
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative
Perception
Ahmed N. Ahmed
a
, Siegfried Mercelis
b
and Ali Anwar
c
Imec Research Group, IDLab, Faculty of Applied Engineering, University of Antwerp, 2000 Antwerp, Belgium
{ahmed.ahmed, siegfried.mercelis, ali.anwar}@uantwerpen.be
Keywords:
Collaborative Perception, Autonomous Driving, Attention, Graphs, Object Detection.
Abstract:
Multi-agent collaborative perception has gained significant attention due to its ability to overcome the chal-
lenges stemming from the limited line-of-sight visibility of individual agents that raised safety concerns for
autonomous navigation. This paper introduces GIFF, a graph-based iterative attention collaborative percep-
tion framework designed to improve situational awareness among multi-agent systems, including vehicles and
roadside units. GIFF enhances autonomous driving perception by fusing perceptual data shared among neigh-
boring agents, allowing agents to “see” through occlusions, detect distant objects, and increase resilience to
sensor noise and failures, at low computational cost. To achieve this, we propose a novel framework that
integrates both channel and spatial attention mechanisms, learned iteratively and in parallel. We evaluate our
approach on object detection task using the V2X-Sim and OPV2V datasets by conducting extensive experi-
ments. GIFF has demonstrated effectiveness compared to state-of-the-art methods and has proved to achieve
notable improvements in average precision and the number of model parameters.
1 INTRODUCTION
Situational awareness is an important topic in the field
of autonomous driving. Autonomous vehicles (AV)
mainly rely on onboard sensors to perceive their sur-
rounding environment. However, as shown in Fig. 1,
the onboard sensors deployed on the AV are limited
by the sensor’s field of view, and horizontal range,
due to that the perception system becomes suscepti-
ble to many challenges such as occlusion and long-
distance perception sparsity, which hinder the situa-
tional awareness ability of the AV. While deep learn-
ing has improved the perception stacks with data-
driven techniques (Qian et al., 2022), the percep-
tion module in AV to date is still brittle, especially
in the face of extreme situations and corner cases
that can lead to catastrophic scenarios. In recent
years, there has been an increasing amount of re-
search focused on collaborative perception enabling
the vehicle to communicate with neighboring AVs
and roadside units to achieve Vehicle-to-Everything
(V2X) (Ahmed et al., 2024a; Ahmed et al., 2024b;
Li et al., 2021; Wang et al., 2020) significantly im-
proving the situational awareness abilities, a simpli-
a
https://orcid.org/0000-0002-7192-699X
b
https://orcid.org/0000-0001-9355-6566
c
https://orcid.org/0000-0002-5523-0634
fied illustration is shown in Fig. 1. With the ad-
vent of telecommunication technology developments,
collaborative perception (Han et al., 2023) is becom-
ing a promising paradigm that enables sensor infor-
mation to be shared between neighboring agents (for
simplicity, we refer to vehicles and roadside units as
agents) in real time. The collaborative perception
module operates by intelligently aggregating visual
data from multiple relevant agents within the commu-
nication range to enhance visual reasoning and detec-
tion precision as shown in Fig. 1. In practice, the effi-
cacy of collaborative perception hinges on what data
to transmit within the limited network bandwidth and
how to aggregate the information received from other
agents to build a coherent situational awareness of the
surroundings. Due to the topological nature of this
problem, in this work, we propose a graph iterative
attention-based network to aggregate the ego agent’s
local observations with those of neighboring agents.
By utilizing both the attention mechanism to attend
only to the relevant region of the information provided
by the neighboring agents and message-passing func-
tionality within the graph networks, our methodology
yields in enhanced situational awareness.
On the one hand, various types of graph neural
networks have been proposed (Zhou et al., 2020; Wu
et al., 2020), and have proved to be effective for fea-
820
Ahmed, A. N., Mercelis, S. and Anwar, A.
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative Perception.
DOI: 10.5220/0013297900003912
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 20th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2025) - Volume 2: VISAPP, pages
820-829
ISBN: 978-989-758-728-3; ISSN: 2184-4321
Proceedings Copyright © 2025 by SCITEPRESS – Science and Technology Publications, Lda.

Figure 1: Illustration of single-agent perception challenges.
From the perspective of the ego vehicle (A), vehicle (B) is
occluded by the yellow vehicle. Likewise, Vehicle (C) is
around the corner lying outside the perception range of Ve-
hicle (A). These typical road scenarios cause dangerous col-
lision risks. If vehicles are given the ability to inform each
other “what they can see” achieving collaborative percep-
tion those collisions will be avoided.
ture aggregation (Ahmed et al., 2021). We chose
GATs (Veli
ˇ
ckovi
´
c et al., 2017) to be our core aggrega-
tion method, as it exploits the underlying graph struc-
ture of the multi-agent collaborative perception data
aggregation problem by utilizing the message pass-
ing among nodes and attention in the graph. The
node features are updated by aggregating node fea-
tures from the neighbors. Addressing the collabo-
rative perception problem through a graph-based ap-
proach allows for the embedding of both ego and re-
ceived feature maps as graph nodes. This method
enables the model to learn edge weights and atten-
tion coefficients, which adaptively weigh nodes and
their associated features based on inter-node correla-
tions. On the other hand, the benefit of incorporat-
ing attention within our proposed feature aggregation
scheme is that attention enhances the representation
power by directing the model’s to focus on the signif-
icant regions within the fused semantic information
and suppressing unnecessary ones. In this work, we
utilize channel and spatial attention modules to attend
to both local and global contexts. We also introduce
an iterative attention fusion approach to further refine
the feature fusion process, further improving the qual-
ity of the final fused feature. The contributions of this
work can be summarized as follows:
• Our method proposes a novel methodology for
aggregation of informative features on channel-
spatial dimensions and incorporating it within
the GATs method which simultaneously aggre-
gates complementary information from connected
nodes
• Our proposed attention learning network is de-
signed so that channel and spatial attention are
learned separately, allowing the model to analyze
spatial and channel information without the bias
introduced by the correlations between channel
and spatial features.
• We propose an iterative attention learning strategy
that gradually builds up a richer, more nuanced
understanding of the fused features progressively
down-weighting less relevant information and fo-
cusing on the most significant elements. This fur-
ther improves the model performance with a sub-
stantial increase in the model’s learnable parame-
ters
• We validate our work using a large open dataset
V2XSim (Li et al., 2022) which includes LiDAR
data retrieved from both vehicles and roadside
units. We also perform an extensive ablation study
to investigate the performance gain of our pro-
posed design choices.
The rest of this paper is organized as follows. Sec-
tion. 2 introduces the related work published in recent
years. Section 3 describes our proposed method in de-
tail. The experimental results are given in section. 4
and 5, then we perform an ablation study in section. 6
we conclude the paper in section. 7.
2 RELATED WORKS
Graphs have been extensively applied in collaborative
perception due to their capability to propagate and
aggregate information across neighboring nodes, ef-
fectively updating each node’s feature representation.
The importance of attention mechanisms in enhanc-
ing computer vision tasks has also been well estab-
lished in prior literature (Guo et al., 2022). Conse-
quently, numerous studies have explored combining
graphs with attention mechanisms to improve infor-
mation aggregation among collaborating agents. The
authors in (Zhou et al., 2022) implemented GNN
in multi-robot systems by modeling each robot as
a graph node and leveraging message-passing com-
bined with cross-attention encoding to enable infor-
mation sharing and fusion within the team. In the do-
main of AVs, V2VNet (Wang et al., 2020) employed
GNNs to aggregate shared neural features for joint de-
tection and prediction; however, this approach used a
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative Perception
821

convolutional gated recurrent unit for message aggre-
gation, which significantly increased model parame-
ters. DiscoNet (Li et al., 2021) introduced a teacher-
student framework that applied a matrix-valued edge
weight within the graph to learn node interactions.
V2X-ViT (Xu et al., 2022a) examined the use of at-
tention alone by utilizing a vision transformer with
window attention for V2X collaboration, though it re-
quires the transmission of full feature maps, increas-
ing bandwidth usage. In addition, Where2comm (Hu
et al., 2022) utilized attention on ego and received fea-
ture maps to assess correlations among agents. De-
spite its advantages, Where2comm lacks flexibility in
allowing ego agents to adjust their perceptual focus
based on immediate environmental conditions, poten-
tially reducing effectiveness in limited communica-
tion scenarios. CollabGAT (Ahmed et al., 2024a) in-
corporated spatial and channel attention in a sequen-
tial setup, following the CBAM (Woo et al., 2018)
model; however, this approach may not fully capture
complex interdependencies between channel and spa-
tial features. Alternatively, the authors in (Ahmed
et al., 2024b) integrated spatial and channel attention
in a parallel arrangement within their collaborative
graph, differing from the sequential arrangement in
CollabGAT (Ahmed et al., 2024a). In contrast, our
proposed method proposes a graph-iterative attention-
based method that incorporates both channel and spa-
tial attention in an iterative manner that learns inter-
dependent patterns in both dimensions parallelly.
3 METHODOLOGY
3.1 Overview
The goal of our proposed method is to aggregate in-
formation received from other agents to help enhance
the ego agent’s situational awareness. In our pro-
posed collaborative perception scheme, we assume
that the environment consists of N agents equipped
with LiDARs, and their point cloud observations X =
{X
i
, X
j
, .., X
N
}. In principle, agents can transmit all
their retrieved raw point cloud data to the ego agent
to aggregate them. However, in practice, we have
to consider the network bandwidth limit, as sharing
the raw point cloud data among neighboring agents
can overload the network, causing huge transmission
delays. Thus, we derive a distributed and efficient
information-fusing framework that is able to: (i) max-
imize the object detection accuracy, for the ego agent
and (ii) minimize the size of the shared data to prevent
bandwidth overloading. The overview of our method-
ology is presented in Fig. 2.
In that regard, the raw point cloud of each agent
X
N
is processed using a unified feature extractor
(section. 3.2) into compact semantic representation,
named feature map F
N
to be transmitted through the
V2X channels in real-time. Subsequently, these fea-
tures are fed into a compression block, further com-
pressing this feature map to further reduce its size to
prepare for transmission(section. 3.3). Afterward, us-
ing the compressed feature map and the pose of the
broadcasting agent we create a collaborative percep-
tion message (CPM) to be broadcast to neighboring
agents. The ego (receiving) agent decompresses the
CPM and passes it to the collaborator selection mod-
ule (section. 3.4) which selects only relevant agents
based on pre-defined metrics (section. 3.4). Even-
tually, the feature map of the selected agents trans-
formed to the ego agent perspective (section. 3.4).
The ego agent and the transformed features are then
fed into the feature fusion network to iteratively ag-
gregate all the received feature maps taking into ac-
count the relevancy of the neighboring agents to the
ego agent (section. 3.5). The fused features are then
forwarded to the decoder network (section 3.6) to
generate predictions on the final outputs in object de-
tection.
3.2 Feature Extractor
To alleviate communication overhead, each agent in-
dependently processes its own LiDAR data, encoding
raw point clouds into semantic information, as illus-
trated in Fig. 2. Specifically, each agent transforms
its collected point cloud data, X , into a bird’s-eye-
view (BEV) representation, flattened along the height
dimension. This BEV representation is then inputted
into a feature extractor, denoted by Θ(·), to produce a
feature map, F
i
= Θ(BEV
i
), where F
i
∈ R
W ×H×C
, with
W , H, and C representing the width, height, and chan-
nel dimensions of the feature map, respectively. Our
approach assumes homogeneous intermediate collab-
orative perception; thus, all agents utilize the same
feature extractor architecture, sharing the same Θ(·).
The primary objective of this work is to improve the
effectiveness of the feature map fusion strategy and to
evaluate our proposed aggregation approach against
state-of-the-art models. To achieve this, we bench-
mark our intermediate feature aggregation methods
by employing the feature extractors from DicoNet (Li
et al., 2021) and V2VNet (Wang et al., 2020); en-
abling an independent analysis of the proposed fusion
strategies across different feature extractor architec-
tures. Further details of this analysis are provided in
Section 6.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
822

3.3 Compression and Sharing
To minimize transmission bandwidth, each agent
compresses its feature map before communication.
We employ the variational compression algorithm de-
scribed in (Ball
´
e et al., 2018) for this purpose, a CNN
is trained to compress the feature map, in a way that
supports end-to-end optimization. This approach al-
lows the system to preserve essential feature map in-
formation while minimizing bandwidth usage. Each
agent transmits a compressed form of its intermediate
semantic information, denoted as F
N
, along with its
pose ζ
N
, in what we refer to as the collaborative per-
ception message (CPM). This CPM is shared among
all neighboring agents. Upon receiving a CPM, de-
compresses it for further processing, enabling it to se-
lect relevant collaborators and transform their feature
maps to align with its own perspective.
3.4 Collaborator Selection and Spatial
Transformation
It is important to note that not all neighboring agents
contribute positively to enhancing the ego agent’s sit-
uational awareness. In some cases, the semantic in-
formation provided by neighboring agents may de-
grade perception performance due to irrelevant view-
points (Liu et al., 2020b). Therefore, agent i employs
the collaborator selector function which selects only
the agents positioned within a 70-meter radius and
exhibiting a heading intersection of 70 degrees rel-
ative to the ego agent. This relevancy metric range
is based on existing dedicated short-range communi-
cations (DSRC) standards (Kenney, 2011), and was
adopted by multiple collaborative perception meth-
ods (Ahmed et al., 2022; Ahmed et al., 2024a; Wang
et al., 2020). In this work, we assume ideal commu-
nication between agents, where agents consistently
transmit and receive the CPMs of their neighbors at
each timestep. Since each selected collaborator per-
ceives the environment from different viewpoints and
perspectives, its semantic information needs to be
transformed to the ego agent’s perspective. The ego
agent transforms each neighboring agent’s semantic
information to its perspective using the ego and the
selected agents pose ζ
i
, ζ
j
, respectively. The trans-
formed feature of the j-th agent to the ego agent i
is represented as F
j→i
= Γ
j→i
((F
i
, ζ
i
), (F
j
, ζ
i
)), where
Γ
j→i
represents the affine transformation. We utilize
the affine transformation due to its ability to preserve
parallel lines and distance during rotations. The affine
transformation adopted in this work is closely aligned
with the method proposed in (Jaderberg et al., 2015),
with the key distinction being the absence of a lo-
calization network, as each agent broadcasts its pose.
The ego agent repeats this affine transformation pro-
cess for all selected collaborators.
3.5 Graph Fusion Network
Since selected collaborators possess different loca-
tions, and viewpoints of the surroundings their se-
mantic information therefore to account for their dis-
tinct characteristics, the significance of each agent to
the ego agents must be distinguished, and the inter-
actions between multiple agents should vary. To cap-
ture this heterogeneity, we present a novel graph it-
erative attention, employing both spatial and chan-
nel attention parallel iteratively to appropriately en-
hance the feature aggregation. The graph attention-
based aggregation scheme proposed indicates i)the
collaborator’s importance relative to the ego agent,
and ii)emphasizing the significant regions within the
collaborator’s feature map further strengthening the
cross-agent feature aggregation.
Graph Network Structure. As shown in Fig. 2, we
consider each agent’s feature map as a node in the
graph, and the edge weights represent the significance
of those nodes to each other. Intuitively, we repre-
sent the graph as G = (V, E), where V is the set of
nodes incorporating the semantic information of each
agent V = {F
i
, F
j→i
. . . F
N→i
}, and E is a set of edges
connecting the nodes, where E = {W
ii
, W
i j
, W
iN
} rep-
resent the importance between selected collaborator
and the ego agent determining their significance to
each other. In addition to the edge weights W
iN
, we
incorporate an efficient multi-scale attention learn-
ing scheme that learns two different attention maps
a) spatial attention (α
sp
) and b) channel attention
(α
ch
) (as shown in Fig. 3). Different from the edge
weights that reflect the significance of the nodes to
each other, attention directs the models to attend only
to significant regions within the feature maps of the
selected collaborator relative to the ego agent. Incor-
porating channel-spatial attention encodes both local
and global interactions between connected nodes to
better capture the ambiguity in the semantic feature
space. Local attention can help preserve object de-
tails, while global attention can provide a better un-
derstanding of environmental contexts. To this end,
we present a graph-structured attention-based fusion
process where each agent establishes its own graph,
the nodes in the graph maintain the semantic infor-
mation of the selected collaborators, and the ego node
state is updated based on the feature fusion process
driver by the edge weights as well the attention maps.
Attention Fusion Module. The attention module in-
cludes the parallelly learned channel and spatial at-
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative Perception
823
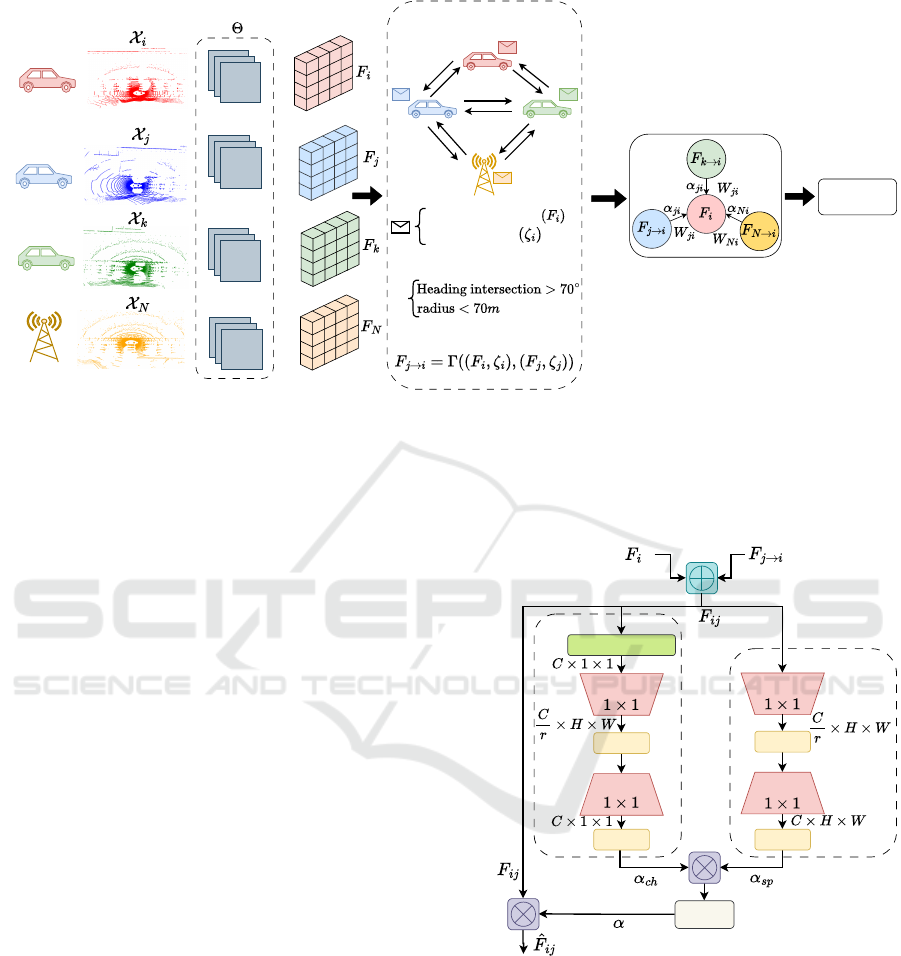
Shared Feature
Extractor
Message sharing
CPM
Semantic
Information
Graph Feature Fusion
Collaborator
Collaborator
Ego Agent
Collaborator
Decoder
Network
Collaborator Selection
Spatial Transformation
Semantic Information
Pose Information
Figure 2: The overall architecture of GIFF. Each agent converts its perceived point cloud X
i
into BEV image. The shared
feature extractor Θ processes the BEV image to obtain the feature map. Subsequently, each agent shares its CPM to initiate
the collaborative selection process. The feature maps corresponding to the relevant agents are then transformed into the ego
agent’s coordinate system. Subsequently, the features are passed to the graph fusion network to aggregate the collaborator’s
feature maps with the ego feature map to produce an updated feature representation. The updated representation is then fed
to the decoder network to perform object detection.
tention maps as illustrated in Fig. 3. In this manner,
the features obtained after applying the attention maps
are aggregated to combine both the low and high-
level features and effectively direct the attention to the
most significant regions within the feature map. In-
cluding both channel and spatial attention boosts our
proposed fusion strategy to handle objects of varying
sizes within the feature maps and aggregate informa-
tion from multiple receptive fields. Instead of relying
solely on global channel attention, which favors large
objects, our method incorporates local channel con-
texts to highlight small objects as well. This allows
the network to adaptively adjust its focus based on the
scale of the objects present in the image. Addition-
ally, the parallel sub-networks block helps effectively
capture the cross-dimension interaction and establish
the inter-dimensional dependencies independently. It
also allows the information flow within the network
by learning which information to emphasize or sup-
press.
F
i j
= AGG(F
i
, F
j→i
) (1)
where AGG is the aggregation operation of the F
i
and F
j→i
, which is computed as summation F
j→i
∈
R
C×H×W
or concatenation F
j→i
∈ R
2C×H×W
this will
be further discussed in section. 6.
• Channel Attention. AS shown in Fig. 3(a),
to compute the channel attention map α
ch
, we
squeeze the spatial dimension of the aggregated
feature F
i j
by applying global average pooling
GlobalAvgPooling
ReLU
PWConv
ReLU
Sigmoid
ReLU
PWConv
ReLU
BN
BN
PWConv
PWConv
BN
BN
(a)
(b)
Figure 3: Illustration of the attention map learning scheme
within GIFF. Part (a) depicts the channel attention map
branch, while part (b) represents the spatial attention map.
The parameter r denotes the channel reduction ratio within
the encoder-decoder framework.
(GAP) to model only the cross-channel informa-
tion. GAP generates a compact feature represen-
tation F
ch
i j
of shape R
C×1×1
by averaging the spa-
tial dimension within each channel of F
i j
. This
reduces the 2D spatial dimension H × W into a
single value per channel i.e. C × 1 × 1. This
distills the most important information from the
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
824
entire spatial dimension of F
i j
into a more com-
pact form as illustrated in Fig. 3. F
ch
i j
is then
used to learn the per-channel attention map that
reflects how important each channel is for the ob-
ject detection task. To learn the attention map, and
maintain a lightweight model, F
ch
i j
is passed to an
encoder-decoder point-wise convolution network
(PwConv) (1 × 1) which local channel context ag-
gregator exploiting only channel interactions. The
channel attention map α
ch
is learned as follows:
F
ch
i j
= GAP(F
i j
) (2a)
α
ch
= Ψ(ϒ(F
ch
i j
)) (2b)
Ψ and ϒ are the decoding-encoding PwConv-
based network used to learn the channel attention
map.
• Spatial Attention. In parallel, we generate a spa-
tial attention map by utilizing the spatial relation-
ship of features as shown in Fig. 3(b). Different
from channel attention, spatial attention focuses
on where within the spatial dimension are the in-
formative parts of the aggregated feature F
i j
, and
increases their weight within the attention map.
On F
i j
, we apply encoder-decoder PwConv lay-
ers to generate the spatial attention map α
sp
. The
spatial attention process is expressed as follows:
α
sp
= Ω(Λ(F
i j
)) (3)
where Ω and Λ are the decoding-encoding
PwConv-based network tailored to learn the spa-
tial attention map.
Following the computation of the channel and
spatial attention maps, these maps are combined
to form the final feature map, denoted as α, in
order to exploit the learned representations. The
feature map α is subsequently utilized to update
the aggregated feature map F
i j
, resulting in the re-
fined feature map F
(l)
i j
, as expressed by:
α = σ(α
ch
⊕ α
sp
) (4)
ˆ
F
i j
= α ⊗ F
i j
(5)
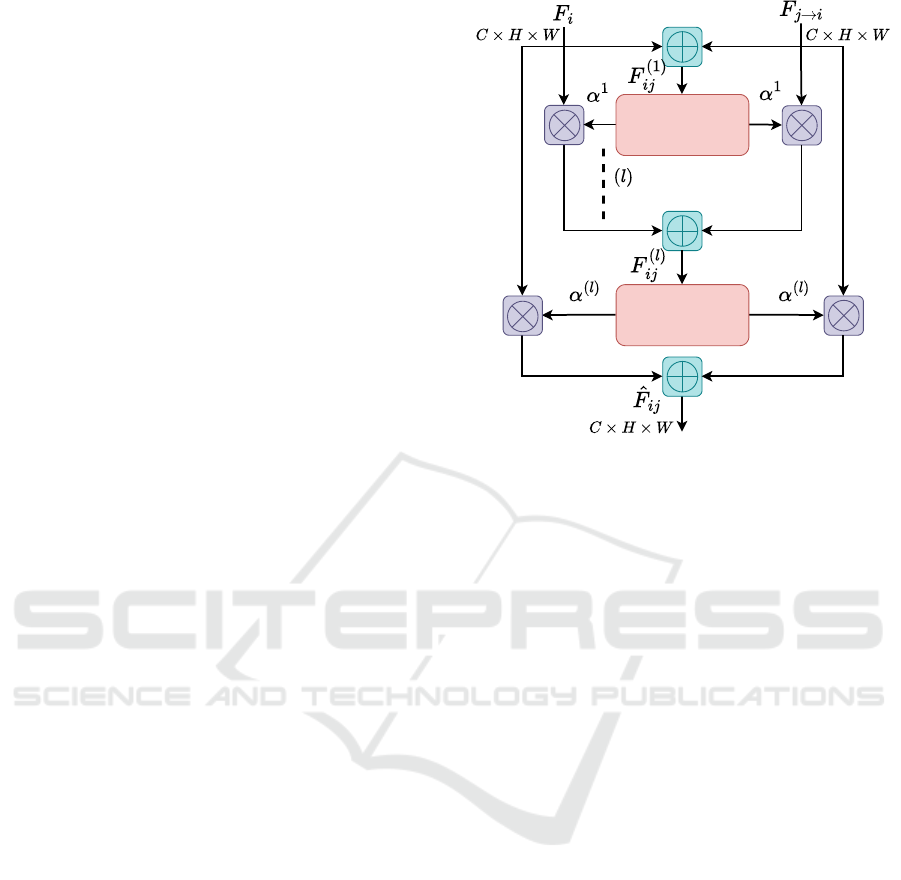
• Iterative Attention To enhance the attention map
of complementary information from the aggre-
gated features, we propose an iterative attention
learning strategy. This strategy progressively
refines the spatial and channel attention maps,
thereby enhancing the discriminative power of the
learned features and improving the feature fusion
process. At the end of each iteration, the features
are aggregated and forwarded to the next iterative
layer, refining the input to the attention module
Attention
Module
Attention
Module
number of iterations
Figure 4: Illustration of the proposed iterative attention fea-
ture fusion where the attention module, shown in Fig.3, is
repeated for l iterations.
and potentially generating more expressive atten-
tion maps. After l iterations, as illustrated in Fig.
4, the fused feature F
(l)
i j
is incrementally updated
through each attention iteration, ultimately pro-
ducing the final representation
ˆ
F
i j
.
The attention fusion module is repeated for every
connected node to compute the updated feature
ˆ
F
iN
.
Node Feature Aggregation. After obtaining updated
features from the attention fusion module, the final
updated feature, H
i
is computed as a weighted sum,
where each feature
ˆ
F
iN
s multiplied by its correspond-
ing learnable edge weight matrix W
iN
as follows:
H
i
=
∑
(W
iN
ˆ
F
iN
) (6)
3.6 Decoder Network
After the graph-based fusion, the ego agent the fea-
ture map H
i
is passed into the detection decoder that
decodes it into objects, including class and regression
output. This study aims to enhance the feature ag-
gregation methodology using a graph attention-based
network and assess its performance in comparison
to state-of-the-art techniques. In line with the fea-
ture extractor (discussed in Section 3.2, we adopt the
same detection decoder network utilized by DiscoNet
Φ
DiscoNet
(·) (Li et al., 2021), and V2VNet Φ
V2VNet
(·)
(Wang et al., 2020), to produce the final detection out-
puts.
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative Perception
825

4 EXPERIMENTAL SETUP
Dataset. We evaluate our work using V2X-Sim
(Li et al., 2022) and OPV2V (Xu et al., 2022b)
datasets. V2X-Sim dataset integrates the SUMO
platform (Krajzewicz et al., 2012) for generating
traffic flow data and the Carla simulator (Dosovitskiy
et al., 2017) to capture sensor data from multiple
agents. V2X-Sim consists of 10,000 frames across
100 scenes, each involving 2-5 collaborative agents.
We split the dataset into training, validation, and
test sets containing 8,000, 1,000, and 1,000 frames,
respectively. Each frame includes data collected
from vehicles and roadside units (RSUs), resulting in
37,200 training samples, 5,000 validation samples,
and 5,000 test samples. This work evaluates object
detection performance in two scenarios: without
RSU (w/o RSU) and with RSU (w/ RSU).
OPV2V is a large-scale V2V perception dataset
created utilizing CARLA (Dosovitskiy et al., 2017)
and OpenCDA (Xu et al., 2021). The dataset con-
sists of around 11,464 LiDAR point cloud frames.
OPV2V is divided into two subsets: the default
CARLA towns and the Culver City digital town. The
default town subset has a total of 10,914 frames.
These frames are divided into train/val/test splits of
6,764/1,980/2,170 frames, respectively. This subset
offers a broad spectrum of scenarios characterized by
varying levels of complexity. In contrast, the Culver
City subset consists of 550 frames used for evaluation
that simulate a real-world urban environment, with a
wide range of objects and structures.
Evaluation Metrics.To supervise foreground-
background classification loss, we utilize the
binary cross-entropy (Mannor et al., 2005). For
the bounding-box regression loss, we utilize the
weighted smooth loss. To assess the collaborative
perception detection performance we utilize average
precision (AP) over the Intersection over Union (IoU)
thresholds of 0.5 and 0.7.
Training Setup. We utilize the Adam optimizer with
an initial learning rate of 10
−3
and steadily decay at
every 10 epochs using a factor of 0.1. All models
are trained on NVIDIA Tesla V100 GPU with a batch
size of 4. We compare GIFF with no, early, and late
collaboration methods. For the intermediate collab-
oration methods, we benchmark six approaches that
evaluated their result using V2XSim: When2Com
(Liu et al., 2020a), Who2Com (Liu et al., 2020b),
V2VNet (Wang et al., 2020), DiscoNet (Li et al.,
2021), Ahmed et. al. (Ahmed et al., 2024b), Collab-
GAT (Ahmed et al., 2024a). For OPV2V the bench-
marks are: F-Cooper(Chen et al., 2019), Who2Com,
AttFuse (Xu et al., 2022b), V2VNet, HP3D-V2V
(Chen et al., 2024) and CollabGAT.
Table 1: Object detection AP on V2X-SIM reporting re-
sults of both with and without RSU at IoU of 0.5 and 0.7.
Note results in red, blue, green denoting the 1
st
,2
nd
and 3
rd
highest AP results.
Method
AP@IoU=0.5 AP@IoU=0.7
w/o RSU w/RSU w/o RSU w/RSU
When2com 44.02 46.39 39.89 40.32
Who2com 44.02 46.39 39.89 40.32
V2VNet 68.35 72.08 63.83 65.85
DiscoNet 69.03 72.87 63.44 66.40
Ahmed et. al 68.97 72.96 63.48 65.94
CollabGAT 69.67 75.57 63.72 73.29
GIFF (Ours) 73.62 78.93 68.37 75.82
No Collaboration 49.90 46.96 44.21 42.33
Late Collaboration 43.99 42.98 39.10 38.26
Early Collaboration 70.43 77.08 67.04 72.57
Table 2: Object detection AP on OPV2V reporting results
tested on default and Culver at IoU of 0.5 and 0.7. Note re-
sults in red, blue, green denoting the 1
st
,2
nd
and 3
rd
high-
est AP results.
Method
Default Culver
AP@0.5 AP@0.7 AP@0.5 AP@0.7
F-Cooper 61.77 49.85 53.79 44.50
Who2Com 62.04 50.52 54.11 44.21
AttFuse 62.86 50.84 54.01 46.37
V2VNet 63.33 51.67 54.54 45.87
HP3D-V2V 67.42 56.50 58.83 50.51
CollabGAT 68.41 58.32 60.01 51.82
GIFF (Ours) 69.60 60.04 61.35 51.93
No Collaboration 49.13 38.38 40.66 26.70
Late Collaboration 59.61 42.53 49.45 39.76
Early Collaboration 52.35 40.66 42.59 35.34
5 RESULTS AND DISCUSSION
Detection Performance. Tables. 1 and 2 shows
the AP object detection performance of GIFF on
V2XSim and OPV2V datasets. As shown in Table. 1,
our method significantly outperforms V2VNet (Wang
et al., 2020), DiscoNet (Li et al., 2021), (Ahmed et al.,
2024b), and CollabGAT (Ahmed et al., 2024a); for
instance, at IoU of 0.7 w/RSU, our method achieves
performance gains of 15.14%, 14.19%, 15%, and
3.45%, respectively. For the OPV2V results shown
in Table. 2, among all fusion models GIFF consis-
tently achieves the highest AP scores for both driv-
ing scenarios. Especially GIFFS’s superiority in the
Culver City scenario demonstrates its strong general-
ization ability. These illustrated results highlight the
effectiveness of GIFF in enhancing the object detec-
tion AP when compared to other state-of-the-art in-
termediate collaboration methods. This improvement
can be attributed to our proposed iterative attention-
based learning network, which iteratively refines the
attention map, allowing the model to focus more ac-
curately on relevant regions in both ego-centric and
received semantic information. Unlike the attention
mechanisms in CollabGAT and Ahmed et al., which
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
826

Table 3: Number of parameters of each model trained on
V2XSim dataset.
Method No. of parameters (M)
V2VNet 21.08
DiscoNet 15.84
Ahmed et. al 15.98
CollabGAT 15.93
GIFF (Ours) 16.12
also incorporate attention within their method, our
iterative attention fusion approach enables superior
feature fusion by progressively learning the signifi-
cance of each feature map in relation to ego-centric
semantic information while preserving spatial rela-
tionships across feature maps. In addition to that, the
attention cooperation within the multi-agent fusion
scheme, where channel attention directs the model to
relevant features across channels, while spatial atten-
tion focuses on important spatial locations, enhancing
the model’s overall feature fusion.
Computational Efficiency. Table. 3 presents the pa-
rameter counts for each state-of-the-art method. Our
proposed method demonstrates a 23.5% reduction in
parameter count compared to the V2VNet network.
For other methods, the parameter count of our model
is either comparable or marginally higher, with an in-
creased range of approximately 0.9% to 1.7%. How-
ever, this slight increase is negligible given the sub-
stantial performance improvements achieved. This
efficiency is attributed to our iterative PWConv atten-
tion mechanism, which iteratively enhances the atten-
tion map without significantly impacting model size,
thereby supporting performance gains in object detec-
tion. A more detailed analysis is presented in the ab-
lation study (Section 6).
Table 4: This table gives an experiment number to differ-
entiate the different settings of GIFF conducted within the
ablation study.
Experiment No. Model Base
Aggregation
Operation
Depth
1
DiscoNet
Sum 256, 128, 64
2(Default) Sum 256, 128, 64, 32
3 Concat 512, 256, 128, 64
4 Concat 512, 256, 128, 64, 32
5
V2VNet
Concat 512, 256, 128, 64
6 Concat 512, 256, 128, 64, 32
6 ABLATION STUDY
Table. 4 shows the design of each experiment con-
ducted to evaluate the effect of every module of GIFF,
with every design carrying the species experiment tag.
Effect of Deeper Attention Layers. This module is
defined by Eqs. 2b and 3, which govern the learn-
ing of channel and spatial attention maps. As shown
in Table 5, a deeper encoder-decoder architecture
leads to a higher object detection AP. This improve-
ment is attributed to our proposed attention network,
which is based on a PwC framework. In this net-
work, deeper layers capture higher-level and more ab-
stract representations of the input data. Consequently,
the network learns intricate patterns and correlations
among features, as the deeper layers combine features
learned in earlier stages to create representations that
capture more complex aspects of the input. These
high-level representations are crucial for learning at-
tention weights effectively. However, we observed
that increasing depth beyond the tested level led to
a decrease in AP due to the vanishing gradient prob-
lem, where the gradient signal becomes too weak to
propagate effectively through multiple layers.
Effect of Aggregation Operation. This section ex-
amines the aggregation function “AGG” employed in
Eq. 1. As presented in Table 5, the experimental
setup in experiment “2” achieves the highest detec-
tion AP with a minimal model parameter count, while
experiment “1” attains the second-highest AP, how-
ever, it achieves the lowest parameter count of all
experiments. Quantitative analysis of the proposed
methodology demonstrates that summation slightly
outperforms concatenation. This can be attributed
to summation’s ability to seamlessly integrate infor-
mation, effectively combining low-level details (such
as edges) with high-level semantics (such as object
shapes), thus yielding more cohesive and generaliz-
able features. Additionally, summation aids gradient
flow during backpropagation by preserving feature
map size and channel consistency, which contributes
to stable training—especially in deep networks prone
to gradient degradation. Concatenation increases di-
mensionality and computational requirements, as re-
flected in a higher parameter count in the last column
of Table 5.
Effect of Iterative Fusion. As shown in Table. 5
adding another layer of attention further improves
the performance as the iterative extraction allows the
model to tune the parameters to extract even more in-
formation from the initially fused feature map. How-
ever, this improvement may be obtained at the cost of
increasing the model’s number of parameters. Inter-
estingly, we find that extra iterations do not boost per-
formance, and two iterations achieve the best results
in our experiment.
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative Perception
827

Table 5: The AP and the number of parameters are represented by different design considerations of GIFF. Aggregation Op-
eration represents the “AGG” featured in Eq. \ref{aggregate features}. “Depths” represents the feature map dimensionality
reduction to compute the attention weights. w/IAtten and w/o represent the AP with and without iterative attention.
Experiment No.
AP@IoU=0.5 AP@IoU=0.7 No. of Parameters (M)
w/ IAtten w/o IAtten w/ IAtten w/o IAtten
w/ IAtten w/o IAtten
w/o RSU w/RSU w/o RSU w/RSU w/o RSU w/RSU w/o RSU w/RSU
1 71.28 77.26 68.56 71.81 66.85 73.29 62.88 65.86 16.10 15.39
2 (Default) 73.62 78.93 68.97 72.96 68.37 75.82 63.48 65.94 16.12 15.98
3 68.53 74.33 68.14 71.61 62.76 67.42 62.36 64.41 16.89 16.20
4 67.15 72.14 68.50 72.25 64.32 68.46 63.32 63.74 16.92 16.21
5 68.56 70.05 67.53 70.0 62.68 71.14 61.55 63.52 17.06 16.78
6 69.93 72.78 68.46 70.94 63.12 68.37 63.10 63.10 17.13 16.85
7 CONCLUSION AND FUTURE
WORK
This paper presents GIFF, a graph iterative attention-
based network designed to address collaborative per-
ception challenges in multi-agent systems. GIFF ef-
fectively facilitates multi-agent collaboration by intel-
ligently fusing perceptual information received from
collaborators. It achieves this by learning the relative
importance of collaborators and identifying the spa-
tial regions within the received semantic information
that require higher attention. The iterative attention
mechanism further enhances the refinement of the
attention-learning process. GIFF achieves superior
performance on the object detection task, as demon-
strated on standard benchmarks such as V2XSim
and OPV2V. Despite these promising results, the ap-
proach has significant potential for future improve-
ments. As part of future work, we aim to address the
impact of transmission delays caused by communica-
tion network characteristics, which hinder the perfor-
mance of collaborative perception.
REFERENCES
Ahmed, A. N., Anwar, A., Mercelis, S., Latr
´
e, S., and
Hellinckx, P. (2021). Ff-gat: Feature fusion using
graph attention networks. In IECON 2021–47th An-
nual Conference of the IEEE Industrial Electronics
Society, pages 1–6. IEEE.
Ahmed, A. N., Mercelis, S., and Anwar, A. (2024a). Col-
labgat: Collaborative perception using graph attention
network. IEEE Access.
Ahmed, A. N., Mercelis, S., and Anwar, A. (2024b). Graph
attention based feature fusion for collaborative per-
ception. In 2024 IEEE Intelligent Vehicles Symposium
(IV), pages 2317–2324. IEEE.
Ahmed, A. N., Ravijts, I., de Hoog, J., Anwar, A., Mer-
celis, S., and Hellinckx, P. (2022). A joint perception
scheme for connected vehicles. In 2022 IEEE Sensors,
pages 1–4. IEEE.
Ball
´
e, J., Minnen, D., Singh, S., Hwang, S. J., and Johnston,
N. (2018). Variational image compression with a scale
hyperprior. arXiv preprint arXiv:1802.01436.
Chen, H., Wang, H., Liu, Z., Gu, D., and Ye, W.
(2024). Hp3d-v2v: High-precision 3d object detection
vehicle-to-vehicle cooperative perception algorithm.
Sensors, 24(7):2170.
Chen, Q., Ma, X., Tang, S., Guo, J., Yang, Q., and Fu,
S. (2019). F-cooper: Feature based cooperative per-
ception for autonomous vehicle edge computing sys-
tem using 3d point clouds. In Proceedings of the 4th
ACM/IEEE Symposium on Edge Computing, pages
88–100.
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., and
Koltun, V. (2017). CARLA: An open urban driving
simulator. In Proceedings of the 1st Annual Confer-
ence on Robot Learning, pages 1–16.
Guo, M.-H., Xu, T.-X., Liu, J.-J., Liu, Z.-N., Jiang, P.-T.,
Mu, T.-J., Zhang, S.-H., Martin, R. R., Cheng, M.-M.,
and Hu, S.-M. (2022). Attention mechanisms in com-
puter vision: A survey. Computational visual media,
8(3):331–368.
Han, Y., Zhang, H., Li, H., Jin, Y., Lang, C., and Li, Y.
(2023). Collaborative perception in autonomous driv-
ing: Methods, datasets, and challenges. IEEE Intelli-
gent Transportation Systems Magazine.
Hu, Y., Fang, S., Lei, Z., Zhong, Y., and Chen, S. (2022).
Where2comm: Communication-efficient collabora-
tive perception via spatial confidence maps. Advances
in neural information processing systems, 35:4874–
4886.
Jaderberg, M., Simonyan, K., Zisserman, A., et al. (2015).
Spatial transformer networks. Advances in neural in-
formation processing systems, 28.
Kenney, J. B. (2011). Dedicated short-range communica-
tions (dsrc) standards in the united states. Proceedings
of the IEEE, 99(7):1162–1182.
Krajzewicz, D., Erdmann, J., Behrisch, M., and Bieker,
L. (2012). Recent development and applications of
sumo-simulation of urban mobility. International
journal on advances in systems and measurements,
5(3&4).
Li, Y., Ma, D., An, Z., Wang, Z., Zhong, Y., Chen, S.,
and Feng, C. (2022). V2x-sim: Multi-agent col-
laborative perception dataset and benchmark for au-
tonomous driving. IEEE Robotics and Automation
Letters, 7(4):10914–10921.
VISAPP 2025 - 20th International Conference on Computer Vision Theory and Applications
828

Li, Y., Ren, S., Wu, P., Chen, S., Feng, C., and Zhang,
W. (2021). Learning distilled collaboration graph for
multi-agent perception. Advances in Neural Informa-
tion Processing Systems, 34:29541–29552.
Liu, Y.-C., Tian, J., Glaser, N., and Kira, Z. (2020a).
When2com: Multi-agent perception via communica-
tion graph grouping. In Proceedings of the IEEE/CVF
Conference on computer vision and pattern recogni-
tion, pages 4106–4115.
Liu, Y.-C., Tian, J., Ma, C.-Y., Glaser, N., Kuo, C.-W., and
Kira, Z. (2020b). Who2com: Collaborative percep-
tion via learnable handshake communication. In 2020
IEEE International Conference on Robotics and Au-
tomation (ICRA), pages 6876–6883. IEEE.
Mannor, S., Peleg, D., and Rubinstein, R. (2005). The cross
entropy method for classification. In Proceedings of
the 22nd international conference on Machine learn-
ing, pages 561–568.
Qian, R., Lai, X., and Li, X. (2022). 3d object detection for
autonomous driving: A survey. Pattern Recognition,
130:108796.
Veli
ˇ
ckovi
´
c, P., Cucurull, G., Casanova, A., Romero, A., Lio,
P., and Bengio, Y. (2017). Graph attention networks.
arXiv preprint arXiv:1710.10903.
Wang, T.-H., Manivasagam, S., Liang, M., Yang, B., Zeng,
W., and Urtasun, R. (2020). V2vnet: Vehicle-to-
vehicle communication for joint perception and pre-
diction. In Computer Vision–ECCV 2020: 16th Euro-
pean Conference, Glasgow, UK, August 23–28, 2020,
Proceedings, Part II 16, pages 605–621. Springer.
Woo, S., Park, J., Lee, J.-Y., and Kweon, I. S. (2018). Cbam:
Convolutional block attention module. In Proceed-
ings of the European conference on computer vision
(ECCV), pages 3–19.
Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., and Philip,
S. Y. (2020). A comprehensive survey on graph neural
networks. IEEE transactions on neural networks and
learning systems, 32(1):4–24.
Xu, R., Guo, Y., Han, X., Xia, X., Xiang, H., and Ma,
J. (2021). Opencda: an open cooperative driving
automation framework integrated with co-simulation.
In 2021 IEEE International Intelligent Transportation
Systems Conference (ITSC), pages 1155–1162. IEEE.
Xu, R., Xiang, H., Tu, Z., Xia, X., Yang, M.-H., and Ma, J.
(2022a). V2x-vit: Vehicle-to-everything cooperative
perception with vision transformer. In European con-
ference on computer vision, pages 107–124. Springer.
Xu, R., Xiang, H., Xia, X., Han, X., Li, J., and Ma, J.
(2022b). Opv2v: An open benchmark dataset and
fusion pipeline for perception with vehicle-to-vehicle
communication. In 2022 International Conference on
Robotics and Automation (ICRA), pages 2583–2589.
IEEE.
Zhou, J., Cui, G., Hu, S., Zhang, Z., Yang, C., Liu, Z.,
Wang, L., Li, C., and Sun, M. (2020). Graph neu-
ral networks: A review of methods and applications.
AI open, 1:57–81.
Zhou, Y., Xiao, J., Zhou, Y., and Loianno, G. (2022).
Multi-robot collaborative perception with graph neu-
ral networks. IEEE Robotics and Automation Letters,
7(2):2289–2296.
GIFF: Graph Iterative Attention Based Feature Fusion for Collaborative Perception
829
