by the com-
plexity and diversity of networked devices, but also
the scarcity of labeled datasets. The contributions of
the paper are as follows:
• Review existing fingerprinting models that use TL
and develop a robust identification model capable
of accommodating the diverse and evolving land-
scape of networked devices.
• Identification and selecting distinctive features
from network traffic protocols that serve as reli-
able fingerprints for different types of IoT devices
and propose a TL methodology for our approach.
• Training an instance-based, a feature-based, and a
hybrid-based models using the limited traffic data
acquired.
• Evaluation the effectiveness of the proposed mod-
els, using well-known performance metrics (e.g.,
Precision, Accuracy). Besides, we validate the
model on the unique datasets with different traf-
fic data.
The remainder of the paper is organized as fol-
lows. Section 2 present notations, concepts, and al-
gorithms used in this paper. Section 3 review exist-
ing solutions related to IoT device identification us-
ing ML and TL. Section 4 details the methodology we
propose to design and implement our IoT device iden-
tification solution. Sections 5 and 6 present, respec-
tively, the experimental setup and the obtained results
along with a detailed discussion. Finally, Section 7
concludes the paper.
2 BACKGROUND
2.1 Transfer Learning
In this section, we outline some key formal definitions
related to Transfer Learning.
A domain D consists of two main components:
a feature space X and a marginal distribution P(X).
The feature space X is defined as X = {x
1
, x
2
, . . . , x
n
},
where n represents the number of feature vectors
within X. Thus, the domain D is represented as:
D = {X , P(X)} (1)
A domain can include both labeled and unlabeled
data, collectively referred to as domain data. In TL,
we have tow types of domains, which are:
• Source Domain: It is denoted as D
s
, i.e.,
{(x
s1
, l
s1
), . . . , (x
sn
s
, l
sn
s
)}, where x
si
∈ X
s
is the ith
instance in the Source Domain D
s
, and l
si
∈ L
s
is
the associated label.
• Target Domain: It is denoted as D
t
and is ex-
pressed as {(x
t1
, l
t1
), . . . , (x
tn
t
, l
tn
t
)}, where x
t j
∈
X
t
is the jth instance in D
t
, and l
t j
∈ L
t
is the as-
sociated label.
A task T is comprised of two components: a la-
bel space L and a decision or predictive function f (·).
The predictive function is based on pairs of feature
vectors and labels {x
i
, l
i
}, where x
i
∈ X and l
i
∈ L.
This function is represented as:
f (·) = P(L|X ) (2)
where, {x
i
, l
i
} corresponds to each i in the range
1, . . . , |L|. Therefore, a task T is defined as:
T = {L, f (·)} (3)
Consider a Domain D with its associated task T .
ML aims to develop a predictive function f (·) that
maps from the feature space X to the label space L
using the knowledge contained within the Domain D.
The Domain D is defined as D = {X, P(X )}, where X
represents the feature space and P(X) is the marginal
distribution of the feature space. Let T = {L, P(L|X )}
represent the task associated with the Domain D. The
task T involves learning a predictive function f (·)
that approximates the conditional probability P(L|X ),
mapping from the feature space X to the label space
L. Thus, the goal of ML is to find the predictive func-
tion f (·) that best models the relationship between the
features X and labels L under the given Domain D and
task T .
Consider a Source Domain D
s
with its associated
source task T
s
, and a Target Domain D
t
with its cor-
responding task T
t
. TL aims to leverage the knowl-
edge learned from D
s
and T
s
to enhance the learn-
ing of the predictive function f
t
(·) for the Target Do-
main. This approach is particularly beneficial when
either D
s
̸= D
t
or T
s
̸= T
t
. Let D
s
= {X
s
, P(X
s
)} and
D
t
= {X
t
, P(X
t
)} represent a Source Domain and a
Target Domain, respectively. The condition D
s
̸= D
t
indicates that either the feature spaces differ (X
s
̸=
X
t
) and/or the marginal distributions differ (P(X
s
) ̸=
P(X
t
)).
2.2 Transfer Learning Approaches
In this paper, we consider using two TL approaches,
namely instance-based and feature-based, and pro-
posed and hybrid-based TL one.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
310

- Instance-Based TL: In this approach, instances
from the Source Domain are weighted and used in the
Target Domain. This increases the number of samples
in the Target Domain and improves the marginal dis-
tribution between the two domains. This approach is
used in a scenario where large source data are avail-
able, but limited target data are available. In this ap-
proach, we have:
P(X
s
) ̸= P(X
t
)
X
s
̸= X
t
(4)
- Feature-Based TL: This method ensures that
both the Source and Target Domains operate within
the same feature space. When the probability distri-
butions differ between the two domains, adjustments
are made to account for these discrepancies. The sim-
ilarity between the source and target domains is eval-
uated using the Maximum Mean Discrepancy (MMD)
metric, which is presented in the next section. In this
approach, we have:
P(X
s
) ̸= P(X
t
)
φ(X
s
) ≈ φ(X
t
)
(5)
where, φ represents a feature mapping function that
aligns source and target domain representations by
projecting their features into a shared feature space
where their distributions align more closely. For in-
stance, PCA (Principal Component Analysis) or Au-
toencoders can be used to that goal.
- Proposed Hybrid-Based TL: In this paper, we
propose a hybrid TL approach that combines two
widely known TL approaches, that is, instance-based
and feature-based techniques to enhance IoT device
fingerprinting. The instance-based TL component as-
signs weights to Source Domain instances, allowing
the reuse of relevant data in the Target Domain. This
approach is particularly beneficial when labeled data
in the Target Domain is limited, as it leverages knowl-
edge from a well-established Source Domain. On
the other hand, the feature-based TL component ap-
plies transformation techniques such as PCA to align
the Source and Target Domains within a shared fea-
ture space, minimizing discrepancies in feature dis-
tributions. By integrating these two TL strategies,
our approach enhances adaptability to new IoT envi-
ronments while improving classification accuracy and
ensuring a more robust fingerprinting mechanism.
2.3 Maximum Mean Discrepancy
Maximum Mean Discrepancy (MMD) is a distance
metric used to compare probability distributions. It
can be utilized as a loss function in various ML
algorithms to compute the difference between the
mean embeddings of two distributions (Tunali, 2023).
MMD is particularly useful in TL, where domains
are considered different if their marginal distributions
vary. In such cases, MMD is commonly used to quan-
tify the degree of similarity between the domains.
Given two random variables, X ∼ P and Y ∼ Q,
the MMD score is zero if and only if P = Q, meaning
the two distributions are identical. If the distributions
differ, the MMD score will be greater than zero. The
MMD score is defined as:
MMD
2
(P, Q) =
∥
µ
P
− µ
Q
∥
2
H
(6)
where, µ
P
and µ
Q
represent the mean embeddings
of the probability distributions P and Q, respec-
tively, and H is a Reproducing Kernel Hilbert Space
(RKHS).
In practice, since the underlying distributions of
the data are not known, an empirical estimate of
MMD is computed using a sample of data points. The
empirical MMD is given by:
MMD
2
(X, Y ) =
1
m(m − 1)
∑
i̸= j
k(x
i
, x
j
)
+
1
n(n − 1)
∑
i̸= j
k(y
i
, y
j
)
−
2
mn
∑
i, j
k(x
i
, y
j
)
(7)
where, x
i
and x
j
are the i
th
and j
th
samples drawn in-
dependently and identically from distributions P and
Q, respectively. m and n denote the number of sam-
ples in X and Y , respectively, and k is the kernel func-
tion used.
3 RELATED WORK
This section examines major contributions in the field
of IoT device identification, with an emphasis on
methodologies involving IoT profiling, fingerprinting,
and intelligent device identification using TL. The re-
viewed work offers a comprehensive understanding
of the current state of IoT device identification tech-
niques that employ TL, while highlighting the need
for innovative solutions to address new challenges.
In (Kawish et al., 2023), the authors propose an
instance-based transfer learning approach specifically
applied to intrusion detection systems (IDS). The pa-
per addresses the challenge of detecting network in-
trusions in environments with varying data distribu-
tions by transferring knowledge from a source domain
A Hybrid-Based Transfer Learning Approach for IoT Device Identification
311
with labeled data to a target domain with insufficient
or no labels. The proposed method focuses on se-
lecting and reweighting relevant instances from the
source domain to improve the performance of IDS in
the target domain. The results demonstrate the effec-
tiveness of this approach in enhancing detection accu-
racy while maintaining efficiency in diverse network
environments.
The authors of (Liu et al., 2021) survey machine
learning techniques for IoT device identification. The
study separates approaches into device-specific pat-
tern recognition, deep learning-based identification,
unsupervised identification, and anomalous behavior
detection. It highlights feature engineering, learning
algorithms, continuous learning, and anomaly detec-
tion. The paper claims that data-driven ML tech-
niques raise IoT device recognition and security. ML
greatly increases IoT device detection dependability
and adaptability in different environments.
In (Meidan et al., 2017), a ML framework for
identifying IoT devices through network traffic pat-
tern analysis is proposed. The system employs su-
pervised learning models to classify device types
based on the traffic characteristics it monitors over
time. The approach delivers precise device finger-
printing by analyzing device activity at the network
level, without the need for deep packet inspection.
The framework demonstrates exceptional classifica-
tion accuracy in the evaluations conducted on genuine
IoT devices, hence validating its efficacy in practical
scenarios.
In (Torrey and Shavlik, 2010), an overview of
TL is provided, detailing its key concepts and tech-
niques. The paper discusses how TL allows models
to apply knowledge from one task to improve perfor-
mance on a different, but related, task. The authors
categorize different TL methods, including instance-
based, feature-based, and model-based approaches,
and highlight their practical applications. The authors
also address challenges such as negative transfer and
emphasize the growing importance of TL in ML ap-
plications.
In (Opoku et al., 2024), the authors presented a
ML-based solution that aims at classifying IoT de-
vices, detecting anomalies, and enhancing both secu-
rity and operational efficiency in IoT networks. The
proposed approach uses network traffic data to ex-
tract specific features, enabling precise device identi-
fication by capturing unique patterns and behaviors.
Their methodology used feature selection with ML
metrics to emphasize prevention of unauthorized ac-
cess and misuse, contributing to improved IoT secu-
rity. However, the paper acknowledges that the per-
formance of the model is sensitive to the quality and
Figure 1: Proposed Methodology.
selection of features, and further work could be done
to prevent learning of a new environment every time.
This will always have to rely heavily on the availabil-
ity and quantity of high-quality network traffic data,
which presents challenges in scenarios with limited
or noisy datasets.
4 METHODOLOGY
Traffic data can be collected using two primary meth-
ods: active probing or passive monitoring, each align-
ing with a different approach to device identifica-
tion (Fan et al., 2024). Active identification involves
gathering information about devices through deliber-
ate network scan. However, passive identification col-
lects information by observing the characteristics of
the communication traffic of devices without active
intervention (LN et al., 2023).
We employ a passive strategy, which does not re-
quire the devices to actively participate in traffic com-
munication, reducing the risk of network disruption.
Thus, we resort to using collected and stored datasets
containing network traffic generated by IoT devices.
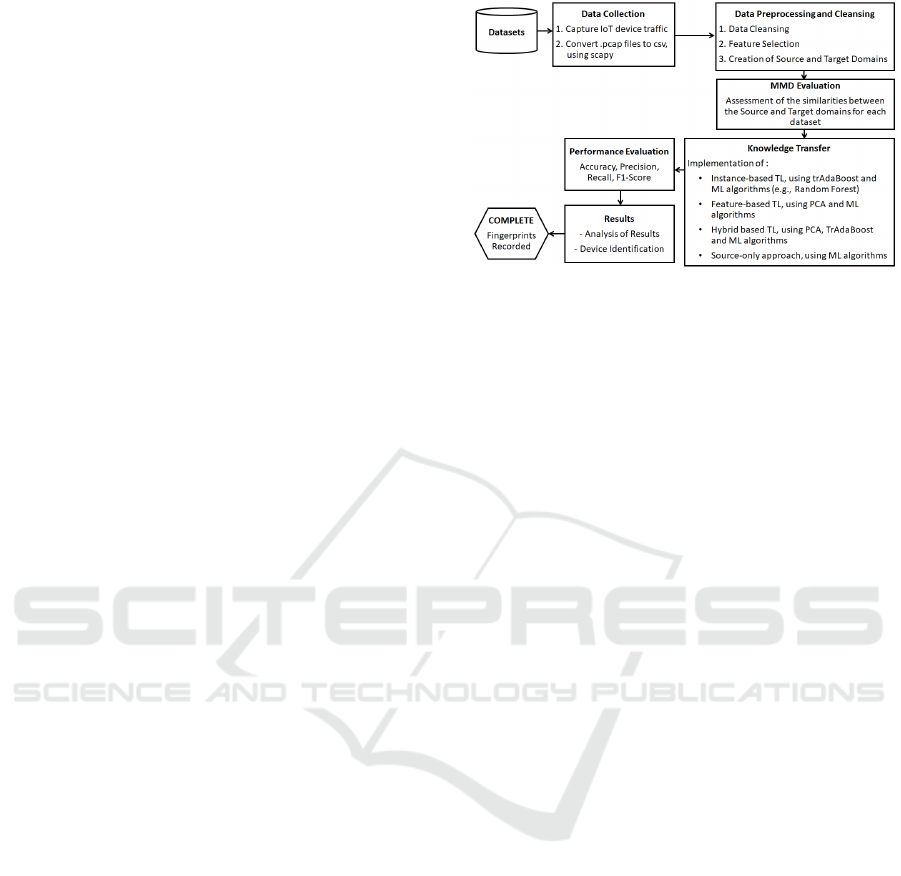
The methodology we propose, which is shown in
Figure 1, is comprised of several modules that are de-
tailed in the following subsections.
4.1 Data Collection and Preprocessing
In this paper, we use three publicly available datasets
that contain real-world IoT network traffic: CIC-
UNB (Dadkhah et al., 2022), IoT Sentinel (Miettinen
et al., 2017), and UNSW (Moustafa and Slay, 2015).
These datasets were originally stored in different for-
mats, with two in CSV files and one in .pcap for-
mat. To standardize the data for analysis, we use the
Python library sqpy to process and convert all .pcap
files into CSV format, ensuring compatibility with our
experimental framework.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
312

Once the datasets were converted, preprocess-
ing steps were applied to enhance data quality and
structure, ensuring optimal performance of ML al-
gorithms. The preprocessing phase involved data
cleansing, feature selection, label encoding, data
merging, shuffling, and normalization. These steps
addressed common issues such as missing values and
inconsistencies while preparing the data for analysis
and model training (Hamad et al., 2019).
Data cleansing focused on identifying and rectify-
ing corrupted, inaccurate, or irrelevant entries (Aksoy
and Gunes, 2019). This process ensured consistency
by handling missing values, merging dataset files, and
applying normalization techniques.
To facilitate training of the ML model, categori-
cal features were converted into numerical represen-
tations using the one-hot encoding method (Brown-
lee, 2024). Additionally, normalization was applied
to standardize feature scales, improving model perfor-
mance and convergence. We used the standard scaler
normalization method, which transforms the charac-
teristics by removing the mean and scaling to the unit
variance:
X
scaled
=
X −µ
σ
(8)
where µ and σ represent the mean and standard
deviation of the variable X, respectively.
The following key tasks were performed during
data preparation and preprocessing.
• Data Conversion and Merging. The raw net-
work traffic data were initially stored in separate
files. After converting all .pcap files to CSV for-
mat using scapy, the individual device traffic logs
were merged into a single comprehensive dataset.
• Data Labeling and Shuffling. Since the data sets
originated from different sources, the labels were
manually assigned based on the identity of the de-
vice. Shuffling was then applied to prevent the
model from learning data patterns in a fixed order,
improving generalization.
• Data Encoding and Normalization. After la-
beling, categorical columns were converted into
numerical values using one-hot encoding. The
dataset was then normalized using a standard
scaler to improve the performance of ML algo-
rithms.
4.2 Feature Selection
Feature selection is essential to identify the most
critical attributes within a dataset, thus improving
model performance and minimizing computing load
(Anowar et al., 2021; Gholami et al., 2023; Li
et al., 2017). We employ an approach termed UF-
SRF (Zhao and Liu, 2007), an unsupervised feature
selection method based on Random Forest. This
method is executed through the “FeatureSelector”
class, which includes functions to assess iteration
counts and quantify feature importance (Zhao and
Liu, 2007; Breiman, 2001).
A random sample of 10,000 instances is extracted
from the dataset, and the three most significant at-
tributes are selected according to their importance rat-
ings. The scores are subsequently summed across
thirty cycles using random class labels. The selec-
tion and use of the top three features aligns with the
benchmark paper (Opoku et al., 2024), we want to im-
prove upon, ensuring fair and precise comparison that
reflect the same context.
After using the feature selection process, only the
most ranked features are preserved, yielding a more
refined dataset. The selected features are presented
in Tables II, III, and IV, corresponding to the CIC-
UNB, IoT Sentinel, and UNSW datasets, respectively.
Space limitations prevented us from showing all the
available features.
Table 1: The features selected from the CIC-UNB
dataset (Dadkhah et al., 2022).
No. Feature Description
1 sum et Aggregate of the data.
2 epoch timestamp Time the specific packet was
recorded.
3 time since
previ-
ously displayed
frame
Time between the current
packet and the first captured
packet.
Table 2: The features selected from the IoT Sentinel
dataset (Miettinen et al., 2017).
No. Feature Description
1 IP Addresses and routes packets
across networks.
2 TCP Provides reliable data transmis-
sion.
3 DNS Resolves domain names to IP ad-
dresses.
4.3 Transfer Learning Approaches
As stated earlier, this study explores three TL
approaches—instance-based, feature-based, and
hybrid-based—alongside a source-only approach for
A Hybrid-Based Transfer Learning Approach for IoT Device Identification
313

Table 3: The features selected from the UNSW
dataset (Moustafa and Slay, 2015).
No. Feature Description
1 dur Recorded total duration
2 service http, ftp, smtp, ssh, dns, ftp-data,
irc, and (-) if not much used ser-
vice
3 synack TCP connection setup time, the
time between the SYN and the
SYN ACK packets.
comparative evaluation.
In the instance-based TL approach, we utilize
the TrAdaBoost algorithm, training models on the
top three features selected during feature selection.
The feature-based TL approach applies two strate-
gies: Principal Component Analysis (PCA) for di-
mensionality reduction and a separate model trained
using only the top three selected features to enhance
classification performance. The hybrid-based TL
approach integrates both instance-based and feature-
based techniques. First, the feature-based approach is
applied to extract key features, followed by instance-
based learning using 100% of the source domain and
70% of the target domain for training, with the re-
maining 30% used for testing.
For comparison, we also consider a source-only
approach, where ML models are trained on the en-
tire dataset without feature selection, allowing us to
evaluate the impact of TL methods against a baseline
model.
4.4 Machine Learning Algorithms
We utilize three ML algorithms, namely Random For-
est (RF), K-Nearest Neighbors (KNN), and Decision
Tree (DT). Considering these three ML algorithms,
the four approaches listed in the previous section, and
the three datasets at hands, we train a total of 36 mod-
els. The goal is to identify which algorithm performs
better in each approach. For training each model, a
10-fold cross-validation approach is used to obtain re-
liable results.
5 EXPERIMENTAL SETUP
To validate the efficacy of our proposed methodol-
ogy, we conduct extensive experiments on a com-
puter running Windows 10 Pro with 2.6 GHz Intel(R)
Core(TM) i5-4210M and a 8GB RAM. The soft-
ware environment includes PyCharm 2024, using the
Pyshark, Pandas, Scapy libraries. In addition, Python
libraries are used to capture and analyze IoT device
traffic from the considered datasets.
5.1 Datasets
As stated earlier, the datasets used in the experiments
are real-world datasets, which are as follows:
• CIC-UNB (Dadkhah et al., 2022): It is made up
of a total of 40 IoT devices, of which 27 are dis-
tinct types of devices (meaning that device types
are represented by several devices each).
• IoT Sentinel (Miettinen et al., 2017): It com-
prises 27 different IoT devices.
• UNSW (Moustafa and Slay, 2015): It encom-
passes a comprehensive collection of 28 devices,
of which only 22 are IoT devices.
The schemes of three datasets are presented in Ta-
ble 4, whereas the list of their IoT device types are
presented in (Dadkhah et al., 2022), (Miettinen et al.,
2017), and (Moustafa and Slay, 2015), respectively.
Table 4: Shemes of the three datasets used (Dadkhah et al.,
2022), (Miettinen et al., 2017), and (Moustafa and Slay,
2015).
Attribute CIC-UNB IoT Sentinel UNSW
Format csv pcap csv
Devices 40 27 22
Features 276 550 352
Size (KB) 776 487 609
Start date Aug 2022 June 2017 Sep 2015
End date Sep 2022 July 2017 Oct 2015
Note that, only the top three features selected in
the feature selection phase are considered in each
dataset. To validate our methodology, we create four
use cases for each dataset, UC1, UC2, UC3, and UC4,
respectively, corresponding to the selection of 1, 2, 3,
and all features.
5.2 Creation of the Source and Target
Domains
To apply TL approaches, we need to create the source
and target domains. To that goal, each dataset is
split into two sets, representing the source and target
domains, with distinctive marginal distributions. To
quantify the differences between the source and tar-
get domains of each dataset, we use the MMD score,
which compares their distributions. This score serves
as a measure of the disparity between the four dis-
tributions. We use this score to examine how these
differences impact the performance of TL.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
314
The MMD is usually calculated using kernel
methods, and in our experiments we use a Gaussian
kernel, which is widely used. An equal number of
samples (n = 100) are drawn from both the source and
target domains. As we are taking empirical estimates
of the MMD score, which vary with the samples, we
average the estimates obtained after conducting 500
iterations. The averaged results are shown in Table 5
for the three datasets at hands. The MMD score is
evaluated using an open-source code, which is avail-
able at (Tunali, 2023).
Table 5: MMD scores for the four use cases involving the
three datasets considered.
Use cases CIC-UNB IoT Sentinel UNSW
UC1 6.250 × 10
−6
5.132 × 10
−6
4.897 × 10
−6
UC2 1.690 × 10
−4
1.750 × 10
−4
1.800 × 10
−4
UC3 3.450 × 10
−4
3.320 × 10
−4
3.280 × 10
−4
UC4 1.571 × 10
−2
1.487 × 10
−2
1.653 × 10
−2
5.3 Model Training
As stated above, we created four use cases (UC1 to
UC4), which differ in the number of the most relevant
features considered. That is, in UC1, one feature (the
top one) is considered, in UC2, the top two features
are considered, in UC3, the top three features are
considered, and in UC4, all features are considered.
As a result, for one of the three datasets at the hands,
we created four datasets, each representing a use
case. Then, each dataset is subsequently divided into
source and target domains, forming the basis for the
four varied experimental approaches: instance-based,
feature-based, hybrid-based, and source-only. These
approaches offer different insights to evaluate the
predictive results of the models in all use cases.
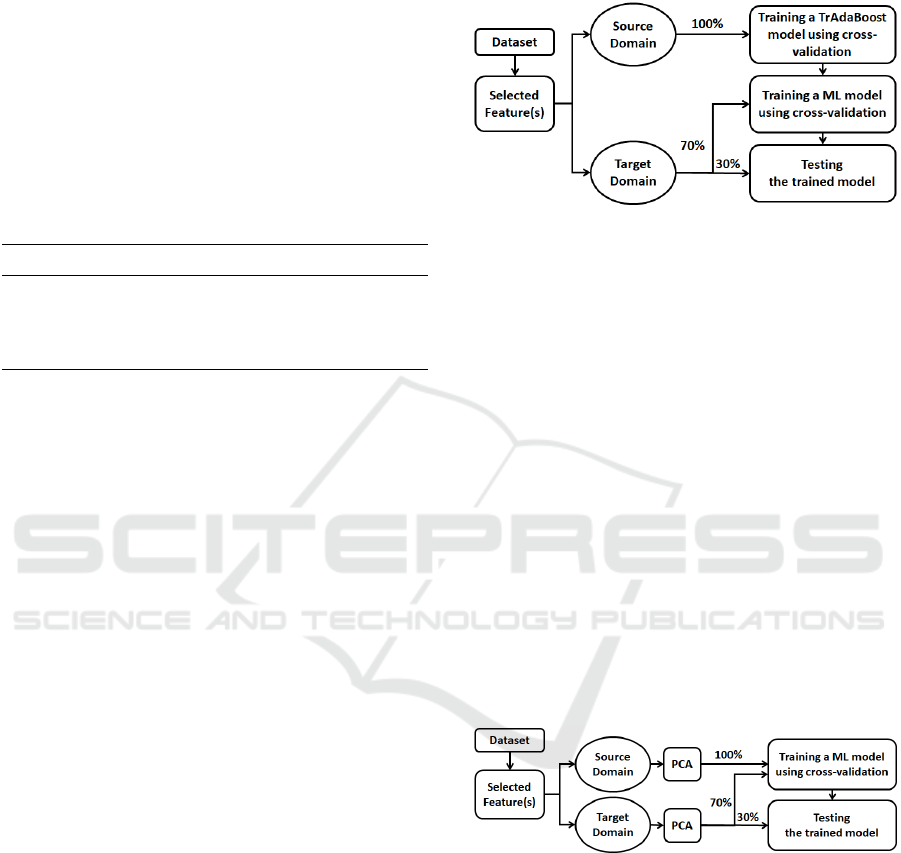
Instance-Based Approach. This approach is im-
plemented with the TrAdaBoost algorithm, using the
ADAPT library (Ulyanov et al., 2021). The latter
is designed to help with knowledge transfer by pro-
gressively modifying weights on instances from the
source dataset. As shown in Figure 2, this approach
uses the complete source domain together with 70%
of the target domain for training a TrAdaBoost Model,
which is then refined with a ML algorithm (e.g., Ran-
dom Forest). The obtained ML model is then tested
on the remaining 30% of the target domain.
TrAdaBoost prioritizes instances in the source
dataset that enhance predictions in the target do-
main. This method enhances the model’s general-
ization abilities and improves classification accuracy
when the source and target data exhibit common pat-
terns. The instance-based methodology offers flexi-
bility in scenarios with restricted target data, render-
ing it suitable for situations requiring exact compari-
son across different datasets.
Figure 2: Instance-based Approach.
Feature-Based. This approach is implemented using
PCA to reduce dimensionality while retaining essen-
tial information from each dataset. PCA, which is im-
plemented using the ADAPT library (Ulyanov et al.,
2021), is traditionally used for further dimensionality
reduction (Anowar et al., 2021; Venkatesh and Anu-
radha, 2019; Kumar and Minz, 2014). Transforms
the data into a lower-dimensional space by identifying
and retaining the most significant components, those
that capture the maximum variance in the dataset.
PCA ensures that only the most informative fea-
tures are carried forward, minimizing redundancy,
and avoiding overfitting, especially in TL context
where the target domain may have limited data. First,
PCA is applied to the source and target domains of
each dataset. Then, the entire source domain and 70%
of the target domain obtained from PCA are used to
train the ML models, while the remaining 30% of the
target domain is reserved for model testing, as shown
in Figure 3.
Figure 3: Feature-based Approach.
Hybrid-Based Approach. This approach trains
a hybrid model that integrates both instance-based
(via TrAdaBoost) and feature-based (via PCA) ap-
proaches. By combining these two techniques, the
hybrid model capitalizes on the strengths of both in-
stance reweighting and feature transformation, pro-
viding a comprehensive approach to data alignment
between source and target domains. As shown in Fig-
ure 4, the hybrid-based approach first applies PCA
to focus on the primary components of the data and
subsequently uses TrAdaBoost to emphasize relevant
instances. This dual-layered technique reduces noise
A Hybrid-Based Transfer Learning Approach for IoT Device Identification
315
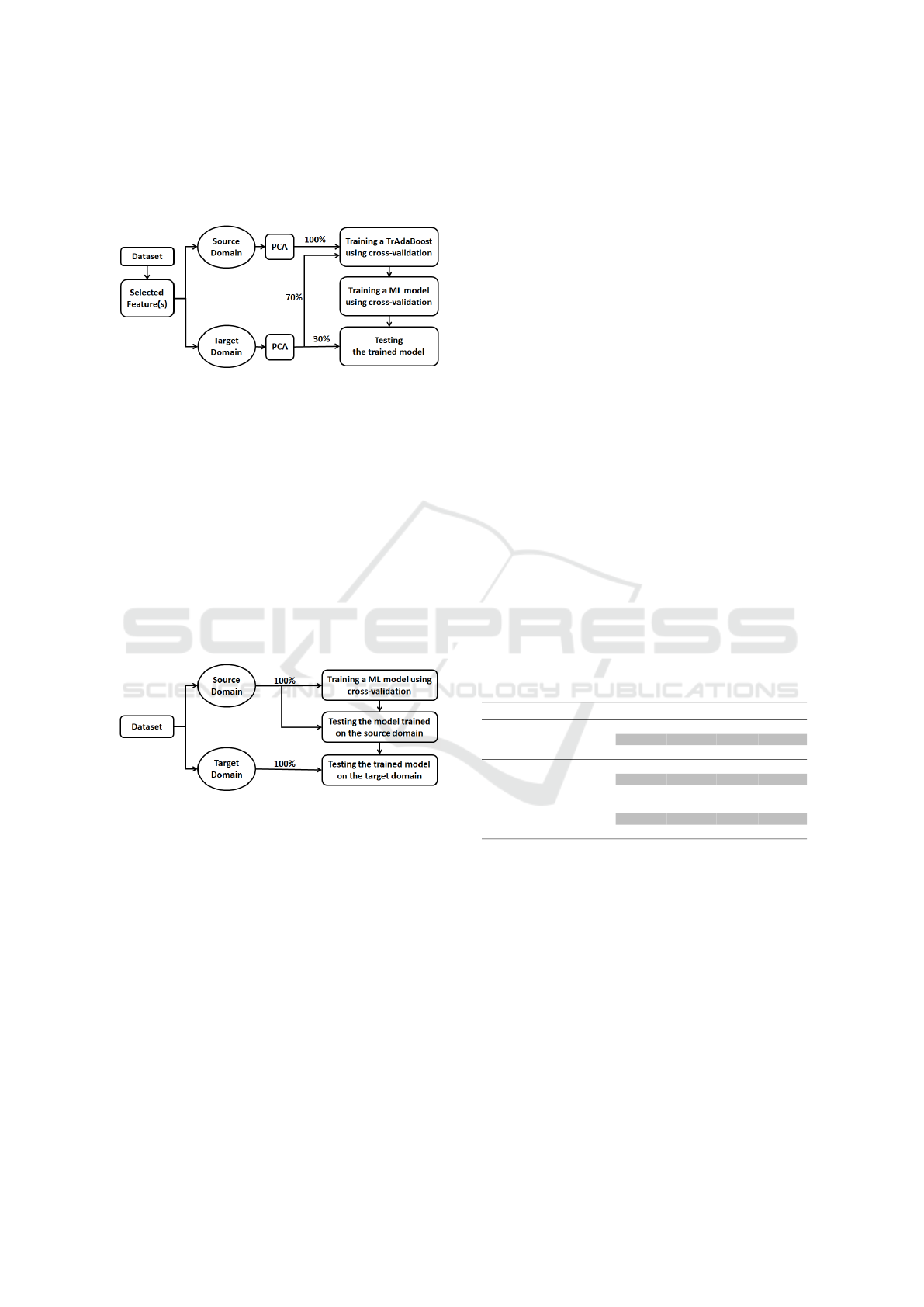
while enhancing the predictive power of the model
across datasets, offering a balanced approach that ac-
commodates both instance relevance and feature sig-
nificance.
Figure 4: Hybrid-based Approach.
Source-Only Approach. This approach establishes
a baseline using the source data without any selec-
tion or modification of the features. As shown in Fig-
ure 5, the source-only approach trains the model di-
rectly on the source data set and evaluates its predic-
tion performance in the target domain. This method
serves as a control model, enabling us to evaluate the
effectiveness of feature selection and transformation
strategies in other approaches. By comparing the out-
comes of this source-only approach with those of the
instance-based, feature-based, and hybrid-based ap-
proaches, we obtain insight into the influence of our
feature extraction and data alignment techniques on
model performance.
Figure 5: Source-only Approach.
6 EXPERIMENTAL RESULTS
To validate our solution, we consider the following.
1. Identification of the best ML algorithm among the
three algorithms considered.
2. Assessment of the impact of employing feature
selection on prediction results.
3. Assessment of the prediction performance of each
one of the four use cases considered.
4. Comparison of our solution with existing solu-
tions that do not use TL.
To evaluate the performance of the solutions, we
use the Accuracy, Recall, Precision, and F1-Score
metrics.
6.1 The Best ML Algorithm Among the
Three Algorithms Considered
As stated in the Methodology section, to train differ-
ent models, we considered Random Forest, KNN, and
Decision Tree; employing mixed TL approaches. The
hybrid approach combined with UC3 proved to be the
best approach, as will be detailed in Section 6.3. This
approach will be used to identify the best ML algo-
rithm among the three ML considered in this paper.
Using the three metrics considered, the performance
results of each of the three ML algorithms for each
data set are presented in Table 6.
Random Forest consistently showed superior per-
formance across all datasets and measures, showcas-
ing its stability and its capacity for effective general-
ization. KNN yielded moderate results; however, De-
cision Tree underperformed, underscoring its limits in
managing intricate data structures. The hybrid-based
implemented using Random Forest demonstrated the
highest efficacy in attaining optimal model perfor-
mance across all datasets. Therefore, in the follow-
ing, we consider the hybrid-based approach combined
with Random Forest and UC3 as “our solution”.
Then we compare it with the other three use cases
(UC1, UC2, and UC4), as well as with a baseline so-
lution (Opoku et al., 2024).
Table 6: Prediction results, as obtained for all three datasets
and the three ML algorithms using the top-three features
(i.e., UC3). The best results are shadowed.
Dataset ML algorithm Accuracy Precision Recall F1-Score
CIC-UNB
KNN 90.50% 89.50% 89.90% 89.70%
Random Forest 99.95% 99.90% 99.85% 99.88%
Decision Tree 88.50% 87.90% 88.00% 87.95%
IoT Sentinel
KNN 91.00% 90.80% 90.50% 90.65%
Random Forest 98.50% 98.00% 98.60% 98.30%
Decision Tree 89.90% 89.50% 89.70% 89.60%
UNSW
KNN 90.20% 90.00% 89.80% 89.90%
Random Forest 97.80% 97.50% 97.40% 97.45%
Decision Tree 90.00% 89.60% 89.80% 89.70%
6.2 Impact of Feature Selection
It is well known that using only the most relevant
features significantly enhances the prediction perfor-
mance compared to using all available features. In
fact, superior results are observed with the use of
the three main characteristics, as shown in Table 7,
where the three main characteristics are considered
(ie, UC3). The table illustrates the effect of feature
selection on the prediction performance of the sug-
gested Random Forest-based solution, again employ-
ing the hybrid-based approach. Using the three most
selected features (UC3), the model consistently sur-
passed the results achieved with all features in all
datasets. Using UC3 for the CIC-UNB dataset in-
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
316

creased accuracy to 99. 85% and F1-Score to 97.
70%. Comparable improvements were observed for
the IoT Sentinel and UNSW datasets, with UC3 im-
proving the F1-Score to 96.50% and 96.40%, respec-
tively. The hybrid-based approach improved these
advances by integrating instance-based reweighting
with feature-based adaptation, thus ensuring superior
generalization and noise mitigation. These findings
validate that focusing on the most relevant features
significantly improves prediction performance.
Table 7: The impact of feature selection on the prediction
performance of our proposed solution (based on Random
Forest). The best results are shadowed.
Dataset Features Accuracy Precision Recall F1-Score
CIC-UNB
All Features 99.50% 99.70% 95.01% 97.00%
UC3 99.85% 99.98% 96.30% 97.70%
IoT Sentinel
All Features 96.50% 95.50% 97.03% 5.80%
UC3 97.10% 96.20% 98.03% 96.50%
UNSW
All Features 95.91% 95.20% 94.06% 95.75%
UC3 96.50% 96.20% 95.00% 96.40%
6.3 Prediction Performance
Through the predefined use cases, we try to determine
if reducing the number of selected features improves
the prediction performance. Tables 8, 9, 10, and 11
show the results of UC1, UC2, UC3 and UC4, re-
spectively. These tables compare TL and ML metrics
in CIC-UNB, IoT Sentinel, and UNSW. These results
demonstrate the usefulness of instance-based, feature-
based, hybrid-based TL, and source-only techniques
in four scenarios, with considerable performance dif-
ferences.
The hybrid-based strategy outperformed the oth-
ers in UC1–UC3 of the CIC-UNB dataset. How-
ever, UC4, which exploited all characteristics, per-
formed slightly differently. For example, the hy-
brid technique had the highest accuracy (97.0%
to 99.5%) and robust precision (96. 4% to 99.
9%) in all use cases. Recall ratings of 99.8%
demonstrated its ability in spotting positive events,
while F1-Score constantly exceeded expectations. In
UC4, the Source-only strategy had comparable ac-
curacy (93.5%), but poorer precision (93.9%), recall
(88.7%), and F1-Score (91.4%) than the hybrid-based
approach. Instance-based and feature-based tech-
niques performed moderately, but the hybrid-based
strategy used its strengths to better compete.
Similarly, the hybrid-based strategy excelled in
all use cases, achieving 96.6% to 98.2% accuracy in
the IoT Sentinel dataset. UC2’s Precision reached
96.8% and Recall 95.0%, demonstrating its flexibility.
While consistent, the Source-only strategy had lower
Recall and Precision in UC4 (90.6% and 89.5%, re-
spectively). Although limited, its F1-Score in UC4
(92.5%) showed a better balance between Precision
and Recall compared to previous use cases. The
feature-based strategy improved UC2 and UC3 but
lagged behind the hybrid-based approach, which bet-
ter controlled dataset complexity. The UNSW dataset
was the hardest, yet the hybrid strategy always per-
formed better. The accuracy ranged from 96.1% to
97.8%, with Precision and Recall peaking at 97.5%
and 96.8%, respectively. The Source-only approach
struggled with the dataset’s complexity, resulting in
Accuracy of just 91.5% in UC4, Precision of 90.3%,
and Recall of 84.9%. The feature-based and instance-
based techniques performed well, but the hybrid-
based approach was more adaptable in balancing Pre-
cision and Recall. All features were used in UC4,
but the results were fragmented and showed different
trends. This shows that using all features without re-
finement cannot reliably identify devices. These find-
ings confirm that feature reduction and optimized ap-
proach improve predictive performance across varied
datasets and use cases.
The results highlight the effectiveness of the
hybrid-based TL approach across all datasets. Its Ac-
curacy, Precision, Recall, and F1-Score were consis-
tently high, showing its capacity to adapt to varied
datasets. Source-only performed worst, demonstrat-
ing its inability to adapt to target domain-specific fea-
tures. Feature-based approaches showed more vari-
ability, while instance-based approaches were more
consistent but less accurate than the hybrid-based
approach. The results show that the hybrid tech-
nique is the most reliable and effective way to handle
different datasets. Its integrated instance-based and
feature-based approaches together allow it to outper-
form competing approaches in all main criteria.
Table 8: Performance results, as obtained in UC1 for three
datasets at hand.
Metric Instance-based Feature-based Hybrid-based
CIC-UNB Dataset
Accuracy 95.5% 93.4% 97.0%
Precision 96.3% 95.2% 97.8%
Recall 92.5% 92.0% 95.0%
F1-Score 94.4% 91.6% 96.4%
IoT Sentinel Dataset
Accuracy 95.8% 93.7% 97.3%
Precision 96.0% 94.5% 97.5%
Recall 92.8% 92.2% 96.2%
F1-Score 94.7% 93.8% 96.7%
UNSW Dataset
Accuracy 95.2% 93.1% 96.8%
Precision 95.5% 90.0% 97.1%
Recall 92.1% 91.5% 94.9%
F1-Score 93.8% 91.3% 96.2%
A Hybrid-Based Transfer Learning Approach for IoT Device Identification
317
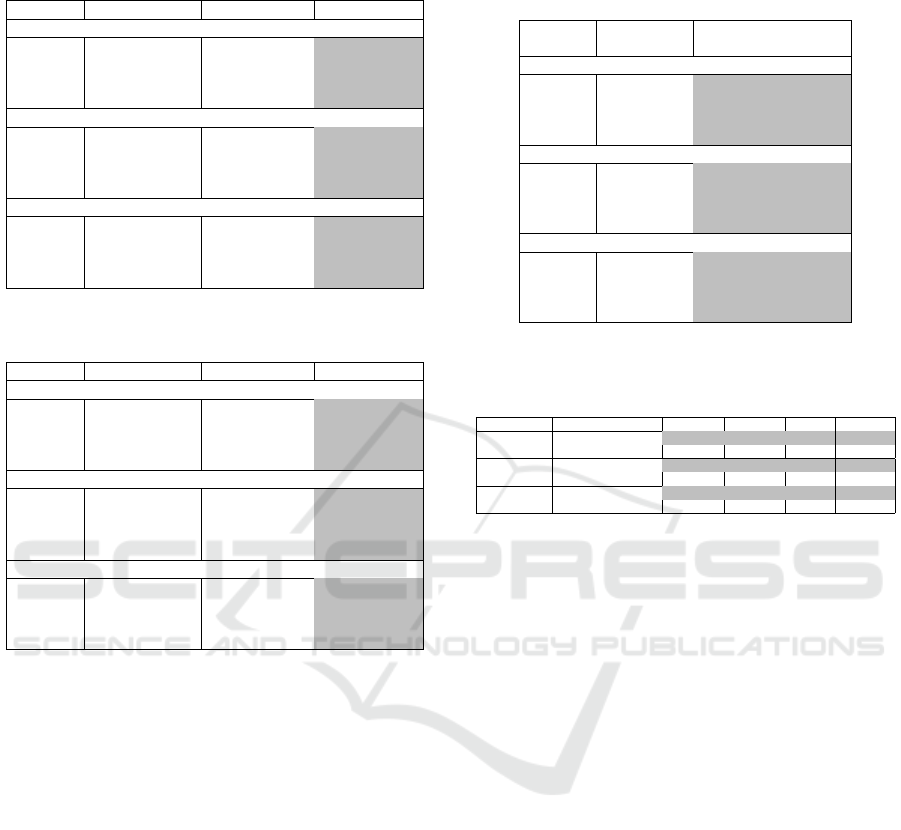
Table 9: Performance results, as obtained in UC2 for three
datasets at hand.
Metric Instance-based Feature-based Hybrid-based
CIC-UNB Dataset
Accuracy 94.0% 94.8% 96.2%
Precision 94.5% 94.9% 96.4%
Recall 92.0% 92.8% 95.1%
F1-Score 93.0% 93.8% 95.5%
IoT Sentinel Dataset
Accuracy 93.8% 94.5% 96.6%
Precision 94.2% 94.8% 96.8%
Recall 92.5% 93.2% 95.0%
F1-Score 93.2% 93.8% 95.9%
UNSW Dataset
Accuracy 93.5% 94.2% 96.1%
Precision 93.8% 94.5% 96.3%
Recall 92.0% 92.7% 94.4%
F1-Score 93.0% 93.5% 95.1%
Table 10: Performance results, as obtained in UC3 for three
datasets at hand.
Metric Instance-based Feature-based Hybrid-based
CIC-UNB Dataset
Accuracy 94.5% 95.8% 99.5%
Precision 95.8% 94.8% 99.9%
Recall 91.5% 91.2% 99.8%
F1-Score 93.2% 93.0% 99.8%
IoT Sentinel Dataset
Accuracy 94.3% 95.8% 98.2%
Precision 95.0% 94.8% 97.8%
Recall 93.8% 92.5% 98.5%
F1-Score 93.4% 93.6% 98.1%
UNSW Dataset
Accuracy 94.2% 95.5% 97.8%
Precision 94.5% 94.8% 97.5%
Recall 91.7% 91.2% 96.8%
F1-Score 93.2% 93.0% 97.1%
6.4 Comparison with Existing Solutions
We compare our best solution, which implements a
hybrid-based approach and Random Forest using the
top three features (UC3), with a solution that does not
use TL (baseline) (Opoku et al., 2024). As shown in
Table 12, the results show a significant improvement,
though the baseline solution (Opoku et al., 2024)
uses also feature selection and considers only the
three-top features. This demonstrates that incorpo-
rating a hybrid-based approach with TL significantly
enhances model performance compared to methods
without TL. Our solution’s ability to leverage deeper
patterns and relationships highlights the potential of
TL to improve predictive accuracy, even when similar
feature sets are used
6.5 Time Performance
To evaluate the computational efficiency of our solu-
tion, Table 13 compares training and testing times for
instance-based, feature-based, hybrid-based (our so-
lution), source-only and TL-free techniques in three
Table 11: Performance results, as obtained in UC4 for three
datasets at hand compared to the hybrid-based approach of
UC3.
Metric Source-only
Hybrid-based of UC3
Our solution
CIC-UNB Dataset
Accuracy 93.5% 99.5%
Precision 93.9% 99.9%
Recall 88.7% 99.8%
F1-Score 91.4% 99.8%
IoT Sentinel Dataset
Accuracy 91.5% 98.2%
Precision 89.5% 97.8%
Recall 90.6% 98.5%
F1-Score 92.5% 98.1%
UNSW Dataset
Accuracy 91.5% 97.8%
Precision 90.3% 97.5%
Recall 84.9% 96.8%
F1-Score 92.9% 97.1%
Table 12: Comparison of our solution (based on Random
Forest and UC3) with an existing solution (Opoku et al.,
2024).
Dataset Solutions Accuracy Precision Recall F1-Score
CIC-UNB Our Solution 99.95% 99.99% 99.80% 99.85%
(Opoku et al., 2024) 99.85% 99.98% 96.30% 97.70%
IoT Sentinel Our Solution 98.20% 97.80% 98.50% 98.15%
(Opoku et al., 2024) 97.10% 96.20% 98.03% 96.50%
UNSW Our Solution 97.80% 97.50% 96.80% 97.10%
(Opoku et al., 2024) 96.50% 96.20% 95.00% 96.40%
datasets. Time efficiency varies by approach.
Overall, instance-based training and testing times
were shorter for all datasets. Testing took 0.021 sec-
onds and training 0.412 seconds in CIC-UNB. Fo-
cusing on conveying only relevant instances from
the source to the target domain provides efficiency.
Though effective, its simplicity restricts its ability to
catch complex patterns in UNSW’s dataset.
The feature-based method was computationally
efficient but took longer to train and test than instance-
based. In the IoT Sentinel dataset, the instance-based
technique was trained in 0.532 seconds and tested in
0.498. Aligning features across source and destina-
tion domains takes time. Its precision and efficiency
may not be enough for more complex datasets.
Our hybrid model offers feature-based and
instance-based benefits. This integration takes longer
to train than standalone approaches (0.489 seconds
for CIC-UNB vs. 0.412 seconds for instance-based)
but faster than source-only (0.511 seconds for the
same dataset). This hybrid model can capture
instance-level and feature-level associations, making
it suitable for moderate to highly complex datasets
like UNSW, where it trained in 0.709 seconds, sur-
passing the source-only approach (0.712 seconds) and
non-TL approach (1.654 seconds).
The source-only technique took longer to train and
test than the hybrid model in all datasets. UNSW’s
training took 0.712 seconds, longer than the hybrid
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
318
model’s 0.709. Using source domain information
without adjusting it for the target domain results in
unfocused optimizations. Transfer learning helps but
is less efficient than hybrid TL.
Non-TL methods took the longest to train and test.
The CIC-UNB training processing time was 1.321
seconds, longer than the TL approaches. Inefficient
results result from training the model from scratch
without source domain knowledge. Thus, this strat-
egy is computationally intensive and impractical for
limited resources and time.
The datasets also affected the calculation times.
Due to its simpler data patterns. UNSW had the
longest timings, suggesting a greater complexity and
scale of this dataset, whereas IoT Sentinel took a little
longer, reflecting reasonably complicated data.
The hybrid-based TL showed the best efficiency-
computational cost ratio. Although slower than
instance-based and feature-based approaches, it was
more accurate and efficient than the Source-only and
non-TL methods. These results indicate that hybrid
TL is the best scalable and efficient model for com-
plex datasets.
Table 13: Training and Testing Time for Different Ap-
proaches on All Datasets.
Dataset Approach
Training Time Testing Time
(sec) (sec)
CIC-UNB
Instance-based TL 0.412 0.021
Feature-based TL 0.398 0.019
Hybrid TL 0.489 0.024
Source-only TL 0.511 0.025
Without TL (Opoku et al., 2024) 1.321 0.017
IoT Sentinel
Instance-based TL 0.532 0.023
Feature-based TL 0.498 0.020
Hybrid TL 0.611 0.029
Source-only TL 0.621 0.030
Without TL (Opoku et al., 2024) 1.378 0.402
UNSW
Instance-based TL 0.623 0.030
Feature-based TL 0.588 0.028
Hybrid TL 0.709 0.035
Source-only TL 0.712 0.037
Without TL (Opoku et al., 2024) 1.715 0.520
7 CONCLUSION
We introduced a reliable and practical framework for
the identification of IoT devices through the analy-
sis of network traffic, using a carefully selected set
of characteristics in conjunction with ML and TL
techniques. Our methodology considered four TL
approaches, each using a different feature engineer-
ing procedure. These approaches were compared to
a baseline method without TL. We ensured that the
proposed approaches met rigorous model evaluation
standards using well-known metrics, that is, preci-
sion, accuracy, recall, and F1-Score.
In all datasets considered, the hybrid-based TL ap-
proach outperformed alternative TL models as well as
the baseline model. The time performance improved
significantly using the hybrid approach, making it
scalable and efficient for real-world applications.
REFERENCES
Aidoo, A., Schiller, E., and Fuhrer, J. (2022). Landscape
of iot security. Journal of Computer Science Review,
25(3):100–120.
Aksoy, A. and Gunes, M. H. (2019). Automated iot de-
vice identification using network traffic. In ICC 2019
- 2019 IEEE International Conference on Communi-
cations (ICC), pages 1–7.
Anowar, F., Sadaoui, S., and Selim, B. (2021). Conceptual
and empirical comparison of dimensionality reduction
algorithms (pca, kpca, lda, mds, svd, lle, isomap, le,
ica, t-sne). Computer Science Review, 40:100378.
Breiman, L. (2001). Random forests. Machine Learning,
45(1):5–32.
Brownlee, J. (2024). Why one-hot encode data in machine
learning? - machinelearningmastery.com. Accessed:
Nov. 27, 2024.
Dadkhah, S., Mahdikhani, H., Danso, P. K., Zohourian, A.,
Truong, K. A., and Ghorbani, A. A. (2022). Towards
the development of a realistic multidimensional iot
profiling dataset. In The 19th Annual International
Conference on Privacy, Security & Trust (PST2022),
Fredericton, Canada.
Dwivedi, Y. K., Hughes, L., Baabdullah, A. M., Ribeiro-
Navarrete, S., Giannakis, M., and Al-Debei (2022).
Metaverse beyond the hype: Multidisciplinary per-
spectives on emerging challenges, opportunities, and
agenda for research, practice and policy. International
Journal of Information Management, 66:102542.
Falola, O., Louafi, H., and Mouhoub, M. (2023). Optimiz-
ing iot device fingerprinting using machine learning.
In Innovations in Digital Forensics, chapter 9, pages
293–317. World Scientific.
Fan, F. L.-N., Li, C.-L., Wu, Y.-C., Duan, C.-X., Wang, Z.-
L., Lin, H., and Yang, J.-H. (2024). Survey on iot
device identification and anomaly detection. Journal
of Software, 35(1):288.
Gholami, M., Mouhoub, M., and Sadaoui, S. (2023). Fea-
ture selection using evolutionary techniques. In 2023
IEEE International Conference on Systems, Man, and
Cybernetics (SMC), pages 1162–1167.
Hamad, S. A., Zhang, W. E., Sheng, Q. Z., and Nepal,
S. (2019). Iot device identification via network-flow
based fingerprinting and learning. In 2019 18th IEEE
International Conference On Trust, Security And Pri-
vacy In Computing And Communications/13th IEEE
International Conference On Big Data Science And
Engineering (TrustCom/BigDataSE).
Kawish, S., Louafi, H., and Yao, Y. (2023). An instance-
based transfer learning approach, applied to intrusion
detection. In 2023 IEEE International Conference on
Privacy, Security, Trust, pages 1–7.
Kumar, V. and Minz, S. (2014). Feature selection. SmartCR,
4(3):211–229.
A Hybrid-Based Transfer Learning Approach for IoT Device Identification
319

Li, J., Cheng, K., Wang, S., Morstatter, F., Trevino, R. P.,
Tang, J., and Liu, H. (2017). Feature selection: A
data perspective. ACM computing surveys (CSUR),
50(6):1–45.
Liu, Y., Wang, J., Li, J., Niu, S., and Song, H. C. (2021).
Machine learning for the detection and identification
of internet of things devices: A survey. IEEE Internet
of Things Journal, 9(1):298–320.
LN, F., CL, L., YC, W., YC, W., ZL, W., H, L., and JH,
Y. (2023). Survey on iot device identification and
anomaly detection. Ruan Jian Xue Bao/Journal of
Software, pages 1–21.
Meidan, Y., Bohadana, M., Shabtai, A., Guarnizo, J. D.,
Ochoa, M., Tippenhauer, N. O., and Elovici, Y.
(2017). Profiliot: A machine learning approach for
iot device identification based on network traffic anal-
ysis. In Proceedings of the Symposium on Applied
Computing, pages 506–509. ACM.
Miettinen, M., Marchal, S., Hafeez, I., Asokan, N., Sadeghi,
A.-R., and Tarkoma, S. (2017). Iot sentinel: Auto-
mated device-type identification for security enforce-
ment in iot. In 2017 IEEE 37th International Confer-
ence on Distributed Computing Systems (ICDCS).
Moustafa, N. and Slay, J. (2015). Unsw-nb15: a com-
prehensive data set for network intrusion detection
systems (unsw-nb15 network data set). In Military
Communications and Information Systems Confer-
ence (MilCIS), 2015. IEEE.
Opoku, S., Louafi, H., and Mouhoub, M. (2024). Iot de-
vice identification based on network traffic analysis
and machine learning. In Proceedings of the Interna-
tional Symposium on Networks, Computers, and Com-
munications (ISNCC), pages 1–8.
Sivanathan, A., Gharakheili, H. H., Loi, F., Radford, A.,
Wijenayake, C., Vishwanath, A., and Sivaraman, V.
(2019). Classifying iot devices in smart environments
using network traffic characteristics. IEEE Transac-
tions on Mobile Computing, 18:1745–1759.
Torrey, L. and Shavlik, J. (2010). Transfer learning. In
Handbook of Research on Machine Learning Appli-
cations and Trends: Algorithms, Methods, and Tech-
niques, pages 242–264. IGI Global.
Tunali, O. (2023). Maximum Mean Discrepancy (MMD) in
Machine Learning. Accessed 16-Jan-2023.
Ulyanov, D., Vedaldi, A., and Lempitsky, V. (2021). Deep
image prior. arXiv preprint arXiv:2107.03049.
Venkatesh, B. and Anuradha, J. (2019). A review of fea-
ture selection and its methods. Cybern. Inf. Technol,
19(1):3–26.
Zhao, Z. and Liu, H. (2007). Spectral feature selection for
supervised and unsupervised learning. In Proceed-
ings of the 24th International Conference on Machine
Learning (ICML ’07), pages 1151–1157. ACM.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
320
