
Effectiveness of Whisper’s Fine-Tuning for Domain-Specific Use Cases in
the Industry
Daniel Pawlowicz
1 a
, Jule Weber
2 b
and Claudia Dukino
3 c
1
University of Stuttgart IAT, Institute of Human Factors and Technology Management, Stuttgart, Germany
2
Eberhard Karls University T
¨
ubingen, T
¨
ubingen, Germany
3
Fraunhofer IAO, Fraunhofer Institute for Industrial Engineering IAO, Stuttgart, Germany
Keywords:
Whisper, Fine-Tuning, Domain, Speech-to-Text Transcription.
Abstract:
The integration of Speech-to-Text (STT) technology has the potential to enhance the efficiency of industrial
workflows. However, standard speech models demonstrate suboptimal performance in domain-specific use
cases. In order to gain user trust, it is essential to ensure accurate transcription, which can be achieved through
the fine-tuning of the model to the specific domain. OpenAI’s Whisper was selected as the initial model and
subsequently fine-tuned with domain-specific real-world recordings. The fine-tuned model outperforms the
initial model in terms of transcription of technical jargon, as evidenced by the results of the study. The fine-
tuned model achieved a validation loss of 1.75 and a Word Error Rate (WER) of 1. In addition to improving
accuracy, this approach addresses the challenges of noisy environments and speaker variability that are com-
mon in real-world industrial environments. The present study demonstrates the efficacy of fine-tuning the
Whisper model to new vocabulary with technical jargon, thereby underscoring the value of model adaptation
for domain-specific use cases.
1 INTRODUCTION
The integration of machine learning tools into mod-
ern business practices has revolutionized workflows
by enabling automation, improving efficiency, and
reducing administrative burdens. Digital assistants,
powered by advanced Speech-to-Text (STT) tran-
scription models, play a central role in these trans-
formations, allowing professionals to perform tasks
like scheduling, documentation, and customer rela-
tionship management (CRM) through intuitive voice-
based interactions (Drawehn and Pohl, 2023).
Although the umbrella term of digital assistant
systems is highly flexible (Pereira et al., 2023), the
essence of these systems lies in their ability to lever-
age natural language input for intuitive communica-
tion with human users (Budzinski et al., 2019). Mod-
ern digital assistants rely on voice input to provide
fast, hands-free communication, increasing efficiency
and usability in various professional contexts (Hoy,
2018). By automating routine tasks, such as tran-
a
https://orcid.org/0009-0004-3090-0787
b
https://orcid.org/0009-0004-6441-2263
c
https://orcid.org/0000-0003-2556-3881
scribing meeting notes or generating reports, digital
assistants enable professionals to focus on core activ-
ities like customer engagement or problem-solving,
enhancing productivity across industries (Fraunhofer
IAO, 2024).
At the heart of these functionalities lies precise
STT transcription, which converts spoken language
into text that digital assistants can process and in-
terpret. However, while state-of-the-art STT mod-
els perform well with everyday language, they of-
ten fall short in domain-specific contexts. Challenges
arise in accurately transcribing technical terminology,
proper nouns, and multilingual content, which are
common in specialized fields. This limitation hinders
the broader adoption of digital assistants in industries
where precise transcription is essential for process-
ing customer data, product information, or technical
terms.
The need for reliable transcription accuracy is par-
ticularly evident in industries with high levels of cus-
tomer interaction, where digital assistants can auto-
mate tasks like updating CRM systems. In addition,
they enable the creation of precise summaries from
voice data. These systems help reduce administrative
overhead by automating routine tasks, which mini-
1396
Pawlowicz, D., Weber, J. and Dukino, C.
Effectiveness of Whisper’s Fine-Tuning for Domain-Specific Use Cases in the Industry.
DOI: 10.5220/0013378100003890
In Proceedings of the 17th International Conference on Agents and Artificial Intelligence (ICAART 2025) - Volume 3, pages 1396-1403
ISBN: 978-989-758-737-5; ISSN: 2184-433X
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)

mizes the time employees spend on repetitive activi-
ties. As a result, employees can focus more on strate-
gic responsibilities, such as developing new business
initiatives and enhancing customer relationships. Ad-
ditionally, they have more time to engage in technical
responsibilities, which involves troubleshooting com-
plex issues and optimizing processes for greater effi-
ciency (Fraunhofer IAO, 2024).
This paper explores the establishment of a com-
prehensive procedure for optimizing STT for domain-
specific applications, which includes both fine-tuning
Whisper, a state-of-the-art STT model, and imple-
menting post-processing tailored to domain-specific
requirements. Whisper’s performance is evaluated in
an industrial setting, focusing on its ability to handle
complex technical terminology, multilingual content,
and noisy environments. By addressing the gap be-
tween general-purpose STT capabilities and domain-
specific requirements, this study contributes to the
broader adoption of digital assistants in specialized
fields.
2 METHODS
2.1 Model Selection
Based on an earlier evaluation, three models were
picked for an assessment of the state-of-the-art
STT performance in domain-specific transcription
tasks: DeepSpeech (Hannun et al., 2014), wav2vec
2.0 (Baevski et al., 2020), and Whisper large-v3
(Radford et al., 2022) (Pfeiffer, 2024). These models
were selected based on their established performance
in prior research and their suitability for multilingual
transcription, handling environmental noise, and
adapting to diverse accents.
The evaluation focused on three key criteria:
• Accuracy: The accuracy was measured as the
Word Error Rate (WER), which is the proportion
of words transcribed incorrectly compared to the
total number of words spoken. It includes sub-
stitutions, deletions, and insertions, calculated as
WER =
S+D+I
N
, where S, D, and I are the above
errors and N is the total number of words in the
reference transcript (Trabelsi et al., 2022; Favre
et al., 2013). The WER is popular and widely re-
ported in the literature (Bandi et al., 2023).
• Supported Languages: Non-English languages
are underrepresented in training datasets (Milde
and K
¨
ohn, 2018; Huang et al., 2023a), which
is why English models perform better (Bermuth
et al., 2021). For this, it is essential to choose
a model that performs well in German to ensure
good accuracy in use cases.
• Domain Adaptability: Adaptability refers to how
easily a STT system can be customized to meet
the specific needs of different domains. Cus-
tomization is particularly crucial for specialized
applications, where general models may not per-
form optimally. Even if a model meets general
performance criteria, it may still struggle when
applied to the specific requirements of a digital
assistant. Therefore, it is essential that the system
can be easily adapted and trained to handle the nu-
ances of the new domain.
For instance, proper nouns are highly depen-
dent on the specific use cases of Automatic
Speech Recognition (ASR) systems, highlight-
ing the need for domain-specific adaptation (Lee
et al., 2021). Additionally speech patterns, includ-
ing vocabulary, pronunciation, and tempo, change
with age (Fukuda et al., 2020). If a model is
trained predominantly on data from younger indi-
viduals, its accuracy may decline when used by
older speakers. This principle can be general-
ized across different social groups, as it is well-
established that speech varies according to factors
such as social class and age.
Whisper stood out for these criteria, especially for its
multilingual support and its popularity, which implies
extensive resources and high adaptability. In addition,
Whisper’s architecture, based on large-scale trans-
former models, is designed to handle different accents
and noisy environments, making it particularly suit-
able for real-world scenarios. Its ability to operate
effectively in both pre-trained and fine-tuned config-
urations provided the flexibility to address domain-
specific challenges while maintaining high baseline
performance. Although Whisper is the leader in this
area at the time of this writing, other models should
be considered in the future as this field of research
continues to evolve rapidly.
2.2 Whisper Model Evaluation
To assess the performance of the Whisper model in a
domain-specific use case, the Whisper large-v3 model
(Radford et al., 2022) was employed to transcribe a
collection of audio recordings from customer visits in
the mechanical engineering field. This assessment in-
cluded evaluating how Whisper coped with challeng-
ing aspects such as environmental noise, accents, and
technical terminology specific to the industrial sec-
tor. A sample of 21 recordings showed a mean WER
of 11% (min. = 0.59%, max. = 50%). The detailed
Effectiveness of Whisper’s Fine-Tuning for Domain-Specific Use Cases in the Industry
1397

evaluation revealed that, while the model transcribed
common words correctly, it showed some flaws.
1. The out-of-the-box Whisper model struggled
with the accurate transcription of proper nouns,
particularly customer and product names, which
are critical in industrial applications. For in-
stance, product names like ”HyperCut 1530”
were occasionally mistranscribed due to the
model’s lack of contextual knowledge about
domain-specific terminology. The accurate
transcription of proper nouns not only relies on
recognizing the correct word but also on under-
standing its specific spelling, which can vary
significantly between different terms. This was
further complicated by the fact that proper nouns
were pronounced differently by different speakers
in the recording, introducing room for error. This
issue extended to other technical terms, where the
absence of relevant training data in the default
Whisper model led to inconsistent and sometimes
nonsensical outputs. These limitations made
manual correction necessary, particularly when
the transcription involved critical customer or
product information.
2. The Whisper model is multilingual, yet it is ill-
equipped to handle bilingualism. While the ma-
jority of the recordings were in German, English
words occasionally emerged in professional set-
tings. This is particularly problematic for techni-
cal terms or proper nouns with English-like char-
acteristics. In such instances, the default Whis-
per model primarily transcribed in German, as this
was the language setting, resulting in errors such
as ”Focus,” a component of a product name, being
transcribed as ”Fokus.”
These issues highlight the importance of domain-
specific fine-tuning to enhance Whisper’s perfor-
mance for specialized tasks. While Whisper demon-
strated robust general-purpose transcription capabili-
ties, adapting the model to specific use cases is nec-
essary to ensure its reliability in professional environ-
ments. For instance, fine-tuning Whisper on domain-
relevant data can improve its ability to handle techni-
cal terms, multilingual contexts, and structured data
such as email addresses and product names.
This study aims to explore the effectiveness of
fine-tuning Whisper for such domain-specific appli-
cations. By adapting the model to the linguistic and
contextual nuances of a particular domain, the goal is
to bridge the gap between general-purpose STT per-
formance and the specific requirements of real-world
use cases.
2.3 Data Collection
The fine-tuning process utilized a dataset of real-
world audio recordings from field service employees
of a mechanical engineering company. These record-
ings were collected to reflect actual usage scenarios,
with content focusing on CRM notes, including prod-
uct names, customer details, and locations. A total of
73 recordings, ranging from 16 seconds to 1 minute
and 30 seconds in length, were gathered. To increase
variability, some texts were recorded multiple times
by different speakers, capturing accents, environmen-
tal noise (e.g., cars), and unclear pronunciations. The
recordings were primarily in German, with occasional
English words for technical terms and product names.
To enhance diversity and address gaps identified
during initial evaluations, 14 additional texts were
crafted and recorded by a female speaker. These sup-
plemental recordings simulated real CRM notes while
introducing domain-specific nuances, such as product
terminology. Additionally, the selection of topics for
the new texts was carefully made to ensure that they
cover relevant scenarios that frequently occur in real-
world applications. This not only improves the over-
all performance of the model but also helps in under-
standing and processing a broader range of user in-
quiries. This approach highlights the flexibility of the
fine-tuning process, which can be adapted to other do-
mains by tailoring datasets to their specific linguistic
challenges.
2.4 Data Annotation
The audio recordings were first transcribed using
Whisper’s out-of-the-box model. Then an automatic
post-processing dictionary was applied, using a rule-
based approach to correct common mistakes in the
original transcription. While this post-processing
dictionary worked well for common misspellings, it
was not robust enough to replace the fine-tuning of
Whisper. The mean WER was still at 3% after the
post-processing for the aforementioned 21 recordings
(min. = 0%, max. = 14%). However it worked well
to reduce manual annotation effort by reviewing the
original transcript and the corrections instead of tran-
scribing everything by hand.
Background noise, unclear speech, or heavily ac-
cented pronunciations were not explicitly annotated
or flagged. Instead, such segments were corrected
to the best of the annotator’s ability. When speak-
ers used unconventional terms or deliberately spelled
out words (e.g., “dot” for “.”), the transcription was
directly edited to reflect the appropriate punctuation
mark. However, this method relied heavily on the
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1398

assumption that the fine-tuned model would learn
to handle such patterns automatically in future iter-
ations. No special markings were used to indicate
noisy sections, which might have affected the model’s
learning in these cases.
The transcriptions and audio paths were formatted
into a JSON file as follows.
[
{
” a u d i o p a t h ” : ” p a t h \ t o \ a u d i o . m4a ” ,
” t r a n s c r i p t i o n ” : ” T h is i s t h e
c o r r e c t t r a n s c r i p t i o n of t h e
a u d i o ”
}
]
2.5 Training
The recordings, initially in .m4a format, were con-
verted to .wav with a sampling rate of 16 kHz to en-
sure compatibility with Whisper. Padding and trun-
cation ensured uniform input lengths, with shorter in-
puts padded and longer ones truncated. An attention
mask was used to differentiate meaningful data from
padding tokens, preventing unexpected behavior dur-
ing training as follows:
i n p u t s = s e l f . p r o c e s s o r ( a u d i o ,
s a m p l i n g r a t e = s r , r e t u r n t e n s o r s =”
p t ” , r e t u r n a t t e n t i o n m a s k = T r u e )
i n p u t f e a t u r e s = i n p u t s . i n p u t f e a t u r e s .
s q u e e z e ( )
# T o k e n i z e t h e t r a n s c r i p t i o n
l a b e l s = s e l f . p r o c e s s o r . t o k e n i z e r (
t r a n s c r i p t i o n , r e t u r n t e n s o r s =” p t ” ,
p a d d i n g = ” m a x l e n g t h ” , ma x l e n g t h
=4 4 8 ,
t r u n c a t i o n = Tru e ) . i n p u t i d s . s q u e e z e ( )
# Mark p a d d i n g t o k e n s t o i g n o r e l o s s
t h e r e
l a b e l s = t o r c h . whe re ( l a b e l s == s e l f .
p r o c e s s o r . t o k e n i z e r . p a d t o k e n i d ,
−100 , l a b e l s )
a t t e n t i o n m a s k = i n p u t s . a t t e n t i o n m a s k .
s q u e e z e ( )
The training loop consisted of forward and backward
passes to optimize model weights using the AdamW
optimizer. Key hyperparameters included:
• Batch size: Due to GPU memory limitations,
batch sizes of 1 and 5 were tested. As seen in
section 3 batch size 1 demonstrated better gener-
alization and was used for further analysis.
• Epochs: Training was conducted for five epochs,
as the validation loss stabilized after the fourth
epoch, preventing overfitting.
• Learning rate: The AdamW optimizer adapted the
learning rate. The starting learning rate was 5 ×
10
−5
.
To prevent overfitting, the dataset was split into
training (80%) and validation (20%) sets using
train test split from scikit-learn (Pedregosa et al.,
2011), ensuring that the model’s performance could
be monitored on unseen data. The model’s perfor-
mance was evaluated using the WER and the absolute
training and validation loss. This approach provided
a clear view of model improvements across epochs.
3 RESULTS
Comparing the results of models trained with batch
sizes of 1 and 5 revealed distinct differences in their
ability to generalize. For batch size 1, both training
and validation losses steadily decreased (Figure 1a),
with validation loss stabilizing after the third epoch.
This indicates effective learning and a reduced risk of
overfitting. In contrast, for batch size 5, while training
loss decreased, validation loss fluctuated, suggesting
difficulties in generalizing to unseen data (Figure 1b).
Similarly, WER trends (Figures 1c and 1d) show
a consistent improvement with batch size 1, whereas
batch size 5 exhibited fluctuations, particularly in
later epochs. These observations led to the decision
to focus on batch size 1 for further analysis, as it pro-
vided greater stability and better generalization de-
spite higher computational costs.
Training for five epochs was found to be optimal.
The loss graphs for batch size 1 showed continued re-
duction in training loss, but the stabilization of vali-
dation loss after the fourth epoch suggested that ad-
ditional epochs might lead to overfitting. The train-
ing loss decreased from approximately 2.46 to 0.44 by
the end of the fifth epoch, reflecting successful model
learning. Validation loss initially mirrored the train-
ing loss but began to stabilize and increase slightly
after epoch three, indicating potential overfitting if
training continued beyond the fifth epoch.
WER trends confirmed this pattern. After an ini-
tial increase in WER in the first two epochs, the metric
dropped significantly from epoch three onward, with
the lowest WER of around 2% achieved at epoch five
(Figure 1c). This demonstrates that the model pro-
gressively improved its transcription accuracy with
fine-tuning, particularly for domain-specific terms,
validating the choice of hyperparameters.
Fine-tuning the Whisper model addressed key
limitations observed in its out-of-the-box perfor-
mance, particularly with the transcription of proper
nouns and bilingual terms. These challenges, crit-
Effectiveness of Whisper’s Fine-Tuning for Domain-Specific Use Cases in the Industry
1399
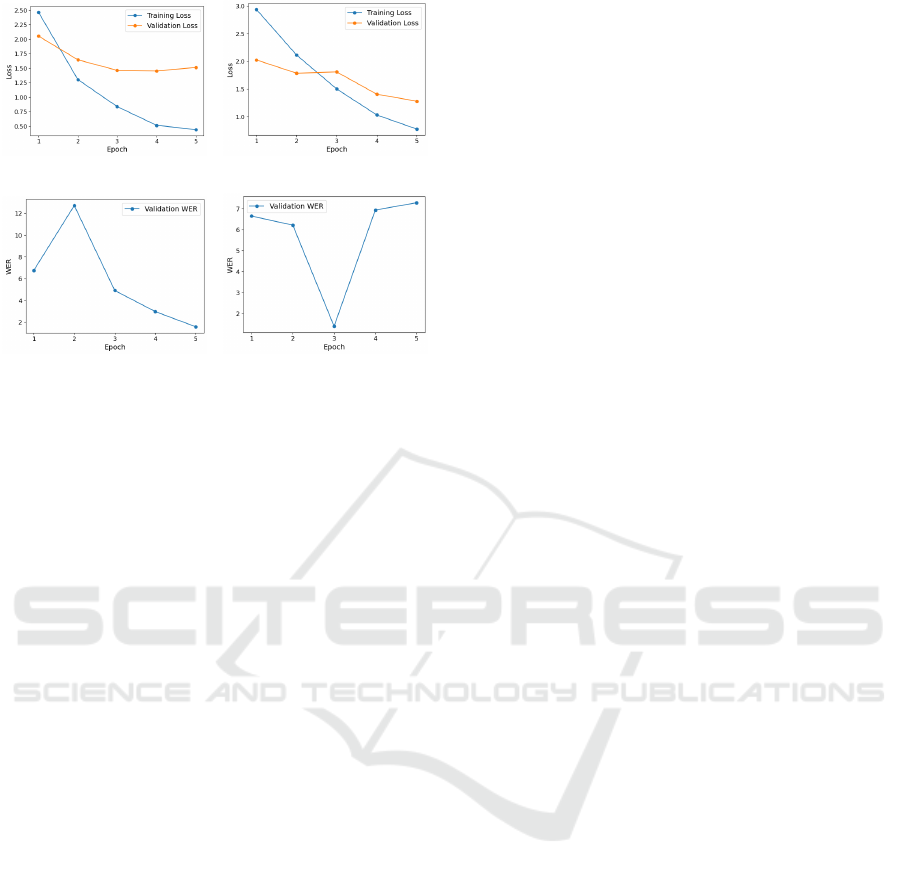
(a) Loss for batch size 1. (b) Loss for batch size 5.
(c) WER for batch size 1. (d) WER for batch size 5.
Figure 1: Comparison between batch size 1 and batch size
5.
ical in domain-specific applications, were mitigated
through the customization of Whisper to industrial
data.
The out-of-the-box Whisper model struggled with
the accurate transcription of proper nouns, including
customer and product names, often producing incon-
sistent or incorrect results due to variability in pronun-
ciation among speakers. This issue was compounded
by the lack of domain-specific contextual knowledge,
introducing further ambiguity.
After fine-tuning, the model showed significant
improvements in its ability to transcribe proper nouns
accurately, even when pronounced differently by vari-
ous speakers. The inclusion of domain-specific train-
ing data allowed the model to better recognize and
adapt to industrial terminology, reducing the need for
manual corrections. Even new proper nouns with sim-
ilar pattern such as product names were transcribed
correctly with the fine-tuned model, addressing one
of the primary flaws of the out-of-the-box model.
Fine-tuning on bilingual recordings improved the
model’s ability to handle mixed-language content.
While some challenges with English terms persisted,
likely cause by the pronunciation of some speak-
ers, the model became better equipped to distin-
guish between German and English terms within the
same transcription, correctly transcribing examples
like ”Focus” in product names. This adaptation mini-
mized errors in critical technical terminology, enhanc-
ing the usability of transcriptions in professional set-
tings.
3.1 Testing the Final Model
The fine-tuned model was tested on new audio exam-
ples to evaluate its performance in real-world scenar-
ios. Fine-tuning effectively addressed significant lim-
itations of the out-of-the-box Whisper model, partic-
ularly in the transcription of domain-specific terms,
technical jargon, and proper nouns. For example,
product names like ”HyperCut 1530” and customer
names spelled out in audio were consistently tran-
scribed correctly, even when pronounced differently
by various speakers. These improvements highlight
the model’s enhanced understanding of industrial ter-
minology and its ability to adapt to speaker variability.
However, certain issues persisted. While the tran-
scription of individual terms improved, the model ex-
hibited challenges in maintaining coherence in longer
sentences. Repetitive loops, such as repeating phrases
unnecessarily, were still observed in complex inputs,
indicating difficulty in capturing the semantic struc-
ture of extended discourse. Additionally, although
the fine-tuned model showed better handling of bilin-
gual content, occasional errors remained in cases
where English terms were embedded in predomi-
nantly German audio (e.g., ”Focus” being transcribed
as ”Fokus”).
Overall, the fine-tuning process significantly im-
proved the model’s ability to handle domain-specific
vocabulary and context, addressing many of the criti-
cal flaws in the out-of-the-box configuration. How-
ever, limitations in sentence-level coherence and
bilingual adaptability suggest room for further opti-
mization, particularly in handling longer and more
complex inputs.
4 DISCUSSION
4.1 Interpretation of Results
The STT transcription component was fine-tuned to
a specific domain, focusing on accurately transcrib-
ing technical terms, product names, and customer-
related information, to optimize the model for eco-
nomical use in specific branches. A detailed quali-
tative evaluation of the transcriptions reveals several
key strengths and areas of concern, providing valu-
able insights into the model’s capabilities and limi-
tations. The primary focus was on the accuracy of
domain-specific vocabulary, the handling of environ-
mental noise, and the system’s overall ability to cap-
ture the intent and structure of spoken content.
One notable issue encountered during the evalu-
ation of the fine-tuned model was the occurrence of
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1400

repeated phrases. At certain points during transcrip-
tion, the model would no longer produce coherent
transcriptions of the audio but instead repeat previous
or newly generated 2-3 word phrases until the tran-
scription was terminated. This repetitiveness problem
makes it challenging to quantitatively analyze and in-
terpret the results. Resolving this issue is crucial for
future work, as reliable and accurate transcription is
foundational for any downstream NLP tasks.
It is possible that this problem is due to the lim-
itations of Whisper, which is only designed to han-
dle 30 second recordings. This theory is supported
by the fact that the repetitive nature of the audio be-
gins after 30 seconds. Although Whisper has a built-
in parameter to overcome this, and the original model
could transcribe longer sequences, it seems that fine-
tuning the model conflicts with this setting. Future
work will need to be done to overcome this signifi-
cant challenge.
As the quantitative evaluation metrics like the
WER suffered from the above described problem,
they are not very meaningful to analyze the perfor-
mance of the model, independent of the repetitive
phrases. However it can be seen, that the fine-tuned
model achieves a lower WER of 2% compared to
the out-of-the-box Whisper model and the rule-based
post-processing approach.
A qualitative interpretation reveals a notable im-
provement in correctly transcribing complex techni-
cal terms and industry-specific jargon, which is cru-
cial in the context of field service reports. Terms such
as product-specific names were consistently tran-
scribed with high accuracy.
This level of precision is essential when docu-
menting technical discussions or generating reports,
as incorrect transcriptions could lead to misunder-
standings and potential delays in customer support.
A key challenge in transcribing documentation
is the accurate recognition of alphanumeric strings,
like serial numbers, email addresses or phone num-
bers, which are often pronounced differently by dif-
ferent speakers. The model generally performed well
in this regard, but occasional errors occurred when
speakers used abbreviations or non-standard pronun-
ciations. For example, variations in how certain prod-
uct names were articulated led to inconsistencies in
transcription, indicating a need for greater robustness
in handling phonetically similar but contextually dis-
tinct terms.
One of the most challenging aspects of real-world
audio is the presence of background noise, such as
conversations, machinery sounds, or traffic noise,
which can significantly impact transcription qual-
ity. The model exhibited a moderate level of noise
robustness, effectively filtering out low-level back-
ground disturbances in controlled settings. However,
in recordings with high levels of environmental noise
or overlapping speech, the model struggled, leading
to incomplete or inaccurate transcriptions. This lim-
itation is particularly relevant in the field service do-
main, where recordings are often made in noisy envi-
ronments such as workshops or cars.
The same results apply for speaker variation and
accents. While the model generally performed well
with native German speakers using a standard ac-
cent, it showed a decline in accuracy with regional
dialects or non-native speakers. This was highlighted
in the transcription of uncommon words or of English
phrases in a German context, where the pronuncia-
tion is highly critical for recognition. Since techni-
cal terms or product names often contained English
elements, this posed a problem for the model. This
points to a need for more diverse training data that
can better represent the full range of speaker varia-
tions encountered in the field.
Overall, while the STT model shows strong per-
formance in key areas, its practical utility in unstruc-
tured and noisy environments remains an open chal-
lenge. Addressing these limitations by diversifying
the training data would be a critical step in making
the digital assistant a more versatile tool for field ser-
vice professionals working in a variety of real-world
conditions.
4.2 Implications
The results presented in this paper demonstrate the
potential of leveraging fine-tuned machine learning
models to improve the functionality and usability of
digital assistant systems, specifically in the context
of specific domains, that are underrepresented in the
current training data for model training. The STT
component showed strong performance in capturing
and processing domain-specific language, technical
terms, and context-specific entities. The insights
gained through the qualitative analysis of the STT
model confirm that targeted adaptations of NLP mod-
els can significantly enhance digital assistants in spe-
cialized industry settings.
The primary goal of this work was to simplify
the interaction between users and the digital assistant
by enabling intuitive, speech-based communication,
thereby reducing administrative workload and allow-
ing employees to focus on technical problem solving
rather than laborious documentation tasks. The fine-
tuned model achieved this goal by reliably transcrib-
ing key technical terms. Despite some limitations in
handling environmental noise and non-standard pro-
Effectiveness of Whisper’s Fine-Tuning for Domain-Specific Use Cases in the Industry
1401

nunciations in the STT model, the system demon-
strated its ability to support technicians in real-world
scenarios by capturing essential details from their
spoken notes and structuring them into actionable
data, especially compared to the out-of-the-box Whis-
per model.
Another central objective of this project was to
create a system that would seamlessly integrate into
existing workflows without requiring extensive user
training or customization. To achieve this, the digital
assistant must be highly accurate, reliable, and able
to handle the wide variety of linguistic input encoun-
tered in day-to-day operations. This is in line with the
need to build trust between the system and its human
users. Trust is a key factor in the successful adoption
and long-term use of any digital assistant. A digi-
tal assistant that consistently performs well and deliv-
ers accurate results encourages employees to incorpo-
rate it into their daily routines. Conversely, negative
experiences–such as low accuracy, misinterpretation
of critical terms, or unexpected system behavior–can
undermine user trust and make integration difficult.
This work has achieved a promising step to this goal.
5 FUTURE STEPS
The immediate priority for future work should be to
fully realize the potential of the assistant and address
the problems identified in the STT model, particu-
larly the issue of repeated phrases at the end of tran-
scriptions. As highlighted in the discussion, this is
likely due to the incorrect handling of the receptive
field. Implementing the long-form algorithm in the
fine-tuning would be the first step towards solving this
problem.
In addition, improving the model’s handling of en-
vironmental noise and speaker variation should be a
high priority. To achieve this, more data augmenta-
tion techniques could be employed, such as adding
synthetic noise to training samples or using vocal
transformation methods to simulate different accents
and speech rates. These adjustments would help the
model to better generalize to the diverse conditions
encountered in real-world scenarios.
In the short term, solving the current problems
would make the transcription and therefore the dig-
ital assistant more reliable and user-friendly, encour-
aging adoption and reducing employee skepticism. In
the medium term, enhanced models with greater ro-
bustness and expanded entity coverage would provide
users with a tool capable of handling complex work-
flows, further reducing manual work and minimizing
data entry errors.
Further enhancements should also take into ac-
count the fact that the field of ASR is fast-moving
and progressive, and therefore domain-specific fine-
tuning may be better supported by other models in the
future.
In the long term, the development of a multimodal
digital assistant with advanced contextual understand-
ing would fundamentally change industrial workflows
in a variety of sectors. Such an assistant would act
as a true collaborator, capable of understanding nu-
anced technical discussions, providing real-time sup-
port, and integrating seamlessly into complex service
environments. This would not only optimize the ef-
ficiency of service processes, but also improve cus-
tomer satisfaction by enabling faster and more accu-
rate resolution of technical issues.
6 CONCLUSION
In summary, this work has demonstrated the effec-
tiveness of fine-tuning machine learning models for
domain-specific applications in digital assistant sys-
tems within the field service context.
The industrial setting was chosen because it is
underrepresented in the literature, where fine-tuning
of language models for medical or legal domains
is much more common (Yang et al., 2024; Huang
et al., 2023b). However, this paper serves as a proof
of concept of the efficacy and feasibility of fine-
tuning Whisper to any specific domain with real-
world recordings and use cases.
The STT component was successfully adapted to
capture complex technical terms and industry-specific
entities, providing a solid foundation for automating
and streamlining documentation processes. The qual-
itative evaluation highlighted the system’s strengths in
handling structured language, while also identifying
areas for further development to improve robustness
and usability.
REFERENCES
Baevski, A., Zhou, H., Mohamed, A., and Auli, M. (2020).
wav2vec 2.0: A Framework for Self-Supervised
Learning of Speech Representations. arXiv (Cornell
University).
Bandi, A., Adapa, P. V. S. R., and Kuchi, Y. E. V. P. K.
(2023). The Power of Generative AI: A Review of
Requirements, Models, Input–Output Formats, Evalu-
ation Metrics, and Challenges. Future Internet, 15(8).
Bermuth, D., Poeppel, A., and Reif, W. (2021). Scri-
bosermo: Fast Speech-to-Text models for German and
other Languages. arXiv (Cornell University).
ICAART 2025 - 17th International Conference on Agents and Artificial Intelligence
1402

Budzinski, O., Noskova, V., and Zhang, X. (2019). The
brave new world of digital personal assistants: ben-
efits and challenges from an economic perspective.
Netnomics, 20(2-3):177–194.
Drawehn, J. and Pohl, V. (2023). Einsatz von KI mit Fokus
Kundenkommunikation.
Favre, B., Cheung, K., Kazemian, S., Lee, A., Liu, Y.,
Munteanu, C., Nenkova, A., Ochei, D., Penn, G.,
Tratz, S., et al. (2013). Automatic human utility eval-
uation of ASR systems: Does WER really predict per-
formance? In INTERSPEECH, pages 3463–3467.
Fraunhofer IAO (2024). DafNe: Digitaler Außendienst-
Assistent f
¨
ur Nebenzeitoptimierung. Retrieved De-
cember 10, 2024.
Fukuda, M., Nishizaki, H., Iribe, Y., Nishimura, R., and
Kitaoka, N. (2020). Improving Speech Recognition
for the Elderly: A New Corpus of Elderly Japanese
Speech and Investigation of Acoustic Modeling for
Speech Recognition. In Calzolari, N., B
´
echet, F.,
Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi,
S., Isahara, H., Maegaard, B., Mariani, J., Mazo,
H., Moreno, A., Odijk, J., and Piperidis, S., editors,
Proceedings of the Twelfth Language Resources and
Evaluation Conference, pages 6578–6585, Marseille,
France. European Language Resources Association.
Hannun, A. Y., Case, C., Casper, J., Catanzaro, B., Diamos,
G., Elsen, E., Prenger, R., Satheesh, S., Sengupta, S.,
Coates, A., and Ng, A. Y. (2014). Deep Speech: Scal-
ing up end-to-end speech recognition. arXiv (Cornell
University).
Hoy, M. B. (2018). Alexa, Siri, Cortana, and More: An
Introduction to Voice Assistants. Medical Reference
Services Quarterly, 37(1):81–88.
Huang, H., Tang, T., Zhang, D., Zhao, X., Song, T., Xia, Y.,
and Wei, F. (2023a). Not All Languages Are Created
Equal in LLMs: Improving Multilingual Capability
by Cross-Lingual-Thought Prompting. In Bouamor,
H., Pino, J., and Bali, K., editors, Findings of the Asso-
ciation for Computational Linguistics: EMNLP 2023,
pages 12365–12394, Singapore. Association for Com-
putational Linguistics.
Huang, Q., Tao, M., Zhang, C., An, Z., Jiang, C., Chen, Z.,
Wu, Z., and Feng, Y. (2023b). Lawyer llama technical
report.
Lee, T., Lee, M.-J., Kang, T. G., Jung, S., Kwon, M.,
Hong, Y., Lee, J., Woo, K.-G., Kim, H.-G., Jeong,
J., Lee, J., Lee, H., and Choi, Y. S. (2021). Adapt-
able Multi-Domain Language Model for Transformer
ASR. In ICASSP 2021 - 2021 IEEE International
Conference on Acoustics, Speech and Signal Process-
ing (ICASSP), pages 7358–7362.
Milde, B. and K
¨
ohn, A. (2018). Open source automatic
speech recognition for german.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V.,
Thirion, B., Grisel, O., Blondel, M., Prettenhofer,
P., Weiss, R., Dubourg, V., Vanderplas, J., Passos,
A., Cournapeau, D., Brucher, M., Perrot, M., and
Duchesnay, E. (2011). Scikit-learn: Machine learning
in Python. Journal of Machine Learning Research,
12:2825–2830.
Pereira, R., Lima, C., Pinto, T., and Reis, A. (2023). Vir-
tual Assistants in Industry 4.0: A Systematic Litera-
ture Review. Electronics, 12(19).
Pfeiffer, M. (2024). Comparison of existing technologies
and models for the design of an AI-supported digital
assistance system.
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey,
C., and Sutskever, I. (2022). Robust Speech Recogni-
tion via Large-Scale Weak Supervision.
Trabelsi, A., Warichet, S., Aajaoun, Y., and Soussilane, S.
(2022). Evaluation of the efficiency of state-of-the-art
Speech Recognition engines. Procedia Computer Sci-
ence, 207:2242–2252. Knowledge-Based and Intel-
ligent Information & Engineering Systems: Proceed-
ings of the 26th International Conference KES2022.
Yang, Q., Wang, R., Chen, J., Su, R., and Tan, T. (2024).
Fine-tuning medical language models for enhanced
long-contextual understanding and domain expertise.
Effectiveness of Whisper’s Fine-Tuning for Domain-Specific Use Cases in the Industry
1403
