
Anomaly Detection in ZkSync Transactions with Unsupervised Machine
Learning
Kamil Kaczy
´
nski
a
and Aleksander Wi ˛acek
Military University of Technology, Institute of Mathematics and Cryptology, Warsaw, Poland
Keywords:
Machine Learning, Blockchain, ZkSync, One Class SVM, Isolation Forest, Anomaly, DDOS.
Abstract:
This work proposes an anomaly detection model that consists of two different machine learning algorithms,
One Class Support Vector Machine and Isolation Forest. The chosen dataset is a publicly available ZkSync
data dump. Although there are several articles on anomaly detection using machine learning in blockchains,
this one is the first to focus on an Ethereum ZkSync rollup. There were two tasks set. One was to find
suspicious transactions in a snippet of the dataset, and the second was to detect possible DDOS attacks, where
one vector corresponds to one day of the life of the network. Evaluation of models was based on calculation of
accuracy, synthetic accuracy, ROC AUC and PR AUC metrics. The models were fine-tuned on synthetically
generated data. The proposed designs show reasonably good performance. The paper can be used as an
inspiration to conduct more research on zero-knowledge rollups, as they may have slightly different user
behavior than on Ethereum. In addition, the paper provides valuable insight into feature engineering and data
processing, which can be useful to some researchers.
1 INTRODUCTION
ZkSync is a Layer 2 zero-knowledge rollup that scales
the Ethereum network and has its own independent
virtual machine (MatterLabs, 2024). Transactions in
rollup are processed off-chain and then, their data
is compressed, put together in a batch, and sent to
Ethereum via on-chain smart contract as a single
transaction. Such mechanism brings advantages for
blockchain users, but it also must ensure rollup state
data availability and, in a zero-knowledge rollup, an
evidence that all transactions from a batch are valid.
ZkSync inherits security from Ethereum i.e. the state
of this rollup can be reconstructed by anyone, and
L2 transactions along with state changes are provable.
Using ZkSync costs significantly less in fees and al-
lows for faster transfer of funds, as the rollup is capa-
ble of processing significantly more transactions per
second than Ethereum. Therefore, the network is ea-
gerly utilized by many users, as it has more than 2
million accounts (but not all are active), and in March
2024, hundreds of thousands of wallets were eligi-
ble for ZkSync airdrop. In such a large environment,
surely some anomalous transactions can occur.
a
https://orcid.org/0000-0002-8540-5538
1.1 Paper Organization
Section 2 gives details on the methodology of this
study. Chosen machine learning models are shown
and a description of the used dataset is given. It also
provides comprehensive information on the created
anomaly detection pipelines. Section 3 presents the
results obtained with anomaly analysis and catego-
rization, as well as with the results of the models tun-
ing process. Section 4 focuses on forming conclu-
sions and proposes future work.
1.2 Related Work
There has already been a lot of research into anomaly
detection in cryptocurrency blockchains, but mainly
on Bitcoin and Ethereum.
In (Sayadi et al., 2019) paper, researchers concen-
trated on finding anomalies in the Bitcoin chain us-
ing One Class Support Vector Machine (OCSVM) for
detection and K-means clustering for categorization.
Due to the lack of labeled anomalies in the dataset that
they chosen to investigate, the authors created syn-
thetic anomalies based on selected attacks: DDOS,
Double Spending, and 51% attack.
In (Park and Kim, 2023), the authors used visu-
alization and statistical methods specifically for the
Kaczy
´
nski, K., Wi ˛acek and A.
Anomaly Detection in ZkSync Transactions with Unsupervised Machine Learning.
DOI: 10.5220/0013441600003979
In Proceedings of the 22nd International Conference on Security and Cryptography (SECRYPT 2025), pages 565-570
ISBN: 978-989-758-760-3; ISSN: 2184-7711
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
565
DDOS attack in Proof-of-Work Ethereum. Although
there are no machine learning (ML) models involved,
the paper provides useful details on relationships be-
tween the features of the blockchain network.
In (Apiecionek and Karbowski, 2024), the authors
concentrated on finding anomalies in contracts and
smart transactions, as well as anomalies that would
indicate Sybil and double-spending attack. Since
blockchain data are not labeled, the authors gener-
ated their own data and conducted research with vari-
ous machine learning algorithms, including OCSVM
and a Fuzzy Neural Network. The performance of the
methods was evaluated.
2 METHODOLOGY
Paper focuses on two different anomaly detection
tasks. In the first, each transaction was treated as a
single vector. The aim was to find transactions that
have unusual attribute values and could potentially
be part of some kind of attack, although no specific
one is expected. In the second approach, the vec-
tor was equivalent to one day, which means that the
daily statistics of ZkSync were calculated and formed
into features. This was a targeting investigation where
anomalies can indicate a possible DDOS attack.
2.1 Dataset Description and
Preparation
Models has been trained on ZkSync data prepared by
Matter-Labs (Silva et al., 2024). The dataset con-
tains blockchain information between February 14,
2023 and March 24, 2024. In this study, transac-
tions and transaction receipts categories were used.
The files of selected categories measure over 87GB,
so to speed up computation, only a fraction of dataset
has been used for transaction-level model. Transac-
tions that occurred in the first months after the launch
of ZkSync were rejected. Those transactions are not
representative. Around December 2023, the Boom of
Inscriptions occurred (Messias et al., 2024), which
caused the peak of average gas units used per trans-
action. Also, there was a peak in May 2023. That
would severely affect the model. Hence, dataframe
of transaction-level model starts with transactions
from 2023-06-25 with a block number of 7.000.000
to avoid massive spike in gas consumption. The
dataframe ends in block 7.099.999. The first 80% of
the dataframe was used to train the model and the rest
was used to evaluate it.
The training data has been filtered to include only
successful transactions. In addition, some system
contracts that appeared in the entries ’from’ or ’to’
were excluded from the whole dataframe. That gives
a total of 938.805 real transactions in the dataframe.
In addition, the effectiveness of the model that was
trained on data with all possible outliers and on data
with some outliers removed was measured. Few uni-
variate statistical methods were tested for the elimina-
tion task of outliers, such as Tukey’s criteria, but the
best results were given simply by applying a high cut
using a 0.999 quantile with a modified Z score (Kan-
nan et al., 2015), (Iglewicz and Hoaglin, 1993). This
operation was performed on the attributes individu-
ally and the multidimensional relationships between
the attributes were not captured. Distributions of fea-
tures such as the value in gwei and the input size, are
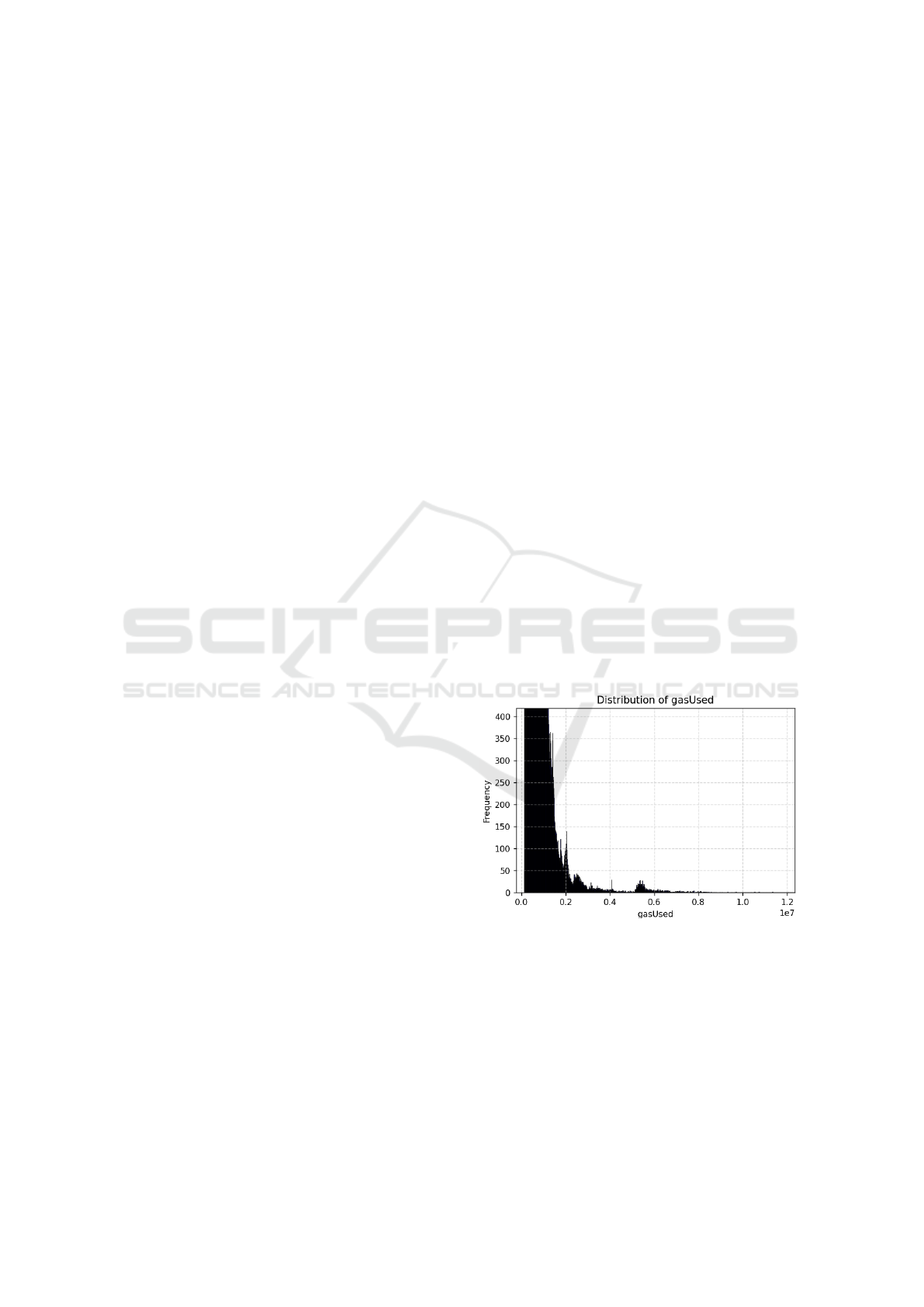
extremely skewed with heavy tails. As an example,
the distribution of the gasUsed, is shown in figure 1
and outliers can be observed in the given chart.
For testing model and fine-tuning parameters, syn-
thetic data have been generated manually. It contains
80 transactions labeled as normal and 20 as novel. For
the DDOS case, there are 90 normal instances and 10
anomalies. The dataset is unlabeled and it is difficult
to define appropriate patterns of anomalous transac-
tions and implement their automatic generation. Syn-
thetic dataset was designed based on statistical values
of the dataframe. Outliers were based on the min /
max parameters, some of them were designed to indi-
cate an error, like a transaction with all attributes set
to 0.
Figure 1: Distribution of gasUsed feature.
The time interval of the DDOS detection model
training set was chosen very carefully in order to max-
imize the size of this set, taking into account the charts
of the values of each feature. An example graph is
shown in figure 2. We chose data between 2023-05-
15 00:00 UTC, block number 3503979 and 2023-12-
03 23:59:59 UTC, block number 20601132. The rest
of the data, starting with block number 20601134,
was used for testing and evaluation. It gives a total
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
566
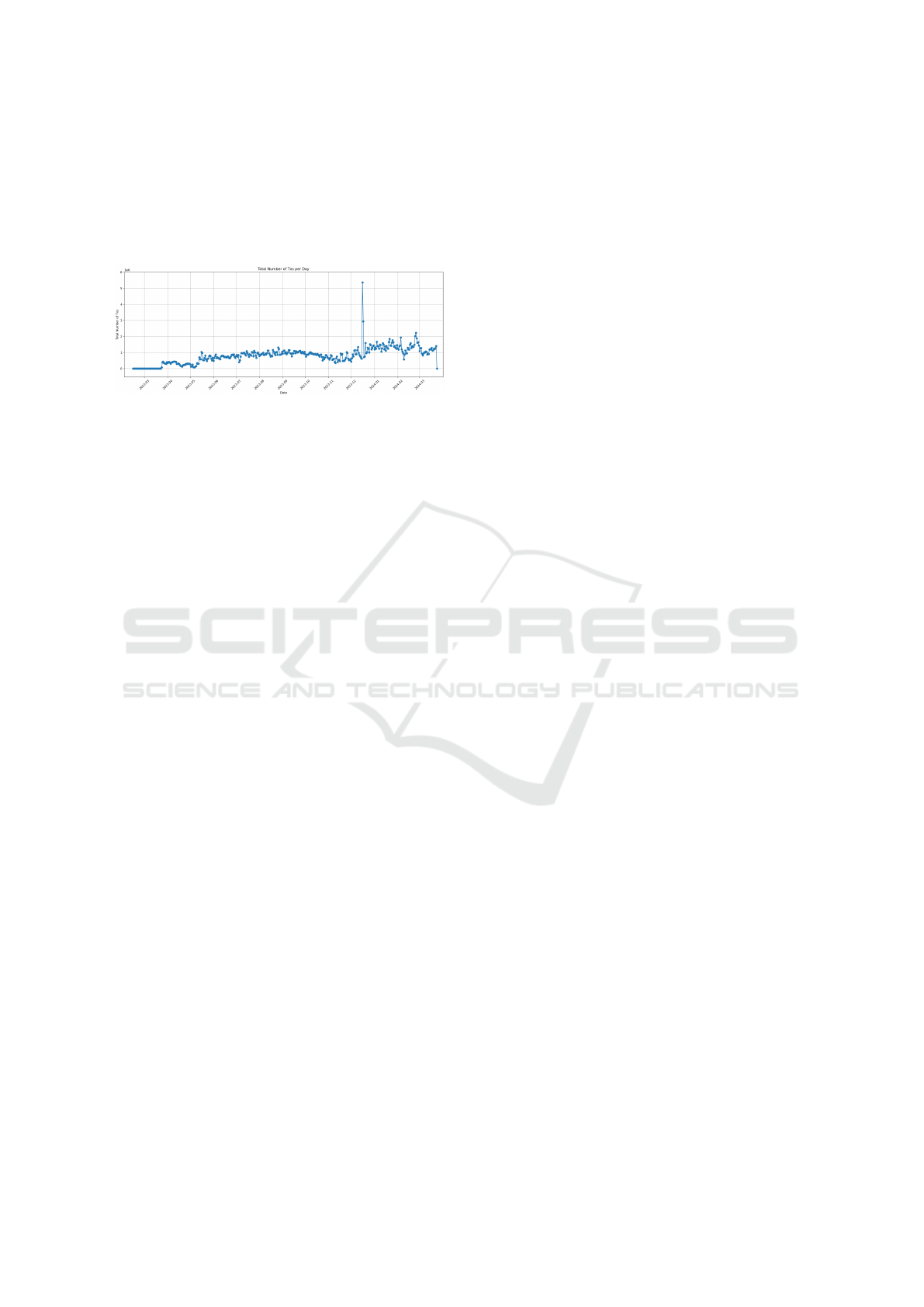
of 203 vectors for the training dataset. According to
(Liu et al., 2012) whether the training dataset contains
anomalies or not, it does not affect the performance
of Isolation Forest model. Since the OCSVM model
should learn mainly on normal data, the chosen data
period contains as many normal instances as possible.
Figure 2: Transaction count per day.
2.2 Chosen Algorithms
Data from ZkSync dump is unlabeled, meaning best
class methods are unsupervised machine learning
algorithms. The base for detecting anomalies is
One-Class Support Vector Machine introduced in
(Schölkopf et al., 2001). The goal of the method
is to maximize the margin between the hyperplane
and origin point, meaning there is only one nor-
mal class of vectors, hence the name of the algo-
rithm. One-Class Support Vector Machine, as stated
in (Rezapour, 2019), is great for analysis of imbal-
anced datasets such as blockchain transactions in this
paper. It is assumed that normal transactions make
up most of the dataset and outliers are only a small
fraction of it. Our choice strengthens the fact, that
OCSVM was also used in some other work presented
in section 1.2. For more details, refer to (Schölkopf
et al., 2001). Assuming that exact relationship be-
tween features is unknown, Radial Basis Function
Kernel has been chosen as a nonlinear kernel (Hof-
mann et al., 2008). We fine-tune two hyperparame-
ters: ν and γ.
The second unsupervised learning algorithm cho-
sen is called the Isolation Forest (Liu et al., 2008).
In contrast to OCSVM, it has linear complexity (Liu
et al., 2012). In this algorithm, there are many binary
trees, named Isolation Trees, created during the train-
ing phase. Three hyperparameters can be fine-tuned.
The number of trees t, indicates how many Isolation
Trees are to be constructed. Those trees form an Iso-
lation Forest, hence the name of algorithm. Hyperpa-
rameter b that specifies the contamination and can be
thought of as a proportion of how many anomalies are
possibly inside the dataset. ψ denotes the size of the
sub-sampling of the dataset.
2.3 Implementation of Data Processing
Chain
Algorithms explained in Section 2.2 have been placed
sequentially in the processing chain. OCSVM was
chosen as the algorithm to filter out most normal
vectors. Its boundary has been chosen to be rather
flat, so most general points are excluded from subse-
quent processing. The anomalies flagged by OCSVM
are then fed into the Isolation Forest prediction algo-
rithm to select the most prominent anomalies. Then
these results were analyzed. In the beginning of the
chain, basic dataset filtering and feature engineer-
ing happened. Features were encoded, if necessary,
and scaled. Hyperparameters were fine-tuned, based
on: total transactions from test dataframe labeled as
anomalies, number of anomalies detected in synthetic
dataframe and synthetic accuracy.
2.4 Feature Selection and
Normalization
2.4.1 Transaction-Level Detection Model
First, all sequential attributes must be excluded, as
they cannot be fitted to the OCSVM model. Most of
the new transactions in the training dataset would be
marked by a model as outliers, as they are not likely to
align with the training dataset. Attributes „from” and
„to” indicate unique blockchain addresses so they can
not be useful as a scaled feature and for that reason
they were rejected. There can be always a new ac-
count created, and thus a new address present in a test
set that is not in a training dataframe. However, once
an anomalous transaction has been found, outliers can
be mapped to addresses, which can form the basis for
a targeted investigation using different models. The
final selected features are: value converted to gwei,
size of input, gasUsed and type of transaction. Be-
cause type attribute is a categorical feature, which can
take one of 5 possible values: 0, 1, 2, 113 or 255, it
has been processed with One Hot Encoder. Thanks to
that, the distance of this feature for each vector is the
same, but at the expense of new dimensions added.
2.4.2 DDOS Detection Model
Numerous machine learning models have been inves-
tigated on cryptocurrency blockchains. In (Sayadi
et al., 2019), the Bitcoin network was studied and
since it is a proof of work blockchain, not every fea-
ture chosen by the authors is relatable to our case.
However, blockchain size, average block size, trans-
action volume, and total number of unique transac-
Anomaly Detection in ZkSync Transactions with Unsupervised Machine Learning
567

tions could potentially be considered in feature engi-
neering. In the total number of transactions, gasUsed
and size can be valuable (Park and Kim, 2023).
Therefore, for our detection model, an approach has
been chosen that a given vector represents a day in
the life of the network. For each day, the following
has been computed: total number of transactions, to-
tal gas used, total size of transactions input and ad-
dress uniquenes ratio.
Sudden increase in the number of transactions, gas
used, and volume of input can indicate DDOS attack.
The uniqueness ratio of the address was calculated
by dividing the number of unique addresses sending
transactions on a given day by the total number of
transactions. Smaller ratios may indicate that an at-
tack is being carried out.
2.4.3 Data Scaling
Features has been scaled. Data were first split into
training/testing to prevent leakage. After the split,
training data were fitted and scaled with Robust
Scaler. Next, the test dataset has been treated with
the same IQR and median. Robust Scaler has been
chosen because we have no information about com-
plex outliers in the dataframe. The scaling process is
defined as:
x
′
=
x − Me(X )
Q
3
− Q
1
(1)
where x ∈ X is a data vector, X is a training dataset,
Q3 and Q1 are third and first quantiles of X. Al-
though Isolation Forest does not require input data to
be scaled, such data was fed both to OCSVM and Iso-
lation Forest (Thakker and Buch, 2024).
3 RESULTS AND THEIR
ANALYSIS
3.1 Transaction-Level Detection
Best OCSVM hyperparameters γ = 0.0001 and ν =
0.1 were found and Isolation Forest best values were
ψ = 2048, b = 0.01 and t = 125. The Isolation Forest
model has been trained on the same data as OCSVM.
Three of the parameters setups gave an accuracy of
100%. It must be noted that it was measured on syn-
thetic dataset, where |X
synth
| = 100. Number of trans-
actions in real test dataset is 191698. OCSVM pre-
dicted 21238 vectors to be anomalies, what gives ap-
proximately 11.1% of whole dataset. It is a high per-
centage of overall population.
To visualize the learned boundary, high-
dimensional test vectors have been reduced to a
2-dimensional plane using the t-SNE algorithm. The
frontier is shown in figures 3 and 4.
Figure 3: Visualisation of OCSVM boundary, ν = 0.005
γ = 0.01.
Figure 4: Visualisation of OCSVM boundary, ν = 0.1 γ =
0.0001.
To further investigate the performance of
OCSVM, model was additionally trained on data
with most of the outliers removed as mentioned in
section 2.1. For γ = 0.0001 and ν = 0.1, model
naturally marked more transactions as anomalies
in the test dataset, 28533 in total, giving around
14.8% of the entire dataset. Isolation Forest predicted
2275 anomalies out of OCSVM’s output, which
gives about 1.2% of overall population. For dataset
with outliers removed, it predicted 3032 vectors as
anomalies, giving around 1,6%.
In both cases it can be seen that the theoretical
contamination and ν parameters transpose into real
findings; however, the OCSVM result on the cleaned
dataset is clearly higher than 10%. Isolation Forest
algorithm was also run with 4 different contamina-
tion values: b ∈ {0.01, 0.05, 0.1, 0.15}. By mapping
anomaly vector sets A
0.01
, A
0.05
, A
0.1
, A
0.15
to those
hyperparameters respectively, it can be seen that:
A
0.01
∩ A
0.05
∩ A
0.1
∩ A
0.15
= A
0.01
(2)
Some of the labeled anomalies were manually in-
vestigated for the sake of an example in this article.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
568

One transaction was found in the lower boundary of
the set of all attributes of OCSVM return. It had a
lower value of ETH transferred than the actual gas
fee paid and also the input data was not present, indi-
cating some unnatural behavior. Further exploration
showed that it was a self transaction and the account
associated with it produces repeatedly a lot of simi-
lar, dust transactions. Other transaction, was a very
high value transfer with more than 3024 ETH. After
investigation it was found out that addresses ’to’ and
’from’ are owned by a CEX. Some transactions had
an enormous input size of 106824, often accompa-
nied with a failed status.. Some deployed a contract
and had very large gas usage, such as over 20 million
units. One transaction was a simple, 1.181273 ETH
transfer with not much gas consumed and no input,
but the model labeled it as anomaly, meaning it is a
false positive.
3.2 DDOS Detection
Best values for OCSVM were ν = 0.05, γ = 0.001 for
DDOS detection task. For Isolation Forest the best
values were ψ = 64, b = 0.1 and t = 125. OCSVM
labeled 69 vectors out of 112 as anomalies. Consider-
ing that near the beginning of the chosen test period,
Boom of Inscriptions happened which led to sudden
increase of network use and fluctuated growth of fea-
ture values, big score of found anomalies could actu-
ally be expected. The Isolation Forest model, did not
change any of the OCSVM results, i.e. it gave same
69 labeled anomalies. On figure 5 it can be seen that
the last point has very low value, and that is because in
data dump, day 2024-03-24 contains one block only.
However, such point was kept to see if the model can
handle completely opposite feature values.
Isolation Forest contamination hyperparameter
was changed to see how much results differed, and
for b = 0.01, 47 vectors were labeled as anomalies.
For the sake of experiment, models have been also
switched, meaning the first model was Isolation For-
est and after it, the OCSVM. In this combination,
Isolation Forest labeled 96 vectors as anomalies and
OCSVM labeled 69. With contamination changed,
Isolation Forest labeled 53 from which OCSVM clas-
sified 47.
3.3 Evaluation
With not labeled data it is a challenge to evaluate cre-
ated model. Nevertheless, some concepts have been
proposed (Goix, 2016), (Škvára et al., 2023). We
tried to calculate some metrics based on a randomly
drawn sample. 100 vectors from the test dataframe
and 100 vectors from model result were randomly se-
lected without repetition. Then on such reduced set
of data, we manually reviewed and labeled vectors.
Then the precision was calculated. The accuracy of
90.0% has been achieved on transaction-level case.
Similar approach has been taken on DDOS detection
model, but in this case all testing vectors have been
labeled. Here an accuracy reached 79.3%. Such ac-
curacy is most likely due to the fact that there are few
samples available. A full summary of the precision
results, for different parameters, is shown in table 1.
Figure 5: Results for number of transactions feature.
Although model 4 and 5 from table 1 have same
accuracy, their prediction results were different. Mod-
els 5,6,7 had the same results. We calculated ROC
AUC and PR AUC for OCSVM and Isolation Forest
models separately, with parameters from table 1. Re-
sults have been put in table 2.
4 CONCLUSION AND FUTURE
WORK
Several OCSVM and Isolation Forest models have
been trained on the ZkSync dataset. For OCSVM
it can be seen that number of anomalies detected in
real dataframe forms over 10% of total transactions.
It makes sense as large values of ν correspond to a
larger soft margin of the model, which naturally re-
sults in bigger number of vectors lying outside of the
normal class. Fine-tuning this parameter is a very im-
portant task. Based on results for transaction-level
case, OCSVM can be considered as a tool for re-
stricting the set of transactions. Isolation Forest can
be used for decreasing false positive ratio in OCSVM
output. Best calculated accuracy is 90%, however it
must be noted that it is an approximation since it was
calculated on a sample of results. Clearing training
dataset of outliers gave worse accuracy. Model had
more false positives. A good idea would be to try dif-
ferent methods of outliers removal.
In DDOS detection case, the best accuracy
was 79.46%, which leaves room for improvement.
ROC AUC and PR AUC are good, however re-
sults for OCSVM are superior towards Isolation For-
Anomaly Detection in ZkSync Transactions with Unsupervised Machine Learning
569

Table 1: Accuracy of models.
Nr Model Parameters Accuracy
1 OCSVM → IForest Tx ν = 0.1, γ = 0.0001, b = 0.01, t = 125, ψ = 2048 90.00%
2 OCSVM → IForest Tx Cleared ν = 0.1, γ = 0.0001, b = 0.01, t = 125, ψ = 2048 79.51%
3 OCSVM → IForest DDOS ν = 0.05, γ = 0.001, b = 0.01, t = 125, ψ = 64 75.89%
4 OCSVM → IForest DDOS ν = 0.05, γ = 0.001, b = 0.01, t = 125, ψ = 128 79.46%
5 OCSVM → IForest DDOS ν = 0.05, γ = 0.001, b = 0.1, t = 125, ψ = 64 79.46%
6 OCSVM → IForest DDOS ν = 0.05, γ = 0.001, b = 0.1, t = 125, ψ = 128 79.46%
7 IForest → OCSVM DDOS ν = 0.05, γ = 0.001, b = 0.1, t = 125, ψ = 64 79.46%
Table 2: ROC AUC and PR AUC for DDOS detection mod-
els.
Model ROC AUC PR AUC
OCSVM model 4. and 5. 0.9848 0.9807
Isolation Forest model 3. 0.8096 0.7795
Isolation Forest model 4. 0.8547 0.8360
Isolation Forest model 5. 0.8096 0.7795
Isolation Forest model 6. 0.8547 0.8360
est. For best hyperparameters, Isolation Forest does
not change the output of OCSVM. In conclusion,
OCSVM could be a good predictor alone, without the
Isolation Forest model, it should be noted, however,
that if there had been many more vectors in the train-
ing and test datasets, the results might have been dif-
ferent.
ZkSync, with all system contracts and options of
interaction within the network, is not straightforward.
Transactions can be used for minting, complex swaps
or any other call to smart contract logic. Hence, ma-
chine learning methods here are not so easy to settle.
A fine idea would be to target the search for anoma-
lies to a specific case, such as dust attacks or detection
of ponzi contracts and money laundering schemes.
OCSVM model can be used as the filtering layer of
data that can later be fed to other algorithms. How-
ever, OCSVM is very complex and its use on large
datasets should be well thought out. Isolation Forest,
on the other hand, is extremely fast. In the future,
different machine learning algorithms might be ex-
plored in the detection of anomalies on ZkSync and
Ethereum blockchains. In addition, models could fo-
cus on smart contract analysis and decoded transac-
tion inputs.
REFERENCES
Apiecionek, Ł. and Karbowski, P. (2024). Fuzzy neural net-
work for detecting anomalies in blockchain transac-
tions. Electronics, 13(23):4646.
Goix, N. (2016). How to evaluate the quality of unsuper-
vised anomaly detection algorithms? arXiv preprint
arXiv:1607.01152.
Hofmann, T., Schölkopf, B., and Smola, A. J. (2008). Ker-
nel methods in machine learning. The Annals of Statis-
tics, 36(3).
Iglewicz, B. and Hoaglin, D. C. (1993). Volume 16: how to
detect and handle outliers. Quality Press.
Kannan, K. S., Manoj, K., and Arumugam, S. (2015). La-
beling methods for identifying outliers. International
Journal of Statistics and Systems, 10(2):231–238.
Liu, F. T., Ting, K. M., and Zhou, Z.-H. (2008). Isolation
forest. In 2008 Eighth IEEE International Conference
on Data Mining, pages 413–422.
Liu, F. T., Ting, K. M., and Zhou, Z.-H. (2012). Isolation-
based anomaly detection. ACM Transactions on
Knowledge Discovery from Data (TKDD), 6(1):1–39.
MatterLabs (2024). Zksync docs,
https://docs.zksync.io/zksync-protocol.
Messias, J., Gogol, K., Silva, M. I., and Livshits, B. (2024).
The writing is on the wall: Analyzing the boom
of inscriptions and its impact on evm-compatible
blockchains. arXiv preprint arXiv:2405.15288.
Park, Y. and Kim, Y. (2023). Visualization with prediction
scheme for early ddos detection in ethereum. Sensors,
23(24):9763.
Rezapour, M. (2019). Anomaly detection using unsuper-
vised methods: credit card fraud case study. Inter-
national Journal of Advanced Computer Science and
Applications, 10(11).
Sayadi, S., Rejeb, S. B., and Choukair, Z. (2019). Anomaly
detection model over blockchain electronic transac-
tions. In 2019 15th international wireless commu-
nications & mobile computing conference (IWCMC),
pages 895–900. IEEE.
Schölkopf, B., Platt, J., Shawe-Taylor, J., Smola, A., and
Williamson, R. (2001). Estimating support of a
high-dimensional distribution. Neural Computation,
13:1443–1471.
Silva, M. I., Messias, J., and Livshits, B. (2024). A
public dataset for the zksync rollup. arXiv preprint
arXiv:2407.18699.
Škvára, V., Pevn
`
y, T., and Šmídl, V. (2023). Is auc the best
measure for practical comparison of anomaly detec-
tors? arXiv preprint arXiv:2305.04754.
Thakker, Z. L. and Buch, S. H. (2024). Effect of feature
scaling pre-processing techniques on machine learn-
ing algorithms to predict particulate matter concentra-
tion for gandhinagar, gujarat, india.
SECRYPT 2025 - 22nd International Conference on Security and Cryptography
570
